Deze blogpost is geschreven in samenwerking met Caroline Chung van Veoneer.
Veoneer is een wereldwijd bedrijf in auto-elektronica en wereldleider op het gebied van elektronische veiligheidssystemen voor auto's. Ze bieden de beste beveiligingssystemen in hun klasse en hebben wereldwijd meer dan 1 miljard elektronische regeleenheden en crashsensoren geleverd aan autofabrikanten. Het bedrijf bouwt voort op een 70-jarige geschiedenis van de ontwikkeling van de autoveiligheid en is gespecialiseerd in geavanceerde hardware en systemen die verkeersincidenten voorkomen en ongevallen beperken.
Automotive in-cabin sensing (ICS) is een opkomende ruimte die gebruik maakt van een combinatie van verschillende soorten sensoren, zoals camera's en radar, en op kunstmatige intelligentie (AI) en machine learning (ML) gebaseerde algoritmen om de veiligheid te verbeteren en de rijervaring te verbeteren. Het bouwen van een dergelijk systeem kan een complexe taak zijn. Ontwikkelaars moeten grote hoeveelheden afbeeldingen handmatig annoteren voor trainings- en testdoeleinden. Dit is zeer tijdrovend en arbeidsintensief. De doorlooptijd voor een dergelijke klus bedraagt enkele weken. Bovendien hebben bedrijven te maken met zaken als inconsistente labels als gevolg van menselijke fouten.
AWS is erop gericht u te helpen uw ontwikkelingssnelheid te verhogen en uw kosten voor het bouwen van dergelijke systemen te verlagen door middel van geavanceerde analyses zoals ML. Onze visie is om ML te gebruiken voor geautomatiseerde annotatie, het opnieuw trainen van veiligheidsmodellen mogelijk te maken en consistente en betrouwbare prestatiestatistieken te garanderen. In dit bericht delen we hoe we samenwerken met de Worldwide Specialist Organization van Amazon en de Generatief AI-innovatiecentrumhebben we een actieve leerpijplijn ontwikkeld voor de begrenzingsvakken van beeldhoofden en annotatie van belangrijke punten in de cabine. De oplossing verlaagt de kosten met meer dan 90%, versnelt het annotatieproces van weken naar uren in termen van doorlooptijd en maakt herbruikbaarheid mogelijk voor vergelijkbare ML-gegevenslabeltaken.
Overzicht oplossingen
Actief leren is een ML-aanpak die een iteratief proces omvat van het selecteren en annoteren van de meest informatieve gegevens om een model te trainen. Gegeven een kleine set gelabelde gegevens en een grote set ongelabelde gegevens, verbetert actief leren de prestaties van het model, vermindert het de etiketteringsinspanningen en integreert menselijke expertise voor robuuste resultaten. In dit bericht bouwen we een actieve leerpijplijn voor beeldannotaties met AWS-services.
Het volgende diagram toont het algemene raamwerk voor onze actieve leerpijplijn. De labelpijplijn neemt afbeeldingen van een Amazon eenvoudige opslagservice (Amazon S3) bucket en voert geannoteerde afbeeldingen uit met de medewerking van ML-modellen en menselijke expertise. De trainingspijplijn verwerkt gegevens voor en gebruikt deze om ML-modellen te trainen. Het initiële model is opgezet en getraind op een kleine set handmatig gelabelde gegevens, en zal worden gebruikt in de labelpijplijn. De labelpijplijn en trainingspijplijn kunnen geleidelijk worden herhaald met meer gelabelde gegevens om de prestaties van het model te verbeteren.
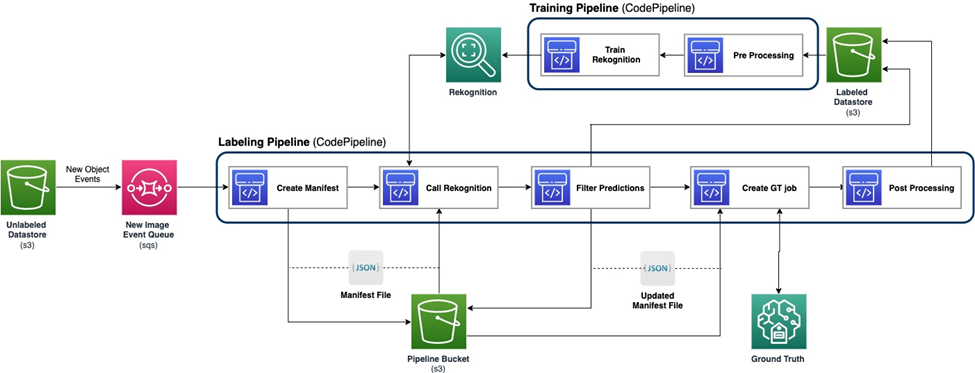
In de etiketteringspijplijn zal een Gebeurtenismelding Amazon S3 wordt aangeroepen wanneer een nieuwe batch afbeeldingen in de Unlabeled Datastore S3-bucket terechtkomt, waardoor de labelpijplijn wordt geactiveerd. Het model produceert de gevolgtrekkingsresultaten voor de nieuwe afbeeldingen. Een aangepaste beoordelingsfunctie selecteert delen van de gegevens op basis van de inferentiebetrouwbaarheidsscore of andere door de gebruiker gedefinieerde functies. Deze gegevens, met de gevolgtrekkingsresultaten, worden verzonden voor een menselijke etiketteringstaak Amazon SageMaker Grondwaarheid gecreëerd door de pijpleiding. Het menselijke labelproces helpt bij het annoteren van de gegevens, en de gewijzigde resultaten worden gecombineerd met de resterende automatisch geannoteerde gegevens, die later door de trainingspijplijn kunnen worden gebruikt.
Het opnieuw trainen van modellen vindt plaats in de trainingspijplijn, waar we de dataset gebruiken die de door mensen gelabelde gegevens bevat om het model opnieuw te trainen. Er wordt een manifestbestand geproduceerd om te beschrijven waar de bestanden zijn opgeslagen, en hetzelfde initiële model wordt opnieuw getraind op basis van de nieuwe gegevens. Na opnieuw trainen vervangt het nieuwe model het oorspronkelijke model en begint de volgende iteratie van de actieve leerpijplijn.
Modelimplementatie
Zowel de etiketteringspijplijn als de trainingspijplijn worden ingezet AWS CodePipeline. AWS CodeBuild Voor de implementatie worden instances gebruikt, wat flexibel en snel is voor een kleine hoeveelheid data. Wanneer snelheid nodig is, gebruiken we Amazon Sage Maker eindpunten op basis van de GPU-instantie om meer bronnen toe te wijzen om het proces te ondersteunen en te versnellen.
De pijplijn voor het opnieuw trainen van modellen kan worden aangeroepen wanneer er een nieuwe gegevensset is of wanneer de prestaties van het model moeten worden verbeterd. Een cruciale taak in de hertrainingspijplijn is het beschikken over een versiebeheersysteem voor zowel de trainingsgegevens als het model. Hoewel AWS-services zoals Amazon Rekognition beschikken over de geïntegreerde versiebeheerfunctie, waardoor de pijplijn eenvoudig te implementeren is, vereisen aangepaste modellen het loggen van metagegevens of aanvullende versiebeheertools.
De gehele workflow wordt geïmplementeerd met behulp van de AWS Cloud-ontwikkelingskit (AWS CDK) om de benodigde AWS-componenten te maken, waaronder de volgende:
- Twee rollen voor CodePipeline- en SageMaker-taken
- Twee CodePipeline-taken, die de workflow orkestreren
- Twee S3-buckets voor de codeartefacten van de pijpleidingen
- Eén S3-bucket voor het labelen van het taakmanifest, de gegevenssets en de modellen
- Voorbewerking en nabewerking AWS Lambda functies voor de SageMaker Ground Truth-labeltaken
De AWS CDK-stacks zijn zeer modulair en herbruikbaar voor verschillende taken. De training, de gevolgtrekkingscode en de SageMaker Ground Truth-sjabloon kunnen worden vervangen voor vergelijkbare actieve leerscenario's.
Modeltraining
Modeltraining omvat twee taken: annotatie van het hoofdkader en annotatie van menselijke sleutelpunten. We introduceren ze allebei in deze sectie.
Annotatie van het hoofdbegrenzingsvak
Annotatie van het hoofdkader is een taak om de locatie van een kader van het menselijk hoofd in een afbeelding te voorspellen. Wij gebruiken een Aangepaste labels voor Amazon-herkenning model voor annotaties van het hoofdkader. Het volgende voorbeeld notebook biedt een stapsgewijze zelfstudie over het trainen van een Rekognition Custom Labels-model via SageMaker.
We moeten eerst de gegevens voorbereiden om met de training te kunnen beginnen. We genereren een manifestbestand voor de training en een manifestbestand voor de testdataset. Een manifestbestand bevat meerdere items, die elk voor een afbeelding zijn. Hier volgt een voorbeeld van het manifestbestand, dat het afbeeldingspad, de grootte en annotatiegegevens bevat:
Met behulp van de manifestbestanden kunnen we datasets laden naar een Rekognition Custom Labels-model voor training en testen. We hebben het model herhaald met verschillende hoeveelheden trainingsgegevens en getest op dezelfde 239 ongeziene afbeeldingen. Bij deze proef wordt de mAP_50 score steeg van 0.33 met 114 trainingsafbeeldingen naar 0.95 met 957 trainingsafbeeldingen. De volgende schermafbeelding toont de prestatiestatistieken van het uiteindelijke Rekognition Custom Labels-model, dat geweldige prestaties levert op het gebied van F1-score, precisie en herinnering.

We hebben het model verder getest op een achtergehouden dataset met 1,128 afbeeldingen. Het model voorspelt consistent nauwkeurige grenskadervoorspellingen op basis van de onzichtbare gegevens, wat een maximum oplevert mAP_50 van 94.9%. In het volgende voorbeeld ziet u een afbeelding met automatische annotaties en een hoofdkader.

Annotatie van belangrijke punten
De annotatie van belangrijke punten produceert locaties van belangrijke punten, waaronder ogen, oren, neus, mond, nek, schouders, ellebogen, polsen, heupen en enkels. Naast de locatievoorspelling is zichtbaarheid van elk punt nodig om te voorspellen in deze specifieke taak, waarvoor we een nieuwe methode ontwerpen.
Voor de annotatie van belangrijke punten gebruiken we a Yolo 8 Pose-model op SageMaker als het initiële model. We bereiden eerst de gegevens voor op training, inclusief het genereren van labelbestanden en een .yaml-configuratiebestand volgens de vereisten van Yolo. Nadat we de gegevens hebben voorbereid, trainen we het model en slaan we artefacten op, inclusief het modelgewichtenbestand. Met het getrainde modelgewichtbestand kunnen we de nieuwe afbeeldingen annoteren.
In de trainingsfase worden alle gelabelde punten met locaties, inclusief zichtbare punten en afgesloten punten, gebruikt voor training. Daarom biedt dit model standaard de locatie en het vertrouwen van de voorspelling. In de volgende afbeelding is een grote betrouwbaarheidsdrempel (hoofddrempel) van bijna 0.6 in staat de punten die zichtbaar of afgedekt zijn te verdelen over de punten die zich buiten het gezichtspunt van de camera bevinden. Afgesloten punten en zichtbare punten worden echter niet gescheiden door het vertrouwen, wat betekent dat het voorspelde vertrouwen niet bruikbaar is voor het voorspellen van de zichtbaarheid.

Om de zichtbaarheid te voorspellen, introduceren we een aanvullend model dat is getraind op de dataset en dat alleen zichtbare punten bevat, met uitsluiting van zowel afgesloten punten als buiten de gezichtspunten van de camera. De volgende afbeelding toont de verdeling van punten met verschillende zichtbaarheid. Zichtbare punten en andere punten kunnen in het aanvullende model worden gescheiden. We kunnen een drempel (extra drempel) in de buurt van 0.6 gebruiken om de zichtbare punten te krijgen. Door deze twee modellen te combineren, ontwerpen we een methode om de locatie en zichtbaarheid te voorspellen.

Een belangrijk punt wordt eerst voorspeld door het hoofdmodel met locatie en hoofdbetrouwbaarheid, daarna krijgen we de aanvullende betrouwbaarheidsvoorspelling uit het aanvullende model. De zichtbaarheid ervan wordt vervolgens als volgt geclassificeerd:
- Zichtbaar als het hoofdvertrouwen groter is dan de hoofddrempel, en het extra vertrouwen groter is dan de extra drempel
- Afgesloten, als het hoofdvertrouwen groter is dan de hoofddrempel, en het extra vertrouwen kleiner is dan of gelijk is aan de extra drempel
- Buiten de beoordeling van de camera, indien anders
Een voorbeeld van annotatie van belangrijke punten wordt gedemonstreerd in de volgende afbeelding, waarbij vaste markeringen zichtbare punten zijn en holle markeringen afgesloten punten. Buiten de camera's worden de beoordelingspunten niet weergegeven.

Op basis van de norm OKS definitie op de MS-COCO dataset, kan onze methode mAP_50 van 98.4% bereiken op de ongeziene testdataset. In termen van zichtbaarheid levert de methode een classificatienauwkeurigheid van 79.2% op voor dezelfde dataset.
Etikettering en herscholing van mensen
Hoewel de modellen uitstekende prestaties leveren op het gebied van testgegevens, zijn er nog steeds mogelijkheden om fouten te maken bij nieuwe gegevens uit de echte wereld. Menselijk labelen is het proces om deze fouten te corrigeren en de prestaties van het model te verbeteren door middel van herscholing. We hebben een beoordelingsfunctie ontworpen die de betrouwbaarheidswaarde combineert die uit de ML-modellen voortkomt voor de uitvoer van alle hoofdkaders of sleutelpunten. We gebruiken de eindscore om deze fouten en de daaruit voortvloeiende slecht gelabelde afbeeldingen te identificeren, die naar het menselijke labelproces moeten worden gestuurd.
Naast slecht gelabelde afbeeldingen wordt een klein deel van de afbeeldingen willekeurig gekozen voor menselijke labels. Deze door mensen gelabelde afbeeldingen worden toegevoegd aan de huidige versie van de trainingsset voor herscholing, waardoor de modelprestaties en de algehele nauwkeurigheid van annotaties worden verbeterd.
Bij de implementatie gebruiken we SageMaker Ground Truth voor de menselijke etikettering proces. SageMaker Ground Truth biedt een gebruiksvriendelijke en intuïtieve gebruikersinterface voor het labelen van gegevens. De volgende schermafbeelding demonstreert een SageMaker Ground Truth-labeltaak voor annotatie van het hoofdkader.

De volgende schermafbeelding demonstreert een SageMaker Ground Truth-labeltaak voor annotatie van belangrijke punten.

Kosten, snelheid en herbruikbaarheid
Kosten en snelheid zijn de belangrijkste voordelen van het gebruik van onze oplossing in vergelijking met menselijke etikettering, zoals weergegeven in de volgende tabellen. Deze tabellen gebruiken we om de kostenbesparingen en snelheidsversnellingen weer te geven. Met behulp van de versnelde GPU SageMaker-instantie ml.g4dn.xlarge zijn de training- en gevolgtrekkingskosten gedurende het hele leven op 100,000 afbeeldingen 99% lager dan de kosten van menselijke labeling, terwijl de snelheid 10-10,000 keer sneller is dan die van menselijke labeling, afhankelijk van de taak.
De eerste tabel geeft een overzicht van de kostenprestatiestatistieken.
| Model | mAP_50 gebaseerd op 1,128 testbeelden | Trainingskosten gebaseerd op 100,000 afbeeldingen | Inferentiekosten gebaseerd op 100,000 afbeeldingen | Kostenreductie vergeleken met menselijke annotatie | Inferentietijd gebaseerd op 100,000 afbeeldingen | Tijdversnelling vergeleken met menselijke annotatie |
| Herkenning hoofdbegrenzingsvak | 0.949 | $4 | $22 | 99% minder | 5.5 h | dagen |
| Yolo Belangrijke punten | 0.984 | $27.20 | * $ 10 | 99.9% minder | minuten | weken |
De volgende tabel bevat een overzicht van de prestatiestatistieken.
| Annotatie taak | mAP_50 (%) | Trainingskosten ($) | Inferentiekosten ($) | Inferentietijd |
| Hoofdbegrenzend vak | 94.9 | 4 | 22 | 5.5 uur kunt opladen |
| Sleutelpunten | 98.4 | 27 | 10 | 5 minuten |
Bovendien biedt onze oplossing herbruikbaarheid voor soortgelijke taken. Ontwikkelingen op het gebied van cameraperceptie voor andere systemen, zoals het geavanceerde bestuurdersassistentiesysteem (ADAS) en systemen in de cabine, kunnen ook onze oplossing overnemen.
Samengevat
In dit bericht hebben we laten zien hoe u een actieve leerpijplijn kunt bouwen voor automatische annotatie van afbeeldingen in de cabine met behulp van AWS-services. We demonstreren de kracht van ML, waarmee u het annotatieproces kunt automatiseren en versnellen, en de flexibiliteit van het raamwerk dat gebruikmaakt van modellen die worden ondersteund door AWS-services of zijn aangepast op SageMaker. Met Amazon S3, SageMaker, Lambda en SageMaker Ground Truth kunt u gegevensopslag, annotatie, training en implementatie stroomlijnen en herbruikbaarheid bereiken terwijl u de kosten aanzienlijk verlaagt. Door deze oplossing te implementeren kunnen autobedrijven flexibeler en kostenefficiënter worden door gebruik te maken van op ML gebaseerde geavanceerde analyses, zoals geautomatiseerde beeldannotatie.
Ga vandaag nog aan de slag en ontgrendel de kracht van AWS-diensten en machinaal leren voor uw gebruiksscenario's voor detectie in de auto!
Over de auteurs
 Yanxiang Yu is een toegepast wetenschapper bij het Amazon Genative AI Innovation Center. Met meer dan 9 jaar ervaring in het bouwen van AI- en machine learning-oplossingen voor industriële toepassingen, is hij gespecialiseerd in generatieve AI, computervisie en tijdreeksmodellering.
Yanxiang Yu is een toegepast wetenschapper bij het Amazon Genative AI Innovation Center. Met meer dan 9 jaar ervaring in het bouwen van AI- en machine learning-oplossingen voor industriële toepassingen, is hij gespecialiseerd in generatieve AI, computervisie en tijdreeksmodellering.
 Tianyi Mao is een Applied Scientist bij AWS, gevestigd in de omgeving van Chicago. Hij heeft meer dan 5 jaar ervaring in het bouwen van machine learning- en deep learning-oplossingen en richt zich op computervisie en versterkend leren met menselijke feedback. Hij werkt graag samen met klanten om hun uitdagingen te begrijpen en deze op te lossen door innovatieve oplossingen te creëren met behulp van AWS-services.
Tianyi Mao is een Applied Scientist bij AWS, gevestigd in de omgeving van Chicago. Hij heeft meer dan 5 jaar ervaring in het bouwen van machine learning- en deep learning-oplossingen en richt zich op computervisie en versterkend leren met menselijke feedback. Hij werkt graag samen met klanten om hun uitdagingen te begrijpen en deze op te lossen door innovatieve oplossingen te creëren met behulp van AWS-services.
 Yanru Xiao is een Applied Scientist bij het Amazon Generative AI Innovation Center, waar hij AI/ML-oplossingen bouwt voor de zakelijke problemen van klanten in de echte wereld. Hij heeft op verschillende gebieden gewerkt, waaronder productie, energie en landbouw. Yanru behaalde zijn Ph.D. in computerwetenschappen aan de Old Dominion University.
Yanru Xiao is een Applied Scientist bij het Amazon Generative AI Innovation Center, waar hij AI/ML-oplossingen bouwt voor de zakelijke problemen van klanten in de echte wereld. Hij heeft op verschillende gebieden gewerkt, waaronder productie, energie en landbouw. Yanru behaalde zijn Ph.D. in computerwetenschappen aan de Old Dominion University.
 Paul George is een ervaren productleider met meer dan 15 jaar ervaring in autotechnologieën. Hij is bedreven in het leiden van productmanagement-, strategie-, Go-to-Market- en systeemengineeringteams. Hij heeft wereldwijd verschillende nieuwe sensor- en perceptieproducten ontwikkeld en gelanceerd. Bij AWS leidt hij de strategie en go-to-market voor werklasten voor autonome voertuigen.
Paul George is een ervaren productleider met meer dan 15 jaar ervaring in autotechnologieën. Hij is bedreven in het leiden van productmanagement-, strategie-, Go-to-Market- en systeemengineeringteams. Hij heeft wereldwijd verschillende nieuwe sensor- en perceptieproducten ontwikkeld en gelanceerd. Bij AWS leidt hij de strategie en go-to-market voor werklasten voor autonome voertuigen.
 Caroline Chung is engineering manager bij Veoneer (overgenomen door Magna International). Ze heeft meer dan 14 jaar ervaring met het ontwikkelen van sensor- en perceptiesystemen. Momenteel leidt ze de voorontwikkelingsprogramma's voor interieurdetectie bij Magna International en geeft ze leiding aan een team van compute vision-ingenieurs en datawetenschappers.
Caroline Chung is engineering manager bij Veoneer (overgenomen door Magna International). Ze heeft meer dan 14 jaar ervaring met het ontwikkelen van sensor- en perceptiesystemen. Momenteel leidt ze de voorontwikkelingsprogramma's voor interieurdetectie bij Magna International en geeft ze leiding aan een team van compute vision-ingenieurs en datawetenschappers.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/build-an-active-learning-pipeline-for-automatic-annotation-of-images-with-aws-services/

