Amazon EMR biedt een beheerd Apache Hadoop-framework dat het gebruik eenvoudig, snel en kosteneffectief maakt Apache HBase. Apache HBase is een enorm schaalbare, gedistribueerde big data-opslag in het Apache Hadoop-ecosysteem. Het is een open-source, niet-relationele database met versiebeheer die bovenop het Apache Hadoop Distributed File System (HDFS) draait. Het is gebouwd voor willekeurige, strikt consistente, real-time toegang voor tabellen met miljarden rijen en miljoenen kolommen. Het monitoren van HBase-clusters is van cruciaal belang om stabiliteits- en prestatieknelpunten te identificeren en deze proactief te ondervangen. In dit bericht bespreken we hoe u kunt gebruiken Amazon beheerde service voor Prometheus en Amazon beheerde Grafana om HBase-statistieken te bewaken, te waarschuwen en te visualiseren.
HBase heeft ingebouwde ondersteuning voor het exporteren van metrische gegevens via het Hadoop metrische subsysteem naar bestanden of Ganglia of via JMX. U kunt beide gebruiken AWS Distro voor OpenTelemetry or Prometheus JMX-exporteurs om statistieken te verzamelen die worden weergegeven door HBase. In dit bericht laten we zien hoe u Prometheus-exporteurs gebruikt. Deze exporteurs gedragen zich als kleine webservers die interne applicatiestatistieken converteren naar Prometheus-indeling en deze aanleveren /metrics pad. Een Prometheus-server die draait op een Amazon Elastic Compute-cloud (Amazon EC2) instantie verzamelt deze statistieken en op afstand schrijft naar een Amazon Managed Service voor Prometheus-werkruimte. Vervolgens gebruiken we Amazon Managed Grafana om dashboards te maken en deze statistieken te bekijken met behulp van een Amazon Managed Service for Prometheus-werkruimte als gegevensbron.
Deze oplossing kan worden uitgebreid naar andere big data-platforms zoals Apache Spark en Apache Presto die ook JMX gebruiken om hun statistieken bloot te leggen.
Overzicht oplossingen
Het volgende diagram illustreert onze oplossingsarchitectuur.
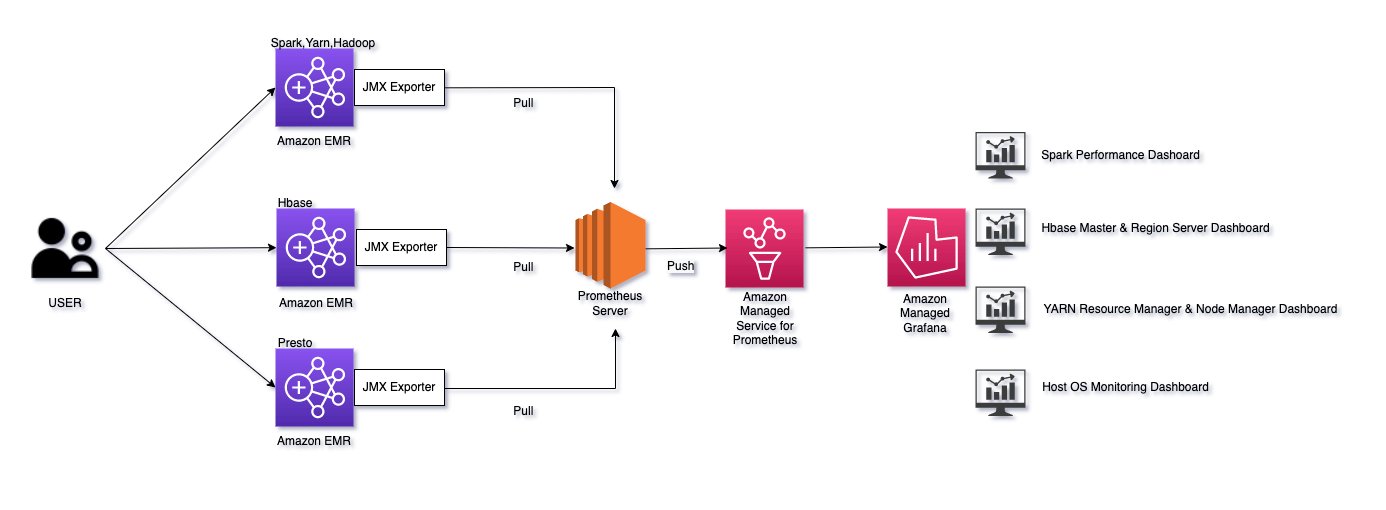
Dit bericht maakt gebruik van een AWS CloudFormatie sjabloon om onderstaande acties uit te voeren:
- Installeer een open-source Prometheus-server op een EC2-instantie.
- Maak passend AWS Identiteits- en toegangsbeheer (IAM) rollen en beveiligingsgroep voor de EC2-instantie waarop de Prometheus-server draait.
- Maak een EMR-cluster met een HBase op Amazon S3-configuratie.
- Installeer JMX-exporteurs op alle EMR-knooppunten.
- Maak extra beveiligingsgroepen voor de EMR-master- en werkknooppunten om verbinding te maken met de Prometheus-server die draait op de EC2-instantie.
- Maak een werkruimte in Amazon Managed Service voor Prometheus.
Voorwaarden
Zorg ervoor dat u over de volgende vereisten beschikt om deze oplossing te implementeren:
Implementeer de CloudFormation-sjabloon
Implementeer de CloudFormation-sjabloon in de us-east-1 Regio:
![]()
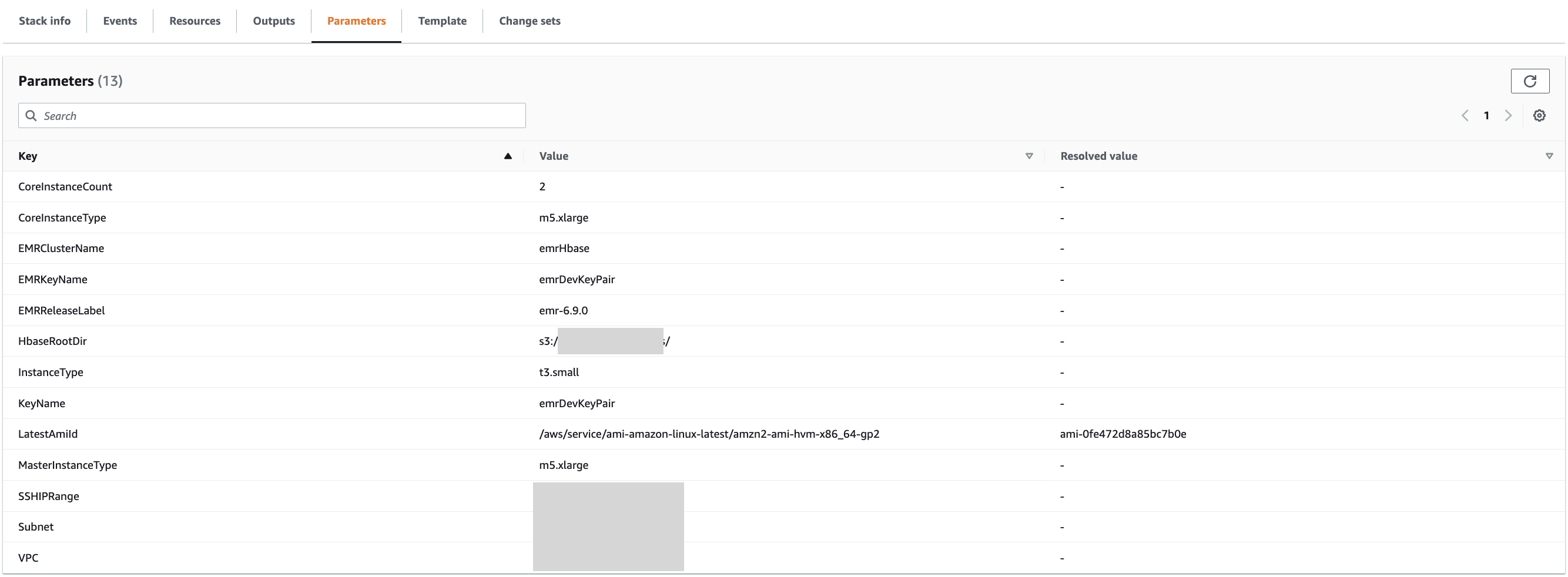
Het duurt 15-20 minuten voordat de sjabloon is voltooid. De sjabloon vereist de volgende velden:
- Stapelnaam – Voer een naam in voor de stapel
- VPC – Kies een bestaande VPC
- subnet – Kies een bestaand subnet
- EMRClusterNaam - Gebruik
EMRHBase - HBaseRootDir – Geef een nieuwe HBase-hoofdmap op (bijvoorbeeld
s3://hbase-root-dir/). - MasterInstanceType – Gebruik m5x.groot
- CoreInstanceType – Gebruik m5x.groot
- CoreInstanceCount – Voer 2 in
- SSHIP-bereik - Gebruik
<your ip address>/32(je kan gaan naar https://checkip.amazonaws.com/ om uw IP-adres te controleren) - EMRKeyNaam – Kies een sleutelpaar voor het EPD-cluster
- EMRRleaseLabel - Gebruik
emr-6.9.0 - instantietype – Gebruik het instantietype EC2 voor het installeren van de Prometheus-server
Schakel schrijven op afstand in op de Prometheus-server
De Prometheus-server draait op een EC2-instantie. U vindt de hostnaam van de instantie in de CloudFormation-stack Uitgangen tabblad voor sleutel PrometheusServerPublicDNSName.
- SSH naar de EC2-instantie met behulp van het sleutelpaar:
- Kopieer de waarde voor Eindpunt – URL voor schrijven op afstand van de Amazon Managed Service voor Prometheus-werkruimteconsole.

- Edit
remote_write urlin/etc/prometheus/conf/prometheus.yml:
Het zou eruit moeten zien als de volgende code:

- Nu moeten we de Prometheus-server opnieuw opstarten om de wijzigingen op te pikken:
Schakel Amazon Managed Grafana in om te lezen vanuit een Amazon Managed Service for Prometheus-werkruimte
We moeten de Amazon Managed Prometheus-werkruimte toevoegen als gegevensbron in Amazon Managed Grafana. Je kunt direct doorgaan naar stap 3 als je al een bestaande Amazon Managed Grafana-werkruimte hebt en deze wilt gebruiken voor HBase-statistieken.
- Laten we eerst een werkruimte maken op Amazon Managed Grafana. U kunt de appendix volgen om een werkruimte te maken met behulp van de Amazon Managed Grafana-console of de volgende API uitvoeren vanaf uw terminal (geef uw rol-ARN op):
- Kies op de Amazon Managed Grafana-console Configureer gebruikers en selecteer een gebruiker die u wilt laten inloggen op Grafana-dashboards.
Zorg ervoor dat uw IAM Identity Center-gebruikerstype admin is. Dit hebben we nodig om dashboards te maken. U kunt de rol van kijker toewijzen aan alle andere gebruikers.


- Meld u aan bij de door Amazon beheerde Grafana-werkruimte-URL met uw beheerdersreferenties.
- Kies AWS-gegevensbronnen in het navigatievenster.

- Voor Service, kiezen Amazon beheerde service voor Prometheus.

- Voor Regio's, kiezen VS-Oosten (N. Virginia).
Maak een HBase-dashboard
Grafana labs heeft een open source dashboard waar je gebruik van kunt maken. U kunt bijvoorbeeld de richtlijnen van het volgende volgen HBase-dashboard. Begin met het maken van uw dashboard en kies de importoptie. Geef de URL van het dashboard op of voer in 12722 En kies Laden. Zorg ervoor dat uw Prometheus-werkruimte is geselecteerd op de volgende pagina. U zou HBase-statistieken op het dashboard moeten zien verschijnen.

Belangrijke HBase-statistieken om te bewaken
HBase heeft een breed scala aan statistieken voor HMaster en RegionServer. Hieronder volgen enkele belangrijke statistieken waarmee u rekening moet houden.
| HMASTER | Metrische naam | Metrische beschrijving |
| . | hadoop_HBase_numregionservers | Aantal live regioservers |
| . | hadoop_HBase_numdeadregionservers | Aantal dode regioservers |
| . | hadoop_HBase_ritcount | Aantal regio's in transitie |
| . | hadoop_HBase_ritcountoverthreshold | Aantal regio's dat langer dan een drempeltijd in transitie is geweest (standaard: 60 seconden) |
| . | hadoop_HBase_ritduration_99th_percentile | Maximale tijd die 99% van de regio's nodig heeft om in overgangstoestand te blijven |
| REGIOSERVER | Metrische naam | Metrische beschrijving |
| . | hadoop_HBase_regioncount | Aantal regio's dat wordt gehost door de regioserver |
| . | hadoop_HBase_storefilecount | Aantal winkelbestanden dat momenteel wordt beheerd door de regioserver |
| . | hadoop_HBase_storefilesize | Geaggregeerde grootte van de winkelbestanden |
| . | hadoop_HBase_hlogfilecount | Aantal vooruitschrijflogboeken dat nog niet is gearchiveerd |
| . | hadoop_HBase_hlogfilesize | Grootte van alle vooruitschrijflogbestanden |
| . | hadoop_HBase_totalrequestcount | Totaal aantal ontvangen verzoeken |
| . | hadoop_HBase_readrequestcount | Aantal ontvangen leesverzoeken |
| . | hadoop_HBase_writerequestcount | Aantal ontvangen schrijfverzoeken |
| . | hadoop_HBase_numopenconnections | Aantal open verbindingen op de RPC-laag |
| . | hadoop_HBase_numactivehandler | Aantal RPC-handlers die actief verzoeken verwerken |
| Geheugenopslag | . | . |
| . | hadoop_HBase_memstoresize | Totale memstore-geheugengrootte van de regioserver |
| . | hadoop_HBase_flushwachtrijlengte | Huidige diepte van de memstore-spoelwachtrij (als deze toeneemt, lopen we achter met het opruimen van memstores naar Amazon S3) |
| . | hadoop_HBase_flushtime_99th_percentile | 99e percentiel latentie voor spoelen |
| . | hadoop_HBase_updatesblockedtime | Aantal milliseconden updates zijn geblokkeerd, zodat de memstore kan worden leeggemaakt |
| Cache blokkeren | . | . |
| . | hadoop_HBase_blockcachesize | Blokcachegrootte |
| . | hadoop_HBase_blockcachefreesize | Blokkeer cache vrije grootte |
| . | hadoop_HBase_blockcachehitcount | Aantal blokcachetreffers |
| . | hadoop_HBase_blockcachemisscount | Aantal gemiste blokcaches |
| . | hadoop_HBase_blockcacheexpresshitpercent | Percentage van de tijd dat verzoeken met ingeschakelde cache de cache raken |
| . | hadoop_HBase_blockcachecounthitpercent | Percentage blokcachetreffers |
| . | hadoop_HBase_blockcacheevictioncount | Aantal blokcacheverwijderingen op de regioserver |
| . | hadoop_HBase_l2cachehitratio | Lokale schijfgebaseerde bucketcache-hitratio |
| . | hadoop_HBase_l2cachemissratio | Bucket cache miss-ratio |
| Verdichting | . | . |
| . | hadoop_HBase_majorcompactiontime_99th_percentile | Tijd in milliseconden voor grote verdichting |
| . | hadoop_HBase_compactiontime_99th_percentile | Tijd in milliseconden voor kleine verdichting |
| . | hadoop_HBase_compactionwachtrijlengte | Huidige diepte van de wachtrij voor verdichtingsverzoeken (indien deze toeneemt, lopen we achter met verdichting van opslagbestanden) |
| . | spoel wachtrij lengte | Aantal spoelbewerkingen dat wacht op verwerking in de regioserver (een hoger getal geeft aan dat spoelbewerkingen traag zijn) |
| IPC-wachtrijen | . | . |
| . | hadoop_HBase_queuesize | Totale gegevensomvang van alle RPC-oproepen in de RPC-wachtrijen op de regioserver |
| . | hadoop_HBase_numcallsingeneralqueue | Aantal RPC-oproepen in de algemene verwerkingswachtrij op de regioserver |
| . | hadoop_HBase_processcalltime_99th_percentile | 99e percentiellatentie voor RPC-oproepen die moeten worden verwerkt in de regioserver |
| . | hadoop_HBase_queuecalltime_99th_percentile | 99e percentiellatentie voor RPC-oproepen om in de RPC-wachtrij op de regioserver te blijven |
| JVM en GC | . | . |
| . | hadoop_HBase_memheapusedm | Hoop gebruikt |
| . | hadoop_HBase_memheapmaxm | Totale hoop |
| . | hadoop_HBase_pausetimewithgc_99th_percentile | Pauzetijd in milliseconden |
| . | hadoop_HBase_gccount | Afvalophaaltelling |
| . | hadoop_HBase_gctimemillis | Tijd besteed aan het ophalen van afval, in milliseconden |
| latencies | . | . |
| . | HBase.regioserver. _ | Operatie latenties, waar is toevoegen, verwijderen, muteren, ophalen, opnieuw afspelen of verhogen, en is min, max, gemiddelde, mediaan, 75e_percentiel, 95e_percentiel of 99e_percentiel |
| . | HBase.regioserver.traag Graaf | Aantal operaties waarvan we dachten dat ze traag waren, waar is een van de voorgaande lijst |
| Bulklading | . | . |
| . | Bulklading_99e_percentiel | hadoop_HBase_bulkload_99th_percentile |
| I / O | . | . |
| . | FsWriteTime_99e_percentiel | hadoop_HBase_fswritetime_99th_percentile |
| . | FsReadTime_99th_percentile | hadoop_HBase_fsreadtime_99th_percentile |
| Uitzonderingen | . | . |
| . | uitzonderingen.RegionTooBusyException | . |
| . | uitzonderingen.callQueueTooBig | . |
| . | uitzonderingen.NotServingRegionException | . |
Overwegingen en beperkingen
Let op het volgende bij het gebruik van deze oplossing:
- U kunt instellen meldingen op Amazon Managed Service voor Prometheus en visualiseer ze in Amazon beheerde Grafana.
- Deze architectuur kan eenvoudig worden uitgebreid met andere open-source frameworks zoals Apache Spark, Apache Presto en Apache Hive.
- Raadpleeg de prijsdetails voor Amazon beheerde service voor Prometheus en Amazon beheerde Grafana.
- Deze scripts zijn alleen bedoeld als richtlijn en zijn niet gereed voor productie-implementaties. Zorg ervoor dat u grondige tests uitvoert.
Opruimen
Om lopende kosten te voorkomen, verwijdert u de CloudFormation-stack en werkruimten die zijn gemaakt in Amazon Managed Grafana en Amazon Managed Service for Prometheus.
Conclusie
In dit bericht heb je geleerd hoe je EMR HBase-clusters kunt monitoren en dashboards kunt opzetten om belangrijke statistieken te visualiseren. Deze oplossing kan dienen als een uniform monitoringplatform voor meerdere EMR-clusters en andere toepassingen. Zie voor meer informatie over EMR HBase Gids vrijgeven en HBase migratie whitepaper.
Bijlage
Voer de volgende stappen uit om een werkruimte te maken op Amazon Managed Grafana:
- Log in op de Amazon Managed Grafana-console en kies Werkruimte maken.

- Voor authenticatie toegangselecteer AWS IAM Identiteitscentrum.
Als u IAM Identity Center niet hebt ingeschakeld, raadpleegt u IAM Identity Center inschakelen.
- Selecteer optioneel om Prometheus-waarschuwingen in uw Grafana-werkruimte te bekijken Schakel Grafana-waarschuwing in.

- Selecteer op de volgende pagina Amazon beheerde service voor Prometheus als de gegevensbron.
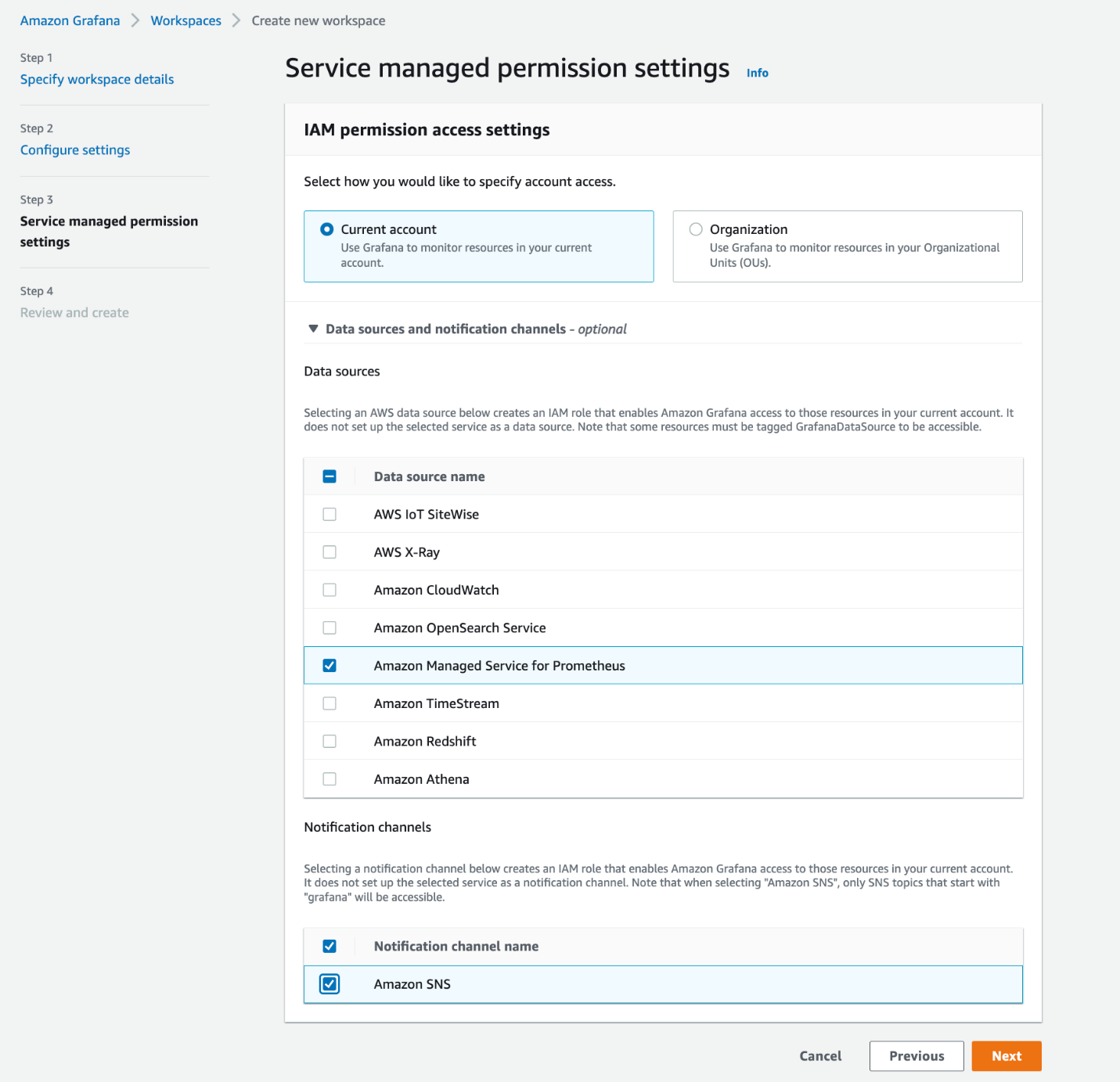
- Nadat de werkruimte is gemaakt, wijst u gebruikers toe voor toegang tot Amazon Managed Grafana.
- Wijs bij een eerste installatie beheerdersrechten toe aan de gebruiker.
U kunt andere gebruikers toevoegen met alleen kijkerstoegang.
Zorg ervoor dat u zich kunt aanmelden bij de Grafana-werkruimte-URL met uw IAM Identity Center-gebruikersreferenties.
Over de auteur
 Anubhav Awasthi is Sr. Big Data Specialist Solutions Architect bij AWS. Hij werkt samen met klanten om architecturale begeleiding te bieden voor het uitvoeren van analyseoplossingen op Amazon EMR, Amazon Athena, AWS Glue en AWS Lake Formation.
Anubhav Awasthi is Sr. Big Data Specialist Solutions Architect bij AWS. Hij werkt samen met klanten om architecturale begeleiding te bieden voor het uitvoeren van analyseoplossingen op Amazon EMR, Amazon Athena, AWS Glue en AWS Lake Formation.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/monitor-apache-hbase-on-amazon-emr-using-amazon-managed-service-for-prometheus-and-amazon-managed-grafana/

