Data zijn uw generatieve AI-differentiator, en een succesvolle generatieve AI De implementatie is afhankelijk van een robuuste datastrategie die een alomvattende datastrategie omvat gegevensbeheer benadering. Het werken met grote taalmodellen (LLM's) voor zakelijke gebruiksscenario's vereist de implementatie van kwaliteits- en privacyoverwegingen om verantwoorde AI te stimuleren. Bedrijfsgegevens gegenereerd uit geïsoleerde bronnen, gecombineerd met het ontbreken van een data-integratiestrategie, zorgen echter voor uitdagingen bij het leveren van de gegevens voor generatieve AI-toepassingen. De noodzaak van een end-to-end strategie voor datamanagement en databeheer bij elke stap van het traject – van het opnemen, opslaan en opvragen van gegevens tot het analyseren, visualiseren en uitvoeren van modellen voor kunstmatige intelligentie (AI) en machine learning (ML) – blijft van het allergrootste belang voor ondernemingen.
In dit bericht bespreken we de behoeften op het gebied van databeheer van generatieve datapijplijnen voor AI-applicaties, een cruciale bouwsteen voor het beheren van gegevens die door LLM's worden gebruikt om de nauwkeurigheid en relevantie van hun reacties op gebruikersprompts op een veilige, beveiligde en transparante manier te verbeteren. Bedrijven doen dit door bedrijfseigen gegevens te gebruiken met benaderingen zoals Retrieval Augmented Generation (RAG), verfijning en voortdurende pre-training met basismodellen.
Data governance is een cruciale bouwsteen voor al deze benaderingen, en we zien twee aandachtsgebieden ontstaan. Ten eerste zijn veel LLM-gebruiksscenario's afhankelijk van bedrijfskennis die moet worden ontleend aan ongestructureerde gegevens zoals documenten, transcripties en afbeeldingen, naast gestructureerde gegevens uit datawarehouses. Ongestructureerde gegevens worden doorgaans in verschillende formaten opgeslagen in silosystemen en worden over het algemeen niet met hetzelfde nauwkeurigheidsniveau beheerd of bestuurd als gestructureerde gegevens. Ten tweede introduceren generatieve AI-toepassingen een groter aantal gegevensinteracties dan conventionele toepassingen, wat vereist dat het beleid voor gegevensbeveiliging, privacy en toegangscontrole wordt geïmplementeerd als onderdeel van de generatieve AI-gebruikersworkflows.
In dit bericht behandelen we data governance voor het bouwen van generatieve AI-applicaties op AWS met een lens op gestructureerde en ongestructureerde bedrijfskennisbronnen, en de rol van data governance tijdens de verzoek-antwoordworkflows van gebruikers.
Gebruik case-overzicht
Laten we een voorbeeld bekijken van een AI-assistent voor klantenondersteuning. De volgende afbeelding toont de typische conversatieworkflow die wordt gestart met een gebruikersprompt.

De workflow omvat de volgende belangrijke stappen voor gegevensbeheer:
- Prompt gebruikerstoegangscontrole en beveiligingsbeleid.
- Toegangsbeleid om machtigingen te extraheren op basis van relevante gegevens en resultaten uit te filteren op basis van de promptgebruikersrol en -machtigingen.
- Handhaaf het privacybeleid voor gegevens, zoals het redigeren van persoonlijk identificeerbare informatie (PII).
- Dwing fijnmazige toegangscontrole af.
- Verleen de gebruikersrol machtigingen voor gevoelige informatie en nalevingsbeleid.
Om een antwoord te bieden dat de bedrijfscontext omvat, moet elke gebruikersprompt worden uitgebreid met een combinatie van inzichten uit gestructureerde gegevens uit het datawarehouse en ongestructureerde gegevens uit het bedrijfsdatameer. Aan de achterkant moeten de batchdata-engineeringprocessen die het datameer van de onderneming vernieuwen, worden uitgebreid om ongestructureerde gegevens op te nemen, te transformeren en te beheren. Als onderdeel van de transformatie moeten de objecten worden behandeld om de gegevensprivacy te garanderen (bijvoorbeeld PII-redactie). Ten slotte moet het toegangscontrolebeleid ook worden uitgebreid naar de ongestructureerde dataobjecten en naar vectorgegevensopslag.
Laten we eens kijken hoe data governance kan worden toegepast op de bedrijfskennisbrongegevenspijplijnen en de gebruikersverzoek-antwoordworkflows.
Enterprise-kennis: gegevensbeheer
In de volgende afbeelding worden de overwegingen voor gegevensbeheer voor gegevenspijplijnen en de werkstroom voor het toepassen van gegevensbeheer samengevat.
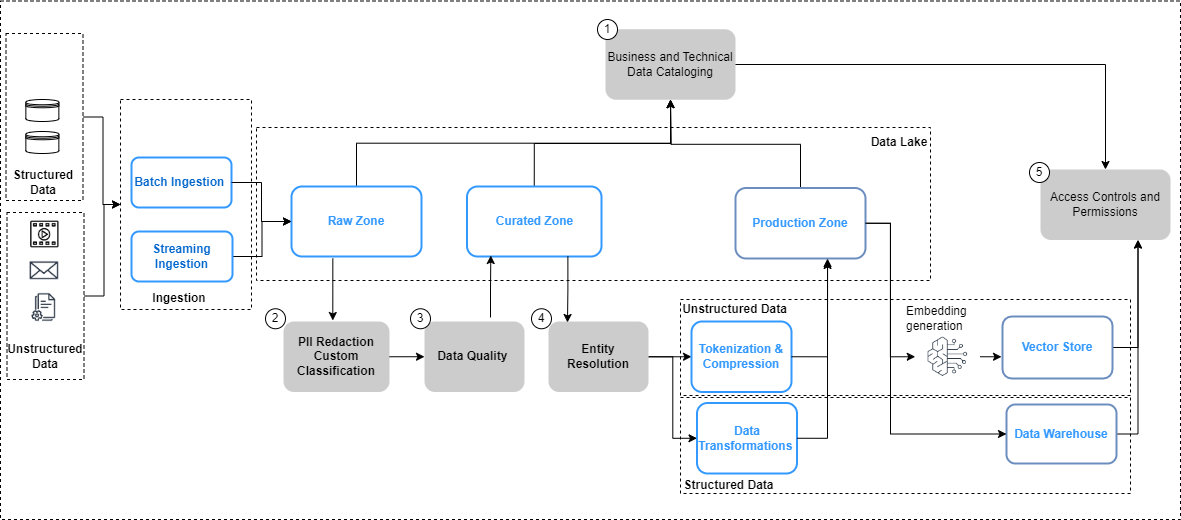
In de bovenstaande afbeelding omvatten de data-engineeringpijplijnen de volgende stappen voor databeheer:
- Creëer en update een catalogus via data-evolutie.
- Implementeer het gegevensprivacybeleid.
- Implementeer datakwaliteit per datatype en bron.
- Koppel gestructureerde en ongestructureerde datasets.
- Implementeer uniforme, fijnmazige toegangscontroles voor gestructureerde en ongestructureerde datasets.
Laten we enkele van de belangrijkste veranderingen in de datapijplijnen, namelijk datacatalogisering, datakwaliteit en vector-inbeddingsbeveiliging, in meer detail bekijken.
Vindbaarheid van gegevens
In tegenstelling tot gestructureerde gegevens, die worden beheerd in goed gedefinieerde rijen en kolommen, worden ongestructureerde gegevens opgeslagen als objecten. Om ervoor te zorgen dat gebruikers de gegevens kunnen ontdekken en begrijpen, is de eerste stap het bouwen van een uitgebreide catalogus met behulp van de metagegevens die worden gegenereerd en vastgelegd in de bronsystemen. Dit begint ermee dat de objecten (zoals documenten en transcriptbestanden) vanuit de relevante bronsystemen worden opgenomen in de onbewerkte zone in de data lake in Amazon eenvoudige opslagservice (Amazon S3) in hun respectievelijke oorspronkelijke formaten (zoals geïllustreerd in de voorgaande afbeelding). Vanaf hier worden de objectmetagegevens (zoals de bestandseigenaar, de aanmaakdatum en het vertrouwelijkheidsniveau) weergegeven geëxtraheerd en opgevraagd met behulp van Amazon S3-mogelijkheden. Metagegevens kunnen per gegevensbron verschillen en het is belangrijk om de velden te onderzoeken en, waar nodig, de benodigde velden af te leiden om alle noodzakelijke metagegevens te voltooien. Als een attribuut als vertrouwelijkheid van de inhoud bijvoorbeeld niet op documentniveau in de bronapplicatie is getagd, moet dit mogelijk worden afgeleid als onderdeel van het metadata-extractieproces en als attribuut worden toegevoegd aan de datacatalogus. Het opnameproces moet naast nieuwe objecten voortdurend objectupdates (wijzigingen, verwijderingen) vastleggen. Voor gedetailleerde implementatierichtlijnen, zie Ongestructureerd gegevensbeheer en -beheer met behulp van AWS AI/ML en analyseservices. Om de ontdekking en introspectie tussen zakelijke woordenlijsten en catalogi met technische gegevens verder te vereenvoudigen, kunt u gebruik maken van Amazon DataZone voor zakelijke gebruikers om gegevens te ontdekken en te delen die zijn opgeslagen in gegevenssilo's.
Data Privacy
Bedrijfskennisbronnen bevatten vaak PII en andere gevoelige gegevens (zoals adressen en burgerservicenummers). Op basis van uw gegevensprivacybeleid moeten deze elementen vanuit de bronnen worden behandeld (gemaskeerd, tokenized of geredigeerd) voordat ze kunnen worden gebruikt voor downstream-gebruiksscenario's. Vanuit de onbewerkte zone in Amazon S3 moeten de objecten worden verwerkt voordat ze kunnen worden geconsumeerd door downstream generatieve AI-modellen. Een belangrijke vereiste hierbij is Identificatie en redactie van PII, waarmee u kunt implementeren Amazon begrijpt het. Het is belangrijk om te onthouden dat het niet altijd haalbaar zal zijn om alle gevoelige gegevens te verwijderen zonder de context van de gegevens te beïnvloeden. Semantische context is een van de belangrijkste factoren die de nauwkeurigheid en relevantie van de output van generatieve AI-modellen bepalen, en het is van cruciaal belang om vanuit de use case terug te werken en het noodzakelijke evenwicht te vinden tussen privacycontroles en modelprestaties.
Gegevensverrijking
Bovendien moeten mogelijk aanvullende metadata uit de objecten worden gehaald. Amazon Comprehend biedt mogelijkheden voor entiteitsherkenning (bijvoorbeeld het identificeren van domeinspecifieke gegevens zoals polisnummers en claimnummers) en aangepaste classificatie (bijvoorbeeld door een transcriptie van een klantenservicechat te categoriseren op basis van de probleembeschrijving). Bovendien moet u mogelijk de ongestructureerde en gestructureerde gegevens combineren om een holistisch beeld te creëren van belangrijke entiteiten, zoals klanten. In een loyaliteitsscenario voor luchtvaartmaatschappijen zou het bijvoorbeeld van grote waarde zijn om ongestructureerde dataverzameling van klantinteracties (zoals transcripties van klantenchats en klantbeoordelingen) te koppelen aan gestructureerde datasignalen (zoals ticketaankopen en het inwisselen van mijlen) om een completer overzicht te creëren. klantprofiel dat vervolgens het leveren van betere en relevantere reisaanbevelingen mogelijk kan maken. AWS-entiteitsresolutie is een ML-service die helpt bij het matchen en koppelen van records. Deze service helpt bij het koppelen van gerelateerde informatiesets om diepere, meer verbonden gegevens te creëren over belangrijke entiteiten zoals klanten, producten, enzovoort, waardoor de kwaliteit en relevantie van LLM-outputs verder kunnen worden verbeterd. Dit is beschikbaar in de getransformeerde zone in Amazon S3 en is klaar om stroomafwaarts te worden gebruikt voor vectoropslag, verfijning of training van LLM's. Na deze transformaties kunnen gegevens beschikbaar worden gemaakt in de beheerde zone in Amazon S3.
Data kwaliteit
Een cruciale factor voor het realiseren van het volledige potentieel van generatieve AI is afhankelijk van de kwaliteit van de gegevens die worden gebruikt om de modellen te trainen, evenals van de gegevens die worden gebruikt om de modelrespons op gebruikersinvoer te vergroten en te verbeteren. Het begrijpen van de modellen en hun uitkomsten in de context van nauwkeurigheid, vertekening en betrouwbaarheid is recht evenredig met de kwaliteit van de gegevens die worden gebruikt om de modellen te bouwen en te trainen.
Amazon SageMaker-modelmonitor biedt een proactieve detectie van afwijkingen in de drift van de modelgegevenskwaliteit en de drift van de modelkwaliteitsmetrieken. Het bewaakt ook de bias-drift in de voorspellingen van uw model en de attributie van functies. Voor meer details, zie Monitoring van in-productie ML-modellen op grote schaal met behulp van Amazon SageMaker Model Monitor. Het detecteren van vooroordelen in uw model is een fundamentele bouwsteen voor verantwoorde AI Amazon SageMaker verduidelijken helpt bij het opsporen van mogelijke vooroordelen die een negatief of minder nauwkeurig resultaat kunnen opleveren. Voor meer informatie, zie Ontdek hoe Amazon SageMaker Clarify helpt bij het detecteren van vooringenomenheid.
Een nieuwer aandachtsgebied bij generatieve AI is het gebruik en de kwaliteit van gegevens in prompts van bedrijfs- en eigen datastores. Een opkomende best practice om hier te overwegen is shift-links, waarin sterk de nadruk wordt gelegd op vroegtijdige en proactieve mechanismen voor kwaliteitsborging. In de context van datapijplijnen die zijn ontworpen om data te verwerken voor generatieve AI-toepassingen, impliceert dit het eerder stroomopwaarts identificeren en oplossen van datakwaliteitsproblemen om de potentiële impact van datakwaliteitsproblemen later te verzachten. AWS Glue-gegevenskwaliteit meet en bewaakt niet alleen de kwaliteit van uw gegevens in rust in uw datameren, datawarehouses en transactionele databases, maar maakt ook vroegtijdige detectie en correctie mogelijk van kwaliteitsproblemen voor uw extractie-, transformatie- en laadpijplijnen (ETL) om uw gegevens te garanderen voldoet aan de kwaliteitsnormen voordat het wordt geconsumeerd. Voor meer details, zie Aan de slag met AWS Glue Data Quality uit de AWS Glue Data Catalog.
Beheer van vectorwinkels
Inbedding in vectordatabases verhoog de intelligentie en mogelijkheden van generatieve AI-toepassingen door functies zoals semantisch zoeken mogelijk te maken en hallucinaties te verminderen. Insluitingen bevatten doorgaans privé- en gevoelige gegevens, en het versleutelen van de gegevens is een aanbevolen stap in de workflow voor gebruikersinvoer. Amazon OpenSearch Serverloos slaat uw vectorinbedding op en doorzoekt deze, en versleutelt uw gegevens in rust AWS Sleutelbeheerservice (AWS KMS). Voor meer details, zie Introductie van de vectorengine voor Amazon OpenSearch Serverless, nu als preview-versie. Op dezelfde manier zijn er extra vectorengine-opties op AWS, inclusief Amazon Kendra en Amazon Aurora, versleutel uw gegevens in rust met AWS KMS. Voor meer informatie, zie Versleuteling in rust en Gegevens beschermen met encryptie.
Omdat insluitingen worden gegenereerd en opgeslagen in een vectoropslag, wordt het controleren van de toegang tot de gegevens met op rollen gebaseerde toegangscontrole (RBAC) een belangrijke vereiste voor het handhaven van de algehele beveiliging. Amazon OpenSearch-service biedt fijnmazige toegangscontroles (FGAC)-functies met AWS Identiteits- en toegangsbeheer (IAM) regels waaraan gekoppeld kan worden Amazon Cognito gebruikers. Overeenkomstige mechanismen voor toegangscontrole voor gebruikers worden ook geleverd door OpenSearch Serverloos, Amazon Kendraen Aurora. Raadpleeg voor meer informatie Gegevenstoegangscontrole voor Amazon OpenSearch Serverless, Controle van gebruikerstoegang tot documenten met tokens en Identiteits- en toegangsbeheer voor Amazon Aurora, Respectievelijk.
Workflows voor gebruikersverzoeken en -antwoorden
Controles op het vlak van databeheer moeten worden geïntegreerd in de generatieve AI-toepassing als onderdeel van het geheel oplossing implementatie om de naleving van het beleid inzake gegevensbeveiliging (gebaseerd op op rollen gebaseerde toegangscontroles) en gegevensprivacy (gebaseerd op op rollen gebaseerde toegang tot gevoelige gegevens) te garanderen. De volgende afbeelding illustreert de workflow voor het toepassen van data governance.
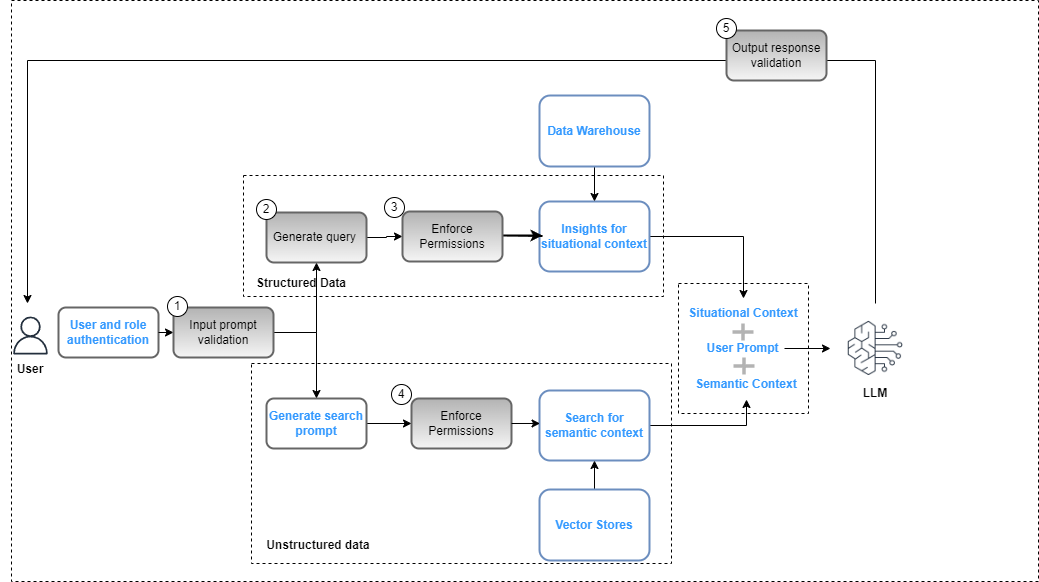
De workflow omvat de volgende belangrijke stappen voor gegevensbeheer:
- Geef een geldige invoerprompt op voor afstemming op het nalevingsbeleid (bijvoorbeeld vooroordelen en toxiciteit).
- Genereer een query door prompttrefwoorden toe te wijzen aan de gegevenscatalogus.
- Pas FGAC-beleid toe op basis van de gebruikersrol.
- Pas RBAC-beleid toe op basis van de gebruikersrol.
- Pas gegevens- en inhoudredactie toe op het antwoord op basis van gebruikersrolmachtigingen en nalevingsbeleid.
Als onderdeel van de promptcyclus moet de gebruikersprompt worden geparseerd en moeten trefwoorden worden geëxtraheerd om te zorgen voor afstemming met het compliancebeleid met behulp van een service als Amazon Comprehend (zie Nieuw voor Amazon Comprehend – Detectie van toxiciteit) Of Vangrails voor Amazon Bedrock (preview). Wanneer dat is gevalideerd en de prompt vereist dat gestructureerde gegevens worden geëxtraheerd, kunnen de trefwoorden worden gebruikt in de gegevenscatalogus (zakelijk of technisch) om de relevante gegevenstabellen en -velden te extraheren en een query uit het datawarehouse samen te stellen. De gebruikersrechten worden geëvalueerd met behulp van AWS Lake-formatie om de relevante gegevens te filteren. In het geval van ongestructureerde gegevens worden de zoekresultaten beperkt op basis van het gebruikerstoestemmingsbeleid dat in de vectoropslag is geïmplementeerd. Als laatste stap moet de outputreactie van de LLM worden geëvalueerd aan de hand van gebruikersrechten (om de privacy en beveiliging van gegevens te garanderen) en de naleving van de veiligheid (bijvoorbeeld richtlijnen voor vooringenomenheid en toxiciteit).
Hoewel dit proces specifiek is voor een RAG-implementatie en van toepassing is op andere LLM-implementatiestrategieën, zijn er aanvullende controles:
- Snelle techniek – De toegang tot de aan te roepen promptsjablonen moet worden beperkt op basis van toegangscontrole aangevuld met bedrijfslogica.
- Modellen verfijnen en basismodellen trainen – In gevallen waarin objecten uit de beheerde zone in Amazon S3 worden gebruikt als trainingsgegevens voor het verfijnen van de basismodellen, moet het machtigingsbeleid worden geconfigureerd met Amazon S3 identiteits- en toegangsbeheer op bucket- of objectniveau op basis van de vereisten.
Samengevat
Databeheer is van cruciaal belang om organisaties in staat te stellen generatieve AI-toepassingen voor ondernemingen te bouwen. Naarmate zakelijke gebruiksscenario's zich blijven ontwikkelen, zal er behoefte zijn aan uitbreiding van de data-infrastructuur om nieuwe, diverse, ongestructureerde datasets te beheren en te beheren om afstemming op het privacy-, beveiligings- en kwaliteitsbeleid te garanderen. Dit beleid moet worden geïmplementeerd en beheerd als onderdeel van de gegevensopname, -opslag en -beheer van de bedrijfskennisbank, samen met de workflows voor gebruikersinteractie. Dit zorgt ervoor dat de generatieve AI-toepassingen niet alleen het risico op het delen van onnauwkeurige of verkeerde informatie minimaliseren, maar ook beschermen tegen vooroordelen en toxiciteit die tot schadelijke of lasterlijke resultaten kunnen leiden. Voor meer informatie over databeheer op AWS, zie Wat is gegevensbeheer?
In volgende berichten zullen we implementatierichtlijnen geven over hoe het beheer van de data-infrastructuur kan worden uitgebreid om generatieve AI-gebruiksscenario's te ondersteunen.
Over de auteurs
 Krishna Rupanagunta leidt een team van Data- en AI-specialisten bij AWS. Hij en zijn team werken samen met klanten om hen te helpen sneller te innoveren en betere beslissingen te nemen met behulp van data, analyses en AI/ML. Hij is te bereiken via LinkedIn.
Krishna Rupanagunta leidt een team van Data- en AI-specialisten bij AWS. Hij en zijn team werken samen met klanten om hen te helpen sneller te innoveren en betere beslissingen te nemen met behulp van data, analyses en AI/ML. Hij is te bereiken via LinkedIn.
 Imtiaz (Taz) zei is de WW Tech Leader voor Analytics bij AWS. Hij houdt ervan om met de gemeenschap in gesprek te gaan over alles wat met data en analytics te maken heeft. Hij is te bereiken via LinkedIn.
Imtiaz (Taz) zei is de WW Tech Leader voor Analytics bij AWS. Hij houdt ervan om met de gemeenschap in gesprek te gaan over alles wat met data en analytics te maken heeft. Hij is te bereiken via LinkedIn.
 Raghvender Arni (Arni) leidt het Customer Acceleration Team (CAT) binnen AWS Industries. De CAT is een wereldwijd, multifunctioneel team van klantgerichte cloudarchitecten, software-ingenieurs, datawetenschappers en AI/ML-experts en -ontwerpers dat innovatie stimuleert via geavanceerde prototyping, en operationele uitmuntendheid in de cloud stimuleert via gespecialiseerde technische expertise.
Raghvender Arni (Arni) leidt het Customer Acceleration Team (CAT) binnen AWS Industries. De CAT is een wereldwijd, multifunctioneel team van klantgerichte cloudarchitecten, software-ingenieurs, datawetenschappers en AI/ML-experts en -ontwerpers dat innovatie stimuleert via geavanceerde prototyping, en operationele uitmuntendheid in de cloud stimuleert via gespecialiseerde technische expertise.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/data-governance-in-the-age-of-generative-ai/

