Introductie
De komst van AI en machinaal leren heeft een revolutie teweeggebracht in de manier waarop we met informatie omgaan, waardoor het gemakkelijker wordt om deze op te halen, te begrijpen en te gebruiken. In deze praktische handleiding verkennen we het creëren van een geavanceerde vraag- en antwoordassistent, mogelijk gemaakt door LLamA2 en LLamAIndex, waarbij gebruik wordt gemaakt van de modernste taalmodellen en indexeringsframeworks om moeiteloos door een zee van PDF-documenten te navigeren. Deze tutorial is ontworpen om ontwikkelaars, datawetenschappers en tech-enthousiastelingen te voorzien van de tools en kennis om een Retrieval-Augmented Generation (RAG)-systeem te bouwen dat op de schouders van giganten in het NLP-domein staat.
In onze zoektocht om de creatie van een AI-gestuurde vraag- en antwoordassistent te demystificeren, vormt deze gids een brug tussen complexe theoretische concepten en hun praktische toepassing in scenario's uit de echte wereld. Door het geavanceerde taalbegrip van LLamA2 te integreren met de efficiënte mogelijkheden voor het ophalen van informatie van LLamAIndex, streven we ernaar een systeem te construeren dat vragen nauwkeurig beantwoordt en ons begrip van de mogelijkheden en uitdagingen op het gebied van NLP verdiept. Dit artikel dient als een uitgebreide routekaart voor liefhebbers en professionals, waarin de synergie tussen geavanceerde modellen en de steeds evoluerende eisen van de informatietechnologie worden benadrukt.

leerdoelen
- Ontwikkel een RAG-systeem met behulp van het LlamA2-model van Hugging Face.
- Integreer meerdere PDF-documenten.
- Indexdocumenten voor efficiënt terugvinden.
- Maak een querysysteem.
- Creëer een robuuste assistent die verschillende vragen kan beantwoorden.
- Focus op praktische implementatie in plaats van alleen op theoretische aspecten.
- Ga aan de slag met hands-on coderen en toepassingen in de echte wereld.
- Maak de complexe wereld van NLP toegankelijk en boeiend.
Inhoudsopgave
LlamA2-model
LLamA2 is een baken van innovatie op het gebied van natuurlijke taalverwerking en verlegt de grenzen van wat mogelijk is met taalmodellen. De architectuur, ontworpen voor zowel efficiëntie als effectiviteit, maakt een ongekend begrip en het genereren van mensachtige tekst mogelijk. In tegenstelling tot zijn voorgangers zoals BERT en GPT biedt LLamA2 een meer genuanceerde benadering van de verwerking van taal, waardoor het bijzonder bedreven is in taken die een diep begrip vereisen, zoals het beantwoorden van vragen. Het nut ervan bij verschillende NLP-taken, van samenvatting tot vertaling, demonstreert zijn veelzijdigheid en vermogen bij het aanpakken van complexe taalkundige uitdagingen.

LlamAIndex begrijpen
Indexering is de ruggengraat van elk efficiënt systeem voor het ophalen van informatie. LlamAIndex, een raamwerk ontworpen voor het indexeren en opvragen van documenten, onderscheidt zich door een naadloze manier te bieden om grote verzamelingen documenten te beheren. Het gaat niet alleen om het opslaan van informatie; het gaat erom het in een oogwenk toegankelijk en opvraagbaar te maken.

Het belang van LlamAIndex kan niet genoeg worden benadrukt, omdat het realtime verwerking van zoekopdrachten in uitgebreide databases mogelijk maakt, waardoor onze vraag- en antwoordassistent snelle en nauwkeurige antwoorden kan geven op basis van een uitgebreide kennisbank.
Tokenisatie en insluitingen
De eerste stap bij het begrijpen van taalmodellen bestaat uit het opsplitsen van tekst in hanteerbare stukken, een proces dat bekend staat als tokenisatie. Deze fundamentele taak is cruciaal voor het voorbereiden van gegevens voor verdere verwerking. Na tokenisatie komt het concept van inbedding in het spel, waarbij woorden en zinnen worden vertaald in numerieke vectoren.
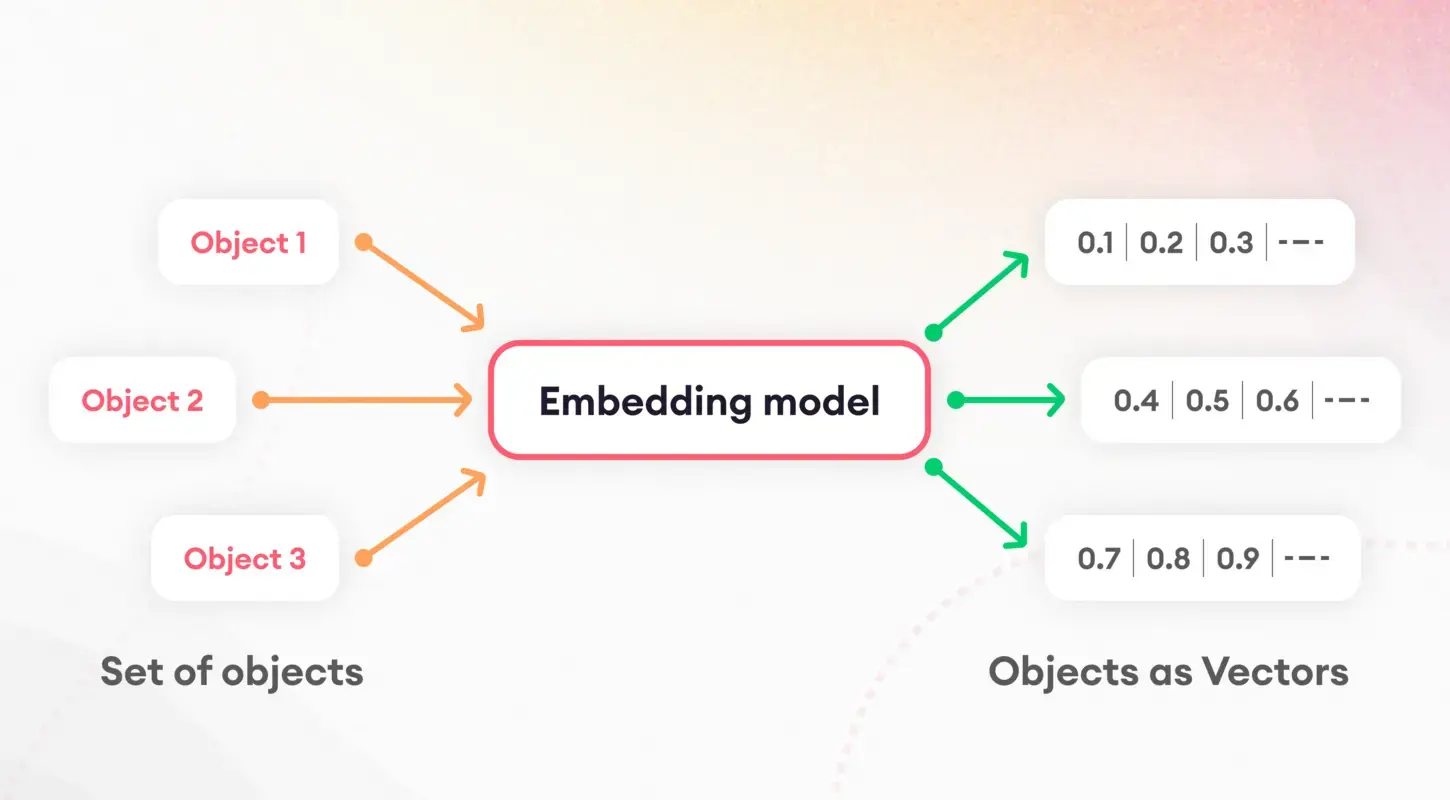
Deze inbedding legt de essentie van taalkundige kenmerken vast, waardoor modellen de onderliggende semantische eigenschappen van tekst kunnen onderscheiden en gebruiken. Met name de inbedding van zinnen speelt een cruciale rol bij taken als de gelijkenis en het terugvinden van documenten, en vormt de basis van onze indexeringsstrategie.
Modelkwantisering
Modelkwantisering presenteert een strategie om de prestaties en efficiëntie van onze vraag- en antwoordassistent te verbeteren. Door de precisie van de numerieke berekeningen van het model te verminderen, kunnen we de omvang ervan aanzienlijk verkleinen en de inferentietijden versnellen. Hoewel dit proces een afweging tussen precisie en efficiëntie introduceert, is het vooral waardevol in omgevingen met beperkte middelen, zoals mobiele apparaten of webapplicaties. Door een zorgvuldige toepassing stelt kwantisering ons in staat een hoog nauwkeurigheidsniveau te handhaven en tegelijkertijd te profiteren van verminderde latentie en opslagvereisten.
ServiceContext en query-engine
De ServiceContext binnen LlamAIndex is een centrale hub voor het beheren van bronnen en configuraties, waardoor ervoor wordt gezorgd dat ons systeem soepel en efficiënt werkt. De lijm houdt onze applicatie bij elkaar, waardoor een naadloze integratie tussen de applicaties mogelijk wordt LlamA2-model, het insluitingsproces en de geïndexeerde documenten. Aan de andere kant is de query-engine het werkpaard dat gebruikersvragen verwerkt, waarbij de geïndexeerde gegevens worden gebruikt om snel relevante informatie op te halen. Deze dubbele opzet zorgt ervoor dat onze vraag- en antwoordassistent gemakkelijk complexe vragen kan afhandelen en gebruikers snelle en nauwkeurige antwoorden kan geven.
Implementatie
Laten we eens in de implementatie duiken. Houd er rekening mee dat ik Google Colab heb gebruikt om dit project te maken.
!pip install pypdf
!pip install -q transformers einops accelerate langchain bitsandbytes
!pip install sentence_transformers
!pip install llama_indexDeze commando's vormen de basis voor het installeren van de benodigde bibliotheken, inclusief transformers voor modelinteractie en zin_transformers voor inbedding. De installatie van llama_index is cruciaal voor ons indexeringsframework.
Vervolgens initialiseren we onze componenten (zorg ervoor dat u een map met de naam 'data' maakt in de sectie Bestanden in Google Colab en upload vervolgens de pdf naar de map):
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.prompts.prompts import SimpleInputPrompt
# Reading documents and setting up the system prompt
documents = SimpleDirectoryReader("/content/data").load_data()
system_prompt = """
You are a Q&A assistant. Your goal is to answer questions based on the given documents.
"""
query_wrapper_prompt = SimpleInputPromptNadat we onze omgeving hebben opgezet en de documenten hebben gelezen, maken we een systeemprompt om de reacties van het LLamA2-model te begeleiden. Deze sjabloon zorgt ervoor dat de uitvoer van het model aansluit bij onze verwachtingen op het gebied van nauwkeurigheid en relevantie.
!huggingface-cli login
Het bovenstaande commando is een toegangspoort tot de enorme verzameling modellen van Hugging Face. Er is een token nodig voor authenticatie.
U moet de volgende link bezoeken: Gezicht knuffelen (zorg ervoor dat u zich eerst aanmeldt bij Hugging Face), maak vervolgens een nieuw token aan, geef een naam op voor het project, selecteer Type als gelezen en klik vervolgens op Een token genereren.
Deze stap onderstreept het belang van het beveiligen en personaliseren van uw ontwikkelomgeving.
import torch
llm = HuggingFaceLLM(
context_window=4096,
max_new_tokens=256,
generate_kwargs={"temperature": 0.0, "do_sample": False},
system_prompt=system_prompt,
query_wrapper_prompt=query_wrapper_prompt,
tokenizer_name="meta-llama/Llama-2-7b-chat-hf",
model_name="meta-llama/Llama-2-7b-chat-hf",
device_map="auto",
model_kwargs={"torch_dtype": torch.float16, "load_in_8bit":True}
)Hier initialiseren we het LLamA2-model met specifieke parameters die zijn afgestemd op ons vraag- en antwoordsysteem. Deze opstelling benadrukt de veelzijdigheid van het model en het vermogen om zich aan te passen aan verschillende contexten en toepassingen.
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index.embeddings.langchain import LangchainEmbedding
embed_model = LangchainEmbedding(
HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2"))De keuze van het inbeddingsmodel is van cruciaal belang voor het vastleggen van de semantische essentie van onze documenten. Door Zinstransformatoren te gebruiken, zorgen we ervoor dat ons systeem de gelijkenis en relevantie van tekstuele inhoud nauwkeurig kan meten, waardoor de effectiviteit van het indexeringsproces wordt vergroot.
service_context = ServiceContext.from_defaults(
chunk_size=1024,
llm=llm,
embed_model=embed_model
)De ServiceContext wordt geïnstantieerd met standaardinstellingen, waarbij ons LLamA2-model wordt gekoppeld en het model wordt ingebed in een samenhangend raamwerk. Deze stap zorgt ervoor dat alle systeemcomponenten geharmoniseerd zijn en gereed zijn voor indexerings- en querybewerkingen.
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()Deze regels markeren het hoogtepunt van ons installatieproces, waarbij we onze documenten indexeren en de query-engine voorbereiden. Deze opzet is van cruciaal belang voor de transitie van gegevensvoorbereiding naar bruikbare inzichten, waardoor onze vraag- en antwoordassistent op vragen kan reageren op basis van de geïndexeerde inhoud.
response = query_engine.query("Give me a Summary of the PDF in 10 pointers.")
print(response)Ten slotte hebben we ons systeem getest door het te bevragen op samenvattingen en inzichten uit onze documentverzameling. Deze interactie demonstreert het praktische nut van onze vraag- en antwoordassistent en toont de naadloze integratie van LLamA2, LLamAIndex en de onderliggende NLP-technologieën die het mogelijk maken.
Output:

Ethische en juridische implicaties
Bij het ontwikkelen van door AI aangedreven vraag- en antwoordsystemen komen verschillende ethische en juridische overwegingen op de voorgrond. Het aanpakken van mogelijke vooroordelen in de trainingsgegevens is van cruciaal belang, evenals het garanderen van eerlijkheid en neutraliteit in de reacties. Bovendien is het naleven van de regelgeving inzake gegevensprivacy van het grootste belang, omdat deze systemen vaak gevoelige informatie verwerken. Ontwikkelaars moeten deze uitdagingen met toewijding en integriteit het hoofd bieden, waarbij ze zich moeten houden aan ethische principes die gebruikers en de integriteit van de verstrekte informatie beschermen.
Toekomstige richtingen en uitdagingen
Het veld van vraag- en antwoordsystemen is rijp voor innovatiemogelijkheden, van multimodale interacties tot domeinspecifieke toepassingen. Deze ontwikkelingen brengen echter hun eigen uitdagingen met zich mee, waaronder het schalen om grote documentcollecties te kunnen huisvesten en diversiteit in gebruikersvragen te garanderen. De voortdurende ontwikkeling en verfijning van modellen zoals LLamA2 en indexeringsframeworks zoals LLamAIndex zijn van cruciaal belang voor het overwinnen van deze hindernissen en het verleggen van de grenzen van wat mogelijk is in NLP.
Casestudy's en voorbeelden
Real-world implementaties van vraag- en antwoordsystemen, zoals klantenservicebots en educatieve tools, onderstrepen de veelzijdigheid en impact van technologieën als LLamA2 en LLamAIndex. Deze casestudies demonstreren de praktische toepassingen van AI in diverse industrieën en belichten de succesverhalen en geleerde lessen, waardoor waardevolle inzichten worden geboden voor toekomstige ontwikkelingen.
Conclusie
Deze handleiding heeft het landschap van het maken van een op PDF gebaseerde vraag- en antwoordassistent doorkruist, van de fundamentele concepten van LLamA2 en LLamAIndex tot de praktische implementatiestappen. Terwijl we de mogelijkheden van AI op het gebied van het ophalen en verwerken van informatie blijven onderzoeken en uitbreiden, is het potentieel om onze interactie met kennis te transformeren grenzeloos. Gewapend met deze tools en inzichten is de reis naar intelligentere en responsievere systemen nog maar net begonnen.
Key Takeaways
- Revolutionaire informatie-interactie: De integratie van AI en machine learning, geïllustreerd door LLamA2 en LLamAIndex, heeft de manier veranderd waarop we toegang krijgen tot en gebruik maken van informatie, waardoor de weg wordt vrijgemaakt voor geavanceerde vraag- en antwoordassistenten die moeiteloos door enorme collecties PDF-documenten kunnen navigeren.
- Praktische brug tussen theorie en toepassing: deze gids overbrugt de kloof tussen theoretische concepten en praktische implementatie, waardoor ontwikkelaars en tech-enthousiastelingen in staat worden gesteld Retrieval-Augmented Generation (RAG)-systemen te bouwen die gebruik maken van de modernste NLP-modellen en indexeringsframeworks.
- Belang van efficiënt indexeren: LLamAIndex speelt een cruciale rol bij het efficiënt ophalen van informatie door het indexeren van grote documentcollecties. Dit zorgt voor snelle en nauwkeurige antwoorden op vragen van gebruikers en verbetert de algehele functionaliteit van de vraag- en antwoordassistent.
- Optimalisatie voor prestaties en efficiëntie: Technieken zoals modelkwantisering verbeteren de prestaties en efficiëntie van vraag- en antwoordassistenten, waardoor lagere latentie- en opslagvereisten mogelijk zijn zonder concessies te doen aan de nauwkeurigheid.
- Ethische overwegingen en toekomstige richtingen: Het ontwikkelen van door AI aangedreven vraag- en antwoordsystemen vereist het aanpakken van ethische en juridische implicaties, waaronder het beperken van vooroordelen en gegevensprivacy. Vooruitkijkend bieden de ontwikkelingen op het gebied van vraag- en antwoordsystemen kansen voor innovatie, terwijl ze ook uitdagingen met zich meebrengen op het gebied van de schaalbaarheid en diversiteit van gebruikersvragen.
Veelgestelde vragen
Ant. LLamA2 biedt een meer genuanceerde benadering van taalverwerking, waardoor diepgaande begripstaken zoals het beantwoorden van vragen mogelijk worden. De architectuur geeft prioriteit aan efficiëntie en effectiviteit, waardoor het veelzijdig is voor verschillende NLP-taken.
Ant. LlamAIndex is een raamwerk voor het indexeren en opvragen van documenten, waardoor realtime verwerking van zoekopdrachten in uitgebreide databases mogelijk wordt gemaakt. Het zorgt ervoor dat vraag- en antwoordassistenten snel relevante informatie uit uitgebreide kennisbanken kunnen halen.
Ant. Inbedding, met name inbedding van zinnen, legt de semantische essentie van tekstuele inhoud vast, waardoor een nauwkeurige meting van gelijkenis en relevantie mogelijk wordt. Dit vergroot de effectiviteit van het indexeringsproces en verbetert het vermogen van de assistent om relevante antwoorden te geven.
Ant. Modelkwantisering optimaliseert de prestaties en efficiëntie door de omvang van numerieke berekeningen te verkleinen, waardoor de latentie en opslagvereisten afnemen. Hoewel het een afweging tussen precisie en efficiëntie introduceert, is het waardevol in omgevingen met beperkte middelen.
Ant. Ontwikkelaars moeten potentiële vooroordelen in trainingsgegevens aanpakken, eerlijkheid en neutraliteit in de reacties garanderen en zich houden aan de regelgeving inzake gegevensprivacy. Het handhaven van ethische principes beschermt gebruikers en handhaaft de integriteit van de informatie die door de vraag- en antwoordassistent wordt verstrekt.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2024/04/a-hands-on-guide-to-creating-a-pdf-based-qa-assistant-with-llama-and-llamaindex/

