AWS-aangedreven datameren, ondersteund door de ongeëvenaarde beschikbaarheid van Amazon eenvoudige opslagservice (Amazon S3), kan omgaan met de schaal, wendbaarheid en flexibiliteit die nodig is om verschillende data- en analysebenaderingen te combineren. Naarmate de datameren groter zijn geworden en het gebruik ervan volwassener is geworden, kan er een aanzienlijke hoeveelheid inspanning worden besteed aan het consistent houden van de gegevens met zakelijke gebeurtenissen. Om ervoor te zorgen dat bestanden op een transactioneel consistente manier worden bijgewerkt, maakt een groeiend aantal klanten gebruik van open source transactionele tabelformaten zoals Apache-ijsberg, Apache Hudi en Linux Stichting Delta Lake die u helpen gegevens op te slaan met hoge compressiesnelheden, een native interface hebben met uw applicaties en frameworks, en incrementele gegevensverwerking vereenvoudigen in datameren die zijn gebouwd op Amazon S3. Deze formaten maken ACID-transacties (atomicity, consistentie, isolatie, duurzaamheid), upserts en verwijderingen mogelijk, en geavanceerde functies zoals tijdreizen en snapshots die voorheen alleen beschikbaar waren in datawarehouses. Elk opslagformaat implementeert deze functionaliteit op enigszins verschillende manieren; voor een vergelijking, zie Een open tafelformaat kiezen voor uw transactionele datameer op AWS.
In 2023, AWS heeft algemene beschikbaarheid aangekondigd voor Apache Iceberg, Apache Hudi en Linux Foundation Delta Lake in Amazon Athena voor Apache Spark, waardoor het niet meer nodig is om een afzonderlijke connector of bijbehorende afhankelijkheden te installeren en versies te beheren, en de configuratiestappen die nodig zijn om deze frameworks te gebruiken, worden vereenvoudigd.
In dit bericht laten we u zien hoe u Spark SQL gebruikt Amazone Athene notebooks en werk met de tabelformaten Iceberg, Hudi en Delta Lake. We demonstreren algemene bewerkingen zoals het maken van databases en tabellen, het invoegen van gegevens in de tabellen, het opvragen van gegevens en het bekijken van momentopnamen van de tabellen in Amazon S3 met behulp van Spark SQL in Athena.
Voorwaarden
Voltooi de volgende vereisten:
Download en importeer voorbeeldnotebooks van Amazon S3
Download de notitieboekjes die in dit bericht worden besproken vanaf de volgende locaties om mee te volgen:
Nadat u de notebooks hebt gedownload, importeert u ze in uw Athena Spark-omgeving door de volgende stappen te volgen: Een notitieblok importeren sectie in Notebookbestanden beheren.
Navigeer naar het specifieke gedeelte Open tafelindeling
Als u geïnteresseerd bent in het ijsbergtabelformaat, navigeer dan naar Werken met Apache Iceberg-tabellen pagina.
Als u geïnteresseerd bent in het Hudi-tabelformaat, navigeert u naar Werken met Apache Hudi-tabellen pagina.
Als u geïnteresseerd bent in het Delta Lake-tabelformaat, navigeert u naar Werken met Linux Foundation Delta Lake-tabellen pagina.
Werken met Apache Iceberg-tabellen
Wanneer u Spark-notebooks in Athena gebruikt, kunt u SQL-query's rechtstreeks uitvoeren zonder dat u PySpark hoeft te gebruiken. We doen dit door gebruik te maken van celmagie. Dit zijn speciale headers in een notebookcel die het gedrag van de cel veranderen. Voor SQL kunnen we de %%sql magic, die de volledige celinhoud interpreteert als een SQL-instructie die op Athena moet worden uitgevoerd.
In deze sectie laten we zien hoe u SQL op Apache Spark voor Athena kunt gebruiken om Apache Iceberg-tabellen te maken, analyseren en beheren.
Zet een notebooksessie op
Om Apache Iceberg in Athena te gebruiken tijdens het maken of bewerken van een sessie, selecteert u de Apache-ijsberg optie door het uit te breiden Apache Spark-eigenschappen sectie. Het zal de eigenschappen vooraf invullen, zoals weergegeven in de volgende schermafbeelding.
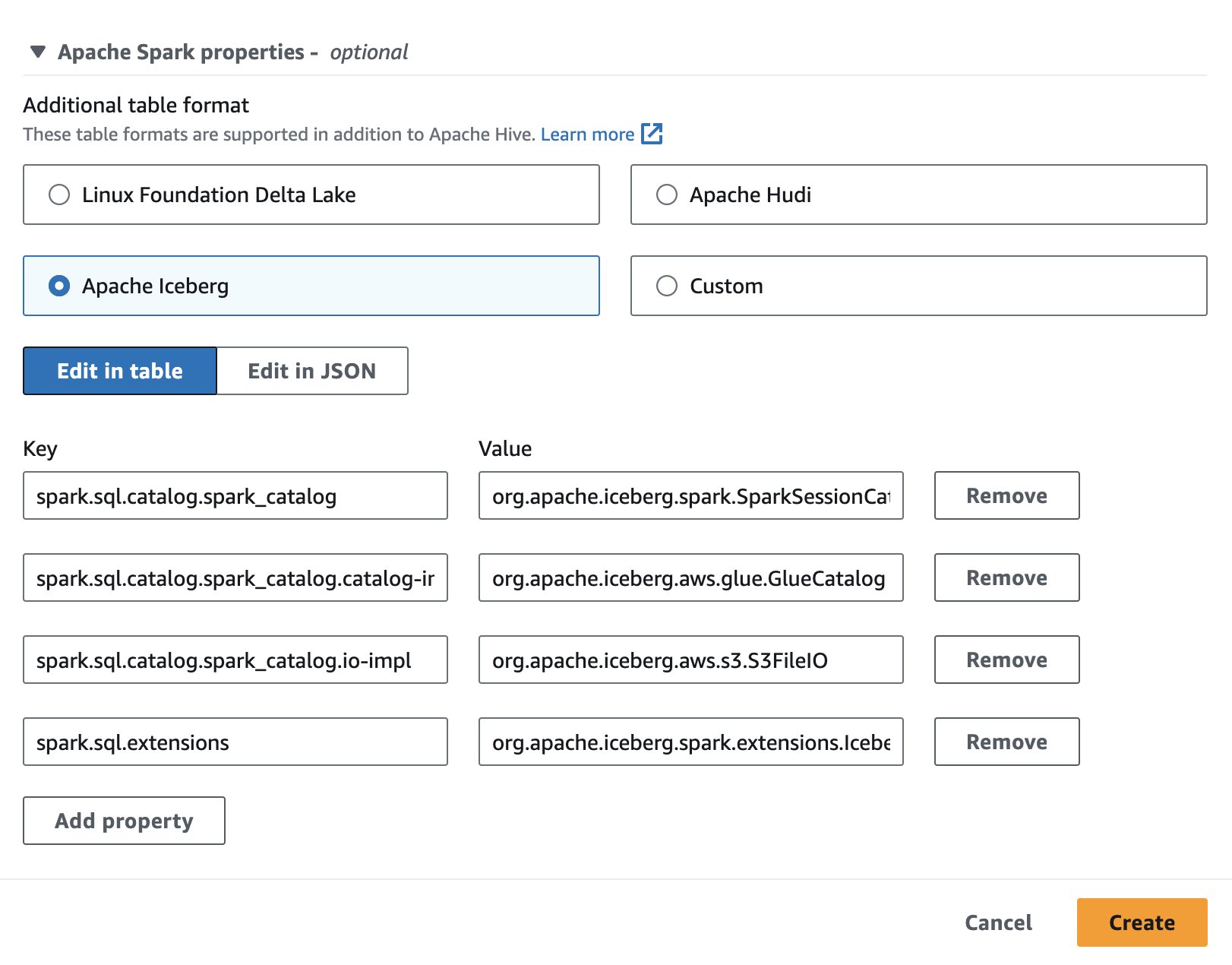
Voor stappen, zie Sessiedetails bewerken or Je eigen notitieboekje maken.
De code die in deze sectie wordt gebruikt, is beschikbaar in de SparkSQL_ijsberg.ipynb bestand om mee te volgen.
Maak een database en een ijsbergtabel
Eerst maken we een database aan in de AWS Glue Data Catalog. Met de volgende SQL kunnen we een database maken met de naam icebergdb:
Vervolgens in de database icebergdb, maken we een ijsbergtabel genaamd noaa_iceberg wijzend naar een locatie in Amazon S3 waar we de gegevens zullen laden. Voer de volgende instructie uit en vervang de locatie s3://<your-S3-bucket>/<prefix>/ met uw S3-bucket en voorvoegsel:
Voeg gegevens in de tabel in
Om de noaa_iceberg IJsbergtabel, we voegen gegevens uit de Parquet-tabel in sparkblogdb.noaa_pq dat is gemaakt als onderdeel van de vereisten. U kunt dit doen met behulp van een INVOEGEN verklaring in Spark:
Als alternatief kunt u gebruiken MAAK TABEL ALS SELECT met de USING iceberg-clausule om in één stap een Iceberg-tabel te maken en gegevens uit een brontabel in te voegen:
Vraag de ijsbergtabel op
Nu de gegevens in de ijsbergtabel zijn ingevoegd, kunnen we beginnen met het analyseren ervan. Laten we een Spark SQL uitvoeren om de minimaal geregistreerde temperatuur per jaar te vinden voor de 'SEATTLE TACOMA AIRPORT, WA US' locatie:
We krijgen de volgende uitvoer.

Gegevens in de ijsbergtabel bijwerken
Laten we eens kijken hoe we gegevens in onze tabel kunnen bijwerken. We willen de zendernaam bijwerken 'SEATTLE TACOMA AIRPORT, WA US' naar 'Sea-Tac'. Met Spark SQL kunnen we een UPDATE verklaring tegen de ijsbergtafel:
We kunnen vervolgens de vorige SELECT-query uitvoeren om de minimaal geregistreerde temperatuur voor de te vinden 'Sea-Tac' locatie:
We krijgen de volgende uitvoer.

Compacte gegevensbestanden
Open tabelformaten zoals Iceberg werken door deltawijzigingen in de bestandsopslag te creëren en de versies van rijen bij te houden via manifestbestanden. Meer gegevensbestanden leiden tot meer metagegevens die worden opgeslagen in manifestbestanden, en kleine gegevensbestanden veroorzaken vaak een onnodige hoeveelheid metagegevens, wat resulteert in minder efficiënte zoekopdrachten en hogere toegangskosten voor Amazon S3. IJsbergjes rennen rewrite_data_files De procedure in Spark voor Athena comprimeert gegevensbestanden, waarbij veel kleine deltawijzigingsbestanden worden gecombineerd tot een kleinere set voor lezen geoptimaliseerde Parquet-bestanden. Het comprimeren van bestanden versnelt de leesbewerking bij opvragen. Als u compactie op onze tabel wilt uitvoeren, voert u de volgende Spark SQL uit:
rewrite_data_files biedt opties om uw sorteerstrategie te specificeren, die kan helpen bij het reorganiseren en comprimeren van gegevens.
Maak een lijst van momentopnamen van tabellen
Elke schrijf-, update-, verwijder-, ups- en compactiebewerking op een Iceberg-tabel creëert een nieuwe momentopname van een tabel, terwijl de oude gegevens en metagegevens behouden blijven voor momentopname-isolatie en tijdreizen. Voer de volgende Spark SQL-instructie uit om de momentopnamen van een ijsbergtabel weer te geven:
Verlopen oude snapshots
Regelmatig verlopende snapshots wordt aanbevolen om gegevensbestanden te verwijderen die niet langer nodig zijn, en om de grootte van tabelmetagegevens klein te houden. Het zal nooit bestanden verwijderen die nog nodig zijn voor een niet-verlopen momentopname. Voer in Spark voor Athena de volgende SQL uit om momentopnamen voor de tabel te laten verlopen icebergdb.noaa_iceberg die ouder zijn dan een specifiek tijdstempel:
Houd er rekening mee dat de tijdstempelwaarde is opgegeven als een tekenreeks in de indeling yyyy-MM-dd HH:mm:ss.fff. De uitvoer geeft een telling van het aantal verwijderde gegevens- en metadatabestanden.
Laat de tabel en database vallen
U kunt de volgende Spark SQL uitvoeren om de Iceberg-tabellen en bijbehorende gegevens in Amazon S3 uit deze oefening op te schonen:
Voer de volgende Spark SQL uit om de database icebergdb te verwijderen:
Voor meer informatie over alle bewerkingen die u kunt uitvoeren op Iceberg-tabellen met Spark voor Athena, raadpleegt u Spark-query's en Vonkenprocedures in de Iceberg-documentatie.
Werken met Apache Hudi-tabellen
Vervolgens laten we zien hoe u SQL op Spark for Athena kunt gebruiken om Apache Hudi-tabellen te maken, analyseren en beheren.
Zet een notebooksessie op
Om Apache Hudi in Athena te gebruiken tijdens het maken of bewerken van een sessie, selecteert u de Apache Hudi optie door het uit te breiden Apache Spark-eigenschappen pagina.
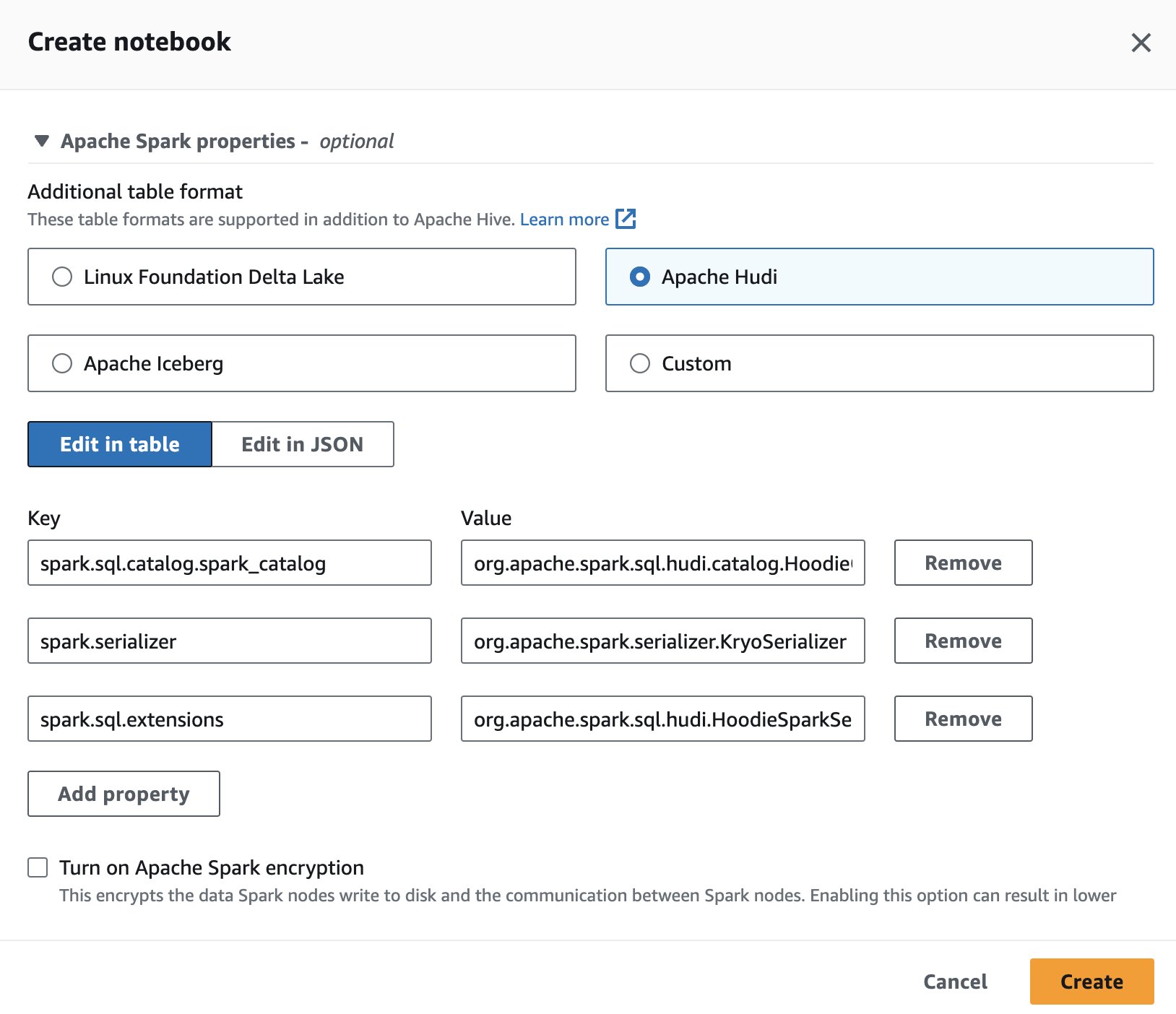
Voor stappen, zie Sessiedetails bewerken or Je eigen notitieboekje maken.
De code die in deze sectie wordt gebruikt, moet beschikbaar zijn in de SparkSQL_hudi.ipynb bestand om mee te volgen.
Maak een database en een Hudi-tabel
Eerst maken we een database genaamd hudidb die wordt opgeslagen in de AWS Glue Data Catalog, gevolgd door het maken van een Hudi-tabel:
We maken een Hudi-tabel die verwijst naar een locatie in Amazon S3 waar we de gegevens zullen laden. Merk op dat de tabel van is kopiëren-op-schrijven type. Het wordt gedefinieerd door type= 'cow' in de tabel DDL. We hebben station en datum gedefinieerd als de meerdere primaire sleutels en preCombinedField als jaar. Bovendien is de tabel op jaarbasis ingedeeld. Voer de volgende instructie uit en vervang de locatie s3://<your-S3-bucket>/<prefix>/ met uw S3-bucket en voorvoegsel:
Voeg gegevens in de tabel in
Net als bij Iceberg gebruiken we de INVOEGEN instructie om de tabel te vullen door gegevens uit de sparkblogdb.noaa_pq tabel gemaakt in het vorige bericht:
Vraag de Hudi-tabel op
Nu de tabel is gemaakt, gaan we een query uitvoeren om de maximaal geregistreerde temperatuur voor de te vinden 'SEATTLE TACOMA AIRPORT, WA US' locatie:
Update gegevens in de Hudi-tabel
Laten we de zendernaam veranderen 'SEATTLE TACOMA AIRPORT, WA US' naar 'Sea–Tac'. We kunnen een UPDATE-instructie uitvoeren op Spark voor Athena -update de archieven van de noaa_hudi tafel:
We voeren de vorige SELECT-query uit om de maximaal geregistreerde temperatuur voor de te vinden 'Sea-Tac' locatie:
Voer tijdreisquery's uit
We kunnen tijdreisquery's in SQL op Athena gebruiken om momentopnamen van gegevens uit het verleden te analyseren. Bijvoorbeeld:
Met deze zoekopdracht worden de temperatuurgegevens van Seattle Airport van een specifiek tijdstip in het verleden gecontroleerd. Met de tijdstempelclausule kunnen we terugreizen zonder de huidige gegevens te wijzigen. Houd er rekening mee dat de tijdstempelwaarde is opgegeven als een tekenreeks in de indeling yyyy-MM-dd HH:mm:ss.fff.
Optimaliseer de querysnelheid met clustering
Om de queryprestaties te verbeteren, kunt u uitvoeren clustering op Hudi-tabellen met behulp van SQL in Spark voor Athena:
Compacte tafels
Compaction is een tabelservice die door Hudi specifiek wordt gebruikt in Merge On Read (MOR)-tabellen om periodiek updates van op rijen gebaseerde logbestanden samen te voegen met het overeenkomstige op kolommen gebaseerde basisbestand om een nieuwe versie van het basisbestand te produceren. Compactie is niet van toepassing op COW-tabellen (Copy On Write) en alleen op MOR-tabellen. U kunt de volgende query uitvoeren in Spark for Athena om compactie uit te voeren op MOR-tabellen:
Laat de tabel en database vallen
Voer de volgende Spark SQL uit om de Hudi-tabel die u hebt gemaakt en de bijbehorende gegevens van de Amazon S3-locatie te verwijderen:
Voer de volgende Spark SQL uit om de database te verwijderen hudidb:
Voor meer informatie over alle bewerkingen die u kunt uitvoeren op Hudi-tabellen met Spark voor Athena, raadpleegt u SQL-DDL en procedures in de Hudi-documentatie.
Werken met Linux Foundation Delta Lake-tabellen
Vervolgens laten we zien hoe u SQL op Spark for Athena kunt gebruiken om Delta Lake-tabellen te maken, analyseren en beheren.
Zet een notebooksessie op
Als u Delta Lake in Spark for Athena wilt gebruiken tijdens het maken of bewerken van een sessie, selecteert u Linux Stichting Delta Lake door het uitbreiden van de Apache Spark-eigenschappen pagina.

Voor stappen, zie Sessiedetails bewerken or Je eigen notitieboekje maken.
De code die in deze sectie wordt gebruikt, moet beschikbaar zijn in de SparkSQL_delta.ipynb bestand om mee te volgen.
Maak een database en een Delta Lake-tabel
In deze sectie maken we een database in de AWS Glue Data Catalog. Met behulp van de volgende SQL kunnen we een database maken met de naam deltalakedb:
Vervolgens in de database deltalakedb, maken we een Delta Lake-tabel met de naam noaa_delta wijzend naar een locatie in Amazon S3 waar we de gegevens zullen laden. Voer de volgende instructie uit en vervang de locatie s3://<your-S3-bucket>/<prefix>/ met uw S3-bucket en voorvoegsel:
Voeg gegevens in de tabel in
We gebruiken een INVOEGEN instructie om de tabel te vullen door gegevens uit de sparkblogdb.noaa_pq tabel gemaakt in het vorige bericht:
U kunt ook CREATE TABLE AS SELECT gebruiken om een Delta Lake-tabel te maken en gegevens uit een brontabel in één query in te voegen.
Vraag de Delta Lake-tabel op
Nu de gegevens in de Delta Lake-tabel zijn ingevoegd, kunnen we beginnen met het analyseren ervan. Laten we een Spark SQL uitvoeren om de minimaal geregistreerde temperatuur voor de 'SEATTLE TACOMA AIRPORT, WA US' locatie:
Update gegevens in de Deltamerentabel
Laten we de zendernaam veranderen 'SEATTLE TACOMA AIRPORT, WA US' naar 'Sea–Tac'. Wij kunnen een UPDATE verklaring over Spark voor Athena om de gegevens van de bij te werken noaa_delta tafel:
We kunnen de vorige SELECT-query uitvoeren om de minimaal geregistreerde temperatuur voor de te vinden 'Sea-Tac' locatie, en het resultaat zou hetzelfde moeten zijn als eerder:
Compacte gegevensbestanden
In Spark voor Athena kunt u OPTIMIZE uitvoeren op de Delta Lake-tabel, waardoor de kleine bestanden worden gecomprimeerd tot grotere bestanden, zodat de query's niet worden belast door de overhead van kleine bestanden. Voer de volgende query uit om de verdichtingsbewerking uit te voeren:
Verwijzen naar Optimalisaties in de Delta Lake-documentatie voor verschillende opties die beschikbaar zijn tijdens het uitvoeren van OPTIMIZE.
Verwijder bestanden waarnaar niet meer wordt verwezen door een Delta Lake-tabel
U kunt bestanden verwijderen die zijn opgeslagen in Amazon S3 en waarnaar niet meer wordt verwezen door een Delta Lake-tabel en die ouder zijn dan de bewaardrempel, door de opdracht VACCUM op de tabel uit te voeren met Spark voor Athena:
Verwijzen naar Verwijder bestanden waarnaar niet langer wordt verwezen door een Delta-tabel in de Delta Lake-documentatie voor opties die beschikbaar zijn met VACUUM.
Laat de tabel en database vallen
Voer de volgende Spark SQL uit om de Delta Lake-tabel te verwijderen die u hebt gemaakt:
Voer de volgende Spark SQL uit om de database te verwijderen deltalakedb:
Als u DROP TABLE DDL uitvoert op de Delta Lake-tabel en -database, worden de metagegevens voor deze objecten verwijderd, maar worden de gegevensbestanden in Amazon S3 niet automatisch verwijderd. U kunt de volgende Python-code in de cel van het notebook uitvoeren om de gegevens van de S3-locatie te verwijderen:
Voor meer informatie over de SQL-instructies die u kunt uitvoeren op een Delta Lake-tabel met behulp van Spark voor Athena, raadpleegt u de quickstart in de Delta Lake-documentatie.
Conclusie
In dit bericht werd gedemonstreerd hoe u Spark SQL in Athena-notebooks kunt gebruiken om databases en tabellen te maken, gegevens in te voegen en op te vragen, en algemene bewerkingen uit te voeren, zoals updates, compacties en tijdreizen op Hudi-, Delta Lake- en Iceberg-tabellen. Open tabelformaten voegen ACID-transacties, upserts en verwijderingen toe aan datameren, waardoor de beperkingen van de opslag van onbewerkte objecten worden overwonnen. Door de noodzaak weg te nemen om afzonderlijke connectoren te installeren, vermindert de ingebouwde integratie van Spark on Athena configuratiestappen en beheeroverhead bij het gebruik van deze populaire raamwerken voor het bouwen van betrouwbare datameren op Amazon S3. Voor meer informatie over het selecteren van een open tabelindeling voor uw data lake-workloads raadpleegt u Een open tafelformaat kiezen voor uw transactionele datameer op AWS.
Over de auteurs
![]() Pathik Sjah is een Sr. Analytics Architect bij Amazon Athena. Hij kwam in 2015 bij AWS en concentreerde zich sindsdien op de big data-analyseruimte, waarbij hij klanten hielp bij het bouwen van schaalbare en robuuste oplossingen met behulp van AWS-analyseservices.
Pathik Sjah is een Sr. Analytics Architect bij Amazon Athena. Hij kwam in 2015 bij AWS en concentreerde zich sindsdien op de big data-analyseruimte, waarbij hij klanten hielp bij het bouwen van schaalbare en robuuste oplossingen met behulp van AWS-analyseservices.
![]() Raj Devnath is productmanager bij AWS op Amazon Athena. Hij heeft een passie voor het bouwen van producten waar klanten dol op zijn en voor het helpen van klanten om waarde uit hun data te halen. Zijn achtergrond ligt in het leveren van oplossingen voor meerdere eindmarkten, zoals financiën, detailhandel, slimme gebouwen, domotica en datacommunicatiesystemen.
Raj Devnath is productmanager bij AWS op Amazon Athena. Hij heeft een passie voor het bouwen van producten waar klanten dol op zijn en voor het helpen van klanten om waarde uit hun data te halen. Zijn achtergrond ligt in het leveren van oplossingen voor meerdere eindmarkten, zoals financiën, detailhandel, slimme gebouwen, domotica en datacommunicatiesystemen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/

