Deel 1 van deze tweedelige serie wordt beschreven hoe je een pseudonimiseringsservice kunt bouwen die gegevensattributen in platte tekst omzet in een pseudoniem of omgekeerd. Een gecentraliseerde pseudonimiseringsdienst biedt een unieke en universeel erkende architectuur voor het genereren van pseudoniemen. Bijgevolg kan een organisatie een standaardproces realiseren om gevoelige gegevens op alle platforms te verwerken. Bovendien neemt dit alle complexiteit en expertise weg die nodig is om de verschillende compliance-eisen van ontwikkelingsteams en analytische gebruikers te begrijpen en te implementeren, waardoor ze zich kunnen concentreren op hun bedrijfsresultaten.
Het volgen van een ontkoppelde servicegerichte aanpak betekent dat u als organisatie onbevooroordeeld bent ten aanzien van het gebruik van specifieke technologieën om uw bedrijfsproblemen op te lossen. Ongeacht welke technologie de voorkeur heeft van individuele teams, ze kunnen de pseudonimiseringsdienst bellen om gevoelige gegevens te pseudonimiseren.
In dit bericht concentreren we ons op algemene consumptiepatronen voor extraheren, transformeren en laden (ETL) die gebruik kunnen maken van de pseudonimiseringsservice. We bespreken hoe u de pseudonimiseringsservice in uw ETL-taken kunt gebruiken Amazon EMR (met behulp van Amazon EMR op EC2) voor streaming- en batchgebruiksscenario's. Daarnaast vindt u een Amazone Athene en AWS lijm gebaseerd consumptiepatroon in de GitHub repo van de oplossing.
Overzicht oplossingen
In het volgende diagram wordt de architectuur van de oplossing beschreven.

Het account aan de rechterkant host de pseudonimiseringsservice, die u kunt implementeren met behulp van de instructies in deel 1 van deze serie.
Het account aan de linkerkant is het account dat je hebt ingesteld als onderdeel van dit bericht en vertegenwoordigt het ETL-platform op basis van Amazon EMR met behulp van de pseudonimiseringsservice.
U kunt de pseudonimiseringsservice en het ETL-platform op hetzelfde account inzetten.
Met Amazon EMR kun je snel en kosteneffectief big data-frameworks zoals Apache Spark creëren, beheren en schalen.
In deze oplossing laten we zien hoe u de pseudonimiseringsservice kunt gebruiken Amazon EMR Met Apache Spark voor batch- en streaming-gebruiksscenario's. De batchtoepassing leest gegevens uit een Amazon eenvoudige opslagservice (Amazon S3) bucket, en de streaming-applicatie gebruikt records van Amazon Kinesis-gegevensstromen.
PySpark-code die wordt gebruikt in batch- en streamingtaken
Beide applicaties gebruiken een gemeenschappelijke nutsfunctie die HTTP POST-aanroepen doet tegen de API Gateway die aan de pseudonimisering is gekoppeld AWS Lambda functie. De REST API-aanroepen worden per Spark-partitie gedaan met behulp van de Spark RDD kaartPartities functie. De hoofdtekst van het POST-verzoek bevat de lijst met unieke waarden voor een bepaalde invoerkolom. Het POST-verzoekantwoord bevat de overeenkomstige gepseudonimiseerde waarden. De code verwisselt de gevoelige waarden met de gepseudonimiseerde waarden voor een bepaalde dataset. Het resultaat wordt opgeslagen op Amazon S3 en de AWS lijm Gegevenscatalogus, met behulp van Apache Iceberg tafel formaat.
Iceberg is een open tafelformaat dat ACID-transacties, schema-evolutie en tijdreisquery's ondersteunt. U kunt deze functies gebruiken om de recht om te worden vergeten (of gegevensverwijdering) oplossingen met behulp van SQL-instructies of programmeerinterfaces. Iceberg wordt ondersteund door Amazon EMR vanaf versie 6.5.0, AWS Glue en Athena. Batch- en streamingpatronen gebruiken Iceberg als doelformaat. Voor een overzicht van hoe u een ACID-compatibel datameer kunt bouwen met behulp van Iceberg, raadpleegt u Bouw een krachtig, ACID-compatibel, evoluerend datameer met Apache Iceberg op Amazon EMR.
Voorwaarden
Je moet de volgende voorwaarden hebben:
- An AWS-account.
- An AWS Identiteits- en toegangsbeheer (IAM)-principal met bevoegdheden om de AWS CloudFormatie stapel en gerelateerde bronnen.
- De AWS-opdrachtregelinterface (AWS CLI) geïnstalleerd op de ontwikkelings- of implementatiemachine die u gaat gebruiken om de meegeleverde scripts uit te voeren.
- Een S3-bucket in hetzelfde account en dezelfde AWS-regio waar de oplossing moet worden geïmplementeerd.
- Python3 geïnstalleerd op de lokale machine waarop de opdrachten worden uitgevoerd.
- PyYAML geïnstalleerd met behulp van pit.
- Een bash-terminal om bash-scripts uit te voeren die CloudFormation-stacks implementeren.
- Een extra S3-bucket met de invoergegevensset in Parquet-bestanden (alleen voor batchtoepassingen). Kopieer de voorbeeldgegevensset naar de S3-bak.
- Een kopie van de nieuwste coderepository op de lokale machine met behulp van
git cloneof de downloadoptie.
Open een nieuwe bash-terminal en navigeer naar de hoofdmap van de gekloonde repository.
De broncode voor de voorgestelde patronen is te vinden in de gekloonde repository. Het gebruikt de volgende parameters:
- ARTEFACT_S3_BUCKET – De S3-bucket waar de infrastructuurcode wordt opgeslagen. De bucket moet worden gemaakt in hetzelfde account en dezelfde regio waar de oplossing zich bevindt.
- AWS_REGION – De regio waar de oplossing zal worden ingezet.
- AWS_PROFIEL – Het benoemde profiel dat wordt toegepast op de AWS CLI-opdracht. Dit moet inloggegevens bevatten voor een IAM-principal met bevoegdheden om de CloudFormation-stack met gerelateerde bronnen te implementeren.
- SUBNET_ID – De subnet-ID waar het EMR-cluster wordt opgestart. Het subnet bestaat al en voor demonstratiedoeleinden gebruiken we de standaard subnet-ID van de standaard VPC.
- EP_URL – De eindpunt-URL van de pseudonimiseringsservice. Haal dit op uit de oplossing die is geïmplementeerd als Deel 1 van deze serie.
- API_GEHEIM - Een Amazon API-gateway sleutel waarin wordt opgeslagen AWS-geheimenmanager. De API-sleutel wordt gegenereerd op basis van de implementatie die wordt weergegeven in Deel 1 van deze serie.
- S3_INPUT_PATH – De S3-URI die verwijst naar de map met de invoergegevensset als Parquet-bestanden.
- KINESIS_DATA_STREAM_NAME - De naam van de Kinesis-gegevensstroom die is geïmplementeerd met de CloudFormation-stack.
- SERIEGROOTTE - Het aantal records dat per batch naar de gegevensstroom moet worden gepusht.
- THREADS_NUM - Het aantal parallelle threads dat op de lokale machine wordt gebruikt om gegevens naar de gegevensstroom te uploaden. Meer threads komen overeen met een hoger berichtenvolume.
- EMR_CLUSTER_ID – De EMR-cluster-ID waar de code wordt uitgevoerd (het EMR-cluster is gemaakt door de CloudFormation-stack).
- STACK_NAME – De naam van de CloudFormation-stack, die is toegewezen in het implementatiescript.
Stappen voor batchimplementatie
Zoals beschreven in de vereisten, uploadt u, voordat u de oplossing implementeert, de Parquet-bestanden van de dataset testen naar Amazon S3. Geef vervolgens als parameter het S3-pad op van de map die de bestanden bevat <S3_INPUT_PATH>.
We creëren de oplossingsbronnen via AWS CloudFormation. U kunt de oplossing implementeren door het bestand implement_1.sh script, dat zich in het deployment_scripts map.
Nadat aan de implementatievereisten is voldaan, voert u de volgende opdracht in om de oplossing te implementeren:
sh ./deployment_scripts/deploy_1.sh
-a <ARTEFACT_S3_BUCKET>
-r <AWS_REGION>
-p <AWS_PROFILE>
-s <SUBNET_ID>
-e <EP_URL>
-x <API_SECRET>
-i <S3_INPUT_PATH>De uitvoer zou eruit moeten zien als de volgende schermafbeelding.

De vereiste parameters voor de opruimopdracht worden afgedrukt aan het einde van de uitvoering van de deploy_1.sh script. Zorg ervoor dat u deze waarden noteert.
Test de batchoplossing
In de CloudFormation-sjabloon geïmplementeerd met behulp van de deploy_1.sh script, de EMR-stap met de Spark-batchtoepassing wordt toegevoegd aan het einde van de EMR-clusterconfiguratie.
Om de resultaten te verifiëren, controleert u de S3-bucket die in de CloudFormation-stackuitvoer met de variabele wordt geïdentificeerd SparkOutputLocation.

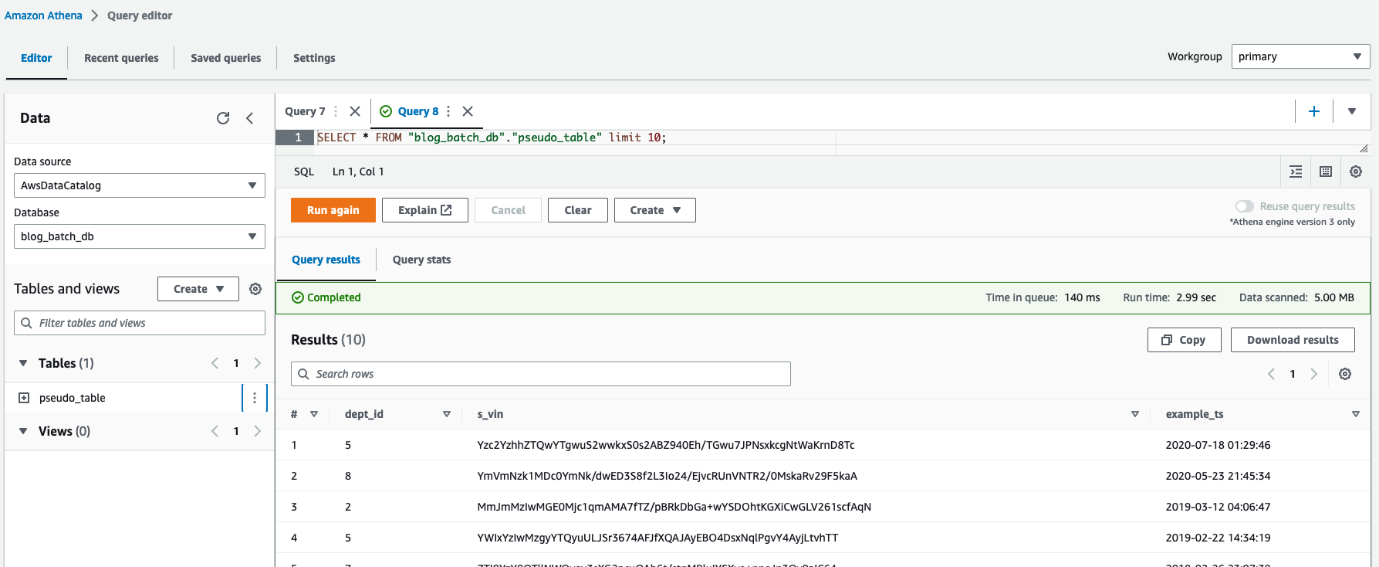
Je kunt Athena ook gebruiken vraag de tabel op pseudo_table in de database blog_batch_db.
Batchbronnen opschonen
Om de hulpbronnen die als onderdeel van deze oefening zijn gecreëerd te vernietigen,
navigeer in een bash-terminal naar de hoofdmap van de gekloonde repository. Voer de opruimopdracht in die wordt weergegeven als de uitvoer van de eerder uitgevoerde opdracht implement_1.sh script:
sh ./deployment_scripts/cleanup_1.sh
-a <ARTEFACT_S3_BUCKET>
-s <STACK_NAME>
-r <AWS_REGION>
-e <EMR_CLUSTER_ID>De uitvoer zou eruit moeten zien als de volgende schermafbeelding.

Implementatiestappen voor streaming
We creëren de oplossingsbronnen via AWS CloudFormation. U kunt de oplossing implementeren door het bestand implement_2.sh script, dat zich in het deployment_scripts map. De CloudFormation-stacksjabloon voor dit patroon is beschikbaar in de GitHub repo.
Nadat aan de implementatievereisten is voldaan, voert u de volgende opdracht in om de oplossing te implementeren:
sh deployment_scripts/deploy_2.sh
-a <ARTEFACT_S3_BUCKET>
-r <AWS_REGION>
-p <AWS_PROFILE>
-s <SUBNET_ID>
-e <EP_URL>
-x <API_SECRET>De uitvoer zou eruit moeten zien als de volgende schermafbeelding.
De vereiste parameters voor de opruimopdracht worden afgedrukt aan het einde van de uitvoer van het implement_2.sh script. Zorg ervoor dat u deze waarden opslaat, zodat u ze later kunt gebruiken.
Test de streamingoplossing
In de CloudFormation-sjabloon geïmplementeerd met behulp van de deploy_2.sh script, de EMR-stap met de Spark-streaming-applicatie wordt toegevoegd aan het einde van de EMR-clusterconfiguratie. Om de end-to-end pijplijn te testen, moet u records naar de geïmplementeerde Kinesis-gegevensstroom pushen. Met de volgende commando's in een bash-terminal kun je een Kinesis-producent activeren die continu records in de stream plaatst, totdat het proces handmatig wordt gestopt. U kunt het berichtenvolume van de producent regelen door het BATCH_SIZE en THREADS_NUM variabelen.


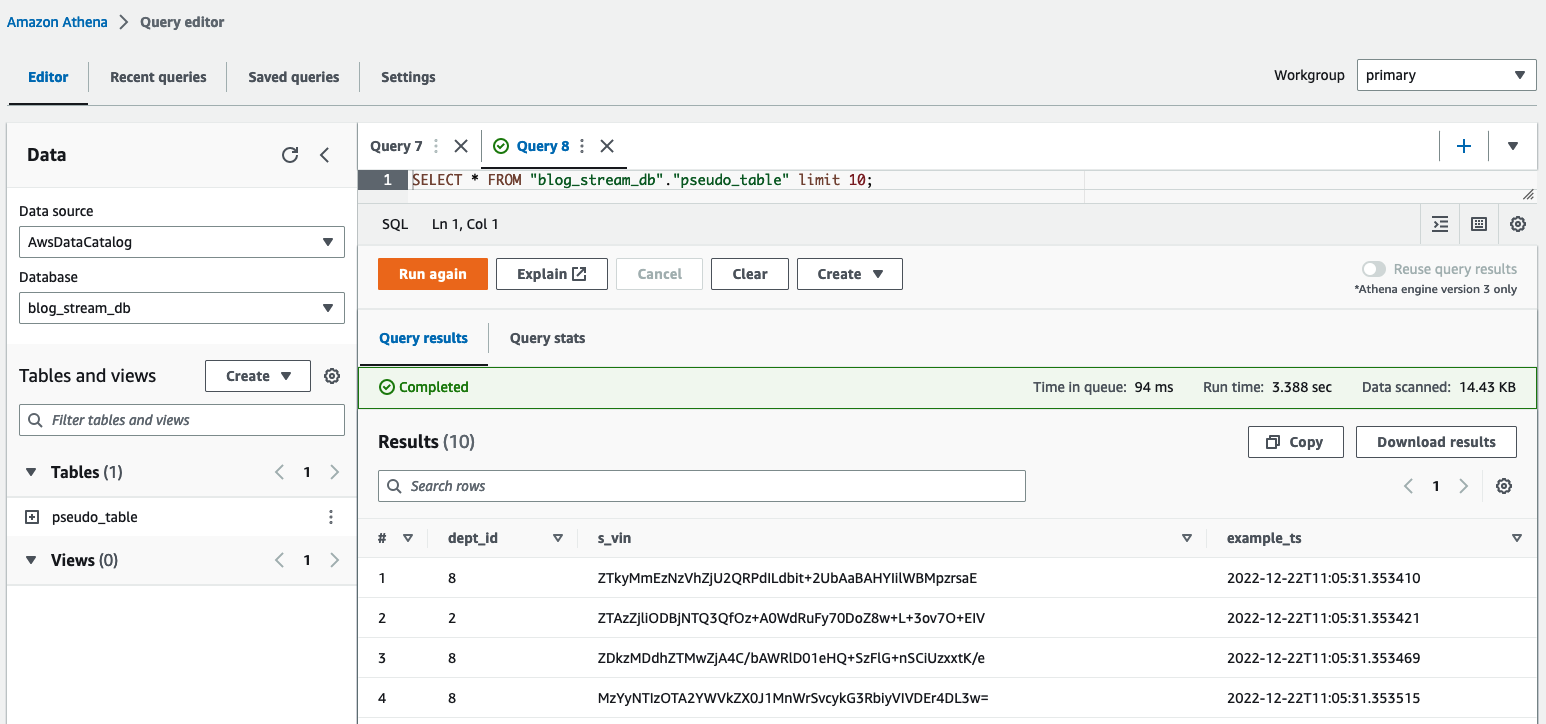
Controleer in de Athena-queryeditor de resultaten door een query uit te voeren op de table pseudo_table in de database blog_stream_db.
Streamingbronnen opruimen
Voer de volgende stappen uit om de hulpbronnen die als onderdeel van deze oefening zijn gemaakt te vernietigen:
- Stop de Python Kinesis-producent die in de vorige sectie in een bash-terminal werd gelanceerd.
- Voer het volgende commando in:
sh ./deployment_scripts/cleanup_2.sh
-a <ARTEFACT_S3_BUCKET>
-s <STACK_NAME>
-r <AWS_REGION>
-e <EMR_CLUSTER_ID>De uitvoer zou eruit moeten zien als de volgende schermafbeelding.

Prestatiedetails
Use cases kunnen verschillen in vereisten met betrekking tot gegevensgrootte, rekencapaciteit en kosten. We hebben een aantal benchmarks en factoren gegeven die de prestaties kunnen beïnvloeden; Wij adviseren u echter ten zeerste om de oplossing in lagere omgevingen te valideren om te zien of deze aan uw specifieke vereisten voldoet.
U kunt de prestaties van de voorgestelde oplossing (die tot doel heeft een dataset te pseudonimiseren met behulp van Amazon EMR) beïnvloeden door het maximale aantal parallelle oproepen naar de pseudonimiseringsservice en de payloadgrootte voor elke oproep. In termen van parallelle oproepen zijn factoren waarmee rekening moet worden gehouden de volgende GetSecretValue-oproeplimiet van Secrets Manager (10.000 per seconde, harde limiet) en het Lambda-standaardgelijktijdigheidsparallellisme (standaard 1,000; kan worden verhoogd door quotumverzoeken). U kunt de maximale parallelliteit bepalen door het aantal uitvoerders, het aantal partities waaruit de gegevensset bestaat, en de clusterconfiguratie (aantal en type knooppunten) aan te passen. Wat de omvang van de payload voor elk gesprek betreft, zijn de factoren waarmee rekening moet worden gehouden de Maximale payloadgrootte van API Gateway (6 MB) en de maximale looptijd van de Lambda-functie (15 minuten). U kunt de grootte van de payload en de runtime van de Lambda-functie bepalen door de waarde van de batchgrootte aan te passen. Dit is een parameter van het PySpark-script die het aantal items bepaalt dat per API-aanroep moet worden gepseudonimiseerd. Om de invloed van al deze factoren vast te leggen en de prestaties van de consumptiepatronen met behulp van Amazon EMR te beoordelen, hebben we de volgende scenario’s ontworpen en gemonitord.
Prestaties van batchverbruikspatronen
Om de prestaties voor het batchconsumptiepatroon te beoordelen, hebben we de pseudonimiseringstoepassing uitgevoerd met drie invoergegevenssets bestaande uit 1, 10 en 100 Parquet-bestanden van elk 97.7 MB. We hebben de invoerbestanden gegenereerd met behulp van de dataset_generator.py scripts.
De clustercapaciteitsknooppunten waren 1 primair (m5.4xlarge) en 15 core (m5d.8xlarge). Deze clusterconfiguratie bleef voor alle drie de scenario's hetzelfde en zorgde ervoor dat de Spark-applicatie maximaal 100 uitvoerders kon gebruiken. De batch_size, wat ook hetzelfde was voor de drie scenario's, was ingesteld op 900 VIN's per API-aanroep en de maximale VIN-grootte was 5 bytes.
De volgende tabel bevat de informatie van de drie scenario's.
| Uitvoerings-ID | Repartition | Gegevenssetgrootte | Aantal executeurs | Kernen per uitvoerder | Uitvoerder geheugen | Runtime |
| A | 800 | 9.53 GB | 100 | 4 | 4 GB | 11 minuten, 10 seconden |
| B | 80 | 0.95 GB | 10 | 4 | 4 GB | 8 minuten, 36 seconden |
| C | 8 | 0.09 GB | 1 | 4 | 4 GB | 7 minuten, 56 seconden |
Zoals we kunnen zien, stelt het correct parallelliseren van de oproepen naar onze pseudonimiseringsservice ons in staat de algehele looptijd te controleren.
In de volgende voorbeelden analyseren we drie belangrijke Lambda-statistieken voor de pseudonimiseringsservice: Invocations, ConcurrentExecutions en Duration.
De volgende grafiek geeft de Invocations metriek, met de statistiek SUM in oranje en RUNNING SUM in blauw.

Door het verschil tussen het begin- en eindpunt van de cumulatieve aanroepingen te berekenen, kunnen we achterhalen hoeveel aanroepingen er tijdens elke run zijn gemaakt.
| ID uitvoeren | Gegevenssetgrootte | Totaal aantal aanroepen |
| A | 9.53 GB | 1.467.000 - 0 = 1.467.000 |
| B | 0.95 GB | 1.467.000 - 1.616.500 = 149.500 |
| C | 0.09 GB | 1.616.500 - 1.631.000 = 14.500 |
Zoals verwacht neemt het aantal aanroepen proportioneel met 10 toe naarmate de gegevensset groter wordt.
De volgende grafiek geeft het totaal weer ConcurrentExecutions metriek, met de statistiek MAX in blauw.
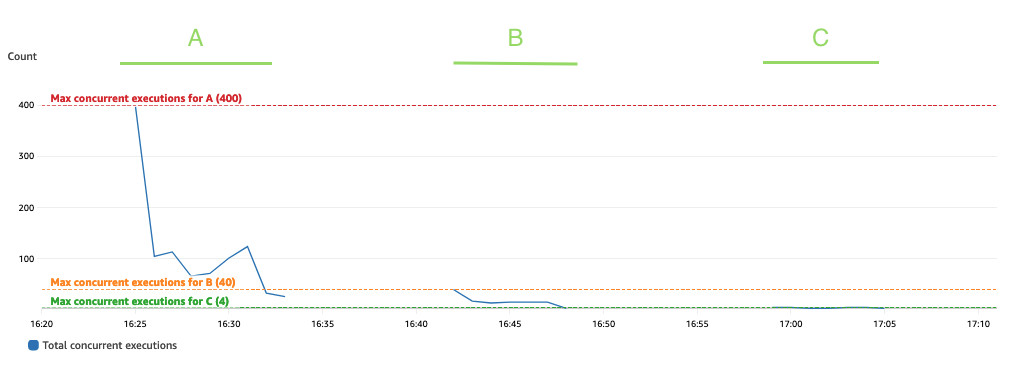
De applicatie is zo ontworpen dat het maximale aantal gelijktijdige uitvoeringen van de Lambda-functie wordt bepaald door het aantal Spark-taken (Spark-gegevenssetpartities) dat parallel kan worden verwerkt. Dit aantal kan worden berekend als MIN (executeurs x executor_cores, Spark-gegevenssetpartities).
In de test verwerkte A 800 partities, met behulp van 100 uitvoerders met elk vier kernen. Hierdoor worden 400 taken parallel verwerkt, zodat de gelijktijdige uitvoeringen van de Lambda-functie niet hoger kunnen zijn dan 400. Dezelfde logica werd toegepast voor uitvoeringen B en C. We kunnen dit zien weerspiegeld in de voorgaande grafiek, waar het aantal gelijktijdige uitvoeringen nooit de grens overschrijdt. 400, 40 en 4 waarden.
Om beperking te voorkomen, moet u ervoor zorgen dat het aantal Spark-taken dat parallel kan worden verwerkt niet boven de gelijktijdigheidslimiet van de Lambda-functie ligt. Als dat het geval is, moet u de gelijktijdigheidslimiet van de Lambda-functie verhogen (als u de prestaties op peil wilt houden) of het aantal partities of het aantal beschikbare uitvoerders verkleinen (wat van invloed is op de prestaties van de applicatie).
De volgende grafiek toont de Lambda Duration metriek, met de statistiek AVG in oranje en MAX in het groen.
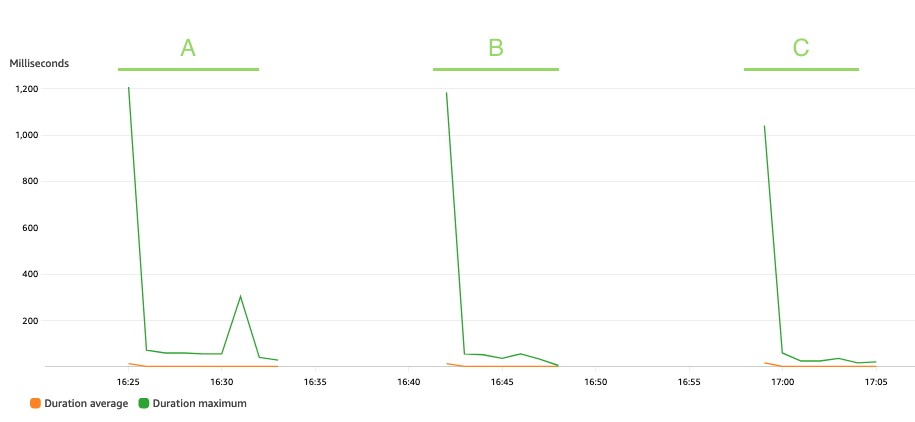
Zoals verwacht heeft de grootte van de dataset geen invloed op de duur van de uitvoering van de pseudonimiseringsfunctie, die, afgezien van enkele initiële aanroepen die te maken krijgen met een koude start, constant blijft op een gemiddelde van 3 milliseconden in de drie scenario's. Dit omdat het maximale aantal records in elke pseudonimiseringsoproep constant is (batch_size waarde).
Lambda wordt gefactureerd op basis van het aantal aanroepen en de tijd die nodig is om uw code uit te voeren (duur). U kunt de gemiddelde duur en aanroepstatistieken gebruiken om de kosten van de pseudonimiseringsservice te schatten.
Prestaties van streaming-consumptiepatronen
Om de prestaties voor het streamingconsumptiepatroon te beoordelen, hebben we de producent.py script, dat een Kinesis-gegevensproducent definieert die records in batches naar de Kinesis-gegevensstroom pusht.
De streaming-applicatie bleef 15 minuten actief en werd geconfigureerd met een batch_interval van 1 minuut, wat het tijdsinterval is waarop streaminggegevens in batches worden verdeeld. De volgende tabel vat de relevante factoren samen.
| Repartition | Clustercapaciteitsknooppunten | Aantal executeurs | Het geheugen van de executeur | Batchvenster | Seriegrootte | VIN-maat |
| 17 |
1 Primair (m5.xgroot), 3 Kern (m5.2xgroot) |
6 | 9 GB | 60 seconden | 900 VIN's/API-oproep. | 5 Bytes/VIN |
De volgende grafieken tonen de Kinesis Data Streams-statistieken PutRecords (in blauw) en GetRecords (in oranje) geaggregeerd met een periode van 1 minuut en met behulp van de statistiek SUM. De eerste grafiek toont de statistiek in bytes, met een piek van 6.8 MB per minuut. De tweede grafiek toont het recordaantal met een piek van 85,000 records per minuut.
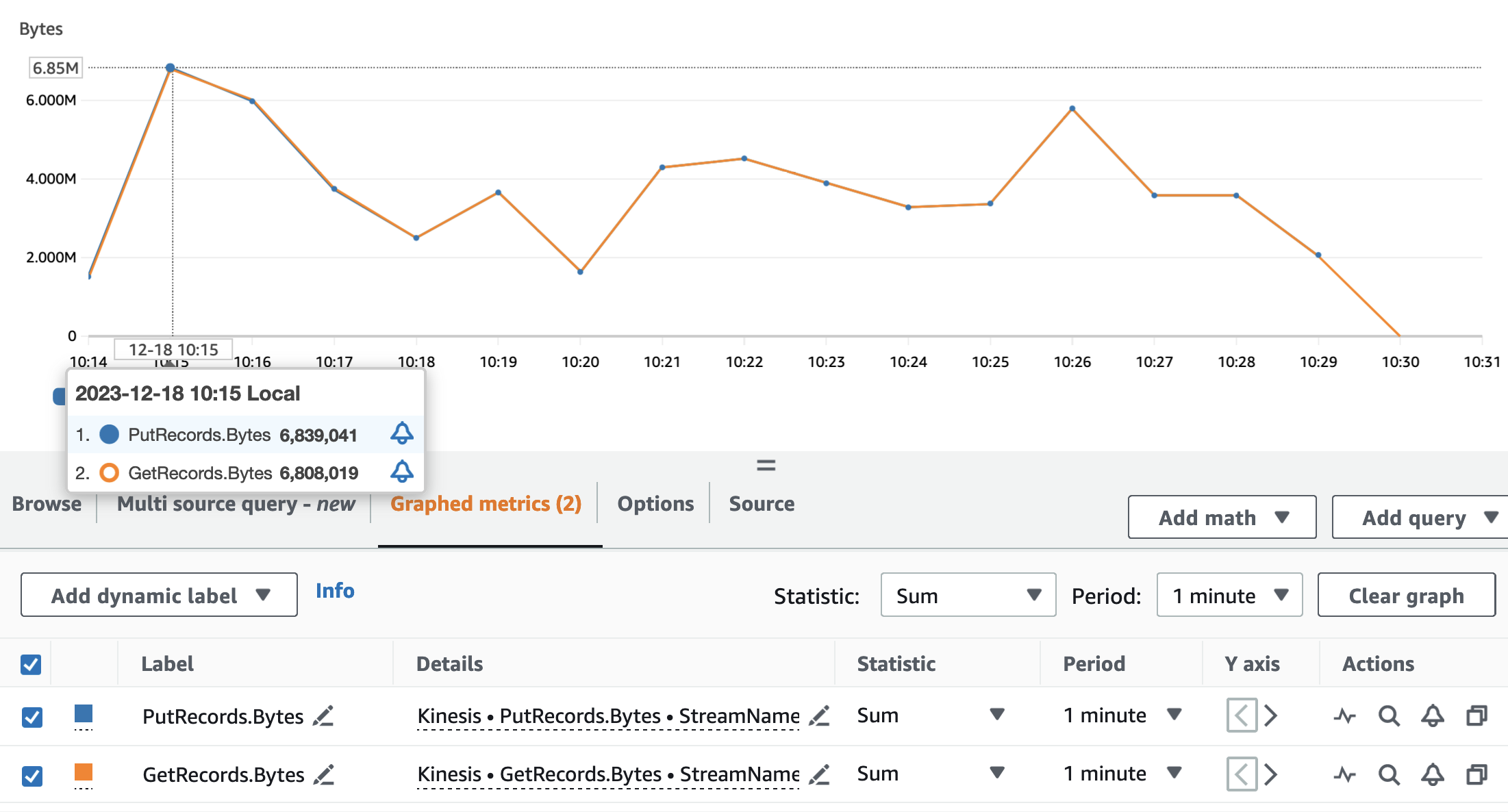

Dat kunnen we zien aan de statistieken GetRecords en PutRecords hebben overlappende waarden voor bijna de gehele uitvoering van de toepassing. Dit betekent dat de streamingapplicatie de belasting van de stream kon bijhouden.
Vervolgens analyseren we de relevante Lambda-statistieken voor de pseudonimiseringsservice: Invocations, ConcurrentExecutions en Duration.
De volgende grafiek geeft de Invocations metriek, met de statistiek SUM (in oranje) en RUNNING SUM in blauw.
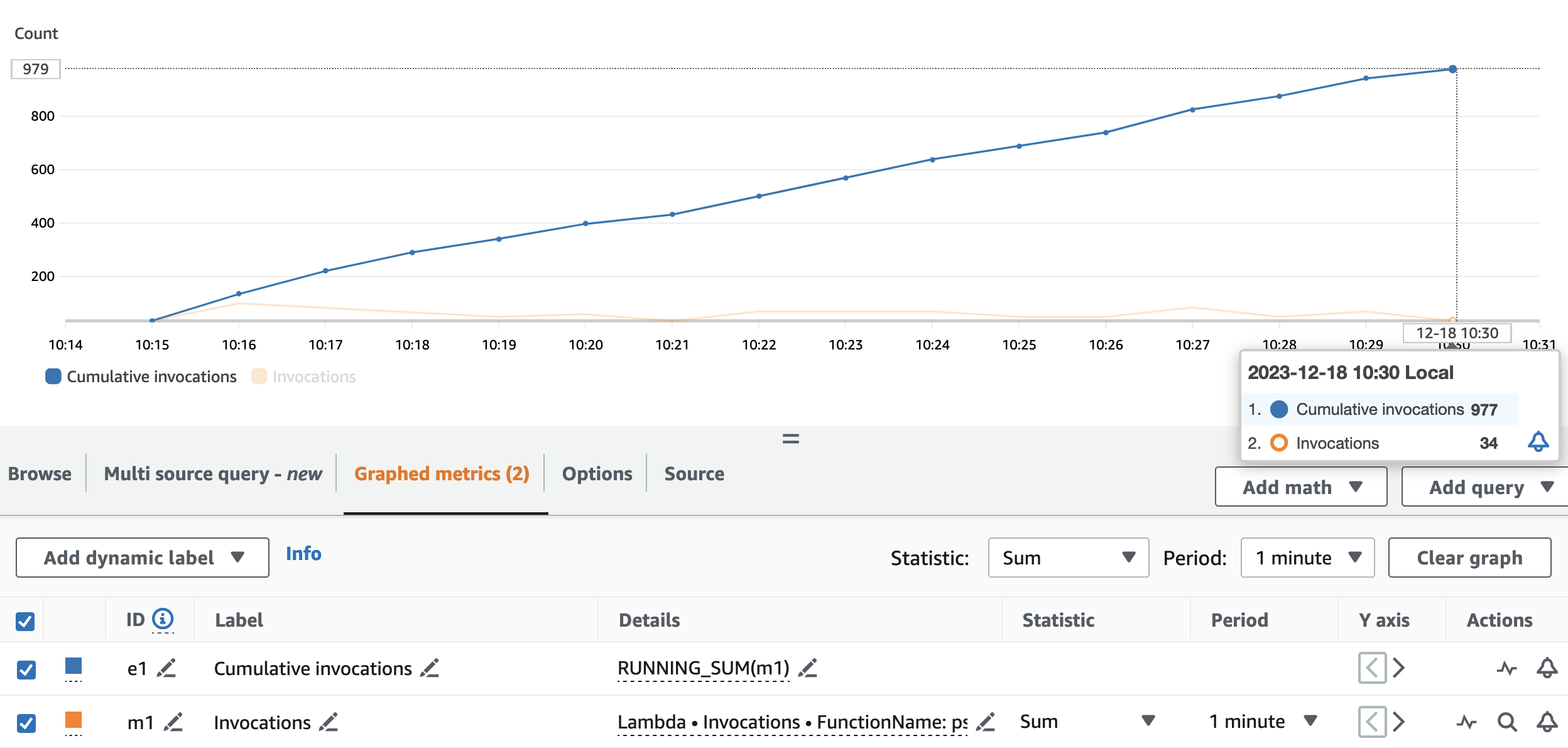
Door het verschil tussen het begin- en eindpunt van de cumulatieve aanroepingen te berekenen, kunnen we achterhalen hoeveel aanroepingen er tijdens de run zijn gemaakt. Concreet riep de streamingapplicatie in 15 minuten 977 keer de pseudonimiserings-API op, wat neerkomt op ongeveer 65 oproepen per minuut.
De volgende grafiek geeft het totaal weer ConcurrentExecutions metriek, met de statistiek MAX in blauw.
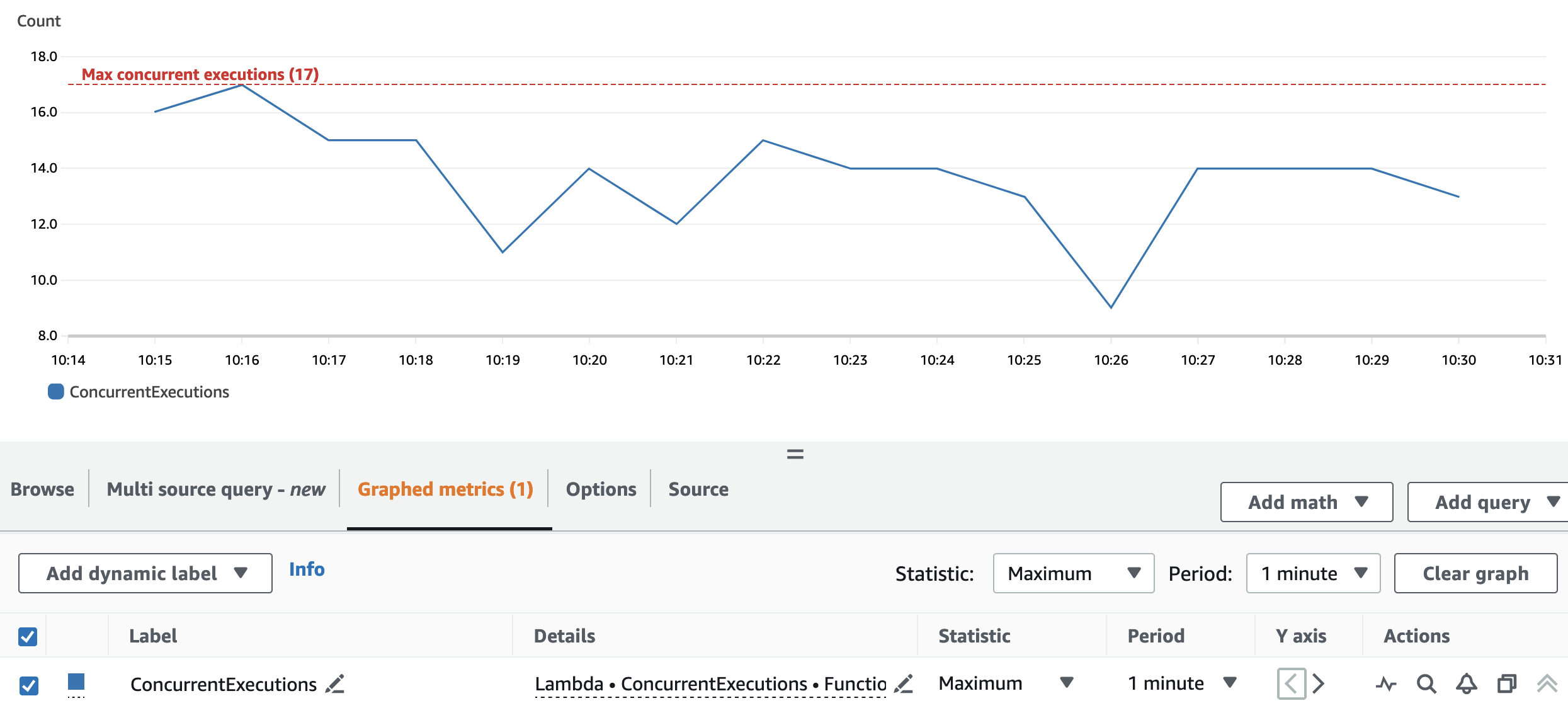
Dankzij de herpartitie en de clusterconfiguratie kan de toepassing alle Spark RDD-partities parallel verwerken. Als gevolg hiervan zijn de gelijktijdige uitvoeringen van de Lambda-functie altijd gelijk aan of lager dan het repartitienummer, dat 17 is.
Om beperking te voorkomen, moet u ervoor zorgen dat het aantal Spark-taken dat parallel kan worden verwerkt niet boven de gelijktijdigheidslimiet van de Lambda-functie ligt. Voor dit aspect gelden dezelfde suggesties als voor het batchgebruik.
De volgende grafiek toont de Lambda Duration metriek, met de statistiek AVG in blauw en MAX in oranje.
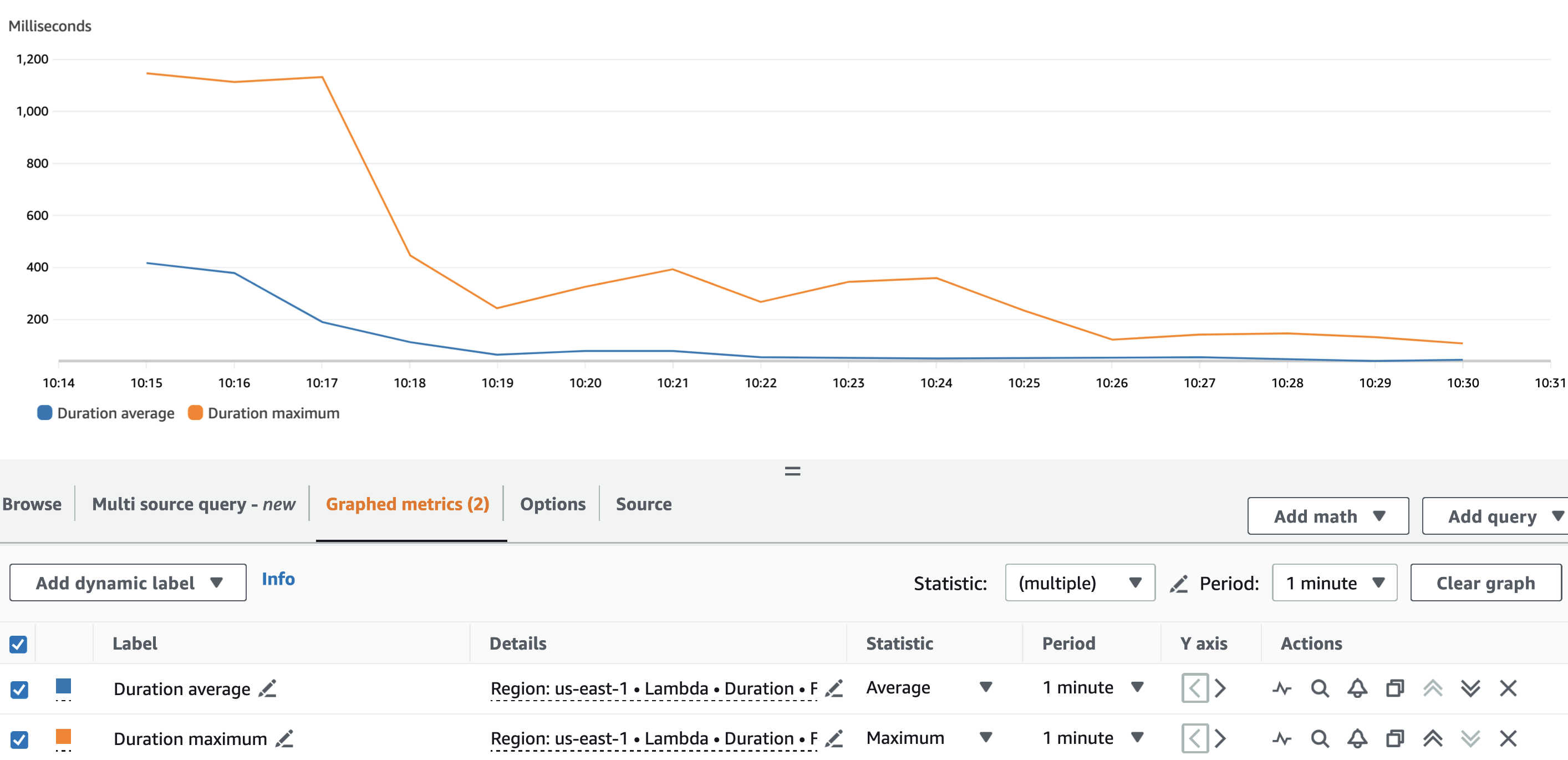
Zoals verwacht was, afgezien van de koude start van de Lambda-functie, de gemiddelde duur van de pseudonimiseringsfunctie gedurende de hele run min of meer constant. Dit omdat de batch_size waarde, die het aantal VIN's definieert dat per oproep moet worden gepseudonimiseerd, werd ingesteld op en bleef constant op 900.
De opnamesnelheid van de Kinesis-datastroom en de consumptiesnelheid van onze streamingapplicatie zijn factoren die van invloed zijn op het aantal API-aanroepen tegen de pseudonimiseringsdienst en dus op de daaraan gerelateerde kosten.
De volgende grafiek toont de Lambda Invocations metriek, met de statistiek SUM in oranje, en de Kinesis Data Streams GetRecords.Records metriek, met de statistiek SUM in blauw. We kunnen zien dat er een correlatie bestaat tussen het aantal records dat per minuut uit de stream wordt opgehaald en het aantal Lambda-functie-aanroepen, waardoor de kosten van de streaming-run worden beïnvloed.

Naast de batch_interval, kunnen we het verbruik van de streaming-applicatie regelen met behulp van Spark-streamingeigenschappen als spark.streaming.receiver.maxRate en spark.streaming.blockInterval. Voor meer details, zie: Spark Streaming + Kinesis-integratie en Spark Streaming-programmeergids.
Conclusie
Navigeren door de regels en voorschriften van de wetgeving inzake gegevensprivacy kan lastig zijn. Pseudonimisering van PII-kenmerken is een van de vele punten waarmee u rekening moet houden bij de verwerking van gevoelige gegevens.
In deze tweedelige serie hebben we onderzocht hoe u een pseudonimiseringsservice kunt bouwen en gebruiken met behulp van verschillende AWS-services met functies die u kunnen helpen bij het bouwen van een robuust dataplatform. In Deel 1, hebben we de basis gelegd door te laten zien hoe je een pseudonimiseringsdienst kunt bouwen. In dit bericht hebben we de verschillende patronen laten zien om de pseudonimiseringsdienst op een kostenefficiënte en performante manier te gebruiken. Bekijk de GitHub opslagplaats voor aanvullende consumptiepatronen.
Over de auteurs
 Edvin Hallvaxhiu is een Senior Global Security Architect bij AWS Professional Services en heeft een passie voor cybersecurity en automatisering. Hij helpt klanten bij het bouwen van veilige en compliant oplossingen in de cloud. Buiten het werk houdt hij van reizen en sporten.
Edvin Hallvaxhiu is een Senior Global Security Architect bij AWS Professional Services en heeft een passie voor cybersecurity en automatisering. Hij helpt klanten bij het bouwen van veilige en compliant oplossingen in de cloud. Buiten het werk houdt hij van reizen en sporten.
 Rahul Shaurya is een Principal Big Data Architect bij AWS Professional Services. Hij helpt en werkt nauw samen met klanten bij het bouwen van dataplatforms en analytische applicaties op AWS. Buiten zijn werk maakt Rahul graag lange wandelingen met zijn hond Barney.
Rahul Shaurya is een Principal Big Data Architect bij AWS Professional Services. Hij helpt en werkt nauw samen met klanten bij het bouwen van dataplatforms en analytische applicaties op AWS. Buiten zijn werk maakt Rahul graag lange wandelingen met zijn hond Barney.
 Andrea Montanari is een Senior Big Data Architect bij AWS Professional Services. Hij ondersteunt klanten en partners actief bij het bouwen van analytische oplossingen op grote schaal op AWS.
Andrea Montanari is een Senior Big Data Architect bij AWS Professional Services. Hij ondersteunt klanten en partners actief bij het bouwen van analytische oplossingen op grote schaal op AWS.
 Maria Guerra is een Big Data Architect bij AWS Professional Services. Maria heeft een achtergrond in data-analyse en werktuigbouwkunde. Ze helpt klanten bij het ontwerpen en ontwikkelen van datagerelateerde workloads in de cloud.
Maria Guerra is een Big Data Architect bij AWS Professional Services. Maria heeft een achtergrond in data-analyse en werktuigbouwkunde. Ze helpt klanten bij het ontwerpen en ontwikkelen van datagerelateerde workloads in de cloud.
 Pushpraj Singh is een Senior Data Architect bij AWS Professional Services. Hij heeft een passie voor data- en DevOps-engineering. Hij helpt klanten bij het bouwen van datagestuurde applicaties op schaal.
Pushpraj Singh is een Senior Data Architect bij AWS Professional Services. Hij heeft een passie voor data- en DevOps-engineering. Hij helpt klanten bij het bouwen van datagestuurde applicaties op schaal.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/build-a-pseudonymization-service-on-aws-to-protect-sensitive-data-part-2/

