We zijn getuige van een snelle toename van de adoptie van grote taalmodellen (LLM) die generatieve AI-toepassingen in verschillende sectoren aandrijven. LLM's kunnen een verscheidenheid aan taken uitvoeren, zoals het genereren van creatieve inhoud, het beantwoorden van vragen via chatbots, het genereren van code en meer.
Organisaties die LLM’s willen gebruiken om hun applicaties aan te drijven, zijn steeds meer op hun hoede als het gaat om gegevensprivacy om ervoor te zorgen dat het vertrouwen en de veiligheid binnen hun generatieve AI-applicaties behouden blijft. Dit omvat ook het correct omgaan met de persoonlijk identificeerbare informatie (PII)-gegevens van klanten. Het omvat ook het voorkomen dat beledigende en onveilige inhoud wordt verspreid naar LLM's en het controleren of de door LLM's gegenereerde gegevens dezelfde principes volgen.
In dit bericht bespreken we nieuwe functies mogelijk gemaakt door Amazon begrijpt het die een naadloze integratie mogelijk maken om de privacy van gegevens, de veiligheid van de inhoud en de snelle veiligheid in nieuwe en bestaande generatieve AI-toepassingen te garanderen.
Amazon Comprehend is een dienst voor natuurlijke taalverwerking (NLP) die machine learning (ML) gebruikt om informatie in ongestructureerde gegevens en tekst in documenten te ontdekken. In dit bericht bespreken we waarom vertrouwen en veiligheid bij LLM's belangrijk zijn voor uw werkdruk. We gaan ook dieper in op de manier waarop deze nieuwe moderatiemogelijkheden worden gebruikt met het populaire generatieve AI-ontwikkelingsframework LangChain om een aanpasbaar vertrouwens- en veiligheidsmechanisme voor uw gebruiksscenario te introduceren.
Waarom vertrouwen en veiligheid bij LLM's belangrijk zijn
Vertrouwen en veiligheid zijn van het grootste belang bij het werken met LLM's vanwege hun diepgaande impact op een breed scala aan toepassingen, van chatbots voor klantenondersteuning tot het genereren van inhoud. Naarmate deze modellen enorme hoeveelheden gegevens verwerken en menselijke reacties genereren, neemt de kans op misbruik of onbedoelde resultaten toe. Ervoor zorgen dat deze AI-systemen binnen ethische en betrouwbare grenzen functioneren, is van cruciaal belang, niet alleen voor de reputatie van bedrijven die er gebruik van maken, maar ook voor het behoud van het vertrouwen van eindgebruikers en klanten.
Naarmate LLM’s meer geïntegreerd raken in onze dagelijkse digitale ervaringen, groeit bovendien hun invloed op onze percepties, overtuigingen en beslissingen. Het garanderen van vertrouwen en veiligheid bij LLM’s gaat verder dan alleen technische maatregelen; het spreekt over de bredere verantwoordelijkheid van AI-beoefenaars en organisaties om ethische normen hoog te houden. Door vertrouwen en veiligheid voorop te stellen, beschermen organisaties niet alleen hun gebruikers, maar zorgen ze ook voor een duurzame en verantwoorde groei van AI in de samenleving. Het kan ook helpen het risico op het genereren van schadelijke inhoud te verminderen en te helpen voldoen aan wettelijke vereisten.
Op het gebied van vertrouwen en veiligheid is contentmoderatie een mechanisme dat verschillende aspecten aanpakt, waaronder maar niet beperkt tot:
- Privacy – Gebruikers kunnen onbedoeld tekst verstrekken die gevoelige informatie bevat, waardoor hun privacy in gevaar komt. Het detecteren en redigeren van PII is essentieel.
- Toxiciteit – Het herkennen en filteren van schadelijke inhoud, zoals haatzaaiende uitlatingen, bedreigingen of misbruik, is van het allergrootste belang.
- Gebruikersintentie – Het is van cruciaal belang om vast te stellen of de gebruikersinvoer (prompt) veilig of onveilig is. Onveilige prompts kunnen expliciet of impliciet kwaadaardige bedoelingen uiten, zoals het opvragen van persoonlijke of privé-informatie en het genereren van aanstootgevende, discriminerende of illegale inhoud. Prompts kunnen ook impliciet advies geven of vragen over medische, juridische, politieke, controversiële, persoonlijke of financiële kwesties
Contentmoderatie met Amazon Comprehend
In deze sectie bespreken we de voordelen van contentmoderatie met Amazon Comprehend.
Aandacht voor privacy
Amazon Comprehend pakt privacy al aan via zijn bestaande PII-detectie- en redactiemogelijkheden via de DetectPIIEntiteiten en BevatPIIEtiteiten API's. Deze twee API's worden ondersteund door NLP-modellen die een groot aantal PII-entiteiten kunnen detecteren, zoals burgerservicenummers (SSN's), creditcardnummers, namen, adressen, telefoonnummers, enzovoort. Voor een volledige lijst met entiteiten, zie PII universele entiteitstypen. DetectPII biedt ook de positie op tekenniveau van de PII-entiteit binnen een tekst; bijvoorbeeld de starttekenpositie van de entiteit NAME (John Doe) in de zin 'Mijn naam is Joh doee” is 12 en de eindtekenpositie is 19. Deze verschuivingen kunnen worden gebruikt om de waarden te maskeren of te redigeren, waardoor de risico's van de verspreiding van privégegevens naar LLM's worden verminderd.
Aanpak van toxiciteit en snelle veiligheid
Vandaag kondigen we twee nieuwe Amazon Comprehend-functies aan in de vorm van API’s: Toxiciteitsdetectie via de DetectToxicContent API en snelle veiligheidsclassificatie via de ClassifyDocument API. Merk op dat DetectToxicContent is een nieuwe API, terwijl ClassifyDocument is een bestaande API die nu snelle veiligheidsclassificatie ondersteunt.
Detectie van toxiciteit
Met de toxiciteitsdetectie van Amazon Comprehend kun je inhoud identificeren en markeren die mogelijk schadelijk, aanstootgevend of ongepast is. Deze mogelijkheid is met name waardevol voor platforms waarop gebruikers inhoud genereren, zoals sociale-mediasites, forums, chatbots, commentaarsecties en applicaties die LLM's gebruiken om inhoud te genereren. Het primaire doel is het handhaven van een positieve en veilige omgeving door de verspreiding van giftige inhoud te voorkomen.
In de kern analyseert het toxiciteitsdetectiemodel tekst om de waarschijnlijkheid te bepalen dat deze haatzaaiende inhoud, bedreigingen, obsceniteiten of andere vormen van schadelijke tekst bevat. Het model is getraind op grote datasets met voorbeelden van zowel toxische als niet-toxische inhoud. De toxiciteits-API evalueert een bepaald stuk tekst om de toxiciteitsclassificatie en betrouwbaarheidsscore te bepalen. Generatieve AI-toepassingen kunnen deze informatie vervolgens gebruiken om passende acties te ondernemen, zoals het voorkomen dat de tekst zich naar LLM's verspreidt. Op het moment van schrijven zijn de labels die door de toxiciteitsdetectie-API worden gedetecteerd dat wel HATE_SPEECH, GRAPHIC, HARRASMENT_OR_ABUSE, SEXUAL, VIOLENCE_OR_THREAT, INSULT en PROFANITY. De volgende code demonstreert de API-aanroep met Python Boto3 voor Amazon Comprehend-toxiciteitsdetectie:
Snelle veiligheidsclassificatie
Snelle veiligheidsclassificatie met Amazon Comprehend helpt bij het classificeren van een invoertekstprompt als veilig of onveilig. Deze mogelijkheid is van cruciaal belang voor toepassingen zoals chatbots, virtuele assistenten of tools voor inhoudsmoderatie, waarbij het begrijpen van de veiligheid van een prompt reacties, acties of inhoudspropagatie naar LLM's kan bepalen.
In wezen analyseert Prompt Safety Classification de menselijke input op expliciete of impliciete kwaadaardige bedoelingen, zoals het opvragen van persoonlijke of privé-informatie en het genereren van aanstootgevende, discriminerende of illegale inhoud. Het markeert ook aanwijzingen die op zoek zijn naar advies over medische, juridische, politieke, controversiële, persoonlijke of financiële onderwerpen. Snelle classificatie retourneert twee klassen, UNSAFE_PROMPT en SAFE_PROMPT, voor een bijbehorende tekst, met een bijbehorende betrouwbaarheidsscore voor elke tekst. De betrouwbaarheidsscore ligt tussen 0 en 1 en komt samen uit op 1. In een chatbot voor klantenondersteuning wordt bijvoorbeeld de tekst 'Hoe reset ik mijn wachtwoord?” signaleert de intentie om advies te zoeken over procedures voor het opnieuw instellen van wachtwoorden en wordt bestempeld als SAFE_PROMPT. Op dezelfde manier kan een uitspraak als “Ik zou willen dat er iets ergs met je gebeurt' kan worden gemarkeerd vanwege mogelijk schadelijke bedoelingen en worden bestempeld als UNSAFE_PROMPT. Het is belangrijk op te merken dat de veiligheidsclassificatie van prompts primair gericht is op het detecteren van intentie via menselijke input (prompts), in plaats van op door machines gegenereerde tekst (LLM-outputs). De volgende code laat zien hoe u toegang krijgt tot de prompt-veiligheidsclassificatiefunctie met de ClassifyDocument API:
Merk op dat endpoint_arn in de voorgaande code is een AWS-meegeleverd Amazon-bronnummer (ARN) van het patroon arn:aws:comprehend:<region>:aws:document-classifier-endpoint/prompt-safety, Waar <region> is de AWS-regio van uw keuze waar Amazon Comprehend is beschikbaar.
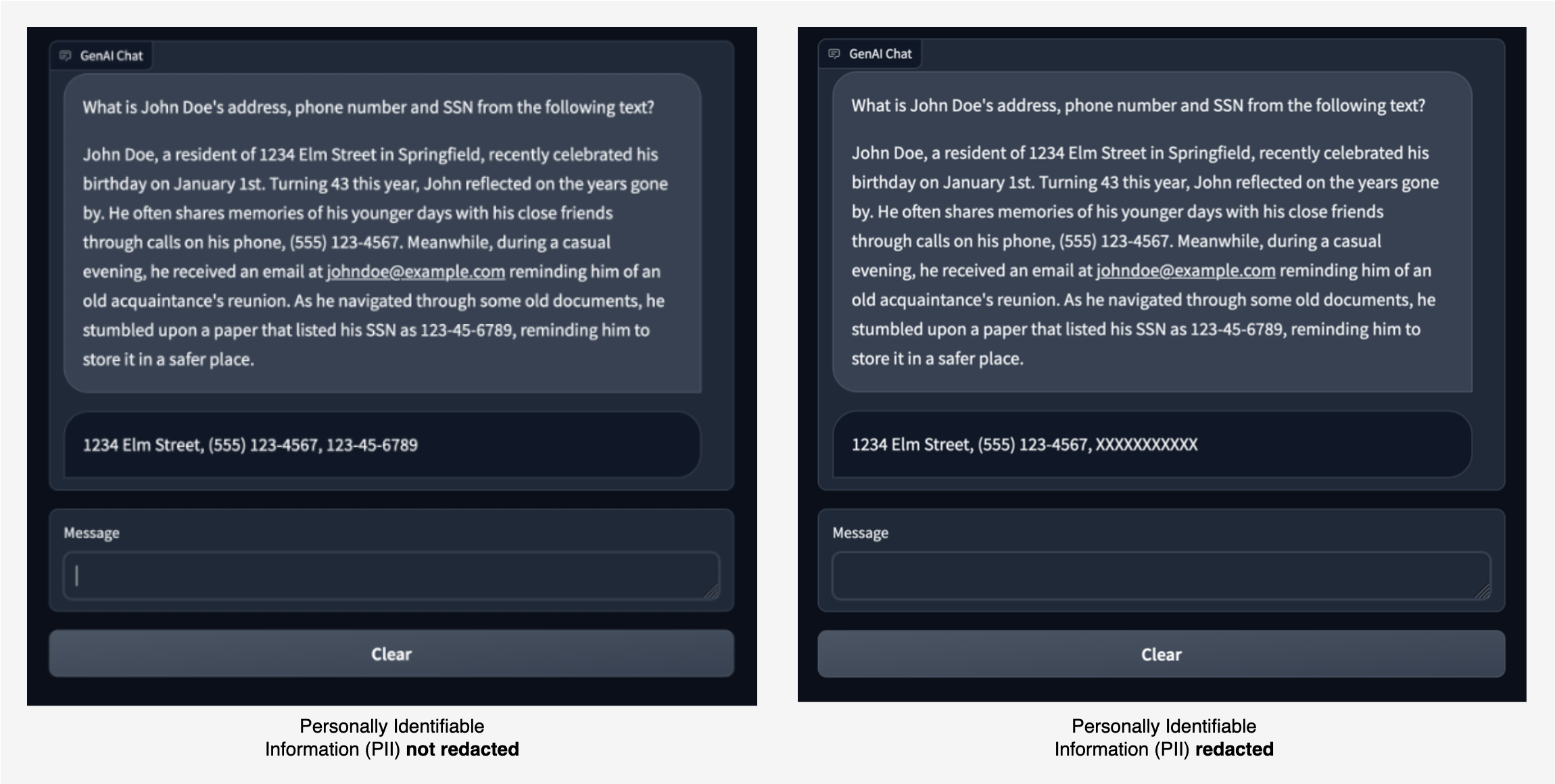
Om deze mogelijkheden te demonstreren, hebben we een voorbeeldchattoepassing gebouwd waarin we een LLM vragen PII-entiteiten zoals adres, telefoonnummer en BSN uit een bepaald stuk tekst te extraheren. De LLM vindt de juiste PII-entiteiten en retourneert deze, zoals weergegeven in de afbeelding aan de linkerkant.
Met Amazon Comprehend-moderatie kunnen we de invoer naar de LLM en de uitvoer van de LLM redigeren. In de afbeelding rechts mag de SSN-waarde zonder redactie aan de LLM worden doorgegeven. Elke SSN-waarde in het antwoord van de LLM wordt echter geredigeerd.
Het volgende is een voorbeeld van hoe kan worden voorkomen dat een prompt met PII-informatie de LLM bereikt. In dit voorbeeld ziet u hoe een gebruiker een vraag stelt die PII-informatie bevat. We gebruiken Amazon Comprehend-moderatie om PII-entiteiten in de prompt te detecteren en een fout weer te geven door de stroom te onderbreken.

De voorgaande chatvoorbeelden laten zien hoe Amazon Comprehend-moderatie beperkingen toepast op gegevens die naar een LLM worden verzonden. In de volgende secties leggen we uit hoe dit moderatiemechanisme wordt geïmplementeerd met behulp van LangChain.
Integratie met LangChain
Met de eindeloze mogelijkheden van de toepassing van LLM’s in verschillende gebruiksscenario’s is het net zo belangrijk geworden om de ontwikkeling van generatieve AI-toepassingen te vereenvoudigen. LangChain is een populair open source-framework waarmee u moeiteloos generatieve AI-toepassingen kunt ontwikkelen. Amazon Comprehend-moderatie breidt het LangChain-framework uit om PII-identificatie en -redactie, toxiciteitsdetectie en snelle veiligheidsclassificatiemogelijkheden te bieden via AmazonComprehendModerationChain.
AmazonComprehendModerationChain is een aangepaste implementatie van de LangChain-basisketen koppel. Dit betekent dat applicaties deze keten met hun eigen keten kunnen gebruiken LLM-ketens om de gewenste moderatie toe te passen op de invoerprompt en op de uitvoertekst van de LLM. Ketens kunnen worden gebouwd door talloze ketens samen te voegen of door ketens te mengen met andere componenten. Je kunt gebruiken AmazonComprehendModerationChain met andere LLM-ketens om op modulaire en flexibele wijze complexe AI-toepassingen te ontwikkelen.
Om het verder uit te leggen, geven we in de volgende paragrafen enkele voorbeelden. De broncode voor de AmazonComprehendModerationChain implementatie is te vinden binnen de LangChain open source-repository. Voor volledige documentatie van de API-interface raadpleegt u de LangChain API-documentatie voor de Amazon Begrijp de moderatieketen. Het gebruik van deze moderatieketen is net zo eenvoudig als het initialiseren van een exemplaar van de klasse met standaardconfiguraties:
Achter de schermen voert de moderatieketen drie opeenvolgende moderatiecontroles uit, namelijk PII, toxiciteit en snelle veiligheid, zoals uitgelegd in het volgende diagram. Dit is de standaardstroom voor moderatie.

Het volgende codefragment toont een eenvoudig voorbeeld van het gebruik van de moderatieketen met de Amazon FalconLite LLM (wat een gekwantiseerde versie is van de Falcon 40B SFT OASST-TOP1-model) gehost in Hugging Face Hub:
In het voorgaande voorbeeld breiden we onze keten uit met comprehend_moderation voor zowel tekst die naar de LLM gaat als tekst die door de LLM wordt gegenereerd. Hierdoor wordt standaard moderatie uitgevoerd die PII, toxiciteit en veiligheidsclassificatie in die volgorde controleert.
Pas uw moderatie aan met filterconfiguraties
U kunt gebruik maken van de AmazonComprehendModerationChain met specifieke configuraties, waardoor u kunt bepalen welke moderaties u wilt uitvoeren in uw generatieve AI-gebaseerde applicatie. In de kern van de configuratie zijn er drie filterconfiguraties beschikbaar.
- ModeratiePiiConfig – Wordt gebruikt om het PII-filter te configureren.
- MatigingToxiciteitConfig – Wordt gebruikt om het filter voor giftige inhoud te configureren.
- ModerationIntentConfig – Wordt gebruikt om het intentiefilter te configureren.
U kunt elk van deze filterconfiguraties gebruiken om het gedrag van uw moderaties aan te passen. De configuraties van elk filter hebben een paar gemeenschappelijke parameters en enkele unieke parameters waarmee ze kunnen worden geïnitialiseerd. Nadat u de configuraties hebt gedefinieerd, gebruikt u de BaseModerationConfig class om de volgorde te definiëren waarin de filters op de tekst moeten worden toegepast. In de volgende code definiëren we bijvoorbeeld eerst de drie filterconfiguraties en specificeren we vervolgens de volgorde waarin ze moeten worden toegepast:
Laten we wat dieper duiken om te begrijpen wat deze configuratie bereikt:
- Ten eerste hebben we voor het toxiciteitsfilter een drempelwaarde van 0.6 gespecificeerd. Dit betekent dat als de tekst een van de beschikbare toxische labels of entiteiten bevat met een score hoger dan de drempelwaarde, de hele keten wordt onderbroken.
- Als er geen giftige inhoud in de tekst wordt aangetroffen, wordt er een PII-controle uitgevoerd. In dit geval willen we controleren of de tekst SSN-waarden bevat. Omdat de
redactparameter is ingesteld opTrue, maskeert de keten de gedetecteerde SSN-waarden (indien aanwezig) waarbij de betrouwbaarheidsscore van de SSN-entiteit groter is dan of gelijk is aan 0.5, waarbij het maskerteken is opgegeven (X). Alsredactis ingesteld opFalse, wordt de keten onderbroken voor elk gedetecteerd SSN. - Ten slotte voert de keten een snelle veiligheidsclassificatie uit en voorkomt dat de inhoud zich verder in de keten verspreidt als de inhoud is geclassificeerd met
UNSAFE_PROMPTmet een betrouwbaarheidsscore groter dan of gelijk aan 0.8.
Het volgende diagram illustreert deze workflow.
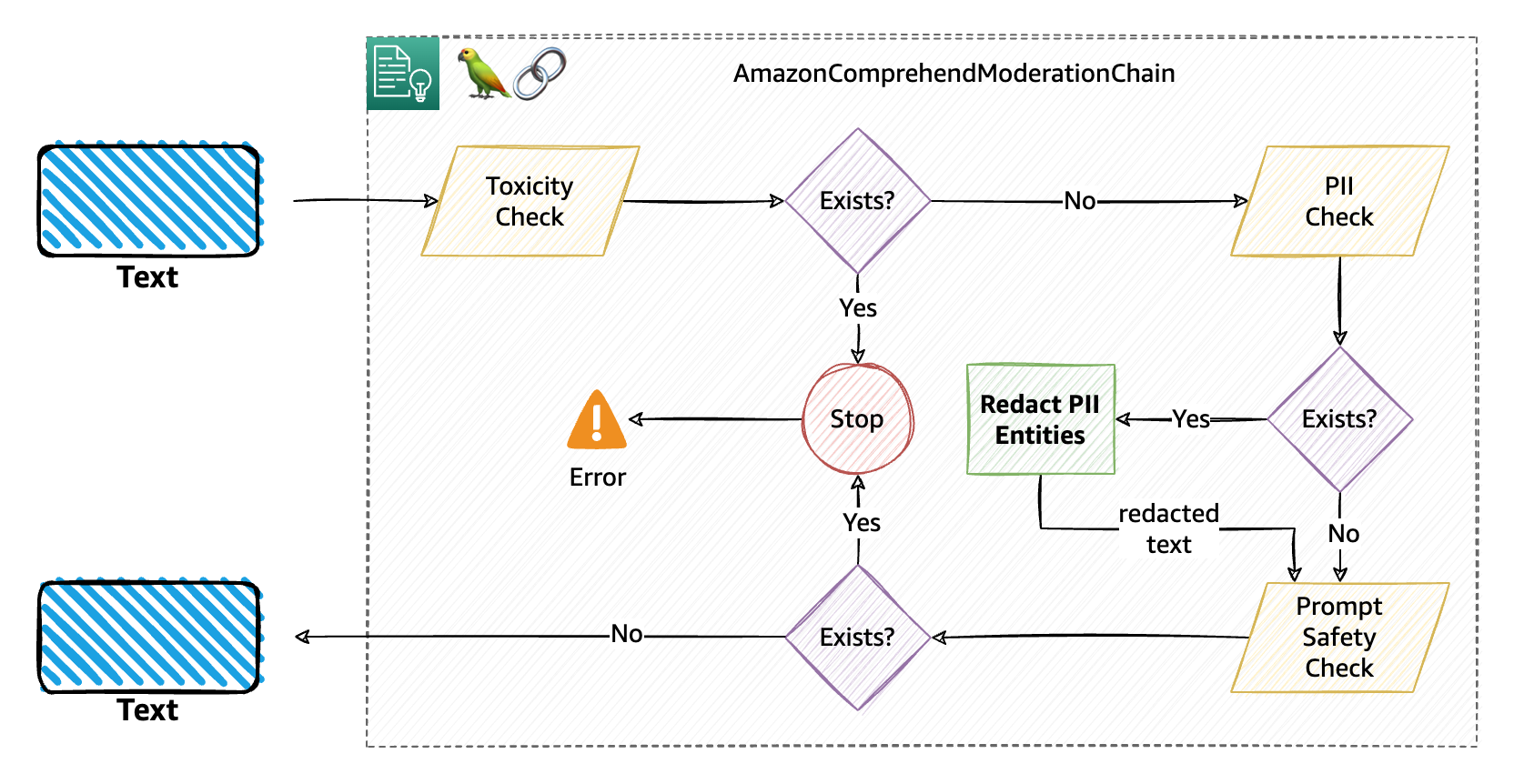
Bij onderbrekingen van de moderatieketen (in dit voorbeeld van toepassing op de toxiciteits- en promptveiligheidsclassificatiefilters) zal de keten een Python-uitzondering, waardoor in wezen de lopende keten wordt gestopt en u de uitzondering kunt opvangen (in een try-catch-blok) en elke relevante actie kunt uitvoeren. De drie mogelijke uitzonderingstypen zijn:
ModerationPIIErrorModerationToxicityErrorModerationPromptSafetyError
U kunt één filter of meer dan één filter configureren met behulp van BaseModerationConfig. Je kunt ook hetzelfde type filter hebben met verschillende configuraties binnen dezelfde keten. Als uw gebruiksscenario bijvoorbeeld alleen betrekking heeft op PII, kunt u een configuratie opgeven die de keten moet onderbreken als er een SSN wordt gedetecteerd; anders moet het redactie van PII-entiteiten met leeftijd en naam uitvoeren. Een configuratie hiervoor kan als volgt worden gedefinieerd:
Het gebruik van callbacks en unieke identificatiegegevens
Als u bekend bent met het concept van workflows, bent u er wellicht ook bekend mee terugbelverzoeken. Callbacks binnen workflows zijn onafhankelijke stukjes code die worden uitgevoerd wanneer aan bepaalde voorwaarden binnen de workflow wordt voldaan. Een terugbelactie kan blokkerend of niet-blokkerend zijn voor de workflow. LangChain-ketens zijn in wezen workflows voor LLM's. AmazonComprehendModerationChain Hiermee kunt u uw eigen terugbelfuncties definiëren. In eerste instantie is de implementatie beperkt tot alleen asynchrone (niet-blokkerende) callback-functies.
Dit betekent in feite dat als je callbacks gebruikt met de moderatieketen, deze onafhankelijk van de ketenrun worden uitgevoerd zonder deze te blokkeren. Voor de moderatieketen krijg je opties om stukjes code uit te voeren, met elke bedrijfslogica, nadat elke moderatie is uitgevoerd, onafhankelijk van de keten.
U kunt optioneel ook een willekeurige unieke identificatiereeks opgeven bij het maken van een AmazonComprehendModerationChain om logboekregistratie en analyse later in te schakelen. Als u bijvoorbeeld een chatbot beheert die wordt aangedreven door een LLM, wilt u wellicht gebruikers volgen die voortdurend misbruik maken of opzettelijk of onbewust persoonlijke informatie vrijgeven. In dergelijke gevallen wordt het noodzakelijk om de oorsprong van dergelijke aanwijzingen te achterhalen en deze eventueel in een database op te slaan of op de juiste manier te loggen voor verdere actie. U kunt een unieke ID doorgeven die een gebruiker duidelijk identificeert, zoals de gebruikersnaam of het e-mailadres, of een toepassingsnaam die de prompt genereert.
De combinatie van callbacks en unieke identificatiegegevens biedt u een krachtige manier om een moderatieketen te implementeren die bij uw gebruiksscenario past, op een veel samenhangendere manier met minder code die gemakkelijker te onderhouden is. De callback-handler is beschikbaar via de BaseModerationCallbackHandler, met drie beschikbare terugbelverzoeken: on_after_pii(), on_after_toxicity() en on_after_prompt_safety(). Elk van deze callback-functies wordt asynchroon aangeroepen nadat de betreffende moderatiecontrole binnen de keten is uitgevoerd. Deze functies ontvangen ook twee standaardparameters:
- moderatie_beacon – Een woordenboek met details zoals de tekst waarop de moderatie is uitgevoerd, de volledige JSON-uitvoer van de Amazon Comprehend API, het type moderatie en of de opgegeven labels (in de configuratie) in de tekst zijn aangetroffen of niet
- unieke_id – De unieke ID die u hebt toegewezen tijdens het initialiseren van een exemplaar van de
AmazonComprehendModerationChain.
Het volgende is een voorbeeld van hoe een implementatie met callback werkt. In dit geval hebben we een enkele callback gedefinieerd die we door de keten willen laten uitvoeren nadat de PII-controle is uitgevoerd:
We gebruiken dan de my_callback object tijdens het initialiseren van de moderatieketen en geef ook a door unique_id. U kunt terugbellen en unieke identificatiegegevens gebruiken met of zonder configuratie. Wanneer je een subklasse hebt BaseModerationCallbackHandler, moet u een of alle callback-methoden implementeren, afhankelijk van de filters die u wilt gebruiken. Kortheidshalve toont het volgende voorbeeld een manier om callbacks en te gebruiken unique_id zonder enige configuratie:
In het volgende diagram wordt uitgelegd hoe deze moderatieketen met callbacks en unieke ID's werkt. Concreet hebben we de PII-callback geïmplementeerd die een JSON-bestand moet schrijven met de gegevens die beschikbaar zijn in de moderation_beacon en unique_id doorgegeven (in dit geval het e-mailadres van de gebruiker).

In de volgende Python notitieboek, hebben we een aantal verschillende manieren verzameld waarop u de moderatieketen kunt configureren en gebruiken met verschillende LLM's, zoals LLM's die worden gehost met Amazon SageMaker JumpStart en gehost Knuffelen Gezicht Hub. We hebben de voorbeeldchatapplicatie die we eerder bespraken ook hieronder opgenomen Python notitieboek.
Conclusie
Het transformatieve potentieel van grote taalmodellen en generatieve AI valt niet te ontkennen. Het verantwoorde en ethische gebruik ervan hangt echter af van het aanpakken van zorgen op het gebied van vertrouwen en veiligheid. Door de uitdagingen te onderkennen en actief maatregelen te implementeren om de risico's te beperken, kunnen ontwikkelaars, organisaties en de samenleving als geheel de voordelen van deze technologieën benutten en tegelijkertijd het vertrouwen en de veiligheid behouden die ten grondslag liggen aan hun succesvolle integratie. Gebruik Amazon Comprehend ContentModerationChain om vertrouwens- en veiligheidsfuncties toe te voegen aan elke LLM-workflow, inclusief Retrieval Augmented Generation (RAG)-workflows geïmplementeerd in LangChain.
Voor informatie over het bouwen van op RAG gebaseerde oplossingen met behulp van LangChain en Amazon Kendra's zeer nauwkeurige, op machine learning (ML) gebaseerde intelligent zoeken, zien - Bouw snel zeer nauwkeurige generatieve AI-applicaties op bedrijfsgegevens met behulp van Amazon Kendra, LangChain en grote taalmodellen. Raadpleeg voor een volgende stap de code voorbeelden we hebben gemaakt voor het gebruik van Amazon Comprehend-moderatie met LangChain. Voor volledige documentatie van de Amazon Comprehend-moderatieketen-API raadpleegt u de LangChain API-documentatie.
Over de auteurs
 Wrick Talukdar is een Senior Architect bij het Amazon Comprehend Service-team. Hij werkt samen met AWS-klanten om hen te helpen machine learning op grote schaal toe te passen. Naast zijn werk houdt hij van lezen en fotograferen.
Wrick Talukdar is een Senior Architect bij het Amazon Comprehend Service-team. Hij werkt samen met AWS-klanten om hen te helpen machine learning op grote schaal toe te passen. Naast zijn werk houdt hij van lezen en fotograferen.
 Anjan Biswas is een Senior AI Services Solutions Architect met een focus op AI/ML en Data Analytics. Anjan maakt deel uit van het wereldwijde AI-serviceteam en werkt samen met klanten om hen te helpen bij het begrijpen en ontwikkelen van oplossingen voor zakelijke problemen met AI en ML. Anjan heeft meer dan 14 jaar ervaring in het werken met wereldwijde supply chain-, productie- en retailorganisaties en helpt klanten actief om aan de slag te gaan en op te schalen met AWS AI-services.
Anjan Biswas is een Senior AI Services Solutions Architect met een focus op AI/ML en Data Analytics. Anjan maakt deel uit van het wereldwijde AI-serviceteam en werkt samen met klanten om hen te helpen bij het begrijpen en ontwikkelen van oplossingen voor zakelijke problemen met AI en ML. Anjan heeft meer dan 14 jaar ervaring in het werken met wereldwijde supply chain-, productie- en retailorganisaties en helpt klanten actief om aan de slag te gaan en op te schalen met AWS AI-services.
 Nikhil Jha is Senior Technical Account Manager bij Amazon Web Services. Zijn aandachtsgebieden zijn onder meer AI/ML en analytics. In zijn vrije tijd speelt hij graag badminton met zijn dochter en gaat hij graag de natuur in.
Nikhil Jha is Senior Technical Account Manager bij Amazon Web Services. Zijn aandachtsgebieden zijn onder meer AI/ML en analytics. In zijn vrije tijd speelt hij graag badminton met zijn dochter en gaat hij graag de natuur in.
 Kin Rane is een AI/ML Specialist Solutions Architect bij Amazon Web Services. Ze is gepassioneerd door toegepaste wiskunde en machine learning. Ze richt zich op het ontwerpen van intelligente documentverwerkingsoplossingen voor AWS-klanten. Naast haar werk houdt ze van salsa- en bachatadansen.
Kin Rane is een AI/ML Specialist Solutions Architect bij Amazon Web Services. Ze is gepassioneerd door toegepaste wiskunde en machine learning. Ze richt zich op het ontwerpen van intelligente documentverwerkingsoplossingen voor AWS-klanten. Naast haar werk houdt ze van salsa- en bachatadansen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/build-trust-and-safety-for-generative-ai-applications-with-amazon-comprehend-and-langchain/

