Introductie
In de snelle wereld van lokale voedselbezorging van vandaag is het garanderen van klanttevredenheid van cruciaal belang voor bedrijven. Grote spelers als Zomato en Swiggy domineren deze industrie. Klanten verwachten vers voedsel; Als ze verwende artikelen ontvangen, stellen ze een terugbetaling of kortingsbon op prijs. Het handmatig bepalen van de versheid van voedsel is echter omslachtig voor klanten en bedrijfspersoneel. Eén oplossing is om dit proces te automatiseren met behulp van Deep Learning-modellen. Deze modellen kunnen de versheid van voedsel voorspellen, waardoor alleen gemarkeerde klachten door medewerkers kunnen worden beoordeeld voor definitieve validatie. Als het model de versheid van het voedsel bevestigt, kan het de klacht automatisch afwijzen. In dit artikel gaan we een voedselkwaliteitsdetector bouwen met behulp van Deep Learning.
Deep Learning, een subset van kunstmatige intelligentie, biedt in deze context een aanzienlijk nut. In het bijzonder kunnen CNN's (Convolutional Neural Networks) worden gebruikt om modellen te trainen met behulp van voedselbeelden om de versheid ervan te onderscheiden. De nauwkeurigheid van ons model hangt volledig af van de kwaliteit van de dataset. Idealiter zou het opnemen van echte voedselafbeeldingen van chatbotklachten van gebruikers in hyperlokale apps voor voedselbezorging de nauwkeurigheid aanzienlijk vergroten. Omdat we echter geen toegang hebben tot dergelijke gegevens, vertrouwen we op een veelgebruikte dataset die bekend staat als de ‘Fresh and Rotten Classification-dataset’, toegankelijk op Kaggle. Om de volledige deep-learning-code te verkennen, klikt u eenvoudig op de meegeleverde knop 'Kopiëren en bewerken' hier.
leerdoelen
- Leer het belang van voedselkwaliteit voor klanttevredenheid en bedrijfsgroei.
- Ontdek hoe deep learning helpt bij het bouwen van de voedselkwaliteitsdetector.
- Doe praktijkervaring op door een stapsgewijze implementatie van dit model.
- Begrijp de uitdagingen en oplossingen die betrokken zijn bij de implementatie ervan.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Inzicht in het gebruik van Deep Learning in de voedselkwaliteitsdetector
Diepe leren, een deelverzameling van Artificial Intelligence, maakt voornamelijk gebruik van ruimtelijke datasets om modellen te construeren. Neurale netwerken binnen Deep Learning worden gebruikt om deze modellen te trainen, waarbij de functionaliteit van het menselijk brein wordt nagebootst.
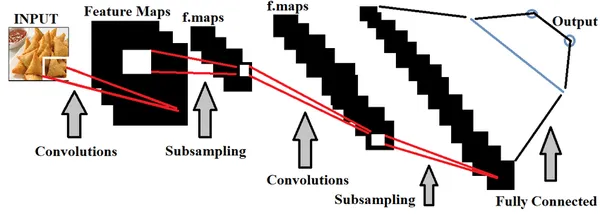
In de context van de detectie van voedselkwaliteit is het trainen van deep learning-modellen met uitgebreide sets voedselafbeeldingen essentieel voor het nauwkeurig onderscheiden van voedselproducten van goede en slechte kwaliteit. We kunnen doen afstemming van hyperparameters op basis van de gegevens die worden ingevoerd, om het model nauwkeuriger te maken.
Belang van voedselkwaliteit bij hyperlokale bezorging
Het integreren van deze functie in hyperlokale voedselbezorging biedt verschillende voordelen. Het model vermijdt vooringenomenheid jegens specifieke klanten en voorspelt accuraat, waardoor de tijd voor het oplossen van klachten wordt verkort. Bovendien kunnen we deze functie gebruiken tijdens het orderverpakkingsproces om de voedselkwaliteit vóór levering te inspecteren, zodat klanten consistent vers voedsel ontvangen.

Ontwikkeling van een voedselkwaliteitsdetector
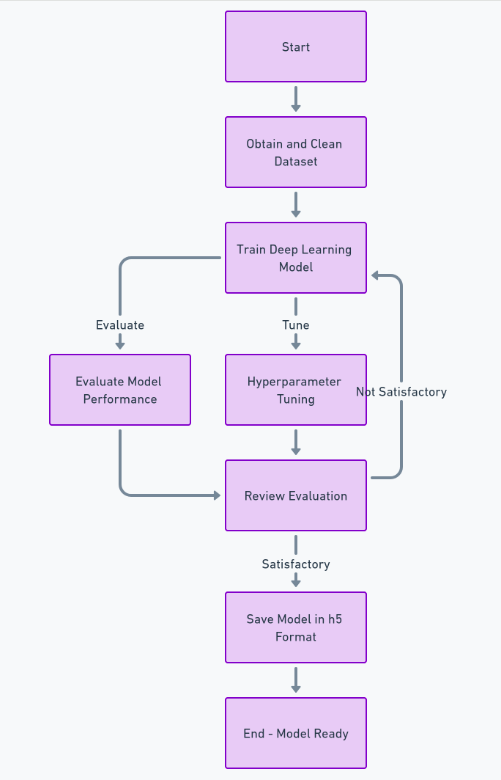
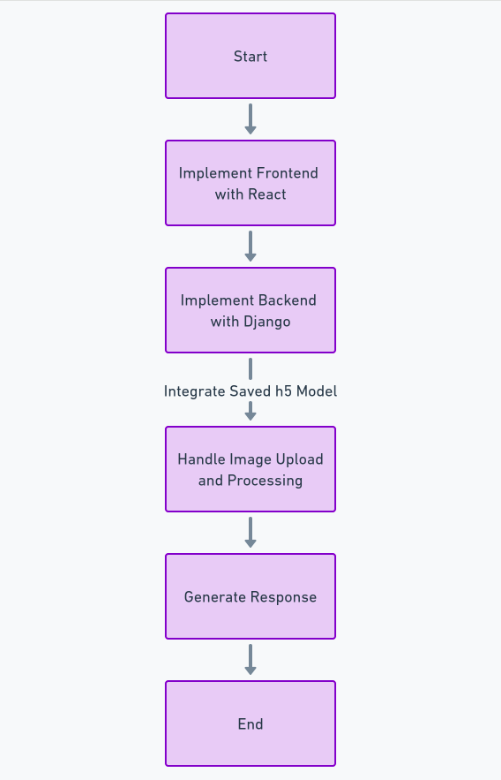
Om deze functie volledig te kunnen bouwen, moeten we een groot aantal stappen volgen, zoals het verkrijgen en opschonen van de dataset, het trainen van het deep learning-model, het evalueren van de prestaties en het afstemmen van hyperparameters, en uiteindelijk het opslaan van het model in h5 formaat. Hierna kunnen we de frontend implementeren met behulp van Reageren, en de backend met behulp van het Python-framework django. We zullen Django gebruiken om het uploaden van afbeeldingen af te handelen en te verwerken.
Over de gegevensset
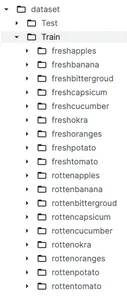
Voordat we dieper ingaan op de voorverwerking van gegevens en het bouwen van modellen, is het van cruciaal belang om de dataset te begrijpen. Zoals eerder besproken, zullen we een dataset van Kaggle gebruiken met de naam Classificatie van vers en rot voedsel. Deze dataset is opgesplitst in twee hoofdcategorieën, genaamd Trainen en test welke worden respectievelijk gebruikt voor trainings- en testdoeleinden. Onder de treinmap hebben we 9 submappen met vers fruit en verse groenten en 9 submappen met rot fruit en rotte groenten.
Belangrijkste kenmerken van dataset
- Beeldverscheidenheid: Deze dataset bevat veel voedselafbeeldingen met veel variatie in termen van hoek, achtergrond en lichtomstandigheden. Dit helpt het model niet bevooroordeeld te zijn en nauwkeuriger te zijn.
- Afbeeldingen van hoge kwaliteit: Deze dataset bevat beelden van zeer goede kwaliteit die zijn vastgelegd door verschillende professionele camera's.
Gegevens laden en voorbereiden
In deze sectie laden we eerst de afbeeldingen met 'tensorflow.keras.preprocessing.image.laad_img' functioneren en visualiseer de afbeeldingen met behulp van de matplotlib-bibliotheek. Het voorbewerken van deze afbeeldingen voor modeltraining is erg belangrijk. Dit omvat het opschonen en ordenen van de afbeeldingen om deze geschikt te maken voor het model.
import os
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import load_img
def visualize_sample_images(dataset_dir, categories):
n = len(categories)
fig, axs = plt.subplots(1, n, figsize=(20, 5))
for i, category in enumerate(categories):
folder = os.path.join(dataset_dir, category)
image_file = os.listdir(folder)[0]
img_path = os.path.join(folder, image_file)
img = load_img(img_path)
axs[i].imshow(img)
axs[i].set_title(category)
plt.tight_layout()
plt.show()
dataset_base_dir = '/kaggle/input/fresh-and-stale-classification/dataset'
train_dir = os.path.join(dataset_base_dir, 'Train')
categories = ['freshapples', 'rottenapples', 'freshbanana', 'rottenbanana']
visualize_sample_images(train_dir, categories)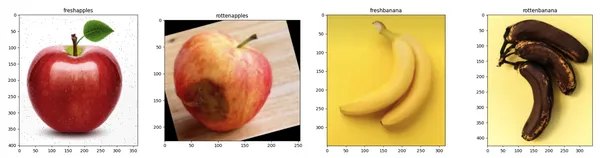
Laten we nu de trainings- en testafbeeldingen in variabelen laden. We zullen het formaat van alle afbeeldingen wijzigen in dezelfde hoogte en breedte van 180.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
batch_size = 32
img_height = 180
img_width = 180
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest',
validation_split=0.2)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='training')
validation_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='validation')
Model gebouw
Laten we nu het deep-learning-model bouwen met behulp van het Sequential-algoritme van 'tensorflow.keras'. We zullen 3 convolutielagen en een Adam-optimalisatie toevoegen. Voordat we verder ingaan op het praktische gedeelte, laten we eerst begrijpen wat de termen 'Sequentieel model''Adam Optimizer'en'Convolutielaag' gemeen.
Sequentieel model
Het sequentiële model bestaat uit een stapeling van lagen en biedt een fundamentele structuur in Keras. Het is ideaal voor scenario's waarin uw neurale netwerk een enkele invoertensor en een enkele uitvoertensor heeft. Je voegt lagen toe in de volgorde van uitvoering, waardoor het geschikt is voor het construeren van eenvoudige modellen met gestapelde lagen. Deze eenvoud maakt het sequentiële model zeer nuttig en gemakkelijker te implementeren.
Adam Optimizer
De afkorting van Adam is 'Adaptive Moment Estimation'. Het dient als een optimalisatie-algoritme als alternatief voor stochastische gradiëntdaling, waarbij netwerkgewichten iteratief worden bijgewerkt. Adam Optimizer is nuttig omdat het voor elk netwerkgewicht een leersnelheid (LR) handhaaft, wat voordelig is bij het verwerken van ruis in de gegevens.
Convolutionele laag (Conv2D)
Het is het belangrijkste onderdeel van de Convolutional Neural Networks (CNN's). Het wordt voornamelijk gebruikt voor het verwerken van ruimtelijke datasets zoals afbeeldingen. Deze laag past een convolutiefunctie of -bewerking toe op de invoer en geeft het resultaat vervolgens door aan de volgende laag.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)),
MaxPooling2D(2, 2),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs = 10
history = model.fit(
train_generator,
steps_per_epoch=train_generator.samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=validation_generator.samples // batch_size)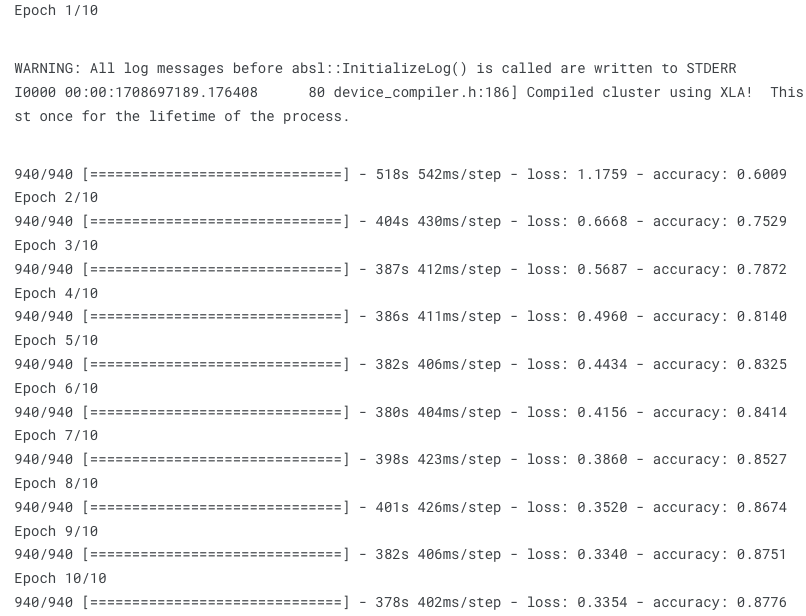
De voedselkwaliteitsdetector testen
Laten we nu het model testen door het een nieuw voedselbeeld te geven en kijken hoe nauwkeurig het kan classificeren in vers en bedorven voedsel.
from tensorflow.keras.preprocessing import image
import numpy as np
def classify_image(image_path, model):
img = image.load_img(image_path, target_size=(img_height, img_width))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array /= 255.0
predictions = model.predict(img_array)
if predictions[0] > 0.5:
print("Rotten")
else:
print("Fresh")
image_path = '/kaggle/input/fresh-and-stale-classification/dataset/Train/
rottenoranges/Screen Shot 2018-06-12 at 11.18.28 PM.png'
classify_image(image_path, model)
Zoals we kunnen zien, heeft het model het correct voorspeld. Zoals wij hebben gegeven rotoranje afbeelding als invoer zoals het model dit correct heeft voorspeld verrot.
Voor de frontend(React) en backend(Django) code kun je hier mijn volledige code op GitHub bekijken: Link
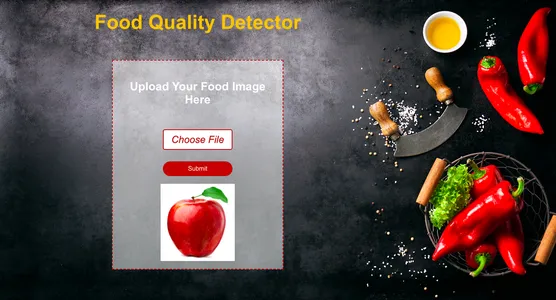
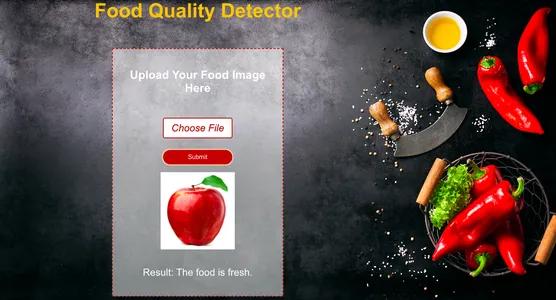
Conclusie
Concluderend, om klachten over de voedselkwaliteit in Hyperlocal Delivery-apps te automatiseren, stellen we voor een deep learning-model te bouwen dat is geïntegreerd met een webapp. Vanwege de beperkte trainingsgegevens is het echter mogelijk dat het model niet elk voedselbeeld nauwkeurig detecteert. Deze implementatie dient als een fundamentele stap naar een grotere oplossing. Toegang tot realtime door gebruikers geüploade afbeeldingen binnen deze apps zou de nauwkeurigheid van ons model aanzienlijk verbeteren.
Key Takeaways
- Voedselkwaliteit speelt een cruciale rol bij het bereiken van klanttevredenheid in de hyperlokale markt voor voedselbezorging.
- U kunt Deep Learning-technologie gebruiken om een nauwkeurige voorspeller van de voedselkwaliteit te trainen.
- Met deze stap-voor-stap handleiding heb je praktijkervaring opgedaan om de webapp te bouwen.
- U hebt het belang van de kwaliteit van de dataset voor het bouwen van een nauwkeurig model begrepen.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2024/03/food-quality-detector/

