De mogelijkheid om snel machine learning (ML)-modellen te bouwen en in te zetten wordt steeds belangrijker in de huidige datagestuurde wereld. Het bouwen van ML-modellen vergt echter veel tijd, moeite en gespecialiseerde expertise. Van het verzamelen en opschonen van gegevens tot het ontwikkelen van functies, het bouwen van modellen, afstemmen en implementeren: ML-projecten duren vaak maanden voordat ontwikkelaars deze voltooien. En ervaren datawetenschappers kunnen moeilijk te vinden zijn.
Dit is waar de AWS-suite van low-code en no-code ML-services een essentieel hulpmiddel wordt. Met slechts een paar klikken gebruiken Amazon SageMaker-canvas, kunt u profiteren van de kracht van ML zonder dat u code hoeft te schrijven.
Als strategische systeemintegrator met diepgaande ML-ervaring maakt Deloitte gebruik van de no-code en low-code ML-tools van AWS om efficiënt ML-modellen te bouwen en in te zetten voor de klanten van Deloitte en voor interne assets. Met deze tools kan Deloitte ML-oplossingen ontwikkelen zonder modellen en pipelines met de hand te hoeven coderen. Dit kan helpen de levertijden van projecten te versnellen en Deloitte in staat te stellen meer werk voor klanten op zich te nemen.
Hieronder volgen enkele specifieke redenen waarom Deloitte deze tools gebruikt:
- Toegankelijkheid voor niet-programmeurs – Tools zonder code maken het bouwen van ML-modellen toegankelijk voor niet-programmeurs. Teamleden met alleen domeinexpertise en zeer weinig codeervaardigheden kunnen ML-modellen ontwikkelen.
- Snelle adoptie van nieuwe technologie – Beschikbaarheid en voortdurende verbetering van kant-en-klare modellen en AutoML zorgen ervoor dat gebruikers voortdurend gebruik maken van toonaangevende technologie.
- Kosteneffectieve ontwikkeling – Tools zonder code helpen de kosten en tijd die nodig zijn voor de ontwikkeling van ML-modellen te verminderen, waardoor deze toegankelijker worden voor klanten, wat hen kan helpen een hoger rendement op hun investering te behalen.
Bovendien bieden deze tools een uitgebreide oplossing voor snellere workflows, waardoor het volgende mogelijk wordt:
- Snellere gegevensvoorbereiding – SageMaker Canvas heeft meer dan 300 ingebouwde transformaties en de mogelijkheid om natuurlijke taal te gebruiken die de datavoorbereiding kan versnellen en data gereed kan maken voor modelbouw.
- Snellere modelbouw – SageMaker Canvas biedt kant-en-klare modellen of Amazon AutoML technologie waarmee u met slechts een paar klikken aangepaste modellen kunt bouwen op basis van bedrijfsgegevens. Dit helpt het proces te versnellen in vergelijking met het coderen van modellen vanaf de basis.
- Gemakkelijkere implementatie – SageMaker Canvas biedt de mogelijkheid om productieklare modellen te implementeren in een Amazon Sagmaker eindpunt in een paar klikken terwijl u het ook registreert Amazon SageMaker-modelregister.
Vishveshwara Vasa, Cloud-CTO voor Deloitte, zegt:
“Dankzij de no-code ML-diensten van AWS, zoals SageMaker Canvas en SageMaker Data Wrangler, hebben wij bij Deloitte Consulting nieuwe efficiëntieverbeteringen gerealiseerd, waardoor de ontwikkelingssnelheid en de implementatieproductiviteit met 30-40% zijn verbeterd in onze klantgerichte en interne projecten.”
In dit bericht demonstreren we de kracht van het bouwen van een end-to-end ML-model zonder code met behulp van SageMaker Canvas door u te laten zien hoe u een classificatiemodel kunt bouwen om te voorspellen of een klant in gebreke blijft bij het betalen van een lening. Door de wanbetalingen op leningen nauwkeuriger te voorspellen, kan het model een financiële dienstverlener helpen risico's te beheersen, leningen op de juiste manier te prijzen, de bedrijfsvoering te verbeteren, aanvullende diensten te verlenen en een concurrentievoordeel te behalen. We demonstreren hoe SageMaker Canvas u kan helpen snel van onbewerkte gegevens over te gaan naar een geïmplementeerd binair classificatiemodel voor het voorspellen van wanbetalingen op leningen.
SageMaker Canvas biedt uitgebreide mogelijkheden voor gegevensvoorbereiding, mogelijk gemaakt door Amazon SageMaker-gegevens Wrangler in de SageMaker Canvas-werkruimte. Hierdoor kunt u alle fasen van een standaard ML-workflow doorlopen, van datavoorbereiding tot modelbouw en implementatie, op één platform.
Gegevensvoorbereiding is doorgaans de meest tijdrovende fase van de ML-workflow. Om de tijd die u besteedt aan gegevensvoorbereiding te verminderen, kunt u met SageMaker Canvas uw gegevens voorbereiden met behulp van meer dan 300 ingebouwde transformaties. Alternatief, u kunt aanwijzingen in natuurlijke taal schrijven, zoals "laat de rijen voor kolom c vallen die uitschieters zijn", en krijg het codefragment te zien dat nodig is voor deze stap voor gegevensvoorbereiding. Vervolgens kunt u dit met een paar klikken toevoegen aan uw datavoorbereidingsworkflow. Hoe je dat kunt gebruiken, laten we je ook in dit bericht zien.
Overzicht oplossingen
Het volgende diagram beschrijft de architectuur voor een standaardclassificatiemodel voor leningen met behulp van SageMaker low-code en no-code tools.
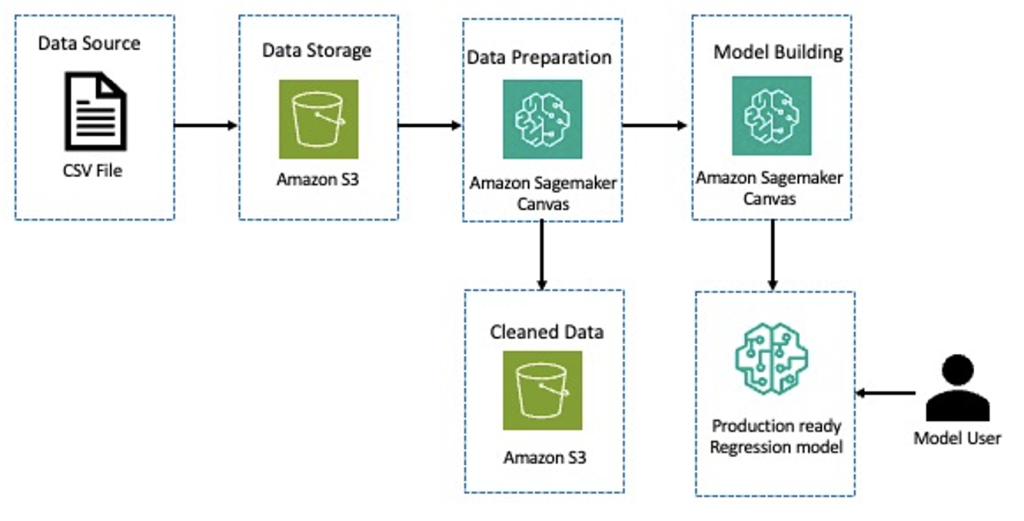
Beginnend met een dataset met details over de wanbetalingsgegevens van leningen Amazon eenvoudige opslagservice (Amazon S3), gebruiken we SageMaker Canvas om inzicht te krijgen in de gegevens. Vervolgens voeren we functie-engineering uit om transformaties toe te passen, zoals het coderen van categorische kenmerken, het verwijderen van functies die niet nodig zijn, en meer. Vervolgens slaan we de opgeschoonde gegevens weer op in Amazon S3. We gebruiken de opgeschoonde dataset om een classificatiemodel te creëren voor het voorspellen van wanbetalingen op leningen. Dan hebben we een productieklaar model voor gevolgtrekking.
Voorwaarden
Zorg ervoor dat het volgende vereisten zijn voltooid en dat u de Canvas Kant-en-klare modellen optie bij het instellen van het SageMaker-domein. Als u uw domein al heeft ingesteld, bewerk uw domeininstellingen en ga naar Canvas-instellingen om de Schakel Canvas Ready-to-use-modellen in keuze. Daarnaast instellen en maak de SageMaker Canvas-applicatie, vraag het vervolgens aan en schakel het in Toegang tot antropische Claude-modellen on Amazonebodem.
dataset
Wij gebruiken een openbare dataset van Kaggle die informatie bevat over financiële leningen. Elke rij in de dataset vertegenwoordigt één enkele lening en de kolommen geven details over elke transactie. Download deze dataset en bewaar deze in een S3-bucket naar keuze. In de volgende tabel worden de velden in de gegevensset vermeld.
| Kolomnaam | Data type | Omschrijving |
Person_age |
Geheel getal | Leeftijd van de persoon die een lening heeft afgesloten |
Person_income |
Geheel getal | Inkomen van de kredietnemer |
Person_home_ownership |
Draad | Eigendomsstatus (eigen of huur) |
Person_emp_length |
Decimaal | Aantal jaren dat ze in dienst zijn |
Loan_intent |
Draad | Reden voor lening (persoonlijk, medisch, educatief, enzovoort) |
Loan_grade |
Draad | Kredietgraad (A–E) |
Loan_int_rate |
Decimaal | Rente |
Loan_amnt |
Geheel getal | Totaalbedrag van de lening |
Loan_status |
Geheel getal | Doel (of ze nu in gebreke zijn gebleven of niet) |
Loan_percent_income |
Decimaal | Leenbedrag vergeleken met het percentage van het inkomen |
Cb_person_default_on_file |
Geheel getal | Eerdere standaardwaarden (indien aanwezig) |
Cb_person_credit_history_length |
Draad | Lengte van hun kredietgeschiedenis |
Vereenvoudig de gegevensvoorbereiding met SageMaker Canvas
Het voorbereiden van gegevens kan tot 80% van de inspanning in ML-projecten vergen. Een goede datavoorbereiding leidt tot betere modelprestaties en nauwkeurigere voorspellingen. SageMaker Canvas maakt interactieve gegevensverkenning, -transformatie en -voorbereiding mogelijk zonder dat er SQL- of Python-code hoeft te worden geschreven.
Voer de volgende stappen uit om uw gegevens voor te bereiden:
- Kies op de SageMaker Canvas-console Data voorbereiding in het navigatievenster.
- Op de creëren menu, kies Document.
- Voor Naam dataset, voer een naam in voor uw dataset.
- Kies creëren.

- Kies Amazon S3 als gegevensbron en koppel deze aan de dataset.
- Nadat de gegevensset is geladen, maakt u een gegevensstroom met behulp van die gegevensset.
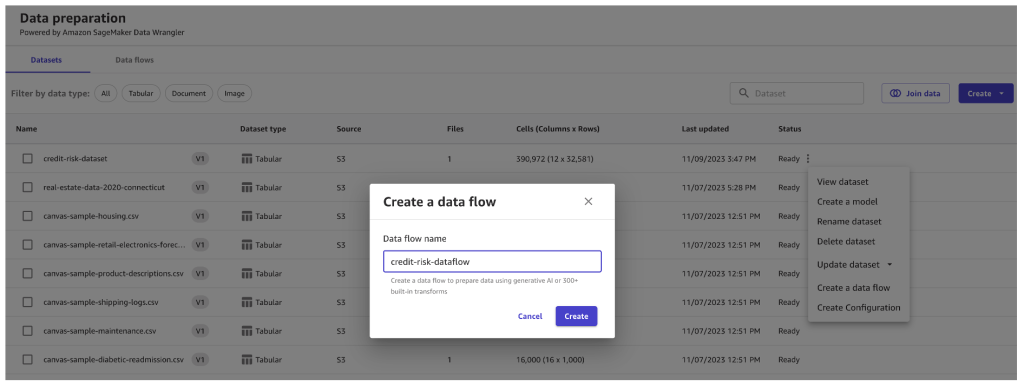
- Ga naar het tabblad Analyses en maak een Rapport Gegevenskwaliteit en inzichten.
Dit is een aanbevolen stap om de kwaliteit van de invoergegevensset te analyseren. De output van dit rapport levert direct ML-aangedreven inzichten op, zoals scheefgetrokken gegevens, duplicaten in de gegevens, ontbrekende waarden en nog veel meer. De volgende schermafbeelding toont een voorbeeld van het gegenereerde rapport voor de leninggegevensset.


Door deze inzichten namens u te genereren, biedt SageMaker Canvas u een reeks problemen in de gegevens die moeten worden verholpen in de gegevensvoorbereidingsfase. Om de twee belangrijkste problemen te kiezen die door SageMaker Canvas zijn geïdentificeerd, moet u de categorische kenmerken coderen en de dubbele rijen verwijderen, zodat uw modelkwaliteit hoog is. Je kunt dit allebei en nog veel meer doen in een visuele workflow met SageMaker Canvas.
- Eerst codeert one-hot het
loan_intent,loan_gradeenperson_home_ownership - Je kunt de
cb_person_cred_history_lengthkolom omdat die kolom de minste voorspellende kracht heeft, zoals blijkt uit het Data Quality and Insights Report.
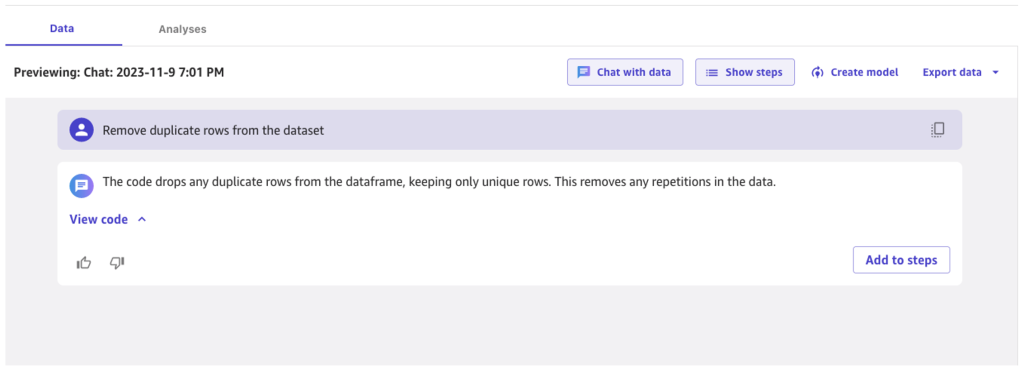
SageMaker Canvas heeft onlangs een Chatten met gegevens keuze. Deze functie maakt gebruik van de kracht van basismodellen om query's in natuurlijke taal te interpreteren en op Python gebaseerde code te genereren om feature-engineering-transformaties toe te passen. Deze functie wordt mogelijk gemaakt door Amazon Bedrock en kan worden geconfigureerd om volledig in uw VPC te draaien, zodat gegevens nooit uw omgeving verlaten. - Als u deze functie wilt gebruiken om dubbele rijen te verwijderen, kiest u het plusteken naast de Kolom laten vallen transformeren, kies dan Chatten met gegevens.
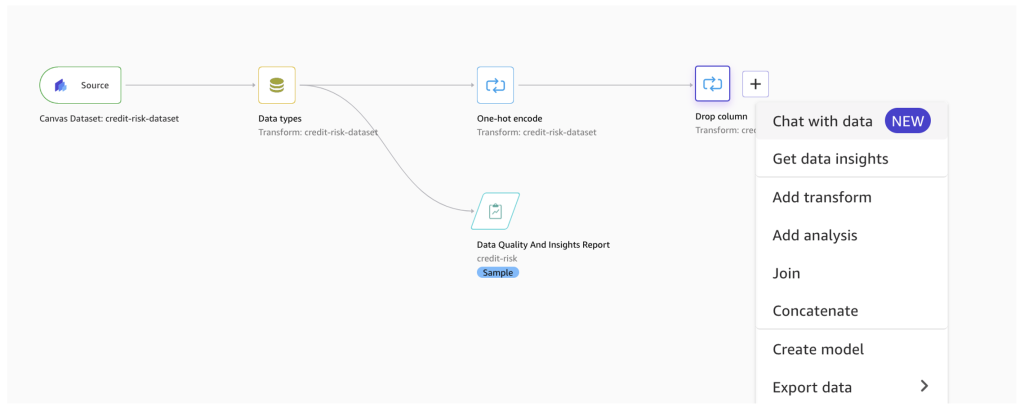
- Voer uw zoekopdracht in natuurlijke taal in (bijvoorbeeld 'Verwijder dubbele rijen uit de dataset').
- Bekijk de gegenereerde transformatie en maak een keuze Voeg toe aan stappen om de transformatie aan de stroom toe te voegen.
- Exporteer ten slotte de uitvoer van deze transformaties naar Amazon S3 of optioneel Amazon SageMaker Feature Store om deze functies in meerdere projecten te gebruiken.
U kunt ook nog een stap toevoegen om een Amazon S3-bestemming voor de dataset te maken om de workflow voor een grote dataset te schalen. Het volgende diagram toont de SageMaker Canvas-gegevensstroom na het toevoegen van visuele transformaties.

U hebt de volledige stap voor gegevensverwerking en feature-engineering voltooid met behulp van visuele workflows in SageMaker Canvas. Hierdoor kan de tijd die een data-engineer besteedt aan het opschonen en gereedmaken van de data voor modelontwikkeling, worden teruggebracht van weken tot dagen. De volgende stap is het bouwen van het ML-model.
Bouw een model met SageMaker Canvas
Amazon SageMaker Canvas biedt een end-to-end workflow zonder code voor het bouwen, analyseren, testen en implementeren van dit binaire classificatiemodel. Voer de volgende stappen uit:
- Maak een gegevensset in SageMaker Canvas.
- Geef de S3-locatie op die is gebruikt om de gegevens te exporteren, of de S3-locatie die zich op de bestemming van de SageMaker Canvas-taak bevindt.
Nu bent u klaar om het model te bouwen. - Kies Modellen in het navigatievenster en kies Nieuw model.
- Geef het model een naam en selecteer Voorspellende analyse als het modeltype.
- Kies de gegevensset die in de vorige stap is gemaakt.
De volgende stap is het configureren van het modeltype. - Kies de doelkolom en het modeltype wordt automatisch ingesteld als 2 categorie voorspelling.
- Kies uw bouwtype, Standaard gebouwd or Snel gebouwd.

SageMaker Canvas geeft de verwachte bouwtijd weer zodra u begint met het bouwen van het model. De standaardbouw duurt gewoonlijk tussen de 2 en 4 uur; Voor kleinere datasets kunt u de optie Snel bouwen gebruiken, wat slechts 2 tot 15 minuten duurt. Voor deze specifieke dataset duurt het ongeveer 45 minuten om het bouwen van het model te voltooien. SageMaker Canvas houdt u op de hoogte van de voortgang van het bouwproces. - Nadat het model is gebouwd, kunt u de modelprestaties bekijken.
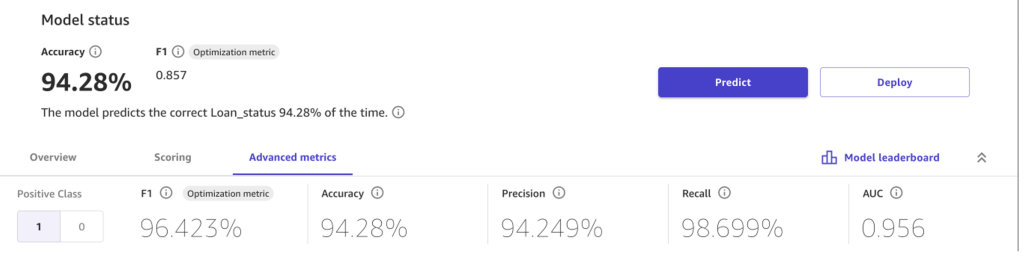
SageMaker Canvas biedt verschillende statistieken, zoals nauwkeurigheid, precisie en F1-score, afhankelijk van het type model. De volgende schermafbeelding toont de nauwkeurigheid en enkele andere geavanceerde statistieken voor dit binaire classificatiemodel. - De volgende stap is het maken van testvoorspellingen.
Met SageMaker Canvas kunt u batchvoorspellingen doen op basis van meerdere invoer of een enkele voorspelling om de modelkwaliteit snel te verifiëren. De volgende schermafbeelding toont een voorbeeld van een gevolgtrekking.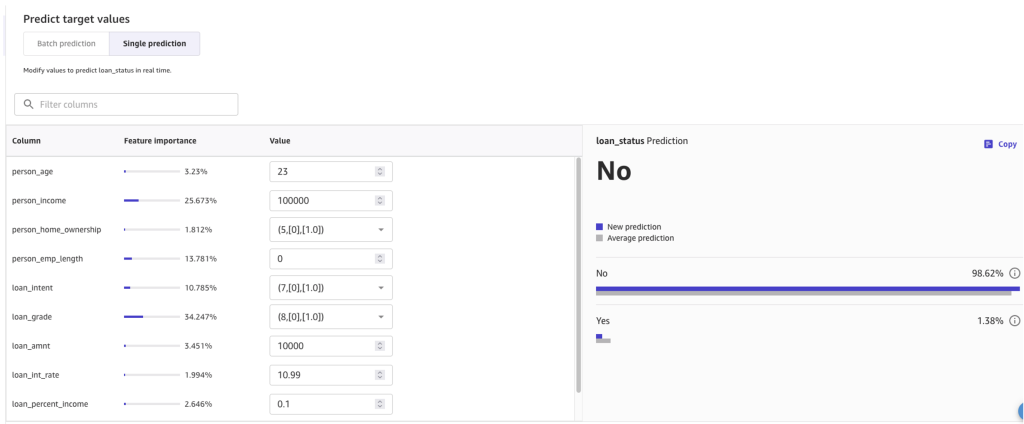
- De laatste stap is het implementeren van het getrainde model.
SageMaker Canvas implementeert het model op SageMaker-eindpunten, en nu heb je een productiemodel klaar voor gevolgtrekking. De volgende schermafbeelding toont het geïmplementeerde eindpunt.
Nadat het model is geïmplementeerd, kunt u het aanroepen via de AWS SDK of AWS-opdrachtregelinterface (AWS CLI) of voer API-aanroepen uit naar elke applicatie van uw keuze om met vertrouwen het risico van een potentiële lener te voorspellen. Voor meer informatie over het testen van uw model raadpleegt u Roep realtime eindpunten aan.
Opruimen
Om te voorkomen dat er extra kosten in rekening worden gebracht, uitloggen bij SageMaker Canvas or verwijder het SageMaker-domein dat is gecreëerd. Aanvullend, verwijder het SageMaker-modeleindpunt en verwijder de dataset die is geüpload naar Amazon S3.
Conclusie
No-code ML versnelt de ontwikkeling, vereenvoudigt de implementatie, vereist geen programmeervaardigheden, verhoogt de standaardisatie en verlaagt de kosten. Deze voordelen maakten no-code ML aantrekkelijk voor Deloitte om zijn ML-serviceaanbod te verbeteren, en ze hebben de tijdlijnen voor het bouwen van hun ML-modellen met 30-40% verkort.
Deloitte is een strategische wereldwijde systeemintegrator met meer dan 17,000 gecertificeerde AWS-professionals over de hele wereld. Het blijft de lat hoger leggen door deelname aan het AWS Competency Program 25 competenties, waaronder Machine Learning. Neem contact op met Deloitte om AWS no-code en low-code oplossingen voor uw onderneming te gaan gebruiken.
Over de auteurs
 Chida Sadayappan leidt de Cloud AI/Machine Learning-praktijk van Deloitte. Hij brengt sterke ervaring op het gebied van thought leadership mee naar opdrachten en gedijt goed in het ondersteunen van uitvoerende belanghebbenden bij het bereiken van prestatieverbeterings- en moderniseringsdoelstellingen in alle sectoren met behulp van AI/ML. Chida is een seriële tech-ondernemer en een fervent gemeenschapsbouwer in de ecosystemen van startups en ontwikkelaars.
Chida Sadayappan leidt de Cloud AI/Machine Learning-praktijk van Deloitte. Hij brengt sterke ervaring op het gebied van thought leadership mee naar opdrachten en gedijt goed in het ondersteunen van uitvoerende belanghebbenden bij het bereiken van prestatieverbeterings- en moderniseringsdoelstellingen in alle sectoren met behulp van AI/ML. Chida is een seriële tech-ondernemer en een fervent gemeenschapsbouwer in de ecosystemen van startups en ontwikkelaars.
 Kuldeep Singh, een Principal Global AI/ML-leider bij AWS met meer dan 20 jaar ervaring in technologie, combineert vakkundig zijn expertise op het gebied van verkoop en ondernemerschap met een diep inzicht in AI, ML en cyberbeveiliging. Hij blinkt uit in het smeden van strategische mondiale partnerschappen en het stimuleren van transformatieve oplossingen en strategieën in verschillende sectoren, met een focus op generatieve AI en GSI’s.
Kuldeep Singh, een Principal Global AI/ML-leider bij AWS met meer dan 20 jaar ervaring in technologie, combineert vakkundig zijn expertise op het gebied van verkoop en ondernemerschap met een diep inzicht in AI, ML en cyberbeveiliging. Hij blinkt uit in het smeden van strategische mondiale partnerschappen en het stimuleren van transformatieve oplossingen en strategieën in verschillende sectoren, met een focus op generatieve AI en GSI’s.
 Kasi Muthu is een senior partneroplossingenarchitect die zich richt op data en AI/ML bij AWS, gevestigd in Houston, Texas. Hij heeft een passie voor het helpen van partners en klanten bij het versnellen van hun clouddatareis. Hij is een vertrouwde adviseur op dit gebied en heeft veel ervaring met het ontwerpen en bouwen van schaalbare, veerkrachtige en performante workloads in de cloud. Buiten zijn werk brengt hij graag tijd door met zijn gezin.
Kasi Muthu is een senior partneroplossingenarchitect die zich richt op data en AI/ML bij AWS, gevestigd in Houston, Texas. Hij heeft een passie voor het helpen van partners en klanten bij het versnellen van hun clouddatareis. Hij is een vertrouwde adviseur op dit gebied en heeft veel ervaring met het ontwerpen en bouwen van schaalbare, veerkrachtige en performante workloads in de cloud. Buiten zijn werk brengt hij graag tijd door met zijn gezin.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/boosting-developer-productivity-how-deloitte-uses-amazon-sagemaker-canvas-for-no-code-low-code-machine-learning/

