Afbeelding door auteur
Wanneer u met modellen werkt, moet u er rekening mee houden dat verschillende algoritmen verschillende leerpatronen hebben bij het opnemen van gegevens. Het is een vorm van intuïtief leren, om het model te helpen de patronen in de gegeven dataset te leren, ook wel het trainen van het model genoemd.
Het model wordt vervolgens getest op de testdataset, een dataset die het model nog niet eerder heeft gezien. U wilt een optimaal prestatieniveau bereiken waarbij het model nauwkeurige uitvoer kan produceren voor zowel de trainings- als de testgegevensset.
Wellicht heb je ook wel eens gehoord van de validatieset. Dit is de methode om uw dataset in tweeën te splitsen: de trainingsdataset en de testdataset. De eerste splitsing van de gegevens zal worden gebruikt om het model te trainen, terwijl de tweede splitsing van de gegevens zal worden gebruikt om het model te testen.
De validatiesetmethode heeft echter nadelen.
Het model heeft alle patronen in de trainingsdataset geleerd, maar heeft mogelijk relevante informatie in de testdataset gemist. Dit heeft ertoe geleid dat het model geen belangrijke informatie meer heeft die de algehele prestaties ervan kan verbeteren.
Een ander nadeel is dat de trainingsdataset te maken kan krijgen met uitschieters of fouten in de gegevens, die het model zal leren. Dit wordt onderdeel van de kennisbasis van het model en zal worden toegepast bij het testen in de tweede fase.
Dus wat kunnen we doen om dit te verbeteren? Opnieuw bemonsteren.
Resampling is een methode waarbij herhaaldelijk samples uit de trainingsdataset worden getrokken. Deze monsters worden vervolgens gebruikt om een specifiek model opnieuw aan te passen om meer informatie over het gemonteerde model te verkrijgen. Het doel is om meer informatie over een monster te verzamelen en de nauwkeurigheid te verbeteren en de onzekerheid in te schatten.
Als u bijvoorbeeld naar lineaire regressie-fits kijkt en de variabiliteit wilt onderzoeken. U gebruikt herhaaldelijk verschillende steekproeven uit de trainingsgegevens en past een lineaire regressie toe op elk van de steekproeven. Hierdoor kunt u onderzoeken hoe de resultaten verschillen op basis van de verschillende monsters, en kunt u nieuwe informatie verkrijgen.
Het grote voordeel van resampling is dat u herhaaldelijk kleine steekproeven uit dezelfde populatie kunt trekken totdat uw model optimaal presteert. U bespaart veel tijd en geld doordat u dezelfde dataset kunt recyclen en geen nieuwe gegevens hoeft te zoeken.
Onderbemonstering en overbemonstering
Als u met zeer ongebalanceerde datasets werkt, is resampling een techniek die u daarbij kunt helpen.
- Onderbemonstering is het verwijderen van monsters uit de meerderheidsklasse, om voor meer evenwicht te zorgen.
- Er is sprake van overbemonstering als u willekeurige steekproeven uit de minderheidsklasse dupliceert omdat er onvoldoende gegevens zijn verzameld.
Deze hebben echter nadelen. Het verwijderen van monsters bij onderbemonstering kan leiden tot informatieverlies. Het dupliceren van willekeurige steekproeven uit de minderheidsklasse kan tot overfitting leiden.
In de datawetenschap worden vaak twee resampling-methoden gebruikt:
- De Bootstrap-methode
- Kruisvalidatie
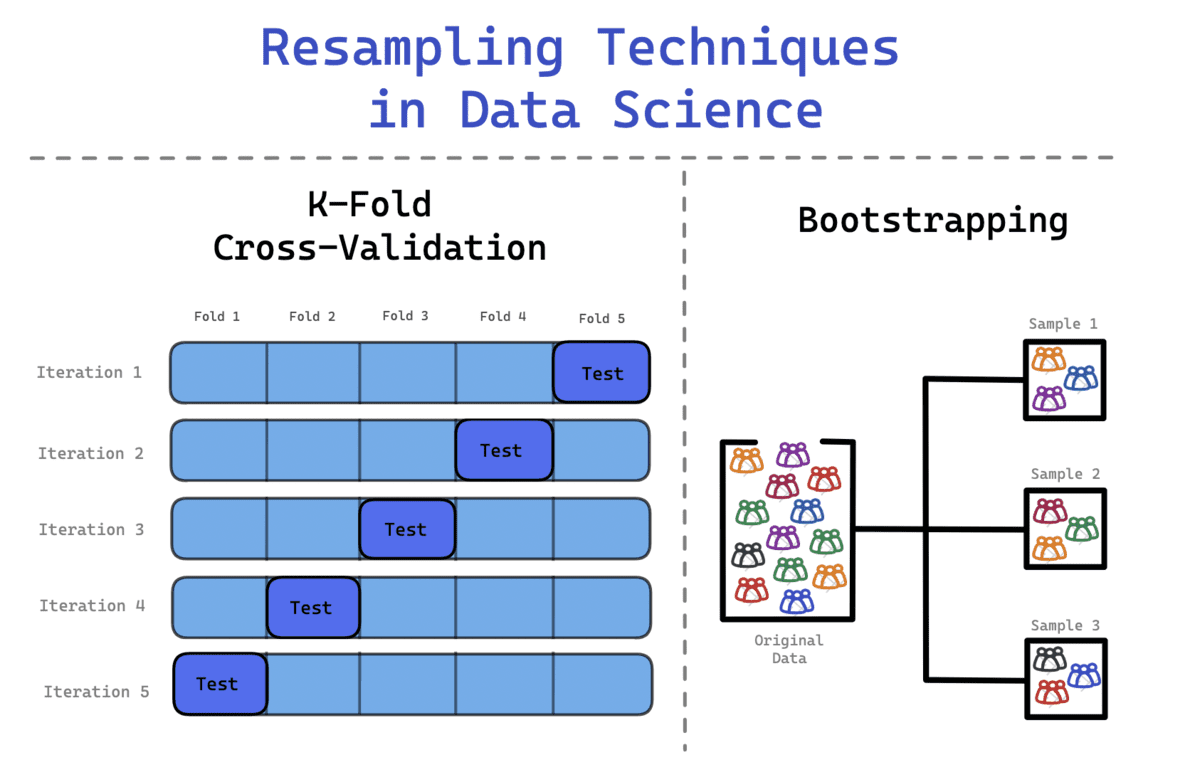
Bootstrap-methode
U zult datasets tegenkomen die niet de typische normale verdeling volgen. Daarom kan de Bootstrap-methode worden toegepast om de verborgen informatie en distributie van de dataset te onderzoeken.
Bij gebruik van de bootstrapping-methode worden de getrokken monsters vervangen en worden de gegevens die niet in de monsters zijn opgenomen, gebruikt om het model te testen. Het is een flexibele statistische methode die datawetenschappers en machine learning-ingenieurs kan helpen bij het kwantificeren van onzekerheid.
Het proces omvat
- Herhaaldelijk voorbeeldwaarnemingen uit de dataset trekken
- Het vervangen van deze voorbeelden om ervoor te zorgen dat de originele dataset dezelfde grootte behoudt.
- Een waarneming kan meer dan één keer voorkomen, of helemaal niet.
Misschien heb je wel eens gehoord van Bagging, de ensembletechniek. Het is een afkorting voor Bootstrap Aggregation, dat bootstrapping en aggregatie combineert om één ensemblemodel te vormen. Er worden meerdere sets van de originele trainingsgegevens gemaakt, die vervolgens worden samengevoegd om tot een definitieve voorspelling te komen. Elk model leert de fouten van het vorige model.
Een voordeel van Bootstrapping is dat ze een lagere variantie hebben in vergelijking met de hierboven genoemde train-test split-methode.
Kruisvalidatie
Wanneer u de dataset herhaaldelijk willekeurig splitst, kan dit ertoe leiden dat de steekproef in de trainings- of testsets terechtkomt. Dit kan helaas een onevenwichtige invloed hebben op uw model door het maken van nauwkeurige voorspellingen.
Om dit te voorkomen, kunt u K-Fold Cross Validation gebruiken om de gegevens effectiever te splitsen. In dit proces worden de gegevens verdeeld in k gelijke sets, waarbij één set wordt gedefinieerd als de testset, terwijl de rest van de sets wordt gebruikt bij het trainen van het model. Het proces gaat door totdat elke set als testset heeft gefunctioneerd en alle sets de trainingsfase hebben doorlopen.
Het proces omvat:
- De gegevens worden opgesplitst in k-vouwen. Een dataset wordt bijvoorbeeld opgesplitst in 10 vouwen – 10 gelijke sets.
- Tijdens de eerste iteratie wordt het model getraind op (k-1) en getest op de enige overgebleven set. Het model wordt bijvoorbeeld getraind op (10-1 = 9) en getest op de resterende 1 set.
- Dit proces wordt herhaald totdat alle vouwen in de testfase als de resterende 1 set hebben gediend.
Dit maakt een evenwichtige weergave van elk monster mogelijk, waardoor wordt verzekerd dat alle gegevens zijn gebruikt om het leren van het model te verbeteren en om de prestaties van het model te testen.
In dit artikel heeft u begrepen wat resampling is en hoe u uw dataset op drie verschillende manieren kunt samplen: train-test splitsen, bootstrap en kruisvalidatie.
Het algemene doel van al deze methoden is om het model te helpen zoveel mogelijk informatie op een effectieve manier op te nemen. De enige manier om ervoor te zorgen dat het model met succes heeft geleerd, is door het model te trainen op verschillende datapunten in de dataset.
Resampling is een belangrijk onderdeel van de voorspellende modelleringsfase; zorgen voor nauwkeurige output, hoogwaardige modellen en effectieve workflows.
Nisha Arja is een datawetenschapper en freelance technisch schrijver. Ze is vooral geïnteresseerd in het geven van loopbaanadvies op het gebied van Data Science of tutorials en op theorie gebaseerde kennis rond Data Science. Ze wil ook de verschillende manieren onderzoeken waarop kunstmatige intelligentie de levensduur van de mens ten goede komt. Een scherpe leerling, die haar technische kennis en schrijfvaardigheid wil verbreden, terwijl ze anderen helpt te begeleiden.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/02/role-resampling-techniques-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=the-role-of-resampling-techniques-in-data-science

