Introductie
Stap in de voorhoede van taalverwerking! In een wereld waar taal een essentiële schakel is tussen de mensheid en technologie, hebben de vooruitgang die is geboekt op het gebied van natuurlijke taalverwerking een aantal buitengewone hoogten bereikt. Binnen deze vooruitgang ligt het baanbrekende Large Language Model, een transformerende kracht die onze interacties met op tekst gebaseerde informatie opnieuw vormgeeft. In dit uitgebreide leertraject verdiep je je in de fijne kneepjes van LangChain, een baanbrekend hulpmiddel dat de manier waarop we omgaan met op tekst gebaseerde informatie opnieuw vormgeeft. Heb je je ooit afgevraagd wat keten is, de “Langchain”?

LangChain staat op zichzelf als toegangspoort tot het meest dynamische veld van grote taalmodellen, dat een diepgaand inzicht biedt in hoe deze modellen de ruwe input transformeren in verfijnde en mensachtige antwoorden. Door deze verkenning ontrafel je de essentiële bouwstenen van LangChain, van LLMChains en Sequential Chains tot de ingewikkelde werking van Router Chains.
leerdoelen
- Begrijp de kerncomponenten van LangChain, inclusief LLMChains en Sequential Chains, om te zien hoe invoer door het systeem stroomt.
- Leer verschillende elementen op coherente wijze te integreren en onderzoek de verbinding tussen de promptsjablonen en taalmodellen.
- Doe praktische ervaring op met het creëren van functionele ketens voor taken in de echte wereld.
- Ontwikkel vaardigheden om de ketenefficiëntie te verbeteren door de structuren, sjablonen en parseertechnieken te verfijnen.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Wat is LLM?
A Groot taalmodel (LLM) verwijst naar een type kunstmatige intelligentie dat is ontworpen om mensachtige tekst te begrijpen en te genereren. Deze modellen trainen, net als GPT-3.5 van OpenAI, op uitgebreide tekstgegevens om de patronen en structuren van menselijke taal te begrijpen. Ze kunnen verschillende taalgerelateerde taken uitvoeren, waaronder vertalen, inhoud maken, vragen beantwoorden en meer.
LLM's zijn waardevolle hulpmiddelen bij de verwerking van natuurlijke taal en hebben toepassingen op gebieden als chatbots, het genereren van inhoud en vertaaldiensten.
Wat is LangChain?
Voordat we de fijne kneepjes van LangChain Chains ontrafelen, gaan we eerst naar de essentie van LangChain zelf. LangChain is een robuuste bibliotheek die is ontworpen om interacties met verschillende aanbieders van grote taalmodellen (LLM) te vereenvoudigen, waaronder OpenAI, Cohere, Bloom, Huggingface en anderen. Wat LangChain onderscheidt is de unieke eigenschap: de mogelijkheid om ketens te creëren en logische verbindingen die helpen bij het overbruggen van een of meerdere LLM's.
Waarom LangChain gebruiken?
LangChain biedt onbeperkte mogelijkheden, alleen beperkt door uw verbeeldingskracht.
- Stel je chatbots voor die niet alleen informatie verstrekken, maar gebruikers ook met humor en charme aanspreken.
- Stel je e-commerceplatforms voor die producten zo nauwkeurig voorstellen dat klanten gedwongen worden een aankoop te doen.
- Stel u gezondheidszorgapps voor die gepersonaliseerde medische inzichten bieden, waardoor individuen weloverwogen beslissingen kunnen nemen over hun welzijn.
Met LangChain heb je de kracht om buitengewone ervaringen te creëren. Het potentieel om deze ideeën om te zetten in realiteit ligt binnen handbereik.
Ketens begrijpen in LangChain
Centraal in LangChain staat een essentieel onderdeel dat bekend staat als LangChain Chains en dat de kernverbinding vormt tussen een of meerdere grote taalmodellen (LLM's).

In bepaalde geavanceerde toepassingen wordt het noodzakelijk om LLM's aan elkaar te koppelen, hetzij met elkaar, hetzij met andere elementen. Deze ketens stellen ons in staat om talloze componenten te integreren en ze tot een samenhangende toepassing te verweven. Laten we dieper ingaan op de verschillende soorten ketens.
Bovendien zorgt de gestructureerde aanpak van Chains in LLM voor een vlekkeloze en effectieve verwerking, waardoor de weg wordt vrijgemaakt voor de ontwikkeling van geavanceerde applicaties die zijn afgestemd op een breed scala aan gebruikersvereisten. Dit vertegenwoordigt een aanzienlijke vooruitgang op het gebied van natuurlijke taalverwerking, omdat deze ingewikkelde verbindingen dienen als het fundamentele raamwerk van LangChain en naadloze interacties tussen meerdere grote taalmodellen (LLM's) mogelijk maken.
Maar eerst: waarom kettingen?
Kettingen zijn van onschatbare waarde vanwege hun vermogen om moeiteloos verschillende componenten te combineren, waardoor een unieke en samenhangende toepassing ontstaat. Door het creëren van ketens kunnen meerdere elementen naadloos samenkomen. Stel je dit scenario voor: een keten is gemaakt om gebruikersinvoer op te nemen, deze op te poetsen met behulp van een PromptTemplate en vervolgens dit verfijnde antwoord door te geven aan een groot taalmodel (LLM). Dit gestroomlijnde proces vereenvoudigt niet alleen de algehele functionaliteit van het systeem, maar verrijkt het ook. In wezen fungeren ketens als de spil, waardoor verschillende delen van de applicatie naadloos met elkaar worden verbonden en de mogelijkheden ervan worden vergroot. Laten we dit samenvatten:
- Het integreren van promptsjablonen met LLM's zorgt voor een krachtige synergie.
- Door de uitvoer van de ene LLM te nemen en deze te gebruiken als invoer voor de volgende, wordt het haalbaar om meerdere LLM's opeenvolgend met elkaar te verbinden.
- Door LLM's te combineren met externe gegevens kan het systeem effectief op vragen reageren.
- Het integreren van LLM's met langetermijngeheugen, zoals chatgeschiedenis, verbetert de algehele context en diepte van interacties.
Bovendien bieden ketens ons de mogelijkheid om complexe toepassingen te bouwen door meerdere ketens met elkaar te verbinden of door ketens met andere vitale elementen te integreren. Deze aanpak maakt een geavanceerde en genuanceerde methode mogelijk voor het ontwikkelen van applicaties, waardoor ingewikkelde en geavanceerde functionaliteiten mogelijk zijn.
Soorten kettingen
Er zijn veel verschillende ketens in Langchain die we kunnen gebruiken. Hier doorlopen we drie van de fundamentele ketens: LLM Chain, Sequential Chain en Router Chain.
LLM-keten – De eenvoudigste keten
De meest basale ketenvorm binnen dit systeem is de LLMChain, algemeen erkend en fundamenteel. De werking ervan omvat een gestructureerde opstelling, inclusief een PromptTemplate, een OpenAI-model (een Large Language Model of een ChatModel) en een optionele uitvoerparser. Binnen deze opstelling accepteert de LLMChain verschillende invoerparameters. Het maakt gebruik van de PromptTemplate om deze invoer om te zetten in een samenhangende prompt. Deze gepolijste prompt wordt vervolgens in het model ingevoerd. Na ontvangst van de uitvoer gebruikt de LLMChain de OutputParser, indien aanwezig, om het resultaat verder te verfijnen en op te maken in de uiteindelijk bruikbare vorm. Om de functionaliteit van LLM-ketens te illustreren, bekijken we het concrete voorbeeld. Een concreet voorbeeld dat de functionaliteit van LLM-ketens illustreert, wordt hieronder beschreven:
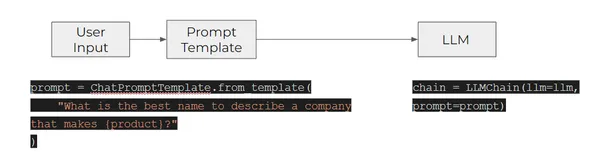
- Het werkt door de invoer van een gebruiker door te geven aan het eerste element in de keten – een PromptTemplate – om de invoer in een bepaalde prompt te formatteren.
- De opgemaakte prompt wordt vervolgens doorgegeven aan het volgende (en laatste) element in de keten: een LLM.
Knutselkettingen – LLM-ketting
Het creëren van ketens, vooral LLM-ketens, is een nauwgezette onderneming, waarvoor het gebruik van grote taalmodellen in LangChain vereist is. Deze ketens dienen als ingewikkelde kanalen, die een soepele uitwisseling van informatie en betrokkenheid mogelijk maken. Door een zorgvuldige structurering kunnen ontwikkelaars levendige applicaties ontwerpen die in staat zijn de input van gebruikers te begrijpen, LLM's gebruiken om intelligente reacties te genereren en de output aanpassen om effectief aan specifieke behoeften te voldoen.
Laten we nu dieper kijken naar hoe we de LLM-ketens in de Langchain kunnen gebruiken.
Noodzakelijke bibliotheken importeren
import langchain
import openai
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate from getpass import getpass
OPENAI_API_KEY = getpass()
Initialiseer LLM en promptsjabloon
We initialiseren het OpenAI Large Language Model met specifieke parameters, waaronder een temperatuur van 0.9, die de diversiteit van de gegenereerde reacties beïnvloedt. Bovendien moeten gebruikers een 'PromptTemplate' definiëren om een variabele (in dit geval 'product') in te voeren en een gestandaardiseerde promptstructuur te creëren. Tijdens runtime kan de tijdelijke aanduiding '{product}' dynamisch worden gevuld met verschillende productnamen.
llm = OpenAI(temperature=0.9, openai_api_key=OPENAI_API_KEY )
prompt = PromptTemplate( input_variables=["product"], template="What is a good name for a company that makes {product}?",
)
Een ketting creëren
We maken een exemplaar van de klasse 'LLMChain', met behulp van een vooraf gedefinieerd OpenAI Large Language Model en een gespecificeerde promptsjabloon. Nu hebben we de mogelijkheid om de keten toe te passen op een product zoals een “gaminglaptop” met behulp van de opdracht chain.run. Hierdoor kan de keten op dynamische wijze reacties op maat van deze specifieke productinput verwerken en genereren.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt, verbose=True) print(chain.run("gaming laptop"))Output:

Op basis hiervan krijgen we de naam van een bedrijf genaamd “GamerTech Laptops”.
Sequentiële keten
Een sequentiële keten is een keten die verschillende individuele ketens combineert, waarbij de output van de ene keten als input dient voor de volgende in een continue reeks. Het werkt door een reeks opeenvolgende ketens uit te voeren.
Er zijn twee soorten opeenvolgende ketens:
Eenvoudige opeenvolgende keten, die een enkele invoer en uitvoer afhandelt, en
Sequentiële ketenbeheer meerdere in- en uitgangen tegelijkertijd.

- Een sequentiële keten voegt verschillende ketens samen door de uitvoer van de ene keten te gebruiken als invoer voor de volgende.
- Het werkt door een reeks opeenvolgende ketens uit te voeren.
- Deze aanpak is waardevol wanneer u het resultaat van de ene operatie als uitgangspunt voor de volgende moet gebruiken, waardoor een naadloze stroom van processen ontstaat.
Eenvoudige opeenvolgende keten
Opeenvolgende ketens bestaan in hun eenvoudigste vorm uit stappen waarbij elke stap één input kost en één output produceert. De output van de ene stap wordt de input voor de volgende.
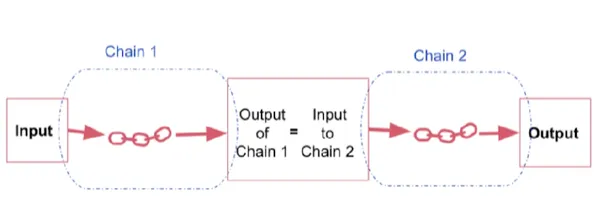
Deze eenvoudige aanpak is effectief bij het omgaan met subketens die zijn ontworpen voor enkelvoudige inputs en outputs. Het zorgt voor een soepele en continue informatiestroom, waarbij elke stap de output naadloos doorgeeft aan de volgende stap.
Knutselketens – Eenvoudige opeenvolgende ketens
Eenvoudige sequentiële ketens zorgen ervoor dat een enkele invoer een reeks samenhangende transformaties kan ondergaan, wat resulteert in een verfijnde uitvoer. Deze sequentiële aanpak zorgt voor een systematische en efficiënte verwerking van gegevens, waardoor het ideaal is voor scenario's waarin een lineaire stroom van informatieverwerking essentieel is
Benodigde bibliotheken importeren
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.prompts import ChatPromptTemplate
from langchain.chains import SimpleSequentialChain
Initialiseren en ketenen
We initialiseren een OpenAI Large Language Model met een temperatuurinstelling van 0.7 en een API-sleutel. Vervolgens maken we een specifieke chatpromptsjabloon met een tijdelijke aanduiding voor een productnaam. Vervolgens vormen we een LLMChain, waarmee antwoorden kunnen worden gegenereerd op basis van de opgegeven prompt. We herhalen dit proces voor twee verschillende ketens.
# This is an LLMChain to write first chain. llm = OpenAI(temperature=0.7, openai_api_key=OPENAI_API_KEY)
first_prompt = ChatPromptTemplate.from_template( "What is the best name to describe a company that makes {product}?"
)
chain_one = LLMChain(llm=llm, prompt=first_prompt) # This is an LLMChain to write second chain. llm = OpenAI(temperature=0.7, openai_api_key=OPENAI_API_KEY)
second_prompt = ChatPromptTemplate.from_template( "Write a 20 words description for the following company:{company_name}"
)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
Twee kettingen aan elkaar koppelen
Creëer een algehele eenvoudige sequentiële keten, bestaande uit twee verschillende individuele ketens, chain_one en chain_two. Voer dit uit met de invoer "gaminglaptop", deze verwerkt de invoer opeenvolgend via de gedefinieerde ketens en levert een uitvoer die de stapsgewijze sequentiële uitvoering van de ketens demonstreert.
overall_simple_chain = SimpleSequentialChain(chains=[chain_one, chain_two], verbose=True )
overall_simple_chain.run("gaming laptop")Output:

Sequentiële keten
Niet alle sequentiële ketens werken met een enkele stringinvoer en -uitvoer. In meer ingewikkelde opstellingen verwerken deze ketens meerdere inputs en genereren ze meerdere uiteindelijke outputs. De zorgvuldige naamgeving van input- en outputvariabelen heeft een belangrijke betekenis in deze complexe ketens.
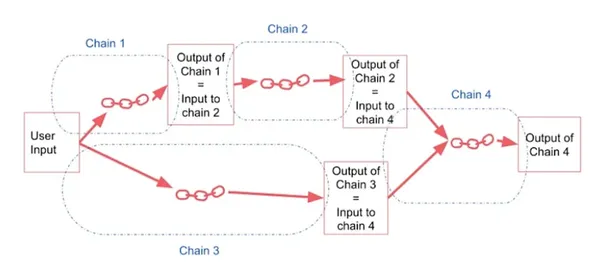
Een meer algemene vorm van sequentiële ketens maakt meerdere inputs/outputs mogelijk. Elke stap in de keten kan meerdere inputs vergen.
Maakketens – Opeenvolgende ketens
Benodigde bibliotheken importeren
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.prompts import ChatPromptTemplate
from langchain.chains import SequentialChain llm = OpenAI(temperature=0.7, openai_api_key=OPENAI_API_KEY)
Initialiseren en ketenen
We definiëren een promptsjabloon, waarin het systeem wordt geïnstrueerd om een specifieke taak uit te voeren. Vervolgens maken we een overeenkomstige LLMChain, met behulp van het aangewezen Large Language Model (LLM) en de gedefinieerde promptsjabloon. De keten is opgezet om de invoer te ontvangen, deze door de LLM te sturen en de uitvoer te genereren. We herhalen dit proces om vier verschillende ketens te creëren.
Review = "Les ordinateurs portables GamersTech impressionne par ses performances exceptionnelles et son design élégant. De sa configuration matérielle robuste à un clavier RVB personnalisable et un système de refroidissement efficace, il établit un équilibre parfait entre prouesses de jeu et portabilité." # prompt template 1: translate to English first_prompt = ChatPromptTemplate.from_template( "Translate the following review to english:" "nn{Review}"
) # chain 1: input= Review and output= English_Review chain_one = LLMChain(llm=llm, prompt=first_prompt, output_key="English_Review" ) # prompt template 2: Summarize the English review second_prompt = ChatPromptTemplate.from_template( "Can you summarize the following review in 1 sentence:" "nn{English_Review}"
) # chain 2: input= English_Review and output= summary chain_two = LLMChain(llm=llm, prompt=second_prompt, output_key="summary" )
# prompt template 3: translate to English third_prompt = ChatPromptTemplate.from_template( "What language is the following review:nn{Review}"
) # chain 3: input= Review and output= language chain_three = LLMChain(llm=llm, prompt=third_prompt, output_key="language" )
# prompt template 4: follow up message fourth_prompt = ChatPromptTemplate.from_template( "Write a follow up response to the following " "summary in the specified language:" "nnSummary: {summary}nnLanguage: {language}"
) # chain 4: input= summary, language and output= followup_message chain_four = LLMChain(llm=llm, prompt=fourth_prompt, output_key="followup_message" )
Twee kettingen aan elkaar koppelen
Er wordt een algehele sequentiële keten met de naam 'overall_chain' gecreëerd, waarin vier individuele ketens 'chain_one', 'chain_two', 'chain_three' en 'chain_four' zijn opgenomen. De invoervariabele ‘Review’ wordt via deze ketens verwerkt en genereert drie verschillende uitvoervariabelen: ‘English_Review’, ‘samenvatting’ en ‘followup_message’. De 'overall_chain' voert de inputbeoordeling uit via de gespecificeerde ketens en produceert deze outputs, waardoor een gestructureerde, sequentiële verwerkingsstroom met gedetailleerde outputs wordt vergemakkelijkt.
overall_chain = SequentialChain( chains=[chain_one, chain_two, chain_three, chain_four], input_variables=["Review"], output_variables=["English_Review", "summary","followup_message"], verbose=True
)
overall_chain(Review)
uitgang

Routerketen
De Router Chain wordt gebruikt voor ingewikkelde taken. Als we meerdere subketens hebben, die elk gespecialiseerd zijn voor een bepaald type invoer, kunnen we een routerketen hebben die beslist aan welke subketen de invoer moet worden doorgegeven.
Het bestaat uit:
- Routerketting: Het is verantwoordelijk voor het selecteren van de volgende keten die moet worden opgeroepen.
- Bestemmingsketens: Ketens waarnaar de routerketen kan routeren.
- Standaard keten: Wordt gebruikt wanneer de router niet kan beslissen welke subketen moet worden gebruikt.
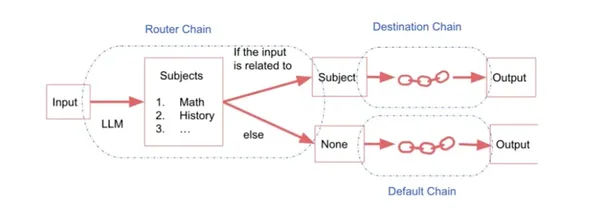
Dit houdt in dat een input naar een specifieke keten wordt gestuurd op basis van wat die input precies is. Wanneer er meerdere subketens zijn, elk op maat gemaakt voor verschillende invoertypen, komt een routerketen in beeld. Deze routerketen fungeert als beslisser en bepaalt naar welke gespecialiseerde subketen de invoer moet worden verzonden. In wezen maakt het de naadloze routering van invoer naar de juiste subketens mogelijk, waardoor een efficiënte en nauwkeurige verwerking wordt gegarandeerd op basis van de specifieke kenmerken van de invoer.
Knutselkettingen – Routerketting
Benodigde bibliotheken importeren
from langchain.chains.router import MultiPromptChain
from langchain.chains.router.llm_router import LLMRouterChain,RouterOutputParser
from langchain.prompts import PromptTemplate llm = OpenAI(temperature=0.7, openai_api_key=OPENAI_API_KEY)Prompt-sjablonen definiëren
Laten we een scenario overwegen waarin we input moeten sturen naar gespecialiseerde ketens op basis van onderwerpen als wiskunde, natuurkunde, geschiedenis of informatica. Om dit te bereiken maken we voor elk onderwerp verschillende prompts: een voor natuurkundevragen, een andere voor wiskundevragen, een derde voor geschiedenisvragen en een vierde voor informaticagerelateerde zaken. We ontwerpen deze aanwijzingen zorgvuldig om tegemoet te komen aan de unieke behoeften van elk vakgebied.
physics_template = """You are a very smart physics professor. You are great at answering questions about physics in a concise
and easy to understand manner. When you don't know the answer to a question you admit
that you don't know. Here is a question:
{input}""" math_template = """You are a very good mathematician. You are great at answering math questions. You are so good because you are able to break down hard problems into their component parts,
answer the component parts, and then put them together
to answer the broader question. Here is a question:
{input}""" history_template = """You are a very good historian. You have an excellent knowledge of and understanding of people,
events and contexts from a range of historical periods. You have the ability to think, reflect, debate, discuss and evaluate the past. You have a respect for historical evidence
and the ability to make use of it to support your explanations and judgements. Here is a question:
{input}"""
Bovendien kan gedetailleerde informatie, inclusief namen en beschrijvingen, aan deze promptsjablonen worden toegevoegd. Deze extra context biedt een uitgebreid inzicht in het doel van elke sjabloon. Deze informatie wordt vervolgens aan de routerketen geleverd. De routerketen bepaalt vervolgens naar welke subketen moet worden gerouteerd op basis van het specifieke onderwerp, en zorgt ervoor dat het juiste promptsjabloon wordt gebruikt voor nauwkeurige en effectieve antwoorden.
# Defining the prompt templates
prompt_infos = [ { "name": "physics", "description": "Good for answering questions about physics", "prompt_template": physics_template }, { "name": "math", "description": "Good for answering math questions", "prompt_template": math_template }, { "name": "History", "description": "Good for answering history questions", "prompt_template": history_template }
]
Bestemmingsketens creëren
Vervolgens verschuift onze focus naar het maken van bestemmingsketens. Deze ketens worden geactiveerd door de RouterChain en functioneren als individuele taalmodelketens, met name LLM-ketens. Bovendien wordt er een standaardketen geschetst om situaties aan te pakken waarin de router op dubbelzinnigheid stuit en niet kan bepalen welke subketen geschikt is om te gebruiken. Deze standaardketen fungeert als een terugvaloptie en zorgt voor een reactie, zelfs in geval van besluiteloosheid.
destination_chains = {}
for p_info in prompt_infos: name = p_info["name"] prompt_template = p_info["prompt_template"] prompt = ChatPromptTemplate.from_template(template=prompt_template) chain = LLMChain(llm=llm, prompt=prompt) destination_chains[name] = chain destinations = [f"{p['name']}: {p['description']}" for p in prompt_infos]
destinations_str = "n".join(destinations)
Een multi-prompt-routersjabloon maken
We stellen een sjabloon op dat de LLM begeleidt bij het aansturen van interacties tussen verschillende ketens. Dit sjabloon schetst niet alleen de specifieke taakinstructies, maar dicteert ook het precieze formaat waaraan de uitvoer moet voldoen, waardoor een gestandaardiseerd en consistent reactiemechanisme wordt gegarandeerd.
MULTI_PROMPT_ROUTER_TEMPLATE = """Given a raw text input to a language model select the model prompt best suited for the input. You will be given the names of the available prompts and a description of what the prompt is best suited for. You may also revise the original input if you think that revising
it will ultimately lead to a better response from the language model. << FORMATTING >>
Return a markdown code snippet with a JSON object formatted to look like:
```json
{{{{ "destination": string name of the prompt to use or "DEFAULT" "next_inputs": string a potentially modified version of the original input
}}}}
``` REMEMBER: "destination" MUST be one of the candidate prompt names specified below OR it can be "DEFAULT" if the input is not
well suited for any of the candidate prompts.
REMEMBER: "next_inputs" can just be the original input if you don't think any modifications are needed. << CANDIDATE PROMPTS >>
{destinations} << INPUT >>
{{input}} << OUTPUT (remember to include the ```json)>>"""
Een standaardketen maken
Er is een vooraf ingesteld promptsjabloon gemaakt voor alle typen invoertekst. Een bijbehorende LLMChain, genaamd 'default_chain', wordt vervolgens gemaakt met behulp van het aangewezen grote taalmodel en de vooraf gedefinieerde prompt. Dankzij deze opstelling kan het Grote Taalmodel reacties genereren op basis van de ingevoerde tekst.
default_prompt = ChatPromptTemplate.from_template("{input}")
default_chain = LLMChain(llm=llm, prompt=default_prompt)Routersjabloon maken
In de toekomst wordt een flexibel routersjabloon ontwikkeld, dat een reeks categorieën omvat, zoals natuurkunde, wiskunde, geschiedenis en informatica. Op basis van deze sjabloon wordt een afzonderlijke promptsjabloon gemaakt die op maat is gemaakt voor de router. Met behulp van dit aangepaste sjabloon wordt een routerketen tot stand gebracht, waarbij gebruik wordt gemaakt van het Large Language Model en de bijbehorende routerprompt.
Om de besluitvormingsmogelijkheden te verbeteren, wordt een routeruitvoerparser geïntroduceerd. Deze parser helpt de routerketen bij het efficiënt navigeren tussen subketens. Deze alomvattende regeling zorgt ervoor dat de input precies naar specifieke subketens wordt gestuurd, wat leidt tot nauwkeurige en gerichte reacties in verschillende bestemmingscategorieën.
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format( destinations=destinations_str
)
router_prompt = PromptTemplate( template=router_template, input_variables=["input"], output_parser=RouterOutputParser(),
) router_chain = LLMRouterChain.from_llm(llm, router_prompt)
Alles aan elkaar koppelen
Er wordt een MultiPromptChain gecreëerd, waarin een routerketen is opgenomen om invoer op intelligente wijze naar specifieke bestemmingsketens te routeren. Bovendien is er een standaardketen opgenomen om gevallen af te handelen waarin de routerketen op dubbelzinnigheid kan stuiten, waardoor een gestructureerde en effectieve verwerkingsstroom wordt gegarandeerd met uitgebreide logboekregistratie voor gedetailleerde inzichten.
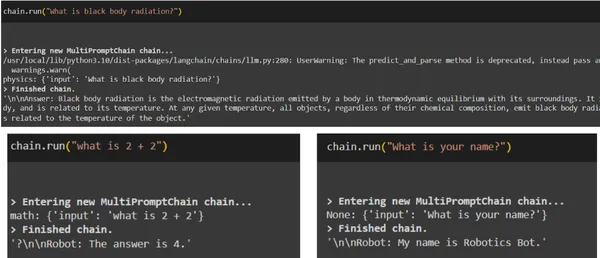
chain = MultiPromptChain(router_chain=router_chain, destination_chains=destination_chains, default_chain=default_chain, verbose=True )uitgang
Real-world gebruiksscenario's van Langchain
Duik in het echte gebruik en de prestaties van oplossingen die worden aangestuurd door Large Language Models (LLM's), en demonstreer hun gevarieerde invloed in verschillende sectoren. Binnen de klantenondersteuning heeft de samenwerking tussen LangChain en LLM's de dienstverlening getransformeerd door de implementatie van slimme chatbots. Deze bots bieden onmiddellijke, gepersonaliseerde ondersteuning en beheren op efficiënte wijze een grote toestroom aan vragen. Door de wachttijden te verkorten, verhogen ze de klanttevredenheid aanzienlijk.
E-commerce
LangChain maakt gebruik van de kracht van Large Language Models (LLM's) om het winkeltraject te verbeteren. Ontwikkelaars kunnen applicaties maken die productspecificaties, gebruikerslikes en aankooppatronen begrijpen. Door de mogelijkheden van LLM's te benutten, bieden deze platforms productaanbevelingen op maat, beantwoorden ze vragen van klanten en creëren ze boeiende productbeschrijvingen. Dit leidt tot hogere verkopen en een hogere klantbetrokkenheid.
Gezondheidszorg
LangChain zorgt voor een revolutie in de patiëntenzorg en diagnose via toepassingen die worden aangedreven door Large Language Models (LLM's). Ontwikkel met de steun van LangChain virtuele assistenten om medische vragen te begrijpen. Deze virtuele assistenten bieden nauwkeurige informatie, beoordelen patiënten op basis van symptomen en versnellen de toegang tot gezondheidszorgkennis. Deze vooruitgang verlicht niet alleen de werkdruk voor medische professionals, maar stelt patiënten ook in staat goed geïnformeerde beslissingen te nemen over hun gezondheid.
Inhoud genereren
LangChain stelt ontwikkelaars in staat applicaties te creëren die fantasierijke en contextueel relevante inhoud produceren, inclusief blogartikelen en productbeschrijvingen. Deze applicaties ondersteunen makers van inhoud door de creativiteit te vergroten, het schrijfproces te stroomlijnen en de consistentie in toon en stijl te behouden.
De praktische implementaties die hier worden benadrukt demonstreren de veelzijdigheid en impact van oplossingen die worden aangestuurd door grote taalmodellen (LLM's) in verschillende industrieën. Het potentieel van LangChain stelt ontwikkelaars in staat innovatieve oplossingen te creëren, de activiteiten te stroomlijnen, de gebruikersbetrokkenheid te verbeteren en de bedrijfsgroei te stimuleren. Er zijn talloze succesverhalen, variërend van aanzienlijke kortere oplostijden voor supporttickets tot hogere klanttevredenheidscijfers voor e-commerce-chatbots, die de tastbare voordelen van LLM-aangedreven applicaties laten zien.
Conclusie
LangChain biedt een uitgebreid scala aan mogelijkheden voor het ontwikkelen van applicaties die bestaan uit Large Language Model-mogelijkheden. Of uw focus nu ligt op taken als tekstaanvulling, taalvertaling, sentimentanalyse, tekstsamenvatting of herkenning van benoemde entiteiten, LangChain is een veelzijdige oplossing.
LangChain biedt een uitgebreid raamwerk voor het bouwen van krachtige applicaties via intelligente ketentechnieken. Door de complexiteit van verschillende ketens en hun configuraties te begrijpen, kunnen ontwikkelaars oplossingen op maat creëren voor complexe taken. Het routeren van invoer via Router Chains voegt een laag van intelligente besluitvorming toe, waardoor we ervoor zorgen dat we invoer naar de meest geschikte verwerkingspaden leiden. Met deze kennis kunnen ontwikkelaars innovatieve toepassingen in verschillende sectoren ontwerpen, processen stroomlijnen, gebruikerservaringen verbeteren en uiteindelijk een revolutie teweegbrengen in de manier waarop we omgaan met taal in de digitale wereld.
Key Takeaways
- LLMChain, de eenvoudigste vorm van keten in LangChain, transformeert gebruikersinvoer met behulp van een PromptTemplate en biedt een fundamenteel en breed inzetbaar raamwerk voor interactie met grote taalmodellen (LLM's).
- Opeenvolgende ketens in LangChain, of het nu gaat om eenvoudige sequentiële ketens of meer complexe opstellingen, zorgen ervoor dat de output van de ene stap dient als input voor de volgende, waardoor het proces wordt vereenvoudigd en ingewikkelde interacties in verschillende toepassingen mogelijk zijn.
- De Router Chain in LangChain fungeert als een intelligente beslisser en stuurt specifieke input naar gespecialiseerde subketens. Deze naadloze routering verbetert de efficiëntie van taken door invoer te matchen met de meest geschikte verwerkingsketens.
Veelgestelde Vragen / FAQ
A1: LangChain is een geavanceerde technologie die gebruik maakt van Large Language Models (LLM's) om taalverwerkingstaken te stroomlijnen. Het integreert verschillende componenten zoals LLMChains en Router Chains, waardoor naadloze taakroutering en efficiënte verwerking mogelijk zijn, wat leidt tot de ontwikkeling van intelligente applicaties.
A2: LLMChain is een fundamenteel element van LangChain. Het werkt door gebruik te maken van een PromptTemplate om gebruikersinvoer te formatteren en deze ter verwerking door te geven aan een LLM. De optionele OutputParser verfijnt de uitvoer en zorgt ervoor dat deze aansluit bij het gewenste formaat, waardoor LLMChain een essentieel hulpmiddel wordt voor het genereren van coherente talen.
A3: Sequentiële ketens combineren verschillende subketens, waardoor de output van de ene als input kan dienen voor de volgende. Eenvoudige sequentiële ketens verwerken afzonderlijke invoer en uitvoer, terwijl complexere sequentiële ketens meerdere invoer en uitvoer tegelijkertijd beheren, waardoor de informatiestroom in LangChain-toepassingen wordt gestroomlijnd.
A4: Routerketens zijn cruciaal voor ingewikkelde taken met meerdere gespecialiseerde subketens. Ze bepalen welke subketen input moet routeren op basis van specifieke kenmerken. De routerketen leidt, samen met bestemmingsketens en een standaardketen, de invoer efficiënt naar de meest geschikte subketen, waardoor een nauwkeurige verwerking wordt gegarandeerd.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/10/a-comprehensive-guide-to-using-chains-in-langchain/

