Introductie
In het steeds evoluerende landschap van kunstmatige intelligentie zijn twee belangrijke spelers samengekomen om nieuwe wegen te bewandelen: Generatieve AI en Reinforcement Learning. Deze geavanceerde technologieën, Generative AI en Reinforcement Learning, hebben het potentieel om zelfverbeterende AI-systemen te creëren, waardoor we een stap dichter bij het verwezenlijken van de droom komen van machines die autonoom leren en zich aanpassen. Deze tools maken de weg vrij voor AI-systemen die zichzelf kunnen verbeteren, waardoor we dichter bij het idee komen van machines die zelfstandig kunnen leren en zich kunnen aanpassen.

AI heeft de afgelopen jaren opmerkelijke wonderen verricht, van het begrijpen van menselijke taal tot het helpen van computers om de wereld om hen heen te zien en te interpreteren. Generatieve AI-modellen zoals GPT-3 en Reinforcement Learning-algoritmen zoals Deep Q-Networks lopen voorop in deze vooruitgang. Hoewel deze technologieën individueel transformatief zijn geweest, opent hun convergentie nieuwe dimensies van AI-mogelijkheden en verlegt ze de grenzen van de wereld.
leerdoelen
- Verkrijg de vereiste en diepgaande kennis van Reinforcement Learning en zijn algoritmen, beloningsstructuren, het algemene raamwerk van Reinforcement Learning en staatsactiebeleid om te begrijpen hoe agenten beslissingen nemen.
- Onderzoek hoe deze twee takken symbiotisch kunnen worden gecombineerd om meer adaptieve, intelligente systemen te creëren, vooral in besluitvormingsscenario's.
- Bestudeer en analyseer verschillende casestudy's die de doeltreffendheid en het aanpassingsvermogen aantonen van de integratie van generatieve AI met Reinforcement Learning op gebieden als gezondheidszorg, autonome voertuigen en contentcreatie.
- Maak uzelf vertrouwd met Python-bibliotheken zoals TensorFlow, PyTorch, OpenAI's Gym en de TF-Agents van Google om praktische codeerervaring op te doen bij het implementeren van deze technologieën.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Generatieve AI: machines creativiteit geven
generatieve AI modellen, zoals OpenAI's GPT-3, zijn ontworpen om inhoud te genereren, of het nu gaat om natuurlijke taal, afbeeldingen of zelfs muziek. Deze modellen werken op basis van het principe van voorspellen wat er in een bepaalde context zal gebeuren. Ze zijn voor van alles gebruikt, van het automatisch genereren van inhoud tot chatbots die menselijke gesprekken kunnen nabootsen. Het kenmerk van generatieve AI is het vermogen om iets nieuws te creëren op basis van de patronen die het leert.
Versterkend leren: AI leren beslissingen te nemen
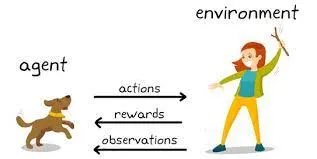
Versterking leren (RL) is een ander baanbrekend vakgebied. Het is de technologie die ervoor zorgt dat kunstmatige intelligentie met vallen en opstaan leert, net zoals een mens dat zou doen. Het wordt gebruikt om AI te leren complexe games zoals Dota 2 en Go te spelen. RL-agenten leren door beloningen of straffen te ontvangen voor hun acties en gebruiken deze feedback om in de loop van de tijd te verbeteren. In zekere zin geeft RL AI een vorm van autonomie, waardoor het beslissingen kan nemen in dynamische omgevingen.
Het raamwerk voor versterkend leren
In deze sectie zullen we het belangrijkste raamwerk van versterkend leren demystificeren:
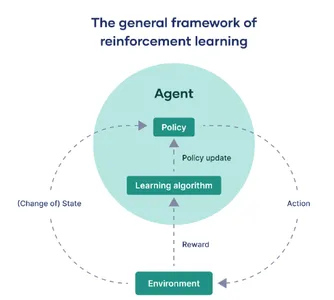
De waarnemende entiteit: de agent
Op het gebied van kunstmatige intelligentie en machinaal leren verwijst de term 'agent' naar het computermodel dat belast is met de interactie met een aangewezen externe omgeving. Zijn primaire rol is het nemen van beslissingen en het ondernemen van acties om ofwel een bepaald doel te bereiken, ofwel maximale beloningen te verzamelen over een reeks stappen.
De wereld rondom: het milieu
De ‘omgeving’ duidt de externe context of het systeem aan waarin de agent opereert. In wezen omvat het elke factor die buiten de controle van de agent ligt, maar toch waarneembaar is. Dit kan variëren van een virtuele game-interface tot een real-world setting, zoals een robot die door een doolhof navigeert. De omgeving is de 'grondwaarheid' waartegen de prestaties van de agent worden beoordeeld.
Navigeren door transities: statusveranderingen
In het jargon van versterkend leren beschrijft ‘staat’ of aangeduid met ‘s’ de verschillende scenario’s waarin de agent zich kan bevinden tijdens zijn interactie met de omgeving. Deze staatstransities zijn cruciaal; ze vormen de basis voor de observaties van de agent en hebben een grote invloed op zijn toekomstige besluitvormingsmechanismen.
Het beslissingsregelboek: beleid
De term 'beleid' vat de strategie van de agent samen voor het selecteren van acties die overeenkomen met verschillende toestanden. Het dient als een functie die het domein van staten in kaart brengt naar een reeks acties, en definieert de modus operandi van de agent in zijn zoektocht om zijn doelen te bereiken.
Verfijning in de loop van de tijd: beleidsupdates
“Beleidsupdate” verwijst naar het iteratieve proces van het aanpassen van het bestaande beleid van de agent. Dit is een dynamisch aspect van versterkend leren, waardoor de agent zijn gedrag kan optimaliseren op basis van historische beloningen of nieuw verworven ervaringen. Het wordt mogelijk gemaakt door gespecialiseerde algoritmen die de strategie van de agent opnieuw kalibreren.
De motor van aanpassing: leeralgoritmen
Leeralgoritmen bieden het wiskundige raamwerk dat de agent in staat stelt zijn beleid te verfijnen. Afhankelijk van de context kunnen deze algoritmen grofweg worden onderverdeeld in modelvrije methoden, die rechtstreeks leren van interacties in de echte wereld, en modelgebaseerde technieken die gebruik maken van een gesimuleerd model van de omgeving om te leren.
De maatstaf voor succes: beloningen
Ten slotte zijn ‘beloningen’ kwantificeerbare maatstaven, verstrekt door de omgeving, die de onmiddellijke effectiviteit van een door de agent uitgevoerde actie meten. Het overkoepelende doel van de agent is om de som van deze beloningen over een bepaalde periode te maximaliseren, wat feitelijk dient als prestatiemaatstaf.
In een notendop kan versterkend leren worden gedistilleerd in een continue interactie tussen de agent en zijn omgeving. De agent doorkruist verschillende staten, neemt beslissingen op basis van een specifiek beleid en ontvangt beloningen die als feedback fungeren. Er worden leeralgoritmen ingezet om dit beleid iteratief te verfijnen, zodat de agent altijd op weg is naar geoptimaliseerd gedrag binnen de beperkingen van zijn omgeving.
De synergie: generatieve AI ontmoet versterkend leren

De echte magie ontstaat wanneer generatieve AI en Reinforcement Learning elkaar ontmoeten. AI-onderzoekers hebben geëxperimenteerd en onderzoek gedaan met het combineren van deze twee domeinen, AI en Reinforcement Learning, om systemen of apparaten te creëren die niet alleen inhoud kunnen genereren, maar ook kunnen leren van gebruikersfeedback om hun output te verbeteren en betere AI-inhoud te krijgen.
- Initiële contentgeneratie: Generatieve AI genereert, net als GPT-3, inhoud op basis van een bepaalde input of context. Deze inhoud kan van alles zijn, van artikelen tot kunst.
- Gebruikersfeedbacklus: Zodra de inhoud is gegenereerd en aan de gebruiker is gepresenteerd, wordt alle gegeven feedback een waardevol bezit voor het verder trainen van het AI-systeem.
- Versterkend leermechanisme (RL): Met behulp van deze gebruikersfeedback komen Reinforcement Learning-algoritmen tussenbeide om te evalueren welke delen van de inhoud werden gewaardeerd en welke delen verfijning behoeven.
- Adaptieve inhoudgeneratie: Op basis van deze analyse past de Generatieve AI vervolgens zijn interne modellen aan om beter af te stemmen op de voorkeuren van de gebruiker. Het verfijnt iteratief de output, waarbij de lessen die uit elke interactie zijn geleerd, worden meegenomen.
- Fusie van technologieën: De combinatie van Genative AI en Reinforcement Learning creëert een dynamisch ecosysteem waarin gegenereerde inhoud dient als speeltuin voor de RL-agent. Gebruikersfeedback fungeert als beloningssignaal en geeft de AI aanwijzingen over hoe verbeteringen kunnen worden doorgevoerd.
Deze combinatie van generatieve AI en versterkend leren zorgt voor een zeer adaptief systeem dat ook kan leren van feedback uit de echte wereld, zoals menselijke feedback, waardoor meer op de gebruiker afgestemde en effectieve resultaten mogelijk worden en betere resultaten worden behaald die aansluiten bij de menselijke behoeften.
Synergie van codefragmenten
Laten we de synergie tussen generatieve AI en versterkend leren begrijpen:
import torch
import torch.nn as nn
import torch.optim as optim # Simulated Generative AI model (e.g., a text generator)
class GenerativeAI(nn.Module): def __init__(self): super(GenerativeAI, self).__init__() # Model layers self.fc = nn.Linear(10, 1) # Example layer def forward(self, input): output = self.fc(input) # Generate content, for this example, a number return output # Simulated User Feedback
def user_feedback(content): return torch.rand(1) # Mock user feedback # Reinforcement Learning Update
def rl_update(model, optimizer, reward): loss = -torch.log(reward) optimizer.zero_grad() loss.backward() optimizer.step() # Initialize model and optimizer
gen_model = GenerativeAI()
optimizer = optim.Adam(gen_model.parameters(), lr=0.001) # Iterative improvement
for epoch in range(100): content = gen_model(torch.randn(1, 10)) # Mock input reward = user_feedback(content) rl_update(gen_model, optimizer, reward)
Code uitleg
- Generatief AI-model: Het is als een machine die inhoud probeert te genereren, zoals een tekstgenerator. In dit geval is het ontworpen om wat invoer te nemen en een uitvoer te produceren.
- Gebruikersfeedback: Stel je voor dat gebruikers feedback geven op de inhoud die de AI genereert. Deze feedback helpt de AI te leren wat goed of slecht is. In deze code gebruiken we willekeurige feedback als voorbeeld.
- Versterkende leerupdate: Nadat u feedback heeft gekregen, werkt de AI zichzelf bij om beter te worden. Het past de interne instellingen aan om het genereren van inhoud te verbeteren.
- Iteratieve verbetering: De AI doorloopt vele cycli (100 keer in deze code) van het genereren van inhoud, het krijgen van feedback en het leren ervan. Na verloop van tijd wordt het beter in het creëren van de gewenste inhoud.
Deze code definieert een basismodel voor generatieve AI en een feedbacklus. De AI genereert inhoud, ontvangt willekeurige feedback en past zichzelf in meer dan 100 iteraties aan om de mogelijkheden voor het maken van inhoud te verbeteren.
In een echte toepassing zou je een geavanceerder model en meer genuanceerde gebruikersfeedback gebruiken. Dit codefragment geeft echter de essentie weer van hoe Generative AI en Reinforcement Learning kunnen harmoniseren om een systeem te bouwen dat niet alleen inhoud genereert, maar ook leert deze te verbeteren op basis van feedback.
Toepassingen in de echte wereld
De mogelijkheden die voortkomen uit de synergie van generatieve AI en Reinforcement Learning zijn eindeloos. Laten we eens kijken naar de toepassingen in de echte wereld:
Inhoud genereren
Door AI gecreëerde inhoud kan steeds persoonlijker worden en aansluiten bij de smaak en voorkeuren van individuele gebruikers.
Overweeg een scenario waarin een RL-agent GPT-3 gebruikt om een gepersonaliseerde nieuwsfeed te genereren. Na elk gelezen artikel geeft de gebruiker feedback. Laten we ons hier eens voorstellen dat feedback eenvoudigweg 'leuk' of 'niet leuk' is, die worden omgezet in numerieke beloningen.
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch # Initialize GPT-2 model and tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2') # RL update function
def update_model(reward, optimizer): loss = -torch.log(reward) optimizer.zero_grad() loss.backward() optimizer.step() # Initialize optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # Example RL loop
for epoch in range(10): input_text = "Generate news article about technology." input_ids = tokenizer.encode(input_text, return_tensors='pt') with torch.no_grad(): output = model.generate(input_ids) article = tokenizer.decode(output[0]) print(f"Generated Article: {article}") # Get user feedback (1 for like, 0 for dislike) reward = float(input("Did you like the article? (1 for yes, 0 for no): ")) update_model(torch.tensor(reward), optimizer)Kunst en muziek
AI kan kunst en muziek genereren die resoneert met menselijke emoties, en de stijl ervan evolueren op basis van feedback van het publiek. Een RL-agent zou de parameters van een algoritme voor neurale stijloverdracht kunnen optimaliseren op basis van feedback om kunst of muziek te creëren die beter resoneert met menselijke emoties.
# Assuming a function style_transfer(image, style) exists
# RL update function similar to previous example # Loop through style transfers
for epoch in range(10): new_art = style_transfer(content_image, style_image) show_image(new_art) reward = float(input("Did you like the art? (1 for yes, 0 for no): ")) update_model(torch.tensor(reward), optimizer)Conversationele AI
chatbots en virtuele assistenten kunnen meer natuurlijke en contextbewuste gesprekken voeren, waardoor ze ongelooflijk nuttig zijn bij de klantenservice. Chatbots kunnen versterkend leren gebruiken om hun gespreksmodellen te optimaliseren op basis van de gespreksgeschiedenis en gebruikersfeedback.
# Assuming a function chatbot_response(text, model) exists
# RL update function similar to previous examples for epoch in range(10): user_input = input("You: ") bot_response = chatbot_response(user_input, model) print(f"Bot: {bot_response}") reward = float(input("Was the response helpful? (1 for yes, 0 for no): ")) update_model(torch.tensor(reward), optimizer)Autonome voertuigen
AI-systemen in autonome voertuigen kunnen leren van rijervaringen uit de praktijk, waardoor de veiligheid en efficiëntie worden verbeterd. Een RL-agent in een autonoom voertuig kan zijn traject in realtime aanpassen op basis van verschillende beloningen, zoals brandstofefficiëntie, tijd of veiligheid.
# Assuming a function drive_car(state, policy) exists
# RL update function similar to previous examples for epoch in range(10): state = get_current_state() # e.g., traffic, fuel, etc. action = drive_car(state, policy) reward = get_reward(state, action) # e.g., fuel saved, time taken, etc. update_model(torch.tensor(reward), optimizer)Deze codefragmenten zijn illustratief en vereenvoudigd. Ze helpen het concept te manifesteren dat generatieve AI en RL kunnen samenwerken om de gebruikerservaring in verschillende domeinen te verbeteren. Elk fragment laat zien hoe de agent zijn beleid iteratief verbetert op basis van de ontvangen beloningen, vergelijkbaar met hoe men iteratief een deep learning-model zoals Unet voor radarbeeldsegmentatie zou kunnen verbeteren.
Casestudies
Gezondheidszorgdiagnose en behandelingsoptimalisatie
- probleem: In de gezondheidszorg is een nauwkeurige en tijdige diagnose cruciaal. Het is voor artsen vaak een uitdaging om grote hoeveelheden medische literatuur en de zich ontwikkelende best practices bij te houden.
- Oplossing: Generatieve AI-modellen zoals BERT kunnen inzichten uit medische teksten halen. Een RL-agent kan behandelplannen optimaliseren op basis van historische patiëntgegevens en opkomend onderzoek.
- Casestudies: IBM's Watson for Oncology gebruikt generatieve AI en RL om oncologen te helpen bij het nemen van behandelbeslissingen door de medische dossiers van een patiënt te analyseren aan de hand van de enorme medische literatuur. Dit heeft de nauwkeurigheid van de behandelaanbevelingen verbeterd.
Detailhandel en gepersonaliseerd winkelen
- probleem: In e-commerce is het personaliseren van winkelervaringen voor klanten essentieel voor het verhogen van de omzet.
- Oplossing: Generatieve AI kan, net als GPT-3, productbeschrijvingen, recensies en aanbevelingen genereren. Een RL-agent kan deze aanbevelingen optimaliseren op basis van gebruikersinteracties en feedback.
- Casestudies: Amazon gebruikt generatieve AI voor het genereren van productbeschrijvingen en gebruikt RL om productaanbevelingen te optimaliseren. Dit heeft geleid tot een aanzienlijke stijging van de omzet en de klanttevredenheid.
Contentcreatie en marketing
- probleem: Marketeers moeten op grote schaal boeiende inhoud creëren. Het is een uitdaging om te weten wat resoneert met het publiek.
- Oplossing: Generatieve AI, zoals GPT-2, kan blogposts, sociale media-inhoud en advertentieteksten genereren. RL kan het genereren van inhoud optimaliseren op basis van betrokkenheidsstatistieken.
- Casestudies: HubSpot, een marketingplatform, gebruikt generatieve AI om te helpen bij het creëren van inhoud. Ze gebruiken RL om contentstrategieën te verfijnen op basis van gebruikersbetrokkenheid, wat resulteert in effectievere marketingcampagnes.
Ontwikkeling van videogames
- probleem: Het creëren van niet-spelerpersonages (NPC's) met realistisch gedrag en spelomgevingen die zich aanpassen aan de acties van spelers is complex en tijdrovend.
- Oplossing: Genatieve AI kan spelniveaus, personages en dialogen ontwerpen. RL-agenten kunnen het NPC-gedrag optimaliseren op basis van spelersinteracties.
- Casestudies: In de game-industrie gebruiken studio's als Ubisoft Generative AI voor het bouwen van werelden en RL voor NPC AI. Deze aanpak heeft geresulteerd in meer dynamische en boeiende gameplay-ervaringen.
Financiële handel
- probleem: In de zeer competitieve wereld van de financiële handel kan het vinden van winstgevende strategieën een uitdaging zijn.
- Oplossing: Generatieve AI kan helpen bij data-analyse en het genereren van strategieën. RL-agenten kunnen handelsstrategieën leren en optimaliseren op basis van marktgegevens en door de gebruiker gedefinieerde doelen.
- Casestudies: Hedgefondsen zoals Renaissance Technologies maken gebruik van generatieve AI en RL om winstgevende handelsalgoritmen te ontdekken. Dit heeft geleid tot substantiële rendementen op beleggingen.
Deze casestudies laten zien hoe de combinatie van generatieve AI en Reinforcement Learning verschillende industrieën transformeert door taken te automatiseren, ervaringen te personaliseren en besluitvormingsprocessen te optimaliseren.
Ethische overwegingen
Eerlijkheid in AI
Het waarborgen van eerlijkheid in AI-systemen is van cruciaal belang om vooroordelen of discriminatie te voorkomen. AI-modellen moeten worden getraind op diverse en representatieve datasets. Het opsporen en beperken van vooroordelen in AI-modellen is een voortdurende uitdaging. Dit is vooral belangrijk op domeinen zoals het verstrekken van leningen of het aannemen van personeel, waar bevooroordeelde algoritmen ernstige gevolgen in de echte wereld kunnen hebben.
Verantwoordelijkheid en verantwoordelijkheid
Naarmate AI-systemen zich blijven ontwikkelen, worden verantwoordelijkheid en verantwoordelijkheid centraal. Ontwikkelaars, organisaties en toezichthouders moeten duidelijke verantwoordelijkheidslijnen definiëren. Er moeten ethische richtlijnen en standaarden worden opgesteld om individuen en organisaties verantwoordelijk te houden voor de beslissingen en acties van AI-systemen. In de gezondheidszorg is verantwoordelijkheid bijvoorbeeld van cruciaal belang om de patiëntveiligheid en het vertrouwen in door AI ondersteunde diagnoses te garanderen.
Transparantie en uitlegbaarheid
Het ‘black box’-karakter van sommige AI-modellen is een punt van zorg. Om ethische en verantwoorde AI te garanderen, is het van cruciaal belang dat AI-besluitvormingsprocessen transparant en begrijpelijk zijn. Onderzoekers en ingenieurs moeten werken aan de ontwikkeling van AI-modellen die verklaarbaar zijn en inzicht geven in waarom een bepaalde beslissing is genomen. Dit is van cruciaal belang voor gebieden als het strafrecht, waar beslissingen van AI-systemen een aanzienlijke impact kunnen hebben op de levens van individuen.
Gegevensprivacy en toestemming
Het respecteren van gegevensprivacy is een hoeksteen van ethische AI. AI-systemen zijn vaak afhankelijk van gebruikersgegevens en het verkrijgen van geïnformeerde toestemming voor gegevensgebruik is van het grootste belang. Gebruikers moeten controle hebben over hun gegevens en er moeten mechanismen zijn om gevoelige informatie te beschermen. Dit probleem is vooral belangrijk bij AI-gestuurde personalisatiesystemen, zoals aanbevelingsengines en virtuele assistenten.
Schadebeperking
AI-systemen moeten worden ontworpen om het creëren van schadelijke, misleidende of valse informatie te voorkomen. Dit is vooral relevant op het gebied van het genereren van inhoud. Algoritmen mogen geen inhoud genereren die haatzaaiende uitlatingen, desinformatie of schadelijk gedrag bevordert. Strengere richtlijnen en monitoring zijn essentieel op platforms waar door gebruikers gegenereerde inhoud de overhand heeft.
Menselijk toezicht en ethische expertise
Menselijk toezicht blijft cruciaal. Zelfs nu AI autonomer wordt, moeten menselijke experts op verschillende gebieden samenwerken met AI. Ze kunnen ethische oordelen vellen, AI-systemen verfijnen en ingrijpen wanneer dat nodig is. In autonome voertuigen moet een menselijke veiligheidschauffeur bijvoorbeeld klaar zijn om de controle over te nemen in complexe of onvoorziene situaties.
Deze ethische overwegingen staan voorop bij de ontwikkeling en inzet van AI en zorgen ervoor dat AI-technologieën de samenleving ten goede komen, terwijl de principes van eerlijkheid, verantwoordelijkheid en transparantie worden gehandhaafd. Het aanpakken van deze problemen is van cruciaal belang voor de verantwoorde en ethische integratie van AI in ons leven.
Conclusie
We zijn getuige van een spannend tijdperk waarin generatieve AI en versterkend leren zich beginnen te verenigen. Deze convergentie baant de weg naar zelfverbeterende AI-systemen, die in staat zijn tot zowel innovatieve creatie als effectieve besluitvorming. Met grote macht komt echter ook een grote verantwoordelijkheid. De snelle vooruitgang op het gebied van AI brengt ethische overwegingen met zich mee die cruciaal zijn voor een verantwoorde inzet ervan. Terwijl we aan deze reis beginnen om AI te creëren die niet alleen begrijpt, maar ook leert en zich aanpast, openen we grenzeloze mogelijkheden voor innovatie. Niettemin is het van cruciaal belang om vooruitgang te boeken met ethische integriteit en ervoor te zorgen dat de technologie die we creëren als een kracht ten goede dient en de mensheid als geheel ten goede komt.
Key Takeaways
- Generatieve AI en Reinforcement Learning (RL) komen samen om zelfverbeterende systemen te creëren, waarbij de eerste zich richt op het genereren van inhoud en de laatste op het nemen van beslissingen met vallen en opstaan.
- In RL omvatten de belangrijkste componenten de agent, die beslissingen neemt; de omgeving waarmee de agent interageert; en beloningen, die dienen als prestatiemaatstaven. Beleid en leeralgoritmen zorgen ervoor dat de agent in de loop van de tijd kan verbeteren.
- De combinatie van generatieve AI en RL maakt systemen mogelijk die inhoud genereren en zich aanpassen op basis van gebruikersfeedback, waardoor hun output iteratief wordt verbeterd.
- Een Python-codefragment illustreert deze synergie door een gesimuleerd generatief AI-model voor het genereren van inhoud te combineren met RL om te optimaliseren op basis van gebruikersfeedback.
- Toepassingen in de echte wereld zijn enorm, waaronder het genereren van gepersonaliseerde inhoud, het maken van kunst en muziek, conversatie-AI en zelfs autonome voertuigen.
- Deze gecombineerde technologieën kunnen een revolutie teweegbrengen in de manier waarop AI interageert met en zich aanpast aan menselijke behoeften en voorkeuren, wat kan leiden tot meer gepersonaliseerde en effectieve oplossingen.
Veelgestelde Vragen / FAQ
A. Door generatieve AI en Reinforcement Learning te combineren ontstaan intelligente systemen die niet alleen nieuwe data genereren, maar ook de effectiviteit ervan optimaliseren. Deze synergetische relatie vergroot de reikwijdte en efficiëntie van AI-toepassingen, waardoor ze veelzijdiger en adaptiever worden.
A. Versterkend leren fungeert als de besluitvormingskern van het systeem. Door gebruik te maken van een feedbacklus rond beloningen, evalueert en past het de gegenereerde inhoud van de Generatieve AI-module aan. Dit iteratieve proces optimaliseert de strategie voor het genereren van gegevens in de loop van de tijd.
A. Praktische toepassingen zijn breed van opzet. In de gezondheidszorg kan deze technologie op dynamische wijze behandelplannen creëren en verfijnen met behulp van realtime patiëntgegevens. Ondertussen zou het in de automobielsector zelfrijdende auto's in staat kunnen stellen hun route in realtime aan te passen als reactie op fluctuerende wegomstandigheden.
A. Python blijft de go-to-taal vanwege het uitgebreide ecosysteem. Bibliotheken zoals TensorFlow en PyTorch worden vaak gebruikt voor generatieve AI-taken, terwijl OpenAI's Gym en Google's TF-Agents typische keuzes zijn voor Reinforcement Learning-implementaties.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/10/generative-ai-and-reinforcement-learning/

