Introductie
In het verleden heeft generatieve AI de markt veroverd en als gevolg daarvan hebben we nu verschillende modellen met verschillende toepassingen. De evaluatie van Gen AI begon met de Transformer-architectuur en deze strategie is sindsdien op andere gebieden overgenomen. Laten we een voorbeeld nemen. Zoals we weten gebruiken we momenteel het VIT-model op het gebied van stabiele diffusie. Wanneer je het model verder onderzoekt, zul je zien dat er twee soorten diensten beschikbaar zijn: betaalde diensten en open source-modellen die gratis te gebruiken zijn. De gebruiker die toegang wil tot de extra diensten kan gebruik maken van betaalde diensten als OpenAI, en voor het open source-model hebben we een Hugging Face.
U heeft toegang tot het model en kunt, afhankelijk van uw taak, het betreffende model downloaden van de services. Houd er ook rekening mee dat er kosten in rekening kunnen worden gebracht voor tokenmodellen, afhankelijk van de betreffende service in de betaalde versie. Op dezelfde manier levert AWS ook diensten zoals AWS Bedrock, dat via API toegang tot LLM-modellen mogelijk maakt. Laten we aan het einde van deze blogpost de prijzen voor services bespreken.
leerdoelen
- Inzicht in generatieve AI met stabiele diffusie, LLaMA 2 en Claude-modellen.
- Ontdek de kenmerken en mogelijkheden van de Stable Diffusion-, LLaMA 2- en Claude-modellen van AWS Bedrock.
- Een onderzoek naar AWS Bedrock en de prijzen ervan.
- Leer hoe u deze modellen kunt gebruiken voor verschillende taken, zoals het genereren van afbeeldingen, tekstsynthese en het genereren van code.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Wat is generatieve AI?
Generatieve AI is een subset van kunstmatige intelligentie (AI) die is ontwikkeld om nieuwe inhoud te creëren op basis van gebruikersverzoeken, zoals afbeeldingen, tekst of code. Deze modellen zijn goed getraind op grote hoeveelheden data, waardoor de productie van content of het reageren op gebruikersverzoeken veel nauwkeuriger en qua tijd minder complex is. Generatieve AI heeft veel toepassingen in verschillende domeinen, zoals creatieve kunsten, het genereren van inhoud, data-vergroting en probleemoplossing.
U kunt verwijzen naar enkele van mijn blogs die zijn gemaakt met LLM-modellen, zoals chatbot (Gemini Pro) en Geautomatiseerde afstemming van LLaMA 2-modellen op Gradient AI Cloud. Ik heb ook het knuffelgezicht gemaakt BLOEIEN model van Meta om de chatbot te ontwikkelen.
Belangrijkste kenmerken van GenAI
- Content creatie: LLM-modellen kunnen nieuwe inhoud genereren door de zoekopdrachten te gebruiken die door de gebruiker als invoer worden verstrekt om tekst, afbeeldingen of code te genereren.
- Scherpstellen: We kunnen het model eenvoudig verfijnen, wat betekent dat we het model op verschillende parameters kunnen trainen om de prestaties van LLM-modellen te verbeteren en hun kracht te verbeteren.
- Datagedreven leren: Generatieve AI-modellen worden getraind op grote datasets met verschillende parameters, waardoor ze patronen uit gegevens en trends in de gegevens kunnen leren om nauwkeurige en betekenisvolle resultaten te genereren.
- Efficiënt: Generatieve AI-modellen zorgen voor nauwkeurige resultaten; op deze manier besparen ze tijd en middelen in vergelijking met handmatige creatiemethoden.
- Veelzijdigheid: Deze modellen zijn op alle terreinen bruikbaar. Generatieve AI heeft toepassingen in verschillende domeinen, waaronder creatieve kunsten, het genereren van inhoud, gegevensvergroting en probleemoplossing.
Wat is AWS Bedrock?
AWS Bedrock is een platform dat wordt aangeboden door Amazon Web Services (AWS). AWS biedt een verscheidenheid aan diensten, daarom hebben ze onlangs de Generative AI-service Bedrock toegevoegd, die een verscheidenheid aan grote taalmodellen (LLM's) heeft toegevoegd. Deze modellen zijn gebouwd voor specifieke taken in verschillende domeinen. We hebben verschillende modellen zoals het tekstgeneratiemodel en het afbeeldingsmodel die door datawetenschappers naadloos kunnen worden geïntegreerd in software zoals VSCode. We kunnen LLM's gebruiken om te trainen en in te zetten voor verschillende NLP-taken, zoals het genereren van tekst, samenvattingen, vertalingen en meer.
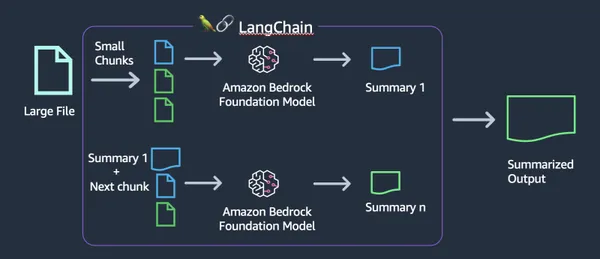
Belangrijkste kenmerken van AWS Bedrock
- Toegang tot vooraf getrainde modellen: AWS Bedrock biedt veel vooraf getrainde LLM-modellen die gebruikers gemakkelijk kunnen gebruiken zonder dat ze helemaal opnieuw modellen hoeven te maken of te trainen.
- Scherpstellen: Gebruikers kunnen vooraf getrainde modellen verfijnen met behulp van hun eigen datasets om ze aan te passen aan specifieke gebruiksscenario's en domeinen.
- Schaalbaarheid: AWS Bedrock is gebouwd op de AWS-infrastructuur en biedt schaalbaarheid voor het verwerken van grote datasets en rekenintensieve AI-workloads.
- Uitgebreide API: Bedrock biedt een uitgebreide API waarmee we eenvoudig met het model kunnen communiceren.
Hoe AWS-basis te bouwen?
Het opzetten van AWS Bedrock is eenvoudig maar krachtig. Dit framework, gebaseerd op Amazon Web Services (AWS), biedt een betrouwbare basis voor uw applicaties. Laten we de eenvoudige stappen doornemen om aan de slag te gaan.
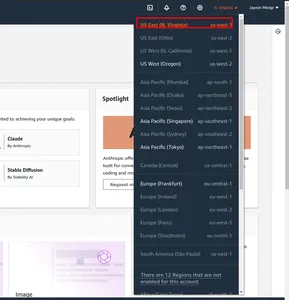
Stap 1: Navigeer eerst naar de AWS Management Console. En verander de regio. Ik heb in het rode vakje us-east-1 gemarkeerd.
Stap 2: Zoek vervolgens naar “Bedrock” in de AWS Management Console en klik erop. Klik vervolgens op de knop "Aan de slag". Hiermee gaat u naar het Bedrock-dashboard, waar u toegang heeft tot de gebruikersinterface.
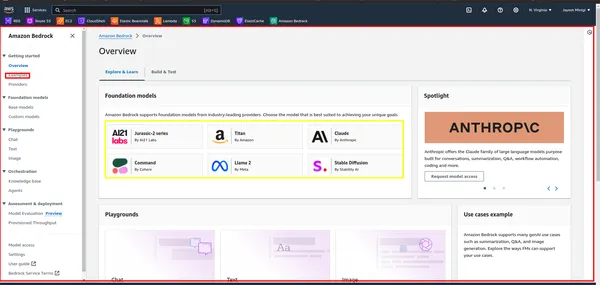
Stap 3: Binnen het dashboard ziet u een gele rechthoek met daarin verschillende funderingsmodellen, zoals LLaMA 2, Claude, enz. Klik op de rode rechthoek om voorbeelden en demonstraties van deze modellen te bekijken.
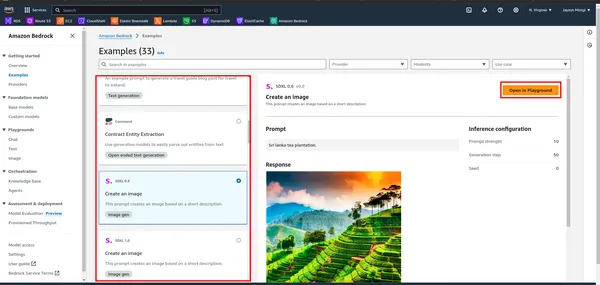
Stap 4: Als u op het voorbeeld klikt, wordt u naar een pagina geleid waar u een rode rechthoek vindt. Klik op een van deze opties voor speeltuindoeleinden.
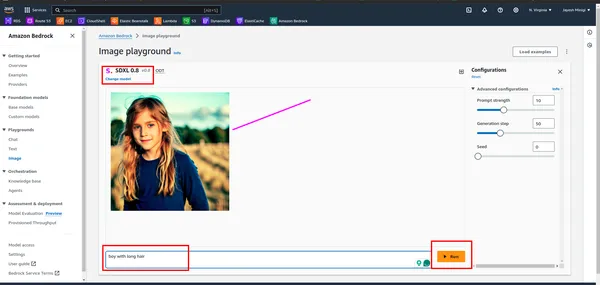
Wat is stabiele diffusie?
Stabiele diffusie is een GenAI-model dat afbeeldingen genereert op basis van gebruikersinvoer (tekst). Gebruikers geven tekstprompts en Stable Diffusion produceert overeenkomstige afbeeldingen, zoals gedemonstreerd in het praktische gedeelte. Het werd gelanceerd in 2022 en maakt gebruik van diffusietechnologie en latente ruimte om beelden van hoge kwaliteit te creëren.
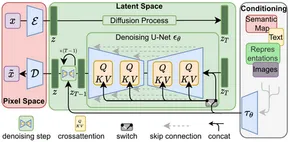
Na de introductie van de transformatorarchitectuur in natuurlijke taalverwerking (NLP) werd aanzienlijke vooruitgang geboekt. In computer vision werden modellen zoals de Vision Transformer (ViT) gangbaar. Terwijl traditionele architecturen zoals het encoder-decoder-model gebruikelijk waren, gebruikt Stable Diffusion een encoder-decoder-architectuur die gebruik maakt van U-Net. Deze architectonische keuze draagt bij aan de effectiviteit ervan bij het genereren van hoogwaardige beelden.
Stabiele diffusie werkt door geleidelijk Gaussiaanse ruis aan een beeld toe te voegen totdat er alleen willekeurige ruis overblijft: een proces dat bekend staat als voorwaartse diffusie. Vervolgens wordt deze ruis omgekeerd om het originele beeld opnieuw te creëren met behulp van een ruisvoorspeller.
Over het geheel genomen vertegenwoordigt Stable Diffusion een opmerkelijke vooruitgang in generatieve AI, die efficiënte en hoogwaardige mogelijkheden voor het genereren van afbeeldingen biedt.
Belangrijkste kenmerken van stabiele diffusie
- Afbeelding genereren: Stabiele diffusie gebruikt het VIT-model om afbeeldingen van de gebruiker (tekst) als invoer te creëren.
- Veelzijdigheid: Dit model is veelzijdig, dus we kunnen dit model op hun respectievelijke velden gebruiken. We kunnen afbeeldingen, GiF, video's en animaties maken.
- Efficiënt: Stabiele diffusiemodellen maken gebruik van latente ruimte, waardoor minder verwerkingskracht nodig is in vergelijking met andere modellen voor het genereren van afbeeldingen.
- Fine-tuning-mogelijkheden: Gebruikers kunnen Stabiele Diffusie afstemmen op hun specifieke behoeften. Door parameters zoals ruisonderdrukkingsstappen en geluidsniveaus aan te passen, kunnen gebruikers de uitvoer aanpassen aan hun voorkeuren.
Enkele afbeeldingen die zijn gemaakt met behulp van het stabiele diffusiemodel


Hoe stabiele diffusie opbouwen?
Om Stabiele Diffusie te bouwen, moet u verschillende stappen volgen, waaronder het opzetten van uw ontwikkelomgeving, toegang krijgen tot het model en het aanroepen met de juiste parameters.
Stap 1. Voorbereiding van de omgeving
- Creatie van virtuele omgevingen: Creëer een virtuele omgeving met venv
conda create -p ./venv python=3.10 -y
- Activering van virtuele omgeving: Activeer de virtuele omgeving
conda activate ./venvStap 2. Vereistenpakketten installeren
!pip install boto3
!pip install awscliStap 3: De AWS CLI instellen
- Eerst moet u een gebruiker aanmaken in IAM en deze de benodigde rechten verlenen, zoals beheerderstoegang.
- Volg daarna de onderstaande opdrachten om de AWS CLI zo in te stellen dat u eenvoudig toegang krijgt tot het model.
- Configureer AWS-referenties: Na de installatie moet u uw AWS-inloggegevens configureren. Open een terminal- of opdrachtprompt en voer de volgende opdracht uit:
aws configure- Nadat u de bovenstaande opdracht hebt uitgevoerd, ziet u een gebruikersinterface die er ongeveer zo uitziet.
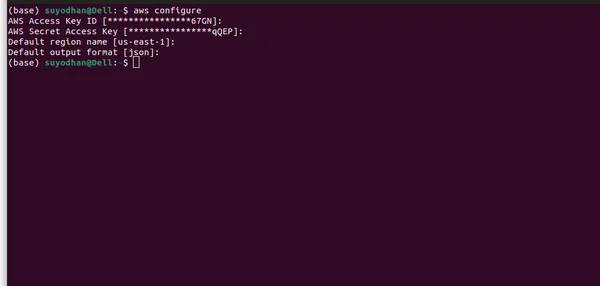
- Zorg ervoor dat u alle benodigde informatie verstrekt en de juiste regio selecteert, aangezien het LLM-model mogelijk niet in alle regio's beschikbaar is. Daarnaast heb ik de regio gespecificeerd waar het LLM-model beschikbaar is op AWS Bedrock.
Stap 4: De benodigde bibliotheken importeren
- Importeer de benodigde pakketten.
import boto3
import json
import base64
import os
- Boto3 is een Python-bibliotheek die een eenvoudig te gebruiken interface biedt voor programmatische interactie met Amazon Web Services (AWS)-bronnen.
Stap 5: Maak een AWS Bedrock-client
bedrock = boto3.client(service_name="bedrock-runtime")
Stap 6: Definieer de payloadparameters
- Bekijk eerst de API in AWS Bedrock.
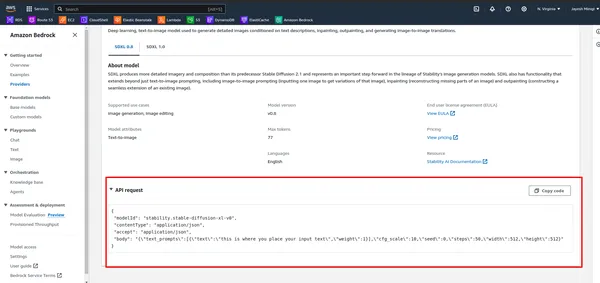
- Voer de onderstaande cel uit.
# DEFINE THE USER QUERY
USER_QUERY="provide me an 4k hd image of a beach, also use a blue sky rainy season and
cinematic display"
payload_params = {
"text_prompts": [{"text": USER_QUERY, "weight": 1}],
"cfg_scale": 10,
"seed": 0,
"steps": 50,
"width": 512,
"height": 512
}
Stap 7: Definieer het payload-object
model_id = "stability.stable-diffusion-xl-v0"
response = bedrock.invoke_model(
body= json.dumps(payload_params),
modelId=model_id,
accept="application/json",
contentType="application/json",
)
Stap 8: Stuur een verzoek naar de AWS Bedrock API en ontvang de antwoordtekst
response_body = json.loads(response.get("body").read())

Stap 9: Extraheer afbeeldingsgegevens uit het antwoord
artifact = response_body.get("artifacts")[0]
image_encoded = artifact.get("base64").encode("utf-8")
image_bytes = base64.b64decode(image_encoded)
Stap 10: Sla de afbeelding op in een bestand
output_dir = "output"
os.makedirs(output_dir, exist_ok=True)
file_name = f"{output_dir}/generated-img.png"
with open(file_name, "wb") as f:
f.write(image_bytes)

Stap 11: Maak een Streamlit-app
- Installeer eerst de Streamlit. Open daarvoor de terminal en ga er voorbij.
pip install streamlit
- Maak een Python-script voor de Streamlit-app
import streamlit as st
import boto3
import json
import base64
import os
def generate_image(prompt_text):
prompt_template = [{"text": prompt_text, "weight": 1}]
bedrock = boto3.client(service_name="bedrock-runtime")
payload = {
"text_prompts": prompt_template,
"cfg_scale": 10,
"seed": 0,
"steps": 50,
"width": 512,
"height": 512
}
body = json.dumps(payload)
model_id = "stability.stable-diffusion-xl-v0"
response = bedrock.invoke_model(
body=body,
modelId=model_id,
accept="application/json",
contentType="application/json",
)
response_body = json.loads(response.get("body").read())
artifact = response_body.get("artifacts")[0]
image_encoded = artifact.get("base64").encode("utf-8")
image_bytes = base64.b64decode(image_encoded)
# Save image to a file in the output directory.
output_dir = "output"
os.makedirs(output_dir, exist_ok=True)
file_name = f"{output_dir}/generated-img.png"
with open(file_name, "wb") as f:
f.write(image_bytes)
return file_name
def main():
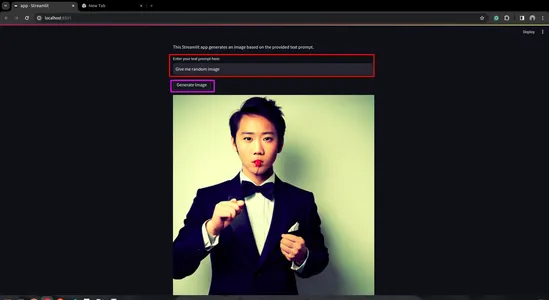
st.title("Generated Image")
st.write("This Streamlit app generates an image based on the provided text prompt.")
# Text input field for user prompt
prompt_text = st.text_input("Enter your text prompt here:")
if st.button("Generate Image") and prompt_text:
image_file = generate_image(prompt_text)
st.image(image_file, caption="Generated Image", use_column_width=True)
elif st.button("Generate Image") and not prompt_text:
st.error("Please enter a text prompt.")
if __name__ == "__main__":
main()
- Voer de Streamlit-app uit
streamlit run app.py
Wat is LLaMA 2?
LLaMA 2, of het Large Language Model of Many Applications, behoort tot de categorie Large Language Models (LLM). Facebook (Meta) heeft dit model ontwikkeld om een breed spectrum van toepassingen voor natuurlijke taalverwerking (NLP) te verkennen. In de eerdere series was het 'LAMA'-model het startgezicht van de ontwikkeling, maar er werd gebruik gemaakt van verouderde methoden.
Belangrijkste kenmerken van LLaMA 2
- Veelzijdigheid: LLaMA 2 is een krachtig model dat diverse taken met hoge nauwkeurigheid en efficiëntie kan uitvoeren
- Contextueel begrip: Bij het leren van reeks tot reeks onderzoeken we fonemen, morfemen, lexemen, syntaxis en context. LLaMA 2 maakt een beter begrip van contextuele nuances mogelijk.
- Transfer leren: LLaMA 2 is een robuust model, dat profiteert van uitgebreide training op een grote dataset. Transferleren vergemakkelijkt het snelle aanpassingsvermogen aan specifieke taken.
- Open-Source: Bij Data Science is de gemeenschap een belangrijk aspect. Open-sourcemodellen maken het voor onderzoekers, ontwikkelaars en gemeenschappen mogelijk om deze te verkennen, aan te passen en te integreren in hun projecten.
Cases
- LLaMA 2 kan daarbij helpen het creëren van tekstgeneratie taken, zoals verhalen schrijven, inhoud creëren, Etc.
- Wij kennen het belang van zero-shot learning. We kunnen dus LLaMA 2 gebruiken voor het beantwoorden van vragen taken, vergelijkbaar met ChatGPT. Het biedt relevante en nauwkeurige antwoorden.
- Voor taalvertalingen hebben we API's op de markt, maar we moeten ons abonneren. Maar LLaMA 2 biedt gratis taalvertaling, waardoor het gemakkelijk te gebruiken is.
- LLaMA 2 is gemakkelijk te gebruiken en een uitstekende keuze om te ontwikkelen chatbots.
Hoe LLaMA te bouwen 2
Om LLaMA 2 te bouwen, moet u verschillende stappen volgen, waaronder het opzetten van uw ontwikkelomgeving, toegang krijgen tot het model en het aanroepen met de juiste parameters.
Stap 1: Bibliotheken importeren
- Importeer in de eerste cel van het notitieblok de benodigde bibliotheken:
import boto3
import json
Stap 2: Definieer Prompt en AWS Bedrock Client
- Definieer in de volgende cel de prompt voor het genereren van het gedicht en maak een client voor toegang tot de AWS Bedrock API:
prompt_data = """
Act as a Shakespeare and write a poem on Generative AI
"""
bedrock = boto3.client(service_name="bedrock-runtime")
Stap 3: Payload definiëren en model aanroepen
- Bekijk eerst de API in AWS Bedrock.
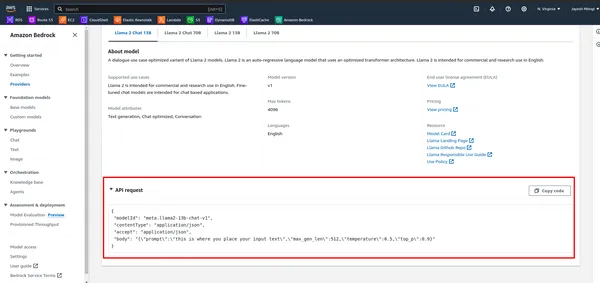
- Definieer de payload met de prompt en andere parameters en roep vervolgens het model aan met behulp van de AWS Bedrock-client:
payload = {
"prompt": "[INST]" + prompt_data + "[/INST]",
"max_gen_len": 512,
"temperature": 0.5,
"top_p": 0.9
}
body = json.dumps(payload)
model_id = "meta.llama2-70b-chat-v1"
response = bedrock.invoke_model(
body=body,
modelId=model_id,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get("body").read())
response_text = response_body['generation']
print(response_text)
Stap 4: Voer het notitieblok uit
- Voer de cellen in het notitieblok één voor één uit door op Shift + Enter te drukken. De uitvoer van de laatste cel toont het gegenereerde gedicht.
Stap 5: Maak een Streamlit-app
- Maak een Python-script: maak een nieuw Python-script (bijv. lama2_app.py) en open het in de code-editor van uw voorkeur
import streamlit as st
import boto3
import json
# Define AWS Bedrock client
bedrock = boto3.client(service_name="bedrock-runtime")
# Streamlit app layout
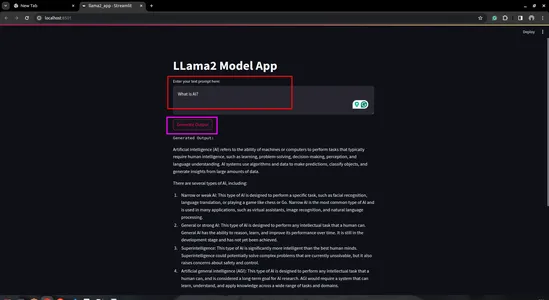
st.title('LLama2 Model App')
# Text input for user prompt
user_prompt = st.text_area('Enter your text prompt here:', '')
# Button to trigger model invocation
if st.button('Generate Output'):
payload = {
"prompt": user_prompt,
"max_gen_len": 512,
"temperature": 0.5,
"top_p": 0.9
}
body = json.dumps(payload)
model_id = "meta.llama2-70b-chat-v1"
response = bedrock.invoke_model(
body=body,
modelId=model_id,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get("body").read())
generation = response_body['generation']
st.text('Generated Output:')
st.write(generation)
- Voer de Streamlit-app uit:
- Sla uw Python-script op en voer het uit met behulp van de Streamlit-opdracht in uw terminal:
streamlit run llama2_app.py
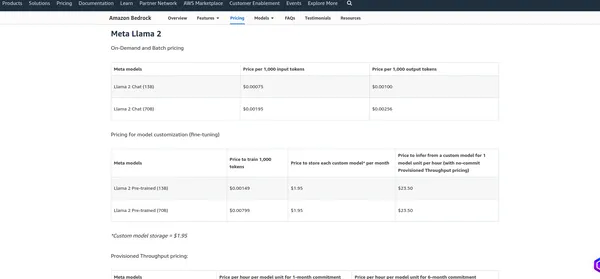
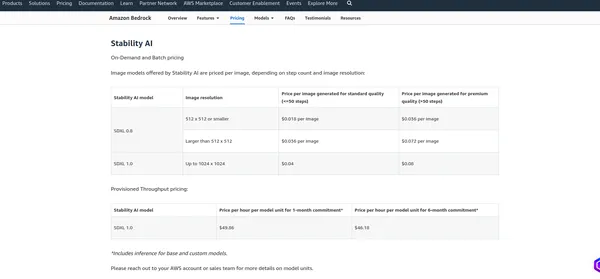
Prijzen van AWS-basis
De prijsstelling van AWS Bedrock hangt af van verschillende factoren en de diensten die u gebruikt, zoals modelhosting, gevolgtrekkingsverzoeken, gegevensopslag en gegevensoverdracht. AWS brengt doorgaans kosten in rekening op basis van gebruik, wat betekent dat u alleen betaalt voor wat u gebruikt. Ik raad aan om de officiële prijspagina te raadplegen, aangezien AWS hun prijsstructuur kan wijzigen. Ik kan u de huidige kosten verstrekken, maar u kunt het beste de informatie op de website verifiëren officiële pagina voor de meest nauwkeurige details.
Meta LlaMA 2
Stabiliteit AI
Conclusie
Deze blog verdiepte zich in het domein van generatieve AI, waarbij de nadruk specifiek lag op twee krachtige LLM-modellen: Stable Diffusion en LLamV2. We hebben ook AWS Bedrock onderzocht als platform voor het maken van LLM-model-API's. Met behulp van deze API's hebben we gedemonstreerd hoe code moet worden geschreven voor interactie met de modellen. Daarnaast hebben we de AWS Bedrock-speeltuin gebruikt om de mogelijkheden van de modellen te oefenen en te beoordelen.
In het begin hebben we het belang benadrukt van het selecteren van de juiste regio binnen AWS Bedrock, omdat deze modellen mogelijk niet in alle regio's beschikbaar zijn. In de toekomst hebben we elk LLM-model praktisch onderzocht, beginnend met het maken van Jupyter-notebooks en vervolgens overgaand naar de ontwikkeling van Streamlit-applicaties.
Ten slotte bespraken we de prijsstructuur van AWS Bedrock, waarbij we de noodzaak onderstreepten om de bijbehorende kosten te begrijpen en naar de officiële prijspagina te verwijzen voor nauwkeurige informatie.
Key Takeaways
- Stabiele diffusie en LLAMV2 op AWS Bedrock bieden gemakkelijke toegang tot krachtige generatieve AI-mogelijkheden.
- AWS Bedrock biedt een eenvoudige interface en uitgebreide documentatie voor naadloze integratie.
- Deze modellen hebben verschillende belangrijke kenmerken en gebruiksscenario's in verschillende domeinen.
- Vergeet niet om de juiste regio te kiezen voor toegang tot de gewenste modellen op AWS Bedrock.
- Praktische implementatie van generatieve AI-modellen zoals Stable Diffusion en LLAMv2 biedt efficiëntie op AWS Bedrock.
Veelgestelde Vragen / FAQ
A. Genatieve AI is een subset van kunstmatige intelligentie die zich richt op het creëren van nieuwe inhoud, zoals afbeeldingen, tekst of code, in plaats van alleen maar bestaande gegevens te analyseren.
A. Stable Diffusion is een generatief AI-model dat fotorealistische afbeeldingen produceert op basis van tekst- en beeldaanwijzingen met behulp van diffusietechnologie en latente ruimte.
A. AWS Bedrock biedt API's voor het beheren, trainen en implementeren van modellen, waardoor gebruikers toegang krijgen tot grote taalmodellen zoals LLAMv2 voor verschillende toepassingen.
A. U hebt toegang tot LLM-modellen op AWS Bedrock met behulp van de meegeleverde API's, zoals het aanroepen van het model met specifieke parameters en het ontvangen van de gegenereerde uitvoer.
A. Stabiele diffusie kan afbeeldingen van hoge kwaliteit genereren op basis van tekstprompts, werkt efficiënt met behulp van latente ruimte en is toegankelijk voor een breed scala aan gebruikers.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2024/02/building-end-to-end-generative-ai-models-with-aws-bedrock/

