Introductie
Grote taalmodellen (LLM's) zijn prominente innovatiepijlers in het steeds evoluerende landschap van kunstmatige intelligentie. Deze modellen, zoals GPT-3, hebben indrukwekkend getoond natuurlijke taalverwerking en mogelijkheden voor het genereren van inhoud. Toch vereist het benutten van hun volledige potentieel inzicht in hun ingewikkelde werking en het toepassen van effectieve technieken, zoals verfijning, om hun prestaties te optimaliseren.
Als data scientist Met een voorliefde voor het graven in de diepten van LLM-onderzoek, ben ik begonnen aan een reis om de trucs en strategieën te ontrafelen die deze modellen laten schitteren. In dit artikel zal ik u door enkele belangrijke aspecten leiden van het creëren van hoogwaardige gegevens voor LLM's, het bouwen van effectieve modellen en het maximaliseren van hun bruikbaarheid in echte toepassingen.

Leerdoelen:
- Begrijp de gelaagde aanpak van LLM-gebruik, van fundamentele modellen tot gespecialiseerde agenten.
- Leer meer over veiligheid, versterkend leren en het verbinden van LLM's met databases.
- Ontdek 'LIMA', 'Distill' en vraag-antwoordtechnieken voor samenhangende antwoorden.
- Maak kennis met geavanceerde fijnafstemming met modellen als “phi-1” en ken de voordelen ervan.
- Meer informatie over schaalwetten, bias reductieen het aanpakken van modeltendensen.
Inhoudsopgave
Effectieve LLM's bouwen: benaderingen en technieken
Wanneer je je verdiept in het domein van LLM's, is het belangrijk om de fasen van hun toepassing te herkennen. Voor mij vormen deze fasen een kennispiramide, waarbij elke laag voortbouwt op de vorige. De fundamenteel model is de basis: het is het model dat uitblinkt in het voorspellen van het volgende woord, vergelijkbaar met het voorspellende toetsenbord van uw smartphone.
De magie gebeurt wanneer u dat fundamentele model neemt en het verfijnt met behulp van gegevens die relevant zijn voor uw taak. Dit is waar chatmodellen in het spel komen. Door het model te trainen op chatgesprekken of leerzame voorbeelden, kun je het model ertoe aanzetten chatbot-achtig gedrag te vertonen, wat een krachtig hulpmiddel is voor verschillende toepassingen.
Veiligheid staat voorop, vooral omdat internet een nogal ongemanierde plek kan zijn. De volgende stap houdt in Versterking leren van menselijke feedback (RLHF). Deze fase brengt het gedrag van het model in lijn met menselijke waarden en beschermt het tegen ongepaste of onnauwkeurige reacties.
Naarmate we verder in de piramide komen, komen we de applicatielaag tegen. Dit is waar LLM's verbinding maken met databases, waardoor ze waardevolle inzichten kunnen bieden, vragen kunnen beantwoorden en zelfs taken kunnen uitvoeren code generatie or tekst samenvatting.
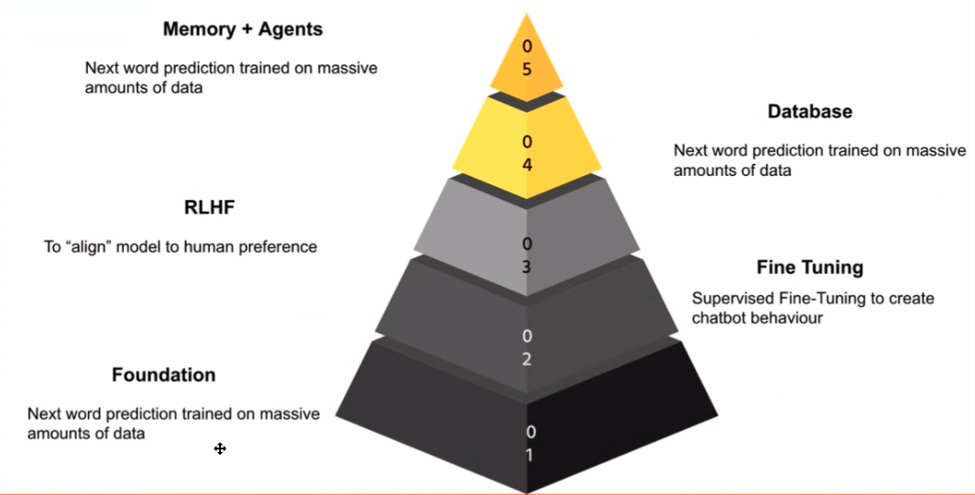
Ten slotte bestaat het toppunt van de piramide uit het creëren van agenten die zelfstandig taken kunnen uitvoeren. Deze agenten kunnen worden gezien als gespecialiseerde LLM's die uitblinken in specifieke domeinen, zoals financiën or geneeskunde.
Verbetering van de gegevenskwaliteit en verfijning
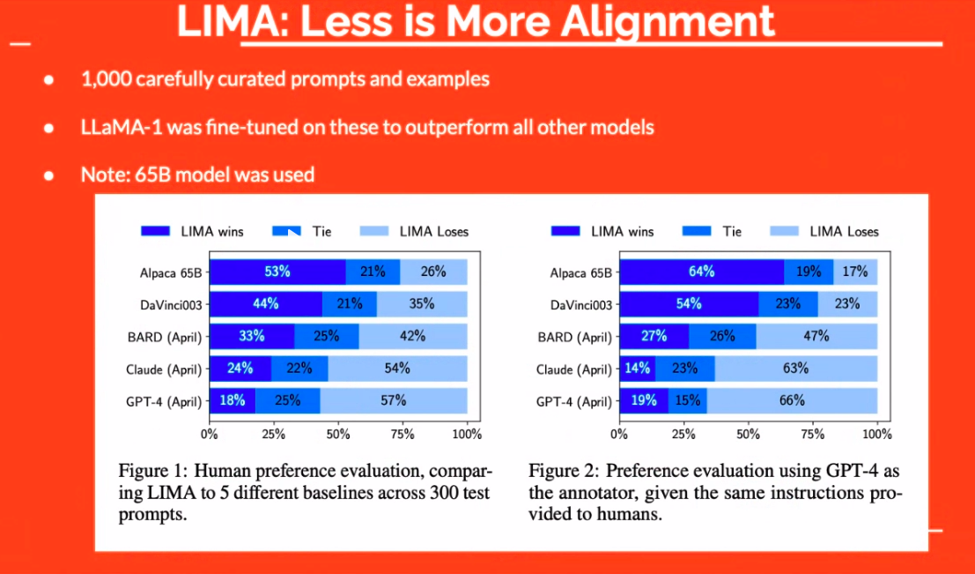
Gegevenskwaliteit speelt een cruciale rol in de effectiviteit van LLM's. Het gaat niet alleen om het hebben van gegevens; het gaat erom dat je over de juiste gegevens beschikt. De ‘LIMA’-aanpak heeft bijvoorbeeld aangetoond dat zelfs een kleine reeks zorgvuldig samengestelde voorbeelden beter kan presteren dan grotere modellen. De focus verschuift dus van kwantiteit naar kwaliteit.
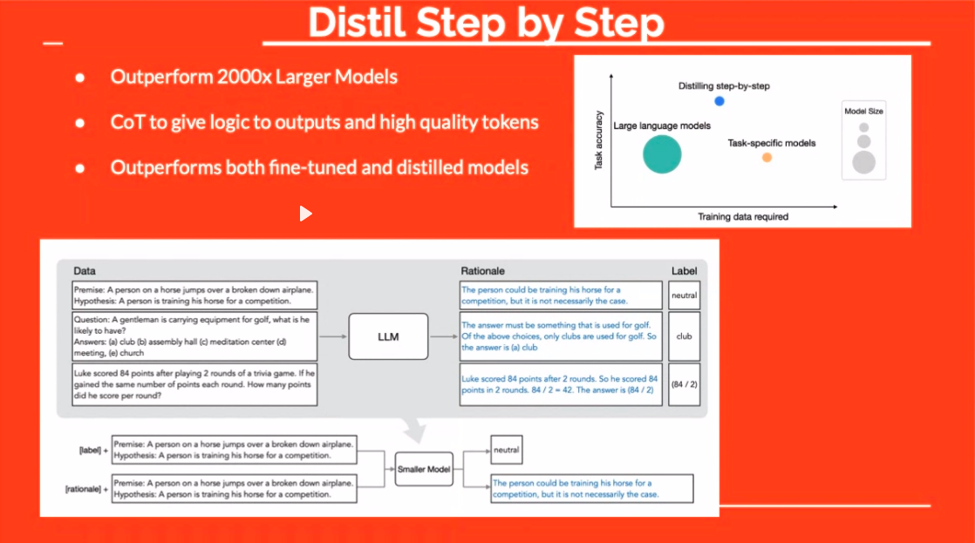
De “Distill”-techniek biedt nog een intrigerende mogelijkheid. Door tijdens het verfijnen een redenering aan de antwoorden toe te voegen, leert u het model het ‘wat’ en het ‘waarom’. Dit resulteert vaak in robuustere, coherentere reacties.
Meta's ingenieuze aanpak om vraagparen te creëren uit antwoorden is ook het vermelden waard. Door gebruik te maken van een LLM om vragen te formuleren op basis van bestaande oplossingen, maakt deze techniek de weg vrij voor een meer diverse en effectieve trainingsdataset.
Vraagparen maken vanuit PDF's met behulp van LLM's
Een bijzonder fascinerende techniek is het genereren van vragen uit antwoorden, een concept dat op het eerste gezicht paradoxaal lijkt. Deze techniek lijkt op reverse engineering-kennis. Stel je voor dat je een tekst hebt en er vragen uit wilt halen. Dit is waar LLM's schitteren.
Met een tool als LLM Data Studio kunt u bijvoorbeeld een pdf uploaden, waarna de tool op basis van de inhoud relevante vragen stelt. Door dergelijke technieken te gebruiken, kunt u op efficiënte wijze datasets samenstellen die LLM's voorzien van de kennis die nodig is om specifieke taken uit te voeren.
Verbetering van de modelvaardigheden door middel van verfijning
Oké, laten we het over de verfijning hebben. Stel je dit eens voor: een model met 1.3 miljard parameters dat in slechts vier dagen helemaal opnieuw is getraind op een set van acht A8's. Verbazingwekkend, toch? Wat ooit een dure onderneming was, is nu relatief economisch geworden. De fascinerende wending hier is het gebruik van GPT 100 voor het genereren van synthetische gegevens. Voer 'phi-3.5' in, de familienaam van het model die een geïntrigeerde wenkbrauw opwerpt. Vergeet niet dat dit een pre-fine-tuning-gebied is, mensen. De magie ontstaat bij het aanpakken van de taak om Python-code te maken op basis van doc-strings.
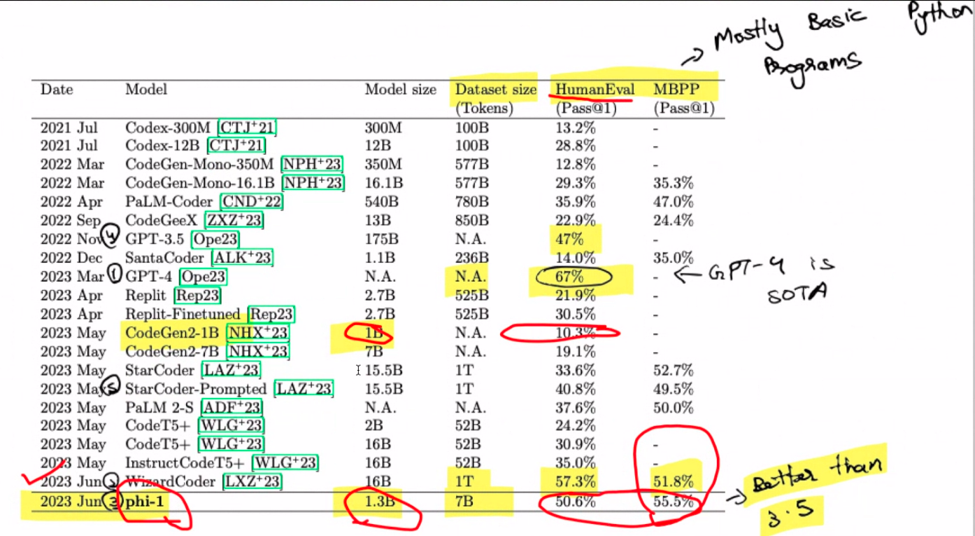
Hoe zit het met schaalwetten? Stel je ze voor als de regels voor modelgroei: groter betekent meestal beter. Houd echter uw paarden vast, want de kwaliteit van de gegevens verandert het spel. Dit kleine geheim? Een kleiner model kan soms zijn grotere tegenhangers overtreffen. Tromgeroffel aub! GPT-4 steelt hier de show en regeert oppermachtig. Opvallend is dat de WizzardCoder met een iets hogere score zijn entree maakt. Maar wacht, het pièce de résistance is phi-1, de kleinste van het stel, die ze allemaal overtreft. Het is alsof de underdog de race wint.
Onthoud dat deze krachtmeting helemaal draait om het maken van Python-code op basis van doc-strings. Phi-1 is misschien wel uw codegenie, maar vraag hem niet om uw website te bouwen met GPT-4; dat is niet zijn sterkste kant. Over phi-1 gesproken: het is een wonder met 1.3 miljard parameters, gevormd door 80 tijdperken van voortraining op 7 miljard tokens. Een hybride feest van synthetisch gegenereerde en gefilterde gegevens van schoolboekkwaliteit vormt het toneel. Met een vleugje verfijning van codeoefeningen stijgen de prestaties naar nieuwe hoogten.
Vermindering van modelvooroordelen en tendensen
Laten we even pauzeren en het merkwaardige geval van modeltendensen onderzoeken. Ooit gehoord van sycophantie? Het is die onschuldige kantoorcollega die altijd meeknikt met jouw niet zo geweldige ideeën. Het blijkt dat taalmodellen dergelijke tendensen ook kunnen vertonen. Neem een hypothetisch scenario waarin je beweert dat 1 plus 1 gelijk is aan 42, terwijl je tegelijkertijd je wiskundige vaardigheden beweert. Deze modellen zijn gemaakt om ons te plezieren, dus misschien zijn ze het wel met je eens. DeepMind komt ten tonele en werpt licht op de weg om dit fenomeen terug te dringen.
Om deze tendens te beteugelen komt er een slimme oplossing naar voren: leer het model de meningen van gebruikers te negeren. We maken een einde aan de 'ja-man'-eigenschap door voorbeelden te presenteren waarin dit niet het geval zou moeten zijn. Het is een kleine reis, gedocumenteerd in een document van twintig pagina's. Hoewel het geen directe oplossing voor hallucinaties is, is het een parallelle weg die het ontdekken waard is.
Effectieve agenten en API-oproepen
Stel je een autonoom exemplaar voor van een LLM (een agent) die in staat is om zelfstandig taken uit te voeren. Deze agenten zijn het gesprek van de dag, maar helaas is hun achilleshiel het gevolg van hallucinaties en andere vervelende problemen. Een persoonlijke anekdote speelt hier een rol terwijl ik praktisch aan agenten sleutelde.
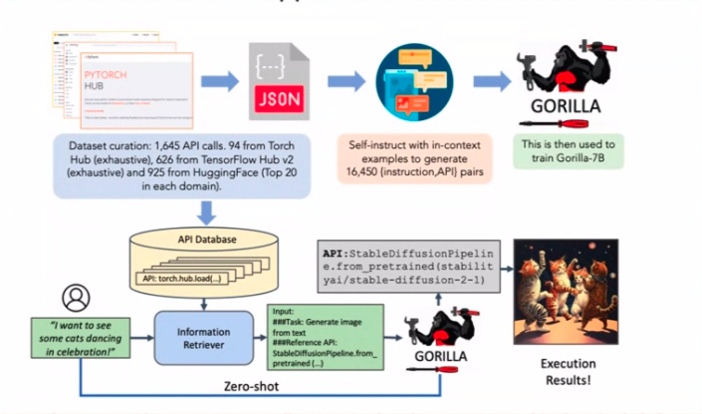
Overweeg een agent die belast is met het boeken van vluchten of hotels via API's. De vangst? Het zou die vervelende hallucinaties moeten vermijden. Nu terug naar dat papier. De geheime saus voor het verminderen van API-oproepende hallucinaties? Verfijning met enorm veel voorbeelden van API-aanroepen. Eenvoud voert de boventoon.
Combinatie van API's en LLM-annotaties
Het combineren van API's met LLM-annotaties klinkt als een technische symfonie, nietwaar? Het recept begint met een schat aan verzamelde voorbeelden, gevolgd door een vleugje ChatGPT-annotaties voor de smaak. Weet je nog die API's die niet goed werken? Ze worden eruit gefilterd, wat de weg vrijmaakt voor een effectief annotatieproces.
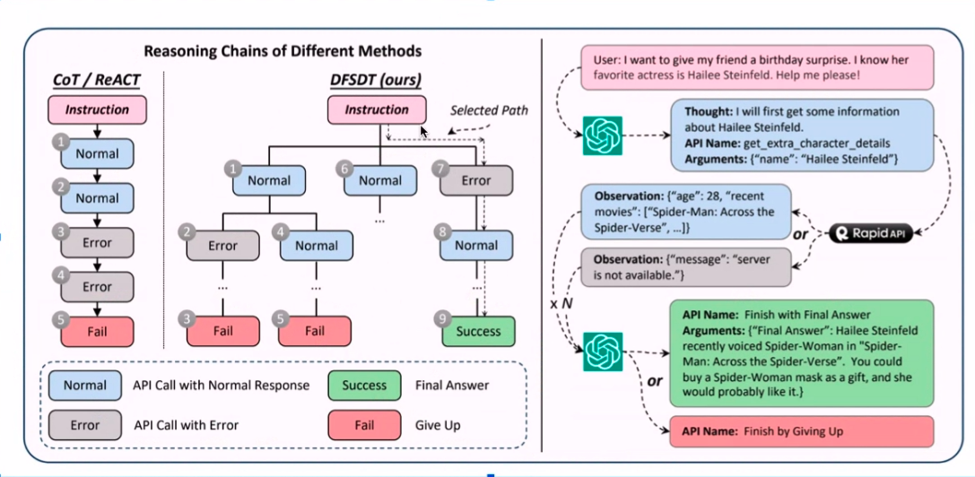
De kers op de taart is de diepgaande zoekfunctie, die ervoor zorgt dat alleen API's die echt werken de oplossing halen. Deze geannoteerde goudmijn verfijnt een LlaMA 1-model, en voila! De resultaten zijn ronduit opmerkelijk. Geloof me; deze ogenschijnlijk uiteenlopende papieren passen naadloos in elkaar en vormen een formidabele strategie.
Conclusie
En daar heb je het: de tweede helft van onze aangrijpende verkenning van de wonderen van taalmodellen. We hebben het landschap doorkruist, van schaalwetten tot modeltendensen en van efficiënte agenten tot API-aanroepverfijning. Elk stukje van de puzzel draagt bij aan een AI-meesterwerk dat de toekomst herschrijft. Dus, mijn mede-kenniszoekers, onthoud deze trucs en technieken, want ze zullen blijven evolueren, en we zullen hier zijn, klaar om de volgende golf van AI-innovaties te ontdekken. Tot dan, veel plezier met ontdekken!
Key Takeaways:
- Technieken als ‘LIMA’ laten zien dat goed samengestelde, kleinere datasets beter kunnen presteren dan grotere.
- Het opnemen van rationale in antwoorden tijdens het afstemmen en creatieve technieken zoals vraagparen uit antwoorden verbetert de LLM-antwoorden.
- Effectieve agenten, API’s en annotatietechnieken dragen bij aan een robuuste AI-strategie, waarbij ongelijksoortige componenten tot een samenhangend geheel worden overbrugd.
Veelgestelde Vragen / FAQ
Antw.: Bij het verbeteren van de LLM-prestaties gaat het om de nadruk op datakwaliteit boven kwantiteit. Technieken als ‘LIMA’ laten zien dat samengestelde, kleinere datasets beter kunnen presteren dan grotere, en dat het toevoegen van onderbouwing aan antwoorden tijdens het verfijnen de reacties verbetert.
Antw: Fine-tuning is cruciaal voor LLM's. “phi-1” is een model met 1.3 miljard parameters dat uitblinkt in het genereren van Python-code uit doc-strings, en laat de magie van fijnafstemming zien. Schaalwetten suggereren dat grotere modellen beter zijn, maar soms presteren kleinere modellen zoals “phi-1” beter dan grotere.
Antw: Modelneigingen, zoals het eens zijn met onjuiste uitspraken, kunnen worden aangepakt door modellen te trainen om het niet eens te zijn met bepaalde input. Dit helpt de 'ja-man'-eigenschap bij LLM's te verminderen, hoewel het geen directe oplossing is voor hallucinaties.
Over de auteur: Sanyam Bhutani
Sanyam Bhutani is Senior Data Scientist en Kaggle Grandmaster bij H2O, waar hij chai drinkt en inhoud maakt voor de gemeenschap. Als hij geen chai drinkt, wandelt hij door de Himalaya, vaak met LLM Research-papieren. De afgelopen zes maanden heeft hij elke dag op internet over generatieve AI geschreven. Daarvoor werd hij erkend voor zijn nummer 6 Kaggle Podcast: Chai Time Data Science, en stond hij ook algemeen bekend op internet vanwege het “maximaliseren van de rekenkracht per kubieke inch van een ATX-behuizing” door twaalf GPU’s in zijn thuiskantoor te installeren.
DataHour-pagina: https://community.analyticsvidhya.com/c/datahour/cutting-edge-tricks-of-applying-large-language-models
LinkedIn: https://www.linkedin.com/in/sanyambhutani/
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/09/cutting-edge-tricks-of-applying-large-language-models/

