Er is enorme vooruitgang geboekt op het gebied van gedistribueerd diep leren voor grote taalmodellen (LLM's), vooral na de release van ChatGPT in december 2022. LLM's blijven in omvang groeien met miljarden of zelfs biljoenen parameters, en dat zal vaak niet gebeuren. passen in een enkel versnellerapparaat zoals GPU of zelfs een enkel knooppunt zoals ml.p5.32xlarge vanwege geheugenbeperkingen. Klanten die LLM's trainen, moeten hun werklast vaak over honderden of zelfs duizenden GPU's verdelen. Het mogelijk maken van training op een dergelijke schaal blijft een uitdaging bij gedistribueerde training, en efficiënt trainen in zo'n groot systeem is een ander even belangrijk probleem. De afgelopen jaren heeft de gedistribueerde trainingsgemeenschap 3D-parallellisme (data-parallellisme, pijplijn-parallellisme en tensor-parallellisme) en andere technieken (zoals sequentie-parallellisme en expert-parallellisme) geïntroduceerd om dergelijke uitdagingen aan te pakken.
In december 2023 kondigde Amazon de release aan van de SageMaker-model parallelle bibliotheek 2.0 (SMP), dat state-of-the-art efficiëntie bereikt bij het trainen van grote modellen, samen met de SageMaker gedistribueerde data-parallellismebibliotheek (SMDDP). Deze release is een belangrijke update van 1.x: SMP is nu geïntegreerd met open source PyTorch Volledig gedeelde gegevens parallel (FSDP) API's, waarmee u een vertrouwde interface kunt gebruiken bij het trainen van grote modellen, en die compatibel zijn met Transformator motor (TE), waarbij voor het eerst tensor-parallellismetechnieken naast FSDP worden ontsloten. Voor meer informatie over de release, zie De parallelle bibliotheek van het Amazon SageMaker-model versnelt nu de PyTorch FSDP-workloads met maximaal 20%.
In dit bericht onderzoeken we de prestatievoordelen van Amazon Sage Maker (inclusief SMP en SMDDP), en hoe u de bibliotheek kunt gebruiken om grote modellen efficiënt te trainen op SageMaker. We demonstreren de prestaties van SageMaker met benchmarks op ml.p4d.24xlarge clusters tot 128 exemplaren, en FSDP gemengde precisie met bfloat16 voor het Llama 2-model. We beginnen met een demonstratie van bijna-lineaire schaalefficiëntie voor SageMaker, gevolgd door het analyseren van de bijdragen van elke functie voor een optimale doorvoer, en eindigen met een efficiënte training met verschillende reekslengtes tot 32,768 via tensorparallellisme.
Bijna-lineaire schaling met SageMaker
Om de algehele trainingstijd voor LLM-modellen te verkorten, is het behouden van een hoge doorvoer bij het schalen naar grote clusters (duizenden GPU's) van cruciaal belang gezien de communicatieoverhead tussen de knooppunten. In dit bericht demonstreren we robuuste en bijna lineaire schalingsefficiënties (door het aantal GPU's te variëren voor een vaste totale probleemgrootte) op p4d-instances die zowel SMP als SMDDP aanroepen.
In deze sectie demonstreren we de bijna lineaire schaalprestaties van SMP. Hier trainen we Llama 2-modellen van verschillende groottes (7B-, 13B- en 70B-parameters) met behulp van een vaste sequentielengte van 4,096, de SMDDP-backend voor collectieve communicatie, TE ingeschakeld, een wereldwijde batchgrootte van 4 miljoen, met 16 tot 128 p4d-knooppunten . De volgende tabel geeft een overzicht van onze optimale configuratie- en trainingsprestaties (model TFLOP's per seconde).
| Model maat | Aantal knooppunten | TFLOP's* | sdp* | tp* | ontladen* | Efficiëntie op schaal |
| 7B | 16 | 136.76 | 32 | 1 | N | 100.0% |
| 32 | 132.65 | 64 | 1 | N | 97.0% | |
| 64 | 125.31 | 64 | 1 | N | 91.6% | |
| 128 | 115.01 | 64 | 1 | N | 84.1% | |
| 13B | 16 | 141.43 | 32 | 1 | Y | 100.0% |
| 32 | 139.46 | 256 | 1 | N | 98.6% | |
| 64 | 132.17 | 128 | 1 | N | 93.5% | |
| 128 | 120.75 | 128 | 1 | N | 85.4% | |
| 70B | 32 | 154.33 | 256 | 1 | Y | 100.0% |
| 64 | 149.60 | 256 | 1 | N | 96.9% | |
| 128 | 136.52 | 64 | 2 | N | 88.5% |
*Bij de gegeven modelgrootte, sequentielengte en aantal knooppunten tonen we de globaal optimale doorvoer en configuraties na het verkennen van verschillende sdp-, tp- en activatie-offloading-combinaties.
De voorgaande tabel geeft een overzicht van de optimale doorvoercijfers, afhankelijk van de mate van sharded data parallel (sdp) (doorgaans met behulp van FSDP hybride sharding in plaats van volledige sharding, met meer details in de volgende sectie), tensor parallel (tp) graad en veranderingen in de activatie-offloading-waarde. het demonstreren van een bijna lineaire schaling voor SMP samen met SMDDP. Gegeven bijvoorbeeld de Llama 2-modelgrootte 7B en reekslengte 4,096, bereikt het in totaal schaalefficiënties van 97.0%, 91.6% en 84.1% (ten opzichte van 16 knooppunten) op respectievelijk 32, 64 en 128 knooppunten. De schaalefficiëntie is stabiel bij verschillende modelgroottes en neemt iets toe naarmate de modelgrootte groter wordt.
SMP en SMDDP demonstreren ook vergelijkbare schaalefficiënties voor andere sequentielengtes zoals 2,048 en 8,192.
SageMaker-model parallelle bibliotheek 2.0-prestaties: Llama 2 70B
De modelgroottes zijn de afgelopen jaren blijven groeien, samen met frequente state-of-the-art prestatie-updates in de LLM-gemeenschap. In deze sectie illustreren we de prestaties in SageMaker voor het Llama 2-model met behulp van een vaste modelgrootte 70B, sequentielengte van 4,096 en een globale batchgrootte van 4 miljoen. Om te vergelijken met de globaal optimale configuratie en doorvoer van de vorige tabel (met SMDDP-backend, doorgaans FSDP hybride sharding en TE), breidt de volgende tabel zich uit naar andere optimale doorvoer (mogelijk met tensor-parallellisme) met extra specificaties voor de gedistribueerde backend (NCCL en SMDDP) , FSDP-shardingstrategieën (volledige sharding en hybride sharding), en TE wel of niet inschakelen (standaard).
| Model maat | Aantal knooppunten | TFLOPS | TFLOPs #3-configuratie | TFLOP's verbeteren ten opzichte van de basislijn | ||||||||
| . | . | NCCL volledige sharding: #0 | SMDDP volledige sharding: #1 | SMDDP hybride sharding: #2 | SMDDP hybride sharding met TE: #3 | sdp* | tp* | ontladen* | #0 → #1 | #1 → #2 | #2 → #3 | #0 → #3 |
| 70B | 32 | 150.82 | 149.90 | 150.05 | 154.33 | 256 | 1 | Y | -0.6% | 0.1% | 2.9% | 2.3% |
| 64 | 144.38 | 144.38 | 145.42 | 149.60 | 256 | 1 | N | 0.0% | 0.7% | 2.9% | 3.6% | |
| 128 | 68.53 | 103.06 | 130.66 | 136.52 | 64 | 2 | N | 50.4% | 26.8% | 4.5% | 99.2% | |
*Bij de gegeven modelgrootte, sequentielengte en aantal knooppunten tonen we de globaal optimale doorvoer en configuratie na het verkennen van verschillende sdp-, tp- en activatie-offloading-combinaties.
De nieuwste release van SMP en SMDDP ondersteunt meerdere functies, waaronder native PyTorch FSDP, uitgebreide en flexibelere hybride sharding, transformatormotorintegratie, tensor-parallellisme en geoptimaliseerde collectieve werking. Om beter te begrijpen hoe SageMaker efficiënte gedistribueerde training voor LLM's bereikt, onderzoeken we de incrementele bijdragen van SMDDP en het volgende SMP kernfuncties:
- SMDDP-verbetering ten opzichte van NCCL met volledige FSDP-sharding
- Vervanging van volledige FSDP-sharding door hybride sharding, waardoor de communicatiekosten worden verlaagd om de doorvoer te verbeteren
- Een verdere verhoging van de doorvoer met TE, zelfs als tensorparallellisme is uitgeschakeld
- Bij lagere resource-instellingen kan activatie-offloading mogelijk training mogelijk maken die anders onhaalbaar of erg traag zou zijn vanwege de hoge geheugendruk
FSDP volledige sharding: SMDDP-verbetering via NCCL
Zoals u in de vorige tabel kunt zien, is er, wanneer de modellen volledig zijn geshard met FSDP, hoewel de doorvoercapaciteiten van NCCL (TFLOPs #0) en SMDDP (TFLOPs #1) vergelijkbaar zijn bij 32 of 64 knooppunten, een enorme verbetering van 50.4% ten opzichte van NCCL naar SMDDP op 128 knooppunten.
Bij kleinere modelgroottes zien we consistente en significante verbeteringen met SMDDP ten opzichte van NCCL, beginnend bij kleinere clustergroottes, omdat SMDDP het communicatieknelpunt effectief kan verzachten.
FSDP hybride sharding om de communicatiekosten te verlagen
In SMP 1.0 zijn we van start gegaan gesharde gegevens parallellisme, een gedistribueerde trainingstechniek, mogelijk gemaakt door Amazon in eigen beheer Microfoons technologie. In SMP 2.0 introduceren we SMP hybride sharding, een uitbreidbare en flexibelere hybride shardingtechniek waarmee modellen kunnen worden geshard over een subset van GPU's, in plaats van alle trainings-GPU's, wat het geval is voor volledige FSDP-sharding. Het is handig voor middelgrote modellen die niet over het hele cluster hoeven te worden verdeeld om te voldoen aan de geheugenbeperkingen per GPU. Dit leidt ertoe dat clusters meer dan één modelreplica hebben en dat elke GPU tijdens runtime met minder peers communiceert.
De hybride sharding van SMP maakt efficiënte model-sharding over een groter bereik mogelijk, van de kleinste shard-graad zonder problemen met onvoldoende geheugen tot de hele clustergrootte (wat neerkomt op volledige sharding).
De volgende afbeelding illustreert voor de eenvoud de doorvoerafhankelijkheid van sdp bij tp = 1. Hoewel dit niet noodzakelijkerwijs hetzelfde is als de optimale tp-waarde voor volledige sharding van NCCL of SMDDP in de vorige tabel, liggen de cijfers redelijk dicht bij elkaar. Het valideert duidelijk de waarde van het overschakelen van volledige sharding naar hybride sharding bij een grote clustergrootte van 128 knooppunten, wat van toepassing is op zowel NCCL als SMDDP. Voor kleinere modelgroottes beginnen aanzienlijke verbeteringen met hybride sharding bij kleinere clustergroottes, en het verschil blijft toenemen met de clustergrootte.
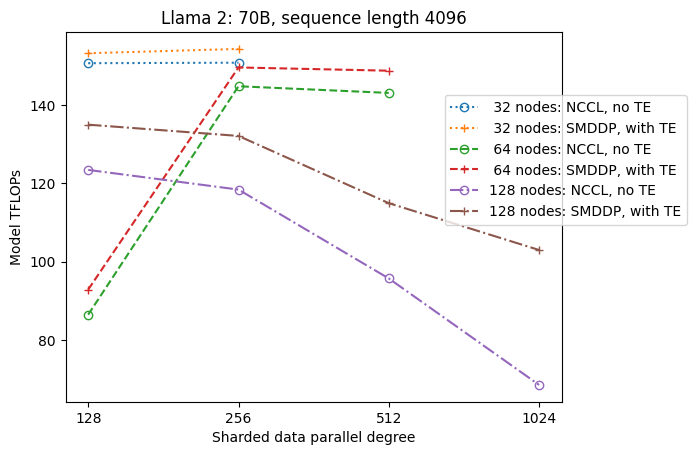
Verbeteringen met TE
TE is ontworpen om LLM-training op NVIDIA GPU's te versnellen. Ondanks dat we FP8 niet gebruiken omdat het niet wordt ondersteund op p4d-instanties, zien we nog steeds een aanzienlijke versnelling met TE op p4d.
Naast MiCS die is getraind met de SMDDP-backend, introduceert TE een consistente boost voor de doorvoer over alle clustergroottes (de enige uitzondering is volledige sharding op 128 knooppunten), zelfs wanneer tensor-parallellisme is uitgeschakeld (tensor-parallelle graad is 1).
Voor kleinere modelgroottes of verschillende reekslengtes is de TE-boost stabiel en niet triviaal, in het bereik van ongeveer 3–7.6%.
Activeringsoffloading bij lage resource-instellingen
Bij lage broninstellingen (bij een klein aantal knooppunten) kan FSDP een hoge geheugendruk ervaren (of zelfs onvoldoende geheugen in het ergste geval) wanneer activeringscontrolepunten zijn ingeschakeld. Voor dergelijke scenario's met een knelpunt in het geheugen is het inschakelen van activatie-offloading mogelijk een optie om de prestaties te verbeteren.
Zoals we eerder zagen, bereikt de Llama 2 met modelgrootte 13B en reekslengte 4,096 bijvoorbeeld de beste doorvoer met activatie-offloading wanneer deze beperkt is tot 32 knooppunten met ten minste 16 knooppunten met activeringscontrolepunten en zonder activatie-offloading. knooppunten.
Maak training met lange reeksen mogelijk: SMP-tensorparallellisme
Langere reekslengtes zijn gewenst voor lange gesprekken en context, en krijgen meer aandacht in de LLM-gemeenschap. Daarom rapporteren we in de volgende tabel verschillende doorvoersnelheden van lange reeksen. De tabel toont de optimale doorvoer voor Llama 2-training op SageMaker, met verschillende reekslengtes van 2,048 tot 32,768. Met een reekslengte van 32,768 is native FSDP-training niet haalbaar met 32 knooppunten bij een wereldwijde batchgrootte van 4 miljoen.
| . | . | . | TFLOPS | ||
| Model maat | Sequentielengte: | Aantal knooppunten | Native FSDP en NCCL | SMP en SMDDP | SMP-verbetering |
| 7B | 2048 | 32 | 129.25 | 138.17 | 6.9% |
| 4096 | 32 | 124.38 | 132.65 | 6.6% | |
| 8192 | 32 | 115.25 | 123.11 | 6.8% | |
| 16384 | 32 | 100.73 | 109.11 | 8.3% | |
| 32768 | 32 | NA | 82.87 | . | |
| 13B | 2048 | 32 | 137.75 | 144.28 | 4.7% |
| 4096 | 32 | 133.30 | 139.46 | 4.6% | |
| 8192 | 32 | 125.04 | 130.08 | 4.0% | |
| 16384 | 32 | 111.58 | 117.01 | 4.9% | |
| 32768 | 32 | NA | 92.38 | . | |
| *: max | . | . | . | . | 8.3% |
| *: mediaan | . | . | . | . | 5.8% |
Wanneer de clustergrootte groot is en een vaste globale batchgrootte heeft, kan sommige modeltraining onhaalbaar zijn met native PyTorch FSDP, omdat er geen ingebouwde pijplijn of tensor-parallellisme-ondersteuning is. In de voorgaande tabel is, gegeven een globale batchgrootte van 4 miljoen, 32 knooppunten en een sequentielengte van 32,768, de effectieve batchgrootte per GPU 0.5 (bijvoorbeeld tp = 2 met batchgrootte 1), wat anders onhaalbaar zou zijn zonder de introductie van tensor-parallellisme.
Conclusie
In dit bericht demonstreerden we efficiënte LLM-training met SMP en SMDDP op p4d-instanties, waarbij we bijdragen toeschreven aan meerdere belangrijke functies, zoals SMDDP-verbetering ten opzichte van NCCL, flexibele FSDP hybride sharding in plaats van volledige sharding, TE-integratie en het mogelijk maken van tensor-parallellisme ten gunste van lange reekslengtes. Na te zijn getest in een breed scala aan instellingen met verschillende modellen, modelgroottes en sequentielengtes, vertoont het een robuuste, bijna lineaire schaalefficiëntie, tot 128 p4d-instanties op SageMaker. Samenvattend blijft SageMaker een krachtig hulpmiddel voor LLM-onderzoekers en praktijkmensen.
Raadpleeg voor meer informatie: SageMaker-modelparallellismebibliotheek v2, of neem contact op met het SMP-team op sm-model-parallel-feedback@amazon.com.
Danksagung
We willen Robert Van Dusen, Ben Snyder, Gautam Kumar en Luis Quintela bedanken voor hun constructieve feedback en discussies.
Over de auteurs

Xinle Sheila Liu is een SDE in Amazon SageMaker. In haar vrije tijd houdt ze van lezen en buitensporten.
 Suhit Kodgule is een Software Development Engineer bij de AWS Artificial Intelligence-groep die werkt aan deep learning-frameworks. In zijn vrije tijd houdt hij van wandelen, reizen en koken.
Suhit Kodgule is een Software Development Engineer bij de AWS Artificial Intelligence-groep die werkt aan deep learning-frameworks. In zijn vrije tijd houdt hij van wandelen, reizen en koken.
 Victor Zhu is een software-ingenieur in gedistribueerd diep leren bij Amazon Web Services. Hij kan worden gevonden terwijl hij geniet van wandelen en bordspellen rond de SF Bay Area.
Victor Zhu is een software-ingenieur in gedistribueerd diep leren bij Amazon Web Services. Hij kan worden gevonden terwijl hij geniet van wandelen en bordspellen rond de SF Bay Area.
 Derya Cavdar werkt als software engineer bij AWS. Haar interesses omvatten deep learning en gedistribueerde trainingsoptimalisatie.
Derya Cavdar werkt als software engineer bij AWS. Haar interesses omvatten deep learning en gedistribueerde trainingsoptimalisatie.
 Teng Xu is een Software Development Engineer in de Distributed Training-groep in AWS AI. Hij houdt van lezen.
Teng Xu is een Software Development Engineer in de Distributed Training-groep in AWS AI. Hij houdt van lezen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/distributed-training-and-efficient-scaling-with-the-amazon-sagemaker-model-parallel-and-data-parallel-libraries/

