Voor het bouwen van elke generatieve AI-toepassing is het verrijken van de grote taalmodellen (LLM's) met nieuwe gegevens absoluut noodzakelijk. Dit is waar de Retrieval Augmented Generation (RAG)-techniek in beeld komt. RAG is een machine learning (ML)-architectuur die externe documenten (zoals Wikipedia) gebruikt om zijn kennis uit te breiden en state-of-the-art resultaten te bereiken voor kennisintensieve taken. . Voor het opnemen van deze externe gegevensbronnen zijn vectordatabases ontwikkeld, die vectorinsluitingen van de gegevensbron kunnen opslaan en zoeken naar overeenkomsten mogelijk maken.
In dit bericht laten we zien hoe u een RAG-opnamepijplijn kunt bouwen, transformeren en laden (ETL) om grote hoeveelheden gegevens op te nemen in een Amazon OpenSearch-service clusteren en gebruiken Amazon Relational Database Service (Amazon RDS) voor PostgreSQL met de pgvector-extensie als vectorgegevensopslag. Elke service implementeert algoritmen voor k-dichtstbijzijnde buur (k-NN) of geschatte naaste buur (ANN) en afstandsmetrieken om de gelijkenis te berekenen. We introduceren de integratie van straal in het RAG-mechanisme voor het ophalen van contextuele documenten. Ray is een open source, Python, gedistribueerde computerbibliotheek voor algemene doeleinden. Het maakt gedistribueerde gegevensverwerking mogelijk om inbedding voor een grote hoeveelheid gegevens te genereren en op te slaan, parallellisatie over meerdere GPU's. We gebruiken een Ray-cluster met deze GPU's om voor elke service parallelle opname en query's uit te voeren.
In dit experiment proberen we de volgende aspecten te analyseren voor OpenSearch Service en de pgvector-extensie op Amazon RDS:
- Als vectoropslag de mogelijkheid om een grote dataset met tientallen miljoenen records voor RAG te schalen en te verwerken
- Mogelijke knelpunten in de ingest-pijplijn voor RAG
- Hoe u optimale prestaties kunt bereiken op het gebied van opname en ophaaltijden van zoekopdrachten voor OpenSearch Service en Amazon RDS
Raadpleeg voor meer informatie over vectorgegevensopslag en hun rol bij het bouwen van generatieve AI-toepassingen De rol van vectordatastores in generatieve AI-toepassingen.
Overzicht van de OpenSearch-service
OpenSearch Service is een beheerde service voor het veilig analyseren, zoeken en indexeren van zakelijke en operationele gegevens. OpenSearch Service ondersteunt gegevens op petabyteschaal met de mogelijkheid om meerdere indexen op tekst- en vectorgegevens te maken. Met een geoptimaliseerde configuratie streeft het naar een hoge herinnering voor de zoekopdrachten. OpenSearch Service ondersteunt zowel ANN als exact k-NN zoeken. OpenSearch Service ondersteunt een selectie algoritmen uit de NMSLIB, FAISS en Luceen bibliotheken om de k-NN-zoekopdracht mogelijk te maken. We hebben de ANN-index voor OpenSearch gemaakt met het Hierarchical Navigable Small World (HNSW)-algoritme, omdat dit wordt beschouwd als een betere zoekmethode voor grote datasets. Voor meer informatie over de keuze van het indexalgoritme, zie Kies het k-NN-algoritme voor uw gebruiksscenario op miljarden schaal met OpenSearch.
Overzicht van Amazon RDS voor PostgreSQL met pgvector
De pgvector-extensie voegt een open source vectorgelijkeniszoekopdracht toe aan PostgreSQL. Door gebruik te maken van de pgvector-extensie kan PostgreSQL overeenkomsten zoeken op vectorinbedding, waardoor bedrijven een snelle en bekwame oplossing krijgen. pgvector biedt twee soorten zoekopdrachten naar vectorgelijkenis: exacte dichtstbijzijnde buur, wat resulteert in een herinnering van 100%, en geschatte dichtstbijzijnde buur (ANN), wat betere prestaties oplevert dan exacte zoekopdracht met een afweging tussen terugroepen. Voor zoekopdrachten via een index kunt u kiezen hoeveel centra u bij de zoekopdracht wilt gebruiken, waarbij meer centra een betere herinnering opleveren met een wisselwerking tussen de prestaties.
Overzicht oplossingen
Het volgende diagram illustreert de oplossingsarchitectuur.

Laten we de belangrijkste componenten in meer detail bekijken.
dataset
We gebruiken OSCAR-gegevens als ons corpus en de SQUAD-gegevensset om voorbeeldvragen te bieden. Deze gegevenssets worden eerst geconverteerd naar Parquet-bestanden. Vervolgens gebruiken we een Ray-cluster om de Parquet-gegevens naar inbedding te converteren. De gemaakte insluitingen worden met pgvector opgenomen in de OpenSearch Service en Amazon RDS.
OSCAR (Open Super-large Crawled Aggregated corpus) is een enorm meertalig corpus dat wordt verkregen door taalclassificatie en filtering van de Gemeenschappelijke crawl corpus met behulp van de onaardig architectuur. Gegevens worden per taal verspreid, zowel in originele als in gededupliceerde vorm. De Oscar Corpus-dataset omvat ongeveer 609 miljoen records en neemt ongeveer 4.5 TB in beslag als onbewerkte JSONL-bestanden. De JSONL-bestanden worden vervolgens geconverteerd naar Parquet-indeling, waardoor de totale grootte wordt geminimaliseerd tot 1.8 TB. We hebben de dataset verder verkleind tot 25 miljoen records om tijd te besparen tijdens de opname.
SQuAD (Stanford Question Answering Dataset) is een dataset voor begrijpend lezen die bestaat uit vragen die door crowdworkers worden gesteld over een reeks Wikipedia-artikelen, waarbij het antwoord op elke vraag een stuk tekst is, of span, uit de overeenkomstige leespassage, anders is de vraag mogelijk niet te beantwoorden. We gebruiken SQUAD, gelicentieerd als CC-BY-SA 4.0, om voorbeeldvragen te geven. Het bevat ongeveer 100,000 vragen, waarvan meer dan 50,000 onbeantwoordbare vragen, geschreven door crowdworkers, die lijken op beantwoordbare vragen.
Stralencluster voor opname en het creëren van vectorinbedding
Tijdens onze tests hebben we ontdekt dat de GPU's de grootste impact hebben op de prestaties bij het maken van de insluitingen. Daarom hebben we besloten een Ray-cluster te gebruiken om onze onbewerkte tekst te converteren en de insluitingen te maken. straal is een open source unified compute-framework waarmee ML-ingenieurs en Python-ontwikkelaars Python-applicaties kunnen schalen en ML-workloads kunnen versnellen. Ons cluster bestond uit 5 g4dn.12xlarge Amazon Elastic Compute-cloud (Amazon EC2)-instanties. Elke instantie was geconfigureerd met 4 NVIDIA T4 Tensor Core GPU's, 48 vCPU en 192 GiB geheugen. Voor onze tekstrecords hebben we ze uiteindelijk in 1,000 stukjes opgedeeld met een overlap van 100 stukjes. Dit komt uit op ongeveer 200 per record. Voor het model dat wordt gebruikt om inbedding te maken, zijn we uitgekomen all-mpnet-base-v2 om een 768-dimensionale vectorruimte te creëren.
Opstelling infrastructuur
We hebben de volgende RDS-instantietypen en OpenSearch-serviceclusterconfiguraties gebruikt om onze infrastructuur op te zetten.
Dit zijn onze eigenschappen voor het RDS-instantietype:
- Instantietype: db.r7g.12xlarge
- Toegewezen opslag: 20 TB
- Multi-AZ: waar
- Versleutelde opslag: waar
- Prestatie-inzichten inschakelen: Waar
- Behoud van prestatie-inzichten: 7 dagen
- Opslagtype: gp3
- Voorziene IOPS: 64,000
- Indextype: IVF
- Aantal lijsten: 5,000
- Afstandsfunctie: L2
Dit zijn onze OpenSearch Service-clustereigenschappen:
- Versie: 2.5
- Gegevensknooppunten: 10
- Type gegevensknooppuntinstantie: r6g.4xlarge
- Primaire knooppunten: 3
- Primair knooppuntinstantietype: r6g.xlarge
- Index: HNSW-motor:
nmslib - Vernieuwingsinterval: 30 seconden
ef_construction: 256- m: 16
- Afstandsfunctie: L2
We hebben grote configuraties gebruikt voor zowel het OpenSearch Service-cluster als de RDS-instanties om prestatieknelpunten te voorkomen.
We implementeren de oplossing met behulp van een AWS Cloud-ontwikkelingskit (AWS-CDK) stack, zoals beschreven in de volgende sectie.
Implementeer de AWS CDK-stack
Met de AWS CDK-stack kunnen we OpenSearch Service of Amazon RDS kiezen voor het opnemen van gegevens.
Voorafgaande vereisten
Voordat u doorgaat met de installatie, wijzigt u onder cdk, bin, src.tc de Booleaanse waarden voor Amazon RDS en OpenSearch Service in waar of onwaar, afhankelijk van uw voorkeur.
Je hebt ook een servicegekoppelde versie nodig AWS Identiteits- en toegangsbeheer (IAM)-rol voor het OpenSearch Service-domein. Voor meer details, zie Amazon OpenSearch Service Construct-bibliotheek. U kunt ook de volgende opdracht uitvoeren om de rol te maken:
Deze AWS CDK-stack zal de volgende infrastructuur inzetten:
- Een VPC
- Een jumphost (binnen de VPC)
- Een OpenSearch Service-cluster (als u de OpenSearch-service gebruikt voor opname)
- Een RDS-instantie (bij gebruik van Amazon RDS voor opname)
- An AWS-systeembeheerder document voor het inzetten van de Ray-cluster
- An Amazon eenvoudige opslagservice (Amazon S3) emmer
- An AWS lijm taak voor het converteren van de JSONL-bestanden van de OSCAR-gegevensset naar Parquet-bestanden
- Amazon Cloud Watch dashboards
Download de gegevens
Voer de volgende opdrachten uit vanaf de jumphost:
Voordat je de git repository gaat klonen, zorg ervoor dat je een Hugging Face-profiel hebt en toegang hebt tot het OSCAR-gegevenscorpus. U moet de gebruikersnaam en het wachtwoord gebruiken voor het klonen van de OSCAR-gegevens:
Converteer JSONL-bestanden naar Parquet
De AWS CDK-stack heeft de AWS Glue ETL-taak gemaakt oscar-jsonl-parquet om de OSCAR-gegevens van JSONL naar Parquet-indeling te converteren.
Nadat u het oscar-jsonl-parquet job, moeten de bestanden in Parquet-indeling beschikbaar zijn onder de parketmap in de S3-bucket.
Download de vragen
Download vanaf uw jumphost de vraaggegevens en upload deze naar uw S3-bucket:
Zet het Ray-cluster op
Als onderdeel van de AWS CDK-stack-implementatie hebben we een Systems Manager-document gemaakt met de naam CreateRayCluster.
Voer de volgende stappen uit om het document uit te voeren:
- Op de Systems Manager-console, onder Documenten in het navigatievenster, kies Van mij.
- Open de
CreateRayClusterdocument. - Kies lopen.
Op de run-opdrachtpagina worden de standaardwaarden voor het cluster ingevuld.
De standaardconfiguratie vraagt 5 g4dn.12xlarge. Zorg ervoor dat uw account limieten heeft om dit te ondersteunen. De relevante servicelimiet is het uitvoeren van On-Demand G- en VT-instanties. De standaard hiervoor is 64, maar deze configuratie vereist 240 CPUS.
- Nadat u de clusterconfiguratie hebt gecontroleerd, selecteert u de jumphost als doel voor de run-opdracht.
Met deze opdracht worden de volgende stappen uitgevoerd:
- Kopieer de Ray-clusterbestanden
- Zet het Ray-cluster op
- Stel de OpenSearch Service-indexen in
- Stel de RDS-tabellen in
U kunt de uitvoer van de opdrachten controleren op de Systems Manager-console. Dit proces duurt 10 tot 15 minuten voor de eerste lancering.
Inname uitvoeren
Maak vanaf de jumphost verbinding met het Ray-cluster:
De eerste keer dat u verbinding maakt met de host, installeert u de vereisten. Deze bestanden moeten al aanwezig zijn op het hoofdknooppunt.
Als u bij een van de opnamemethoden een foutmelding als de volgende krijgt, heeft dit te maken met verlopen inloggegevens. De huidige oplossing (op het moment van schrijven) is het plaatsen van referentiebestanden in het Ray-hoofdknooppunt. Om veiligheidsrisico's te voorkomen, mag u geen IAM-gebruikers gebruiken voor authenticatie wanneer u speciaal gebouwde software ontwikkelt of met echte gegevens werkt. Gebruik in plaats daarvan federatie met een identiteitsprovider zoals AWS IAM Identity Center (opvolger van AWS Single Sign-On).
Meestal worden de inloggegevens in het bestand opgeslagen ~/.aws/credentials op Linux- en macOS-systemen, en %USERPROFILE%.awscredentials op Windows, maar dit zijn referenties voor de korte termijn met een sessietoken. U kunt het standaardgegevensbestand ook niet overschrijven en daarom moet u langetermijngegevens aanmaken zonder het sessietoken met behulp van een nieuwe IAM-gebruiker.
Om inloggegevens voor de lange termijn aan te maken, moet u een AWS-toegangssleutel en een geheime AWS-toegangssleutel genereren. U kunt dat doen vanuit de IAM-console. Voor instructies, zie Authenticeer met IAM-gebruikersreferenties.
Nadat u de sleutels hebt gemaakt, maakt u verbinding met de jumphost met behulp van Session Manager, een mogelijkheid van Systems Manager, en voer de volgende opdracht uit:
Nu kunt u de opnamestappen opnieuw uitvoeren.
Neem gegevens op in de OpenSearch-service
Als u de OpenSearch-service gebruikt, voert u het volgende script uit om de bestanden op te nemen:
Wanneer het voltooid is, voert u het script uit dat gesimuleerde query's uitvoert:
Neem gegevens op in Amazon RDS
Als u Amazon RDS gebruikt, voert u het volgende script uit om de bestanden op te nemen:
Als het klaar is, zorg er dan voor dat u een volledig vacuüm uitvoert op de RDS-instantie.
Voer vervolgens het volgende script uit om gesimuleerde query's uit te voeren:
Stel het Ray-dashboard in
Voordat u het Ray-dashboard instelt, moet u het AWS-opdrachtregelinterface (AWS CLI) op uw lokale computer. Voor instructies, zie Installeer of update de nieuwste versie van de AWS CLI.
Voer de volgende stappen uit om het dashboard in te stellen:
- Installeer de Sessiebeheer-plug-in voor de AWS CLI.
- Kopieer in het Isengard-account de tijdelijke inloggegevens voor bash/zsh en voer deze uit in uw lokale terminal.
- Maak een session.sh-bestand op uw machine en kopieer de volgende inhoud naar het bestand:
- Wijzig de map waarin dit session.sh-bestand is opgeslagen.
- Voer het commando uit
Chmod +xom uitvoerbare toestemming aan het bestand te geven. - Voer het volgende commando uit:
Bijvoorbeeld:
U ziet een bericht zoals het volgende:
Open een nieuw tabblad in uw browser en voer localhost:8265 in.
U ziet het Ray-dashboard en statistieken van de lopende taken en clusters. U kunt vanaf hier statistieken volgen.
U kunt bijvoorbeeld het Ray-dashboard gebruiken om de belasting op het cluster te observeren. Zoals te zien is in de volgende schermafbeelding, worden de GPU's tijdens opname bijna 100% benut.
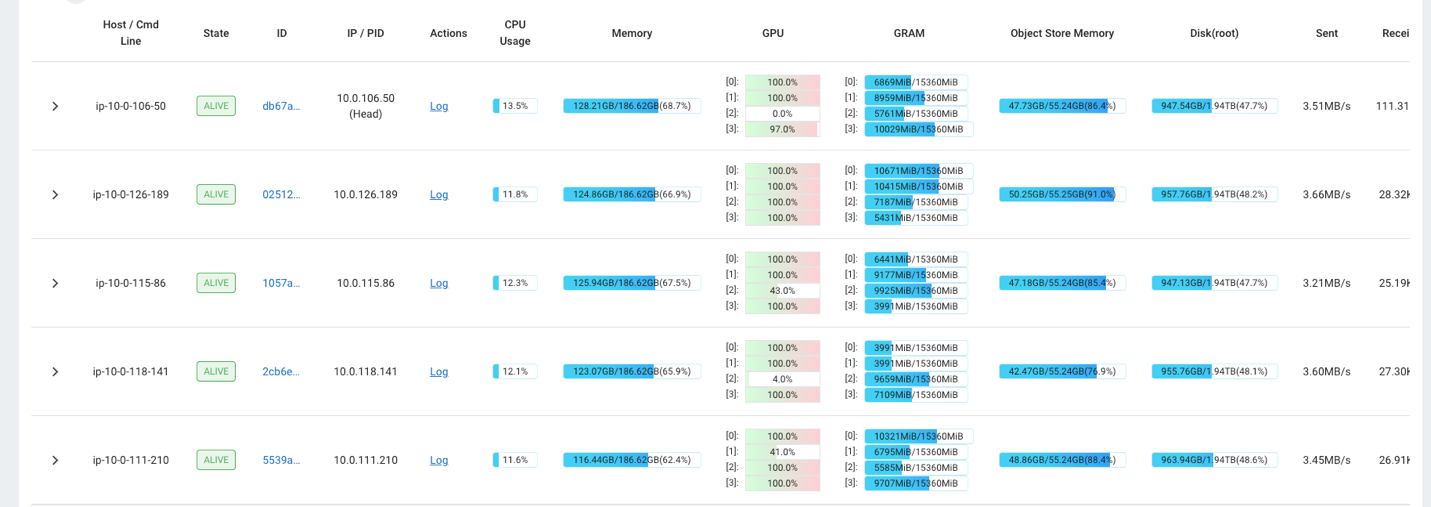
U kunt ook gebruik maken van de RAG_Benchmarks CloudWatch-dashboard om de opnamesnelheid en responstijden van zoekopdrachten te bekijken.
Uitbreidbaarheid van de oplossing
U kunt deze oplossing uitbreiden om andere AWS-vectorwinkels of vectorwinkels van derden aan te sluiten. Voor elke nieuwe vectoropslag moet u scripts maken voor het configureren van de gegevensopslag en voor het opnemen van gegevens. De rest van de pijpleiding kan indien nodig worden hergebruikt.
Conclusie
In dit bericht hebben we een ETL-pijplijn gedeeld die u kunt gebruiken om gevectoriseerde RAG-gegevens in zowel OpenSearch Service als Amazon RDS te plaatsen met de pgvector-extensie als vectorgegevensopslag. De oplossing maakte gebruik van een Ray-cluster om de noodzakelijke parallelliteit te bieden om een groot datacorpus op te nemen. U kunt deze methodologie gebruiken om elke vectordatabase van uw keuze te integreren om RAG-pijplijnen te bouwen.
Over de auteurs
 Randy DeFauw is een Senior Principal Solutions Architect bij AWS. Hij heeft een MSEE-diploma behaald aan de Universiteit van Michigan, waar hij werkte aan computervisie voor autonome voertuigen. Hij heeft ook een MBA van de Colorado State University. Randy heeft diverse functies in de technologiesector bekleed, variërend van software-engineering tot productmanagement. Hij betrad de big data-ruimte in 2013 en blijft dat gebied verkennen. Hij werkt actief aan projecten op het gebied van ML en heeft gepresenteerd op tal van conferenties, waaronder Strata en GlueCon.
Randy DeFauw is een Senior Principal Solutions Architect bij AWS. Hij heeft een MSEE-diploma behaald aan de Universiteit van Michigan, waar hij werkte aan computervisie voor autonome voertuigen. Hij heeft ook een MBA van de Colorado State University. Randy heeft diverse functies in de technologiesector bekleed, variërend van software-engineering tot productmanagement. Hij betrad de big data-ruimte in 2013 en blijft dat gebied verkennen. Hij werkt actief aan projecten op het gebied van ML en heeft gepresenteerd op tal van conferenties, waaronder Strata en GlueCon.
 David Christian is een Principal Solutions Architect gevestigd in Zuid-Californië. Hij heeft zijn bachelor Informatiebeveiliging en een passie voor automatisering. Zijn aandachtsgebieden zijn DevOps-cultuur en transformatie, infrastructuur als code en veerkracht. Voordat hij bij AWS kwam, bekleedde hij functies in beveiliging, DevOps en systeemtechniek, waarbij hij grootschalige private en publieke cloudomgevingen beheerde.
David Christian is een Principal Solutions Architect gevestigd in Zuid-Californië. Hij heeft zijn bachelor Informatiebeveiliging en een passie voor automatisering. Zijn aandachtsgebieden zijn DevOps-cultuur en transformatie, infrastructuur als code en veerkracht. Voordat hij bij AWS kwam, bekleedde hij functies in beveiliging, DevOps en systeemtechniek, waarbij hij grootschalige private en publieke cloudomgevingen beheerde.
 Prachi Kulkarni is een Senior Solutions Architect bij AWS. Haar specialisatie is machine learning en ze werkt actief aan het ontwerpen van oplossingen met behulp van verschillende AWS ML-, big data- en analysemogelijkheden. Prachi heeft ervaring in meerdere domeinen, waaronder de gezondheidszorg, uitkeringen, detailhandel en onderwijs, en heeft in verschillende functies gewerkt op het gebied van productengineering en -architectuur, management en klantensucces.
Prachi Kulkarni is een Senior Solutions Architect bij AWS. Haar specialisatie is machine learning en ze werkt actief aan het ontwerpen van oplossingen met behulp van verschillende AWS ML-, big data- en analysemogelijkheden. Prachi heeft ervaring in meerdere domeinen, waaronder de gezondheidszorg, uitkeringen, detailhandel en onderwijs, en heeft in verschillende functies gewerkt op het gebied van productengineering en -architectuur, management en klantensucces.
 Richa Gupta is een oplossingsarchitect bij AWS. Ze heeft een passie voor het ontwerpen van end-to-end oplossingen voor klanten. Haar specialisatie is machine learning en hoe dit kan worden gebruikt om nieuwe oplossingen te bouwen die leiden tot operationele uitmuntendheid en de bedrijfsopbrengsten stimuleren. Voordat ze bij AWS kwam, werkte ze als Software Engineer en Solutions Architect, waar ze oplossingen bouwde voor grote telecomoperatoren. Buiten haar werk verkent ze graag nieuwe plekken en houdt ze van avontuurlijke activiteiten.
Richa Gupta is een oplossingsarchitect bij AWS. Ze heeft een passie voor het ontwerpen van end-to-end oplossingen voor klanten. Haar specialisatie is machine learning en hoe dit kan worden gebruikt om nieuwe oplossingen te bouwen die leiden tot operationele uitmuntendheid en de bedrijfsopbrengsten stimuleren. Voordat ze bij AWS kwam, werkte ze als Software Engineer en Solutions Architect, waar ze oplossingen bouwde voor grote telecomoperatoren. Buiten haar werk verkent ze graag nieuwe plekken en houdt ze van avontuurlijke activiteiten.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/build-a-rag-data-ingestion-pipeline-for-large-scale-ml-workloads/

