
Afbeelding door auteur
Een van de gebieden waarop datawetenschap berust is machinaal leren. Dus als je je wilt verdiepen in datawetenschap, is het begrijpen van machine learning een van de eerste stappen die je moet nemen.
Maar waar begin je? Je begint met het begrijpen van het verschil tussen de twee belangrijkste typen machine learning-algoritmen. Pas daarna kunnen we praten over individuele algoritmen die op je prioriteitenlijst zouden moeten staan om als beginner te leren.
Het belangrijkste onderscheid tussen de algoritmen is gebaseerd op de manier waarop ze leren.

Afbeelding door auteur
Algoritmen voor begeleid leren zijn getraind op a gelabelde dataset. Deze dataset dient als supervisie (vandaar de naam) voor het leren, omdat sommige gegevens die deze bevatten al als correct antwoord zijn gelabeld. Op basis van deze input kan het algoritme leren en dat leren toepassen op de rest van de gegevens.
Daarnaast is onbeheerde leeralgoritmen leren op een ongelabelde dataset, wat betekent dat ze patronen in gegevens vinden zonder dat mensen aanwijzingen geven.
U kunt er meer in detail over lezen algoritmen voor machine learning en soorten leren.
Er zijn ook enkele andere vormen van machinaal leren, maar niet voor beginners.
Algoritmen worden gebruikt om twee belangrijke problemen binnen elk type machine learning op te lossen.
Nogmaals, er zijn nog wat taken, maar deze zijn niet voor beginners.

Afbeelding door auteur
Begeleide leertaken
Regressie is de taak van het voorspellen van a numerieke waarde, Genaamd continue uitkomstvariabele of afhankelijke variabele. De voorspelling is gebaseerd op de voorspellende variabele(n) of onafhankelijke variabele(n).
Denk aan het voorspellen van de olieprijzen of de luchttemperatuur.
Classificatie wordt gebruikt om de categorie (klasse) van de invoergegevens. De uitkomst variabele hier is categorisch of discreet.
Denk aan het voorspellen of de e-mail spam is of geen spam en of de patiënt een bepaalde ziekte krijgt of niet.
Leertaken zonder toezicht
Clustering middel het verdelen van gegevens in subsets of clusters. Het doel is om gegevens zo natuurlijk mogelijk te groeperen. Dit betekent dat datapunten binnen hetzelfde cluster meer op elkaar lijken dan op datapunten uit andere clusters.
Dimensionaliteitsreductie verwijst naar het verminderen van het aantal invoervariabelen in een dataset. Het betekent eigenlijk het reduceren van de dataset tot zeer weinig variabelen, terwijl de essentie ervan nog steeds wordt vastgelegd.
Hier is een overzicht van de algoritmen die ik zal behandelen.
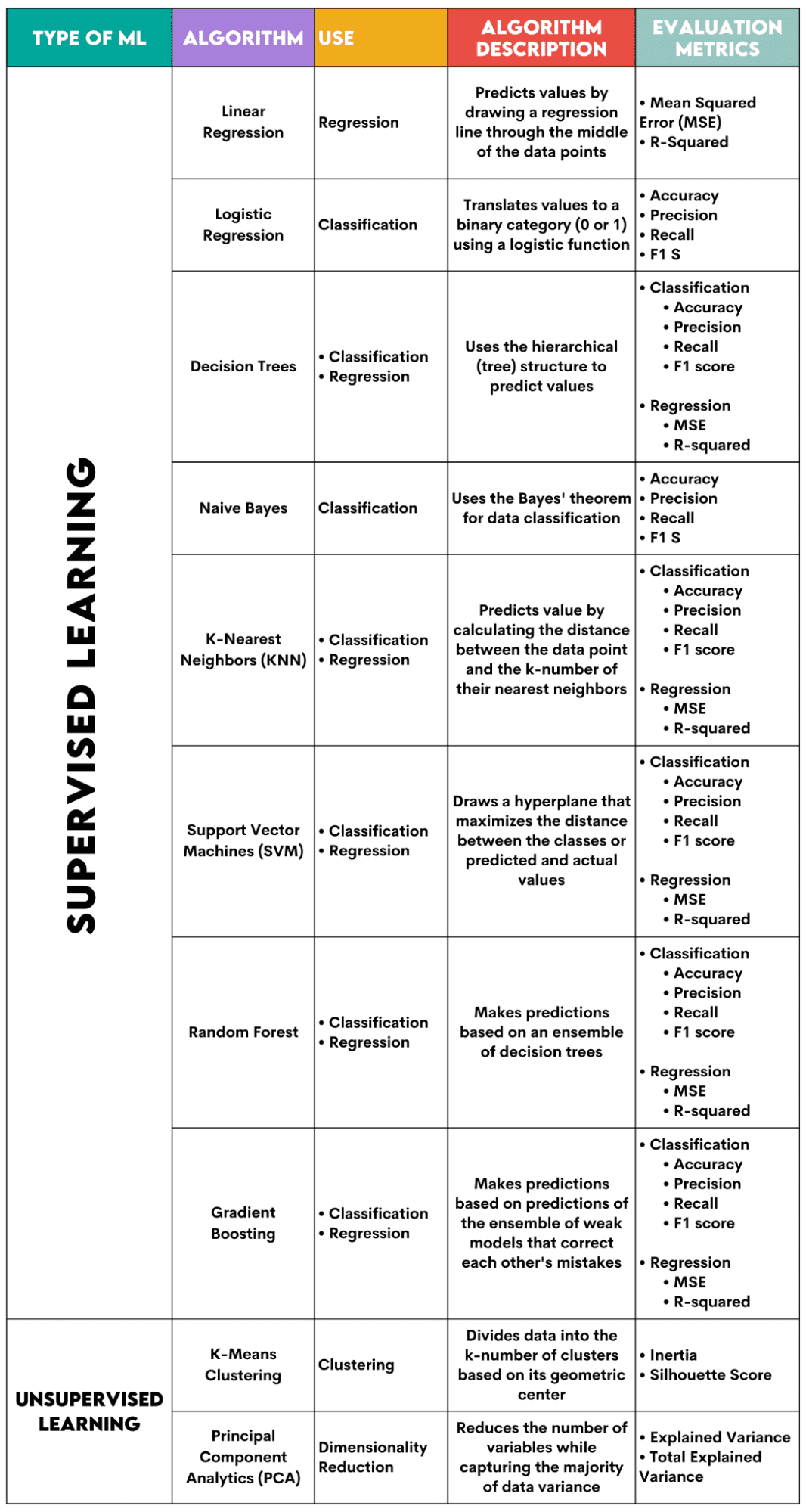
Afbeelding door auteur
Begeleide leeralgoritmen
Bij het kiezen van het algoritme voor uw probleem is het belangrijk om te weten voor welke taak het algoritme wordt gebruikt.
Als datawetenschapper zul je deze algoritmen waarschijnlijk in Python toepassen met behulp van de scikit-learn-bibliotheek. Hoewel het (bijna) alles voor je doet, is het raadzaam dat je op zijn minst de algemene principes van de interne werking van elk algoritme kent.
Ten slotte moet u, nadat het algoritme is getraind, evalueren hoe goed het presteert. Daarvoor heeft elk algoritme enkele standaardstatistieken.
1. Lineaire regressie
Gebruikt voor: Regressie
Beschrijving: Lineaire regressie trekt een rechte lijn een regressielijn tussen de variabelen genoemd. Deze lijn loopt ongeveer door het midden van de datapunten, waardoor de schattingsfout wordt geminimaliseerd. Het toont de voorspelde waarde van de afhankelijke variabele op basis van de waarde van de onafhankelijke variabelen.
Evaluatiestatistieken:
- Gemiddelde kwadratische fout (MSE): vertegenwoordigt het gemiddelde van de gekwadrateerde fout, waarbij de fout het verschil is tussen de werkelijke en de voorspelde waarden. Hoe lager de waarde, hoe beter de prestaties van het algoritme.
- R-kwadraat: vertegenwoordigt het variantiepercentage van de afhankelijke variabele dat kan worden voorspeld door de onafhankelijke variabele. Voor deze maatregel moet u ernaar streven om zo dicht mogelijk bij 1 te komen.
2. Logistieke regressie
Gebruikt voor: Classificatie
Beschrijving: Het maakt gebruik van een logistieke functie om de gegevenswaarden te vertalen naar een binaire categorie, dat wil zeggen 0 of 1. Dit gebeurt met behulp van de drempelwaarde, meestal ingesteld op 0.5. De binaire uitkomst maakt dit algoritme perfect voor het voorspellen van binaire uitkomsten, zoals JA/NEE, WAAR/FALSE of 0/1.
Evaluatiestatistieken:
- Nauwkeurigheid: De verhouding tussen correcte en totale voorspellingen. Hoe dichter bij 1, hoe beter.
- Precisie: de maatstaf voor modelnauwkeurigheid bij positieve voorspellingen; weergegeven als de verhouding tussen correcte positieve voorspellingen en de totale verwachte positieve uitkomsten. Hoe dichter bij 1, hoe beter.
- Bedenk: het meet ook de nauwkeurigheid van het model bij positieve voorspellingen. Het wordt uitgedrukt als de verhouding tussen correcte positieve voorspellingen en het totale aantal observaties in de klas. Lees meer over deze statistieken hier.
- F1-score: Het harmonische gemiddelde van de herinnering en precisie van het model. Hoe dichter bij 1, hoe beter.
3. Beslisbomen
Gebruikt voor: Regressie en classificatie
Beschrijving: Beslissingsbomen zijn algoritmen die de hiërarchische of boomstructuur gebruiken om waarde of een klasse te voorspellen. Het hoofdknooppunt vertegenwoordigt de hele dataset, die vervolgens vertakt in beslissingsknooppunten, vertakkingen en bladeren op basis van de variabele waarden.
Evaluatiestatistieken:
- Nauwkeurigheid, precisie, terugroepactie en F1-score -> voor classificatie
- MSE, R-kwadraat -> voor regressie
4. Naïeve Bayes
Gebruikt voor: Classificatie
Beschrijving: Dit is een familie van classificatie-algoritmen die gebruikmaken van Stelling van Bayes, wat betekent dat ze de onafhankelijkheid tussen kenmerken binnen een klasse aannemen.
Evaluatiestatistieken:
- Nauwkeurigheid
- precisie
- Terugroepen
- F1-score
5. K-dichtstbijzijnde buren (KNN)
Gebruikt voor: Regressie en classificatie
Beschrijving: Het berekent de afstand tussen de testgegevens en de k-nummer van de dichtstbijzijnde datapunten uit de trainingsgegevens. De testgegevens behoren tot een klasse met een hoger aantal 'buren'. Wat de regressie betreft, is de voorspelde waarde het gemiddelde van de k gekozen trainingspunten.
Evaluatiestatistieken:
- Nauwkeurigheid, precisie, terugroepactie en F1-score -> voor classificatie
- MSE, R-kwadraat -> voor regressie
6. Ondersteuning van vectormachines (SVM)
Gebruikt voor: Regressie en classificatie
Beschrijving: Dit algoritme tekent a hypervlak om verschillende gegevensklassen te scheiden. Het bevindt zich op de grootste afstand van de dichtstbijzijnde punten van elke klasse. Hoe groter de afstand van het datapunt tot het hypervlak, hoe meer het tot zijn klasse behoort. Voor regressie is het principe vergelijkbaar: hypervlak maximaliseert de afstand tussen de voorspelde en werkelijke waarden.
Evaluatiestatistieken:
- Nauwkeurigheid, precisie, terugroepactie en F1-score -> voor classificatie
- MSE, R-kwadraat -> voor regressie
7. Willekeurig bos
Gebruikt voor: Regressie en classificatie
Beschrijving: Het willekeurige bosalgoritme gebruikt een ensemble van beslissingsbomen, die vervolgens een beslissingsbos vormen. De voorspelling van het algoritme is gebaseerd op de voorspelling van veel beslissingsbomen. Gegevens worden toegewezen aan een klasse die de meeste stemmen krijgt. Voor regressie is de voorspelde waarde een gemiddelde van de voorspelde waarden van alle bomen.
Evaluatiestatistieken:
- Nauwkeurigheid, precisie, terugroepactie en F1-score -> voor classificatie
- MSE, R-kwadraat -> voor regressie
8. Verloopversterking
Gebruikt voor: Regressie en classificatie
Beschrijving: Deze algoritmen gebruik een ensemble van zwakke modellen, waarbij elk volgend model de fouten van het vorige model herkent en corrigeert. Dit proces wordt herhaald totdat de fout (verliesfunctie) is geminimaliseerd.
Evaluatiestatistieken:
- Nauwkeurigheid, precisie, terugroepactie en F1-score -> voor classificatie
- MSE, R-kwadraat -> voor regressie
Algoritmen voor leren zonder toezicht
9. K-betekent clustering
Gebruikt voor: Clustering
Beschrijving: Het algoritme verdeelt de dataset in k-getalclusters, elk vertegenwoordigd door zijn zwaartepunt of geometrisch centrum. Door het iteratieve proces van het verdelen van gegevens in een k-aantal clusters, is het doel om de afstand tussen de gegevenspunten en het zwaartepunt van hun cluster te minimaliseren. Aan de andere kant probeert het ook de afstand van deze datapunten tot het zwaartepunt van de andere clusters te maximaliseren. Simpel gezegd moeten de gegevens die tot hetzelfde cluster behoren zo veel mogelijk op elkaar lijken en zo verschillend zijn als gegevens uit andere clusters.
Evaluatiestatistieken:
- Traagheid: de som van de kwadratische afstand van de afstand van elk datapunt tot het dichtstbijzijnde clusterzwaartepunt. Hoe lager de traagheidswaarde, hoe compacter het cluster.
- Silhouette Score: Het meet de samenhang (de gelijkenis van gegevens binnen het eigen cluster) en de scheiding (het verschil van gegevens met andere clusters) van de clusters. De waarde van deze score varieert van -1 tot +1. Hoe hoger de waarde, hoe beter de gegevens overeenkomen met het cluster, en hoe slechter deze overeenkomen met andere clusters.
10. Hoofdcomponentanalyse (PCA)
Gebruikt voor: Dimensionaliteitsvermindering
Beschrijving: Het algoritme vermindert het aantal variabelen dat wordt gebruikt door nieuwe variabelen (hoofdcomponenten) te construeren, terwijl er nog steeds wordt geprobeerd de vastgelegde variantie van de gegevens te maximaliseren. Met andere woorden: het beperkt de gegevens tot de meest voorkomende componenten, zonder de essentie van de gegevens te verliezen.
Evaluatiestatistieken:
- Verklaarde variantie: het percentage van de variantie dat door elke hoofdcomponent wordt gedekt.
- Totale verklaarde variantie: het percentage van de variantie dat door alle hoofdcomponenten wordt gedekt.
Machine learning is een essentieel onderdeel van datawetenschap. Met deze tien algoritmen dekt u de meest voorkomende taken in machine learning. Uiteraard geeft dit overzicht u slechts een algemeen idee van hoe elk algoritme werkt. Dit is dus nog maar een begin.
Nu moet je leren hoe je deze algoritmen in Python kunt implementeren en echte problemen kunt oplossen. Daarin raad ik aan om scikit-learn te gebruiken. Niet alleen omdat het een relatief eenvoudig te gebruiken ML-bibliotheek is, maar ook vanwege de mogelijkheden ervan uitgebreide materialen over ML-algoritmen.
Nate Rosidi is een datawetenschapper en in productstrategie. Hij is ook adjunct-professor en doceert analytics, en is de oprichter van StrataScratch, een platform dat datawetenschappers helpt zich voor te bereiden op hun interviews met echte interviewvragen van topbedrijven. Nate schrijft over de nieuwste trends op de carrièremarkt, geeft sollicitatieadvies, deelt data science-projecten en behandelt alles wat SQL betreft.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/a-beginner-guide-to-the-top-10-machine-learning-algorithms?utm_source=rss&utm_medium=rss&utm_campaign=a-beginners-guide-to-the-top-10-machine-learning-algorithms

