Introductie
Data-analyse en visualisatie zijn krachtige tools die ons in staat stellen om complexe datasets te begrijpen en inzichten effectief te communiceren. In deze meeslepende verkenning van conflictgegevens uit de echte wereld duiken we diep in de harde realiteit en complexiteit van conflicten. Onze focus ligt op Manipur, een staat in het noordoosten van India, die helaas wordt ontsierd door langdurig geweld en onrust. De ... gebruiken Gewapend conflict Locatie & evenementgegevens Project (ACLED) dataset [1], beginnen we aan een diepgaande data-analysereis om de veelzijdige aard van de conflicten bloot te leggen.
leerdoelen
- Vaardigheid verwerven in data-analysetechnieken voor ACLED-dataset.
- Ontwikkel vaardigheden in effectieve datavisualisatie voor communicatie.
- Begrijp de impact van geweld op kwetsbare bevolkingsgroepen.
- Krijg inzicht in temporele en ruimtelijke aspecten van de conflicten.
- Ondersteun empirisch onderbouwde benaderingen voor het aanpakken van humanitaire behoeften.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Belangenconflict
Er is geen specifieke organisatie of entiteit verantwoordelijk voor de analyse en interpretatie die in deze blog wordt gepresenteerd. Het doel is puur om het potentieel van datawetenschap in conflictanalyse te demonstreren. Bovendien zijn er geen persoonlijke belangen of vooroordelen betrokken bij deze bevindingen, waardoor een objectieve benadering van het begrijpen van conflictdynamiek wordt gegarandeerd. Bevorder het gebruik van gegevensgestuurde methoden als hulpmiddel voor het verbeteren van inzichten en het informeren van bredere discussies over conflictanalyse.
Implementatie
Waarom ACLED-gegevensset?
Door gebruik te maken van de kracht van datawetenschapstechnieken op de ACLED-dataset. We kunnen inzichten verkrijgen die niet alleen bijdragen aan het begrijpen van de situatie in Manipur, maar ook licht werpen op de humanitaire aspecten die verband houden met het geweld. De ACLED-codeboek is een uitgebreide naslaggids die gedetailleerde informatie geeft over het coderingsschema en de variabelen die in deze dataset worden gebruikt [2].
Het belang van ACLED ligt in de empathische data-analyse, die ons begrip van het geweld in Manipur vergroot, de humanitaire behoeften belicht en bijdraagt aan het aanpakken en verminderen van geweld. Het bevordert een vreedzame en inclusieve toekomst voor de getroffen gemeenschappen.
Door deze gegevensgestuurde analyse kunnen we niet alleen waardevolle inzichten ontrafelen, maar kunnen we ook de menselijke kosten van het geweld in Manipur benadrukken. Door de ACLED-gegevens nauwkeurig te bestuderen, hoop ik dat we licht kunnen werpen op de impact op de burgerbevolking, gedwongen ontheemding en toegang tot essentiële diensten, en zo een alomvattend beeld kunnen schetsen van de humanitaire realiteit in de regio.
Gebeurtenissen van conflict
Als eerste stap zullen we de conflictgebeurtenissen in Manipur verkennen met behulp van de ACLED-dataset. Het onderstaande codefragment leest de ACLED-dataset voor India en filtert de gegevens specifiek voor Manipur, wat resulteert in een gefilterde dataset met de vorm van (aantal rijen, aantal kolommen). De vorm van de gefilterde gegevens wordt vervolgens afgedrukt.
import pandas as pd #import country specific csv downloaded from acleddata.com file_path = './acled_India.csv' all_data = pd.read_csv(file_path) # Filter the data for Manipur df_filtered = all_data.loc[all_data['admin1'] == "Manipur"] shape = df_filtered.shape print("Filtered Data Shape:", shape) #Output: #Filtered Data Shape: (4495, 31)Het aantal rijen in de ACLED-gegevens vertegenwoordigt het aantal individuele gebeurtenissen of incidenten dat is vastgelegd in de dataset. Elke rij komt doorgaans overeen met een specifieke gebeurtenis, zoals een conflict, protest of geweld, en bevat verschillende attributen of kolommen die informatie geven over de gebeurtenis, zoals de locatie, datum, betrokken actoren en andere relevante details.
Door het aantal rijen in de ACLED-gegevensset te tellen, kunt u het totale aantal geregistreerde gebeurtenissen of incidenten in de gegevens bepalen. Door de dataset specifiek voor Manipur te filteren, verkregen we een gefilterde dataset met informatie over individuele gebeurtenissen of incidenten geregistreerd van januari 2016 tot 9 juni 2023. Het totale aantal geregistreerde gebeurtenissen of incidenten in Manipur, dat 4495 rijen bedroeg, gaf inzicht in de reikwijdte en schaal van het conflict of de gebeurtenissen die door ACLED worden gevolgd.
Als volgende stap berekenen we de som van null-waarden langs de kolommen (as=0) in het df_filtered DataFrame. Het biedt inzicht in het aantal ontbrekende waarden in elke kolom van de gefilterde dataset.
df_filtered.isnull().sum(axis = 0) # Output: count of null values in each column
# event_id_cnty: 0 null values
# event_date: 0 null values
# year: 0 null values
# time_precision: 0 null values
# disorder_type: 0 null values
# event_type: 0 null values
# sub_event_type: 0 null values
# actor1: 0 null values
# assoc_actor_1: 1887 null values
# inter1: 0 null values
# actor2: 3342 null values
# assoc_actor_2: 4140 null values
# inter2: 0 null values
# interaction: 0 null values
# civilian_targeting: 4153 null values
# iso: 0 null values
# region: 0 null values
# country: 0 null values
# admin1: 0 null values
# admin2: 0 null values
# admin3: 0 null values
# location: 0 null values
# latitude: 0 null values
# longitude: 0 null values
# geo_precision: 0 null values
# source: 0 null values
# source_scale: 0 null values
# notes: 0 null values
# fatalities: 0 null values
# tags: 1699 null values
# timestamp: 0 null valuesOnderstaand codefragment voert het aantal unieke waarden in elke kolom uit.
n = df_filtered.nunique(axis=0) print("No.of.unique values in each column:n", n) # Output:
# No.of.unique values in each column:
# event_id_cnty: 4495
# event_date: 1695
# year: 8
# time_precision: 3
# disorder_type: 4
# event_type: 6
# sub_event_type: 17
# actor1: 66
# assoc_actor_1: 323
# inter1: 8
# actor2: 61
# assoc_actor_2: 122
# inter2: 9
# interaction: 28
# civilian_targeting: 1
# iso: 1
# region: 1
# country: 1
# admin1: 1
# admin2: 16
# admin3: 37
# location: 495
# latitude: 485
# longitude: 480
# geo_precision: 3
# source: 233
# source_scale: 12
# notes: 4462
# fatalities: 10
# tags: 97
# timestamp: 1070
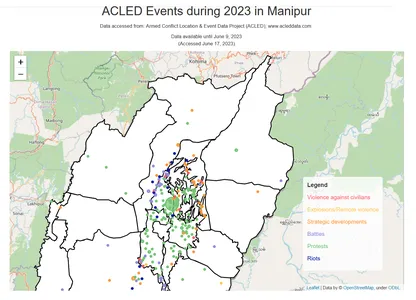
Een interactieve kaart met behulp van Folium Library om de ACLED-gebeurtenissen te visualiseren
Manipur is geografisch verdeeld in twee verschillende regio's: het dalgebied en het heuvelachtige gebied. Het dalgebied, gelegen in het centrale deel van Manipur, is relatief vlak en omgeven door heuvels. Het is het meest dichtbevolkte en agrarisch productieve gebied van de staat. Het heuvelachtige gebied daarentegen bestaat uit de omliggende heuvels en bergen en biedt een meer ruig en bergachtig terrein.
De onderstaande code maakt een interactieve kaart met behulp van de Folium-bibliotheek om de ACLED-gebeurtenissen te visualiseren die plaatsvonden in Manipur in de jaren 2022 en 2023. Het plot de gebeurtenissen als cirkelmarkeringen op de kaart, waarbij de kleur van elke markering het overeenkomstige jaar vertegenwoordigt. Het voegt ook een GeoJSON-laag toe om de grenzen van Manipur weer te geven en bevat een kaarttitel, credits en een legenda die de kleurcodes voor de jaren aangeeft. De definitieve kaart wordt weergegeven met al deze elementen.
import folium # Filter the data for the years 2022 and 2023 df_filtered22_23 = df_filtered[(df_filtered['year'] == 2022) | (df_filtered['year'] == 2023)] # Create a map instance map = folium.Map(location=[24.8170, 93.9368], zoom_start=8) # Load Manipur boundaries from GeoJSON file manipur_geojson = 'Manipur.geojson' # Create a GeoJSON layer for Manipur boundaries and add it to the map folium.GeoJson(manipur_geojson, style_function=lambda feature: { 'fillColor': 'white', 'color': 'black', 'weight': 2, 'fillOpacity': 1 }).add_to(map) # Define color palette for different years color_palette = {2022: 'red', 2023: 'blue'} # Plot the events on the map with different colors based on the year for index, row in df_filtered22_23.iterrows(): folium.CircleMarker([row['latitude'], row['longitude']], radius=3, color=color_palette[row['year']], fill=True, fill_color=color_palette[row['year']], fill_opacity=0.5).add_to(map) # Add map features folium.TileLayer('cartodbpositron').add_to(map) # Set the map's center and zoom level map.fit_bounds(map.get_bounds()) map.get_root().html.add_child(folium.Element(legend_html)) # Display the map mapOutput:
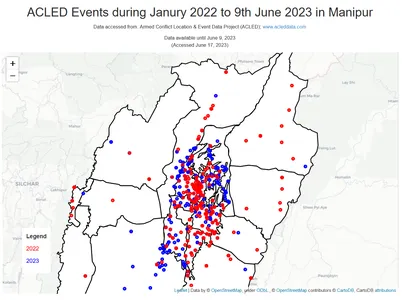
Je kunt zien dat er een hogere concentratie van gebeurtenissen wordt waargenomen in de regio van de centrale vallei. Dit kan te wijten zijn aan verschillende factoren, zoals bevolkingsdichtheid, infrastructuur, bereikbaarheid en historische sociaal-politieke dynamiek. De regio van de centrale vallei, die dichter bevolkt en economisch ontwikkeld is, zou mogelijk getuige kunnen zijn van meer incidenten en gebeurtenissen in vergelijking met de heuvelachtige gebieden.
ACLED-gebeurtenistypen
ACLED event_type verwijst naar de categorisatie van verschillende soorten gebeurtenissen die zijn vastgelegd in de ACLED-dataset. Deze gebeurtenistypen leggen verschillende activiteiten en incidenten vast die verband houden met conflicten, geweld, protesten en andere interessante gebeurtenissen. Sommige typen gebeurtenissen in de ACLED-dataset omvatten geweld tegen burgers, explosies/geweld op afstand, protesten, rellen en meer. Deze gebeurtenistypen geven inzicht in de aard en dynamiek van conflicten en gerelateerde incidenten die zijn vastgelegd in de ACLED-database.
Onderstaande code genereert een staafdiagram met gebeurtenissen die per jaar zijn gegroepeerd en visualiseert de gebeurtenistypen in Manipur, India door de jaren heen.
import pandas as pd import matplotlib.pyplot as plt df_filteredevent = df_filtered.copy() df_filteredevent['event_date'] = pd.to_datetime(df_filteredevent['event_date']) # Group the data by year df_cross_event = df_filteredevent.groupby(df_filteredevent['event_date'].dt.year)
['event_type'].value_counts().unstack() # Define the color palette color_palette = ['#FF5C5C', '#FFC94C', '#FF9633', '#8E8EE1', '#72C472', '#0818A8'] # Plot the bar chart fig, ax = plt.subplots(figsize=(10, 6)) df_cross_event.plot.bar(ax=ax, color=color_palette) # Set the x-axis tick labels to display only the year ax.set_xticklabels(df_cross_event.index, rotation=0) # Set the legend ax.legend(title='Event Types', bbox_to_anchor=(1, 1.02), loc='upper left') # Set the axis labels and title ax.set_xlabel('Year') ax.set_ylabel('Event Count') ax.set_title('Manipur, India: ACLED Event Types by Year') # Adjust the padding and layout plt.tight_layout(rect=[0, 0, 0.95, 1]) # Display the plot plt.show()Output:
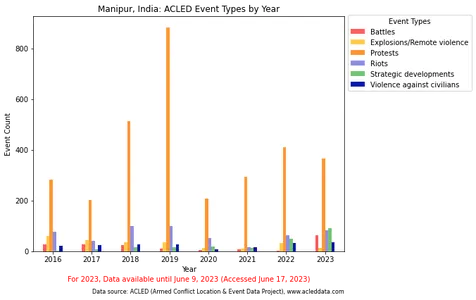
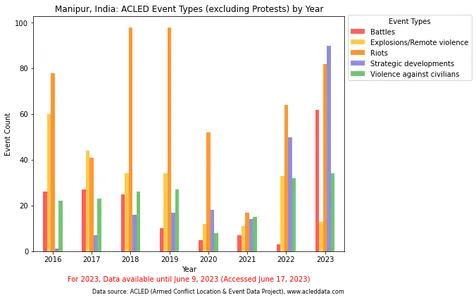
Met name de visualisatie van gebeurtenistypen in een staafdiagram benadrukte de dominantie van de categorie 'Protesten', wat de relatieve verschillen zou kunnen verdoezelen en het een uitdaging zou kunnen maken om andere evenementtypen nauwkeurig te vergelijken. De visualisatie werd aangepast door de categorie "Protesten" uit te sluiten of te scheiden, wat resulteerde in een duidelijkere vergelijking van de overige gebeurtenistypes.
Onderstaand codefragment filtert het gebeurtenistype 'Protesten' uit de gegevens. Vervolgens groepeert het de resterende gebeurtenissen per jaar en visualiseert ze in een staafdiagram, met uitzondering van de dominante categorie "Protesten". De resulterende visualisatie geeft een duidelijker beeld van de gebeurtenistypes per jaar.
import pandas as pd import matplotlib.pyplot as plt df_filteredevent = df_filtered.copy() df_filteredevent['event_date'] = pd.to_datetime(df_filteredevent['event_date']) # Filter out the "Protests" event type df_filteredevent = df_filteredevent[df_filteredevent['event_type'] != 'Protests'] # Group the data by year df_cross_event = df_filteredevent.groupby(df_filteredevent['event_date'].dt.year)
['event_type'].value_counts().unstack() # Define the color palette color_palette = ['#FF5C5C', '#FFC94C', '#FF9633', '#8E8EE1', '#72C472', '#0818A8'] # Plot the bar chart fig, ax = plt.subplots(figsize=(10, 6)) df_cross_event.plot.bar(ax=ax, color=color_palette) # Set the x-axis tick labels to display only the year ax.set_xticklabels(df_cross_event.index, rotation=0) # Set the legend ax.legend(title='Event Types', bbox_to_anchor=(1, 1.02), loc='upper left') # Set the axis labels and title ax.set_xlabel('Year') ax.set_ylabel('Event Count') ax.set_title('Manipur, India: ACLED Event Types (excluding Protests) by Year') # Adjust the padding and layout plt.tight_layout(rect=[0, 0, 0.95, 1]) # Display the plot plt.show()Output:
Gebeurtenisdynamiek visualiseren: gebeurtenistypen en frequenties in kaart brengen
We gebruiken de interactieve kaarten voor het uitzetten van gebeurtenissen op een kaart met variërende markeringsgrootte en kleur op basis van gebeurtenistype en frequentie. Het vertegenwoordigt de ruimtelijke verdeling en intensiteit van verschillende gebeurtenissen, waardoor patronen, hotspots en trends snel kunnen worden geïdentificeerd. Deze aanpak verbetert de geografische dynamiek van de gebeurtenissen, vergemakkelijkt datagestuurde besluitvorming en maakt effectieve toewijzing van middelen en gerichte interventies mogelijk als reactie op de geïdentificeerde patronen en frequenties.
De gebeurtenissen worden uitgezet als cirkelmarkeringen op de kaart, met variërende kleur en grootte op basis van respectievelijk het gebeurtenistype en de frequentie.
import folium import json # Filter the data for the year 2023 df_filtered23 = df_filtered[df_filtered['year'] == 2023] # Calculate the event count for each location event_counts = df_filtered23.groupby(['latitude', 'longitude']).size().
reset_index(name='count') # Create a map instance map = folium.Map(location=[24.8170, 93.9368], zoom_start=8) # Load Manipur boundaries from GeoJSON file with open('Manipur.geojson') as f: manipur_geojson = json.load(f) # Create a GeoJSON layer for Manipur boundaries and add it to the map folium.GeoJson(manipur_geojson, style_function=lambda feature: { 'fillColor': 'white', 'color': 'black', 'weight': 2, 'fillOpacity': 1 }).add_to(map) # Define a custom color palette inspired by ACLED thematic categories event_type_palette = { 'Violence against civilians': '#FF5C5C', # Dark orange 'Explosions/Remote violence': '#FFC94C', # Bright yellow 'Strategic developments': '#FF9633', # Light orange 'Battles': '#8E8EE1', # Purple 'Protests': '#72C472', # Green 'Riots': '#0818A8' # Zaffre } # Plot the events on the map with varying marker size and color based on # the event type and frequency for index, row in event_counts.iterrows(): location = (row['latitude'], row['longitude']) count = row['count'] # Get the event type for the current location event_type = df_filtered23[(df_filtered23['latitude'] == row['latitude']) & (df_filtered23['longitude'] == row['longitude'])] ['event_type'].values[0] folium.CircleMarker( location=location, radius=2 + count * 0.1, color=event_type_palette[event_type], fill=True, fill_color=event_type_palette[event_type], fill_opacity=0.7 ).add_to(map) # Add legends for the year 2023 legend_html = """ <div style="position: fixed; bottom: 50px; right: 50px; z-index: 1000; font-size: 14px; background-color: rgba(255, 255, 255, 0.8); padding: 10px; border-radius: 5px;"> <p><strong>Legend</strong></p> <p><span style="color: #FF5C5C;">Violence against civilians</span></p> <p><span style="color: #FFC94C;">Explosions/Remote violence</span></p> <p><span style="color: #FF9633;">Strategic developments</span></p> <p><span style="color: #8E8EE1;">Battles</span></p> <p><span style="color: #72C472;">Protests</span></p> <p><span style="color: #0818A8;">Riots</span></p> </div> """ map.get_root().html.add_child(folium.Element(legend_html)) # Display the map map Output:
Primaire actoren van conflict
In deze stap krijgen we inzicht in de verschillende entiteiten of groepen die betrokken zijn bij het conflict of de gebeurtenissen in Manipur. In de ACLED-dataset verwijst de "actor1" naar de primaire actor die betrokken is bij een geregistreerde gebeurtenis. Het vertegenwoordigt de belangrijkste entiteit of groep die verantwoordelijk is voor het initiëren van of deelnemen aan een specifiek conflict of evenement. De kolom 'actor1' geeft informatie over de identiteit van de primaire actor, zoals een regering, rebellengroep, etnische milities of andere entiteiten die betrokken zijn bij het conflict of de gebeurtenis. Elke unieke waarde in de kolom "actor1" vertegenwoordigt een afzonderlijke actor of groep die betrokken is bij de geregistreerde gebeurtenissen.
Visualiseerde vervolgens de waardetellingen van 'actor1' met behulp van het onderstaande codefragment:
Deze code filtert een DataFrame op basis van de waardetellingen van de kolom 'actor1' en selecteert alleen die met aantallen groter dan of gelijk aan 5. Vervolgens worden de resulterende gegevens gevisualiseerd.
import matplotlib.pyplot as plt # Filter the DataFrame based on value counts >= 5 filtered_df = df_filtered[(df_filtered['year'] != 2023)]['actor1'].
value_counts().loc[lambda x: x >= 5] # Create a figure and axes for the horizontal bar chart fig, ax = plt.subplots(figsize=(8, 6)) # Define the color palette color_palette = ['#FF5C5C', '#FFC94C', '#FF9633', '#8E8EE1', '#72C472', '#0818A8'] # Plot the horizontal bar chart filtered_df.plot.barh(ax=ax, color=color_palette) # Add labels and title ax.set_xlabel('Count') ax.set_ylabel('Actor1') ax.set_title('Value Counts of Actor1 (>= 5) (January 2016 to 9th December 2022)', pad=55) # Set the data availability information data_info = "Accessed on June 17, 2023" # Add credits and data availability information plt.text(0.5, 1.1, "Data accessed from:", ha='center', transform=ax.transAxes, fontsize=10) plt.text(0.5, 1.05, "Armed Conflict Location & Event Data Project (ACLED); www.acleddata.com", ha='center', transform=ax.transAxes, fontsize=10) plt.text(0.5, 1.0, data_info, ha='center', transform=ax.transAxes, fontsize=10) # Display the count next to each bar for i, v in enumerate(filtered_df.values): ax.text(v + 3, i, str(v), color='black') # Display the plots plt.tight_layout() plt.show() Output:
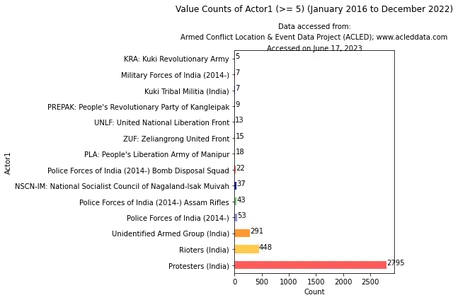
Het diagram geeft gegevens weer van januari 2016 tot 9 december 2022. Ook betekent de voorwaarde "telling groter dan of gelijk aan 5" dat alleen de actoren met een frequentie van 5 of meer in de analyse worden opgenomen en in het diagram worden weergegeven. .
Zoals weergegeven in het onderstaande codefragment, gebruikt na visualisaties om het aantal categorieën tussen 2022 en 2023 te vergelijken.
import matplotlib.pyplot as plt import numpy as np # Filter the DataFrame for the year 2022 filtered_df_2022 = df_filtered[df_filtered['year'] == 2022]['actor1'].
value_counts().loc[lambda x: x >= 10] # Filter the DataFrame for the year 2023 filtered_df_2023 = df_filtered[df_filtered['year'] == 2023]['actor1'].
value_counts().loc[lambda x: x >= 10] # Get the unique categories that appear more than 10 in either DataFrame categories = set(filtered_df_2022.index).union(set(filtered_df_2023.index)) # Create a dictionary to store the category counts category_counts = {'2022': [], '2023': []} # Iterate over the categories for category in categories: # Add the count for 2022 if available, otherwise add 0 category_counts['2022'].append(filtered_df_2022.get(category, 0)) # Add the count for 2023 if available, otherwise add 0 category_counts['2023'].append(filtered_df_2023.get(category, 0)) # Exclude categories with count 0 non_zero_categories = [category for category, count_2022, count_2023 in zip
(categories, category_counts['2022'], category_counts['2023']) if count_2022 > 0 or count_2023 > 0] # Create a figure and axes for the bar chart fig, ax = plt.subplots(figsize=(10, 6)) # Set the x-axis positions x = np.arange(len(non_zero_categories)) # Set the width of the bars width = 0.35 # Plot the bar chart for 2022 bars_2022 = ax.bar(x - width/2, category_counts['2022'], width, color=color_palette[0], label='2022') # Plot the bar chart for 2023 bars_2023 = ax.bar(x + width/2, category_counts['2023'], width, color=color_palette[1], label='2023') # Set the x-axis tick labels and rotate them for better visibility ax.set_xticks(x) ax.set_xticklabels(non_zero_categories, rotation=90) # Set the y-axis label ax.set_ylabel('Count') # Set the title and legend ax.set_title('Comparison of Actor1 Categories (>= 10) - 2022 vs 2023') ax.legend() # Add count values above each bar for rect in bars_2022 + bars_2023: height = rect.get_height() ax.annotate(f'{height}', xy=(rect.get_x() + rect.get_width() / 2, height), xytext=(0, 3), textcoords="offset points", ha='center', va='bottom') # Adjust the spacing between lines plt.subplots_adjust(top=0.9) # Display the plot plt.show()Output:
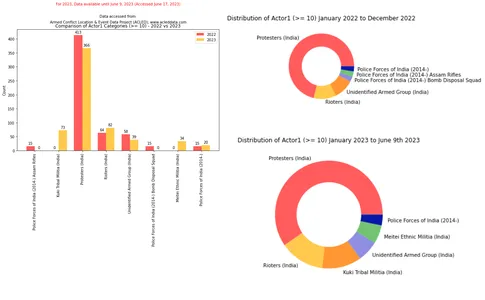
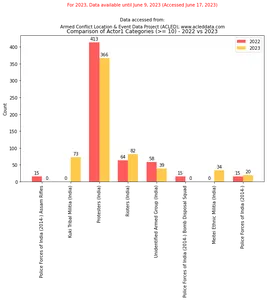
De vergelijking van ACLED-gegevens van Manipur voor het jaar 2022 en gegevens tot 9 juni 2023 kan worden verkregen door onderstaand codefragment te gebruiken:
import matplotlib.pyplot as plt import numpy as np # Filter the DataFrame for the year 2022 filtered_df_2022 = df_filtered[df_filtered['year'] == 2022]['actor1'].
value_counts().loc[lambda x: x >= 10] # Filter the DataFrame for the year 2023 filtered_df_2023 = df_filtered[df_filtered['year'] == 2023]['actor1'].
value_counts().loc[lambda x: x >= 10] # Get the unique categories that appear more than 10 in either DataFrame categories = set(filtered_df_2022.index).union(set(filtered_df_2023.index)) # Create a dictionary to store the category counts category_counts = {'2022': [], '2023': []} # Iterate over the categories for category in categories: # Add the count for 2022 if available, otherwise add 0 category_counts['2022'].append(filtered_df_2022.get(category, 0)) # Add the count for 2023 if available, otherwise add 0 category_counts['2023'].append(filtered_df_2023.get(category, 0)) # Exclude categories with count 0 non_zero_categories = [category for category, count_2022, count_2023 in zip(categories, category_counts['2022'], category_counts['2023']) if count_2022 > 0 or count_2023 > 0] # Create a figure and axes for the bar chart fig, ax = plt.subplots(figsize=(10, 6)) # Set the x-axis positions x = np.arange(len(non_zero_categories)) # Set the width of the bars width = 0.35 # Plot the bar chart for 2022 bars_2022 = ax.bar(x - width/2, category_counts['2022'], width, color=color_palette[0], label='2022') # Plot the bar chart for 2023 bars_2023 = ax.bar(x + width/2, category_counts['2023'], width, color=color_palette[1], label='2023') # Set the x-axis tick labels and rotate them for better visibility ax.set_xticks(x) ax.set_xticklabels(non_zero_categories, rotation=90) # Set the y-axis label ax.set_ylabel('Count') # Set the title and legend ax.set_title('Comparison of Actor1 Categories (>= 10) - 2022 vs 2023') ax.legend() # Add count values above each bar for rect in bars_2022 + bars_2023: height = rect.get_height() ax.annotate(f'{height}', xy=(rect.get_x() + rect.get_width() / 2, height), xytext=(0, 3), textcoords="offset points", ha='center', va='bottom') # Display the plot plt.show() Output:
Analyse van conflictintensiteit
Het volgende codefragment bereidt de gegevens voor op verdere analyse of visualisatie door de kolom 'event_date' te converteren naar datetime. Voer een kruistabel uit en herstructureer het DataFrame om interpretatie en gebruik te vergemakkelijken. Het gebruikt de functie pd.crosstab() om een kruistabel (frequentietabel) te maken tussen de 'event_date' (geconverteerd naar maandelijkse perioden met behulp van dt.to_period('m')) en de kolom 'inter1' in 'df_filtered'. Groepeert later het gefilterde DataFrame op 'event_date' en berekent de som van 'doden' voor elke datum. Bereken en voeg de som van dodelijke slachtoffers per maand toe aan het bestaande DataFrame met kruistabellen, resulterend in 'df_conflicts'. Het bevat zowel de gecategoriseerde gebeurtenisgegevens als de bijbehorende informatie over dodelijke slachtoffers voor verdere analyse.
Code Implementatie
import pandas as pd # Convert 'event_date' column to datetime data type df_filtered['event_date'] = pd.to_datetime(df_filtered['event_date']) # Perform the crosstab operation df_cross = pd.crosstab(df_filtered['event_date'].dt.to_period('m'), df_filtered['inter1']) # Rename the columns df_cross.columns = ['State Forces', 'Rebel Groups', 'Political Militias', 'Identity Militias', 'Rioters', 'Protesters', 'Civilians', 'External/Other Forces'] # Convert the period index to date df_cross['event_date'] = df_cross.index.to_timestamp() # Reset the index df_cross.reset_index(drop=True, inplace=True) df2 = df_filtered.copy() df2['event_date'] = pd.to_datetime(df2['event_date']) fatality_filtered = (df2 .filter(['event_date','fatalities']) .groupby(['event_date']) .fatalities .sum() ) df_fatality_filtered = fatality_filtered.to_frame().reset_index() df_fatality_month= df_fatality_filtered.resample('M', on="event_date").sum() df_fatality_month = df_fatality_month.reset_index() df_fatalities = df_fatality_month.drop(columns=['event_date']) df_concat = pd.concat([df_cross, df_fatalities], axis=1) df_conflicts = df_concat.copy() Output:
De code visualiseert de analyse van de conflictintensiteit voor maandelijkse gebeurtenissen in Manipur, gecategoriseerd op actortype, gewogen op basis van gerapporteerde dodelijke slachtoffers. De breedte van de lijnen is gebaseerd op het aantal dodelijke slachtoffers per actortype. Dit soort analyse stelt ons in staat om patronen te identificeren, en de relatieve impact van verschillende typen actoren die betrokken zijn bij de conflicten. Bied de waardevolle inzichten voor verdere analyse en besluitvorming in conflictstudies.
import plotly.graph_objects as go fig = go.Figure() fig.add_trace(go.Scatter( name='State Forces', x=df_conflicts['event_date'].dt.strftime('%Y-%m'), y=df_conflicts['State Forces'], mode='markers+lines', marker=dict(color='darkviolet', size=4), showlegend=True )) fig.add_trace(go.Scatter( name='Fatality weight', x=df_conflicts['event_date'], y=df_conflicts['State Forces']+df_conflicts['fatalities']/5, mode='lines', marker=dict(color="#444"), line=dict(width=1), hoverinfo='skip', showlegend=False )) fig.add_trace(go.Scatter( name='Fatality weight', x=df_conflicts['event_date'], y=df_conflicts['State Forces']-df_conflicts['fatalities']/5, marker=dict(color="#444"), line=dict(width=1), mode='lines', fillcolor='rgba(68, 68, 68, 0.3)', fill='tonexty', hoverinfo='text', hovertemplate='<br>%{x|%bn%Y}<br><i>Fatalities: %{text}</i>', text=['{}'.format(i) for i in df_conflicts['fatalities']], showlegend=False )) #similiray insert add_trace for other event types too here... fig.update_xaxes( dtick="M3", # Set the tick frequency to 3 months (quarterly) tickformat="%bn%Y" ) fig.update_layout( yaxis_title='No: of Events', title={ 'text': 'Conflict Intensity Analysis: Events in Manipur categorized by actor type, weighted by reported fatalities', 'y': 0.95, 'x': 0.5, 'xanchor': 'center', 'yanchor': 'top', 'font': {'size': 20} }, annotations=[ dict( text="January 2016 to June 9th 2023|Data accessed from: Armed Conflict Location & Event Data Project (ACLED),www.acleddata.com", xref="paper", yref="paper", x=0.5, y=1.06, showarrow=False, font={'size': 12} ) ], hovermode="x", xaxis=dict( showgrid=False ), yaxis=dict( showgrid=False ) ) fig.data[0].marker.size = 4 fig.data[3].marker.size = 4 fig.data[6].marker.size = 4 fig.data[9].marker.size = 4 fig.data[12].marker.size = 4 fig.data[15].marker.size = 4 fig.data[18].marker.size = 4 fig.data[21].marker.size = 4 fig.show()Output:
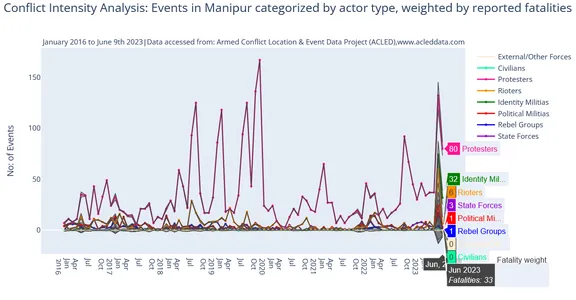
Een variabele waarde hoger (in dit geval 'Demonstranten') dan andere in een multilijngrafiek. Het kan de perceptie vervormen, waardoor het moeilijk wordt om de trends van verschillende variabelen nauwkeurig te vergelijken en te interpreteren. De dominantie van één variabele kan verminderen, omdat het een uitdaging wordt om de relatieve veranderingen en relaties tussen de andere variabelen te beoordelen. De visualisatie kan lijden, met gecomprimeerde of onoverzichtelijke beelden, verlies van detail in minder gewaardeerde variabelen en een onevenwichtige nadruk die interpretaties kan vertekenen.
Om deze nadelen te verminderen en een duidelijke visualisatie te hebben van de recente conflictintensiteit, hebben we de gegevens gefilterd voor conflictgebeurtenissen in 2023 en 2022 en hieronder is de output:
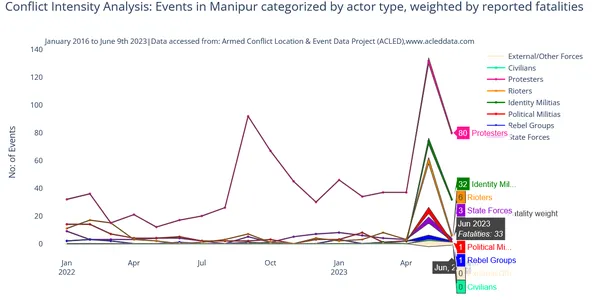
Stel datum in als index voor analyse van conflicttrends met behulp van de dagelijkse gegevens en verkrijg het onderstaande dataframe voor verdere analyse.
Voortschrijdende gemiddelden en analyse van conflicttrends
Bij conflicttrendanalyse zijn de voortschrijdende vensters van 30 dagen en 7 dagen gebruikelijk. Ze worden gebruikt om voortschrijdende gemiddelden of gemiddelden van conflictgerelateerde gegevens over een bepaalde periode te berekenen.
Het voortschrijdende venster verwijst naar een tijdsinterval van vaste grootte dat langs de tijdlijn beweegt, inclusief een opgegeven aantal gegevenspunten binnen dat interval. In een voortschrijdend venster van 30 dagen omvat het interval bijvoorbeeld de huidige dag plus de voorgaande 29 dagen. In een voortschrijdend venster van 7 dagen omvat het interval de huidige dag plus de voorgaande 6 dagen, wat neerkomt op een week aan gegevens.
Het voortschrijdend gemiddelde wordt berekend door het gemiddelde te nemen van de gegevenspunten binnen het venster. Het biedt een vloeiende weergave van de gegevens, waardoor fluctuaties op korte termijn worden verminderd en trends op langere termijn worden benadrukt.
Door de 30-daagse en 7-daagse voortschrijdende middelen in conflictanalyse te berekenen, kunnen analisten inzicht krijgen in de algemene patronen en trends in conflictgebeurtenissen in de loop van de tijd. Het kan langetermijntrends identificeren en tegelijkertijd kortetermijnfluctuaties in de gegevens vastleggen. Deze voortschrijdende gemiddelden kunnen helpen onderliggende patronen bloot te leggen en een duidelijker beeld te geven van de evolutie van conflictdynamiek.
code Snippets
Onderstaand codefragment maakt de plots voor elk conflictscenario.
import matplotlib.pyplot as plt import pandas as pd # Variables to calculate rolling means for variables = ['State Forces', 'Rebel Groups', 'Political Militias', 'Identity Militias', 'Rioters', 'Protesters', 'Civilians', 'External/Other Forces'] # Calculate rolling means for each variable data_7d_rol = {} data_30d_rol = {} for variable in variables: data_7d_rol[variable] = data_ts[variable].rolling(window=7, min_periods=1).mean() data_30d_rol[variable] = data_ts[variable].rolling(window=30, min_periods=1).mean() # Plotting separate graphs for each variable for variable in variables: fig, ax = plt.subplots(figsize=(11, 4)) # Plotting 7-day rolling mean ax.plot(data_ts.index, data_7d_rol[variable], linewidth=2, label='7-d Rolling Mean') # Plotting 30-day rolling mean ax.plot(data_ts.index, data_30d_rol[variable], color='0.2', linewidth=3, label='30-d Rolling Mean') # Beautification of plot ax.legend() ax.set_xlabel('Year') ax.set_ylabel('Events accounted by ' + variable) ax.set_title('Trends in ' + variable + ' Conflicts') # Add main heading and subheading fig.suptitle(main_title, fontsize=14, fontweight='bold', y=1.05) #ax.text(0.5, -0.25, sub_title, transform=ax.transAxes, fontsize=10, color='red', ha='center') ax.text(0.5, 0.95, sub_title, transform=ax.transAxes, fontsize=10, color='red', ha='center') plt.tight_layout() plt.show() Output:
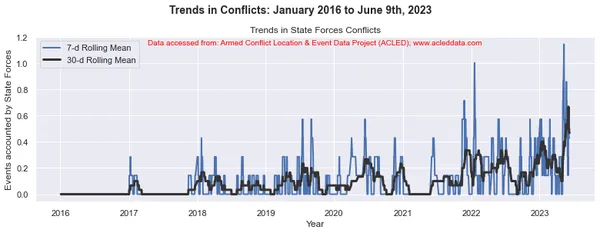
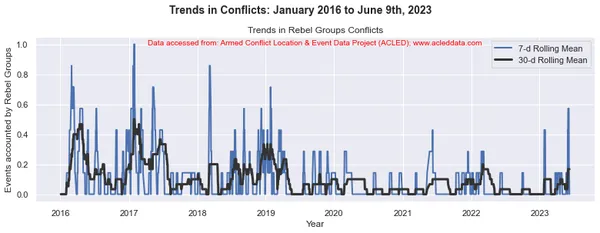
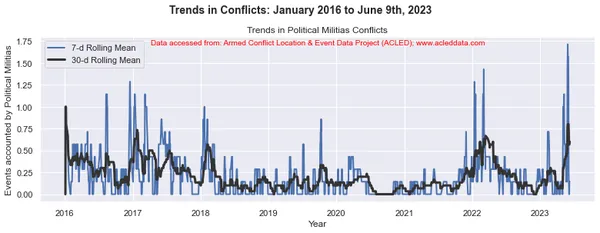
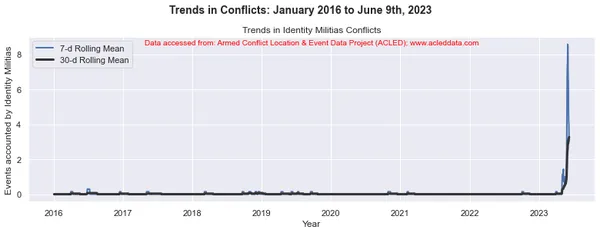

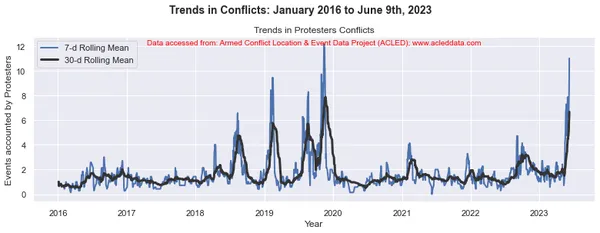
Note: De gegenereerde plots en data-analyse uitgevoerd in deze blog zijn uitsluitend bedoeld om de toepassing van data science-technieken te demonstreren. Deze analyses trekken geen definitieve conclusies of interpretaties met betrekking tot de complexe dynamiek van conflicten. Benader conflictanalyse met de nodige voorzichtigheid, rekening houdend met de veelzijdige aard van conflicten en de behoefte aan alomvattend en contextspecifiek begrip dat buiten het bestek van deze analyse valt.
Conclusie
De blog onderzoekt de gebeurtenissen en conflictpatronen in Manipur, India met behulp van de ACLED-gegevensanalyse. Gebruik interactieve kaarten en andere visualisaties om de ACLED-evenementen in Manipur te visualiseren. Analyse van de soorten evenementen in Manipur bracht verschillende activiteiten en incidenten aan het licht die verband hielden met conflicten, geweld, protesten en andere interessante evenementen. Om de trends in conflictgebeurtenissen te begrijpen, hebben we de 30-daagse en 7-daagse voortschrijdende gemiddelden berekend. Deze voortschrijdende gemiddelden zorgden voor een afgevlakte weergave van de gegevens, waardoor fluctuaties op korte termijn werden verminderd en trends op langere termijn werden benadrukt. Al met al kunnen deze bevindingen bijdragen aan een beter begrip van de conflictdynamiek in de regio en kunnen ze verder onderzoek en besluitvormingsprocessen ondersteunen.
Key Takeaways
- Interactieve ACLED-gegevensanalyse: Duik in echte conflictgegevens en krijg inzichten.
- Interactieve kaarten visualiseren de ruimtelijke en temporele dynamiek van conflicten.
- Benadrukt het belang van het visualiseren en analyseren van gegevens voor effectief begrip.
- Het identificeren van primaire actoren onthult de belangrijkste entiteiten die het conflictlandschap vormgeven.
- Rolling mean-berekeningen brengen kortetermijnfluctuaties en langetermijntrends in conflicten aan het licht.
Ik hoop dat je dit artikel informatief vond. Neem gerust contact met mij op LinkedIn. Laten we contact maken en werken aan het benutten van gegevens voor positieve verandering.
Veelgestelde Vragen / FAQ
A. De ACLED-dataset (Armed Conflict Location & Event Data Project) is een uitgebreide bron die gedetailleerde informatie over conflictgebeurtenissen wereldwijd bijhoudt en vastlegt, waaronder politiek geweld, protesten en rellen. Het draagt bij aan het analyseren van conflictgebeurtenissen door onderzoekers en beleidsmakers waardevolle inzichten te bieden in de patronen, dynamiek en betrokken actoren, wat helpt bij geïnformeerde besluitvorming en conflictgerelateerd onderzoek.
A. Interactieve kaarten en visualisaties maken de verkenning en analyse van ruimtelijke en temporele patronen van conflicten mogelijk door een visuele weergave van gegevens te bieden die de identificatie van trends, hotspots en correlaties mogelijk maakt, waardoor het begrip van conflictdynamiek wordt verbeterd.
A. Het is belangrijk om gebeurtenistypen zorgvuldig te visualiseren en te vergelijken, vooral wanneer één categorie de dataset domineert, om te voorkomen dat de relatieve verschillen worden overschaduwd en om de significantie en dynamiek van andere gebeurtenistypen nauwkeurig te beoordelen.
A. Identificatie en analyse van de belangrijkste actoren die bij conflicten betrokken zijn, geeft inzicht in de belangrijkste entiteiten en groepen die verantwoordelijk zijn voor het initiëren van of deelnemen aan de gebeurtenissen, wat helpt om de dynamiek, motivaties en mogelijke interacties tussen verschillende actoren te begrijpen.
A. Berekeningen met voortschrijdend gemiddelde bieden een vloeiende weergave van conflictincidenten door het gemiddelde te nemen van gegevenspunten over een specifiek tijdvenster, waardoor zowel kortetermijnfluctuaties als langetermijntrends in de gegevens kunnen worden geïdentificeerd.
Referenties
1. Raleigh, Clionadh, Andrew Linke, Håvard Hegre en Joakim Karlsen. (2010). "Introductie van ACLED-gewapende conflictlocatie- en gebeurtenisgegevens." Dagboek van Vredesonderzoek 47(5) 651-660.
2. ACLED. (2023). “Armed Conflict Location & Event Data Project (ACLED) Codeboek, 2023.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/06/exploring-conflict-trends-and-patterns-manipur-acled-data-analysis/

