Introductie
Een betrouwbare statistische techniek om de significantie te bepalen is de variantieanalyse (ANOVA), vooral bij het vergelijken van meer dan twee steekproefgemiddelden. Hoewel de t-verdeling voldoende is om de gemiddelden van twee steekproeven te vergelijken, is een ANOVA vereist wanneer met drie of meer steekproeven tegelijk wordt gewerkt om te bepalen of hun gemiddelden al dan niet hetzelfde zijn, aangezien ze uit dezelfde onderliggende populatie komen.
ANOVA kan bijvoorbeeld worden gebruikt om te bepalen of verschillende meststoffen verschillende effecten hebben op de tarweproductie op verschillende percelen en of deze behandelingen statistisch verschillende resultaten opleveren voor dezelfde populatie.

Prof. RA Fisher introduceerde de term 'Analyse van Variantie' in 1920 toen hij zich bezighield met het probleem bij de analyse van agronomische gegevens. Variabiliteit is een fundamenteel kenmerk van natuurlijke gebeurtenissen. De algehele variatie in een bepaalde dataset is afkomstig van meerdere bronnen, die grofweg kunnen worden geclassificeerd als toewijsbare en toevallige oorzaken.
De variatie als gevolg van toewijsbare oorzaken kan worden gedetecteerd en gemeten, terwijl de variatie als gevolg van toevallige oorzaken buiten de controle van de menselijke hand ligt en niet afzonderlijk kan worden behandeld.
Volgens RA Fisher is Variantieanalyse (ANOVA) de “scheiding van variantie die aan de ene groep oorzaken kan worden toegeschreven, en de variantie die aan een andere groep kan worden toegeschreven”.
leerdoelen
- Begrijp het concept van Variantieanalyse (ANOVA) en het belang ervan bij statistische analyse, vooral bij het vergelijken van meerdere steekproefgemiddelden.
- Leer de aannames die nodig zijn voor het uitvoeren van een ANOVA-test en de toepassing ervan op verschillende gebieden, zoals geneeskunde, onderwijs, marketing, productie, psychologie en landbouw.
- Ontdek het stapsgewijze proces van het uitvoeren van een eenrichtings-ANOVA, inclusief het opstellen van nul- en alternatieve hypothesen, gegevensverzameling en -organisatie, berekening van groepsstatistieken, bepaling van de som van kwadraten, berekening van vrijheidsgraden, berekening van gemiddelde kwadraten , berekening van F-statistieken, bepaling van kritische waarde en besluitvorming.
- Krijg praktische inzichten in het implementeren van een one-way ANOVA-test in Python met behulp van de scipy.stats-bibliotheek.
- Begrijp het significantieniveau en de interpretatie van de F-statistiek en p-waarde in de context van ANOVA.
- Leer meer over post-hoc analysemethoden zoals Tukey's Honestly Significant Difference (HSD) voor verdere analyse van significante verschillen tussen groepen.
Inhoudsopgave
Aannames voor ANOVA-TEST
De ANOVA-test is gebaseerd op de teststatistieken F.
Aannames met betrekking tot de geldigheid van de F-test in ANOVA zijn onder meer de volgende:
- De waarnemingen zijn onafhankelijk.
- De ouderpopulatie waaruit waarnemingen worden gedaan, is normaal.
- Verschillende behandelings- en milieueffecten zijn additief van aard.
Eenrichtings ANOVA
Eénrichtings-ANOVA is a statistische test gebruikt om te bepalen of er statistisch significante verschillen zijn in de gemiddelden van drie of meer groepen voor een enkele factor (onafhankelijke variabele). Het vergelijkt de variantie tussen groepen met de variantie binnen groepen om te beoordelen of deze verschillen waarschijnlijk te wijten zijn aan willekeurig toeval of aan een systematisch effect van de factor.
Verschillende gebruiksscenario's van eenrichtings-ANOVA uit verschillende domeinen zijn:
- Geneeskunde: One-way ANOVA kan worden gebruikt om de effectiviteit van verschillende behandelingen voor een bepaalde medische aandoening te vergelijken. Het zou bijvoorbeeld kunnen worden gebruikt om te bepalen of drie verschillende medicijnen significant verschillende effecten hebben op het verlagen van de bloeddruk.
- Onderwijs: One-way ANOVA kan worden gebruikt om te analyseren of er significante verschillen zijn in toetsscores tussen studenten die les hebben gekregen met verschillende lesmethoden.
- marketing: One-way ANOVA kan worden gebruikt om te beoordelen of er significante verschillen zijn in klanttevredenheid tussen producten van verschillende merken.
- Productie: One-way ANOVA kan worden gebruikt om te analyseren of er significante verschillen zijn in de sterkte van materialen die door verschillende productieprocessen worden geproduceerd.
- Psychologie: One-way ANOVA kan worden gebruikt om te onderzoeken of er significante verschillen zijn in angstniveaus tussen deelnemers die worden blootgesteld aan verschillende stressoren.
- Landbouw: One-way ANOVA kan worden gebruikt om te bepalen of verschillende meststoffen in landbouwexperimenten tot significant verschillende gewasopbrengsten leiden.
Laten we dit met het landbouwvoorbeeld in detail begrijpen:
In landbouwonderzoek kan eenrichtings-ANOVA worden gebruikt om te beoordelen of verschillende meststoffen tot significant verschillende gewasopbrengsten leiden.
Meststofeffect op plantengroei
Stel je voor dat je onderzoek doet naar de impact van verschillende meststoffen op de plantengroei. Je brengt drie soorten meststoffen (A, B en C) aan op aparte groepen planten. Na een bepaalde periode meet je de gemiddelde hoogte van de planten in elke groep. Je kunt one-way ANOVA gebruiken om te testen of er een significant verschil in gemiddelde hoogte bestaat tussen planten die met verschillende meststoffen zijn gekweekt.
Stap 1: Nul- en alternatieve hypothesen
De eerste stap is het opvoeren van nul- en alternatieve hypothesen:
- Nulhypothese(H0): De gemiddelden van alle groepen zijn gelijk (er is geen significant verschil in plantengroei als gevolg van het type kunstmest)
- Alternatieve hypothese (H1): Tenminste één groepsgemiddelde verschilt van de andere (het soort kunstmest heeft een significant effect op de plantengroei).
Stap 2: Gegevensverzameling en gegevensorganisatie
Meet na een bepaalde groeiperiode zorgvuldig de uiteindelijke hoogte van elke plant in alle drie de groepen. Organiseer nu uw gegevens. Elke kolom vertegenwoordigt een type meststof (A, B, C) en elke rij bevat de hoogte van een individuele plant binnen die groep.
Stap3: Bereken de groep Statistieken
- Bereken de gemiddelde eindhoogte voor planten in elke meststofgroep (A, B en C).
- Bereken het totale aantal waargenomen planten (N) voor alle groepen.
- Bepaal het totale aantal groepen (K) in ons geval, k=3(A, B, C)
Stap 4: Bereken de som van het kwadraat
Dus de totale som van het kwadraat, de som van het kwadraat tussen de groepen en de som van het kwadraat binnen de groep worden berekend.
Hier vertegenwoordigt Total Sum of Square de totale variatie in uiteindelijke hoogte van alle planten.
De som van het kwadraat tussen de groepen weerspiegelt de waargenomen variatie tussen de gemiddelde hoogten van de drie meststofgroepen. En de Sum of Square binnen de groep registreert de variatie in de uiteindelijke hoogte binnen elke meststofgroep.
Stap 5: Bereken de vrijheidsgraden
Vrijheidsgraden definiëren het aantal onafhankelijke stukjes informatie die worden gebruikt om een populatieparameter te schatten.
- Vrijheidsgraden tussen groepen: k-1 (aantal groepen min 1) Hier is het dus 3-1 =2
- Vrijheidsgraden binnen de groep: Nk (Totaal aantal waarnemingen minus aantal groepen)
Stap 6: Bereken gemiddelde kwadraten
Gemiddelde kwadraten worden verkregen door de respectieve som van kwadraten te delen door vrijheidsgraden.
- Gemiddeld vierkant tussen: Tussen-groep Som van kwadraat/vrijheidsgraden tussen groepen
- Gemiddeld vierkant binnen: Binnen de groep de som van het kwadraat/vrijheidsgraden binnen de groep
Stap 7: Bereken F-statistieken
De F-statistiek is een teststatistiek die wordt gebruikt om de variatie tussen groepen te vergelijken met de variatie binnen groepen. Een hogere F-statistiek suggereert een potentieel sterker effect van het type meststof op de plantengroei.
De F-statistiek voor eenrichtings-Anova wordt berekend met behulp van deze formule:
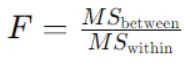
Hier
MSbetween is het gemiddelde kwadraat tussen groepen, berekend als de som van de kwadraten tussen groepen gedeeld door de vrijheidsgraden tussen groepen.
MSwithin is het gemiddelde kwadraat binnen groepen, berekend als de som van de kwadraten binnen groepen gedeeld door de vrijheidsgraden binnen groepen.
- Vrijheidsgraden tussen groepen (dof_between): dof_tussen = k-1
Waar k het aantal groepen (niveaus) van de onafhankelijke variabele is.
- Vrijheidsgraden binnen groepen (dof_within): dof_binnen = Nk
Waarbij N het aantal waarnemingen is en k het aantal groepen (niveaus) van de onafhankelijke variabele.
Voor eenrichtings-ANOVA is de totale vrijheidsgraad de som van de vrijheidsgraden tussen groepen en binnen groepen:
dof_totaal= dof_tussen+dof_binnen
Stap 8: Bepaal de kritische waarde en beslissing
Kies een significantieniveau (alfa) voor de analyse, meestal wordt 0.05 gekozen
Zoek de kritische F-waarde op het gekozen alfaniveau en de berekende vrijheidsgraden tussen groepen en vrijheidsgraden binnen groepen op met behulp van een F-verdelingstabel.
Vergelijk de berekende F-statistiek met de kritische F-waarde
- Als de berekende F-statistiek groter is dan de kritische F-waarde, verwerp dan de nulhypothese (H0). Dit duidt op een statistisch significant verschil in gemiddelde planthoogte tussen de drie meststofgroepen.
- Als de berekende F-statistiek kleiner is dan of gelijk is aan de kritische F-waarde, mag u de nulhypothese (H0) niet verwerpen. Op basis van deze gegevens kunt u geen significant verschil concluderen.
Stap 9: Post-hocanalyse (indien nodig)
Indien de nulhypothese wordt afgewezen, wat wijst op een significant totaalverschil, dan wilt u er wellicht dieper op ingaan. Post-hoc, zoals Tukey's Honestly Significant Difference (HSD), kan helpen identificeren welke specifieke meststofgroepen statistisch verschillende gemiddelde planthoogtes hebben.
Implementatie in Python:
import scipy.stats as stats
# Sample plant height data for each fertilizer type
plant_heights_A = [25, 28, 23, 27, 26]
plant_heights_B = [20, 22, 19, 21, 24]
plant_heights_C = [18, 20, 17, 19, 21]
# Perform one-way ANOVA
f_value, p_value = stats.f_oneway(plant_heights_A, plant_heights_B, plant_heights_C)
# Interpretation
print("F-statistic:", f_value)
print("p-value:", p_value)
# Significance level (alpha) - typically set at 0.05
alpha = 0.05
if p_value < alpha:
print("Reject H0: There is a significant difference in plant growth between the fertilizer groups.")
else:
print("Fail to reject H0: We cannot conclude a significant difference based on this sample.")
Output:

De vrijheidsgraad daartussen is K-1 = 3-1 =2, waarbij k het aantal meststofgroepen voorstelt. De vrijheidsgraad daarbinnen is Nk = 15-3= 12, waarbij N het totale aantal datapunten vertegenwoordigt.
F-kritiek bij dof(2,12) kan worden berekend F-verdelingstabel op een significantieniveau van 0.05.
F-kritisch = 9.42
Omdat F-kritisch < F-statistieken We verwerpen dus de nulhypothese die concludeert dat er een significant verschil is in plantengroei tussen de meststofgroepen.
Met een p-waarde onder de 0.05 blijft onze conclusie consistent: we verwerpen de nulhypothese, wat wijst op een significant verschil in plantengroei tussen de meststofgroepen.
Bidirectionele ANOVA
One-way ANOVA is slechts voor één factor geschikt, maar wat als er twee factoren zijn die uw experiment beïnvloeden? Vervolgens wordt tweeweg-ANOVA gebruikt, waarmee u de effecten van twee onafhankelijke variabelen op één enkele afhankelijke variabele kunt analyseren.
Stap 1: Hypotheses opstellen
- Null-hypothese (H0): Er is geen significant verschil in de gemiddelde uiteindelijke planthoogte als gevolg van het type meststof (A, B, C) of planttijd (vroeg, laat) of hun interactie.
- Alternatieve hypothese (H1): Tenminste één van de volgende beweringen is waar:
- Het type meststof heeft een aanzienlijk effect op de gemiddelde eindhoogte.
- De planttijd heeft een aanzienlijk effect op de gemiddelde eindhoogte.
- Er is een significant interactie-effect tussen het type meststof en de planttijd. Dit betekent dat het effect van de ene factor (meststof) afhankelijk is van de hoogte van de andere factor (planttijd).
Stap 2: Gegevensverzameling en -organisatie
- Meet de uiteindelijke planthoogte.
- Organiseer uw gegevens in een tabel met rijen die individuele planten vertegenwoordigen en kolommen voor:
- Soort meststof (A, B, C)
- Planttijd (vroeg, laat)
- Uiteindelijke hoogte (cm)
Hier is de tabel:

Stap 3: Bereken de som van het kwadraat
Net als bij eenrichtings-ANOVA moet u verschillende kwadratensommen berekenen om de variatie in de uiteindelijke hoogte te beoordelen:
- Totale som van het kwadraat (SST): Vertegenwoordigt de totale variatie tussen alle planten. Hoofdeffect som van het kwadraat:
- Tussen-meststoftypen (SSB_F): Geeft de variatie weer als gevolg van verschillen in het type meststof (gemiddeld over planttijden)
- Tijden tussen platen (SSB_T): Geeft de variatie weer als gevolg van verschillen in planttijden (gemiddeld over de soorten kunstmest).
- Interactie som van het kwadraat (SSI): Legt de variatie vast als gevolg van de interactie tussen het type meststof en de planttijd.
- Som van kwadraten binnen de groep (SSW): Geeft de variatie in uiteindelijke hoogte weer binnen elke combinatie van kunstmest en planttijd.
Stap 4: Bereken de vrijheidsgraden (df):
Vrijheidsgraden definiëren het aantal onafhankelijke stukjes informatie voor elk effect.
- dfTotaal: N-1 (totaal waarnemingen min 1)
- dfmeststof: Aantal soorten kunstmest -1
- dfPlanttijd: Aantal planttijden -1
- dfInteractie: (Aantal mestsoorten -1) * (Aantal planttijden -1)
- dfBinnen: dfTotaal-dfKunstmest-dfplanting-dfInteractie
Stap 5: Bereken gemiddelde kwadraten
Deel elke som van het kwadraat door de overeenkomstige vrijheidsgraad.
- MS_meststof: SSB_F/dfKunstmest
- MS_PlantingTime: SSB_T/dfPlanting
- MS_Interactie: SSI/dfInteractie
- MS_Binnen: SSW/dfBinnen
Stap 6: Bereken F-statistieken
Bereken afzonderlijke F-statistieken voor type meststof, planttijd en interactie-effect:
- F_Bemesten: MS_Fertilizer/MS_Within
- F_PlantingTime: MS_PlantingTime/MS_Within
- F_Interactie: MS_Inteactie/MS_Within
- F_PlantingTime: MS_PlantingTime/MS_Within
- F_Interactie: MS_Interactie/MS_Binnen
Stap 7: Bepaal kritische waarden en beslissing:
Kies een significantieniveau (alfa) voor uw analyse, meestal nemen we 0.05
Zoek kritische F-waarden voor elk effect (meststof, planttijd, interactie) op het gekozen alfaniveau en hun respectievelijke vrijheidsgraden met behulp van een F-verdelingstabel of statistische software.
Vergelijk uw berekende F-statistieken met de kritische F-waarden voor elk effect:
- Als de F-statistiek groter is dan de kritische F-waarde, verwerp dan de nulhypothese (H0) voor dat effect. Dit duidt op een statistisch significant verschil.
- Als de F-statistiek kleiner is dan of gelijk is aan de kritische F-waarde, kun je H0 vanwege dat effect niet verwerpen. Dit duidt op een statistisch niet-significant verschil.
Stap 8: Post-hocanalyse (indien nodig)
Als de nulhypothese wordt verworpen, wat wijst op een significant totaalverschil, wil je misschien dieper ingaan. Post-hoc, zoals Tukey's Honestly Significant Difference (HSD), kan helpen identificeren welke specifieke meststofgroepen statistisch verschillende gemiddelde planthoogtes hebben.
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
# Create a DataFrame from the dictionary
plant_heights = {
'Treatment': ['A', 'A', 'A', 'A', 'A', 'A',
'B', 'B', 'B', 'B', 'B', 'B',
'C', 'C', 'C', 'C', 'C', 'C'],
'Time': ['Early', 'Early', 'Early', 'Late', 'Late', 'Late',
'Early', 'Early', 'Early', 'Late', 'Late', 'Late',
'Early', 'Early', 'Early', 'Late', 'Late', 'Late'],
'Height': [25, 28, 23, 27, 26, 24,
20, 22, 19, 21, 24, 22,
18, 20, 17, 19, 21, 20]
}
df = pd.DataFrame(plant_heights)
# Fit the ANOVA model
model = ols('Height ~ C(Treatment) + C(Time) + C(Treatment):C(Time)', data=df).fit()
# Perform ANOVA
anova_table = sm.stats.anova_lm(model, typ=2)
# Print the ANOVA table
print(anova_table)
# Interpret the results
alpha = 0.05 # Significance level
if anova_table['PR(>F)'][0] < alpha:
print("nReject null hypothesis for Treatment factor.")
else:
print("nFail to reject null hypothesis for Treatment factor.")
if anova_table['PR(>F)'][1] < alpha:
print("Reject null hypothesis for Time factor.")
else:
print("Fail to reject null hypothesis for Time factor.")
if anova_table['PR(>F)'][2] < alpha:
print("Reject null hypothesis for Interaction between Treatment and Time.")
else:
print("Fail to reject null hypothesis for Interaction between Treatment and Time.")
Output:
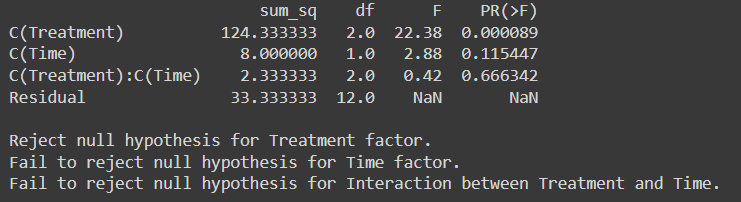
F-kritische waarde voor behandeling bij vrijheidsgraad (2,12) bij een significantieniveau van 0.05 vanaf F-verdelingstabel is 9.42
F-kritische waarde voor tijd bij vrijheidsgraad (1,12) op significantieniveau 0.05 is 61.22
F- kritische waarde voor interactie tussen behandeling en tijd bij een significantieniveau van 0.05 bij vrijheidsgraad (2,12) is 9.42
Omdat F-kritisch < F-statistieken We verwerpen dus de nulhypothese voor de behandelingsfactor.
Maar voor tijdsfactor en interactie tussen behandeling en tijdsfactor zijn we er niet in geslaagd de nulhypothese te verwerpen als F-statistische waarde > F-kritische waarde
Met een p-waarde lager dan 0.05 blijft onze conclusie consistent: we verwerpen de nulhypothese voor de behandelingsfactor, terwijl we met een p-waarde boven 0.05 er niet in slagen de nulhypothese voor de tijdsfactor en de interactie tussen behandeling en tijdsfactor te verwerpen.
Verschil tussen eenrichtings-ANOVA en tweerichtings-ANOVA
Eenrichtings-ANOVA en tweerichtings-ANOVA zijn beide statistische technieken die worden gebruikt om verschillen tussen groepen te analyseren, maar ze verschillen in termen van het aantal onafhankelijke variabelen waarmee ze rekening houden en de complexiteit van het experimentele ontwerp.
Dit zijn de belangrijkste verschillen tussen eenrichtings-ANOVA en tweerichtings-ANOVA:
| Aspect | Eenrichtings ANOVA | Bidirectionele ANOVA |
|---|---|---|
| Aantal variabelen | Analyseert één onafhankelijke variabele (factor) op een continu afhankelijke variabele | Analyseert twee onafhankelijke variabelen (factoren) op een continu afhankelijke variabele |
| Experimenteel ontwerp | Eén categorische onafhankelijke variabele met meerdere niveaus (groepen) | Twee categorisch onafhankelijke variabelen (factoren), vaak aangeduid als A en B, met meerdere niveaus. Maakt onderzoek van de belangrijkste effecten en interactie-effecten mogelijk |
| Interpretatie | Geeft significante verschillen aan tussen groepsgemiddelden | Geeft informatie over de belangrijkste effecten van factoren (A en B) en hun interactie. Helpt bij het beoordelen van verschillen tussen factorniveaus en onderlinge afhankelijkheid |
| Ingewikkeldheid | Relatief eenvoudig en gemakkelijk te interpreteren | Complexer, analyse van de belangrijkste effecten van twee factoren en hun interactie. Vereist een zorgvuldige afweging van factorrelaties |
Conclusie
ANOVA is een krachtig hulpmiddel voor het analyseren van verschillen tussen groepsgemiddelden, essentieel bij het vergelijken van meer dan twee steekproefgemiddelden. Eenrichtings-ANOVA beoordeelt de impact van een enkele factor op een continu resultaat, terwijl tweerichtings-ANOVA deze analyse uitbreidt om twee factoren en hun interactie-effecten in aanmerking te nemen. Door deze verschillen te begrijpen, kunnen onderzoekers de meest geschikte analytische aanpak kiezen voor hun experimentele ontwerpen en onderzoeksvragen.
Veelgestelde Vragen / FAQ
A. ANOVA staat voor Analysis of Variance, een statistische methode die wordt gebruikt om verschillen tussen groepsgemiddelden te analyseren. Het wordt gebruikt bij het vergelijken van gemiddelden van drie of meer groepen om te bepalen of er significante verschillen zijn.
A. Eenrichtings-ANOVA wordt gebruikt als u één categorische onafhankelijke variabele (factor) met meerdere niveaus heeft en u de gemiddelden van deze niveaus wilt vergelijken. Vergelijk bijvoorbeeld de effectiviteit van verschillende behandelingen op één resultaat.
A. Tweerichtings-ANOVA wordt gebruikt als u twee categorisch onafhankelijke variabelen (factoren) heeft en u hun effecten op een continu afhankelijke variabele wilt analyseren, evenals de interactie tussen de twee factoren. Het is nuttig voor het bestuderen van de gecombineerde effecten van twee factoren op een resultaat.
A. De p-waarde in ANOVA geeft de waarschijnlijkheid aan dat de gegevens worden waargenomen als de nulhypothese (geen significant verschil tussen groepsgemiddelden) waar zou zijn. Een lage p-waarde (< 0.05) suggereert dat er significant bewijs is om de nulhypothese te verwerpen en te concluderen dat er verschillen tussen de groepen bestaan.)
A. De F-statistiek in ANOVA meet de verhouding tussen de variantie tussen groepen en de variantie binnen groepen. Een hogere F-statistiek geeft aan dat de variantie tussen groepen groter is in verhouding tot de variantie binnen groepen, wat duidt op een significant verschil tussen de groepsgemiddelden.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2024/04/one-way-and-two-way-analysis-of-variance-anova/

