Amazon RedshiftML stelt data-analisten en databaseontwikkelaars in staat de mogelijkheden van machine learning en kunstmatige intelligentie in hun datawarehouse te integreren. Amazon Redshift ML helpt het maken, trainen en toepassen van machine learning-modellen te vereenvoudigen via bekende SQL-opdrachten.
Je kunt de inferentiemogelijkheden van Amazon Redshift verder verbeteren door Bringing Your Own Models (BYOM). Er zijn twee soorten BYOM: 1) BYOM op afstand voor gevolgtrekkingen op afstand, en 2) lokale BYOM voor lokale gevolgtrekkingen. Met lokale BYOM maak je gebruik van een model dat is getraind in Amazon SageMaker voor inferentie in de database binnen Amazon Redshift door Amazon SageMaker te importeren Autopilot en Amazon SageMaker trainde modellen in Amazon Redshift. Als alternatief kunt u met externe BYOM externe aangepaste ML-modellen aanroepen die in SageMaker zijn geïmplementeerd. Hierdoor kunt u aangepaste modellen in SageMaker gebruiken voor churn, XGBoost, lineaire regressie, classificatie met meerdere klassen en nu ook LLM's.
Amazon Sage Maker snelle start is een SageMaker-functie die helpt bij het implementeren van vooraf getrainde, openbaar beschikbare grote taalmodellen (LLM) voor een breed scala aan probleemtypen, om u op weg te helpen met machine learning. U hebt toegang tot vooraf getrainde modellen en kunt deze ongewijzigd gebruiken, of deze modellen stapsgewijs trainen en verfijnen met uw eigen gegevens.
Voorafgaand posts, ondersteunde Amazon Redshift ML uitsluitend BYOM's die tekst of CSV accepteerden als gegevensinvoer- en uitvoerformaat. Nu is er ondersteuning toegevoegd voor het SUPER-gegevenstype voor zowel invoer als uitvoer. Met deze ondersteuning kunt u LLM's gebruiken in Amazon SageMaker JumpStart, dat tal van eigen en openbaar beschikbare basismodellen van verschillende modelaanbieders biedt.
LLM's hebben uiteenlopende gebruiksscenario's. Amazon Redshift ML ondersteunt beschikbare LLM-modellen in SageMaker, inclusief modellen voor sentimentanalyse. Bij sentimentanalyse kan het model productfeedback en tekstreeksen en daarmee het sentiment analyseren. Deze mogelijkheid is met name waardevol voor het begrijpen van productrecensies, feedback en het algemene sentiment.
Overzicht van de oplossing
In dit bericht gebruiken we Amazon Redshift ML voor sentimentanalyse van beoordelingen die zijn opgeslagen in een Amazon Redshift-tabel. Het model neemt de beoordelingen als invoer en retourneert een sentimentclassificatie als uitvoer. We gebruiken een kant-en-klare LLM in SageMaker Jumpstart. Onderstaande afbeelding toont het oplossingsoverzicht.
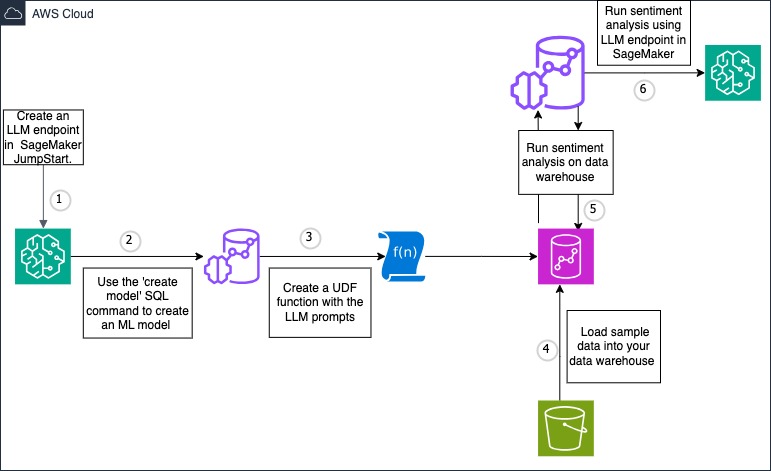
walkthrough
Volg de onderstaande stappen om sentimentanalyses uit te voeren met behulp van de integratie van Amazon Redshift met SageMaker JumpStart om LLM-modellen aan te roepen:
- Implementeer het LLM-model met behulp van basismodellen in SageMaker JumpStart en maak een eindpunt
- Maak met Amazon Redshift ML een model dat verwijst naar het SageMaker JumpStart LLM-eindpunt
- Maak een door de gebruiker gedefinieerde functie (UDF) die de prompt voor sentimentanalyse ontwikkelt
- Laad voorbeeldreviewgegevensset in uw Amazon Redshift-datawarehouse
- Maak een gevolgtrekking op afstand naar het LLM-model om sentimentanalyse voor de invoergegevensset te genereren
- Analyseer de uitvoer
Voorwaarden
Voor deze walkthrough moet u aan de volgende vereisten voldoen:
- An AWS-account
- Een serverloze preview-werkgroep van Amazon Redshift of een door Amazon Redshift ingericht preview-cluster. Verwijzen naar een voorbeeldwerkgroep maken or een voorbeeldcluster maken documentatie voor stappen.
- Voor de preview moet uw Amazon Redshift-datawarehouse ingeschakeld zijn voorbeeld_2023 volg een van deze regio's – US East (N. Virginia), US West (Oregon), EU-West (Ierland), US-East (Ohio), AP-Northeast (Tokio) of EU-North-1 (Stockholm).
Oplossingsstappen
Volg de onderstaande oplossingsstappen
1. Implementeer het LLM-model met behulp van Foundation-modellen in SageMaker JumpStart en maak een eindpunt
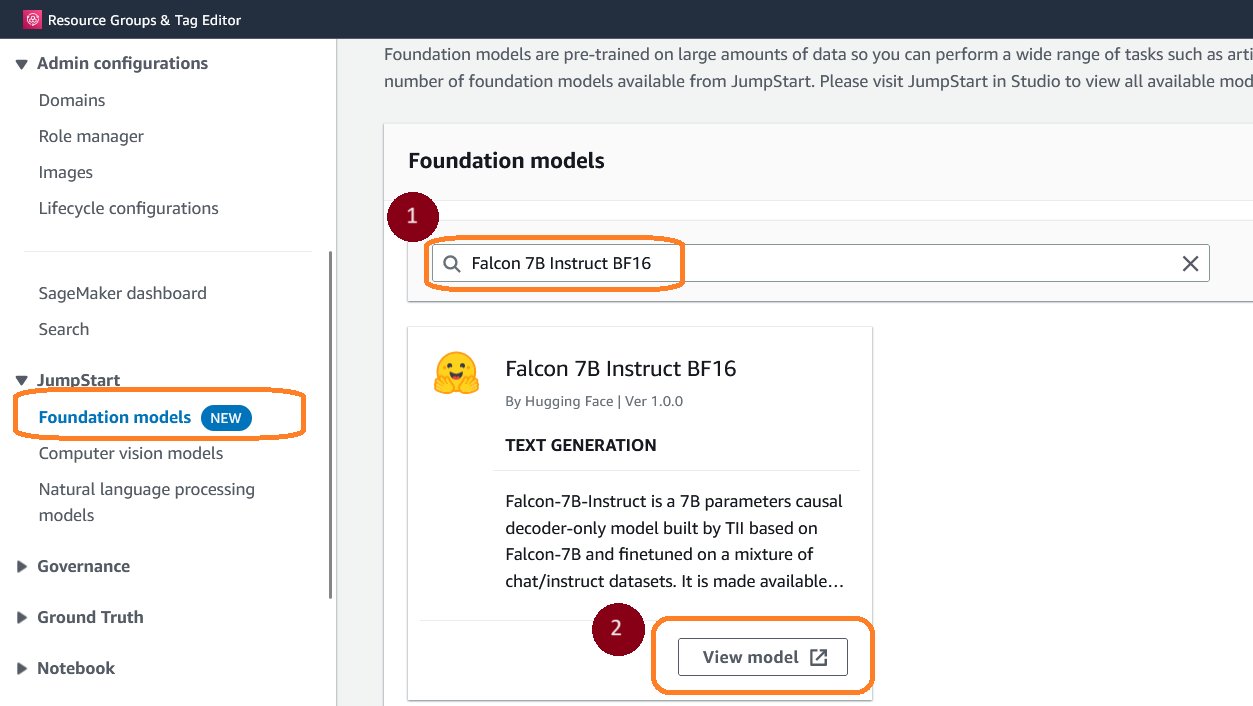
- Navigeer naar Funderingsmodellen in Amazon SageMaker Jumpstart
- Zoek het funderingsmodel door te typen Falcon 7B Instrueer BF16 in het zoekvak
- Kies Bekijk model
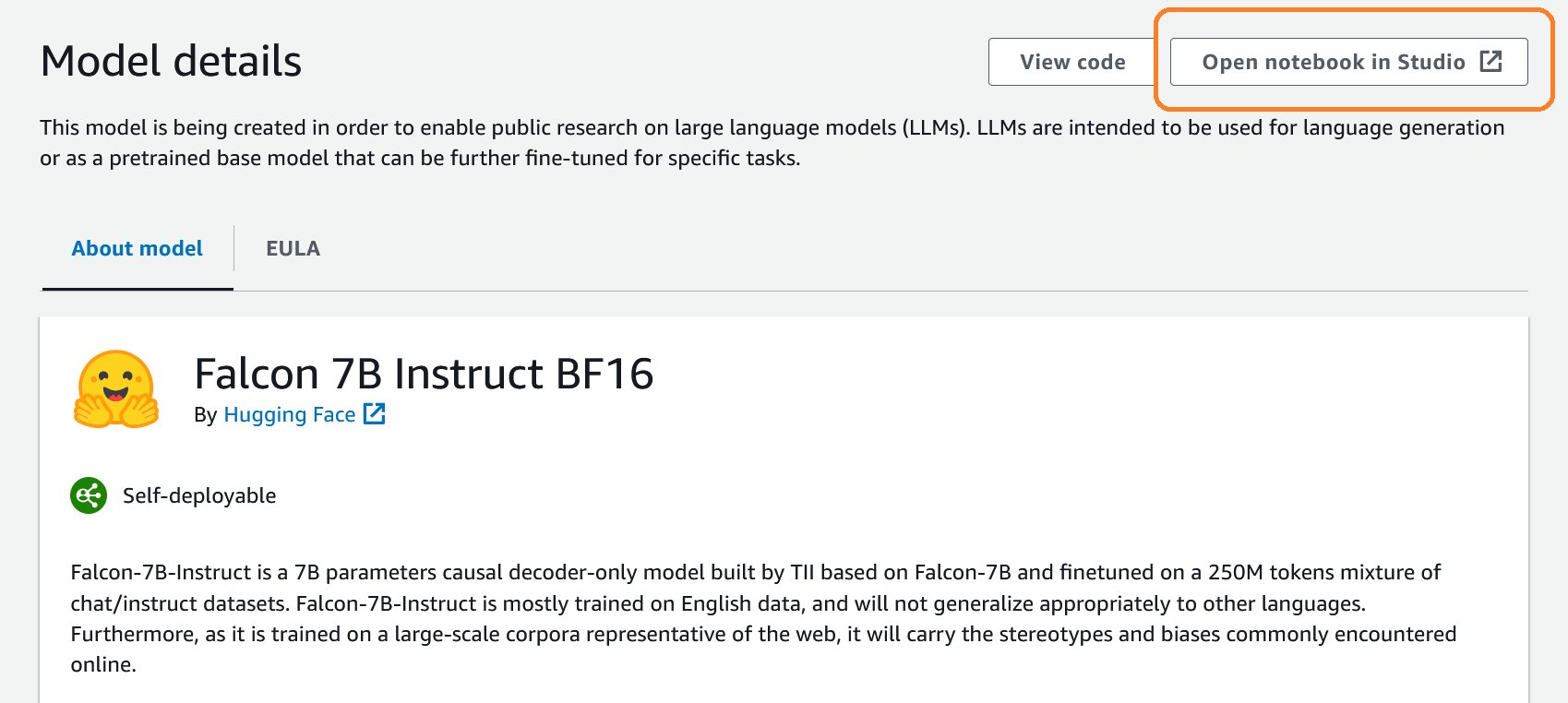
- In het Modeldetails: pagina, kies Notitieblok openen in Studio
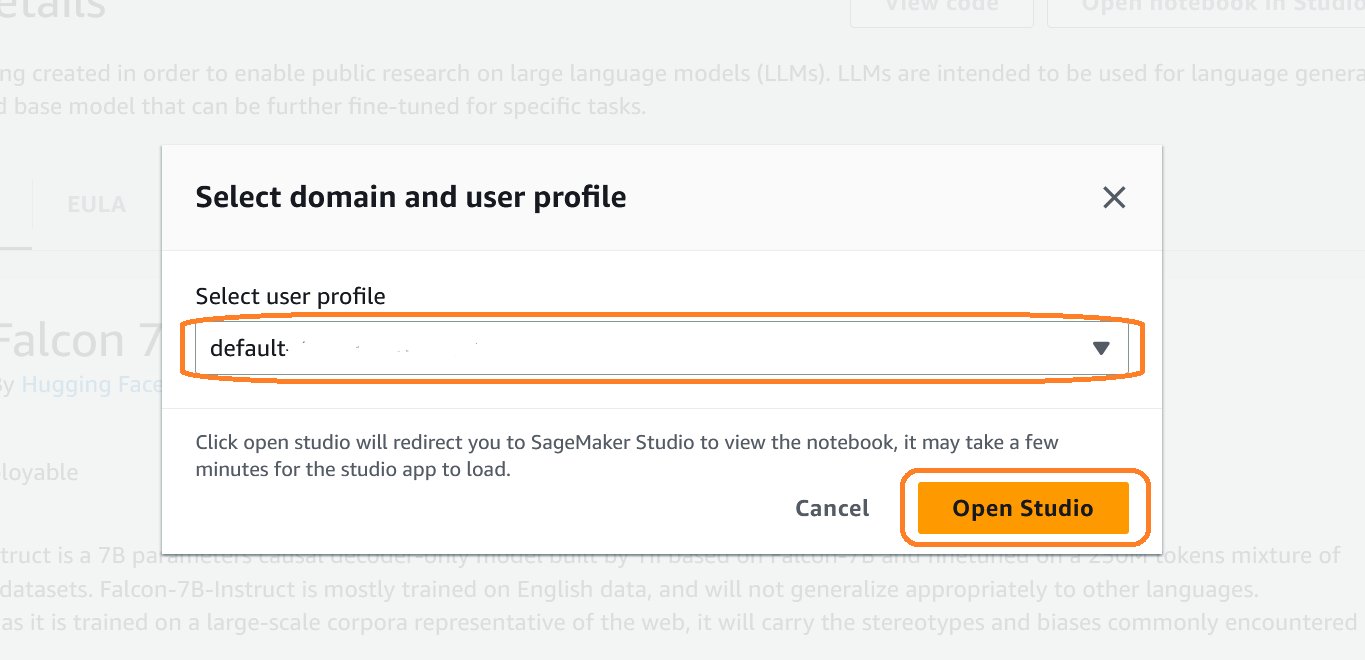
- . Selecteer domein en gebruikersprofiel dialoogvenster wordt geopend, kies het profiel dat u leuk vindt in de vervolgkeuzelijst en kies Studio openen
- Wanneer het notitieblok wordt geopend, verschijnt er een prompt Notebook-omgeving instellen springt open. Kies ml.g5.2xlarge of een ander exemplaartype dat in de notebook wordt aanbevolen en kies kies
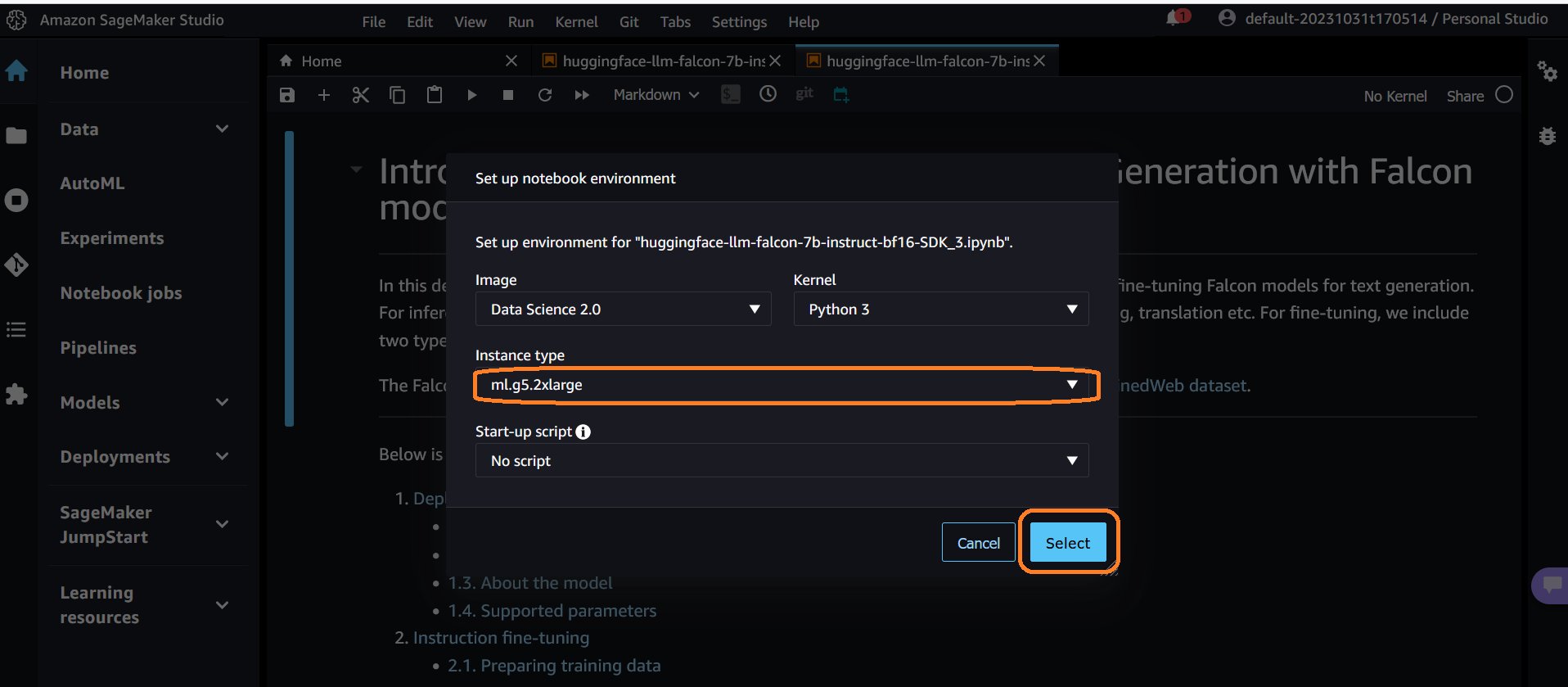
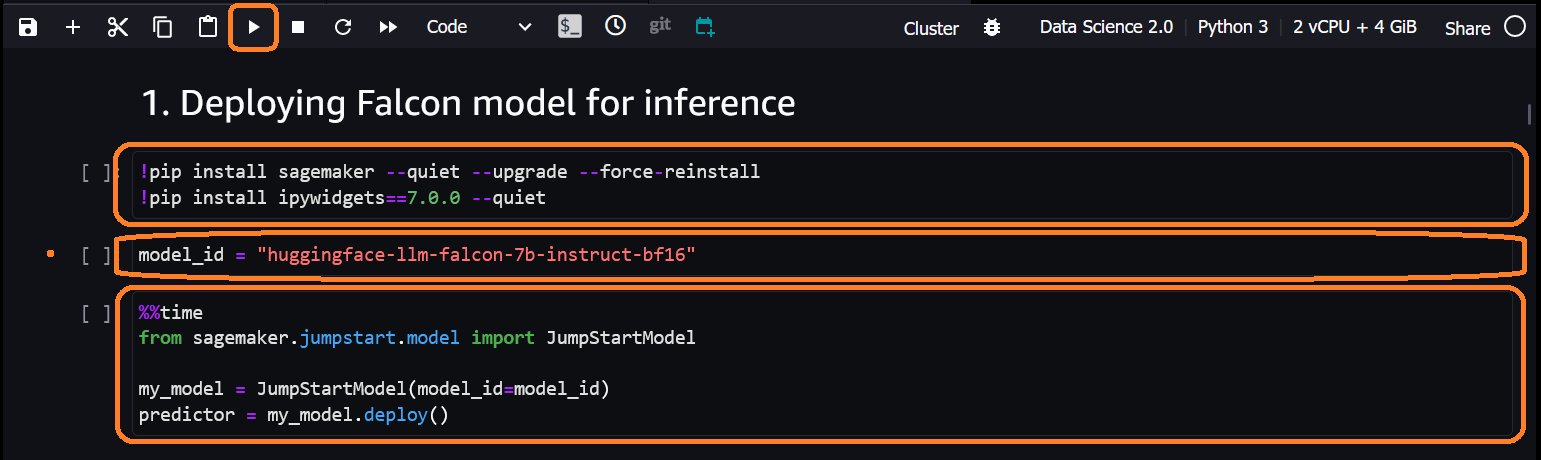
- Scroll naar Implementatie van het Falcon-model voor gevolgtrekking sectie van het notitieboekje en voer de drie cellen in die sectie uit
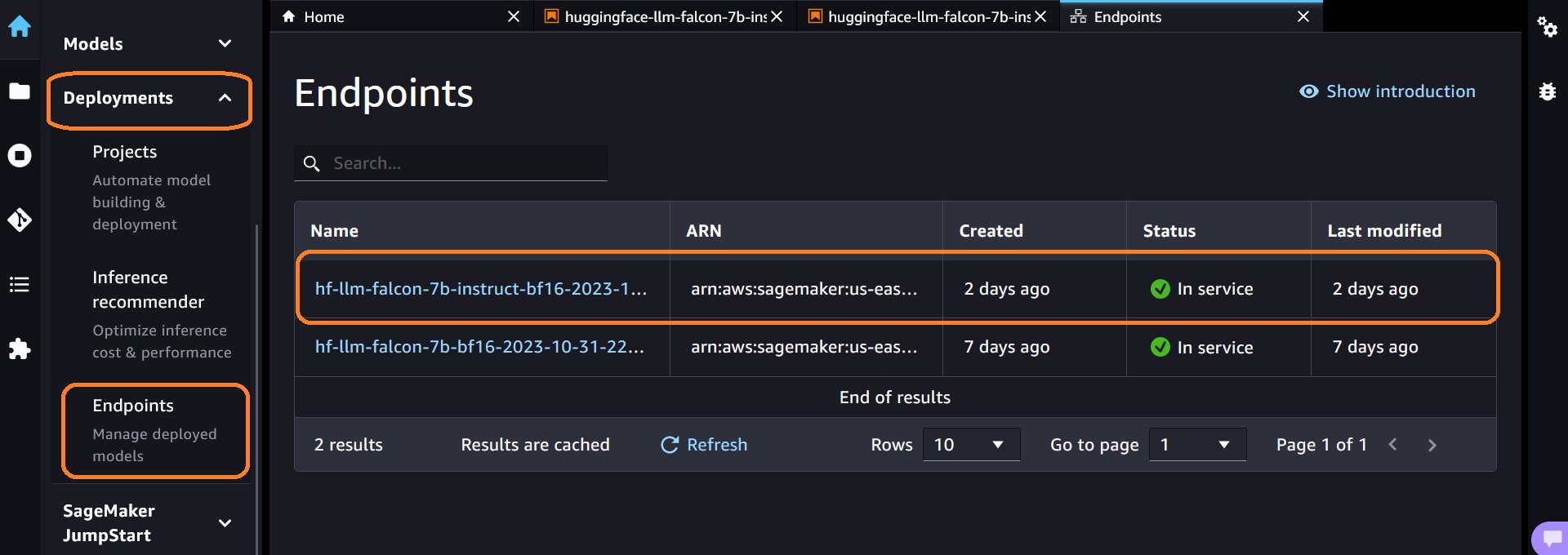
- Zodra de uitvoering van de derde cel is voltooid, vouwt u uit implementaties sectie in het linkerdeelvenster, kies Eindpunten om het gemaakte eindpunt te zien. Je kunt het eindpunt zien Naam. Noteer dat. Het zal in de volgende stappen worden gebruikt
- Selecteer Finish.
2. Maak met Amazon Redshift ML een model dat verwijst naar het SageMaker JumpStart LLM-eindpunt
Maak een model met behulp van Amazon Redshift ML, breng je eigen model (BYOM) -mogelijkheid. Nadat het model is gemaakt, kunt u de uitvoerfunctie gebruiken om op afstand conclusies te trekken uit het LLM-model. Volg de onderstaande stappen om een model in Amazon Redshift te maken voor het eerder gemaakte LLM-eindpunt.
- Log in op het Amazon Redshift-eindpunt. Je kunt gebruiken Query-editor V2 Inloggen
- import dit notitieboekje in Query-editor V2. Het bevat alle SQL's die in deze blog worden gebruikt.
- Zorg ervoor dat het onderstaande IAM-beleid is toegevoegd aan uw IAM-rol. Vervangen waarbij de SageMaker JumpStart-eindpuntnaam eerder is vastgelegd
- Maak een model in Amazon Redshift met behulp van de onderstaande create model-instructie. Vervangen met de eerder vastgelegde eindpuntnaam. Het invoer- en uitvoergegevenstype voor het model moet SUPER zijn.

3. Laad een dataset met voorbeeldreviews in uw Amazon Redshift-datawarehouse
In deze blogpost gebruiken we een voorbeeld van een fictieve recensie-dataset voor de walkthrough
- Log in op Amazon Redshift met behulp van Query-editor V2
- creëren
sample_reviewstabel met behulp van de onderstaande SQL-instructie. In deze tabel wordt de dataset met voorbeeldbeoordelingen opgeslagen - Download de voorbeeldbestand, upload naar uw S3-bucket en laad gegevens in
sample_reviewstabel met behulp van de onderstaande COPY-opdracht
4. Maak een UDF die de prompt voor sentimentanalyse verzorgt
De invoer voor de LLM bestaat uit twee hoofdonderdelen: de prompt en de parameters.
De prompt is de begeleiding of reeks instructies die u aan de LLM wilt geven. De prompt moet duidelijk zijn om de juiste context en richting voor de LLM te bieden. Generatieve AI-systemen zijn sterk afhankelijk van de gegeven aanwijzingen om te bepalen hoe een reactie moet worden gegenereerd. Als de prompt niet voldoende context en begeleiding biedt, kan dit tot nutteloze reacties leiden. Snelle engineering helpt deze valkuilen te vermijden.
Het vinden van de juiste woorden en structuur voor een prompt is een uitdaging en vereist vaak vallen en opstaan. Met Prompt Engineering kun je experimenteren om aanwijzingen te vinden die op betrouwbare wijze de gewenste output opleveren. Snelle engineering helpt bij het vormgeven van de input om de mogelijkheden van het gebruikte generatieve AI-model optimaal te benutten. Goed opgebouwde aanwijzingen zorgen ervoor dat generatieve AI meer genuanceerde, hoogwaardige en behulpzame antwoorden kan bieden die zijn afgestemd op de specifieke behoeften van de gebruiker.
De parameters maken het configureren en afstemmen van de uitvoer van het model mogelijk. Dit omvat instellingen zoals maximale lengte, willekeursniveaus, stopcriteria en meer. Parameters geven controle over de eigenschappen en stijl van de gegenereerde tekst en zijn modelspecifiek.
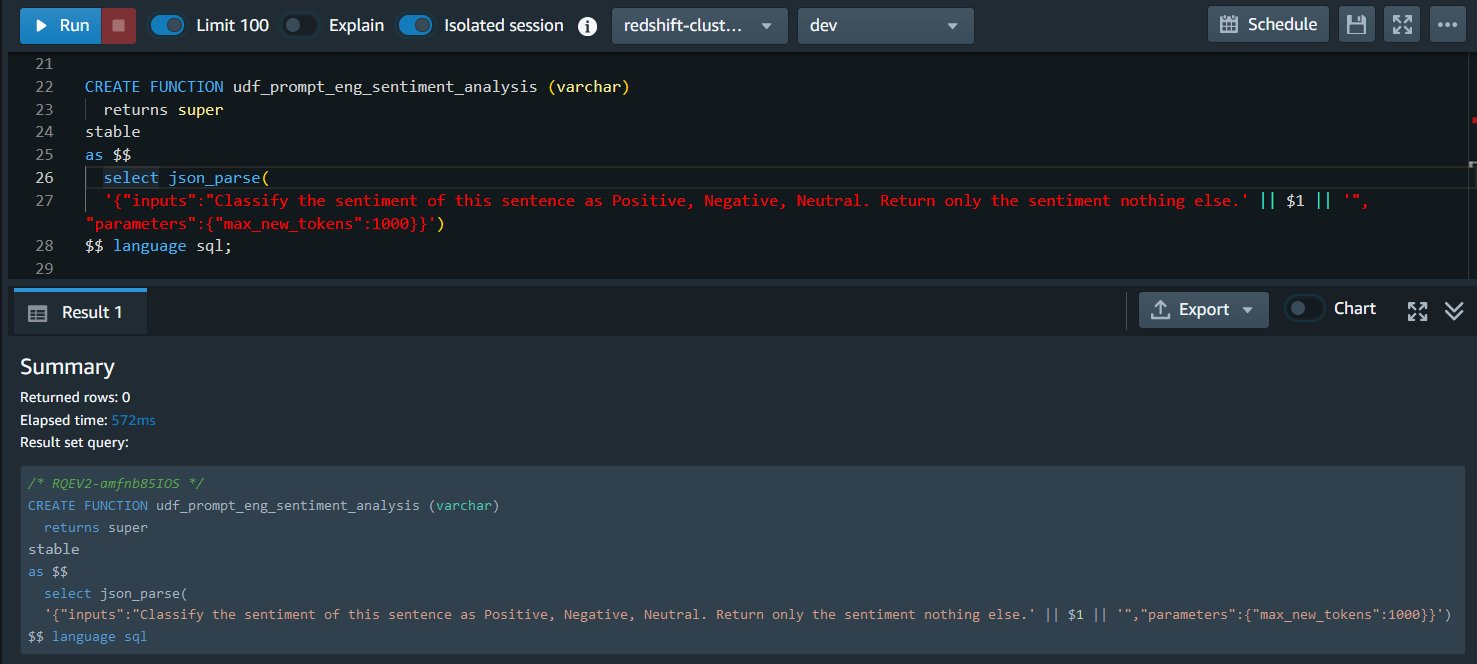
De onderstaande UDF neemt varchar-gegevens in uw datawarehouse en parseert deze in SUPER (JSON-indeling) voor de LLM. Dankzij deze flexibiliteit kunt u uw gegevens als varchar in uw datawarehouse opslaan zonder dat u er een gegevenstypeconversie naar hoeft uit te voeren SUPER om LLM's te gebruiken in Amazon Redshift ML en maakt snelle engineering eenvoudig. Als u een andere prompt wilt proberen, kunt u gewoon de UDF vervangen
De hieronder gegeven UDF heeft zowel de prompt als een parameter.
- Prompt: “Classificeer het sentiment van deze zin als positief, negatief, neutraal. Retourneer alleen het sentiment, niets anders” – Dit geeft het model de opdracht om de recensie in 3 sentimentcategorieën te classificeren.
- Parameter: “max_new_tokens”:1000 – Hiermee kan het model maximaal 1000 tokens retourneren.
5. Maak een gevolgtrekking op afstand van het LLM-model om sentimentanalyse voor de invoergegevensset te genereren
De uitvoer van deze stap wordt opgeslagen in een nieuw gemaakte tabel genaamd sentiment_analysis_for_reviews. Voer de onderstaande SQL-instructie uit om een tabel te maken met uitvoer van het LLM-model

6. Analyseer de uitvoer
De uitvoer van de LLM is van het datatype SUPER. Voor het Falcon-model is de uitvoer beschikbaar in het genoemde attribuut gegenereerde_tekst. Elke LLM heeft zijn eigen uitvoerpayload-formaat. Raadpleeg de documentatie voor de LLM die u wilt gebruiken voor het uitvoerformaat.
Voer de onderstaande query uit om het sentiment uit de uitvoer van het LLM-model te extraheren. Voor elke recensie kunt u de sentimentanalyse bekijken

Schoonmaken
Om te voorkomen dat er in de toekomst kosten in rekening worden gebracht, verwijdert u de bronnen.
- Verwijder het LLM-eindpunt in SageMaker Jumpstart
- Laat vallen
sample_reviewstabel en het model in Amazon Redshift met behulp van de onderstaande query
- Als u een Amazon Redshift-eindpunt hebt gemaakt, verwijdert u het eindpunt ook
Conclusie
In dit bericht hebben we u laten zien hoe u sentimentanalyse kunt uitvoeren voor gegevens die zijn opgeslagen in Amazon Redshift met behulp van Falcon, een groot taalmodel (LLM) in SageMaker jumpstart en Amazon Redshift ML. Falcon wordt als voorbeeld gebruikt, u kunt ook andere LLM-modellen gebruiken met Amazon Redshift ML. Sentimentanalyse is slechts een van de vele gebruiksscenario's die mogelijk zijn met LLM-ondersteuning in Amazon Redshift ML. U kunt andere gebruiksscenario's realiseren, zoals gegevensverrijking, samenvatting van inhoud, ontwikkeling van kennisgrafieken en meer. LLM-ondersteuning verbreedt de analytische mogelijkheden van Amazon Redshift ML, omdat het data-analisten en ontwikkelaars de mogelijkheid blijft geven om machine learning op te nemen in hun datawarehouse-workflow met gestroomlijnde processen, aangestuurd door bekende SQL-opdrachten. De toevoeging van het SUPER-gegevenstype verbetert de Amazon Redshift ML-mogelijkheden, waardoor een soepele integratie van grote taalmodellen (LLM) van SageMaker JumpStart voor externe BYOM-gevolgtrekkingen mogelijk wordt.
Over de auteurs
 Zegen Bamiduro maakt deel uit van het Amazon Redshift Product Management-team. Ze werkt samen met klanten om het gebruik van Amazon Redshift ML in hun datawarehouse te verkennen. In haar vrije tijd houdt Blessing van reizen en avonturen.
Zegen Bamiduro maakt deel uit van het Amazon Redshift Product Management-team. Ze werkt samen met klanten om het gebruik van Amazon Redshift ML in hun datawarehouse te verkennen. In haar vrije tijd houdt Blessing van reizen en avonturen.
 Anusha Challa is een Senior Analytics Specialist Solutions Architect gericht op Amazon Redshift. Ze heeft veel klanten geholpen bij het bouwen van grootschalige datawarehouse-oplossingen in de cloud en op locatie. Ze is gepassioneerd door data-analyse en data science.
Anusha Challa is een Senior Analytics Specialist Solutions Architect gericht op Amazon Redshift. Ze heeft veel klanten geholpen bij het bouwen van grootschalige datawarehouse-oplossingen in de cloud en op locatie. Ze is gepassioneerd door data-analyse en data science.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/large-language-models-for-sentiment-analysis-with-amazon-redshift-ml-preview/

