Dit bericht is geschreven in samenwerking met Andries Engelbrecht en Scott Teal van Snowflake.
Bedrijven evolueren voortdurend en dataleiders worden elke dag uitgedaagd om aan nieuwe eisen te voldoen. Voor veel ondernemingen en grote organisaties is het niet haalbaar om één verwerkingsengine of tool te hebben om aan de verschillende zakelijke vereisten te voldoen. Ze begrijpen dat een one-size-fits-all aanpak niet langer werkt, en erkennen de waarde van het adopteren van schaalbare, flexibele tools en open dataformaten om de interoperabiliteit in een moderne data-architectuur te ondersteunen en zo de levering van nieuwe oplossingen te versnellen.
Klanten gebruiken AWS en Snowflake om speciaal gebouwde data-architecturen te ontwikkelen die de prestaties leveren die nodig zijn voor moderne analytics en kunstmatige intelligentie (AI) use cases. Het implementeren van deze oplossingen vereist het delen van gegevens tussen speciaal gebouwde datastores. Dit is de reden waarom Snowflake en AWS verbeterde ondersteuning bieden voor Apache Iceberg om data-interoperabiliteit tussen dataservices mogelijk te maken en te vergemakkelijken.
Apache Iceberg is een open-source tabelformaat dat betrouwbaarheid, eenvoud en hoge prestaties biedt voor grote datasets met transactionele integriteit tussen verschillende verwerkingsengines. In dit bericht bespreken we het volgende:
- Voordelen van ijsbergtabellen voor datameren
- Twee architecturale patronen voor het delen van ijsbergtabellen tussen AWS en Snowflake:
- Beheer uw ijsbergtafels met AWS lijm Gegevenscatalogus
- Beheer uw ijsbergtafels met Snowflake
- Het proces waarbij bestaande data lakes-tabellen worden geconverteerd naar Iceberg-tabellen zonder de gegevens te kopiëren
Nu u een goed begrip van de onderwerpen heeft, gaan we ze allemaal in detail bekijken.
Voordelen van Apache-ijsberg
Apache Iceberg is een gedistribueerd, door de gemeenschap aangestuurd, door Apache 2.0 gelicentieerd, 100% open-source datatabelformaat dat de gegevensverwerking helpt vereenvoudigen op grote datasets die zijn opgeslagen in datameren. Data-ingenieurs gebruiken Apache Iceberg omdat het op elke schaal snel, efficiënt en betrouwbaar is en bijhoudt hoe datasets in de loop van de tijd veranderen. Apache Iceberg biedt integraties met populaire raamwerken voor gegevensverwerking, zoals Apache Spark, Apache Flink, Apache Hive, Presto en meer.
IJsbergtabellen houden metagegevens bij om grote verzamelingen bestanden samen te vatten en bieden functies voor gegevensbeheer, waaronder tijdreizen, terugdraaien, gegevensverdichting en volledige schema-evolutie, waardoor de beheeroverhead wordt verminderd. Oorspronkelijk ontwikkeld bij Netflix voordat het open source werd voor de Apache Software Foundation, was Apache Iceberg een blanco ontwerp om veelvoorkomende data lake-uitdagingen op te lossen, zoals gebruikerservaring, betrouwbaarheid en prestaties, en wordt nu ondersteund door een robuuste gemeenschap van ontwikkelaars die zich richten op het voortdurend verbeteren en toevoegen van nieuwe functies aan het project, om aan de echte gebruikersbehoeften te voldoen en hen optionele mogelijkheden te bieden.
Transactionele datameren gebouwd op AWS en Snowflake
Snowflake biedt verschillende integraties voor Iceberg-tafels met meerdere opbergmogelijkheden, waaronder Amazon S3en meerdere catalogusopties, waaronder AWS-lijmgegevenscatalogus en Sneeuwvlok. AWS biedt integraties voor verschillende AWS-diensten ook met Iceberg-tabellen, inclusief AWS Glue Data Catalog voor het bijhouden van tabelmetagegevens. Door Snowflake en AWS te combineren, beschikt u over meerdere opties om een transactioneel datameer uit te bouwen voor analytische en andere gebruiksscenario's, zoals het delen van gegevens en samenwerking. Door een metadatalaag aan datameren toe te voegen, krijgt u een betere gebruikerservaring, vereenvoudigd beheer en verbeterde prestaties en betrouwbaarheid op zeer grote datasets.
Beheer uw ijsbergtafel met AWS Glue
U kunt AWS Glue gebruiken om de gegevens op te nemen, te catalogiseren, te transformeren en te beheren Amazon eenvoudige opslagservice (Amazone S3). AWS Glue is een serverloze data-integratieservice waarmee u extractie-, transformatie- en laadpijplijnen (ETL) visueel kunt maken, uitvoeren en monitoren om gegevens in Iceberg-formaat in uw datameren te laden. Met AWS Glue kunt u meer dan 70 verschillende gegevensbronnen ontdekken en er verbinding mee maken, en uw gegevens beheren in een gecentraliseerde gegevenscatalogus. Snowflake kan worden geïntegreerd met AWS Glue Data Catalog om toegang te krijgen tot de Iceberg-tabelcatalogus en de bestanden op Amazon S3 voor analytische vragen. Dit verbetert de prestaties en computerkosten aanzienlijk in vergelijking met externe tabellen op Snowflake, omdat de aanvullende metagegevens het snoeien in queryplannen verbeteren.
U kunt dezelfde integratie gebruiken om te profiteren van de mogelijkheden voor het delen en samenwerken van gegevens in Snowflake. Dit kan erg krachtig zijn als je gegevens in Amazon S3 hebt en het delen van Snowflake-gegevens met andere bedrijfseenheden, partners, leveranciers of klanten moet inschakelen.
Het volgende architectuurdiagram biedt een overzicht op hoog niveau van dit patroon.
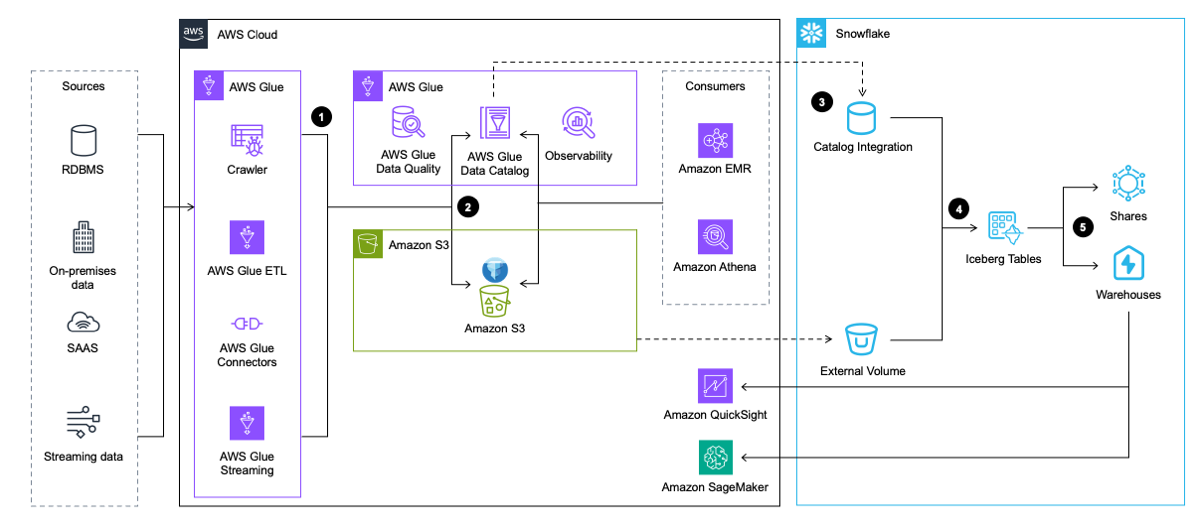
De workflow omvat de volgende stappen:
- AWS Glue haalt gegevens uit applicaties, databases en streamingbronnen. AWS Glue transformeert het vervolgens en laadt het in het datameer in Amazon S3 in Iceberg-tabelformaat, terwijl de metadata over de Iceberg-tabel in de AWS Glue Data Catalog wordt ingevoegd en bijgewerkt.
- De AWS Glue-crawler genereert en werkt metadata van Iceberg-tabellen bij en slaat deze op in AWS Glue Data Catalog voor bestaande Iceberg-tabellen op een S3-datameer.
- Snowflake kan worden geïntegreerd met AWS Glue Data Catalog om de momentopnamelocatie op te halen.
- In het geval van een zoekopdracht gebruikt Snowflake de snapshotlocatie van AWS Glue Data Catalog om Iceberg-tabelgegevens in Amazon S3 te lezen.
- Snowflake kan query's uitvoeren in de tabelindelingen Iceberg en Snowflake. Jij kan gegevens delen voor samenwerking met een of meer accounts in dezelfde Snowflake-regio. Je kunt data in Snowflake ook gebruiken voor visualisatie gebruik Amazon QuickSight, of gebruik het voor machine learning (ML) en kunstmatige intelligentie (AI) doeleinden Met Amazon Sage Maker.
Beheer uw ijsbergtafel met Sneeuwvlok
Een tweede patroon biedt ook interoperabiliteit tussen AWS en Snowflake, maar implementeert data-engineering-pijplijnen voor opname en transformatie naar Snowflake. In dit patroon worden gegevens door Snowflake in Iceberg-tabellen geladen via integraties met AWS-services zoals AWS Glue of via andere bronnen zoals Snowpipe. Snowflake schrijft vervolgens gegevens rechtstreeks naar Amazon S3 in Iceberg-formaat voor downstream-toegang door Snowflake en verschillende AWS-services, en Snowflake beheert de Iceberg-catalogus die snapshotlocaties in tabellen bijhoudt waartoe AWS-services toegang hebben.
Net als het vorige patroon kunt u door Snowflake beheerde Iceberg-tabellen gebruiken met het delen van Snowflake-gegevens, maar u kunt S3 ook gebruiken om datasets te delen in gevallen waarin een partij geen toegang heeft tot Snowflake.
Het volgende architectuurdiagram biedt een overzicht van dit patroon met door Snowflake beheerde Iceberg-tabellen.
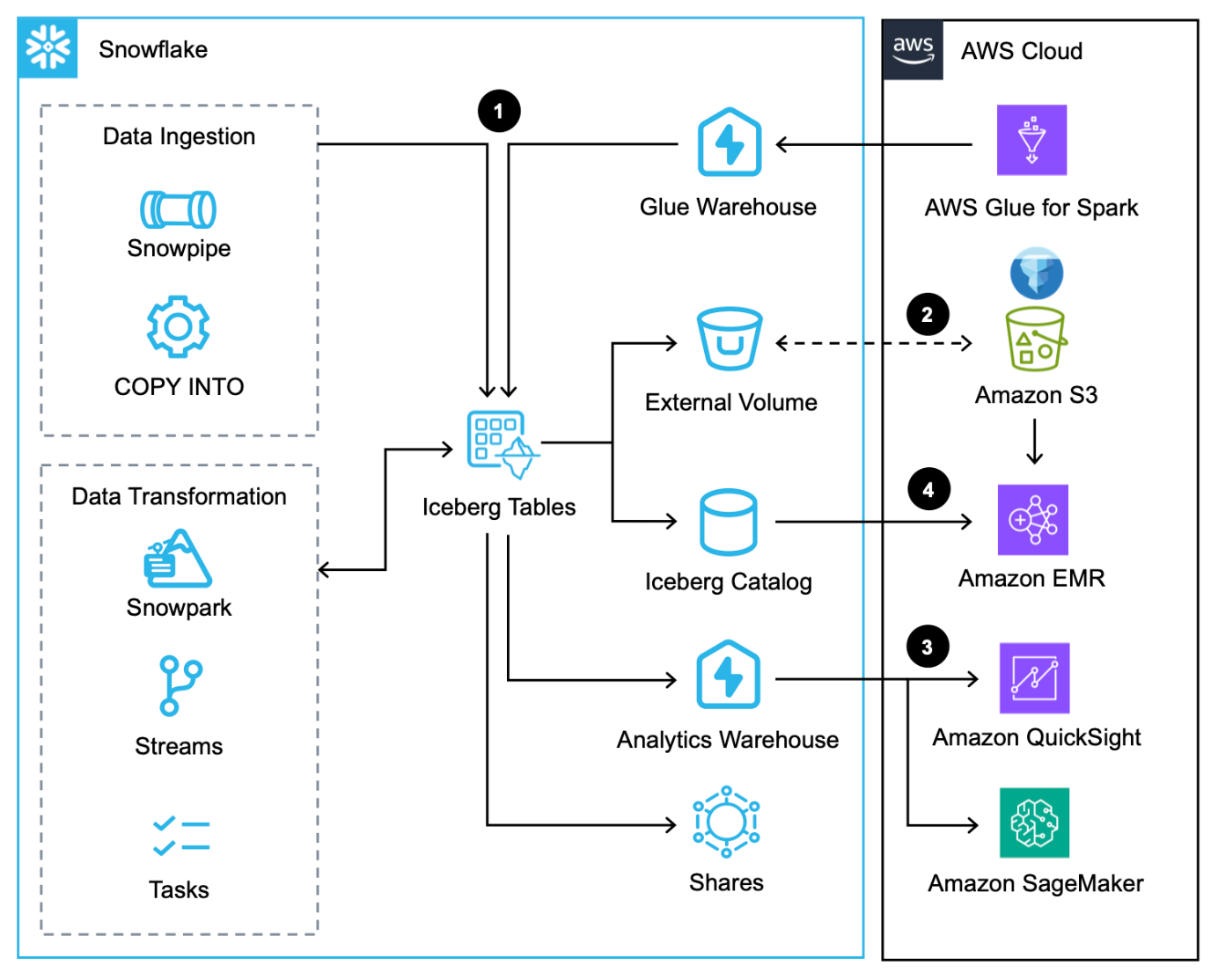
Deze workflow bestaat uit de volgende stappen:
- Naast het laden van gegevens via de COPY commando, Sneeuwpijp en de native Snowflake-connector voor AWS Glue, kun je gegevens integreren via de Snowflake Het delen van gegevens.
- Snowflake schrijft ijsbergtabellen naar Amazon S3 en werkt de metadata automatisch bij bij elke transactie.
- IJsbergtabellen in Amazon S3 worden door Snowflake opgevraagd voor analytische en ML-workloads met behulp van services als QuickSight en SageMaker.
- Apache Spark-services op AWS kunnen dat wel toegang tot snapshotlocaties van Snowflake via een Snowflake Iceberg Catalog SDK en scan direct de Iceberg-tabelbestanden in Amazon S3.
Oplossingen vergelijken
Deze twee patronen benadrukken de opties die vandaag de dag beschikbaar zijn voor datapersona's om hun data-interoperabiliteit tussen Snowflake en AWS te maximaliseren met behulp van Apache Iceberg. Maar welk patroon is ideaal voor uw gebruikssituatie? Als u AWS Glue Data Catalog al gebruikt en Snowflake alleen nodig heeft voor leesquery's, dan kan het eerste patroon Snowflake integreren met AWS Glue en Amazon S3 om Iceberg-tabellen te doorzoeken. Als u AWS Glue Data Catalog nog niet gebruikt en Snowflake nodig heeft om lees- en schrijfbewerkingen uit te voeren, dan is het tweede patroon waarschijnlijk een goede oplossing waarmee u gegevens van AWS kunt opslaan en openen.
Aangezien lees- en schrijfbewerkingen waarschijnlijk per tabel zullen werken in plaats van voor de gehele gegevensarchitectuur, is het raadzaam een combinatie van beide patronen te gebruiken.
Migreer bestaande datameren naar een transactioneel datameer met Apache Iceberg
U kunt bestaande op Parquet, ORC en Avro gebaseerde data lake-tabellen op Amazon S3 converteren naar Iceberg-indeling om de voordelen van transactionele integriteit te benutten en tegelijkertijd de prestaties en gebruikerservaring te verbeteren. Er zijn verschillende opties voor migratie van ijsbergtabellen (MOMENTOPNAME, MIGREREN en BESTANDEN TOEVOEGEN) voor het migreren van bestaande data lake-tabellen naar het Iceberg-formaat, wat de voorkeur verdient boven het herschrijven van alle onderliggende gegevensbestanden – een kostbare en tijdrovende inspanning met grote datasets. In deze sectie concentreren we ons op ADD_FILES, omdat dit handig is voor aangepaste migraties.
Voor ADD_FILES-opties kunt u AWS Glue gebruiken om Iceberg-metagegevens en statistieken te genereren voor een bestaande data lake-tabel en nieuwe Iceberg-tabellen in AWS Glue Data Catalog te maken voor toekomstig gebruik zonder dat u de onderliggende gegevens hoeft te herschrijven. Voor instructies over het genereren van Iceberg-metagegevens en statistieken met behulp van AWS Glue, raadpleegt u Migreer een bestaand datameer naar een transactioneel datameer met Apache Iceberg or Converteer bestaande Amazon S3 data lake-tabellen naar Snowflake Unmanaged Iceberg-tabellen met AWS Glue.
Deze optie vereist dat u gegevenspijplijnen pauzeert tijdens het converteren van de bestanden naar Iceberg-tabellen, wat een eenvoudig proces is in AWS Glue omdat de bestemming alleen maar hoeft te worden gewijzigd in een Iceberg-tabel.
Conclusie
In dit bericht zag je de twee architectuurpatronen voor het implementeren van Apache Iceberg in een datameer voor betere interoperabiliteit tussen AWS en Snowflake. We hebben ook richtlijnen gegeven voor het migreren van bestaande data lake-tabellen naar het Iceberg-formaat.
MELD U AAN VOOR AWS Dev Day op 10 april om niet alleen aan de slag te gaan met Apache Iceberg, maar ook met het streamen van datapijplijnen Amazon Data-brandslang en Sneeuwpijpstreaming, en generatieve AI-toepassingen met Stroomverlicht in Sneeuwvlok en Amazonebodem.
Over de auteurs
 Andries Engelbrecht is Principal Partner Solutions Architect bij Snowflake en werkt samen met strategische partners. Hij is actief betrokken bij strategische partners zoals AWS die product- en service-integraties ondersteunen, evenals de ontwikkeling van gezamenlijke oplossingen met partners. Andries heeft meer dan 20 jaar ervaring op het gebied van data en analytics.
Andries Engelbrecht is Principal Partner Solutions Architect bij Snowflake en werkt samen met strategische partners. Hij is actief betrokken bij strategische partners zoals AWS die product- en service-integraties ondersteunen, evenals de ontwikkeling van gezamenlijke oplossingen met partners. Andries heeft meer dan 20 jaar ervaring op het gebied van data en analytics.
 Deenbandhu Prasad is een Senior Analytics Specialist bij AWS, gespecialiseerd in big data-diensten. Hij heeft een passie voor het helpen van klanten bij het bouwen van moderne data-architecturen op de AWS Cloud. Hij heeft klanten van elke omvang geholpen bij het implementeren van datamanagement-, datawarehouse- en data lake-oplossingen.
Deenbandhu Prasad is een Senior Analytics Specialist bij AWS, gespecialiseerd in big data-diensten. Hij heeft een passie voor het helpen van klanten bij het bouwen van moderne data-architecturen op de AWS Cloud. Hij heeft klanten van elke omvang geholpen bij het implementeren van datamanagement-, datawarehouse- en data lake-oplossingen.
 Brian Dolan trad in 2012 in dienst bij Amazon als Military Relations Manager na zijn eerste carrière als marinevlieger. In 2014 trad Brian in dienst bij Amazon Web Services, waar hij Canadese klanten, van startups tot ondernemingen, hielp bij het verkennen van de AWS Cloud. Meest recent was Brian lid van het Non-Relational Business Development-team als Go-To-Market Specialist voor Amazon DynamoDB en Amazon Keyspaces voordat hij in 2022 bij de Analytics Worldwide Specialist Organization kwam als Go-To-Market Specialist voor AWS Glue.
Brian Dolan trad in 2012 in dienst bij Amazon als Military Relations Manager na zijn eerste carrière als marinevlieger. In 2014 trad Brian in dienst bij Amazon Web Services, waar hij Canadese klanten, van startups tot ondernemingen, hielp bij het verkennen van de AWS Cloud. Meest recent was Brian lid van het Non-Relational Business Development-team als Go-To-Market Specialist voor Amazon DynamoDB en Amazon Keyspaces voordat hij in 2022 bij de Analytics Worldwide Specialist Organization kwam als Go-To-Market Specialist voor AWS Glue.
 Nidhi Gupta is een Sr. Partner Solution Architect bij AWS. Ze brengt haar dagen door met het werken met klanten en partners, en het oplossen van architectonische uitdagingen. Ze heeft een passie voor data-integratie en -orkestratie, serverloze en big data-verwerking, en machine learning. Nidhi heeft uitgebreide ervaring met het leiden van het architectuurontwerp en de productierelease en -implementaties voor dataworkloads.
Nidhi Gupta is een Sr. Partner Solution Architect bij AWS. Ze brengt haar dagen door met het werken met klanten en partners, en het oplossen van architectonische uitdagingen. Ze heeft een passie voor data-integratie en -orkestratie, serverloze en big data-verwerking, en machine learning. Nidhi heeft uitgebreide ervaring met het leiden van het architectuurontwerp en de productierelease en -implementaties voor dataworkloads.
 Scott Teal is Product Marketing Lead bij Snowflake en richt zich op datalakes, opslag en governance.
Scott Teal is Product Marketing Lead bij Snowflake en richt zich op datalakes, opslag en governance.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-your-data-lake-with-amazon-s3-aws-glue-and-snowflake/

