Introductie
In slechts zes maanden tijd is OpenAI's ChatGPT een integraal onderdeel van ons leven geworden. Het is niet alleen meer beperkt tot technologie; mensen van alle leeftijden en beroepen, van studenten tot schrijvers, maken er veelvuldig gebruik van. Deze chatmodellen blinken uit in nauwkeurigheid, snelheid en mensachtige gesprekken. Ze staan klaar om een belangrijke rol te spelen op verschillende gebieden, niet alleen op het gebied van technologie.
Er zijn open-sourcetools zoals AutoGPT's, BabyAGI en Langchain ontstaan, die gebruikmaken van de kracht van taalmodellen. Automatiseer programmeertaken met prompts, verbind taalmodellen met gegevensbronnen en maak sneller dan ooit tevoren AI-applicaties. Langchain is een Q&A-tool met ChatGPT voor pdf's, waardoor het een one-stop-shop is voor het bouwen van AI-applicaties.
leerdoelen
- Bouw een chatbot-interface met Gradio
- Extraheer teksten uit pdf's en maak inbeddingen
- Sla inbeddingen op in de Chroma-vectordatabase
- Query naar de backend sturen (Langchain-keten)
- Voer semantische zoekopdrachten uit op teksten om relevante gegevensbronnen te vinden
- Verzend gegevens naar LLM (ChatGPT) en ontvang antwoorden op de chatbot
De Langchain maakt het gemakkelijk om al deze stappen in een paar regels code uit te voeren. Het heeft wrappers voor meerdere services, waaronder inbeddingsmodellen, chatmodellen en vectordatabases.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Wat is Langchain?
Langchain is een open-source tool geschreven in Python die helpt bij het verbinden van externe gegevens met grote taalmodellen. Het maakt de chatmodellen zoals GPT-4 of GPT-3.5 meer agentisch en databewust. Dus in zekere zin biedt Langchain een manier om LLM's te voeden met nieuwe gegevens waarop het niet is getraind. Langchain biedt veel ketens die de complexiteit wegnemen bij de interactie met taalmodellen. We hebben ook verschillende andere hulpmiddelen nodig, zoals modellen voor het maken van vectorinbeddingen en vectordatabases om vectoren op te slaan. Laten we, voordat we verder gaan, eerst even kijken naar tekstinsluitingen. Wat zijn dit en waarom is het belangrijk?
Tekst insluitingen
Tekstinbedding is het hart en de ziel van Large Language Operations. Technisch gezien kunnen we werken met taalmodellen met natuurlijke taal, maar het opslaan en ophalen van natuurlijke taal is zeer inefficiënt. In dit project zullen we bijvoorbeeld snelle zoekbewerkingen moeten uitvoeren op grote hoeveelheden gegevens. Het is onmogelijk om dergelijke bewerkingen uit te voeren op gegevens in natuurlijke taal.
Om het efficiënter te maken, moeten we tekstgegevens omzetten in vectorvormen. Er zijn speciale ML-modellen voor het maken van inbeddingen van teksten. De teksten worden omgezet in multidimensionale vectoren. Eenmaal ingebed, kunnen we deze gegevens groeperen, sorteren, zoeken en meer. We kunnen de afstand tussen twee zinnen berekenen om te weten hoe nauw ze verwant zijn. En het beste is dat deze bewerkingen niet alleen beperkt zijn tot trefwoorden zoals de traditionele zoekopdrachten in databases, maar eerder de semantische nabijheid van twee zinnen vastleggen. Dit maakt het dankzij Machine Learning een stuk krachtiger.
Langchain-tools
Langchain heeft wrappers voor alle belangrijke vectordatabases zoals Chroma, Redis, Pinecone, Alpine db en meer. En hetzelfde geldt voor LLM's, naast OpeanAI-modellen ondersteunt het ook de modellen van Cohere, GPT4ALL - een open-source alternatief voor GPT-modellen. Voor insluitingen biedt het wrappers voor OpeanAI-, Cohere- en HuggingFace-insluitingen. U kunt ook uw aangepaste inbeddingsmodellen gebruiken.
Kortom, Langchain is een metatool die veel complicaties van interactie met onderliggende technologieën wegneemt, waardoor het voor iedereen gemakkelijker wordt om snel AI-applicaties te bouwen.
In dit artikel gebruiken we de OpeanAI-inbeddingen model voor het maken van inbeddingen. Als u een AI-app voor eindgebruikers wilt implementeren, overweeg dan om Opensource-modellen te gebruiken, zoals Huggingface-modellen of Google's Universal zin-encoder.
Om vectoren op te slaan, zullen we gebruiken ChromaDB, een open-source vectoropslagdatabase. Voel je vrij om andere databases te verkennen, zoals Alpine, Pinecone en Redis. Langchain heeft wikkels voor al deze vectorwinkels.
Om een Langchain-ketting te maken, zullen we gebruiken ConversationalRetrievalChain(), ideaal voor gesprekken met chatmodellen met geschiedenis (om de context van het gesprek te behouden). Bekijk hun officiële documentatie met betrekking tot verschillende LLM-ketens.
Dev-omgeving opzetten
Er zijn nogal wat bibliotheken die we zullen gebruiken. Installeer ze dus van tevoren. Om een naadloze, overzichtelijke ontwikkelomgeving te creëren, gebruikt u virtuele omgevingen or havenarbeider.
gradio = "^3.27.0"
openai = "^0.27.4"
langchain = "^0.0.148"
chromadb = "^0.3.21"
tiktoken = "^0.3.3"
pypdf = "^3.8.1"
pymupdf = "^1.22.2"Importeer nu deze bibliotheken
import gradio as gr
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI from langchain.document_loaders import PyPDFLoader
import os import fitz
from PIL import ImageChat-interface bouwen
De interface van de applicatie heeft twee belangrijke functionaliteiten: de ene is een chatinterface en de andere geeft de relevante pagina van de pdf weer als een afbeelding. Afgezien hiervan een tekstvak voor het accepteren van OpenAI API-sleutels van eindgebruikers. Ik zou het ten zeerste aanbevelen om het artikel door te nemen een GPT-chatbot bouwen met Gradio helemaal opnieuw. Het artikel bespreekt de fundamentele aspecten van Gradio. We zullen veel dingen uit dit artikel lenen.
Met de klasse Gradio Blocks kunnen we een webapp bouwen. Met de klassen Rij en Kolommen kunnen meerdere componenten op de webapp worden uitgelijnd. We zullen ze gebruiken om de webinterface aan te passen.
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style()
De interface is eenvoudig met een paar componenten.
Het heeft:
- Een chat-interface om te communiceren met de PDF.
- Een component voor het weergeven van relevante PDF-pagina's.
- Een tekstvak voor het accepteren van de API-sleutel en een knop voor het wijzigen van de sleutel.
- Een tekstvak voor het stellen van vragen en een verzendknop.
- Een knop om bestanden te uploaden.
Hier is een momentopname van de webinterface.
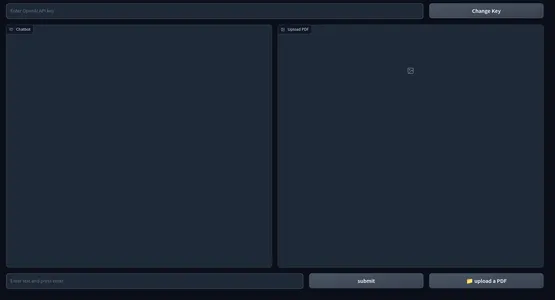
Het frontend-gedeelte van onze applicatie is voltooid. Laten we naar de backend springen.
backend
Laten we eerst eens schetsen met welke processen we te maken zullen krijgen.
- Behandel geüploade PDF en OpenAI API-sleutel
- Extraheer teksten uit PDF en maak er tekstinsluitingen van met behulp van OpenAI-insluitingen.
- Sla vectorinbeddingen op in de ChromaDB-vectoropslag.
- Creëer een Conversational Retrieval chain met Langchain.
- Maak insluitingen van opgevraagde tekst en voer een zoekactie naar overeenkomsten uit op ingesloten documenten.
- Stuur relevante documenten naar het OpenAI chatmodel (gpt-3.5-turbo).
- Haal het antwoord op en stream het in de chat-UI.
- Render relevante PDF-pagina op Web UI.
Dit zijn de overzichten van onze applicatie. Laten we beginnen met bouwen.
Gradio-evenementen
Wanneer een specifieke actie op de web-UI wordt uitgevoerd, worden deze gebeurtenissen geactiveerd. De gebeurtenissen maken de webapp dus interactief en dynamisch. Met Gradio kunnen we gebeurtenissen definiëren met Python-codes.
Gradio Events gebruikt componentvariabelen die we eerder hebben gedefinieerd om te communiceren met de backend. We zullen een paar gebeurtenissen definiëren die we nodig hebben voor onze applicatie. Dit zijn
- API-sleutelgebeurtenis indienen: Als u op Enter drukt nadat u de API-sleutel hebt geplakt, wordt deze gebeurtenis geactiveerd.
- Sleutel wijzigen: Hiermee kunt u een nieuwe API-sleutel opgeven
- Voer vragen in: Stuur tekstvragen naar de chatbot
- Bestand uploaden: hiermee kan de eindgebruiker een PDF-bestand uploaden
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style() # Set up event handlers # Event handler for submitting the OpenAI API key api_key.submit(fn=set_apikey, inputs=[api_key], outputs=[api_key]) # Event handler for changing the API key change_api_key.click(fn=enable_api_box, outputs=[api_key]) # Event handler for uploading a PDF btn.upload(fn=render_first, inputs=[btn], outputs=[show_img]) # Event handler for submitting text and generating response submit_btn.click( fn=add_text, inputs=[chatbot, txt], outputs=[chatbot], queue=False ).success( fn=generate_response, inputs=[chatbot, txt, btn], outputs=[chatbot, txt] ).success( fn=render_file, inputs=[btn], outputs=[show_img] )Tot nu toe hebben we onze functies die binnen boven de gebeurtenishandlers worden genoemd, niet gedefinieerd. Vervolgens gaan we al deze functies definiëren om een functionele webapp te maken.
Omgaan met API-sleutels
Het omgaan met de API-sleutels van een gebruiker is belangrijk omdat het hele ding draait op het BYOK-principe (Bring Your Own Key). Telkens wanneer een gebruiker een sleutel indient, moet het tekstvak onveranderlijk worden met een prompt die suggereert dat de sleutel is ingesteld. En wanneer de "Change Key" -gebeurtenis wordt geactiveerd, moet de box invoer kunnen verwerken.
Definieer hiervoor twee globale variabelen.
enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set',interactive=False)Functies definiëren
def set_apikey(api_key): os.environ['OPENAI_API_KEY'] = api_key return disable_box def enable_api_box(): return enable_boxDe functie set_apikey neemt een tekenreeksinvoer en retourneert de variabele disable_box, waardoor het tekstvak na uitvoering onveranderlijk is. In de sectie Gradio Events hebben we de api_key Submit Event gedefinieerd, die de functie set_apikey aanroept. We hebben de API-sleutel ingesteld als een omgevingsvariabele met behulp van de OS-bibliotheek.
Als u op de knop API-sleutel wijzigen klikt, wordt de variabele enable_box geretourneerd, waardoor de veranderlijkheid van het tekstvak weer mogelijk wordt.
Maak een ketting
Dit is de belangrijkste stap. Deze stap omvat het extraheren van teksten en het maken van inbeddingen en het opslaan ervan in vectorwinkels. Met dank aan Langchain, dat wrappers biedt voor meerdere services om het u gemakkelijker te maken. Dus laten we de functie definiëren.
def process_file(file): # raise an error if API key is not provided if 'OPENAI_API_KEY' not in os.environ: raise gr.Error('Upload your OpenAI API key') # Load the PDF file using PyPDFLoader loader = PyPDFLoader(file.name) documents = loader.load() # Initialize OpenAIEmbeddings for text embeddings embeddings = OpenAIEmbeddings() # Create a ConversationalRetrievalChain with ChatOpenAI language model # and PDF search retriever pdfsearch = Chroma.from_documents(documents, embeddings,) chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.3), retriever= pdfsearch.as_retriever(search_kwargs={"k": 1}), return_source_documents=True,) return chain- Een controle gemaakt of de API-sleutel is ingesteld of niet. Dit veroorzaakt een fout aan de voorkant als de sleutel niet is ingesteld.
- Laad een PDF-bestand met PyPDFLoader
- Gedefinieerde inbeddingsfunctie met OpenAIEmbeddings.
- Een vectoropslag gemaakt van de lijst met teksten uit de PDF met behulp van de inbeddingsfunctie.
- Een keten gedefinieerd met de chatOpenAI (standaard gebruikt ChatOpenAI gpt-3.5-turbo), een base retriever (gebruikt een zoeken naar overeenkomsten).
Reactie genereren
Zodra de keten is gemaakt, bellen we de keten en sturen we onze vragen. Stuur een chatgeschiedenis samen met de vragen om de context van gesprekken te behouden en reacties naar de chatinterface te streamen. Laten we de functie definiëren.
def generate_response(history, query, btn): global COUNT, N, chat_history # Check if a PDF file is uploaded if not btn: raise gr.Error(message='Upload a PDF') # Initialize the conversation chain only once if COUNT == 0: chain = process_file(btn) COUNT += 1 # Generate a response using the conversation chain result = chain({"question": query, 'chat_history':chat_history}, return_only_outputs=True) # Update the chat history with the query and its corresponding answer chat_history += [(query, result["answer"])] # Retrieve the page number from the source document N = list(result['source_documents'][0])[1][1]['page'] # Append each character of the answer to the last message in the history for char in result['answer']: history[-1][-1] += char # Yield the updated history and an empty string yield history, ''
- Geeft een foutmelding als er geen PDF is geüpload.
- Roept de functie process_file slechts één keer aan.
- Verzendt vragen en chatgeschiedenis naar de keten
- Haalt het paginanummer op van het meest relevante antwoord.
- Lever reacties op aan de voorkant.
Render afbeelding van een PDF-bestand
De laatste stap is het weergeven van de afbeelding van het PDF-bestand met het meest relevante antwoord. We kunnen de PyMuPdf- en PIL-bibliotheken gebruiken om de afbeeldingen van het document weer te geven.
def render_file(file): global N # Open the PDF document using fitz doc = fitz.open(file.name) # Get the specific page to render page = doc[N] # Render the page as a PNG image with a resolution of 300 DPI pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) # Create an Image object from the rendered pixel data image = Image.frombytes('RGB', [pix.width, pix.height], pix.samples) # Return the rendered image return image
- Open het bestand met Fitz van PyMuPdf.
- Download de relevante pagina.
- Download pix map voor de pagina.
- Maak de afbeelding van de Image-klasse van PIL.
Dit is alles wat we moeten doen voor een functionele web-app om met elke pdf te chatten.
Alles samenvoegen
#import csv
import gradio as gr
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI from langchain.document_loaders import PyPDFLoader
import os import fitz
from PIL import Image # Global variables
COUNT, N = 0, 0
chat_history = []
chain = ''
enable_box = gr.Textbox.update(value=None, placeholder='Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value='OpenAI API key is Set', interactive=False) # Function to set the OpenAI API key
def set_apikey(api_key): os.environ['OPENAI_API_KEY'] = api_key return disable_box # Function to enable the API key input box
def enable_api_box(): return enable_box # Function to add text to the chat history
def add_text(history, text): if not text: raise gr.Error('Enter text') history = history + [(text, '')] return history # Function to process the PDF file and create a conversation chain
def process_file(file): if 'OPENAI_API_KEY' not in os.environ: raise gr.Error('Upload your OpenAI API key') loader = PyPDFLoader(file.name) documents = loader.load() embeddings = OpenAIEmbeddings() pdfsearch = Chroma.from_documents(documents, embeddings) chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.3), retriever=pdfsearch.as_retriever(search_kwargs={"k": 1}), return_source_documents=True) return chain # Function to generate a response based on the chat history and query
def generate_response(history, query, btn): global COUNT, N, chat_history, chain if not btn: raise gr.Error(message='Upload a PDF') if COUNT == 0: chain = process_file(btn) COUNT += 1 result = chain({"question": query, 'chat_history': chat_history}, return_only_outputs=True) chat_history += [(query, result["answer"])] N = list(result['source_documents'][0])[1][1]['page'] for char in result['answer']: history[-1][-1] += char yield history, '' # Function to render a specific page of a PDF file as an image
def render_file(file): global N doc = fitz.open(file.name) page = doc[N] # Render the page as a PNG image with a resolution of 300 DPI pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) image = Image.frombytes('RGB', [pix.width, pix.height], pix.samples) return image # Gradio application setup
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style() # Set up event handlers # Event handler for submitting the OpenAI API key api_key.submit(fn=set_apikey, inputs=[api_key], outputs=[api_key]) # Event handler for changing the API key change_api_key.click(fn=enable_api_box, outputs=[api_key]) # Event handler for uploading a PDF btn.upload(fn=render_first, inputs=[btn], outputs=[show_img]) # Event handler for submitting text and generating response submit_btn.click( fn=add_text, inputs=[chatbot, txt], outputs=[chatbot], queue=False ).success( fn=generate_response, inputs=[chatbot, txt, btn], outputs=[chatbot, txt] ).success( fn=render_file, inputs=[btn], outputs=[show_img] )
demo.queue()
if __name__ == "__main__": demo.launch()Nu we alles hebben geconfigureerd, laten we onze applicatie starten.
U kunt de toepassing in foutopsporingsmodus starten met de volgende opdracht
gradio-app.py
Anders kunt u de applicatie ook gewoon uitvoeren met de Python-opdracht. Hieronder een impressie van het eindproduct. GitHub-repository van de codes.
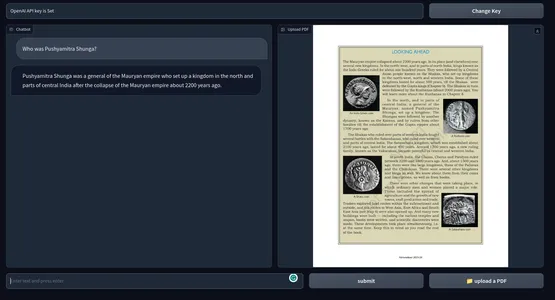
[Ingesloten inhoud]
Mogelijke verbeteringen
De huidige applicatie werkt uitstekend. Maar er zijn een paar dingen die je kunt doen om het beter te maken.
- Dit maakt gebruik van OpenAI-inbeddingen die op de lange termijn duur kunnen zijn. Voor een app die klaar is voor productie, zijn alle modellen voor offline inbedding mogelijk geschikter.
- Gradio voor prototyping is prima, maar voor de echte wereld zou een app met een modern javascript-framework zoals Next Js of Svelte veel beter zijn qua prestaties en esthetiek.
- We gebruikten cosinusgelijkenis voor het vinden van relevante teksten. In sommige omstandigheden is een KNN-aanpak wellicht beter.
- Voor PDF's met dichte tekstinhoud is het misschien beter om kleinere stukjes tekst te maken.
- Hoe beter het model, hoe beter de prestatie. Experimenteer met andere LLM's en vergelijk de uitkomsten.
Praktische gebruiksscenario's
Gebruik de tools op meerdere gebieden, van onderwijs tot rechten tot de academische wereld of elk gebied dat u zich kunt voorstellen waarbij de persoon enorme teksten moet doornemen. Enkele van de praktische use-cases van ChatGPT voor PDF's zijn
- Onderwijsinstellingen: Studenten kunnen hun studieboeken, studiemateriaal en opdrachten uploaden, en de tool kan vragen beantwoorden en bepaalde secties uitleggen. Dit kan het algehele leerproces voor studenten minder inspannend maken.
- Juridisch: Advocatenkantoren hebben te maken met talloze juridische documenten in pdf-formaat. Deze tool kan worden gebruikt om gemakkelijk relevante informatie uit procesdocumenten, juridische contracten en statuten te halen. Het kan advocaten helpen om clausules, precedenten en andere informatie sneller te vinden.
- Academie: Onderzoekers hebben vaak te maken met onderzoeksdocumenten en technische documentatie. Een tool die de literatuur kan samenvatten, analyseren en antwoorden kan geven op basis van documenten kan een grote bijdrage leveren aan het besparen van tijd en het verbeteren van de productiviteit.
- Administratie: Overheid kantoren en andere administratieve afdelingen hebben dagelijks te maken met grote hoeveelheden formulieren, aanvragen en rapporten. Het gebruik van een chatbot die documenten beantwoordt, kan het administratieproces stroomlijnen, waardoor iedereen tijd en geld bespaart.
- Financiering: Financiële rapporten analyseren en ze keer op keer opnieuw bekijken is vervelend. Dit kan gemakkelijker worden gemaakt door een chatbot in te zetten. Eigenlijk een stagiair.
- Media: Journalisten en analisten kunnen een chatGPT-compatibele PDF-tool voor het beantwoorden van vragen gebruiken om grote tekstbestanden te doorzoeken en snel antwoorden te vinden.
Een PDF Q&A-tool met chatGPT kan sneller informatie verzamelen uit grote hoeveelheden PDF-tekst. Het is als een zoekmachine voor tekstgegevens. Niet alleen pdf's, maar we kunnen deze tool ook uitbreiden naar alles met tekstgegevens met een beetje codemanipulatie.
Conclusie
Het ging dus allemaal om het bouwen van een chatbot om met elk PDF-bestand te praten met ChatGPT. Dankzij Langchain is het bouwen van AI-applicaties een stuk eenvoudiger geworden. Enkele van de belangrijkste afhaalrestaurants uit het artikel zijn:
- Gradio is een open-source tool voor het maken van prototypen van AI-toepassingen. We hebben de voorkant van de applicatie gemaakt met Gradio.
- Langchain is een andere open-sourcetool waarmee we AI-applicaties kunnen bouwen. Het heeft wrappers voor populaire LLM's en vectorgegevensarchieven, waardoor we gemakkelijk kunnen communiceren met onderliggende services.
- We hebben Langchain gebruikt voor het bouwen van de backend-systemen van onze applicatie.
- OpenAI-modellen waren over het algemeen cruciaal voor onze app. We gebruikten de OpenAI-insluitingen en de GPT 3.5-engine om met pdf's te chatten.
- Een Q&A-tool met ChatGPT voor pdf's en andere tekstgegevens kan een grote bijdrage leveren aan het stroomlijnen van kennistaken.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/05/build-a-chatgpt-for-pdfs-with-langchain/

