De hoeveelheid wereldwijd gegenereerde gegevens blijft stijgen, van gaming, detailhandel en financiën tot productie, gezondheidszorg en reizen. Organisaties zijn op zoek naar meer manieren om de constante instroom van gegevens snel te gebruiken om te innoveren voor hun bedrijven en klanten. Ze moeten de gegevens op betrouwbare wijze vastleggen, verwerken, analyseren en in een groot aantal gegevensopslagplaatsen laden, en dat allemaal in realtime.
Apache Kafka is een populaire keuze voor deze realtime streamingbehoeften. Het kan echter een uitdaging zijn om een Kafka-cluster op te zetten samen met andere gegevensverwerkingscomponenten die automatisch worden geschaald, afhankelijk van de behoeften van uw toepassing. U riskeert te weinig voorzieningen voor piekverkeer, wat kan leiden tot downtime, of te veel voorzieningen voor de basisbelasting, wat tot verspilling leidt. AWS biedt meerdere serverloze services zoals Amazon Managed Streaming voor Apache Kafka (Amazone MSK), Amazon Data-brandslang, Amazon DynamoDB en AWS Lambda die automatisch schaalt, afhankelijk van uw behoeften.
In dit bericht leggen we uit hoe u sommige van deze services kunt gebruiken, waaronder MSK Serverloos, om een serverloos dataplatform te bouwen dat aan uw realtime behoeften voldoet.
Overzicht oplossingen
Laten we ons een scenario voorstellen. U bent verantwoordelijk voor het beheer van duizenden modems voor een internetprovider die in meerdere regio's wordt ingezet. U wilt de kwaliteit van de modemconnectiviteit bewaken, die een aanzienlijke impact heeft op de productiviteit en tevredenheid van klanten. Uw implementatie omvat verschillende modems die moeten worden gemonitord en onderhouden om minimale downtime te garanderen. Elk apparaat verzendt elke seconde duizenden records van 1 KB, zoals CPU-gebruik, geheugengebruik, alarm en verbindingsstatus. U wilt realtime toegang tot deze gegevens, zodat u de prestaties in realtime kunt volgen en problemen snel kunt opsporen en verhelpen. U hebt ook toegang op langere termijn tot deze gegevens nodig voor machine learning-modellen (ML) om voorspellende onderhoudsbeoordelingen uit te voeren, optimalisatiemogelijkheden te vinden en de vraag te voorspellen.
Uw klanten die de gegevens ter plaatse verzamelen, zijn geschreven in Python en kunnen alle gegevens als Apache Kafka-onderwerpen naar Amazon MSK sturen. Voor de lage latentie en realtime gegevenstoegang van uw toepassing kunt u gebruik maken van Lambda en DynamoDB. Voor gegevensopslag op langere termijn kunt u de beheerde serverloze connectorservice gebruiken Amazon Data-brandslang om gegevens naar uw datameer te verzenden.
Het volgende diagram laat zien hoe u deze end-to-end serverloze applicatie kunt bouwen.
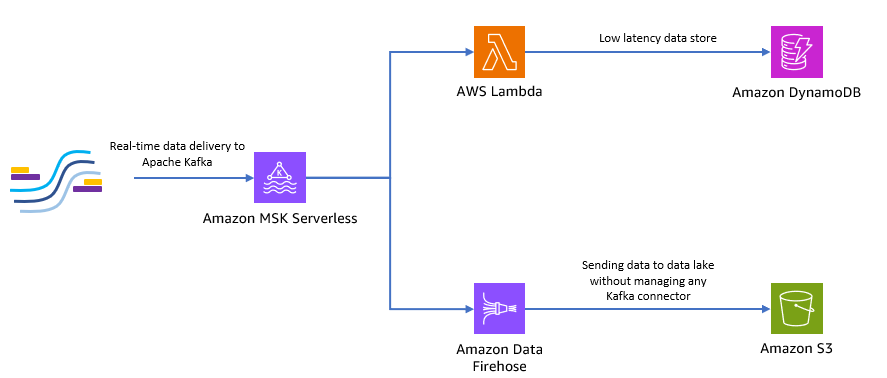
Laten we de stappen in de volgende secties volgen om deze architectuur te implementeren.
Creëer een serverloos Kafka-cluster op Amazon MSK
We gebruiken Amazon MSK om realtime telemetriegegevens van modems op te nemen. Het maken van een serverloos Kafka-cluster is eenvoudig op Amazon MSK. Het duurt slechts een paar minuten om de AWS-beheerconsole of AWS SDK. Om de console te gebruiken, zie Aan de slag met MSK Serverloze clusters. U maakt een serverloos cluster, AWS Identiteits- en toegangsbeheer (IAM)-rol en clientmachine.
Maak een Kafka-onderwerp met Python
Wanneer uw cluster en clientmachine gereed zijn, SSH naar uw clientmachine en installeer Kafka Python en de MSK IAM-bibliotheek voor Python.
- Voer de volgende opdrachten uit om Kafka Python en de MSK IAM-bibliotheek:
- Maak een nieuw bestand met de naam
createTopic.py. - Kopieer de volgende code naar dit bestand, waarbij u de
bootstrap_serversenregioninformatie met de details voor uw cluster. Voor instructies over het ophalen van debootstrap_serversinformatie voor uw MSK-cluster, zie De bootstrap-makelaars krijgen voor een Amazon MSK-cluster.
- Voer de ... uit
createTopic.pyscript om een nieuw Kafka-onderwerp te maken met de naammytopicop uw serverloze cluster:
Produceer records met Python
Laten we enkele voorbeelden van modemtelemetriegegevens genereren.
- Maak een nieuw bestand met de naam
kafkaDataGen.py. - Kopieer de volgende code naar dit bestand, waarbij u de
BROKERSenregioninformatie met de details voor uw cluster:
- Voer de ... uit
kafkaDataGen.pyom continu willekeurige gegevens te genereren en deze te publiceren in het opgegeven Kafka-onderwerp:
Bewaar evenementen in Amazon S3
Nu slaat u alle onbewerkte gebeurtenisgegevens op in een Amazon eenvoudige opslagservice (Amazon S3) data lake voor analyse. U kunt dezelfde gegevens gebruiken om ML-modellen te trainen. De integratie met Amazon Data Firehose stelt Amazon MSK in staat om naadloos gegevens van uw Apache Kafka-clusters in een S3-datameer te laden. Voer de volgende stappen uit om continu gegevens van Kafka naar Amazon S3 te streamen, waardoor het niet meer nodig is om uw eigen connectorapplicaties te bouwen of te beheren:
- Maak op de Amazon S3-console een nieuwe bucket. Je kunt ook een bestaande emmer gebruiken.
- Maak een nieuwe map in uw S3-bucket met de naam
streamingDataLake. - Kies op de Amazon MSK-console uw MSK Serverless-cluster.
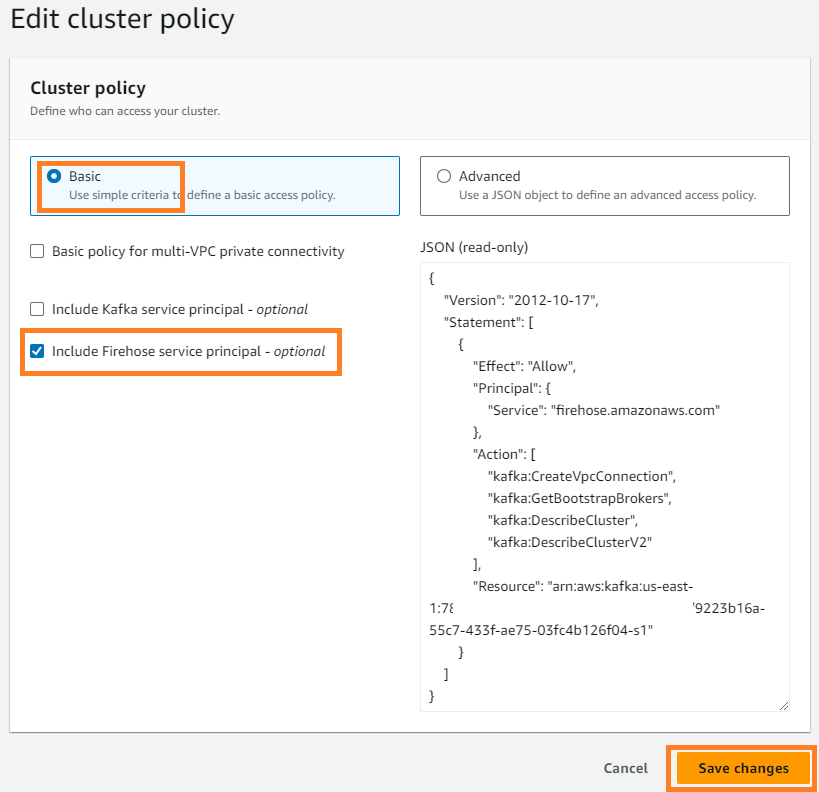
- Op de Acties menu, kies Clusterbeleid bewerken.

- kies Firehose-service-principal opnemen En kies Wijzigingen opslaan.
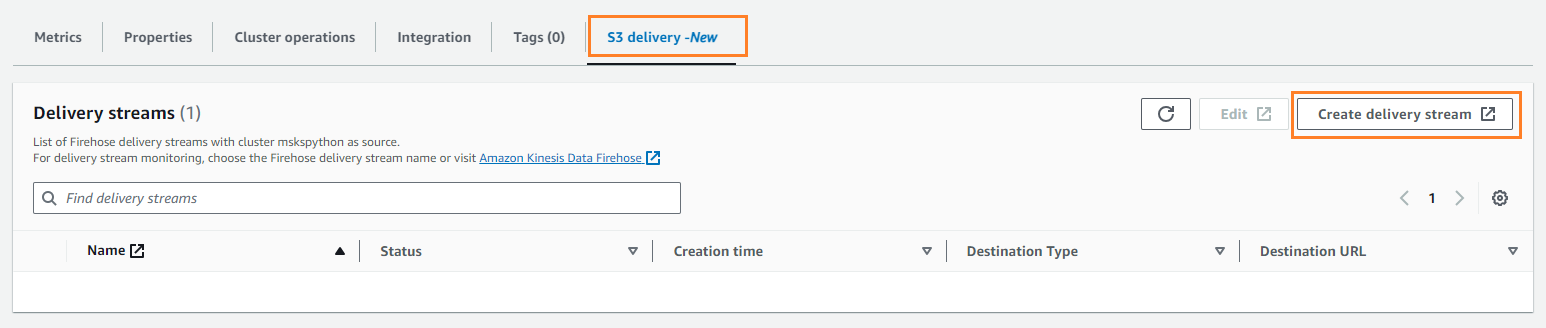
- Op de S3-levering tabblad, kies Maak een leveringsstroom.
- Voor bron, kiezen Amazon MSK.
- Voor Bestemming, kiezen Amazon S3.

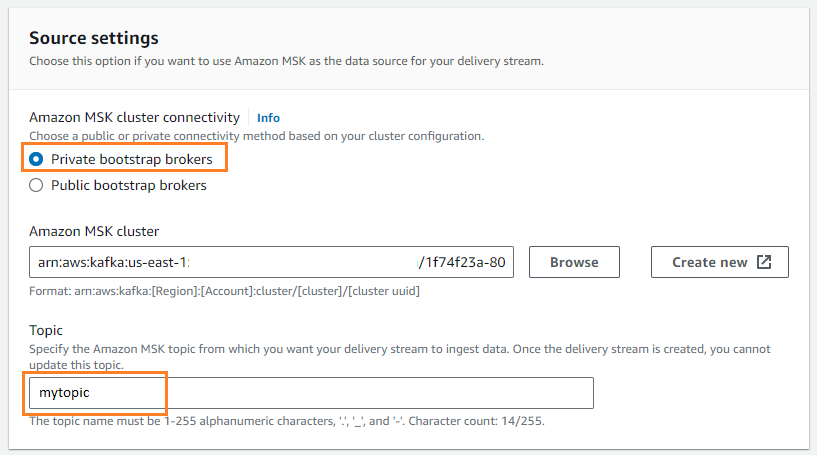
- Voor Amazon MSK-clusterconnectiviteitselecteer Particuliere bootstrapmakelaars.
- Voor Thema, voer een onderwerpnaam in (voor dit bericht,
mytopic).
- Voor S3 emmer, kiezen Blader en kies je S3-emmer.
- Enter
streamingDataLakeals uw S3-bucketvoorvoegsel. - Enter
streamingDataLakeErrals het uitvoervoorvoegsel van uw S3-bucketfout.

- Kies Maak een leveringsstroom.
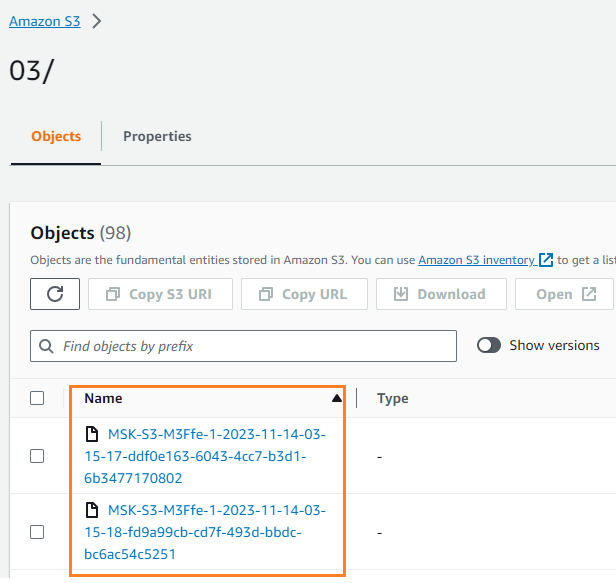
U kunt verifiëren dat de gegevens naar uw S3-bucket zijn geschreven. Je zou moeten zien dat de streamingDataLake map is gemaakt en de bestanden worden opgeslagen in partities.
Bewaar gebeurtenissen in DynamoDB
Voor de laatste stap bewaart u de meest recente modemgegevens in DynamoDB. Hierdoor heeft de clienttoepassing toegang tot de modemstatus en kan hij op afstand communiceren met de modem, waar dan ook, met lage latentie en hoge beschikbaarheid. Lambda werkt naadloos samen met Amazon MSK. Lambda peilt intern naar nieuwe berichten van de gebeurtenisbron en roept vervolgens synchroon de doel-Lambda-functie aan. Lambda leest de berichten in batches en levert deze aan uw functie als een gebeurtenispayload.
Laten we eerst een tabel maken in DynamoDB. Verwijzen naar DynamoDB API-machtigingen: verwijzing naar acties, bronnen en voorwaarden om te verifiëren dat uw clientmachine over de benodigde machtigingen beschikt.
- Maak een nieuw bestand met de naam
createTable.py. - Kopieer de volgende code naar het bestand, waarbij u de
regioninformatie:
- Voer de ... uit
createTable.pyscript om een tabel te maken met de naamdevice_statusin DynamoDB:
Laten we nu de Lambda-functie configureren.
- Kies op de Lambda-console Functies in het navigatievenster.
- Kies Maak functie.
- kies Auteur vanaf nul.
- Voor Functienaam¸ voer een naam in (bijvoorbeeld
my-notification-kafka). - Voor Runtime, kiezen Python 3.11.
- Voor machtigingenselecteer Gebruik een bestaande rol en kies een rol bij machtigingen om uit uw cluster te lezen.
- Maak de functie.
Op de configuratiepagina van de Lambda-functie kunt u nu bronnen, bestemmingen en uw applicatiecode configureren.
- Kies Trigger toevoegen.
- Voor Trigger configuratie, ga naar binnen
MSKom Amazon MSK te configureren als trigger voor de Lambda-bronfunctie. - Voor MSK-cluster, ga naar binnen
myCluster. - deselecteren Activeer trekker, omdat u uw Lambda-functie nog niet heeft geconfigureerd.
- Voor Seriegrootte, ga naar binnen
100. - Voor Start positie, kiezen Latest.
- Voor Onderwerpnaam¸ voer een naam in (bijvoorbeeld
mytopic). - Kies Toevoegen.
- Op de pagina met details over de Lambda-functie, op de Code Voer de volgende code in:
- Implementeer de Lambda-functie.
- Op de Configuratie tabblad, kies Edit om de trigger te bewerken.
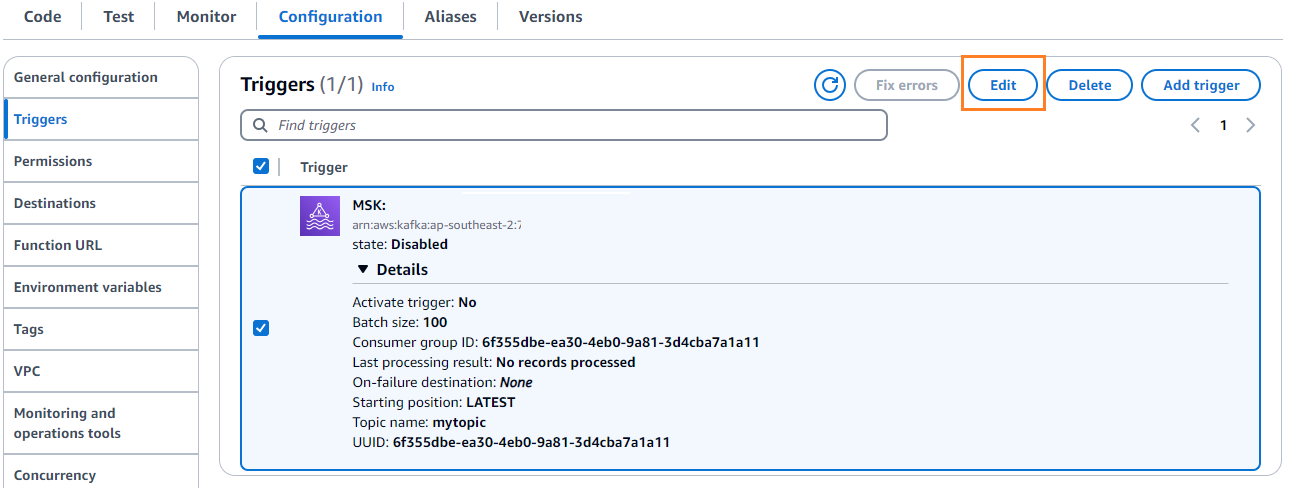
- Selecteer de trigger en kies vervolgens Bespaar.
- Kies op de DynamoDB-console Artikelen verkennen in het navigatievenster.
- Selecteer de tafel
device_status.
U zult zien dat Lambda gebeurtenissen die in het Kafka-onderwerp zijn gegenereerd, naar DynamoDB schrijft.

Samengevat
Streamingdatapijplijnen zijn van cruciaal belang voor het bouwen van realtime applicaties. Het opzetten en beheren van de infrastructuur kan echter lastig zijn. In dit bericht hebben we besproken hoe je een serverloze streamingpijplijn op AWS kunt bouwen met behulp van Amazon MSK, Lambda, DynamoDB, Amazon Data Firehose en andere services. De belangrijkste voordelen zijn dat er geen servers hoeven te worden beheerd, automatische schaalbaarheid van de infrastructuur en een pay-as-you-go-model met volledig beheerde services.
Klaar om uw eigen realtime pijplijn te bouwen? Ga vandaag nog aan de slag met een gratis AWS-account. Met de kracht van serverless kunt u zich concentreren op uw applicatielogica, terwijl AWS het ongedifferentieerde zware werk afhandelt. Laten we iets geweldigs bouwen op AWS!
Over de auteurs
 Masudur Rahaman Sayem is een Streaming Data Architect bij AWS. Hij werkt wereldwijd samen met AWS-klanten om datastreamingarchitecturen te ontwerpen en te bouwen om echte zakelijke problemen op te lossen. Hij is gespecialiseerd in het optimaliseren van oplossingen die gebruik maken van streaming datadiensten en NoSQL. Sayem is erg gepassioneerd door gedistribueerd computergebruik.
Masudur Rahaman Sayem is een Streaming Data Architect bij AWS. Hij werkt wereldwijd samen met AWS-klanten om datastreamingarchitecturen te ontwerpen en te bouwen om echte zakelijke problemen op te lossen. Hij is gespecialiseerd in het optimaliseren van oplossingen die gebruik maken van streaming datadiensten en NoSQL. Sayem is erg gepassioneerd door gedistribueerd computergebruik.
 Michaël Oguike is productmanager voor Amazon MSK. Hij is gepassioneerd door het gebruik van data om inzichten te ontdekken die actie stimuleren. Hij helpt graag klanten uit een breed scala van sectoren om hun bedrijf te verbeteren met behulp van datastreaming. Michael leert ook graag over gedragswetenschappen en psychologie uit boeken en podcasts.
Michaël Oguike is productmanager voor Amazon MSK. Hij is gepassioneerd door het gebruik van data om inzichten te ontdekken die actie stimuleren. Hij helpt graag klanten uit een breed scala van sectoren om hun bedrijf te verbeteren met behulp van datastreaming. Michael leert ook graag over gedragswetenschappen en psychologie uit boeken en podcasts.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-serverless-streaming-pipeline-with-apache-kafka-on-amazon-msk-using-python/

