Tienduizenden klanten draaien bedrijfskritische workloads Amazon roodverschuiving, het snelle datawarehouse in de cloud op petabyte-schaal dat de beste prijs-prestatieverhouding levert. Met Amazon Redshift kunt u gegevens opvragen in uw datawarehouse, operationele datastores en datalake met behulp van standaard SQL. U kunt ook AWS-services integreren zoals Amazon EMR, Amazone Athene, Amazon Sage Maker, AWS lijm, AWS Lake-formatie en Amazon Kinesis om te profiteren van alle analytische mogelijkheden in de AWS Cloud.
Amazon Redshift RSQL is een native opdrachtregelclient voor interactie met Amazon Redshift-clusters en databases. U kunt verbinding maken met een Amazon Redshift-cluster, database-objecten beschrijven, gegevens opvragen en resultaten van zoekopdrachten bekijken in verschillende uitvoerindelingen. U kunt Amazon Redshift RSQL gebruiken om bestaande scripts voor extraheren, transformeren, laden (ETL) en automatisering, zoals Teradata BTEQ-scripts, te vervangen. U kunt Amazon Redshift RSQL-statements in een shellscript verpakken om bestaande functionaliteit in de lokale systemen te repliceren. Amazon Redshift RSQL is beschikbaar voor Linux-, Windows- en macOS-besturingssystemen.
In dit bericht wordt uitgelegd hoe u een generiek configuratiegestuurd orkestratieframework kunt maken met behulp van AWS Stap Functies, Amazon Elastic Compute-cloud (Amazone EC2), AWS Lambda, Amazon DynamoDB en AWS-systeembeheerder om op RSQL gebaseerde ETL-workloads te orkestreren. Als u migreert van verouderde datawarehouse-workloads naar Amazon Redshift, kunt u deze methodologie gebruiken om uw datawarehousing-workloads te orkestreren.
Overzicht oplossingen
Klanten die migreren van verouderde datawarehouses naar Amazon Redshift kunnen een aanzienlijke investering doen in bedrijfseigen scripts zoals Basic Teradata Query (BTEQ)-scripting voor databaseautomatisering, ETL of andere taken. U kunt nu de AWS Schema Conversie Tool (AWS SCT) om eigen scripts zoals BTEQ-scripts automatisch te converteren naar Amazon Redshift RSQL-scripts. De geconverteerde scripts draaien op Amazon Redshift met weinig tot geen wijzigingen. Raadpleeg voor meer informatie over nieuwe opties voor databasescripting Versnel uw datawarehouse-migratie naar Amazon Redshift – deel 4.
Tijdens dergelijke migraties wilt u misschien ook uw huidige on-premises orkestratietools van derden moderniseren met een cloud-native framework om uw huidige orkestratiemogelijkheden te repliceren en te verbeteren. Het orkestreren van datawarehouse-workloads omvat het plannen van de taken, controleren of aan de voorwaarden is voldaan, het uitvoeren van de bedrijfslogica die is ingebed in RSQL, het bewaken van de status van de taken en het waarschuwen als er fouten zijn.
Met deze oplossing kunnen lokale klanten migreren naar een cloud-native orchestration-framework dat gebruikmaakt van AWS-serverloze services zoals Step Functions, Lambda, DynamoDB en Systems Manager om de Amazon Redshift RSQL-taken uit te voeren die zijn geïmplementeerd op een persistent EC2-exemplaar. U kunt de oplossing ook inzetten voor greenfield-implementaties. Deze oplossing voldoet niet alleen aan de functionele vereisten, maar biedt ook volledige auditing, logging en monitoring van alle ETL- en ELT-processen die worden uitgevoerd.
Om hoge beschikbaarheid en veerkracht te garanderen, kunt u meerdere EC2-exemplaren gebruiken die deel uitmaken van een groep voor automatisch schalen, samen met Amazon elastisch bestandssysteem (Amazon EFS) om de RSQL-taken te implementeren en uit te voeren. Wanneer u groepen voor automatisch schalen gebruikt, kunt u RSQL op de EC2-instantie installeren als onderdeel van het bootstrap-script. U kunt ook de Amazon Redshift RSQL-scripts op de EC2-instantie implementeren met behulp van AWS CodePipeline en AWS CodeDeploy. Voor meer details, zie: Groepen voor automatisch schalen Amazon EFT-gebruikershandleiding en Integratie van CodeDeploy met Amazon EC2 Auto Scaling.
Het volgende diagram illustreert de architectuur van het orchestration-framework.
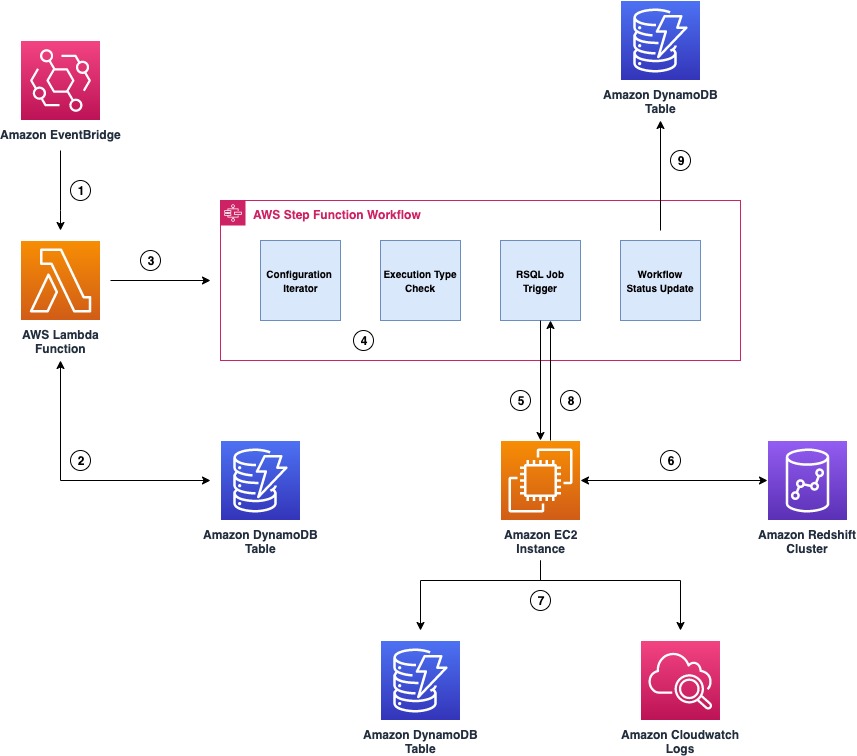
De belangrijkste onderdelen van het raamwerk zijn als volgt:
- Amazon EventBridge wordt gebruikt als de ETL-workflowplanner en activeert een Lambda-functie volgens een vooraf ingesteld schema.
- De functie vraagt een DynamoDB-tabel op voor de configuratie die is gekoppeld aan de RSQL-taak en vraagt de status van de taak, uitvoeringsmodus en herstartinformatie voor die taak op.
- Na ontvangst van de configuratie activeert de functie een Step Functions-statusmachine door de configuratiedetails door te geven.
- Step Functions begint met het uitvoeren van verschillende stadia (zoals configuratie-iteratie, uitvoeringstypecontrole en meer) van de werkstroom.
- Step Functions maakt gebruik van de Systeembeheerder
SendCommandAPI om de RSQL-taak te activeren en gaat in een gepauzeerde status metTaskToken. De RSQL-scripts worden bewaard op een EC2-instantie en zijn verpakt in een shellscript. Systeembeheer voert eenAWS-RunShellScriptSSM-document om de RSQL-taak op de EC2-instantie uit te voeren. - De RSQL-taak voert ETL- en ELT-bewerkingen uit op het Amazon Redshift-cluster. Wanneer het voltooid is, retourneert het een succes-/mislukkingscode en een statusbericht terug naar het aanroepende shellscript.
- Het shellscript roept een aangepaste Python-module aan met de succes-/mislukkingscode, het statusbericht en de callwait
TaskTokendie is ontvangen van Step Functions. De Python-module logt de RSQL-taakstatus in de taakaudit DynamoDB-audittabel en exporteert logboeken naar de Amazon Cloud Watch log groep. - De Python-module voert vervolgens een
SendTaskSuccessorSendTaskFailureAPI-aanroep op basis van de uitvoeringsstatus van de RSQL-taak. Op basis van de status van de RSQL-taak hervat Step Functions de stroom of stopt met falen. - Step Functions registreert de werkstroomstatus (geslaagd of mislukt) in de DynamoDB-werkstroomcontroletabel.
Voorwaarden
U moet de volgende vereisten hebben:
AWS CDK-stacks implementeren
Voer de volgende stappen uit om uw bronnen te implementeren met behulp van de AWS CDK:
- Kloon de GitHub-repo:
- Werk de volgende omgevingsparameters bij in
cdk.json(dit bestand is te vinden in de infra-directory):- ec2_instance_id – De EC2-instantie-ID waarop RSQL-taken worden geïmplementeerd
- roodverschuiving_geheim_id – De naam van de Secrets Manager-sleutel die de inloggegevens van de Amazon Redshift-database opslaat
- rsql_script_pad – Het absolute directorypad in de EC2-instantie waar de RSQL-taken zijn opgeslagen
- rsql_log_pad – Het absolute directorypad in de EC2-instantie die wordt gebruikt voor het opslaan van de RSQL-taaklogboeken
- rsql_script_wrapper – Het absolute directorypad van het RSQL-wrapperscript (rsql_trigger.sh) op de EC2-instantie.
Het volgende is een voorbeeld:
cdk.jsonbestand nadat het is gevuld met de parameters - Implementeer de AWS CDK-stack met de volgende code:
Laten we eens kijken naar de bronnen die de AWS CDK-stack in meer detail inzet.
CloudWatch-logboekgroep
Een CloudWatch-logboekgroep (/ops/rsql-logs/) wordt gemaakt, dat wordt gebruikt voor het opslaan, bewaken en openen van logbestanden van EC2-instanties en andere bronnen.
De logboekgroep wordt gebruikt om de logboeken van de uitvoering van de RSQL-taak op te slaan. Voor elk RSQL-script worden alle stdout en stderr logboeken worden opgeslagen als een logboekstroom binnen deze logboekgroep.
DynamoDB-configuratietabel
De DynamoDB-configuratietabel (rsql-blog-rsql-config-table) is de basisbouwsteen van deze oplossing. Alle RSQL-taken, herstartinformatie en uitvoeringsmodus (sequentieel of parallel) en de volgorde waarin de taken moeten worden uitgevoerd, worden in deze configuratietabel opgeslagen.
De tabel heeft de volgende opbouw:
- werkstroom_id – De identificatie voor de op RSQL gebaseerde ETL-workflow.
- workflow_description – De beschrijving voor de op RSQL gebaseerde ETL-workflow.
- workflow_stages – De opeenvolging van fasen binnen een workflow.
- uitvoering_type – Het type run voor RSQL-taken (sequentieel of parallel).
- fase_beschrijving – De beschrijving voor het podium.
- scripts – De lijst met RSQL-scripts die moeten worden uitgevoerd. De RSQL-scripts moeten op de locatie worden geplaatst die in een latere stap is gedefinieerd.
Het volgende is een voorbeeld van een invoer in de configuratietabel. Je kan de ... zien workflow_id is blog_test_workflow en de beschrijving is Testworkflow voor blog.
Het heeft drie fasen die in de volgende volgorde worden geactiveerd: Schema & Table Creation Stage, Data Insertion Stage 1, and Data Insertion Stage 2. Het podium Schema & Table Creation Stage heeft twee RSQL-taken die opeenvolgend worden uitgevoerd, en Data Insertion Stage 1 en Data Insertion Stage 2 elk heeft twee taken die parallel worden uitgevoerd.
DynamoDB-audittabellen
De audittabellen slaan de uitvoeringsdetails op voor elke RSQL-taak binnen de ETL-workflow met een unieke identificatiecode voor monitoring- en rapportagedoeleinden. De reden waarom er twee audittabellen zijn, is omdat de ene tabel de auditinformatie op RSQL-taakniveau opslaat en de andere op workflowniveau.
De taakcontroletabel (rsql-blog-rsql-job-audit-table) heeft de volgende opbouw:
- taak_naam – De naam van het RSQL-script
- workflow_execution_id – De run-ID voor de werkstroom
- uitvoering_start_ts – De starttijdstempel voor de RSQL-taak
- uitvoering_end_ts – De eindtijdstempel voor de RSQL-taak
- uitvoering_status – De uitvoeringsstatus van de RSQL-taak (
Running, Completed, Failed) - instantie_id – De EC2-instantie-ID waarop de RSQL-taak wordt uitgevoerd
- ssm_command_id – De opdracht-ID van de systeembeheerder die wordt gebruikt om de RSQL-taak te activeren
- werkstroom_id - The
workflow_idwaaronder de RSQL-taak wordt uitgevoerd
De werkstroomcontroletabel (rsql-blog-rsql-workflow-audit-table) heeft de volgende structuur:
- workflow_execution_id – De run-ID voor de werkstroom
- werkstroom_id – De identificatie voor een bepaalde workflow
- uitvoering_start_ts – De starttijdstempel voor de werkstroom
- uitvoering_status – De uitvoeringsstatus van de werkstroom of statusmachine (
Running, Completed, Failed) - rsql_jobs – De lijst met RSQL-scripts die deel uitmaken van de werkstroom
- uitvoering_end_ts – De eindtijdstempel voor de werkstroom
Lambda-functies
De AWS CDK maakt de Lambda-functies die de configuratiegegevens ophalen uit de DynamoDB-configuratietabel, de auditdetails in DynamoDB bijwerken, de RSQL-scripts op de EC2-instantie activeren en elke fase herhalen. Het volgende is een lijst van de functies:
rsql-blog-master-iterator-lambdarsql-blog-parallel-load-check-lambdarsql-blog-sequential-iterator-lambdarsql-blog-rsql-invoke-lambdarsql-blog-update-audit-ddb-lambda
Step Functions staat machines
Deze oplossing implementeert een Step Functions callback-taakintegratiepatroon waarmee Step Functions-workflows een token naar een extern systeem kunnen sturen via meerdere AWS-services.
De AWS CDK implementeert de volgende statusmachines:
- RSQLParallelStateMachine – De parallelle toestandsmachine wordt geactiveerd als het uitvoeringstype voor een fase in de configuratietabel is ingesteld op parallel. De Lambda-functie met een callback-token wordt parallel geactiveerd voor elk van de RSQL-scripts met behulp van een Kaart staat.
- RSQLSequentialStateMachine – De sequentiële toestandsmachine wordt geactiveerd als het uitvoeringstype voor een fase in de configuratietabel is ingesteld op sequentieel. Deze toestandsmachine gebruikt een iterator ontwerppatroon om elke RSQL-taak binnen de fase uit te voeren volgens de volgorde vermeld in de configuratie.
- RSQLMasterStatemachine - De primaire toestandsmachine herhaalt elke fase en activeert verschillende toestandsmachines op basis van de run-modus (sequentieel of parallel) met behulp van een Keuze staat.
Verplaats het RSQL-script en de instantiecode
Kopieer de instance_code en rsql_scripts mappen (aanwezig in de GitHub-repo) naar de EC2-instantie. Zorg ervoor dat de framework-directory binnen instance_code wordt ook gekopieerd.
De volgende screenshots laten zien dat de instance_code en rsql_scripts mappen worden gekopieerd naar dezelfde bovenliggende map op de EC2-instantie.




Workflow voor uitvoeren van RSQL-script
Zie het volgende diagram om het mechanisme voor het uitvoeren van de RSQL-scripts verder te illustreren.

De Lambda-functie, die de configuratiedetails ophaalt uit de configuratie-DynamoDB-tabel, activeert de Step Functions-workflow, die de volgende stappen uitvoert:
- Een Lambda-functie die is gedefinieerd als een werkstroomstap, ontvangt de stapfuncties
TaskTokenen configuratiedetails. - De
TaskTokenen configuratiedetails worden doorgegeven aan de EC2-instantie met behulp van de Systems ManagerSendCommandAPI-oproep. Nadat de Lambda-functie is uitgevoerd, gaat de werkstroomtak naar de gepauzeerde status en wacht op een callback-token. - De RSQL-scripts worden uitgevoerd op de EC2-instantie, die ETL en ELT uitvoert op Amazon Redshift. Nadat de scripts zijn uitgevoerd, passeert het RSQL-script de voltooiingsstatus en
TaskTokennaar een Python-script. Dit Python-script is ingebed in het RSQL-script. - Het Python-script werkt de RSQL-taakstatus bij (geslaagd/mislukt) in de taakcontrole DynamoDB-tabel. Het exporteert ook de RSQL-taaklogboeken naar de CloudWatch-loggroep.
- Het Python-script geeft de RSQL-taakstatus (geslaagd/mislukt) en het statusbericht terug aan de Step Functions-workflow samen met
TaskTokenmet deSendTaskSuccessorSendTaskFailureAPI-oproep. - Afhankelijk van de ontvangen taakstatus hervat Step Functions de workflow of stopt de workflow.
Als EC2-automatische schalingsgroepen worden gebruikt, kunt u de Systeembeheerder gebruiken SendCommand om veerkracht en hoge beschikbaarheid te garanderen door een of meer EC2-exemplaren op te geven (die deel uitmaken van de groep voor automatisch schalen). Voor meer informatie, zie Voer opdrachten op schaal uit.
Als er meerdere EC2-exemplaren worden gebruikt, stelt u de max-concurrency parameter van de RunCommand API-aanroep naar 1, die ervoor zorgt dat de RSQL-taak wordt geactiveerd op slechts één EC2-instantie. Voor meer details, zie Controles voor gelijktijdigheid gebruiken.
Voer het orkestratieframework uit
Voer de volgende stappen uit om het orchestration-framework uit te voeren:
- Navigeer op de DynamoDB-console naar de configuratietabel en voeg de eerder verstrekte configuratiegegevens in. Raadpleeg voor instructies over het invoegen van de voorbeeld-JSON-configuratiedetails Schrijf gegevens naar een tabel met behulp van de console of AWS CLI.

- Open op de Lambda-console het rsql-blog-rsql-workflow-trigger-lambda functie en kies: test.

- Voeg de testgebeurtenis toe die lijkt op de volgende code en kies test:

- Navigeer op de Step Functions-console naar de
rsql-master-state-machinefunctie om de detailpagina te openen.
- Kies Edit, kies dan Workflow Studio Nieuw. De volgende schermafbeelding toont de primaire statusmachine.

- Kies Annuleer om Workflow Studio te verlaten, kies dan Annuleer nogmaals om de bewerkingsmodus te verlaten. U wordt teruggeleid naar de detailpagina.

- Op de executies tabblad, kies de laatste uitvoering.

- Vanuit de grafiekweergave kunt u de status van elke staat controleren door deze te kiezen. Elke staat die een externe bron gebruikt, heeft een link ernaar op de Details Tab.

- Het orkestratieframework voert de ETL-belasting uit, die bestaat uit de volgende voorbeeld-RSQL-scripts:
- rsql_blog_script_1.sh – Dit script maakt een schema
rsql_blogbinnen de database - rsql_blog_script_2.sh – Dit script maakt een tabel aan
blog_tablebinnen het schema dat in het eerdere script is gemaakt - rsql_blog_script_3.sh – Voegt één rij in de tabel in die in het vorige script is gemaakt
- rsql_blog_script_4.sh – Voegt één rij in de tabel in die in het vorige script is gemaakt
- rsql_blog_script_5.sh – Voegt één rij in de tabel in die in het vorige script is gemaakt
- rsql_blog_script_6.sh – Voegt één rij in de tabel in die in het vorige script is gemaakt
- rsql_blog_script_1.sh – Dit script maakt een schema
U moet deze RSQL-scripts vervangen door de RSQL-scripts die zijn ontwikkeld voor uw workloads door de relevante configuratiedetails in te voegen in de configuratie DynamoDB-tabel (rsql-blog-rsql-config-table).
Validatie
Nadat u het framework hebt uitgevoerd, vindt u een schema (genaamd rsql_blog) met één tafel (genaamd blog_table) aangemaakt. Deze tabel bestaat uit vier rijen.

U kunt de logboeken van de RSQL-taak controleren in de CloudWatch-loggroep (/ops/rsql-logs/) en ook de uitvoeringsstatus van de werkstroom in de DynamoDB-tabel voor werkstroomcontrole (rsql-blog-rsql-workflow-audit-table).


Opruimen
Om te voorkomen dat er kosten in rekening worden gebracht voor de resources die u hebt gemaakt, verwijdert u deze. AWS CDK verwijdert alle bronnen behalve gegevensbronnen zoals DynamoDB-tabellen.
- Verwijder eerst alle AWS CDK-stacks
- Selecteer op de DynamoDB-console de volgende tabellen en verwijder ze:
rsql-blog-rsql-config-tablersql-blog-rsql-job-audit-tablersql-blog-rsql-workflow-audit-table
Conclusie
U kunt Amazon Redshift RSQL, Systems Manager, EC2-instances en Step Functions gebruiken om een modern en kosteneffectief orkestratieframework voor ETL-workflows te creëren. Er is geen overhead voor het maken en beheren van verschillende statusmachines voor elk van uw ETL-workflows. In dit bericht hebben we gedemonstreerd hoe dit op configuratie gebaseerde generieke orchestration-framework kan worden gebruikt om complexe op RSQL gebaseerde ETL-workflows te activeren.
U kunt ook een activeren E-mail notificatie door Amazon eenvoudige meldingsservice (Amazon SNS) binnen de statusmachine om het operationele team op de hoogte te stellen van de voltooiingsstatus van het ETL-proces. Verder kunt u een gebeurtenisgestuurd ETL-orkestratieframework bereiken door EventBridge te gebruiken om de workflow-trigger-lambda-functie te starten.
Over de auteurs
 Akhil is Data Analytics Consultant bij AWS Professional Services. Hij helpt klanten bij het ontwerpen en bouwen van schaalbare data-analyseoplossingen en het migreren van datapijplijnen en datawarehouses naar AWS. In zijn vrije tijd houdt hij van reizen, spelletjes spelen en films kijken.
Akhil is Data Analytics Consultant bij AWS Professional Services. Hij helpt klanten bij het ontwerpen en bouwen van schaalbare data-analyseoplossingen en het migreren van datapijplijnen en datawarehouses naar AWS. In zijn vrije tijd houdt hij van reizen, spelletjes spelen en films kijken.

Ramesh Raghupatie is Senior Data Architect bij WWCO ProServe bij AWS. Hij werkt samen met AWS-klanten om datawarehouses en datameren op de AWS Cloud te ontwerpen, implementeren en migreren naar datawarehouses. Hoewel hij niet aan het werk is, houdt Ramesh van reizen, tijd doorbrengen met familie en yoga.
 Raza Hafez is een Senior Data Architect binnen de Shared Delivery Practice van AWS Professional Services. Hij heeft meer dan 12 jaar professionele ervaring met het bouwen en optimaliseren van enterprise datawarehouses en is gepassioneerd om klanten in staat te stellen de kracht van hun data te realiseren. Hij is gespecialiseerd in het migreren van enterprise datawarehouses naar AWS Modern Data Architecture.
Raza Hafez is een Senior Data Architect binnen de Shared Delivery Practice van AWS Professional Services. Hij heeft meer dan 12 jaar professionele ervaring met het bouwen en optimaliseren van enterprise datawarehouses en is gepassioneerd om klanten in staat te stellen de kracht van hun data te realiseren. Hij is gespecialiseerd in het migreren van enterprise datawarehouses naar AWS Modern Data Architecture.
 Dipal Mahajan is een Lead Consultant bij Amazon Web Services, gevestigd in India, waar hij wereldwijde klanten begeleidt bij het bouwen van zeer veilige, schaalbare, betrouwbare en kostenefficiënte applicaties in de cloud. Hij brengt uitgebreide ervaring mee op het gebied van softwareontwikkeling, architectuur en analyse uit sectoren als financiën, telecom, detailhandel en gezondheidszorg.
Dipal Mahajan is een Lead Consultant bij Amazon Web Services, gevestigd in India, waar hij wereldwijde klanten begeleidt bij het bouwen van zeer veilige, schaalbare, betrouwbare en kostenefficiënte applicaties in de cloud. Hij brengt uitgebreide ervaring mee op het gebied van softwareontwikkeling, architectuur en analyse uit sectoren als financiën, telecom, detailhandel en gezondheidszorg.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/generic-orchestration-framework-for-data-warehousing-workloads-using-amazon-redshift-rsql/

