Introductie
Als enthousiaste leerlingen willen leren data science en machine learning, ze zouden het versterkte gezin moeten leren kennen. Er zijn veel algoritmen die afkomstig zijn uit de familie van Boosted, zoals AdaBoost, Gradient Boosting, XGBoost en nog veel meer. Een van de algoritmen uit de Boosted-familie is een CatBoost-algoritme. CatBoost is een machine learning algoritme, en staat voor Categorical Boosting. Yandex heeft het ontwikkeld. Het is een open-source bibliotheek. Het wordt in beide gebruikt Python en R talen. CatBoost werkt heel goed met categorische variabelen in de dataset. Net als andere boosting-algoritmen creëert CatBoost ook meerdere beslissingsbomen op de achtergrond, ook wel een ensemble van bomen genoemd, om een classificatielabel te voorspellen. Het is gebaseerd op gradiëntversterking.
Lees ook: CatBoost: een machine learning-bibliotheek om automatisch categorische (CAT) gegevens te verwerken

leerdoelen
- Begrijp het concept van versterkte algoritmen en hun betekenis in datawetenschap en machine learning.
- Verken het CatBoost-algoritme als een van de gebooste gezinsleden, zijn oorsprong en zijn rol bij het omgaan met categorische variabelen.
- Begrijp de belangrijkste kenmerken van CatBoost, inclusief de behandeling van categorische variabelen, gradiëntboosting, geordende boosting en regularisatietechnieken.
- Krijg inzicht in de voordelen van CatBoost, zoals de robuuste verwerking van categorische variabelen en uitstekende voorspellende prestaties.
- Leer CatBoost in Python te implementeren voor regressie- en classificatietaken, het verkennen van modelparameters en het doen van voorspellingen op testgegevens.
Dit artikel is gepubliceerd als onderdeel van de Data Science Blogathon.
Belangrijke kenmerken van CatBoost
- Omgaan met categorische variabelen: CatBoost blinkt uit in het omgaan met datasets die categorische kenmerken bevatten. Met behulp van verschillende methoden gaan we automatisch om met categorische variabelen door ze om te zetten in numerieke representaties. Het omvat doelstatistieken, one-hot codering of een combinatie van beide. Deze mogelijkheid bespaart tijd en moeite door de vereiste voor handmatige voorverwerking van categorische kenmerken weg te nemen.
- Gradiëntversterking: CatBoost gebruikt verhoging van de gradiënt, een ensembletechniek die verschillende zwakke leerlingen (beslisbomen) combineert om effectieve voorspellende modellen te creëren. Door bomen toe te voegen die getraind en geïnstrueerd zijn om de fouten veroorzaakt door de voorgaande bomen recht te zetten, worden iteratief bomen gecreëerd terwijl een differentieerbare verliesfunctie wordt geminimaliseerd. Deze iteratieve benadering verbetert geleidelijk het voorspellende vermogen van het model.
- Besteld boosten: CatBoost stelt een nieuwe techniek voor genaamd "Ordered Boosting" om categorische kenmerken effectief aan te pakken. Bij het bouwen van de boom gebruikt het een techniek die bekend staat als permutatiegestuurde voorsortering van categorische variabelen om de optimale splitsingspunten te identificeren. Deze methode stelt CatBoost in staat om alle mogelijke gesplitste configuraties te overwegen, waardoor voorspellingen worden verbeterd en overfitting wordt verminderd.
- regularisatie: In CatBoost worden regularisatietechnieken gebruikt om overfitting te verminderen en generalisatie te verbeteren. Het beschikt over L2-regularisatie op bladwaarden, die de verliesfunctie wijzigt door een strafterm toe te voegen om buitensporige bladwaarden te voorkomen. Bovendien gebruikt het een geavanceerde methode die bekend staat als "Ordered Target Encoding" om overfitting te voorkomen bij het coderen van categorische gegevens.
Voordelen van CatBoost
- Robuuste behandeling van de categorische variabele: De automatische verwerking van CatBoost maakt voorverwerking handig en effectief. Het maakt handmatige coderingsmethoden overbodig en verkleint de kans op informatieverlies in verband met conventionele procedures.
- Uitstekende voorspellende prestaties: Voorspellingen gemaakt met behulp van CatBoost's gradiëntboosting-framework en Ordered Boosting zijn vaak nauwkeurig. Het kan sterke modellen produceren die veel andere algoritmen overtreffen en ingewikkelde relaties in de gegevens effectief vastleggen.
Cases
In verschillende Kaggle-wedstrijden met gegevens in tabelvorm heeft Catboost bewezen een toppresteerder te zijn. CatBoost maakt met succes gebruik van verschillende regressie- en classificatietaken. Hier zijn een paar gevallen waarin CatBoost met succes is gebruikt:
- Cloudflare gebruikt Catboost om bots te identificeren die zich richten op de websites van zijn gebruikers.
- Ride-hailingservice Careem, gevestigd in Dubai, gebruikt Catboost om te voorspellen waar haar klanten naartoe zullen reizen.
Implementatie
Aangezien CatBoost een open source-bibliotheek is, moet u ervoor zorgen dat u deze hebt geïnstalleerd. Zo niet, dan is hier de opdracht om het CatBoost-pakket te installeren.
#installing the catboost library
!pip install catboostJe kunt een catboost-algoritme trainen en bouwen in zowel Python- als R-talen, maar we zullen in deze implementatie alleen Python als taal gebruiken.
Zodra het CatBoost-pakket is geïnstalleerd, importeren we de catboost en andere noodzakelijke bibliotheken.
#import libraries
import pandas as pd
import os
import matplotlib.pyplot as plt
import seaborn as sns import catboost as cb
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score import warnings
warnings.filterwarnings('ignore')
Hier gebruiken we de Big Mart-verkoopgegevensset en voeren we enkele gegevenscontroles uit.
#uploading dataset
os.chdir('E:Dataset')
dt = pd.read_csv('big_mart_sales.csv') dt.head() dt.describe()
dt.info()
dt.shape
De dataset bevat meer dan 1 records en 35 kolommen, waarvan 8 kolommen categorisch zijn, maar we zullen die kolommen niet converteren naar numeriek formaat. Catboost zelf kan zulke dingen doen. Dit is de magie van Catboost. U kunt zoveel dingen vermelden als u wilt in de modelparameter. Ik heb alleen "iteratie" voor demo-doeleinden als parameter genomen.
#import csv
X = dt.drop('Attrition', axis=1)
y = dt['Attrition'] X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=14)
print(X_train.shape)
print(X_test.shape) cat_var = np.where(X_train.dtypes != np.float)[0] model = cb.CatBoostClassifier(iterations=10)
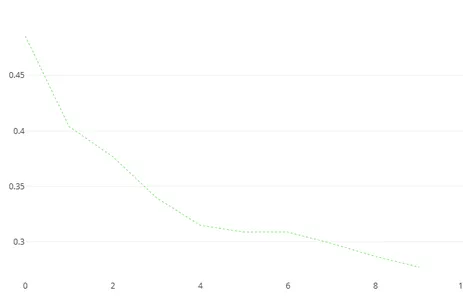
model.fit(X_train, y_train, cat_features=cat_var, plot=True)
Er zijn veel modelparameters die u gebruikt. Hieronder staan de belangrijke parameters die u kunt vermelden bij het bouwen van een CatBoost-model.
parameters
- Iteraties: Het aantal boosting-iteraties of te bouwen bomen. Hogere waarden kunnen leiden tot betere prestaties maar langere trainingsperioden. Het is een geheel getal dat varieert van 1 tot oneindig [1, ∞].
- Lverdienpercentage: De stapgrootte waarmee het algoritme voor het versterken van de gradiënt leert. Een lager getal zorgt ervoor dat het model langzamer convergeert, maar zou de generalisatie kunnen verbeteren. Het moet een zwevende waarde zijn, variërend van 0 tot 1
- Ddiepte: De maximale diepte van de individuele beslissingsbomen in het ensemble. Hoewel diepere bomen een grotere kans hebben op overfitting, kunnen ze meer gecompliceerde interacties vastleggen. Het is een geheel getal dat varieert van 1 tot oneindig [1, ∞].
- Loss_functie: Tijdens de training moeten we de verliesfunctie optimaliseren. Verschillende soorten problemen, zoals "Logloss" voor binaire classificatie, "MultiClass" voor classificatie met meerdere klassen, "RMSE" voor regressie, enz. hebben verschillende
oplossingen. Het is een tekenreekswaarde. - l2_leaf_reg: De bladwaarden werden onderworpen aan L2-regularisatie. Grote bladwaarden worden bestraft met hogere waarden, waardoor overfitting wordt geminimaliseerd. Het is een float-waarde, variërend van 0 tot oneindig [0, ∞].
- grens_telling: Het aantal splitsingen voor numerieke functies. Hoewel hogere getallen een nauwkeurigere splitsing bieden, kunnen ze ook overfitting veroorzaken. 128 is de voorgestelde waarde voor grotere datasets. Het is een geheel getal tussen 1 en 255 [1, 255].
- willekeurige_sterkte: Het willekeurigheidsniveau dat moet worden gebruikt bij het selecteren van de splitsingspunten. Er wordt meer willekeur geïntroduceerd met een grotere waarde, waardoor overfitting wordt voorkomen. Bereik: [0, ∞].
- inpaktemperatuur: Bepaalt de intensiteit van de bemonstering van de trainingsexemplaren. Een grotere waarde verlaagt de willekeur van het inpakproces, terwijl een lagere waarde deze verhoogt. Het is een float-waarde, variërend van 0 tot oneindig [0, ∞].
Voorspellingen doen op het getrainde model
#model prediction on the test set
y_pred = model.predict(X_test) print(accuracy_score(y_pred, y_test)) print(confusion_matrix(y_pred, y_test))U kunt de drempelwaarde ook instellen met behulp van de predict_proba() functie. Hier hebben we een nauwkeurigheidsscore van meer dan 85% behaald, wat een goede waarde is gezien het feit dat we geen enkele categorische variabele in getallen hebben verwerkt. Dat laat ons zien hoe krachtig het Catboost-algoritme is.
Conclusie
CatBoost is een van de doorbraak en bekende modellen op het gebied van machine learning. Het kreeg veel belangstelling vanwege het vermogen om zelf met categorische kenmerken om te gaan. Uit dit artikel leert u het volgende:
- De praktische implementatie van catboost.
- Wat zijn de belangrijke kenmerken van het catboost-algoritme?
- Gebruik gevallen waarin catboost goed heeft gepresteerd
- Modelparameters van catboost tijdens het trainen van een model
Veelgestelde Vragen / FAQ
A. Catboost is een algoritme voor machinaal leren onder toezicht. Het kan worden gebruikt voor zowel regressie- als classificatieproblemen.
A. Catboost is een open-source gradiëntverhogende bibliotheek die categorische gegevens heel goed verwerkt; vandaar dat het de boosttechniek gebruikt.
A. De pool is als een intern gegevensformaat in Catboost. Als je er een numpy-array aan doorgeeft, zal het deze impliciet eerst naar Pool converteren, zonder het je te vertellen. Als u veel formules op één dataset moet toepassen, verhoogt het gebruik van Pool de prestaties drastisch (zoals 10x), omdat u elke keer de conversiestap overslaat.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/07/catboost-building-model-with-categorical-data/

