Inhoudsopgave
Introductie
Leren is het verwerven en beheersen van kennis over een domein door ervaring. Het is niet alleen iets menselijks, maar hoort ook bij machines. De computerwereld is drastisch getransformeerd van een ineffectief mechanisch systeem naar een gigantische geautomatiseerde techniek met de komst van kunstmatige intelligentie. Data is de brandstof die deze technologie aandrijft; de recente beschikbaarheid van enorme hoeveelheden gegevens heeft het tot het modewoord in technologie gemaakt. Kunstmatige intelligentie, in zijn eenvoudigste vorm, is het simuleren van menselijke intelligentie in machines voor betere besluitvorming.
Kunstmatige intelligentie (AI) is een tak van de informatica die zich bezighoudt met de simulatie van menselijke intelligentieprocessen door machines. De term 'cognitive computing' wordt ook gebruikt om naar AI te verwijzen, aangezien computermodellen worden ingezet om het menselijke denkproces te simuleren. Elk apparaat dat zijn huidige omgeving herkent en zijn doel optimaliseert, zou AI-enabled zijn. AI kan grofweg worden gecategoriseerd als zwak of sterk. De systemen die zijn ontworpen en getraind om een bepaalde taak uit te voeren, staan bekend als zwakke AI, net als de spraakgestuurde systemen. Ze kunnen een vraag beantwoorden of een programmaopdracht uitvoeren, maar kunnen niet werken zonder menselijke tussenkomst. Sterke AI is een gegeneraliseerd menselijk cognitief vermogen. Het kan taken oplossen en oplossingen vinden zonder menselijke tussenkomst. Zelfrijdende auto's zijn een voorbeeld van sterke AI die Computer Vision, Image Recognition en Deep Learning gebruikt om een voertuig te besturen. AI heeft zijn intrede gedaan in verschillende sectoren waar zowel bedrijven als consumenten baat bij hebben. Gezondheidszorg, onderwijs, financiën, wetgeving en productie zijn er maar een paar. Veel technologieën zoals automatisering, machine learning, machine vision, natuurlijke taalverwerking en robotica bevatten AI.
De drastische toename van het routinewerk van de mens vraagt om automatisering. Precisie en nauwkeurigheid zijn de volgende rijtermen die de uitvinding van een intelligent systeem vereisen in tegenstelling tot de handmatige systemen. Besluitvorming en patroonherkenning zijn de dwingende taken die aandringen op automatisering, omdat ze onbevooroordeelde beslissende resultaten vereisen die kunnen worden verkregen door intensief te leren over de historische gegevens van het betreffende domein. Dit kan worden bereikt door middel van machine learning, waarbij van het systeem dat voorspellingen doet, wordt verlangd dat het een enorme training op de gegevens uit het verleden ondergaat om in de toekomst nauwkeurige voorspellingen te doen. Enkele van de populaire toepassingen van ML in het dagelijks leven zijn onder andere schattingen van reistijden door snellere routes aan te bieden, schattingen van de optimale routes en de prijs per rit. De toepassing ervan is te zien in e-mailintelligentie die spamfilters uitvoert, e-mailclassificaties uitvoert en slimme antwoorden geeft. Op het gebied van bankieren en persoonlijke financiën wordt het gebruikt om kredietbeslissingen te nemen en frauduleuze transacties te voorkomen. Het speelt een belangrijke rol in de gezondheidszorg en diagnose, sociale netwerken en persoonlijke assistenten zoals Siri en Cortana. De lijst is bijna eindeloos en wordt elke dag langer naarmate meer en meer velden AI en ML gebruiken voor hun dagelijkse activiteiten.
Echte kunstmatige intelligentie duurt nog tientallen jaren, maar we hebben tegenwoordig een type AI dat Machine Learning wordt genoemd. AI, ook wel bekend als cognitief computergebruik, is gesplitst in twee verwante technieken, Machine Learning en Deep Learning. Machine learning heeft een aanzienlijke plaats ingenomen in het onderzoek naar het maken van briljante en geautomatiseerde machines. Ze kunnen patronen in gegevens herkennen zonder expliciet geprogrammeerd te zijn. Machine learning biedt de tools en technologieën om te leren van de data en, nog belangrijker, van de veranderingen in de data. Machine learning-algoritmen hebben hun plaats gevonden in veel toepassingen; van de apps die bepalen welk eten je kiest tot degene die beslissen over je volgende film om te kijken, inclusief de chatbots die je salonafspraken boeken, zijn een paar van die verbluffende Machine Learning-applicaties die de informatietechnologie-industrie op zijn kop zetten. Zijn tegenhanger, de Deep Learning-techniek, heeft zijn functionaliteit geïnspireerd op de menselijke hersencellen en wint aan populariteit. Diep leren is een subset van machine learning die op een incrementele manier leert, van de categorieën op laag niveau naar categorieën op hoog niveau. Deep Learning-algoritmen leveren nauwkeurigere resultaten op wanneer ze worden getraind met zeer grote hoeveelheden gegevens. Problemen worden opgelost met behulp van een end-to-end-mode, waardoor ze de naam Magic Box / Black Box krijgen. Hun prestaties worden geoptimaliseerd met behulp van geavanceerde machines. De functionaliteit van Deep Learning is geïnspireerd op de menselijke hersencellen en wint aan populariteit. Diep leren is eigenlijk een subset van machinaal leren dat op een incrementele manier leert van de categorieën op laag niveau naar categorieën op hoog niveau. Deep Learning heeft de voorkeur in toepassingen zoals zelfrijdende auto's, pixelrestauraties en natuurlijke taalverwerking. Deze toepassingen verbazen ons simpelweg, maar de realiteit is dat de absolute krachten van deze technologieën nog moeten worden onthuld. Dit artikel geeft een overzicht van deze technologieën en vat de theorie erachter samen met hun toepassingen.
Wat is machinaal leren?
Computers kunnen alleen doen waarvoor ze geprogrammeerd zijn. Dit was het verhaal van het verleden totdat computers bewerkingen kunnen uitvoeren en beslissingen kunnen nemen zoals mensen. Machine Learning, een subset van AI, is de techniek waarmee computers mensen kunnen nabootsen. De term Machine Learning is uitgevonden door Arthur Samuel in het jaar 1952, toen hij het eerste computerprogramma ontwierp dat kon leren terwijl het werd uitgevoerd. Arthur Samuel was een pionier op twee meest gewilde gebieden, kunstmatige intelligentie en computergaming. Volgens hem is machine learning het "studiegebied dat computers de mogelijkheid geeft om te leren zonder expliciet geprogrammeerd te zijn".
In gewone termen is machine learning een subset van kunstmatige intelligentie waarmee software zelf kan leren van de ervaringen uit het verleden en die kennis kan gebruiken om hun prestaties in de toekomst te verbeteren zonder expliciet te worden geprogrammeerd. Overweeg een voorbeeld om de verschillende bloemen te identificeren op basis van verschillende attributen zoals kleur, vorm, geur, bloembladgrootte enz. Bij traditionele programmering zijn alle taken hard gecodeerd met enkele regels die moeten worden gevolgd in het identificatieproces. Bij machine learning zou deze taak eenvoudig kunnen worden volbracht door de machine te laten leren zonder te worden geprogrammeerd. Machines leren van de gegevens die ze krijgen. Data is de brandstof die het leerproces aandrijft. Hoewel de term machine learning al in 1959 werd geïntroduceerd, is de brandstof die deze technologie aandrijft pas nu beschikbaar. Machine learning vereist enorme hoeveelheden gegevens en rekenkracht die ooit een droom was en nu tot onze beschikking staat.
Traditioneel programmeren versus machinaal leren:
Wanneer computers worden gebruikt om sommige taken uit te voeren in plaats van mensen, moeten ze worden voorzien van enkele instructies, een computerprogramma genaamd. Traditionele programmering wordt al meer dan een eeuw toegepast. Ze begonnen in het midden van de 1800e eeuw, waar een computerprogramma de gegevens gebruikt en op een computersysteem draait om de uitvoer te genereren. Een traditioneel geprogrammeerde bedrijfsanalyse zal bijvoorbeeld de bedrijfsgegevens en de regels (computerprogramma) als invoer nemen en de bedrijfsinzichten uitvoeren door de regels op de gegevens toe te passen.
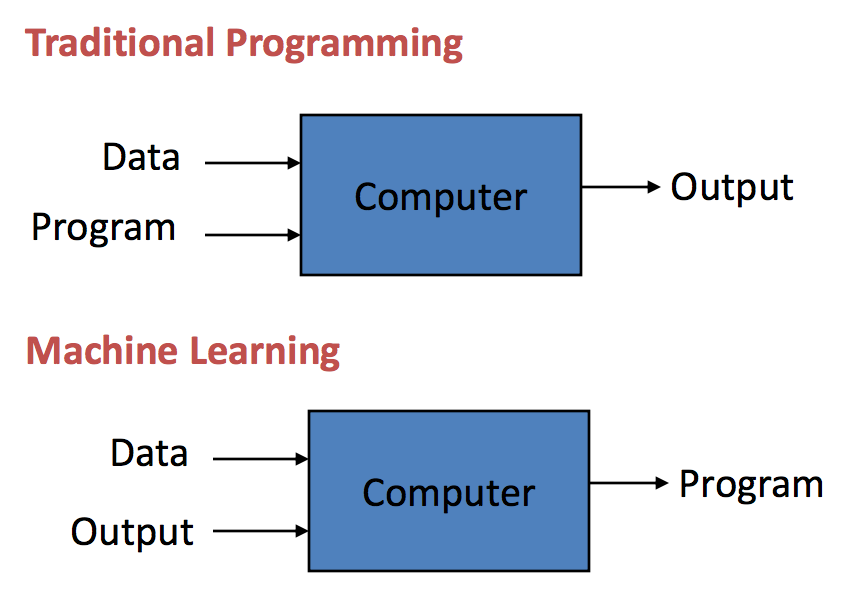
Integendeel, bij Machine learning worden de data en de outputs, ook wel labels genoemd, als input geleverd aan een algoritme dat met een model komt, als output.
Als de demografische gegevens en transacties van de klant bijvoorbeeld als invoergegevens worden ingevoerd en de klantverloopcijfers uit het verleden als uitvoergegevens (labels) worden gebruikt, kan een algoritme een model bouwen dat kan voorspellen of een klant zal afhaken of niet. Dat model wordt een voorspellend model genoemd. Dergelijke machine learning-modellen kunnen worden gebruikt om elke situatie te voorspellen die wordt voorzien van de nodige historische gegevens. Technieken voor machinaal leren zijn erg waardevol omdat ze de computers in staat stellen nieuwe regels te leren in een hoogdimensionale complexe ruimte, die moeilijker te begrijpen zijn voor de mens.
Behoefte aan machinaal leren:
Machine learning bestaat al een tijdje, maar de mogelijkheid om wiskundige berekeningen automatisch en snel toe te passen op enorme hoeveelheden data wint nu aan kracht. Machine Learning kan worden gebruikt om veel taken te automatiseren, met name taken die alleen kunnen worden uitgevoerd door mensen met hun ingeteelde intelligentie. Deze intelligentie kan via machine learning worden gerepliceerd naar machines.
Machine learning heeft zijn plaats gevonden in toepassingen zoals zelfrijdende auto's, online aanbevelingsengines zoals vriendenaanbevelingen op Facebook en suggesties van Amazon, en bij het opsporen van cyberfraude. Machine learning is nodig voor problemen zoals beeld- en spraakherkenning, taalvertaling en verkoopprognoses, waarbij we de vaste regels die voor het probleem moeten worden gevolgd niet kunnen opschrijven.
Activiteiten zoals besluitvorming, prognoses, voorspellingen doen, waarschuwingen geven over afwijkingen, verborgen trends of relaties blootleggen, vereisen diverse, veel ongestructureerde en real-time gegevens van verschillende artefacten die alleen het beste kunnen worden afgehandeld door het machine learning-paradigma.
Geschiedenis van machinaal leren
In dit gedeelte wordt ingegaan op de ontwikkeling van machine learning door de jaren heen. Vandaag zijn we getuige van een aantal verbazingwekkende toepassingen zoals zelfrijdende auto's, natuurlijke taalverwerking en gezichtsherkenningssystemen die gebruik maken van ML-technieken voor hun verwerking. Dit alles begon in het jaar 1943, toen Warren McCulloch, een neurofysioloog, samen met een wiskundige genaamd Walter Pitts een artikel schreef dat een licht wierp op neuronen en de werking ervan. Ze creëerden een model met elektrische circuits en zo werd een neuraal netwerk geboren.
De beroemde "Turing-test" werd in 1950 gemaakt door Alan Turing, die zou nagaan of de computers echte intelligentie hadden. Het moet een mens laten geloven dat het geen computer is, maar een mens, om de test te doorstaan. Arthur Samuel ontwikkelde het eerste computerprogramma dat kon leren terwijl het het damspel speelde in het jaar 1952. Het eerste neurale netwerk, het perceptron genaamd, werd ontworpen door Frank Rosenblatt in het jaar 1957.
De grote verschuiving vond plaats in de jaren 1990, toen machine learning veranderde van een kennisgestuurde techniek naar een datagestuurde techniek vanwege de beschikbaarheid van de enorme hoeveelheden data. IBM's Deep Blue, ontwikkeld in 1997, was de eerste machine die de wereldkampioen schaak versloeg. Bedrijven hebben ingezien dat het potentieel voor complexe berekeningen kan worden vergroot door machine learning. Enkele van de nieuwste projecten zijn: Google Brain, ontwikkeld in 2012, was een diep neuraal netwerk dat zich richtte op patroonherkenning in afbeeldingen en video's. Het werd later gebruikt om objecten in YouTube-video's te detecteren. In 2014 creëerde Face Book Deep Face, dat mensen kan herkennen net zoals mensen dat doen. In 2014 creëerde Deep Mind een computerprogramma genaamd Alpha Go, een bordspel dat een professionele Go-speler versloeg. Vanwege zijn complexiteit zou het spel een zeer uitdagend, maar toch klassiek spel voor kunstmatige intelligentie zijn. Wetenschappers Stephen Hawking en Stuart Russel hebben het gevoel dat als AI de kracht krijgt om zichzelf steeds sneller te herontwerpen, een onverslaanbare "intelligentie-explosie" kan leiden tot het uitsterven van de mens. Musk karakteriseert AI als de "grootste existentiële bedreiging" van de mensheid. Open AI is een organisatie die in 2015 door Elon Musk is opgericht om veilige en vriendelijke AI te ontwikkelen die de mensheid ten goede kan komen. Recentelijk zijn enkele van de doorbraakgebieden in AI Computer Vision, Natural Language Processing en Reinforcement Learning.
Kenmerken van machinaal leren
In de afgelopen jaren is het technologiedomein getuige geweest van een immens populair onderwerp genaamd Machine Learning. Bijna elk bedrijf probeert deze technologie te omarmen. Bedrijven hebben de manier waarop ze zaken doen getransformeerd en de toekomst lijkt rooskleuriger en veelbelovender dankzij de impact van machine learning. Enkele van de belangrijkste kenmerken van machine learning kunnen zijn:
Automatisering: het vermogen om repetitieve taken te automatiseren en zo de bedrijfsproductiviteit te verhogen, is de grootste sleutelfactor van machine learning. ML-aangedreven papierwerk en e-mailautomatisering worden door veel organisaties gebruikt. In de financiële sector zorgt ML ervoor dat de boekhouding sneller en nauwkeuriger verloopt en snel en gemakkelijk bruikbare inzichten worden verkregen. E-mailclassificatie is een klassiek voorbeeld van automatisering, waarbij spam-e-mails automatisch door Gmail worden geclassificeerd in de spammap.
Verbeterde klantbetrokkenheid: Het bieden van een op maat gemaakte ervaring voor klanten en het bieden van uitstekende service zijn erg belangrijk voor elk bedrijf om hun merkloyaliteit te promoten en langdurige klantrelaties te behouden. Deze kunnen worden bereikt door middel van ML. Het creëren van aanbevelingsengines die perfect zijn afgestemd op de behoeften van de klant en het creëren van chatbots die menselijke gesprekken soepel kunnen simuleren door de nuances van gesprekken te begrijpen en vragen op de juiste manier te beantwoorden. Een AVA van luchtvaartmaatschappij Air Asia is een voorbeeld van zo'n chatbot. Het is een virtuele assistent die wordt aangedreven door AI en direct reageert op vragen van klanten. Het kan 11 menselijke talen nabootsen en maakt gebruik van natuurlijke taalbegriptechniek.
Geautomatiseerde gegevensvisualisatie: we zijn ons ervan bewust dat er enorme hoeveelheden gegevens worden gegenereerd door bedrijven, machines en individuen. Bedrijven genereren gegevens van transacties, e-commerce, medische dossiers, financiële systemen enz. Machines genereren ook enorme hoeveelheden gegevens van satellieten, sensoren, camera's, computerlogbestanden, IoT-systemen, camera's enz. Individuen genereren enorme gegevens van sociale netwerken, e-mails , blogs, internet enz. De relaties tussen de gegevens kunnen eenvoudig worden geïdentificeerd door middel van visualisaties. Het identificeren van patronen en trends in gegevens kan eenvoudig worden gedaan door middel van een visuele samenvatting van informatie in plaats van duizenden rijen in een spreadsheet te doorlopen. Bedrijven kunnen waardevolle nieuwe inzichten verwerven via datavisualisaties om de productiviteit in hun domein te verhogen via gebruiksvriendelijke geautomatiseerde datavisualisatieplatforms die worden aangeboden door machine learning-applicaties. Auto Viz is zo'n platform dat geautomatiseerde tolgelden voor gegevensvisualisatie biedt om de productiviteit in bedrijven te verbeteren.
Nauwkeurige data-analyse: Het doel van data-analyse is om antwoorden te vinden op specifieke vragen die business analytics en business intelligence proberen te identificeren. Traditionele data-analyse omvat veel methoden van vallen en opstaan, die absoluut onmogelijk worden bij het werken met grote hoeveelheden zowel gestructureerde als ongestructureerde data. Data-analyse is een zeer belangrijke taak die enorm veel tijd kost. Machine learning komt goed van pas door veel algoritmen en datagedreven modellen aan te bieden die perfect met realtime data om kunnen gaan.
Business intelligence: Business intelligence verwijst naar gestroomlijnde verzameloperaties; verwerking en analyse van gegevens in een organisatie. Business intelligence-toepassingen kunnen, wanneer ze worden aangedreven door AI, nieuwe gegevens nauwkeurig onderzoeken en de patronen en trends herkennen die relevant zijn voor de organisatie. Wanneer machine learning-functies worden gecombineerd met big data-analyse, kan dit bedrijven helpen om oplossingen te vinden voor de problemen die de bedrijven helpen groeien en meer winst maken. ML is een van de krachtigste technologieën geworden om de bedrijfsvoering te vergroten, van e-commerce tot de financiële sector tot de gezondheidszorg.
Talen voor machinaal leren
Er zijn veel programmeertalen voor machine learning. De keuze van de taal en het gewenste programmeerniveau zijn afhankelijk van hoe machine learning in een applicatie wordt gebruikt. De basisprincipes van programmeren, logica, datastructuren, algoritmen en geheugenbeheer zijn nodig om machine learning-technieken te implementeren voor alle zakelijke toepassingen. Met deze kennis kan men direct machine learning-modellen implementeren met behulp van de verschillende ingebouwde bibliotheken die door veel programmeertalen worden aangeboden. Er zijn ook veel grafische en scripttalen zoals Orange, Big ML, Weka en andere waarmee ML-algoritmen kunnen worden geïmplementeerd zonder hardcoded te zijn; alles wat je nodig hebt is slechts een fundamentele kennis over programmeren.
Er is geen enkele programmeertaal die als de 'beste' voor machine learning kan worden bestempeld. Elk van hen is goed waar ze worden toegepast. Sommigen geven er misschien de voorkeur aan om Python te gebruiken voor NLP-toepassingen, terwijl anderen misschien de voorkeur geven aan R of Python voor toepassingen voor sentimentanalyse en sommigen gebruiken Java voor ML-toepassingen met betrekking tot beveiliging en detectie van bedreigingen. Hieronder staan vijf verschillende talen die het meest geschikt zijn voor ML-programmering.

Python:
Bijna 8 miljoen ontwikkelaars gebruiken Python voor codering over de hele wereld. In de jaarlijkse ranglijst van het IEEE Spectrum werd Python gekozen als de meest populaire programmeertaal. Het zag ook dat de Stack-overflow-trends in programmeertalen laten zien dat Python de afgelopen vijf jaar in opkomst is. Het heeft een uitgebreide verzameling pakketten en bibliotheken voor machine learning. Elke gebruiker met de basiskennis van programmeren in Python kan deze bibliotheken zonder veel moeite meteen gebruiken.
Om met tekstgegevens te werken, zijn pakketten als NLTK, SciKit en Numpy handig. OpenCV en Sci-Kit-afbeelding kunnen worden gebruikt om afbeeldingen te verwerken. Men kan Librosa gebruiken tijdens het werken met audiogegevens. Bij het implementeren van deep learning-applicaties komen TensorFlow, Keras en PyTorch van pas als levensredder. Sci-Kit-learn kan worden gebruikt voor het implementeren van primitieve machine learning-algoritmen en Sci-Py voor het uitvoeren van wetenschappelijke berekeningen. Pakketten zoals Matplotlib, Sci-Kit en Seaborn zijn het meest geschikt voor de beste datavisualisaties.
R:
R is een uitstekende programmeertaal voor machine learning-toepassingen die gebruik maken van statistische gegevens. R zit vol met een verscheidenheid aan tools om machine learning-modellen te trainen en te evalueren om nauwkeurige toekomstige voorspellingen te doen. R is een open source programmeertaal en zeer kostenbesparend. Het is zeer flexibel en platformonafhankelijk. Het heeft een breed spectrum aan technieken voor databemonstering, data-analyse, modelevaluatie en datavisualisatie. De uitgebreide lijst met pakketten omvat MICE dat wordt gebruikt voor het afhandelen van ontbrekende waarden, CARET om classificatie- en regressieproblemen uit te voeren, PARTY en rpart om partities in gegevens aan te maken, willekeurig FOREST voor het in een krat plaatsen van beslissingsbomen, properr en dplyr worden gebruikt voor gegevensmanipulatie, ggplot voor het creëren van datavisualisaties, Rmarkdown en Shiny om inzichten waar te nemen door het creëren van rapporten.
Java en Javascript:
Java krijgt meer aandacht in machine learning van de ingenieurs die een Java-achtergrond hebben. De meeste open source-tools zoals Hadoop en Spark die worden gebruikt voor big data-verwerking, zijn geschreven in Java. Het heeft een verscheidenheid aan bibliotheken van derden, zoals JavaML, om algoritmen voor machine learning te implementeren. Arbiter Java wordt gebruikt voor afstemming van hyperparameters in ML. De andere zijn Deeplearning4J en Neuroph die worden gebruikt in deep learning-toepassingen. Schaalbaarheid van Java is een geweldige lift naar ML-algoritmen die het maken van complexe en enorme applicaties mogelijk maken. Virtuele Java-machines zijn een bijkomend voordeel om code op meerdere platforms te maken.
Julia:
Julia is een programmeertaal voor algemeen gebruik die in staat is om complexe numerieke analyses en computationele wetenschap uit te voeren. Het is specifiek ontworpen om wiskundige en wetenschappelijke bewerkingen uit te voeren in algoritmen voor machine learning. Julia-code wordt met hoge snelheid uitgevoerd en vereist geen optimalisatietechnieken om prestatieproblemen aan te pakken. Heeft een verscheidenheid aan tools zoals TensorFlow, MLBase.jl, Flux.jl, SciKitlearn.jl. Het ondersteunt alle soorten hardware, inclusief TPU's en GPU's. Techreuzen als Apple en Oracle zetten Julia in voor hun machine learning-toepassingen.
Lis:
LIST (List Processing) is de op een na oudste programmeertaal die nog steeds wordt gebruikt. Het is ontwikkeld voor AI-gerichte toepassingen. LISP wordt gebruikt bij inductief logisch programmeren en machine learning. ELIZA, de eerste AI-chatbot, is ontwikkeld met behulp van LISP. Veel toepassingen voor machine learning, zoals chatbots eCommerce, zijn ontwikkeld met behulp van LISP. Het biedt snelle prototyping-mogelijkheden, automatische ophaling van afval, biedt dynamische objectcreatie en biedt veel flexibiliteit in bewerkingen.
Soorten machine learning
Op hoog niveau wordt machine learning gedefinieerd als de studie van het aanleren van een computerprogramma of een algoritme om automatisch een specifieke taak te verbeteren. Vanuit het onderzoekspunt kan door het oog van theoretische en wiskundige modellering worden gekeken naar de werking van het hele proces. Het is interessant om meer te weten te komen over de verschillende soorten machine learning in een wereld die doordrenkt is van kunstmatige intelligentie en machine learning. Vanuit het perspectief van een computergebruiker kan dit worden gezien als het begrijpen van de soorten machine learning en hoe deze zich in verschillende toepassingen kunnen openbaren. En vanuit het perspectief van de beoefenaar is het noodzakelijk om de soorten machine learning te kennen voor het maken van deze toepassingen voor een bepaalde taak.
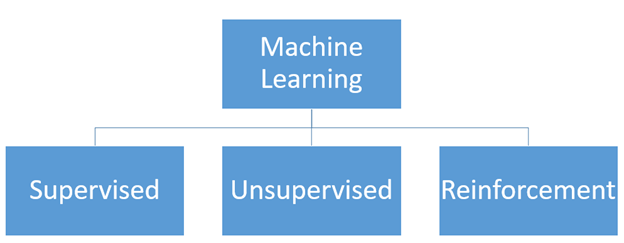
Leren onder toezicht:
Gesuperviseerd leren is de klasse van problemen die een model gebruikt om de afbeelding tussen de invoervariabelen en de doelvariabele te leren. Toepassingen bestaande uit de trainingsgegevens die de verschillende invoervariabelen beschrijven en de doelvariabele staan bekend als begeleide leertaken.
Laat de set invoervariabele (x) zijn en de doelvariabele (y). Een gesuperviseerd leeralgoritme probeert een hypothetische functie te leren die een afbeelding is die wordt gegeven door de uitdrukking y=f(x), die een functie is van x.
Het leerproces wordt hier gemonitord of begeleid. Omdat we de uitvoer al kennen, wordt het algoritme elke keer dat het een voorspelling doet, gecorrigeerd om de resultaten te optimaliseren. Modellen worden aangepast aan trainingsgegevens die bestaan uit zowel de invoer- als de uitvoervariabele en vervolgens worden deze gebruikt om voorspellingen te doen over testgegevens. Tijdens de testfase worden alleen de inputs geleverd en de outputs die door het model worden geproduceerd, worden vergeleken met de achtergehouden doelvariabelen en worden gebruikt om de prestaties van het model te schatten.
Er zijn grofweg twee soorten gesuperviseerde problemen: Classificatie – waarbij een klassenlabel wordt voorspeld en Regressie – waarbij een numerieke waarde wordt voorspeld.
De gegevensset met handgeschreven cijfers van MINST kan worden gezien als een voorbeeld van een classificatietaak. De invoer is de afbeelding van handgeschreven cijfers en de uitvoer is een klasselabel dat de cijfers in het bereik van 0 tot 9 in verschillende klassen identificeert.
De dataset voor de huizenprijs in Boston kan worden gezien als een voorbeeld van een regressieprobleem waarbij de invoer de kenmerken van het huis zijn en de uitvoer de prijs van een huis in dollars, wat een numerieke waarde is.
Ongecontroleerd leren:
In een zonder toezicht leren probleem dat het model zelf probeert te leren en patronen te herkennen en de relaties tussen de gegevens te extraheren. Net als bij begeleid leren is er geen supervisor of leraar om het model te besturen. Unsupervised learning werkt alleen op de invoervariabelen. Er zijn geen doelvariabelen om het leerproces te sturen. Het doel hier is om de onderliggende patronen in de gegevens te interpreteren om meer vaardigheid te verkrijgen over de onderliggende gegevens.
Er zijn twee hoofdcategorieën bij leren zonder toezicht; ze clusteren - waarbij het de taak is om de verschillende groepen in de gegevens te achterhalen. En de volgende is Density Estimation - die probeert de distributie van gegevens te consolideren. Deze bewerkingen worden uitgevoerd om de patronen in de gegevens te begrijpen. Visualisatie en projectie kunnen ook als onbewaakt worden beschouwd, omdat ze proberen meer inzicht in de gegevens te geven. Visualisatie omvat het maken van plots en grafieken op de gegevens en projectie is betrokken bij de dimensionaliteitsreductie van de gegevens.
Versterking leren:
Versterkend leren is een type probleem waarbij er een agent is en de agent opereert in een omgeving op basis van de feedback of beloning die aan de agent wordt gegeven door de omgeving waarin deze opereert. De beloningen kunnen zowel positief als negatief zijn. De agent gaat vervolgens verder in de omgeving op basis van de verkregen beloningen.
De wapeningsagent bepaalt de stappen om een bepaalde taak uit te voeren. Er is hier geen vaste trainingsdataset en de machine leert vanzelf.
Een spel spelen is een klassiek voorbeeld van een versterkingsprobleem, waarbij het doel van de agent is om een hoge score te behalen. Het maakt de opeenvolgende bewegingen in het spel op basis van de feedback van de omgeving, wat kan zijn in termen van beloningen of een straf. Reinforcement learning heeft geweldige resultaten opgeleverd in Google's AplhaGo van Google, dat 's werelds nummer één Go-speler versloeg.
Algoritmen voor machine learning
Er zijn verschillende algoritmen voor machine learning beschikbaar en het is erg moeilijk en tijdrovend om de meest geschikte algoritmen voor het betreffende probleem te selecteren. Deze algoritmen kunnen worden gegroepeerd in twee categorieën. Ten eerste kunnen ze worden gegroepeerd op basis van hun leerpatroon en ten tweede op basis van hun overeenkomst in hun functie.
Op basis van hun leerstijl kunnen ze worden onderverdeeld in drie typen:
- Begeleide leeralgoritmen: De trainingsgegevens worden verstrekt samen met het label dat het trainingsproces begeleidt. Het model wordt getraind totdat het gewenste nauwkeurigheidsniveau is bereikt met de trainingsgegevens. Voorbeelden van dergelijke problemen zijn classificatie en regressie. Voorbeelden van gebruikte algoritmen zijn Logistic Regression, Nearest Neighbor, Naive Bayes, Decision Trees, Linear Regression, Support Vector Machines (SVM), Neural Networks.
- Ongecontroleerde leeralgoritmen: Invoergegevens zijn niet gelabeld en komen niet met een label. Het model wordt voorbereid door de patronen in de invoergegevens te identificeren. Voorbeelden van dergelijke problemen zijn clustering, dimensionaliteitsreductie en het leren van associatieregels. Lijst met algoritmen die voor dit soort problemen worden gebruikt, omvat het Apriori-algoritme en K-Means en associatieregels
- Semi-gesuperviseerde leeralgoritmen: De kosten om de gegevens te labelen zijn vrij duur, omdat hiervoor de kennis van bekwame menselijke experts vereist is. De invoergegevens zijn een combinatie van zowel gelabelde als niet-gelabelde gegevens. Het model doet de voorspellingen door zelf de onderliggende patronen te leren. Het is een mix van zowel classificatie- als clusteringproblemen.
Op basis van de gelijkenis van de functie kunnen de algoritmen als volgt worden gegroepeerd:
- Regressie-algoritmen: Regressie is een proces dat zich bezighoudt met het identificeren van de relatie tussen de doeluitvoervariabelen en de invoerkenmerken om voorspellingen te doen over de nieuwe gegevens. De zes beste regressie-algoritmen zijn: eenvoudige lineaire regressie, lasso-regressie, logistische regressie, multivariate regressie-algoritme, meervoudig regressie-algoritme.
- Op instanties gebaseerde algoritmen: Deze behoren tot de leerfamilie die nieuwe gevallen van het probleem meet met die in de trainingsgegevens om de beste match te vinden en dienovereenkomstig een voorspelling te doen. De belangrijkste op instanties gebaseerde algoritmen zijn: k-Nearest Neighbor, Learning Vector Quantization, Self-Organizing Map, Locally Weighted Learning en Support Vector Machines.
- regularisatie: Regularisatie verwijst naar de techniek van het regulariseren van het leerproces van een bepaalde set kenmerken. Het normaliseert en modereert. De gewichten die aan de kenmerken worden toegekend, worden genormaliseerd, waardoor wordt voorkomen dat bepaalde kenmerken het voorspellingsproces domineren. Deze techniek helpt het probleem van overfitting bij machine learning te voorkomen. De verschillende regularisatie-algoritmen zijn Ridge Regression, Least Absolute Shrinkage and Selection Operator (LASSO) en Least-Angle Regression (LARS).
- Beslisboomalgoritmen: Deze methoden construeren een op een boom gebaseerd model dat is gebaseerd op de beslissingen die zijn genomen door de waarden van de attributen te onderzoeken. Beslisbomen worden gebruikt voor zowel classificatie- als regressieproblemen. Enkele van de bekende beslissingsboomalgoritmen zijn: Classificatie en regressieboom, C4.5 en C5.0, voorwaardelijke beslissingsbomen, Chi-kwadraat automatische interactiedetectie en beslissingsstomp.
- Bayesiaanse algoritmen: Deze algoritmen passen de stelling van Bayes toe voor de classificatie- en regressieproblemen. Ze omvatten Naive Bayes, Gaussian Naive Bayes, Multinomial Naive Bayes, Bayesian Belief Network, Bayesian Network en Averaged One-Dependence Estimators.
- Clustering-algoritmen: Clustering-algoritmen omvatten het groeperen van gegevenspunten in clusters. Alle gegevenspunten in dezelfde groep delen vergelijkbare eigenschappen en gegevenspunten in verschillende groepen hebben zeer verschillende eigenschappen. Clustering is een leerbenadering zonder toezicht en wordt op veel gebieden meestal gebruikt voor statistische gegevensanalyse. Algoritmen zoals k-Means, k-Medians, verwachtingsmaximalisatie, hiërarchische clustering, op dichtheid gebaseerde ruimtelijke clustering van toepassingen met ruis vallen onder deze categorie.
- Algoritmen voor het leren van associatieregels: Association rule learning is een op regels gebaseerde leermethode voor het identificeren van de relaties tussen variabelen in een zeer grote dataset. Association Rule learning wordt voornamelijk gebruikt bij marktmandanalyse. De meest populaire algoritmen zijn: Apriori-algoritme en Eclat-algoritme.
- Kunstmatige neurale netwerkalgoritmen: Kunstmatige neurale netwerkalgoritmen vinden hun basis in de biologische neuronen in het menselijk brein. Ze behoren tot de klasse van complexe patroonvergelijkings- en voorspellingsprocessen bij classificatie- en regressieproblemen. Enkele van de populaire kunstmatige neurale netwerkalgoritmen zijn: Perceptron, Multilayer Perceptrons, Stochastic Gradient Descent, Back-Propagation, Hopfield Network en Radial Basis Function Network.
- Algoritmen voor diep leren: Dit zijn gemoderniseerde versies van een kunstmatig neuraal netwerk, dat zeer grote en complexe databases met gelabelde gegevens aankan. Deep learning-algoritmen zijn op maat gemaakt om tekst-, beeld-, audio- en videogegevens te verwerken. Diep leren maakt gebruik van autodidactische leerconstructies met veel verborgen lagen om big data te verwerken en biedt krachtigere rekenbronnen. De meest populaire deep learning-algoritmen zijn: Enkele van de populaire deep learning-ms zijn Convolutional Neural Network, Recurrent Neural Networks, Deep Boltzmann Machine, Auto-Encoders Deep Belief Networks en Long Short-Term Memory Networks.
- Dimensionaliteit Reductie Algoritmen: Dimensionaliteitsreductie-algoritmen maken gebruik van de intrinsieke structuur van gegevens op een manier zonder toezicht om gegevens uit te drukken met behulp van een gereduceerde informatieset. Ze zetten gegevens met een hoge dimensie om in een lagere dimensie die kan worden gebruikt in leermethoden onder toezicht, zoals classificatie en regressie. Enkele van de bekende algoritmen voor het verminderen van dimensionaliteit zijn Principal Component Analysis, Principal Component Regressio, Linear Discriminant Analysis, Quadratic Discriminant Analysis, Mixture Discriminant Analysis, Flexible Discriminant Analysis en Sammon Mapping.
- Ensemble-algoritmen: Ensemble-methoden zijn modellen die zijn samengesteld uit verschillende zwakkere modellen die afzonderlijk worden getraind en de individuele voorspellingen van de modellen worden gecombineerd met behulp van een methode om de uiteindelijke algehele voorspelling te krijgen. De kwaliteit van de output hangt af van de gekozen methode om de individuele resultaten te combineren. Enkele van de populaire methoden zijn: Random Forest, Boosting, Bootstrapped Aggregation, AdaBoost, Stacked Generalization, Gradient Boosting Machines, Gradient Boosted Regression Trees en Weighted Average.
Levenscyclus van machinaal leren
Machine learning geeft computers de mogelijkheid om automatisch te leren zonder ze expliciet te hoeven programmeren. Het machine learning-proces bestaat uit verschillende fasen om modellen van hoge kwaliteit te ontwerpen, ontwikkelen en implementeren. De levenscyclus van machine learning bestaat uit de volgende stappen
- Software voor buiten
- Data voorbereiding
- Gegevens ruzie
- Data-analyse
- Model opleiding
- Model testen
- Inzet van het model
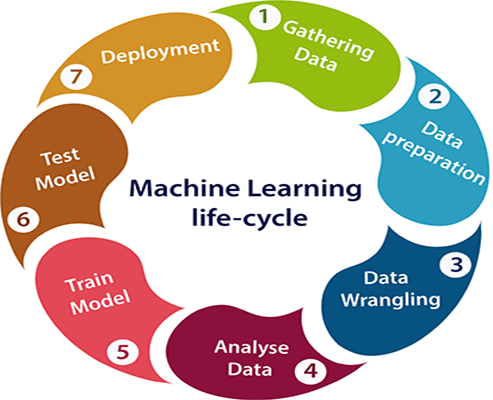
- Gegevensverzameling: Dit is de allereerste stap bij het maken van een machine learning-model. Het belangrijkste doel van deze stap is het identificeren en verzamelen van alle gegevens die relevant zijn voor het probleem. Gegevens kunnen worden verzameld uit verschillende bronnen, zoals bestanden, databases, internet, IoT-apparaten, en de lijst wordt steeds groter. De efficiëntie van de output hangt rechtstreeks af van de kwaliteit van de verzamelde gegevens. Er moet dus uiterste zorg worden besteed aan het verzamelen van grote hoeveelheden kwaliteitsgegevens.
- Data voorbereiding: De verzamelde gegevens worden geordend en op één plek gezet of verder verwerkt. Data-exploratie is een onderdeel van deze stap, waarbij de kenmerken, de aard, het formaat en de kwaliteit van de data worden ontsloten. Dit omvat het maken van cirkeldiagrammen, staafdiagrammen, histogrammen, scheefheid enz. Gegevensverkenning biedt nuttig inzicht in de gegevens en helpt bij het oplossen van 75% van het probleem.
- Gegevens ruzie: In Data Wrangling worden de ruwe data opgeschoond en omgezet in een bruikbaar formaat. De gebruikelijke technieken die worden toegepast om het meeste uit de verzamelde gegevens te halen, zijn:
- Controle op ontbrekende waarde en imputatie van ontbrekende waarde
- Ongewenste gegevens en Null-waarden verwijderen
- Optimaliseren van de data op basis van het interessedomein
- Detecteren en verwijderen van uitschieters
- De dimensie van de gegevens verkleinen
- De gegevens balanceren, onderbemonstering en overbemonstering.
- Verwijderen van dubbele records
- Data analyse: Deze stap heeft betrekking op het functieselectie- en modelselectieproces. De voorspellende kracht van de onafhankelijke variabelen ten opzichte van de afhankelijke variabele wordt geschat. Alleen die variabelen die gunstig zijn voor het model worden geselecteerd. Vervolgens wordt de juiste machine learning-techniek zoals classificatie, regressie, clustering, associatie, enz. geselecteerd en wordt het model gebouwd met behulp van de gegevens.
- Model opleiding: Training is een zeer belangrijke stap in machine learning, aangezien het model de verschillende patronen, kenmerken en regels uit de onderliggende gegevens probeert te begrijpen. Gegevens worden opgesplitst in trainingsgegevens en testgegevens. Het model wordt getraind op de trainingsgegevens totdat de prestaties een acceptabel niveau bereiken.
- Model testen: Na het trainen van het model wordt het getest om de prestaties op de ongeziene testgegevens te evalueren. De nauwkeurigheid van de voorspelling en de prestaties van het model kunnen worden gemeten met behulp van verschillende maatregelen, zoals verwarringsmatrix, precisie en herinnering, gevoeligheid en specificiteit, oppervlakte onder de curve, F1-score, R-vierkant, gini-waarden enz.
- implementatie: Dit is de laatste stap in de levenscyclus van machine learning en we implementeren het model dat is gebouwd in het echte systeem. Voordat het wordt geïmplementeerd, wordt het model gebeitst, dat wil zeggen dat het moet worden omgezet in een platformonafhankelijke uitvoerbare vorm. Het gebeitste model kan worden geïmplementeerd met behulp van Rest API of Micro-Services.
Diepe leren
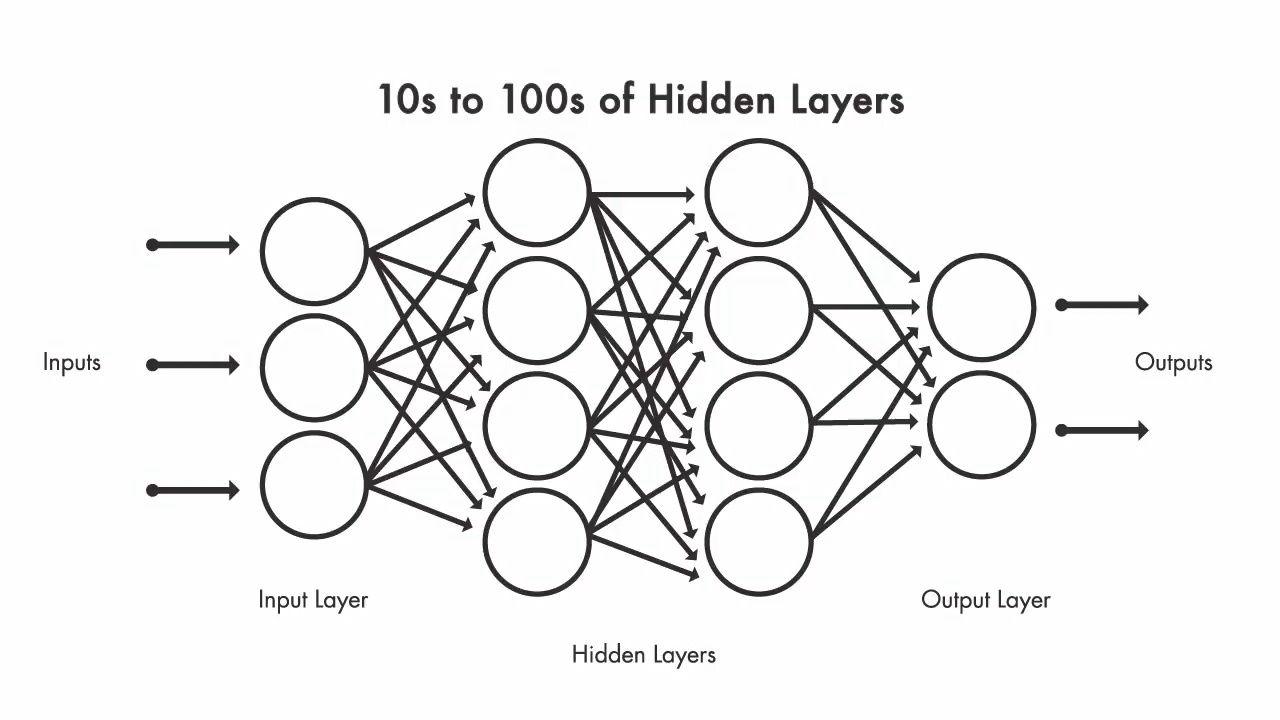
Diep leren is een subset van machine learning die de functionaliteit van de neuronen in het menselijk brein volgt. Het deep learning-netwerk bestaat uit meerdere neuronen die in lagen met elkaar zijn verbonden. Het neurale netwerk heeft veel diepe lagen die het leerproces mogelijk maken. Het deep learning neurale netwerk bestaat uit een invoerlaag, een uitvoerlaag en meerdere verborgen lagen die samen het volledige netwerk vormen. De verwerking vindt plaats via de verbindingen die de invoergegevens bevatten, de vooraf toegewezen gewichten en de activeringsfunctie die het pad bepaalt voor de controlestroom door het netwerk. Het netwerk werkt met een enorme hoeveelheid gegevens en verspreidt deze door elke laag door complexe functies op elk niveau te leren. Als de uitkomst van het model niet is zoals verwacht, worden de gewichten aangepast en herhaalt het proces zich totdat het gewenste resultaat is bereikt.

Diep neuraal netwerk kan de functies automatisch leren zonder expliciet te worden geprogrammeerd. Elke laag geeft een dieper informatieniveau weer. Het deep learning-model volgt een hiërarchie van kennis die in elk van de lagen wordt weergegeven. Een neuraal netwerk met vijf lagen leert meer dan een neuraal netwerk met drie lagen. Het leren in een neuraal netwerk gebeurt in twee stappen. In de eerste stap wordt een niet-lineaire transformatie toegepast op de invoer en wordt een statistisch model gemaakt. Tijdens de tweede stap wordt het gemaakte model verbeterd met behulp van een wiskundig model dat derivaat wordt genoemd. Deze twee stappen worden duizenden keren herhaald door het neurale netwerk totdat het het gewenste nauwkeurigheidsniveau bereikt. De herhaling van deze twee stappen staat bekend als iteratie.
Het neurale netwerk met slechts één verborgen laag staat bekend als een ondiep netwerk en het neurale netwerk met meer dan één verborgen laag staat bekend als diep neuraal netwerk.
Soorten neurale netwerken:
Er zijn verschillende soorten neurale netwerken beschikbaar voor verschillende soorten processen. De meest gebruikte soorten worden hier besproken.
- perceptron: Het perceptron is een enkellaags neuraal netwerk dat alleen een invoerlaag en een uitvoerlaag bevat. Er zijn geen verborgen lagen. De activeringsfunctie die hier wordt gebruikt, is de sigmoïde functie.
- Feedforward: Het feed forward neurale netwerk is de eenvoudigste vorm van een neuraal netwerk waarbij de informatie slechts in één richting stroomt. Er zijn geen cycli in het pad van het neurale netwerk. Elk knooppunt in een laag is verbonden met alle knooppunten in de volgende laag. Alle knooppunten zijn dus volledig verbonden en er zijn geen back-loops.
- Terugkerende neurale netwerken: Recurrent Neural Networks slaat de output van het netwerk op in zijn geheugen en stuurt het terug naar het netwerk om te helpen bij het voorspellen van de output. Het netwerk bestaat uit twee verschillende lagen. De eerste is een feed forward neuraal netwerk en de tweede is een terugkerend neuraal netwerk waarbij de vorige netwerkwaarden en toestanden worden onthouden in een geheugen. Als er een verkeerde voorspelling wordt gedaan, wordt de leersnelheid gebruikt om geleidelijk over te gaan naar het maken van de juiste voorspelling door middel van back-propagatie.
- Convolutioneel neuraal netwerk: Convolutionele neurale netwerken worden gebruikt waar het nodig is om nuttige informatie uit ongestructureerde gegevens te halen. Voortplanting van signa is unidirectioneel in een CNN. De eerste laag is een convolutionele laag die wordt gevolgd door een pooling, gevolgd door meerdere convolutionele en pooling-lagen. De uitvoer van deze lagen wordt ingevoerd in een volledig verbonden laag en een softmax die het classificatieproces uitvoert. De neuronen in een CNN hebben leerbare gewichten en vooroordelen. Convolution gebruikt de niet-lineaire RELU-activeringsfunctie. CNN's worden gebruikt in signaal- en beeldverwerkingstoepassingen.
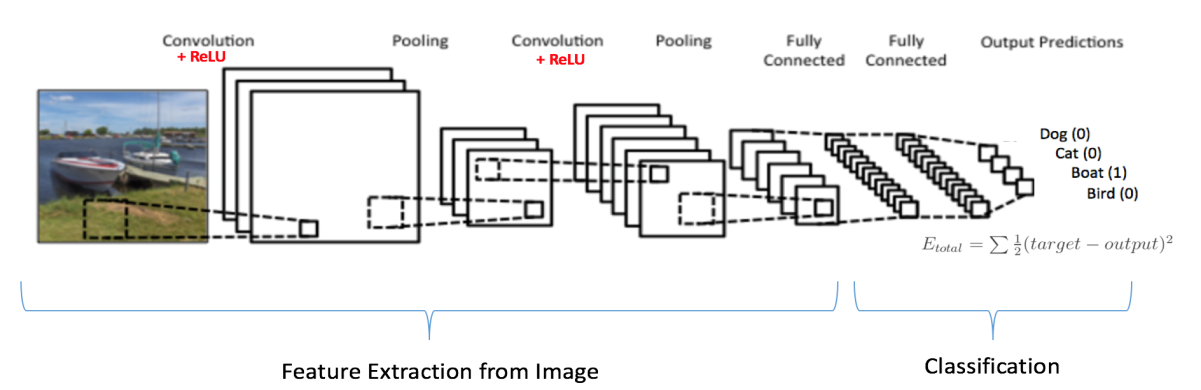
- Versterking leren: Bij bekrachtigend leren leert de agent die in een complexe en onzekere omgeving opereert door een methode van vallen en opstaan. De agent wordt virtueel beloond of gestraft als gevolg van zijn acties en helpt bij het verfijnen van de geproduceerde output. Het doel is om het totale aantal beloningen dat de agent ontvangt te maximaliseren. Het model leert vanzelf om de beloningen te maximaliseren. De DeepMind- en zelfrijdende auto's van Google zijn voorbeelden van toepassingen waarbij versterkend leren wordt gebruikt.
Verschil tussen machinaal leren en diep leren
Diep leren is een onderdeel van machine learning. De machine learning-modellen worden steeds beter naarmate ze hun functies met enige begeleiding leren. Als de voorspellingen niet kloppen, moet een expert het model aanpassen. Bij deep learning is het model zelf in staat om vast te stellen of de voorspellingen kloppen of niet.
- Werking: Diep leren neemt de gegevens als invoer en probeert automatisch intelligente beslissingen te nemen met behulp van de uitgezette lagen van een kunstmatig neuraal netwerk. Machine learning neemt de invoergegevens, parseert deze en wordt getraind op de gegevens. Het probeert op basis van de gegevens beslissingen te nemen op basis van wat het tijdens de trainingsfase heeft geleerd.
- Feature extractie: Diep leren haalt de relevante kenmerken uit de invoergegevens. Het extraheert automatisch de kenmerken op een hiërarchische manier. De functies worden laagsgewijs aangeleerd. Het leert in eerste instantie de functies op laag niveau en terwijl het verder gaat in het netwerk, probeert het de meer specifieke functies te leren. Terwijl machine learning-modellen functies vereisen die met de hand uit de dataset worden geplukt. Deze functies worden geleverd als invoer voor het model om de voorspelling te doen.
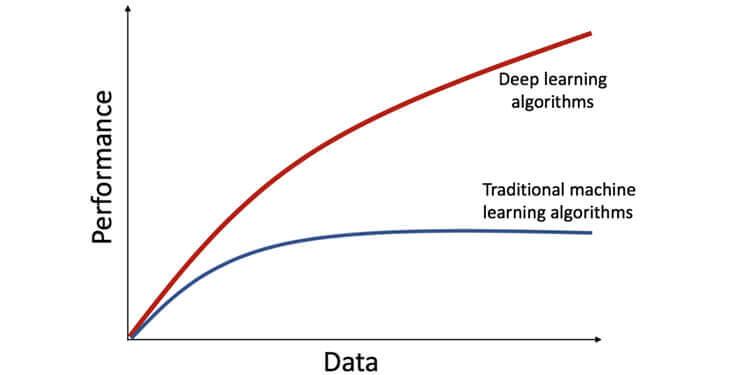
- Gegevensafhankelijkheid: Deep learning-modellen vereisen enorme hoeveelheden gegevens omdat ze het functie-extractieproces zelf uitvoeren. Maar een machine learning-model werkt prima met kleinere datasets. De diepte van het netwerk in een deep learning-model neemt toe met de data en daarmee neemt ook de complexiteit van het deep learning-model toe. Het volgende diagram laat zien dat de prestaties van het deep learning-model toenemen met meer gegevens, maar dat de machine learning-modellen de curve na een bepaalde periode afvlakken.
- Rekenkracht: Deep learning-netwerken zijn in hoge mate afhankelijk van enorme gegevens, waarvoor de ondersteuning van GPU's vereist is in plaats van de normale CPU's. GPU's kunnen de verwerking van deep learning-modellen maximaliseren, omdat ze meerdere berekeningen tegelijkertijd kunnen verwerken. De hoge geheugenbandbreedte in GPU's maakt ze geschikt voor deep learning-modellen. Aan de andere kant kunnen machine learning-modellen op CPU's worden geïmplementeerd.
- Uitvoertijd: Normaal gesproken duurt het trainen van deep learning-algoritmen lang vanwege het grote aantal parameters. De ResNet-architectuur, een voorbeeld van een algoritme voor diep leren, heeft bijna twee weken nodig om helemaal opnieuw te trainen. Maar machine learning-algoritmen hebben minder tijd nodig om te trainen (enkele minuten tot enkele uren). Dit is volledig omgekeerd ten opzichte van de testtijd. Deep learning-algoritmen hebben minder tijd nodig om te worden uitgevoerd.
- Interpreteerbaarheid: Het is gemakkelijker om machine learning-algoritmen te interpreteren en te begrijpen wat er bij elke stap wordt gedaan en waarom het wordt gedaan. Maar deep learning-algoritmen staan bekend als black boxes, omdat men echt niet weet wat er aan de binnenkant van de deep learning-architectuur gebeurt. Welke neuronen worden geactiveerd en hoeveel ze bijdragen aan de output. De interpretatie van machine learning-modellen is dus veel eenvoudiger dan de deep learning-modellen.
Toepassingen van machinaal leren
- Verkeersassistenten: We gebruiken allemaal verkeersassistenten als we reizen. Google Maps is handig om ons de routes naar onze bestemming te geven en toont ons ook de routes met minder verkeer. Iedereen die de kaarten gebruikt, geeft zijn locatie, afgelegde route en rijsnelheid door aan Google Maps. Deze details over het verkeer worden verzameld door Google Maps en het probeert het verkeer op uw route te voorspellen en probeert uw route hierop aan te passen.
- Sociale media: De meest voorkomende toepassing van machine learning is te zien in het automatisch taggen van vrienden en vriendensuggesties. Facebook gebruikt Deep Face voor beeldherkenning en gezichtsherkenning in digitale afbeeldingen.
- Productaanbeveling: Wanneer u door Amazon bladert voor een bepaald product maar het niet koopt, krijgt u de volgende dag, wanneer u YouTube of Facebook opent, advertenties te zien die daarmee verband houden. Uw zoekgeschiedenis wordt bijgehouden door Google en beveelt producten aan op basis van uw zoekgeschiedenis. Dit is een toepassing van machine learning-techniek.
- persoonlijke assistenten: Persoonlijke assistenten helpen bij het vinden van nuttige informatie. De invoer voor een persoonlijke assistent kan via spraak of tekst zijn. Er is niemand die zou kunnen zeggen dat ze niets weten over Siri en Alexa. Persoonlijke assistenten kunnen helpen bij het beantwoorden van telefoontjes, het plannen van vergaderingen, het maken van aantekeningen, het verzenden van e-mails, enz.
- Sentiment analyse: Het is een real-time machine learning-applicatie die de mening van mensen kan begrijpen. De applicatie kan worden bekeken op op beoordelingen gebaseerde websites en in besluitvormingsapplicaties.
- Taal vertaling: Het vertalen van talen is geen moeilijke taak meer, aangezien er nu een hand vol taalvertalers beschikbaar is. Google's GNMT is een efficiënte neurale machinevertaaltool die toegang heeft tot duizenden woordenboeken en talen om een nauwkeurige vertaling van zinnen of woorden te bieden met behulp van de Natural Language Processing-technologie.
- Online fraudedetectie: ML-algoritmen kunnen leren van historische fraudepatronen en fraudetransacties in de toekomst herkennen.ML-algoritmen hebben bewezen efficiënter te zijn dan mensen in de snelheid van informatieverwerking. Fraudedetectiesysteem aangedreven door ML kan fraude vinden die mensen niet kunnen detecteren.
- Gezondheidszorg: AI wordt de toekomst van de gezondheidszorg. AI speelt een sleutelrol bij de klinische besluitvorming, waardoor ziekten vroegtijdig kunnen worden opgespoord en behandelingen voor patiënten kunnen worden aangepast. PathAI, dat machine learning gebruikt, wordt door pathologen gebruikt om ziekten nauwkeurig te diagnosticeren. Quantitative Insights is AI-software die de snelheid en nauwkeurigheid bij de diagnose van borstkanker verbetert. Het biedt betere resultaten voor patiënten door een verbeterde diagnose door radiologen.
Toepassingen van diep leren
- Zelfrijdende auto's: Autonoom rijdende auto's worden mogelijk gemaakt door deep learning-technologie. Er wordt ook onderzoek gedaan bij de Ai Labs om functies zoals voedselbezorging te integreren in zelfrijdende auto's. Gegevens worden verzameld van sensoren, camera's en geomapping helpen om meer geavanceerde modellen te creëren die naadloos door het verkeer kunnen reizen.
- Detectie van fraudenieuws: Het opsporen van fraudenieuws is erg belangrijk in de wereld van vandaag. Internet is de bron geworden van allerlei soorten nieuws, zowel echt als nep. Proberen nepnieuws te identificeren is een zeer moeilijke taak. Met behulp van deep learning kunnen we nepnieuws opsporen en verwijderen uit de nieuwsfeeds.
- Natuurlijke taalverwerking: Proberen de syntaxis, semantiek, tonen of nuances van een taal te begrijpen, is een zeer moeilijke en complexe taak voor mensen. Machines zouden kunnen worden getraind om de nuances van een taal te identificeren en de reacties daarop af te stemmen met behulp van de Natural Language Processing-techniek. Diep leren wint aan populariteit in toepassingen zoals het classificeren van tekst, twitteranalyse, taalmodellering, sentimentanalyse, enz., Waarbij gebruik wordt gemaakt van natuurlijke taalverwerking.
- Virtuele Assistenten: Virtuele assistenten gebruiken deep learning-technieken om uitgebreide kennis te hebben over de onderwerpen, van de voorkeuren van mensen om uit eten te gaan tot hun favoriete liedjes. Virtuele assistenten proberen de gesproken talen te begrijpen en de taken uit te voeren. Google werkt al vele jaren aan deze technologie, Google duplex genaamd, die gebruikmaakt van natuurlijk taalbegrip, deep learning en tekst-naar-spraak om mensen te helpen overal in het midden van de week afspraken te boeken. En zodra de assistent klaar is met de klus, krijgt u een bevestigingsmelding dat uw afspraak is afgehandeld. De gesprekken verlopen niet zoals verwacht, maar de assistent begrijpt de context om te nuanceren en handelt het gesprek gracieus af.
- Visuele herkenning: Het kan nostalgisch zijn om door oude foto's te bladeren, maar het zoeken naar een bepaalde foto kan een vervelend proces worden omdat het gaat om sorteren en scheiden, wat tijdrovend is. Diep leren kan nu worden toegepast op afbeeldingen om ze te sorteren op basis van locaties in de foto's, combinatie van mensen, op bepaalde gebeurtenissen of datums. Het doorzoeken van de foto's is niet langer vervelend en complex. Vision AI haalt inzichten uit afbeeldingen in de cloud met AutoML Vision of vooraf getrainde Vision API-modellen om tekst te identificeren en emoties in afbeeldingen te begrijpen.
- Inkleuren van zwart-witafbeeldingen: Het kleuren van een zwart-witafbeelding is als een kinderspel met behulp van Computer Vision-algoritmen die deep learning-technieken gebruiken om de afbeeldingen tot leven te brengen door ze in te kleuren met de juiste kleurtinten. De microservices Colourful Image Colorization is een algoritme dat gebruikmaakt van computervisietechniek en deep learning-algoritmen die zijn getraind in de Imagenet-database om zwart-witafbeeldingen in te kleuren.
- Geluiden toevoegen aan stomme films: AI kan nu realistische soundtracks maken voor stille video's. CNN's en terugkerende neurale netwerken worden gebruikt om kenmerkextractie en het voorspellingsproces uit te voeren. Onderzoek heeft aangetoond dat deze algoritmen, die hebben geleerd geluid te voorspellen, betere geluidseffecten voor oude films kunnen produceren en robots kunnen helpen de objecten in hun omgeving te begrijpen.
- Vertaling van afbeelding naar taal: Dit is een andere interessante toepassing van diep leren. De Google Translate-app kan afbeeldingen automatisch vertalen in realtime taal naar keuze. Het deep learning netwerk leest de afbeelding en vertaalt de tekst in de benodigde taal.
- Pixelherstel: De onderzoekers van Google Brain hebben een Deep Learning-netwerk getraind dat een afbeelding met een zeer lage resolutie van het gezicht van een persoon neemt en het gezicht van de persoon daardoor voorspelt. Deze methode staat bekend als Pixel Recursive Super Resolution. Deze methode verbetert de resolutie van foto's door de opvallende kenmerken te identificeren, wat net voldoende is om de persoonlijkheid van de persoon te identificeren.
Conclusie
In dit hoofdstuk zijn de toepassingen van machine learning en deep learning ontdekt om een duidelijker beeld te krijgen van de huidige en toekomstige mogelijkheden van kunstmatige intelligentie. Er wordt voorspeld dat veel toepassingen van kunstmatige intelligentie ons leven in de nabije toekomst zullen beïnvloeden. Voorspellende analyses en kunstmatige intelligentie zullen in de toekomst een fundamentele rol spelen bij het creëren van inhoud en ook bij de ontwikkeling van software. Feit is dat ze al impact maken. In de komende jaren zullen AI-ontwikkeltools, bibliotheken en talen de universeel geaccepteerde standaardcomponenten worden van elke toolkit voor softwareontwikkeling die je kunt noemen. De technologie van kunstmatige intelligentie wordt de toekomst in alle domeinen, waaronder gezondheid, zaken, milieu, openbare veiligheid en beveiliging.
Referenties
[1] Aditya Sharma(2018), "Verschillen tussen machinaal leren en diep leren"
[2] Kislay Keshari(2020), "Top 10 toepassingen van machinaal leren: toepassingen voor machinaal leren in het dagelijks leven"
[3] Brett Grossfeld(2020), "Deep learning vs machine learning: een eenvoudige manier om het verschil te begrijpen"
[4] Door Nikita Duggal (2020), "Real-World Machine Learning-applicaties die je zullen verbazen"
[5] PP Shinde en S. Shah, "A Review of Machine Learning and Deep Learning Applications", 2018 Vierde internationale conferentie over Computing Communication Control and Automation (ICCUBEA), Pune, India, 2018, pp. 1-6
[6] https://www.javatpoint.com/machine-learning-life-cycle
[7] https://medium.com/app-affairs/9-applications-of-machine-learning-from-day-to-day-life-112a47a429d0
[8] Dan Shewan(2019), “10 bedrijven die machine learning op coole manieren gebruiken”
[9] Marina Chatterjee(2019), “Top 20 toepassingen van deep learning in 2020 in verschillende sectoren
[10] Een rondleiding door machine learning-algoritmen door Jason Brownlee in Algoritmen voor machine learning
[11] Jaderberg, Max, et al. "Ruimtelijke transformatornetwerken." In Vooruitgang in neurale informatieverwerkingssystemen (2015): 2017-2025.
[12] Van Veen, F. & Leijnen, S. (2019). De dierentuin van het neurale netwerk. Opgehaald van https://www.asimovinstitute.org/neural-network-zoo
[13] Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, ImageNet-classificatie met diepe convolutionele neurale netwerken, [pdf], 2012
[14] Yadav, Neha, Anupam, Kumar, Manoj, An Introduction to neurale netwerken voor differentiaalvergelijkingen (ISBN: 978-94-017-9815-0)
[15] Hugo Mayo, Hashan Punchihewa, Julie Emile, Jackson Morrison Geschiedenis van machinaal leren, 2018
[16] Pedro Domingos, 2012, De "volkskennis" aanboren die nodig is om toepassingen voor machine learning te bevorderen. door Een paar nuttig, doi:10.1145/2347736.2347755
[17] Alex Smola en SVN Vishwanathan, Inleiding tot machine learning, Cambridge University Press 2008
[18] Antonio Guili en Sujit Pal, Deep Learning met Keras: Deep learning-modellen en neurale netwerken implementeren met de kracht van Python, Jaar van uitgave: 2017; Packt Publishing Ltd.
[19] Aurelien Geron,Hands-on machine learning met Scikit-Learn en Tensor Flow: concepten, tools en technieken om intelligente systemen te bouwen, Jaar van uitgave: 2017. O'Reilly
[20] Beste taal voor machinaal leren: welke programmeertaal te leren, 31 augustus 2020, Springboard India.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.mygreatlearning.com/blog/machine-learning-and-deep-learning/

