Introductie
In een wereld die een technologische revolutie ondergaat, hervormt de samensmelting van kunstmatige intelligentie en gezondheidszorg het landschap van medische diagnose en behandeling. Een van de stille helden achter deze transformatie is de toepassing van grote taalmodellen (LLM's) op het gebied van de medische wereld, de gezondheidszorg en vooral in tekstanalyse. Dit artikel duikt in het domein van LLM's in de context van op tekst gebaseerde medische toepassingen en onderzoekt hoe deze krachtige AI-modellen een revolutie teweegbrengen in de gezondheidszorg.

leerdoelen
- Begrijp de rol van grote taalmodellen (LLM's) bij medische tekstanalyse.
- Erken het belang van medische beeldvorming in de moderne gezondheidszorg.
- Identificeer de uitdagingen die het volume aan medische beelden in de gezondheidszorg met zich meebrengt.
- Begrijp hoe LLM's helpen bij het automatiseren van medische tekstanalyse en diagnose.
- Waardeer de efficiëntie van LLM's bij het beoordelen van kritieke medische gevallen.
- Ontdek hoe LLM's bijdragen aan gepersonaliseerde behandelplannen op basis van de geschiedenis van de patiënt.
- Begrijp de samenwerkingsrol van LLM's bij het assisteren van radiologen.
- Ontdek hoe LLM's kunnen helpen bij het onderwijs voor medische studenten en praktijkmensen.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
De onzichtbare wereld van medische beeldvorming en gezondheidszorg
Voordat we ons in de wereld van LLM's verdiepen, nemen we even de tijd om de aanwezigheid van medische beeldvorming te waarderen. Het is de ruggengraat van de moderne geneeskunde in het huidige technoleven, die helpt ziekten te visualiseren en op te sporen en de voortgang van veel behandelingen te monitoren. Vooral radiologie is sterk afhankelijk van medische beelden van röntgenfoto's, MRI's, CT-scans en meer.
Deze schat aan medische beelden brengt echter een uitdaging met zich mee: het enorme volume. Ziekenhuizen en zorginstellingen gebruiken dagelijks grote hoeveelheden medische beelden. Het handmatig analyseren en interpreteren van deze zondvloed is lastig, tijdrovend en vatbaar voor menselijke fouten.

Naast hun cruciale rol bij het analyseren van medische beelden, blinken grote taalmodellen uit in het begrijpen en verwerken van op tekst gebaseerde medische informatie. Ze bieden duidelijkheid bij het begrijpen van complex medisch jargon en helpen zelfs bij het interpreteren van aantekeningen en rapporten. LLM's dragen bij aan een efficiëntere en nauwkeurigere medische tekstanalyse, waardoor de algemene capaciteiten van zorgprofessionals en medische analyses worden verbeterd.
Laten we met dit inzicht verder onderzoeken hoe LLM's een revolutie teweegbrengen in de gezondheidszorgsector op het gebied van medische beeldvorming en tekstanalyse.
Toepassingen van LLM's in medische tekstanalyse
Laten we, voordat we de veelzijdige rollen begrijpen die grote taalmodellen in de gezondheidszorg vervullen, een korte blik werpen op hun belangrijkste toepassingen op het gebied van medische tekstanalyse:
- Ziektediagnose en prognose: LLM's kunnen grote databases met medische teksten doorzoeken om zorgverleners te helpen bij het diagnosticeren van verschillende ziekten. Ze kunnen niet alleen helpen bij de initiële diagnose, maar ze kunnen ook onderbouwde inschattingen maken over het ziekteverloop en de prognose, op basis van voldoende contextuele informatie.
- Klinische documentatie en elektronische medische dossiers: Het omgaan met uitgebreide klinische documentatie kan voor medische professionals tijdrovend zijn. LLM's bieden een efficiëntere manier om elektronische medische dossiers (EPD's) te transcriberen, samen te vatten en te analyseren, waardoor zorgverleners zich meer kunnen concentreren op de patiëntenzorg.
- Ontdekking en herbestemming van geneesmiddelen: Door een overvloed aan biomedische literatuur te doorzoeken, kunnen LLM's potentiële kandidaat-geneesmiddelen identificeren en zelfs alternatieve toepassingen voor bestaande geneesmiddelen voorstellen, waardoor het ontdekkings- en herbestemmingsproces in de farmacologie wordt versneld.
- Biomedische literatuuranalyse: De steeds groter wordende hoeveelheid medische literatuur kan overweldigend zijn. LLM's kunnen talloze wetenschappelijke artikelen doorzoeken, de belangrijkste bevindingen identificeren en beknopte samenvattingen geven, wat helpt bij de snellere assimilatie van nieuwe kennis.
- Patiëntondersteuning en gezondheidschatbots: LLM's vormen de drijvende kracht achter intelligente chatbots die een scala aan functies kunnen verwerken, van het beantwoorden van veelvoorkomende gezondheidsvragen tot het aanbieden van eerste triage in noodsituaties, waardoor onschatbare ondersteuning wordt geboden aan zowel patiënten als zorgverleners.
Hoe LLM's werken in de gezondheidszorgsector?

- Wat zijn grote taalmodellen? Grote taalmodellen zijn een subset van machine learning-modellen die zijn ontworpen om mensachtige tekst te begrijpen, interpreteren en genereren. Deze modellen zijn getraind op enorme datasets bestaande uit boeken, artikelen, websites en andere op tekst gebaseerde bronnen. Ze dienen als zeer geavanceerde tekstanalysatoren en -generatoren die context en semantiek kunnen begrijpen.
- De evolutie van LLM's op medisch gebied: In het afgelopen decennium hebben LLM's bekendheid verworven in de gezondheidszorg, waarbij ze evolueerden van eenvoudige chatbots naar geavanceerde tools die complexe medische literatuur kunnen ontleden. De komst van krachtigere hardware en efficiëntere algoritmen heeft het voor deze modellen mogelijk gemaakt om binnen enkele seconden gigabytes aan gegevens te doorzoeken en realtime inzichten en analyses te bieden. Door hun aanpassingsvermogen kunnen ze voortdurend leren van nieuwe informatie, waardoor ze steeds nauwkeuriger en betrouwbaarder worden.
- Hoe verschillen LLM's van traditionele NLP-methoden? Traditionele Natural Language Processing (NLP)-methoden, zoals op regels gebaseerde systemen of eenvoudigere machine learning-modellen, werken op vaste algoritmen met beperkte mogelijkheden om de context te begrijpen. LLM's maken echter gebruik van diepgaand leren om de fijne kneepjes van de menselijke taal te begrijpen, inclusief idiomen, medisch jargon en complexe zinsstructuren. Hierdoor kunnen LLM's inzichten genereren die veel genuanceerder en contextueel nauwkeuriger zijn dan wat traditionele NLP-methoden kunnen bieden.
Voordelen en mogelijkheden van LLM's in medische tekstanalyse
- Contextueel begrip: In tegenstelling tot traditionele zoekalgoritmen die afhankelijk zijn van het matchen van trefwoorden, begrijpen LLM's de context van de tekst, waardoor genuanceerdere en nauwkeurigere inzichten mogelijk zijn.
- Speed: LLM's kunnen snel rapporten analyseren en genereren, waardoor kostbare tijd wordt bespaard in kritieke gezondheidszorgomgevingen.
- multifunctionaliteit: Naast eenvoudige tekstanalyse kunnen ze helpen bij de diagnose, gepersonaliseerde behandelaanbevelingen geven en dienen als educatieve hulpmiddelen.
- Aanpassingsvermogen: Deze modellen kunnen worden afgestemd op specifieke medische domeinen of functies, waardoor ze ongelooflijk veelzijdig zijn.
De rol van LLM's bij medische tekstanalyse
- Geautomatiseerde analyse en diagnose: Grote taalmodellen worden getraind met behulp van vele datasets, waaronder medische literatuur en realtime casestudies. Ze blinken uit in het begrijpen van de context en kunnen complex medisch jargon ontleden. LLM's kunnen geautomatiseerde analyses uitvoeren en zelfs ziekten diagnosticeren wanneer ze worden toegepast op medische teksten.
- Efficiënte triage: Op de spoedeisende hulp telt elke minuut. Grote taalmodellen kunnen gevallen snel beoordelen door medische rapporten of tekstuele aantekeningen van het ziekenhuis te analyseren en kritieke aandoeningen, zoals bloedingen of afwijkingen, te signaleren. Dit versnelt de patiëntenzorg en optimaliseert de toewijzing van middelen.
- Gepersonaliseerde behandelplannen: LLM's voor medische beeldvorming dragen bij aan gepersonaliseerde geneeskunde door de geschiedenis van patiënten te analyseren, inclusief genetica, allergieën en reacties op behandelingen uit het verleden. Op basis van deze informatie kunnen zij behandelplannen op maat aanbevelen.
- Assisteren van radiologen: Grote taalmodellen helpen als assistenten van radiologen. Ze kunnen medische rapporten vooraf screenen, afwijkingen benadrukken en mogelijke diagnoses voorstellen. Deze gezamenlijke aanpak verbetert de nauwkeurigheid van diagnoses en vermindert de vermoeidheid van radiologen.
- Educatieve hulpmiddelen: Grote taalmodellen kunnen nuttig zijn als hulpmiddelen voor onderwijsdoeleinden voor medische studenten en praktijkmensen. Ze kunnen 3D-reconstructies genereren op basis van tekstuele beschrijvingen, medische scenario's simuleren en gedetailleerde uitleg geven voor educatieve doeleinden.
Hoe LLM's kunnen worden geautomatiseerd voor diagnose?
Hier is een vereenvoudigd codefragment dat gebruik maakt van een taalmodel (zoals GPT-3) om te zien hoe grote taalmodellen kunnen worden gebruikt voor geautomatiseerde analyse en diagnose op basis van medische tekst:
import openai
import time # Your OpenAI API key
api_key = "YOUR_API_KEY" # Patient's medical report medical_report = """
Patient: John Doe
Age: 45
Symptoms: Persistent cough, shortness of breath, fever. Medical History:
- Allergies: None
- Medications: None
- Past Illnesses: None Diagnosis:
Based on the patient's symptoms and medical history, John Doe is suffering from a respiratory infection, possibly pneumonia. Further tests and evaluation are recommended for confirmation. """ # Initialize OpenAI's GPT-3 model
openai.api_key = api_key # Define a language model
prompt = f"Diagnose the condition by seeing the following report:n{medical_report}nDiagnosis:" while True: try: # Generate a diagnosis using the language model response = openai.Completion.create( engine="davinci", prompt=prompt, max_tokens=50 # Adjust the number of tokens based on your requirements ) # Extract and print the generated diagnosis diagnosis = response.choices[0].text.strip() print("Generated Diagnosis:") print(diagnosis) # Break out of the loop once the response is successfully obtained break except openai.error.RateLimitError as e: # If you hit the rate limit, wait for a moment and retry print("Rate limit exceeded. Waiting for rate limit reset...") time.sleep(60) # Wait for 1 minute (adjust as needed) except Exception as e: # Handle other exceptions print(f"An error occurred: {e}") break # Break out of the loop on other errors
Output:

- Importeer de openai-bibliotheek en stel de OpenAI-sleutel in
- Maak een medisch rapport met patiëntinformatie, symptomen en medische geschiedenis.
- Initialiseer het GPT-3-model van OpenAI en definieer een prompt die het model vraagt een diagnose te stellen van de medische aandoening op basis van het verstrekte rapport.
- Gebruik de openai.Completion om een diagnose te genereren. En pas de parameter max_tokens aan om de lengte van de gegenereerde tekst te bepalen.
- Pak de gegenereerde diagnose uit en druk deze af.
Voorbeelduitvoer
Generated Diagnosis: "Based on the patient's symptoms and medical history, it is likely that John Doe is suffering from a respiratory infection, possibly pneumonia.
Further tests and evaluation are recommended for confirmation."Deze code laat zien hoe een Large Language Model kan helpen bij het genereren van geautomatiseerde medische diagnoses op basis van tekstuele medische rapporten. Bedenk dat medische diagnoses in de echte wereld altijd overleg met beroepsbeoefenaren in de gezondheidszorg moeten omvatten en niet mogen vertrouwen op door AI gegenereerde diagnoses.
Combinatie van VIT en LLM voor uitgebreide medische beeldanalyse
Laten we enkele codefragmenten onderzoeken die de toepassing van LLM's in medische beeldvorming demonstreren.
import torch
from transformers import ViTFeatureExtractor, ViTForImageClassification # Load a pre-trained Vision Transformer (ViT) model
model_name = "google/vit-base-patch16-224-in21k"
feature_extractor = ViTFeatureExtractor(model_name)
model = ViTForImageClassification.from_pretrained(model_name) # Load and preprocess a medical image
from PIL import Image image = Image.open("chest_xray.jpg")
inputs = feature_extractor(images=image, return_tensors="pt") # Get predictions from the model
outputs = model(**inputs)
logits_per_image = outputs.logitsIn deze code gebruiken we het Vision Transformer (ViT)-model om een medisch beeld te classificeren. LLM's zijn, net als ViT, aanpasbaar aan verschillende beeldgerelateerde taken in de medische beeldvorming.
Geautomatiseerde detectie van afwijkingen
import torch
import torchvision.transforms as transforms
from PIL import Image
from transformers import ViTFeatureExtractor, ViTForImageClassification # Load a pre-trained Vision Transformer (ViT) model
model_name = "google/vit-base-patch16-224-in21k"
feature_extractor = ViTFeatureExtractor(model_name)
model = ViTForImageClassification.from_pretrained(model_name) # Load and preprocess a medical image
image = Image.open("chest_xray.jpg")
transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(),
])
input_image = transform(image).unsqueeze(0) # Extract features from the image
inputs = feature_extractor(images=input_image)
outputs = model(**inputs)
logits_per_image = outputs.logitsIn deze code gebruiken we een Vision Transformer (ViT)-model om automatisch afwijkingen in een medisch beeld te detecteren. Het model extraheert kenmerken uit de afbeelding en de variabele logits_per_image bevat de voorspellingen van het model.
Ondertiteling van medische afbeeldingen
import torch
from transformers import ViTFeatureExtractor, ViTForImageToText # Load a pre-trained ViT model for image captioning
model_name = "google/vit-base-patch16-224-in21k-cmlm"
feature_extractor = ViTFeatureExtractor.from_pretrained(model_name)
model = ViTForImageToText.from_pretrained(model_name) # Load and preprocess a medical image
image = Image.open("MRI_scan.jpg")
inputs = feature_extractor(images=image, return_tensors="pt")
output = model.generate(input_ids=inputs["pixel_values"]) caption = feature_extractor.decode(output[0], skip_special_tokens=True)
print("Image Caption:", caption)Deze code laat zien hoe een LLM beschrijvende bijschriften voor medische beelden kan genereren. Het maakt gebruik van een vooraf getraind Vision Transformer (ViT) -model.
Technische workflow van LLM's in medische tekstanalyse
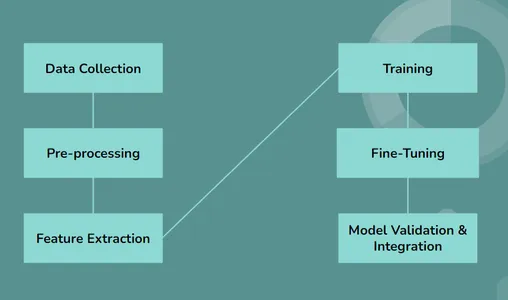
- Gegevensverzameling: LLM's initiëren het proces door verschillende datasets te gebruiken en te verzamelen, waaronder medische rapporten, onderzoeksartikelen en klinische aantekeningen.
- Voorverwerking: De verzamelde gegevens ondergaan een voorbewerking, waarbij de tekst wordt gestandaardiseerd, opgeschoond en georganiseerd voor analyse.
- Functie-extractie: Grote taalmodellen gebruiken geavanceerde methoden om de informatie die cruciaal en nuttig is uit tekstuele gegevens te halen of te vinden, waarbij belangrijke details en medische problemen worden geïdentificeerd.
- Opleiding: Grote taalmodellen worden getraind met behulp van deep learning dat helpt bij het vinden en observeren van de patronen en medische aandoeningen binnen de informatie in tekstuele vorm.
- Scherpstellen: Het model is afgestemd op specifieke medische taken na het trainingsproces. Het kan bijvoorbeeld leren specifieke ziekten of aandoeningen te identificeren op basis van medische rapporten.
- Modelvalidatie: De prestaties van de LLM worden rigoureus gevalideerd met behulp van afzonderlijke datasets om nauwkeurigheid en betrouwbaarheid bij medische tekstanalyse te garanderen.
- integratie: Eenmaal gevalideerd wordt het model geïntegreerd in gezondheidszorgsystemen en workflows, waar het professionals in de gezondheidszorg kan helpen bij het analyseren en interpreteren van medische tekstgegevens.
Zeker! Hieronder vindt u een vereenvoudigd codefragment dat helpt te begrijpen hoe een taalmodel zoals GPT-3 (een type LLM – Large Language Model) kan worden gebruikt voor medische, op tekst gebaseerde taken in een medische afdeling. In dit codefragment maken we een Python-script dat de OpenAI GPT-3 API gebruikt om een medisch diagnoserapport te genereren op basis van de symptomen en medische geschiedenis van de patiënt.
Zorg er eerst voor dat het OpenAI Python-pakket is geïnstalleerd (openai). Je hebt een API-sleutel van OpenAI nodig.
import openai # Set your OpenAI API key here
api_key = "YOUR_API_KEY" # Function to generate a medical diagnosis report
def generate_medical_diagnosis_report(symptoms, medical_history): prompt = f"Patient presents with the following symptoms: {symptoms}. Medical history: {medical_history}. Please provide a diagnosis and recommended treatment." # Call the OpenAI GPT-3 API response = openai.Completion.create( engine="text-davinci-002", # You can choose the appropriate engine prompt=prompt, max_tokens=150, # Adjust max_tokens based on the desired response length api_key=api_key ) # Extract and return the model's response diagnosis_report = response.choices[0].text.strip() return diagnosis_report # Example usage
if __name__ == "__main__": symptoms = "Persistent cough, fever, and chest pain" medical_history = "Patient has a history of asthma and allergies." diagnosis_report = generate_medical_diagnosis_report(symptoms, medical_history) print("Medical Diagnosis Report:") print(diagnosis_report)
Houd er rekening mee dat dit een vereenvoudigd voorbeeld is, en dat medische toepassingen in de echte wereld rekening houden met gegevensprivacy, naleving van de regelgeving en overleg met medische professionals. Gebruik dergelijke modellen altijd op verantwoorde wijze en raadpleeg gezondheidszorgdeskundigen voor daadwerkelijke medische diagnose en behandeling.
Grote taalmodellen: de kracht die verder gaat dan voorspellen
Grote taalmodellen vinden ook hun weg naar verschillende delen van de gezondheidszorg:
- Ontdekking van geneesmiddelen: LLM's helpen bij het ontdekken van geneesmiddelen door grote datasets van chemicaliën te bestuderen, te voorspellen hoe ze werken en de ontwikkeling van geneesmiddelen sneller te maken.
- Elektronische gezondheidsdossiers (EPD): Wanneer LLM's worden gebruikt met EPD's, kunnen ze snel patiëntendossiers analyseren om risico's te voorspellen, behandelingen voor te stellen en te bestuderen hoe behandelingen de gezondheid van patiënten beïnvloeden.
- Samenvatting van de medische literatuur: LLM's kunnen uitgebreide medische literatuur doorzoeken, belangrijke inzichten eruit halen en beknopte samenvattingen genereren, waardoor onderzoekers en zorgverleners worden geholpen.
- Telegeneeskunde en virtuele gezondheidsassistenten: LLM's kunnen virtuele gezondheidsassistenten aansturen die vragen van patiënten begrijpen, gezondheidsinformatie verstrekken en begeleiding bieden bij symptomen en behandelingsopties.

Ethische overwegingen
- Patiëntprivacy: Bescherm patiëntgegevens rigoureus om de vertrouwelijkheid te behouden.
- Gegevensbias: Beoordeel en corrigeer voortdurend vooroordelen binnen LLM's om eerlijke diagnoses te garanderen.
- Geïnformeerde toestemming: Beveilig de toestemming van de patiënt voor AI-ondersteunde diagnostiek en behandeling.
- Transparantie: Zorg voor transparantie in door AI gegenereerde aanbevelingen voor zorgverleners.
- Data kwaliteit: Behoud de gegevenskwaliteit en nauwkeurigheid voor betrouwbare resultaten.
- Mitigatie van bias: Geef prioriteit aan voortdurende beperking van vooroordelen in LLM's voor toepassingen in de ethische gezondheidszorg.
Conclusie
In de steeds veranderende wereld van gezondheidszorg en AI is het teamwerk van Large Language Models (LLM's) en medische beeldvorming een groot probleem en zeer belangrijk. Het gaat niet om het vervangen van menselijke kennis, maar om het verbeteren ervan en het behalen van resultaten zoals mensen zonder zijn tussenkomst. LLM's helpen bij snelle diagnoses en gepersonaliseerde behandelingen, waardoor het voor medische experts gemakkelijker wordt om patiënten snel te helpen.
Maar als we op deze technologie ingaan, mogen we niet vergeten om ethisch verantwoord om te gaan met het veiligstellen van patiëntinformatie in veiligere handen. De mogelijkheden zijn groot en groot, maar we hebben ook grote verantwoordelijkheden. Het gaat allemaal om het vinden van de juiste balans tussen vooruitgang en het beschermen van mensen.
De reis is net begonnen. Met LLM's aan onze zijde gaan we een pad in dat leidt tot nauwkeurigere diagnoses, betere patiëntresultaten en een gezondheidszorgsysteem dat zowel efficiënt als meelevend is. De toekomst van de gezondheidszorg, geleid door LLM's, belooft een gezondere wereld voor iedereen.
Key Takeaways
- Grote Taalmodellen (LLM's) zorgen voor een revolutie in de manier waarop medische teksten worden geanalyseerd, waardoor vooruitgang wordt geboekt in de diagnose en behandelplanning.
- Ze versnellen de spoedeisende hulp door problemen snel te identificeren in medische rapporten en klinische aantekeningen.
- LLM's vergroten de capaciteiten van radiologen door te helpen bij op tekst gebaseerde beeldinterpretatie in plaats van deze te vervangen, waardoor ze bijdragen aan een uitgebreid begrip van gegevens.
- Deze modellen vinden bruikbaarheid in het onderwijs en bieden uiteenlopende toepassingen binnen de zorgsector.
- Het benutten van LLM's op medisch gebied vereist een zorgvuldige afweging van de privacy van patiënten, de eerlijkheid van gegevens en de transparantie van modellen.
- De gezamenlijke inspanningen van LLM's en medische experts kunnen de kwaliteit en het medeleven van de gezondheidszorgdiensten verbeteren.
Veelgestelde Vragen / FAQ
A. Nee, LLM's vervangen radiologen op het gebied van medische beeldvorming niet. In plaats daarvan werken ze samen. LLM's helpen radiologen door problemen snel op te sporen en het proces sneller te maken. Ze worden gebruikt voor onderwijs en hebben andere medische toepassingen. De privacy van patiënten en eerlijkheid in gegevens zijn essentieel bij het gebruik van LLM's in de geneeskunde.
A. LLM's passen zich aan verschillende medische beelden aan door diverse datasets te verfijnen die specifiek zijn voor elke beeldvormingsmodaliteit. Tijdens dit proces leren ze unieke kenmerken en patronen van röntgenfoto's, MRI's en CT-scans die op tekst zijn gebaseerd. Cross-modale trainingstechnieken maken ze beschikbaar om kennis over te dragen tussen modaliteiten, waarbij de nauwkeurigheid behouden blijft en tegelijkertijd modaliteitsspecifieke nuances worden begrepen.
A. Uitdagingen bij LLM's op het gebied van medische beeldvorming zijn onder meer het aanpakken en beperken van databias, het verkrijgen van geïnformeerde toestemming van patiënten voor AI-ondersteunde diagnostiek, en het garanderen van transparantie in de manier waarop door AI gegenereerde aanbevelingen worden geformuleerd en gepresenteerd met behoud van de ethiek.
A. Ja, LLM's kunnen dienen als educatieve hulpmiddelen in de gezondheidszorg. Ze helpen bij het aanleren van medische concepten en delen waardevolle informatie op een gemakkelijk te begrijpen manier. Dit kan ten goede komen aan verschillende soorten studenten, beroepsbeoefenaren in de gezondheidszorg en zelfs patiënten die meer willen weten over hun aandoeningen.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/10/the-impact-of-large-language-models-on-medical-text-analysis/

