Introductie
In de snelle wereld van vandaag is klantenservice een cruciaal aspect van elk bedrijf. Een Zendesk Answer Bot, mogelijk gemaakt door Large Language Models (LLM's) zoals GPT-4, kan de efficiëntie en kwaliteit van de klantenondersteuning aanzienlijk verbeteren door antwoorden te automatiseren. Deze blogpost begeleidt u bij het bouwen en implementeren van uw eigen Zendesk Auto Responder met behulp van LLM's en bij het implementeren van op RAG gebaseerde workflows in GenAI om het proces te stroomlijnen.

Wat zijn op RAG gebaseerde workflows in GenAI
Op RAG (Retrieval Augmented Generation) gebaseerde workflows in GenAI (Generative AI) combineren de voordelen van ophalen en genereren om de mogelijkheden van het AI-systeem te verbeteren, met name bij het verwerken van domeinspecifieke gegevens uit de echte wereld. Simpel gezegd stelt RAG de AI in staat relevante informatie uit een database of andere bronnen te halen om het genereren van nauwkeurigere en beter geïnformeerde antwoorden te ondersteunen. Dit is vooral nuttig in zakelijke omgevingen waar nauwkeurigheid en context van cruciaal belang zijn.
Wat zijn de componenten in een op RAG gebaseerde workflow?
- Kennis basis: De kennisbank is een gecentraliseerde opslagplaats van informatie waarnaar het systeem verwijst bij het beantwoorden van vragen. Het kan veelgestelde vragen, handleidingen en andere relevante documenten bevatten.
- Trigger/vraag: Deze component is verantwoordelijk voor het initiëren van de workflow. Meestal is het de vraag of het verzoek van een klant die een reactie of actie vereist.
- Taak/actie: Op basis van de analyse van de trigger/query voert het systeem een specifieke taak of actie uit, zoals het genereren van een antwoord of het uitvoeren van een backend-bewerking.
Enkele voorbeelden van op RAG gebaseerde workflows
- Workflow voor klantinteractie in het bankwezen:
- Chatbots aangedreven door GenAI en RAG kunnen de betrokkenheid in de banksector aanzienlijk verbeteren door interacties te personaliseren.
- Via RAG kunnen de chatbots relevante informatie uit een database ophalen en gebruiken om gepersonaliseerde antwoorden op vragen van klanten te genereren.
- Tijdens een chatsessie kan een op RAG gebaseerd GenAI-systeem bijvoorbeeld de transactiegeschiedenis of accountinformatie van de klant uit een database halen om beter geïnformeerde en gepersonaliseerde antwoorden te geven.
- Deze workflow verbetert niet alleen de klanttevredenheid, maar verhoogt mogelijk ook het retentiepercentage door een meer gepersonaliseerde en informatieve interactie-ervaring te bieden.
- E-mailcampagnes workflow:
- Bij marketing en sales is het creëren van gerichte campagnes cruciaal.
- RAG kan worden ingezet om de nieuwste productinformatie, klantfeedback of markttrends uit externe bronnen op te halen om beter geïnformeerd en effectiever marketing-/verkoopmateriaal te genereren.
- Bij het opzetten van een e-mailcampagne kan een op RAG gebaseerde workflow bijvoorbeeld recente positieve recensies of nieuwe productfuncties ophalen om in de campagne-inhoud op te nemen, waardoor de betrokkenheidspercentages en verkoopresultaten mogelijk worden verbeterd.
- Geautomatiseerde codedocumentatie en wijzigingsworkflow:
- In eerste instantie kan een RAG-systeem bestaande codedocumentatie, codebase en coderingsstandaarden uit de projectrepository halen.
- Wanneer een ontwikkelaar een nieuwe functie moet toevoegen, kan RAG een codefragment genereren volgens de coderingsstandaarden van het project door te verwijzen naar de opgehaalde informatie.
- Als er een wijziging in de code nodig is, kan het RAG-systeem wijzigingen voorstellen door de bestaande code en documentatie te analyseren, waardoor consistentie en naleving van coderingsstandaarden worden gegarandeerd.
- Door wijziging of toevoeging van een postcode kan RAG de codedocumentatie automatisch bijwerken om de wijzigingen weer te geven, waarbij de benodigde informatie uit de codebase en bestaande documentatie wordt opgehaald.
Hoe u alle Zendesk-tickets kunt downloaden en indexeren om ze op te halen
Laten we nu aan de slag gaan met de tutorial. We zullen een bot bouwen om inkomende Zendesk-tickets te beantwoorden, terwijl we een aangepaste database van eerdere Zendesk-tickets en -reacties gebruiken om het antwoord te genereren met behulp van LLM's.
- Toegang tot de Zendesk-API: Gebruik de Zendesk API om alle tickets te openen en te downloaden. Zorg ervoor dat u over de benodigde machtigingen en API-sleutels beschikt om toegang te krijgen tot de gegevens.
We maken eerst onze Zendesk API-sleutel. Zorg ervoor dat u een beheerdersgebruiker bent en ga naar de volgende link om uw API-sleutel te maken: https://YOUR_SUBDOMAIN.zendesk.com/admin/apps-integrations/apis/zendesk-api/settings/tokens
Maak een API-sleutel en kopieer deze naar uw klembord.
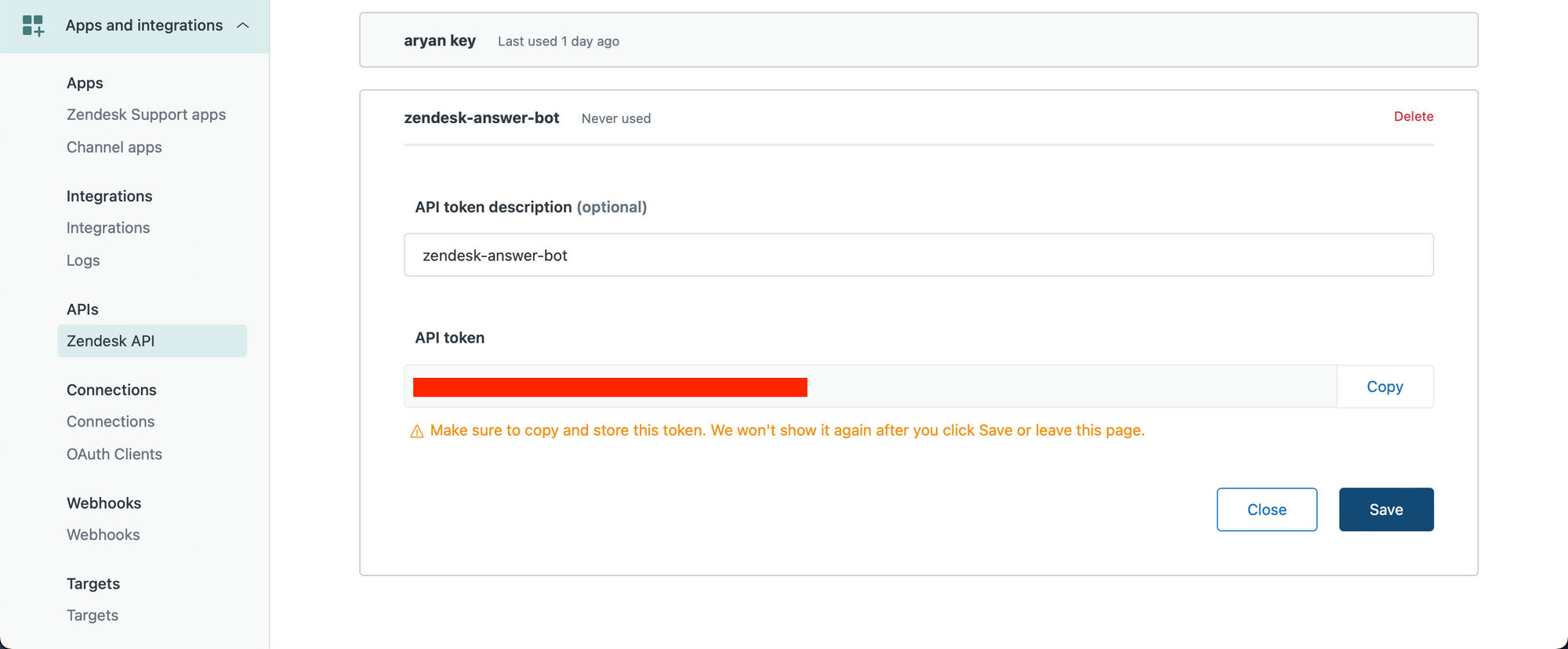
Laten we nu aan de slag gaan in een Python-notebook.
We voeren onze Zendesk-inloggegevens in, inclusief de API-sleutel die we zojuist hebben verkregen.
subdomain = YOUR_SUBDOMAIN
username = ZENDESK_USERNAME
password = ZENDESK_API_KEY
username = '{}/token'.format(username)We halen nu ticketgegevens op. In de onderstaande code hebben we vragen en antwoorden van elk ticket opgehaald en slaan we elke set [query, array of questions] op die een ticket vertegenwoordigt in een array met de naam ticketgegevens.
Wij halen alleen de laatste 1000 tickets op. U kunt dit indien nodig wijzigen.
import requests ticketdata = []
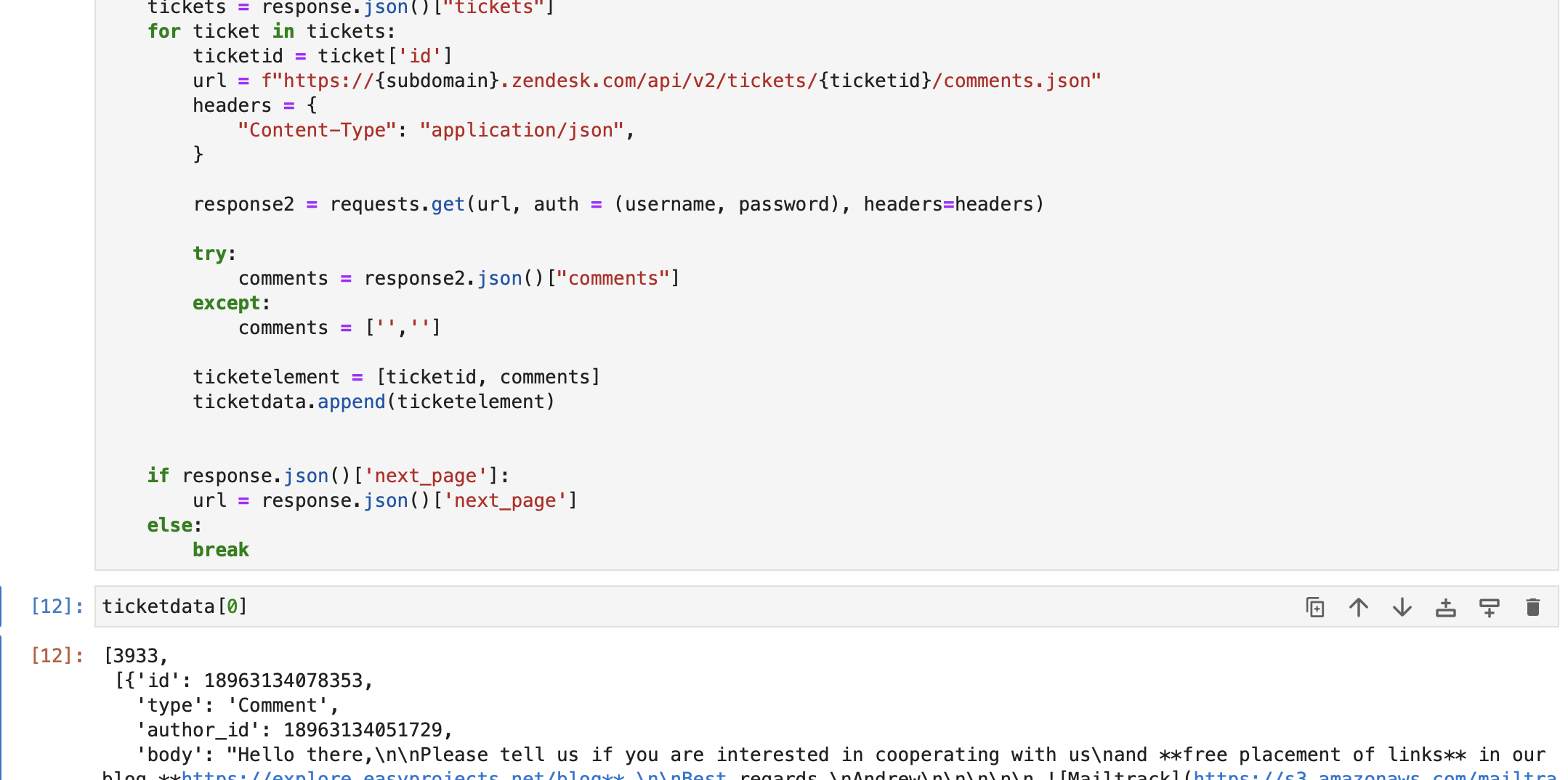
url = f"https://{subdomain}.zendesk.com/api/v2/tickets.json" params = {"sort_by": "created_at", "sort_order": "desc"} headers = {"Content-Type": "application/json"} tickettext = "" while len(ticketdata) <= 1000: response = requests.get( url, auth=(username, password), params=params, headers=headers ) tickets = response.json()["tickets"] for ticket in tickets: ticketid = ticket["id"] url = f"https://{subdomain}.zendesk.com/api/v2/tickets/{ticketid}/comments.json" headers = { "Content-Type": "application/json", } response2 = requests.get(url, auth=(username, password), headers=headers) try: comments = response2.json()["comments"] except: comments = ["", ""] ticketelement = [ticketid, comments] ticketdata.append(ticketelement) if response.json()["next_page"]: url = response.json()["next_page"] else: breakZoals je hieronder kunt zien, hebben we ticketgegevens uit de Zendesk-db opgehaald. Elk element erin ticketgegevens bevat –
A. Ticket ID
B. Alle opmerkingen/antwoorden in het ticket.
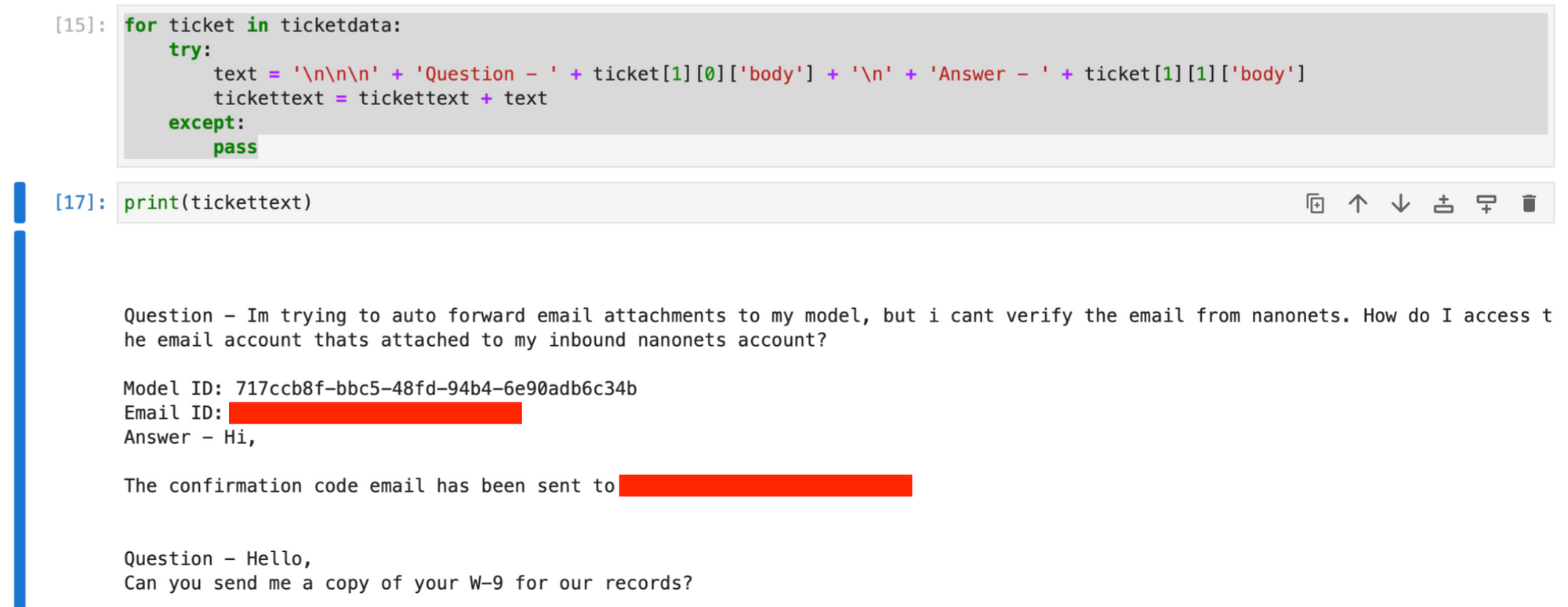
Vervolgens gaan we verder met het maken van een op tekst gebaseerde string met de vragen en eerste antwoorden van alle opgehaalde tickets, met behulp van de ticketgegevens matrix.
for ticket in ticketdata: try: text = ( "nnn" + "Question - " + ticket[1][0]["body"] + "n" + "Answer - " + ticket[1][1]["body"] ) tickettext = tickettext + text except: passDe tickettekst string bevat nu alle tickets en eerste reacties, waarbij de gegevens van elk ticket worden gescheiden door nieuweregeltekens.
Optioneel : U kunt ook gegevens uit uw Zendesk Support-artikelen ophalen om de kennisbank verder uit te breiden, door de onderstaande code uit te voeren.
import re def remove_tags(text): clean = re.compile("<.*?>") return re.sub(clean, "", text) articletext = ""
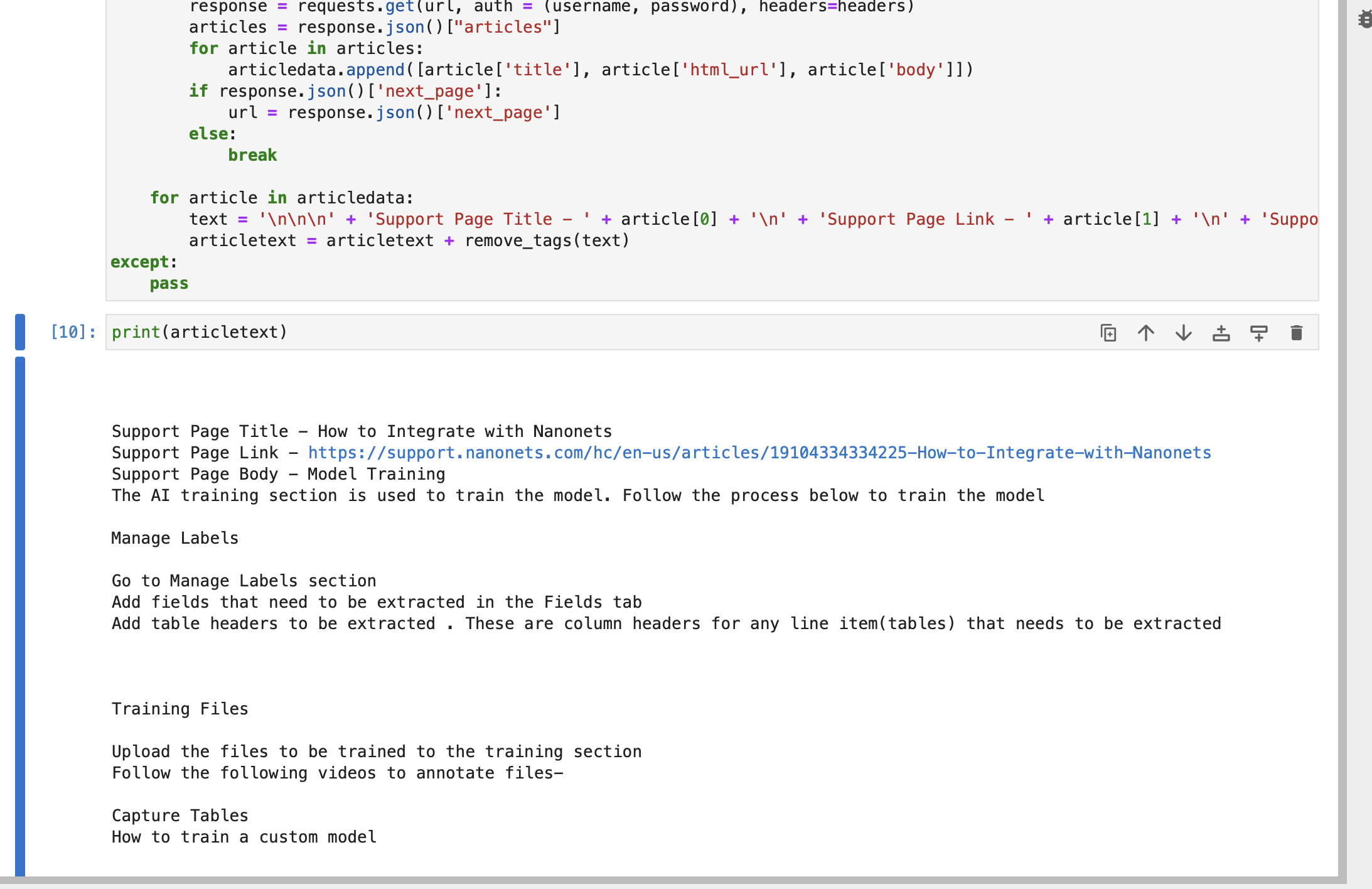
try: articledata = [] url = f"https://{subdomain}.zendesk.com/api/v2/help_center/en-us/articles.json" headers = {"Content-Type": "application/json"} while True: response = requests.get(url, auth=(username, password), headers=headers) articles = response.json()["articles"] for article in articles: articledata.append([article["title"], article["html_url"], article["body"]]) if response.json()["next_page"]: url = response.json()["next_page"] else: break for article in articledata: text = ( "nnn" + "Support Page Title - " + article[0] + "n" + "Support Page Link - " + article[1] + "n" + "Support Page Body - " + article[2] ) articletext = articletext + remove_tags(text)
except: passDe snaar artikeltekst bevat de titel, link en hoofdtekst van elk artikelgedeelte van uw Zendesk-ondersteuningspagina's.
optioneel : u kunt uw klantendatabase of een andere relevante database verbinden en deze vervolgens gebruiken tijdens het maken van de indexwinkel.
Combineer de opgehaalde gegevens.
knowledge = tickettext + "nnn" + articletext- Indextickets: Eenmaal gedownload, indexeert u de tickets met behulp van een geschikte indexeringsmethode om snel en efficiënt ophalen te vergemakkelijken.
Om dit te doen, installeren we eerst de afhankelijkheden die nodig zijn voor het maken van het vectorarchief.
pip install langchain openai pypdf faiss-cpuMaak een indexarchief met behulp van de opgehaalde gegevens. Dit zal fungeren als onze kennisbank wanneer we proberen nieuwe tickets via GPT te beantwoorden.
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY" from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from transformers import GPT2TokenizerFast
import os
import pandas as pd
import numpy as np tokenizer = GPT2TokenizerFast.from_pretrained("gpt2") def count_tokens(text: str) -> int: return len(tokenizer.encode(text)) text_splitter = RecursiveCharacterTextSplitter( chunk_size=512, chunk_overlap=24, length_function=count_tokens,
) chunks = text_splitter.create_documents([knowledge]) token_counts = [count_tokens(chunk.page_content) for chunk in chunks]
df = pd.DataFrame({"Token Count": token_counts})
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(chunks, embeddings)
path = "zendesk-index"
db.save_local(path)
Uw index wordt opgeslagen op uw lokale systeem.

- Update de index regelmatig: Werk de index regelmatig bij met nieuwe tickets en wijzigingen aan bestaande tickets, zodat het systeem toegang heeft tot de meest actuele gegevens.
We kunnen het bovenstaande script plannen om elke week te draaien, en onze 'zendesk-index' of een andere gewenste frequentie updaten.
Hoe u het ticket kunt ophalen als er een nieuw ticket binnenkomt
- Controleer op nieuwe tickets: Zet een systeem op om Zendesk voortdurend te controleren op nieuwe tickets.
We zullen een eenvoudige Flask API maken en deze hosten. Starten,
- Maak een nieuwe map met de naam 'Zendesk Answer Bot'.
- Voeg uw FAISS db-map 'zendesk-index' toe aan de map 'Zendesk Answer Bot'.
- Maak een nieuw Python-bestand zendesk.py en kopieer de onderstaande code daarin.
from flask import Flask, request, jsonify app = Flask(__name__) @app.route('/zendesk', methods=['POST'])
def zendesk(): return 'dummy response' if __name__ == '__main__': app.run(port=3001, debug=True)- Voer de Python-code uit.
- Download en configureer ngrok met behulp van de instructies hier. Zorg ervoor dat u het ngrok authtoken in uw terminal configureert zoals aangegeven op de link.
- Open een nieuwe terminalinstantie en voer onderstaande opdracht uit.
ngrok http 3001- We hebben nu onze Flask Service beschikbaar via een extern IP-adres waarmee we overal API-aanroepen naar onze service kunnen doen.
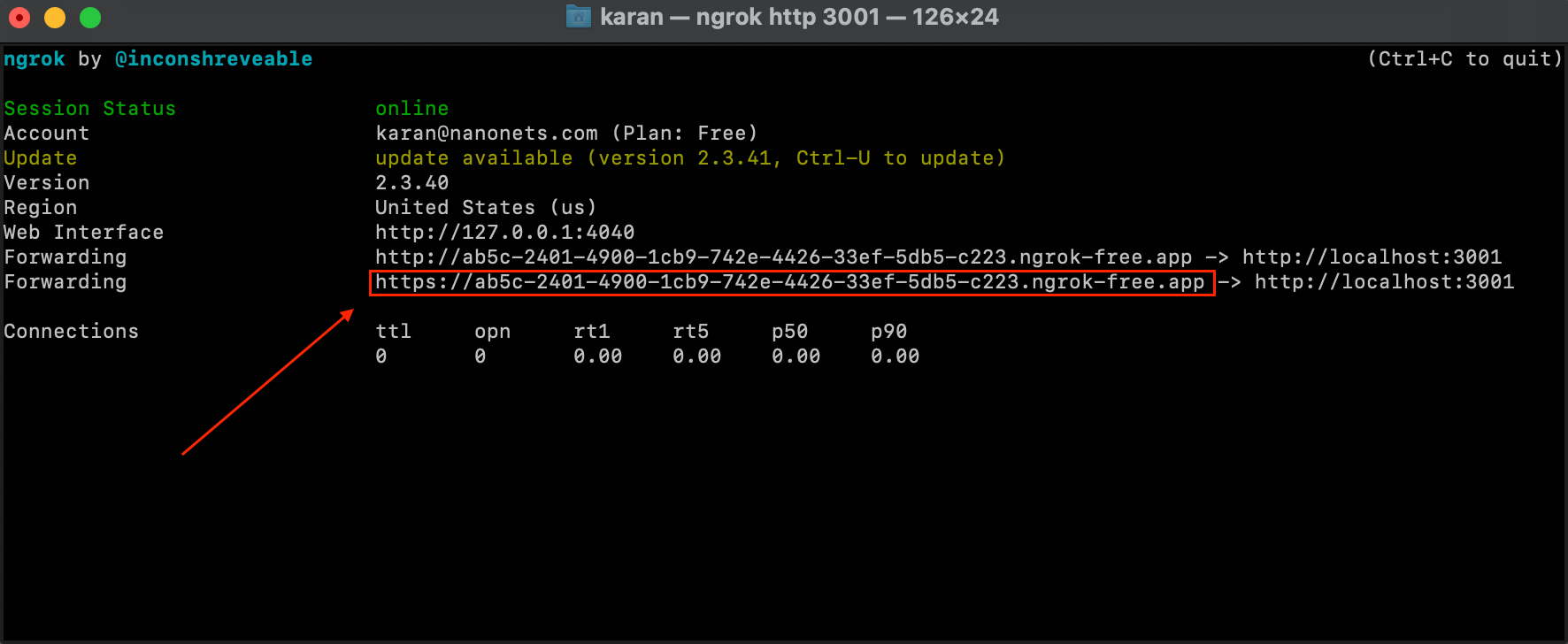
- Vervolgens hebben we een Zendesk Webhook opgezet door de volgende link te bezoeken: https://YOUR_SUBDOMAIN.zendesk.com/admin/apps-integrations/webhooks/webhooks OF door de onderstaande code rechtstreeks uit te voeren in onze originele Jupyter-notebook.
OPMERKING: Het is belangrijk op te merken dat hoewel het gebruik van ngrok goed is voor testdoeleinden, het sterk wordt aanbevolen om de Flask API-service naar een serverinstantie te verplaatsen. In dat geval wordt het statische IP-adres van de server het Zendesk Webhook-eindpunt en moet u het eindpunt in uw Zendesk Webhook zo configureren dat het naar dit adres verwijst – https://YOUR_SERVER_STATIC_IP:3001/zendesk
zendesk_workflow_endpoint = "HTTPS_NGROK_FORWARDING_ADDRESS" url = "https://" + subdomain + ".zendesk.com/api/v2/webhooks"
payload = { "webhook": { "endpoint": zendesk_workflow_endpoint, "http_method": "POST", "name": "Nanonets Workflows Webhook v1", "status": "active", "request_format": "json", "subscriptions": ["conditional_ticket_events"], }
}
headers = {"Content-Type": "application/json"} auth = (username, password) response = requests.post(url, json=payload, headers=headers, auth=auth)
webhook = response.json() webhookid = webhook["webhook"]["id"]
- We hebben nu een Zendesk Trigger ingesteld, die de bovenstaande webhook activeert die we zojuist hebben gemaakt, zodat deze wordt uitgevoerd wanneer er een nieuw ticket verschijnt. We kunnen de Zendesk-trigger instellen door de volgende link te bezoeken: https://YOUR_SUBDOMAIN.zendesk.com/admin/objects-rules/rules/triggers OF door de onderstaande code rechtstreeks uit te voeren in ons originele Jupyter-notebook.
url = "https://" + subdomain + ".zendesk.com/api/v2/triggers.json" trigger_payload = { "trigger": { "title": "Nanonets Workflows Trigger v1", "active": True, "conditions": {"all": [{"field": "update_type", "value": "Create"}]}, "actions": [ { "field": "notification_webhook", "value": [ webhookid, json.dumps( { "ticket_id": "{{ticket.id}}", "org_id": "{{ticket.url}}", "subject": "{{ticket.title}}", "body": "{{ticket.description}}", } ), ], } ], }
} response = requests.post(url, auth=(username, password), json=trigger_payload)
trigger = response.json()
- Relevante informatie ophalen: Wanneer er een nieuw ticket binnenkomt, kunt u de geïndexeerde kennisbank gebruiken om relevante informatie en eerdere tickets op te halen die kunnen helpen bij het genereren van een reactie.
Nadat de trigger en webhook zijn ingesteld, zorgt Zendesk ervoor dat onze huidige Flask-service een API-aanroep krijgt op de /zendesk-route met de ticket-ID, het onderwerp en de hoofdtekst wanneer er een nieuw ticket binnenkomt.
We moeten nu onze Flask Service configureren
A. genereer een antwoord met behulp van onze vectorwinkel 'zendesk-index'.
B. update het ticket met het gegenereerde antwoord.
We vervangen onze huidige flask-servicecode in zendesk.py door de onderstaande code:
from flask import Flask, request, jsonify
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from transformers import GPT2TokenizerFast
import os
import pandas as pd
import numpy as np app = Flask(__name__) @app.route('/zendesk', methods=['POST'])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson['body'] zendb = FAISS.load_local('zendesk-index', zenembeddings) docs = zendb.similarity_search(query) if __name__ == '__main__': app.run(port=3001, debug=True)Zoals u kunt zien, hebben we een zoektocht naar gelijkenissen uitgevoerd in onze vectorindex en de meest relevante tickets en artikelen opgehaald om een reactie te genereren.
Een reactie genereren en posten op Zendesk
- Reactie genereren: Gebruik de LLM om een samenhangend en accuraat antwoord te genereren op basis van de opgehaalde informatie en de geanalyseerde context.
Laten we nu doorgaan met het instellen van ons API-eindpunt. We passen de code verder aan, zoals hieronder weergegeven, om een reactie te genereren op basis van de relevante opgehaalde informatie.
@app.route("/zendesk", methods=["POST"])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson["body"] zendb = FAISS.load_local("zendesk-index", zenembeddings) docs = zendb.similarity_search(query) zenchain = load_qa_chain(OpenAI(temperature=0.7), chain_type="stuff") answer = zenchain.run(input_documents=docs, question=query)
De beantwoorden variabele bevat het gegenereerde antwoord.
- Beoordelingsreactie: Laat eventueel een menselijke agent het gegenereerde antwoord beoordelen op nauwkeurigheid en geschiktheid voordat het wordt geplaatst.
De manier waarop we dit garanderen is door het door GPT gegenereerde antwoord NIET rechtstreeks als Zendesk-antwoord te plaatsen. In plaats daarvan zullen we een functie maken om nieuwe tickets bij te werken met een interne notitie met daarin het door GPT gegenereerde antwoord.
Voeg de volgende functie toe aan de zendesk.py-kolfservice –
def update_ticket_with_internal_note( subdomain, ticket_id, username, password, comment_body
): url = f"https://{subdomain}.zendesk.com/api/v2/tickets/{ticket_id}.json" email = username headers = {"Content-Type": "application/json"} comment_body = "Suggested Response - " + comment_body data = {"ticket": {"comment": {"body": comment_body, "public": False}}} response = requests.put(url, json=data, headers=headers, auth=(email, password))
- Posten op Zendesk: Gebruik de Zendesk API om het gegenereerde antwoord op het bijbehorende ticket te plaatsen, zodat u verzekerd bent van tijdige communicatie met de klant.
Laten we nu de functie voor het maken van interne notities opnemen in ons API-eindpunt.
@app.route("/zendesk", methods=["POST"])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson["body"] zendb = FAISS.load_local("zendesk-index", zenembeddings) docs = zendb.similarity_search(query) zenchain = load_qa_chain(OpenAI(temperature=0.7), chain_type="stuff") answer = zenchain.run(input_documents=docs, question=query) update_ticket_with_internal_note(subdomain, ticket, username, password, answer) return answer
Hiermee is onze workflow voltooid!
Laten we de workflow die we hebben opgezet herzien –
- Onze Zendesk Trigger start de workflow wanneer er een nieuw Zendesk-ticket verschijnt.
- De trigger stuurt de gegevens van het nieuwe ticket naar onze webhook.
- Onze Webhook stuurt een verzoek naar onze Flask Service.
- Onze Flask Service doorzoekt de vectoropslag die is gemaakt met eerdere Zendesk-gegevens om relevante eerdere tickets en artikelen op te halen om het nieuwe ticket te beantwoorden.
- De relevante tickets en artikelen uit het verleden worden samen met de gegevens van het nieuwe ticket doorgegeven aan GPT om een reactie te genereren.
- Het nieuwe ticket wordt bijgewerkt met een interne notitie met het door GPT gegenereerde antwoord.
We kunnen dit handmatig testen –
- We maken handmatig een ticket aan op Zendesk om de flow te testen.
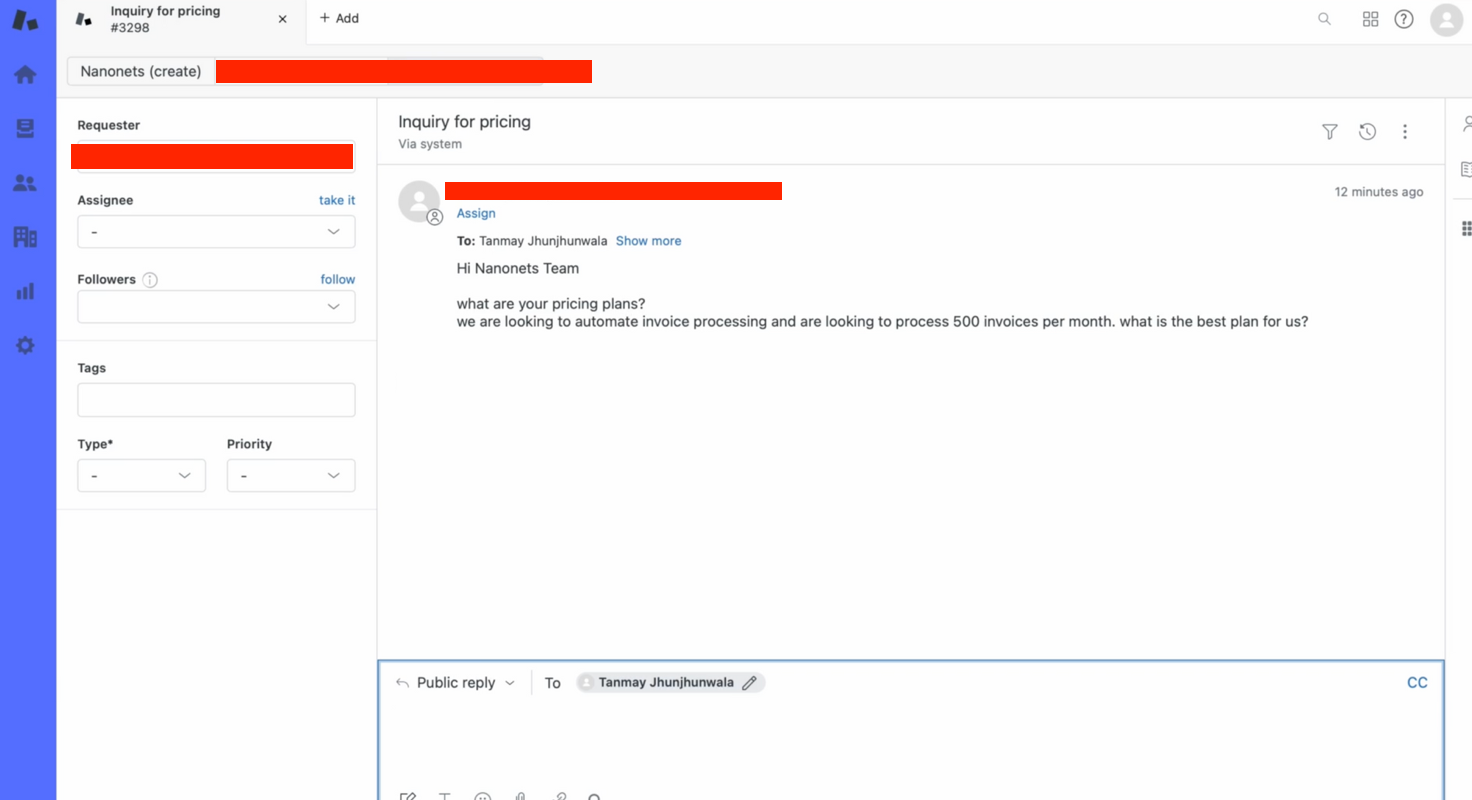
- Binnen enkele seconden geeft onze bot een relevant antwoord op de ticketvraag!

Hoe u deze hele workflow met Nanonets kunt uitvoeren
Nanonets biedt een krachtig platform om RAG-gebaseerde workflows naadloos te implementeren en te beheren. Hier ziet u hoe u Nanonetten kunt gebruiken voor deze workflow:
- Integreren met Zendesk: Verbind Nanonets met Zendesk om tickets efficiënt te monitoren en op te halen.
- Modellen bouwen en trainen: Gebruik nanonetten om LLM's te bouwen en te trainen om nauwkeurige en coherente antwoorden te genereren op basis van de kennisbasis en de geanalyseerde context.
- Automatiseer reacties: Stel automatiseringsregels in Nanonets in om gegenereerde antwoorden automatisch naar Zendesk te posten of ter beoordeling door te sturen naar menselijke agenten.
- Bewaken en optimaliseren: Bewaak voortdurend de prestaties van de workflow en optimaliseer de modellen en regels om de nauwkeurigheid en efficiëntie te verbeteren.
Door LLM's te integreren met op RAG gebaseerde workflows in GenAI en gebruik te maken van de mogelijkheden van Nanonets kunnen bedrijven hun klantenondersteuningsactiviteiten aanzienlijk verbeteren en snelle en nauwkeurige antwoorden bieden op vragen van klanten op Zendesk.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://nanonets.com/blog/build-your-own-zendesk-answer-bot-with-llms/

