Afbeelding door redacteur
Zoals Karl Pearson, een Britse wiskundige, ooit heeft gezegd: Statistieken is de grammatica van de wetenschap en dit geldt vooral voor computer- en informatiewetenschappen, natuurwetenschappen en biologische wetenschappen. Wanneer je aan de slag gaat met je reis naar binnen data Science or gegevens Analytics, zal het hebben van statistische kennis u helpen om beter gebruik te maken van data-inzichten.
"Statistiek is de grammatica van de wetenschap." Karel Pearson
Het belang van statistiek in datawetenschap en data-analyse kan niet worden onderschat. Statistieken bieden tools en methoden om structuur te vinden en diepere data-inzichten te geven. Zowel statistiek als wiskunde houden van feiten en haten gissingen. Als u de grondbeginselen van deze twee belangrijke onderwerpen kent, kunt u kritisch nadenken en creatief zijn bij het gebruik van de gegevens om bedrijfsproblemen op te lossen en gegevensgestuurde beslissingen te nemen. In dit artikel behandel ik de volgende statistische onderwerpen voor datawetenschap en data-analyse:
- Random variables - Probability distribution functions (PDFs) - Mean, Variance, Standard Deviation - Covariance and Correlation - Bayes Theorem - Linear Regression and Ordinary Least Squares (OLS) - Gauss-Markov Theorem - Parameter properties (Bias, Consistency, Efficiency) - Confidence intervals - Hypothesis testing - Statistical significance - Type I & Type II Errors - Statistical tests (Student's t-test, F-test) - p-value and its limitations - Inferential Statistics - Central Limit Theorem & Law of Large Numbers - Dimensionality reduction techniques (PCA, FA)Als je geen voorkennis hebt van statistiek en je de essentiële statistische concepten vanaf het begin wilt identificeren en leren om je voor te bereiden op je sollicitatiegesprekken, dan is dit artikel iets voor jou. Dit artikel is ook goed leesbaar voor iedereen die zijn/haar statistische kennis wil opfrissen.
Welkom bij LunarTech.ai, waar we de kracht begrijpen van strategieën voor het zoeken naar werk in het dynamische veld van datawetenschap en AI. We duiken diep in de tactieken en strategieën die nodig zijn om door het competitieve zoekproces naar werk te navigeren. Of het nu gaat om het definiëren van uw carrièredoelen, het aanpassen van sollicitatiemateriaal of het benutten van vacaturesites en netwerken, onze inzichten bieden de begeleiding die u nodig hebt om uw droombaan binnen te halen.
Voorbereiding op data science-interviews? Wees niet bang! We werpen een licht op de fijne kneepjes van het interviewproces en voorzien u van de kennis en voorbereiding die nodig zijn om uw kansen op succes te vergroten. Van eerste telefonische screenings tot technische beoordelingen, technische interviews en gedragsinterviews, we laten geen middel onbeproefd.
At LunarTech.ai, gaan we verder dan de theorie. Wij zijn jouw springplank naar ongeëvenaard succes op het gebied van technologie en datawetenschap. Ons uitgebreide leertraject is op maat gemaakt om naadloos in uw levensstijl te passen, zodat u de perfecte balans kunt vinden tussen persoonlijke en professionele verplichtingen terwijl u geavanceerde vaardigheden verwerft. Met onze toewijding aan uw loopbaangroei, inclusief hulp bij het plaatsen van een baan, het opstellen van cv's door experts en het voorbereiden van sollicitatiegesprekken, zult u naar voren komen als een krachtpatser die klaar is voor de branche.
Sluit u vandaag nog aan bij onze community van ambitieuze individuen en begin samen aan deze spannende data science-reis. Met LunarTech.ai, de toekomst ziet er rooskleurig uit en jij bezit de sleutels om grenzeloze kansen te ontsluiten.
Het concept van willekeurige variabelen vormt de hoeksteen van veel statistische concepten. Het is misschien moeilijk om de formele wiskundige definitie ervan te verteren, maar simpel gezegd, a willekeurige variabele is een manier om de uitkomsten van willekeurige processen, zoals het opgooien van een munt of het gooien van een dobbelsteen, in getallen om te zetten. We kunnen bijvoorbeeld het willekeurige proces van het opgooien van een munt definiëren door willekeurige variabele X die de waarde 1 aanneemt als de uitkomst als hoofden en 0 als de uitkomst is staarten.
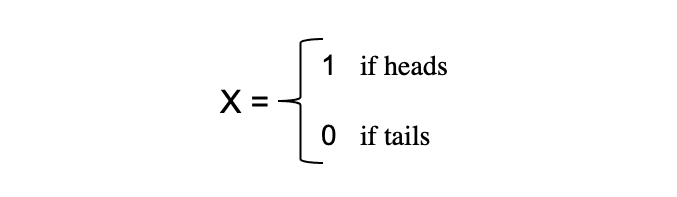
In dit voorbeeld hebben we een willekeurig proces van het opgooien van een munt waar dit experiment kan produceren twee mogelijke uitkomsten: {0,1}. Deze verzameling van alle mogelijke uitkomsten wordt de voorbeeldruimte van het experiment. Elke keer dat het willekeurige proces wordt herhaald, wordt dit een genoemd evenement. In dit voorbeeld is het opgooien van een munt en het krijgen van een munt als uitkomst een gebeurtenis. De kans of waarschijnlijkheid dat deze gebeurtenis optreedt met een bepaalde uitkomst wordt de waarschijnlijkheid van dat evenement. Een waarschijnlijkheid van een gebeurtenis is de waarschijnlijkheid dat een willekeurige variabele een specifieke waarde van x aanneemt die kan worden beschreven door P(x). In het voorbeeld van het opgooien van een munt is de kans op kop of munt gelijk, namelijk 0.5 of 50%. We hebben dus de volgende instelling:
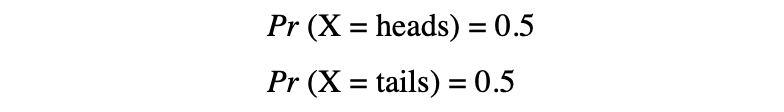
waarbij de waarschijnlijkheid van een gebeurtenis, in dit voorbeeld, alleen waarden in het bereik [0,1] kan aannemen.
Het belang van statistiek in datawetenschap en data-analyse kan niet worden onderschat. Statistieken bieden tools en methoden om structuur te vinden en diepere data-inzichten te geven.
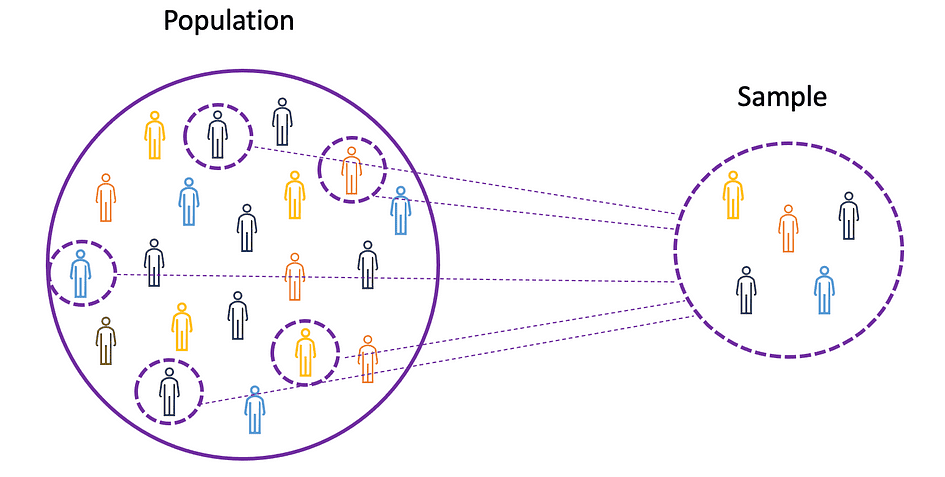
Om de concepten van gemiddelde, variantie en vele andere statistische onderwerpen te begrijpen, is het belangrijk om de concepten van te leren bevolking en monster. De bevolking is de verzameling van alle waarnemingen (individuen, objecten, gebeurtenissen of procedures) en is meestal erg groot en divers, terwijl een monster is een subset van observaties van de populatie die idealiter een waarheidsgetrouwe weergave is van de populatie.
Afbeeldingsbron: de auteur
Aangezien experimenteren met een hele populatie onmogelijk of simpelweg te duur is, gebruiken onderzoekers of analisten steekproeven in plaats van de hele populatie in hun experimenten of proeven. Om ervoor te zorgen dat de experimentele resultaten betrouwbaar zijn en gelden voor de hele populatie, moet de steekproef een waarheidsgetrouwe weergave van de populatie zijn. Dat wil zeggen, het monster moet onbevooroordeeld zijn. Hiervoor kan men gebruik maken van statistische steekproeftechnieken zoals Willekeurige steekproeven, systematische steekproeven, geclusterde steekproeven, gewogen steekproeven en gestratificeerde steekproeven.
Gemiddelde
Het gemiddelde, ook wel het gemiddelde genoemd, is een centrale waarde van een eindige reeks getallen. Laten we aannemen dat een willekeurige variabele X in de gegevens de volgende waarden heeft:
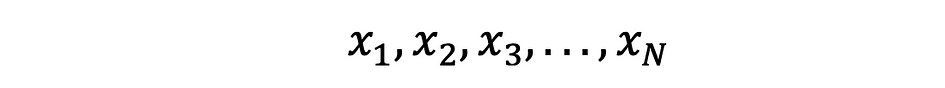
waarbij N het aantal waarnemingen of gegevenspunten in de steekproefreeks is of gewoon de gegevensfrequentie. Dan de steekproefgemiddelde gedefinieerd door ?, die heel vaak wordt gebruikt om de te benaderen gemiddelde bevolking, kan als volgt worden uitgedrukt:
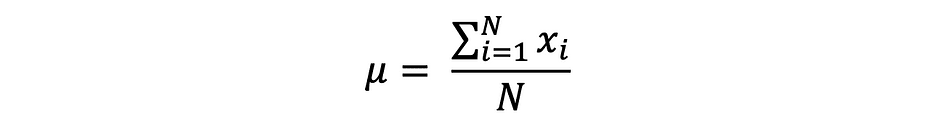
Het gemiddelde wordt ook wel genoemd verwachting die vaak wordt gedefinieerd door E() of willekeurige variabele met een balk bovenaan. Bijvoorbeeld de verwachting van willekeurige variabelen X en Y E(X) en E(Y) kan respectievelijk als volgt worden uitgedrukt:
import numpy as np
import math
x = np.array([1,3,5,6])
mean_x = np.mean(x)
# in case the data contains Nan values
x_nan = np.array([1,3,5,6, math.nan])
mean_x_nan = np.nanmean(x_nan)variance
De variantie meet hoe ver de gegevenspunten zijn uitgespreid van de gemiddelde waarde, en is gelijk aan de som van de kwadraten van verschillen tussen de gegevenswaarden en het gemiddelde (het gemiddelde). Verder is de populatievariantie, kan als volgt worden uitgedrukt:
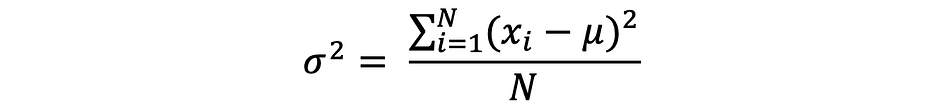
x = np.array([1,3,5,6])
variance_x = np.var(x) # here you need to specify the degrees of freedom (df) max number of logically independent data points that have freedom to vary
x_nan = np.array([1,3,5,6, math.nan])
mean_x_nan = np.nanvar(x_nan, ddof = 1)Voor het afleiden van verwachtingen en varianties van verschillende populaire kansverdelingsfuncties, bekijk deze Github-repo.
Standaardafwijking
De standaarddeviatie is gewoon de vierkantswortel van de variantie en meet de mate waarin de gegevens afwijken van het gemiddelde. De standaarddeviatie gedefinieerd door sigma kan als volgt worden uitgedrukt:
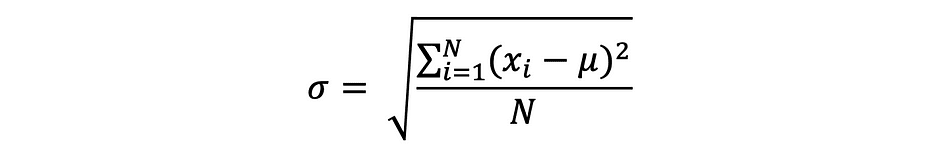
Standaarddeviatie heeft vaak de voorkeur boven variantie omdat deze dezelfde eenheid heeft als de gegevenspunten, wat betekent dat u deze gemakkelijker kunt interpreteren.
x = np.array([1,3,5,6])
variance_x = np.std(x) x_nan = np.array([1,3,5,6, math.nan])
mean_x_nan = np.nanstd(x_nan, ddof = 1)Covariantie
De covariantie is een maat voor de gezamenlijke variabiliteit van twee willekeurige variabelen en beschrijft de relatie tussen deze twee variabelen. Het wordt gedefinieerd als de verwachte waarde van het product van de afwijkingen van de twee willekeurige variabelen van hun gemiddelden. De covariantie tussen twee willekeurige variabelen X en Z kan worden beschreven door de volgende uitdrukking, waar E(X) en E(Z) vertegenwoordigen respectievelijk de gemiddelden van X en Z.
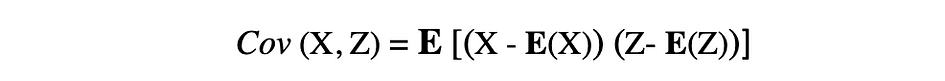
Covariantie kan negatieve of positieve waarden aannemen, evenals waarde 0. Een positieve waarde van covariantie geeft aan dat twee willekeurige variabelen de neiging hebben om in dezelfde richting te variëren, terwijl een negatieve waarde suggereert dat deze variabelen in tegengestelde richtingen variëren. Ten slotte betekent de waarde 0 dat ze niet samen variëren.
x = np.array([1,3,5,6])
y = np.array([-2,-4,-5,-6])
#this will return the covariance matrix of x,y containing x_variance, y_variance on diagonal elements and covariance of x,y
cov_xy = np.cov(x,y)Correlatie
De correlatie is ook een maat voor relaties en meet zowel de sterkte als de richting van de lineaire relatie tussen twee variabelen. Als er een correlatie wordt gedetecteerd, betekent dit dat er een relatie of een patroon is tussen de waarden van twee doelvariabelen. De correlatie tussen twee willekeurige variabelen X en Z is gelijk aan de covariantie tussen deze twee variabelen gedeeld door het product van de standaarddeviaties van deze variabelen, wat beschreven kan worden door de volgende uitdrukking.
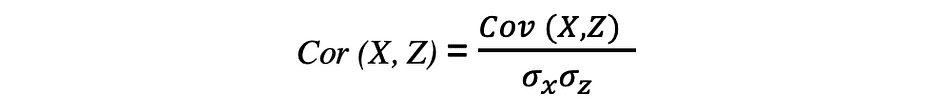
De waarden van correlatiecoëfficiënten liggen tussen -1 en 1. Houd er rekening mee dat de correlatie van een variabele met zichzelf altijd 1 is, dat wil zeggen Kor(X, X) = 1. Een ander ding om in gedachten te houden bij het interpreteren van correlatie is om het niet te verwarren met oorzakelijkheid, aangezien een correlatie geen oorzakelijk verband is. Zelfs als er een correlatie is tussen twee variabelen, kun je niet concluderen dat de ene variabele een verandering veroorzaakt in de andere. Deze relatie kan toevallig zijn, of een derde factor kan ervoor zorgen dat beide variabelen veranderen.
x = np.array([1,3,5,6])
y = np.array([-2,-4,-5,-6])
corr = np.corrcoef(x,y)Een functie die alle mogelijke waarden, de bemonsteringsruimte en de bijbehorende kansen beschrijft die een willekeurige variabele kan aannemen binnen een bepaald bereik, begrensd tussen de minimaal en maximaal mogelijke waarden, wordt genoemd een kansverdelingsfunctie (pdf) of waarschijnlijkheidsdichtheid. Elke pdf moet aan de volgende twee criteria voldoen:
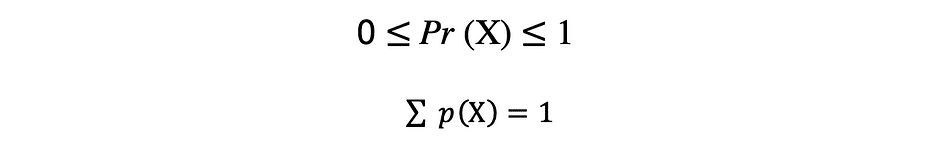
waarbij het eerste criterium stelt dat alle kansen getallen moeten zijn in het bereik van [0,1] en het tweede criterium stelt dat de som van alle mogelijke kansen gelijk moet zijn aan 1.
Kansfuncties worden gewoonlijk ingedeeld in twee categorieën: discreet en doorlopend. Discreet distributie functie beschrijft het willekeurige proces met telbaar voorbeeldruimte, zoals in het geval van een voorbeeld van het opgooien van een munt die slechts twee mogelijke uitkomsten heeft. Continu distributiefunctie beschrijft het willekeurige proces met doorlopend voorbeeldruimte. Voorbeelden van discrete verdelingsfuncties zijn Bernoulli, Binominaal, Vis, Discreet uniform. Voorbeelden van continue distributiefuncties zijn Normaal, Continu uniform, Cauchy.
Binomiale distributie
De binominale verdeling is de discrete kansverdeling van het aantal successen in een reeks van n onafhankelijke experimenten, elk met de booleaanse uitkomst: succes (met waarschijnlijkheid p) Of storing (met waarschijnlijkheid q = 1 ? P). Laten we aannemen dat een willekeurige variabele X een binominale verdeling volgt, en dan de waarneemkans k successen in n onafhankelijke proeven kunnen worden uitgedrukt door de volgende kansdichtheidsfunctie:
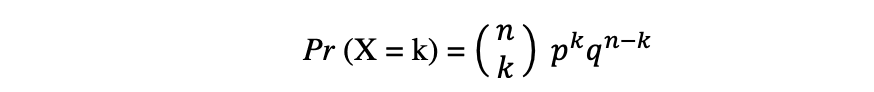
De binominale verdeling is handig bij het analyseren van de resultaten van herhaalde onafhankelijke experimenten, vooral als men geïnteresseerd is in de waarschijnlijkheid dat een bepaalde drempel wordt gehaald bij een bepaald foutenpercentage.
Binominale verdelingsgemiddelde en variantie
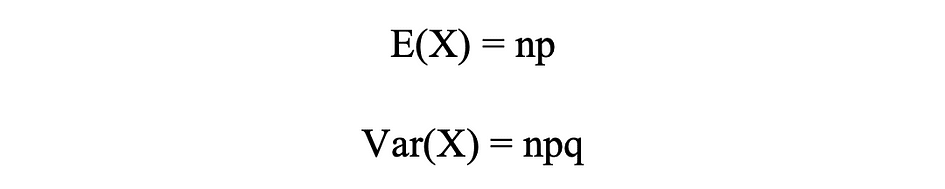
De onderstaande afbeelding visualiseert een voorbeeld van binominale verdeling waarbij het aantal onafhankelijke pogingen gelijk is aan 8 en de kans op succes in elke poging gelijk is aan 16%.
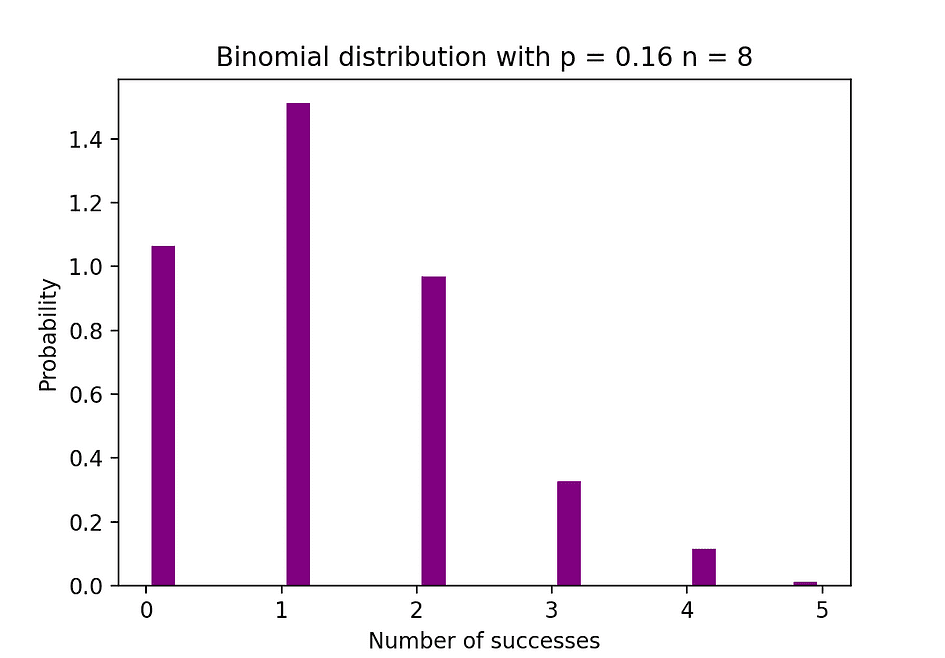
Afbeeldingsbron: de auteur
# Random Generation of 1000 independent Binomial samples
import numpy as np
n = 8
p = 0.16
N = 1000
X = np.random.binomial(n,p,N)
# Histogram of Binomial distribution
import matplotlib.pyplot as plt
counts, bins, ignored = plt.hist(X, 20, density = True, rwidth = 0.7, color = 'purple')
plt.title("Binomial distribution with p = 0.16 n = 8")
plt.xlabel("Number of successes")
plt.ylabel("Probability")
plt.show()Poisson Distributie
De Poisson-verdeling is de discrete kansverdeling van het aantal gebeurtenissen dat zich in een bepaalde tijdsperiode voordoet, gegeven het gemiddelde aantal keren dat de gebeurtenis zich in die tijdsperiode voordoet. Laten we aannemen dat een willekeurige variabele X een Poisson-verdeling volgt, en dan de waarneemkans k gebeurtenissen over een tijdsperiode kunnen worden uitgedrukt door de volgende waarschijnlijkheidsfunctie:
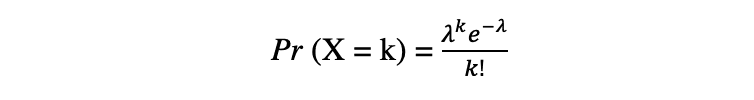
WAAR e is Euler's nummer en ? lambda, de aankomstsnelheidsparameter is de verwachte waarde van X. Poisson-verdelingsfunctie is erg populair vanwege het gebruik ervan bij het modelleren van telbare gebeurtenissen die binnen een bepaald tijdsinterval plaatsvinden.
Poisson-verdelingsgemiddelde en variantie
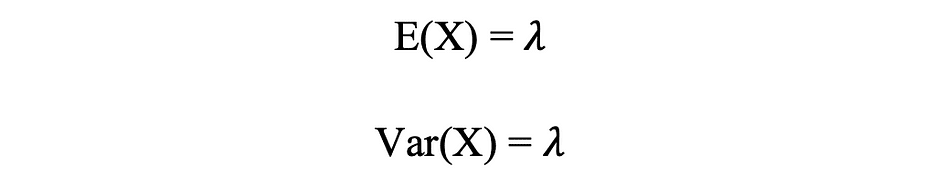
Poisson-distributie kan bijvoorbeeld worden gebruikt om het aantal klanten te modelleren dat tussen 7 en 10 uur in de winkel arriveert, of het aantal patiënten dat tussen 11 en 12 uur op de spoedeisende hulp arriveert. De onderstaande afbeelding visualiseert een voorbeeld van een Poisson-verdeling, waarbij we het aantal webbezoekers tellen dat op de website aankomt, waarbij wordt aangenomen dat de aankomstsnelheid, lambda, gelijk is aan 7 minuten.
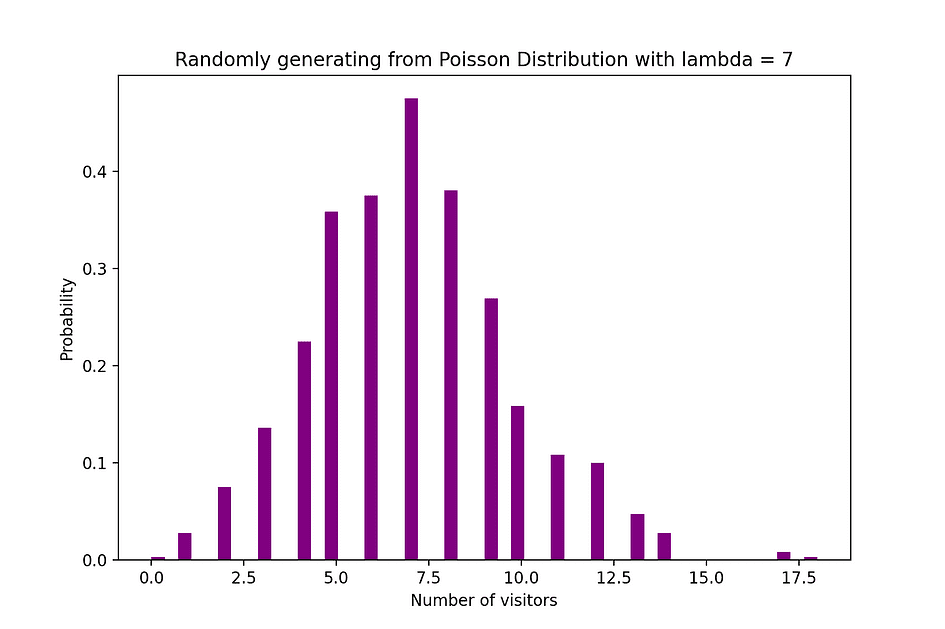
Afbeeldingsbron: de auteur
# Random Generation of 1000 independent Poisson samples
import numpy as np
lambda_ = 7
N = 1000
X = np.random.poisson(lambda_,N) # Histogram of Poisson distribution
import matplotlib.pyplot as plt
counts, bins, ignored = plt.hist(X, 50, density = True, color = 'purple')
plt.title("Randomly generating from Poisson Distribution with lambda = 7")
plt.xlabel("Number of visitors")
plt.ylabel("Probability")
plt.show()Normale verdeling
De normale kansverdeling waar is de continue kansverdeling voor een willekeurige variabele met reële waarde. Normale verdeling, ook wel genoemd Gaussische verdeling is misschien wel een van de meest populaire verdelingsfuncties die vaak worden gebruikt in de sociale en natuurwetenschappen voor modelleringsdoeleinden, het wordt bijvoorbeeld gebruikt om de lengte van mensen of testscores te modelleren. Laten we aannemen dat een willekeurige variabele X een normale verdeling volgt, dan kan de kansdichtheidsfunctie als volgt worden uitgedrukt.
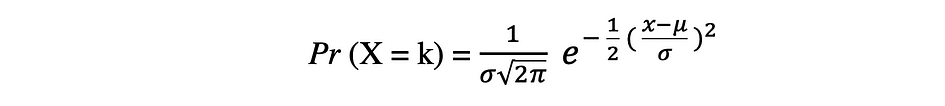
waar de parameter ? (mij) is het gemiddelde van de verdeling, ook wel de genoemd locatieparameter, parameter ? (sigma) is de standaarddeviatie van de verdeling, ook wel de genoemd schaalparameter:. Het nummer ? (pi) is een wiskundige constante die ongeveer gelijk is aan 3.14.
Normale verdeling gemiddelde & variantie
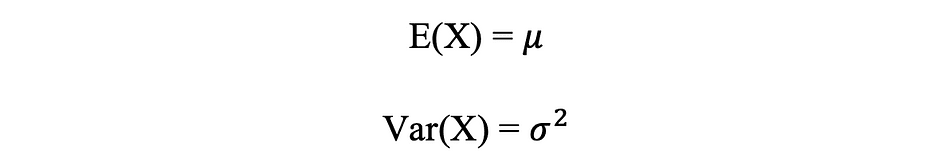
De onderstaande afbeelding visualiseert een voorbeeld van een normale verdeling met een gemiddelde van 0 (? = 0) en standaarddeviatie van 1 (? = 1), genaamd Standaard Normaal distributie wat is symmetrisch.
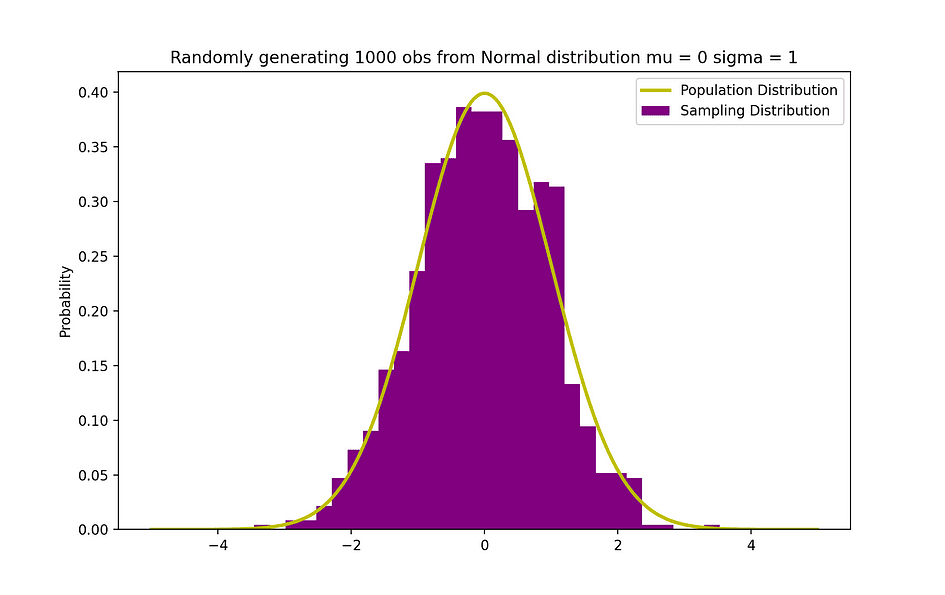
Afbeeldingsbron: de auteur
# Random Generation of 1000 independent Normal samples
import numpy as np
mu = 0
sigma = 1
N = 1000
X = np.random.normal(mu,sigma,N) # Population distribution
from scipy.stats import norm
x_values = np.arange(-5,5,0.01)
y_values = norm.pdf(x_values)
#Sample histogram with Population distribution
import matplotlib.pyplot as plt
counts, bins, ignored = plt.hist(X, 30, density = True,color = 'purple',label = 'Sampling Distribution')
plt.plot(x_values,y_values, color = 'y',linewidth = 2.5,label = 'Population Distribution')
plt.title("Randomly generating 1000 obs from Normal distribution mu = 0 sigma = 1")
plt.ylabel("Probability")
plt.legend()
plt.show()De stelling van Bayes of vaak genoemd Wet van Bayes is misschien wel de krachtigste regel van waarschijnlijkheid en statistiek, genoemd naar de beroemde Engelse statisticus en filosoof Thomas Bayes.

Bron afbeelding: Wikipedia
De stelling van Bayes is een krachtige waarschijnlijkheidswet die het concept van brengt subjectiviteit in de wereld van Statistiek en Wiskunde waar alles om feiten draait. Het beschrijft de waarschijnlijkheid van een gebeurtenis, gebaseerd op de voorafgaande informatie van voorwaarden die mogelijk verband houden met die gebeurtenis. Als bijvoorbeeld bekend is dat het risico op het krijgen van het coronavirus of covid-19 toeneemt met de leeftijd, dan kan de stelling van Bayes het risico voor een persoon van een bekende leeftijd nauwkeuriger bepalen door het te conditioneren op de leeftijd dan simpelweg aan te nemen dat deze persoon is gemeenschappelijk voor de bevolking als geheel.
Het concept van voorwaardelijke kans, die een centrale rol speelt in de theorie van Bayes, is een maat voor de waarschijnlijkheid dat een gebeurtenis plaatsvindt, gegeven dat er al een andere gebeurtenis heeft plaatsgevonden. De stelling van Bayes kan worden beschreven door de volgende uitdrukking waarbij de X en Y respectievelijk staan voor de gebeurtenissen X en Y:
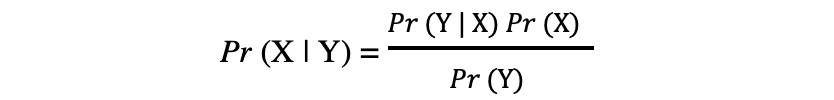
- Pr (X|Y): de waarschijnlijkheid dat gebeurtenis X zich voordoet, gegeven dat gebeurtenis of voorwaarde Y heeft plaatsgevonden of waar is
- Pr (Y|X): de waarschijnlijkheid dat gebeurtenis Y optreedt, gegeven dat gebeurtenis of voorwaarde X heeft plaatsgevonden of waar is
- Pr (X) & Pr (Y): de waarschijnlijkheid van het waarnemen van respectievelijk gebeurtenissen X en Y
In het geval van het eerdere voorbeeld is de kans om Coronavirus (gebeurtenis X) te krijgen afhankelijk van een bepaalde leeftijd Pr (X|Y), wat gelijk is aan de kans om op een bepaalde leeftijd te zijn als iemand een Coronavirus krijgt, Pr (Y|X), vermenigvuldigd met de kans op het krijgen van een Coronavirus, Pr (X), gedeeld door de kans om op een bepaalde leeftijd te zijn., Pr (J).
Eerder werd het concept van oorzakelijk verband tussen variabelen geïntroduceerd, wat gebeurt wanneer een variabele een directe impact heeft op een andere variabele. Wanneer de relatie tussen twee variabelen lineair is, dan is lineaire regressie een statistische methode die kan helpen om de impact van een eenheidsverandering in een variabele te modelleren, de onafhankelijke variabele op de waarden van een andere variabele, de afhankelijke variabele.
Afhankelijke variabelen worden vaak aangeduid als responsvariabelen or uitgelegd variabelen, terwijl onafhankelijke variabelen vaak worden aangeduid als regressoren or verklarende variabelen. Wanneer het lineaire regressiemodel is gebaseerd op een enkele onafhankelijke variabele, wordt het model aangeroepen Eenvoudige lineaire regressie en wanneer het model is gebaseerd op meerdere onafhankelijke variabelen, wordt dit aangeduid als Meerdere lineaire regressie. Eenvoudige lineaire regressie kan worden beschreven door de volgende uitdrukking:
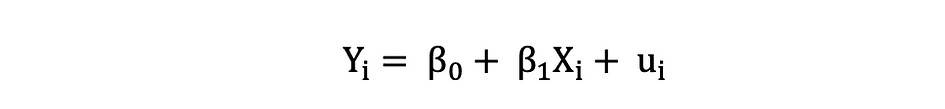
WAAR Y is de afhankelijke variabele, X is de onafhankelijke variabele die deel uitmaakt van de gegevens, ?0 is het snijpunt dat onbekend en constant is, ?1 is de hellingscoëfficiënt of een parameter die overeenkomt met de variabele X die ook onbekend en constant is. Eindelijk, u is de foutterm die het model maakt bij het schatten van de Y-waarden. Het belangrijkste idee achter lineaire regressie is het vinden van de best passende rechte lijn, de regressielijn, via een set gepaarde ( X, Y ) gegevens. Een voorbeeld van de toepassing Lineaire regressie is het modelleren van de impact van Flipper lengte op pinguïns' Lichaamsgewicht, die hieronder wordt gevisualiseerd.
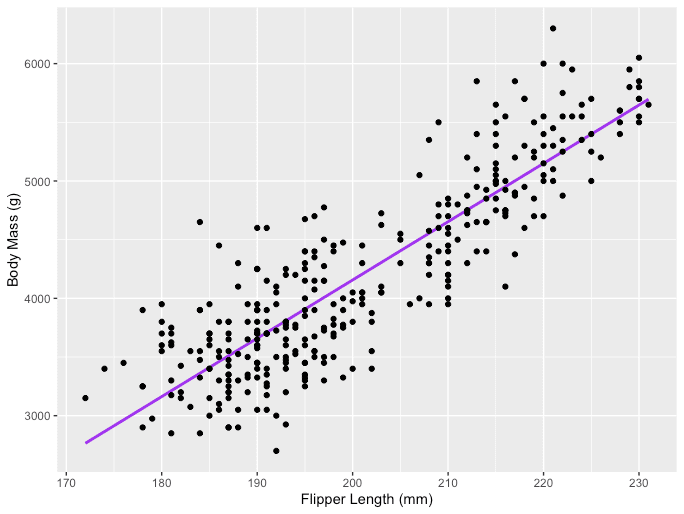
Afbeeldingsbron: de auteur
# R code for the graph
install.packages("ggplot2")
install.packages("palmerpenguins")
library(palmerpenguins)
library(ggplot2)
View(data(penguins))
ggplot(data = penguins, aes(x = flipper_length_mm,y = body_mass_g))+ geom_smooth(method = "lm", se = FALSE, color = 'purple')+ geom_point()+ labs(x="Flipper Length (mm)",y="Body Mass (g)")Meervoudige lineaire regressie met drie onafhankelijke variabelen kan worden beschreven met de volgende uitdrukking:
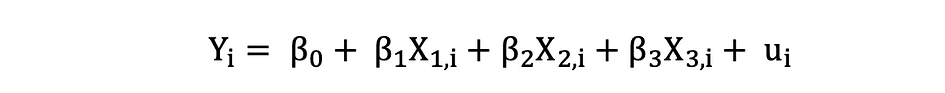
Gewone kleinste kwadraten
De gewone kleinste kwadraten (OLS) is een methode voor het schatten van de onbekende parameters zoals ?0 en ?1 in een lineair regressiemodel. Het model is gebaseerd op het principe van kleinste vierkantjes dat minimaliseert de som van de kwadraten van de verschillen tussen de waargenomen afhankelijke variabele en de waarden die worden voorspeld door de lineaire functie van de onafhankelijke variabele, vaak aangeduid als gepaste waarden. Dit verschil tussen de werkelijke en voorspelde waarden van afhankelijke variabele Y wordt aangeduid als overgebleven en wat OLS doet, is het minimaliseren van de som van gekwadrateerde residuen. Dit optimalisatieprobleem resulteert in de volgende OLS-schattingen voor de onbekende parameters ?0 en ?1, ook wel bekend als coëfficiënt schattingen.
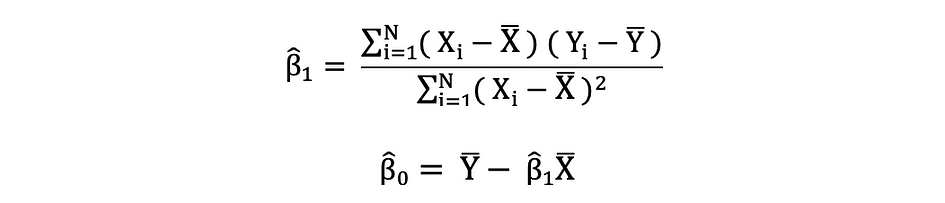
Zodra deze parameters van het Simple Linear Regression-model zijn geschat, wordt de gepaste waarden van de responsvariabele kan als volgt worden berekend:
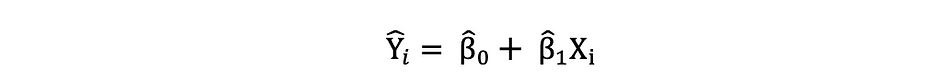
Standaardfout
De residuen of de geschatte fouttermen kunnen als volgt worden bepaald:
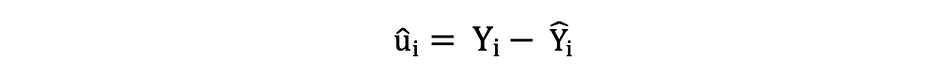
Het is belangrijk om het verschil tussen de fouttermen en residuen in gedachten te houden. Fouttermen worden nooit waargenomen, terwijl de residuen uit de gegevens worden berekend. De OLS schat de fouttermen voor elke waarneming, maar niet de werkelijke foutterm. De werkelijke foutvariantie is dus nog onbekend. Bovendien zijn deze schattingen onderhevig aan steekproefonzekerheid. Wat dit betekent is dat we nooit in staat zullen zijn om de exacte schatting, de werkelijke waarde, van deze parameters te bepalen op basis van voorbeeldgegevens in een empirische toepassing. We kunnen het echter schatten door de te berekenen monster resterende variantie door de residuen als volgt te gebruiken.
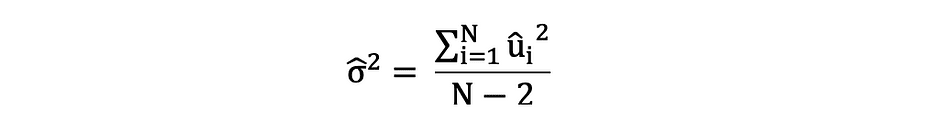
Deze schatting voor de variantie van steekproefresiduen helpt bij het schatten van de variantie van de geschatte parameters, die vaak als volgt wordt uitgedrukt:
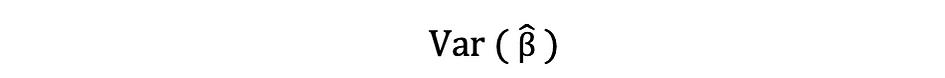
De vierkantswortel van deze variantieterm wordt genoemd de standaardfout van de schatting, wat een belangrijk onderdeel is bij het beoordelen van de nauwkeurigheid van de parameterschattingen. Het wordt gebruikt om teststatistieken en betrouwbaarheidsintervallen te berekenen. De standaardfout kan als volgt worden uitgedrukt:
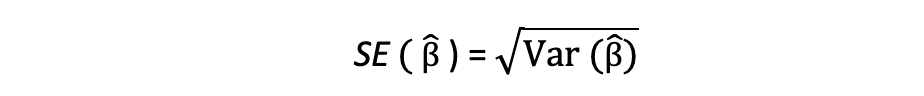
Het is belangrijk om het verschil tussen de fouttermen en residuen in gedachten te houden. Fouttermen worden nooit waargenomen, terwijl de residuen uit de gegevens worden berekend.
OLS-veronderstellingen
De OLS-schattingsmethode maakt de volgende aanname waaraan moet worden voldaan om betrouwbare voorspellingsresultaten te krijgen:
A1: Lineariteit aanname stelt dat het model lineair is in parameters.
A2: Random Voorbeeld van een Aanname stelt dat alle waarnemingen in de steekproef willekeurig zijn geselecteerd.
A3: Exogeniteit aanname stelt dat onafhankelijke variabelen niet gecorreleerd zijn met de fouttermen.
A4: homoskedasticiteit Aanname stelt dat de variantie van alle fouttermen constant is.
A5: geen perfecte multicollineariteit Aanname stelt dat geen van de onafhankelijke variabelen constant is en dat er geen exacte lineaire relaties zijn tussen de onafhankelijke variabelen.
def runOLS(Y,X): # OLS esyimation Y = Xb + e --> beta_hat = (X'X)^-1(X'Y) beta_hat = np.dot(np.linalg.inv(np.dot(np.transpose(X), X)), np.dot(np.transpose(X), Y)) # OLS prediction Y_hat = np.dot(X,beta_hat) residuals = Y-Y_hat RSS = np.sum(np.square(residuals)) sigma_squared_hat = RSS/(N-2) TSS = np.sum(np.square(Y-np.repeat(Y.mean(),len(Y)))) MSE = sigma_squared_hat RMSE = np.sqrt(MSE) R_squared = (TSS-RSS)/TSS # Standard error of estimates:square root of estimate's variance var_beta_hat = np.linalg.inv(np.dot(np.transpose(X),X))*sigma_squared_hat SE = [] t_stats = [] p_values = [] CI_s = [] for i in range(len(beta)): #standard errors SE_i = np.sqrt(var_beta_hat[i,i]) SE.append(np.round(SE_i,3)) #t-statistics t_stat = np.round(beta_hat[i,0]/SE_i,3) t_stats.append(t_stat) #p-value of t-stat p[|t_stat| >= t-treshhold two sided] p_value = t.sf(np.abs(t_stat),N-2) * 2 p_values.append(np.round(p_value,3)) #Confidence intervals = beta_hat -+ margin_of_error t_critical = t.ppf(q =1-0.05/2, df = N-2) margin_of_error = t_critical*SE_i CI = [np.round(beta_hat[i,0]-margin_of_error,3), np.round(beta_hat[i,0]+margin_of_error,3)] CI_s.append(CI) return(beta_hat, SE, t_stats, p_values,CI_s, MSE, RMSE, R_squared)In de veronderstelling dat aan de OLS-criteria A1 — A5 is voldaan, zijn de OLS-schatters van de coëfficiënten β0 en β1 WIT/BEIGE/BLAUW en Consistent.
Stelling van Gauss-Markov
Deze stelling benadrukt de eigenschappen van OLS-schattingen waar de term WIT/BEIGE/BLAUW staat voor Beste lineaire zuivere schatter.
Vooringenomenheid
De vooringenomenheid van een schatter is het verschil tussen de verwachte waarde en de werkelijke waarde van de parameter die wordt geschat en kan als volgt worden uitgedrukt:
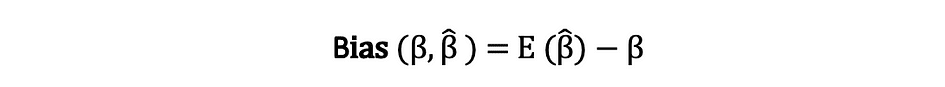
Als we stellen dat de schatter is onpartijdige wat we bedoelen is dat de bias gelijk is aan nul, wat inhoudt dat de verwachte waarde van de schatter gelijk is aan de werkelijke parameterwaarde, dat wil zeggen:

Onpartijdigheid garandeert niet dat de verkregen schatting met een bepaalde steekproef gelijk is aan of dicht bij ?. Wat het betekent is dat, als een herhaaldelijk willekeurige steekproeven trekt uit de populatie en vervolgens elke keer de schatting berekent, dan zou het gemiddelde van deze schattingen gelijk zijn aan of zeer dicht bij β liggen.
Efficiënt
De term Beste in de stelling van Gauss-Markov heeft betrekking op de variantie van de schatter en wordt aangeduid als doeltreffendheid. Een parameter kan meerdere schatters hebben, maar degene met de laagste variantie wordt efficiënt genoemd.
Consistentie
De term consistentie gaat hand in hand met de termen steekproefomvang en convergentie. Als de schatter convergeert naar de ware parameter als de steekproefomvang erg groot wordt, dan wordt gezegd dat deze schatter consistent is, dat wil zeggen:
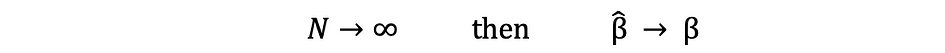
In de veronderstelling dat aan de OLS-criteria A1 — A5 is voldaan, zijn de OLS-schatters van de coëfficiënten β0 en β1 WIT/BEIGE/BLAUW en Consistent.
Stelling van Gauss-Markov
Al deze eigenschappen gelden voor OLS-schattingen zoals samengevat in de stelling van Gauss-Markov. Met andere woorden, OLS-schattingen hebben de kleinste variantie, ze zijn onbevooroordeeld, lineair in parameters en consistent. Deze eigenschappen kunnen wiskundig worden bewezen door de eerder gemaakte OLS-aannames te gebruiken.
Het betrouwbaarheidsinterval is het bereik dat de werkelijke populatieparameter bevat met een bepaalde vooraf gespecificeerde waarschijnlijkheid, ook wel de betrouwbaarheidsniveau van het experiment, en het wordt verkregen door gebruik te maken van de steekproefresultaten en de foutmarge.
Foutmarge
De foutmarge is het verschil tussen de resultaten van de steekproef en gebaseerd op wat het resultaat zou zijn geweest als men de hele populatie had gebruikt.
Betrouwbaarheidsniveau
Het betrouwbaarheidsniveau beschrijft het niveau van zekerheid in de experimentele resultaten. Een betrouwbaarheidsniveau van 95% betekent bijvoorbeeld dat als iemand hetzelfde experiment 100 keer herhaaldelijk zou uitvoeren, 95 van die 100 proeven tot vergelijkbare resultaten zouden leiden. Houd er rekening mee dat het betrouwbaarheidsniveau vóór de start van het experiment wordt gedefinieerd, omdat dit van invloed is op hoe groot de foutmarge aan het einde van het experiment zal zijn.
Betrouwbaarheidsinterval voor OLS-schattingen
Zoals eerder vermeld, zijn de OLS-schattingen van de eenvoudige lineaire regressie, de schattingen voor snijpunt ?0 en hellingscoëfficiënt ?1, onderhevig aan steekproefonzekerheid. We kunnen echter wel CI's construeren voor deze parameters die de werkelijke waarde van deze parameters in 95% van alle monsters zal bevatten. Dat wil zeggen, 95% betrouwbaarheidsinterval voor ? kan als volgt worden geïnterpreteerd:
- Het betrouwbaarheidsinterval is de reeks waarden waarvoor een hypothesetest niet kan worden verworpen tot een niveau van 5%.
- Het betrouwbaarheidsinterval heeft een kans van 95% om de werkelijke waarde van ? te bevatten.
95% betrouwbaarheidsinterval van OLS-schattingen kan als volgt worden samengesteld:
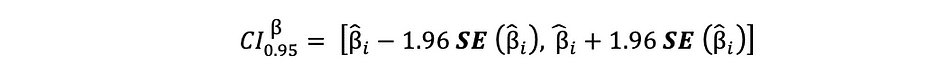
die is gebaseerd op de parameterschatting, de standaardfout van die schatting en de waarde 1.96 die de foutmarge vertegenwoordigt die overeenkomt met de afwijzingsregel van 5%. Deze waarde wordt bepaald aan de hand van de Normale verdelingstabel, die verderop in dit artikel worden besproken. Ondertussen illustreert de volgende afbeelding het idee van 95% BI:
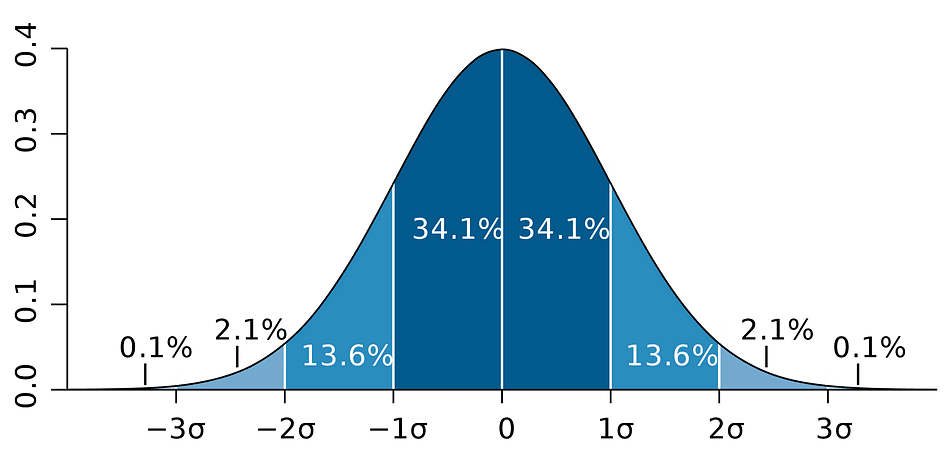
Bron afbeelding: Wikipedia
Merk op dat het betrouwbaarheidsinterval ook afhangt van de steekproefomvang, aangezien het wordt berekend met behulp van de standaardfout die is gebaseerd op de steekproefomvang.
Het betrouwbaarheidsniveau wordt gedefinieerd vóór de start van het experiment, omdat dit van invloed is op hoe groot de foutmarge aan het einde van het experiment zal zijn.
Het testen van een hypothese in Statistieken is een manier om de resultaten van een experiment of enquête te testen om te bepalen hoe betekenisvol de resultaten zijn. Kortom, men test of de verkregen resultaten geldig zijn door de kans te berekenen dat de resultaten door toeval zijn ontstaan. Als het de letter is, zijn de resultaten niet betrouwbaar en het experiment ook niet. Hypothesetesten maken deel uit van de Statistische gevolgtrekking.
Null en alternatieve hypothese
Eerst moet je bepalen welke scriptie je wilt toetsen, daarna moet je de scriptie formuleren Nul hypothese en Alternatieve hypothese. De test kan twee mogelijke uitkomsten hebben en op basis van de statistische resultaten kunt u de gestelde hypothese verwerpen of accepteren. Als vuistregel hebben statistici de neiging om de versie of formulering van de hypothese onder de nulhypothese te plaatsen dat moet worden afgewezen, terwijl de acceptabele en gewenste versie wordt vermeld onder de alternatieve hypothese.
Statistische significantie
Laten we eens kijken naar het eerder genoemde voorbeeld waarin het lineaire regressiemodel werd gebruikt om te onderzoeken of een pinguïn Flipper lengte, de onafhankelijke variabele, heeft invloed op Lichaamsgewicht, de afhankelijke variabele. We kunnen dit model formuleren met de volgende statistische uitdrukking:
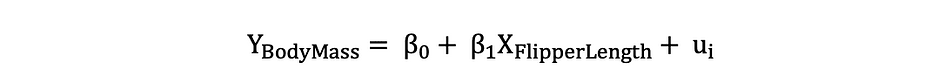
Als de OLS-schattingen van de coëfficiënten eenmaal zijn geschat, kunnen we de volgende nulhypothese en alternatieve hypothese formuleren om te testen of de flipperlengte een statistisch significant invloed op de lichaamsmassa:
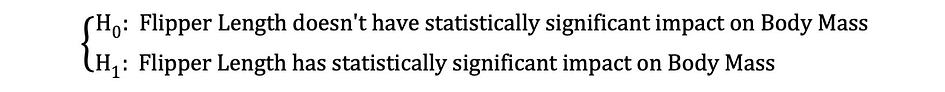
waarbij H0 en H1 respectievelijk de nulhypothese en de alternatieve hypothese vertegenwoordigen. Het verwerpen van de nulhypothese zou betekenen dat een toename van één eenheid in Flipper lengte heeft een directe invloed op de Body Mass. Aangezien de parameterschatting van ?1 deze impact van de onafhankelijke variabele beschrijft, Flipper lengte, op de afhankelijke variabele, Lichaamsgewicht. Deze hypothese kan als volgt worden geherformuleerd:
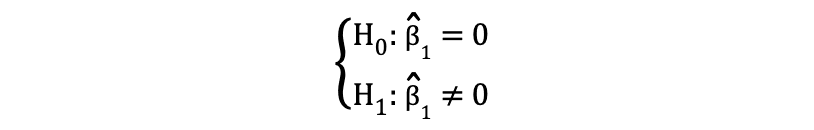
waarbij H0 stelt dat de parameterschatting van ?1 dus gelijk is aan 0 Flipper lengte effect op Body Mass is statistisch onbeduidend terwijl H0 stelt dat de parameterschatting van ?1 niet gelijk is aan 0, wat dat suggereert Flipper lengte effect op Body Mass is statistisch significant.
Type I- en Type II-fouten
Bij het uitvoeren van statistische hypothesetesten moet men rekening houden met twee conceptuele soorten fouten: Type I-fout en Type II-fout. De type I-fout treedt op wanneer de nulhypothese ten onrechte wordt verworpen, terwijl de type II-fout optreedt wanneer de nulhypothese ten onrechte niet wordt verworpen. Een verwarring Matrix kan helpen om de ernst van deze twee soorten fouten duidelijk te visualiseren.
Als vuistregel hebben statistici de neiging om de versie van de hypothese onder de te plaatsen Nul hypothese dat dat moet worden afgewezen, terwijl de acceptabele en gewenste versie wordt vermeld onder de Alternatieve hypothese.
Zodra de nulhypothese en de alternatieve hypothese zijn vermeld en de testaannames zijn gedefinieerd, is de volgende stap het bepalen welke statistische test geschikt is en het berekenen van de test statistiek. Het al dan niet verwerpen van de Null kan worden bepaald door de teststatistiek te vergelijken met de kritische waarde. Deze vergelijking laat zien of de waargenomen teststatistiek al dan niet extremer is dan de gedefinieerde kritische waarde en kan twee mogelijke resultaten hebben:
- De teststatistiek is extremer dan de kritische waarde? de nulhypothese kan worden verworpen
- De teststatistiek is niet zo extreem als de kritische waarde? de nulhypothese kan niet worden verworpen
De kritische waarde is gebaseerd op een vooraf gespecificeerde waarde mate van belangrijkheid ? (meestal gekozen om gelijk te zijn aan 5%) en het type kansverdeling dat de teststatistiek volgt. De kritische waarde verdeelt het gebied onder deze kansverdelingskromme in de afwijzingsgebied(en) en niet-afwijzende regio. Er zijn talloze statistische tests die worden gebruikt om verschillende hypothesen te testen. Voorbeelden van statistische tests zijn Studenten t-toets, F-test, Chi-kwadraat-test, Durbin-Hausman-Wu endogeniteitstest, white Heteroskedasticiteitstest. In dit artikel zullen we twee van deze statistische tests bekijken.
De type I-fout treedt op wanneer de nulhypothese ten onrechte wordt verworpen, terwijl de type II-fout optreedt wanneer de nulhypothese ten onrechte niet wordt verworpen.
Studenten t-toets
Een van de eenvoudigste en meest populaire statistische toetsen is de Student's t-toets. die kan worden gebruikt voor het testen van verschillende hypothesen, vooral wanneer het gaat om een hypothese waarbij het belangrijkste interessegebied is om bewijs te vinden voor het statistisch significante effect van een enkele variabele. De teststatistieken van de t-toets volgen Student's t-verdeling en kan als volgt worden bepaald:
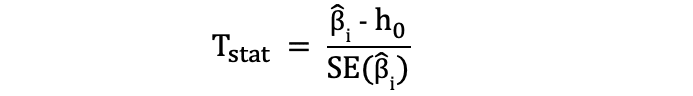
waarbij h0 in de teller de waarde is waartegen de parameterschatting wordt getoetst. De statistieken van de t-toets zijn dus gelijk aan de parameterschatting min de hypothetische waarde gedeeld door de standaardfout van de coëfficiëntschatting. In de eerder genoemde hypothese, waarin we wilden testen of Flipper Length een statistisch significante invloed heeft op Body Mass of niet. Deze toets kan worden uitgevoerd met behulp van een t-toets en de h0 is in dat geval gelijk aan de 0 aangezien de hellingscoëfficiëntschatting wordt getoetst aan de waarde 0.
Er zijn twee versies van de t-toets: a tweezijdige t-toets en eenzijdige t-toets. Of je de eerste of de laatste versie van de test nodig hebt, hangt helemaal af van de hypothese die je wilt testen.
De tweezijdige or tweezijdige t-toets kan worden gebruikt wanneer de hypothese wordt getest gelijk tegen niet gelijk relatie onder de nulhypothesen en alternatieve hypothesen die vergelijkbaar is met het volgende voorbeeld:
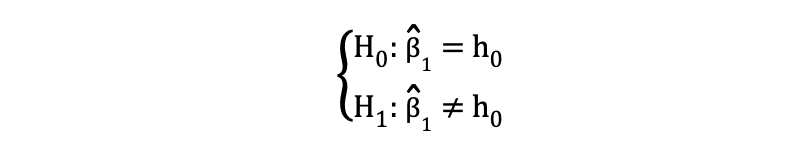
De tweezijdige t-toets heeft twee afwijzingsgebieden zoals gevisualiseerd in onderstaande figuur:
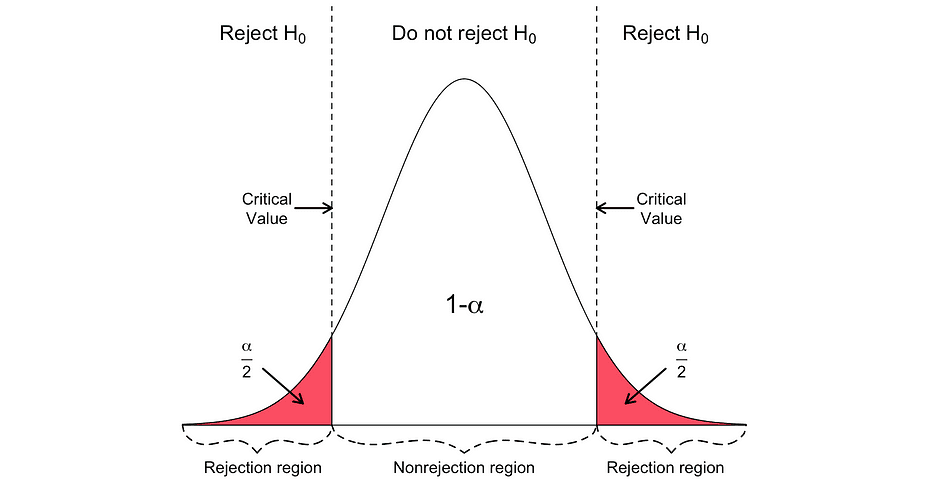
In deze versie van de t-toets wordt de Null verworpen als de berekende t-statistieken te klein of te groot zijn.
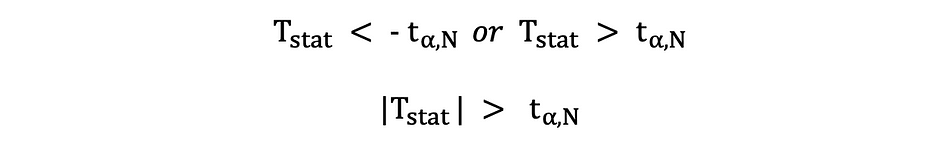
Hier worden de teststatistieken vergeleken met de kritische waarden op basis van de steekproefomvang en het gekozen significantieniveau. Om de exacte waarde van het afkappunt te bepalen, de tweezijdige t-verdelingstafel kunnen worden gebruikt.
De eenzijdige of eenzijdige t-toets kan worden gebruikt wanneer de hypothese wordt getest positief negatief tegen negatief positief relatie onder de nulhypothesen en alternatieve hypothesen die vergelijkbaar is met de volgende voorbeelden:
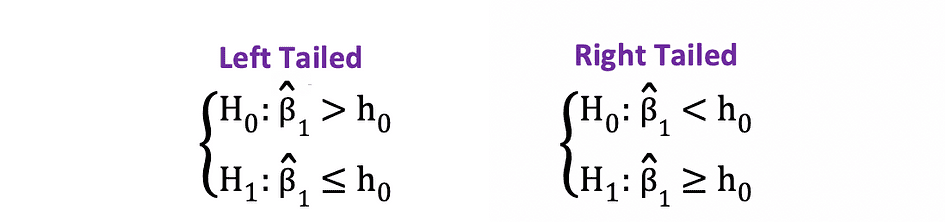
Eenzijdige t-toets heeft een single afwijzingsregio en afhankelijk aan de kant van de hypothese bevindt het afwijzingsgebied zich aan de linker- of rechterkant, zoals gevisualiseerd in de onderstaande figuur:
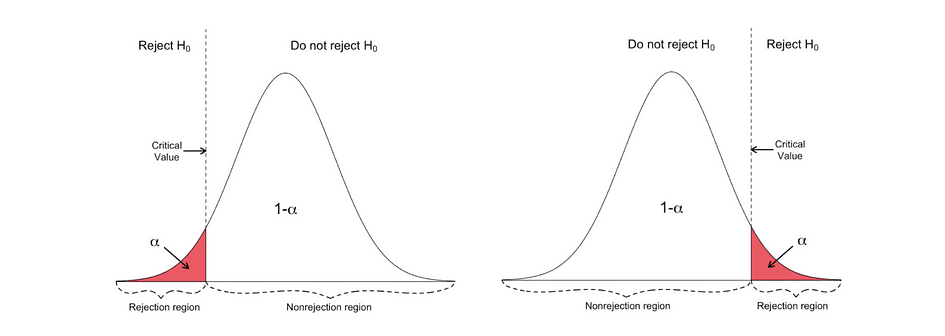
In deze versie van de t-toets wordt de Null verworpen als de berekende t-statistiek kleiner/groter is dan de kritische waarde.
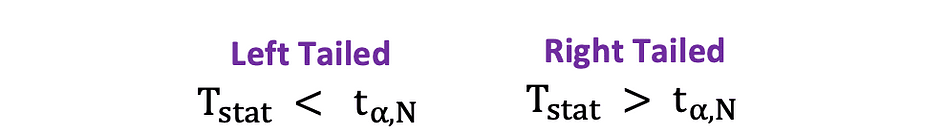
F-test
F-test is een andere zeer populaire statistische test die vaak wordt gebruikt om het testen van hypothesen te testen a gezamenlijke statistische significantie van meerdere variabelen. Dit is het geval wanneer je wilt testen of meerdere onafhankelijke variabelen een statistisch significante impact hebben op een afhankelijke variabele. Hieronder volgt een voorbeeld van een statistische hypothese die kan worden getest met behulp van de F-toets:
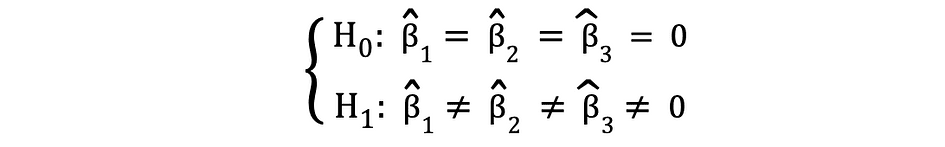
waarbij de nul stelt dat de drie variabelen die overeenkomen met deze coëfficiënten gezamenlijk statistisch niet significant zijn en de alternatieve stelt dat deze drie variabelen gezamenlijk statistisch significant zijn. De teststatistieken van de F-test volgen F distributie en kan als volgt worden bepaald:

waar de SSRbeperkt is de som van gekwadrateerde residuen van de begrensd model wat hetzelfde model is waarbij de doelvariabelen die onder de Null als onbeduidend zijn aangegeven, worden uitgesloten van de gegevens, de SSRunrestricted is de som van de gekwadrateerde residuen van de onbeperkt model dat is het model dat alle variabelen omvat, de q vertegenwoordigt het aantal variabelen dat gezamenlijk wordt getest op de onbeduidendheid onder de nul, N is de steekproefomvang en de k is het totale aantal variabelen in het onbeperkte model. SSR-waarden worden verstrekt naast de parameterschattingen na het uitvoeren van de OLS-regressie en hetzelfde geldt ook voor de F-statistieken. Hieronder volgt een voorbeeld van MLR-modeluitvoer waarbij de SSR- en F-statistiekwaarden zijn gemarkeerd.
Bron afbeelding: Voorraad en Whatson
F-test heeft een enkel afwijzingsgebied zoals hieronder gevisualiseerd:
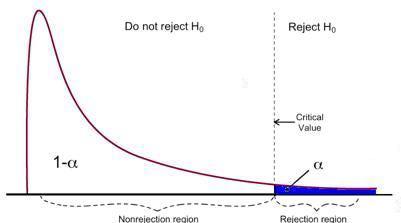
Bron afbeelding: U van Michigan
Als de berekende F-statistieken groter zijn dan de kritische waarde, kan de Null worden verworpen, wat suggereert dat de onafhankelijke variabelen gezamenlijk statistisch significant zijn. De afwijzingsregel kan als volgt worden uitgedrukt:
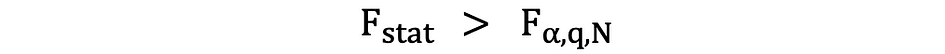
Een andere snelle manier om te bepalen of de nulhypothese moet worden verworpen of ondersteund, is door te gebruiken p-waarden. De p-waarde is de waarschijnlijkheid dat de aandoening onder de Null optreedt. Anders gezegd, de p-waarde is de waarschijnlijkheid, ervan uitgaande dat de nulhypothese waar is, om een resultaat te zien dat minstens zo extreem is als de teststatistiek. Hoe kleiner de p-waarde, des te sterker is het bewijs tegen de nulhypothese, wat suggereert dat deze verworpen kan worden.
De interpretatie van a p-waarde is afhankelijk van het gekozen significantieniveau. Meestal worden significantieniveaus van 1%, 5% of 10% gebruikt om de p-waarde te interpreteren. Dus in plaats van de t-toets en de F-toets te gebruiken, kunnen p-waarden van deze teststatistieken worden gebruikt om dezelfde hypothesen te testen.
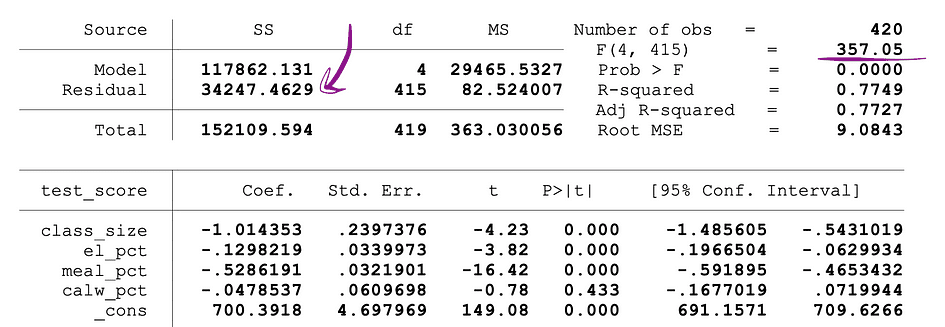
De volgende afbeelding toont een voorbeelduitvoer van een OLS-regressie met twee onafhankelijke variabelen. In deze tabel staat de p-waarde van de t-toets, waarmee de statistische significantie wordt getest klas grootte parameterschatting van de variabele, en de p-waarde van de F-test, waarbij de gezamenlijke statistische significantie van de wordt getest klas grootte, en el_pct variabelen parameterschattingen, zijn onderstreept.
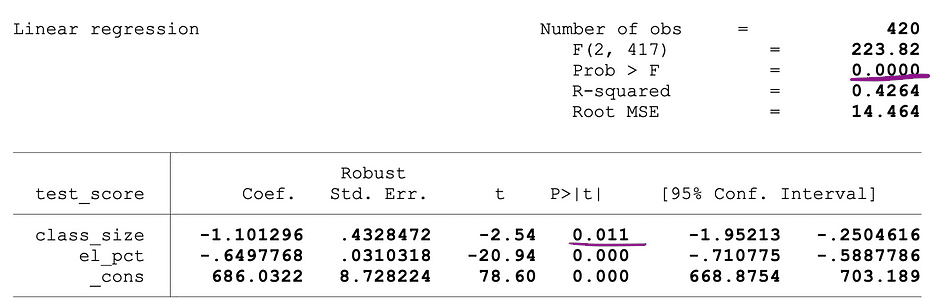
Bron afbeelding: Voorraad en Whatson
De p-waarde die overeenkomt met de klas grootte variabele is 0.011 en bij vergelijking van deze waarde met de significantieniveaus 1% of 0.01 , 5% of 0.05, 10% of 0.1, kunnen de volgende conclusies worden getrokken:
- 0.011 > 0.01 ? Nul van de t-toets kan niet worden verworpen bij een significantieniveau van 1%
- 0.011 < 0.05 ? Nul van de t-toets kan worden verworpen bij een significantieniveau van 5%
- 0.011 < 0.10 ? Null van de t-toets kan worden verworpen bij een significantieniveau van 10%
Deze p-waarde suggereert dus dat de coëfficiënt van de klas grootte variabele is statistisch significant bij significantieniveaus van 5% en 10%. De p-waarde die overeenkomt met de F-toets is 0.0000 en aangezien 0 kleiner is dan alle drie de afkapwaarden; 0.01, 0.05, 0.10, kunnen we concluderen dat de nul van de F-toets in alle drie de gevallen verworpen kan worden. Dit suggereert dat de coëfficiënten van klas grootte en el_pct variabelen zijn gezamenlijk statistisch significant bij significantieniveaus van 1%, 5% en 10%.
Beperking van p-waarden
Hoewel het gebruik van p-waarden veel voordelen heeft, heeft het ook beperkingen. De p-waarde hangt namelijk af van zowel de grootte van de associatie als de steekproefomvang. Als de grootte van het effect klein en statistisch niet-significant is, kan de p-waarde toch een a aangeven aanzienlijke impact omdat de grote steekproefomvang groot is. Het tegenovergestelde kan ook voorkomen, een effect kan groot zijn, maar niet voldoen aan de p<0.01, 0.05 of 0.10 criteria als de steekproefomvang klein is.
Inferentiële statistiek gebruikt steekproefgegevens om redelijke oordelen te vormen over de populatie waaruit de steekproefgegevens afkomstig zijn. Het wordt gebruikt om de relaties tussen variabelen binnen een steekproef te onderzoeken en voorspellingen te doen over hoe deze variabelen zich verhouden tot een grotere populatie.
Te gebruiken zowel Wet van grote getallen (LLN) en Centrale limietstelling (CLM) spelen een belangrijke rol in verklarende statistiek omdat ze laten zien dat de experimentele resultaten behouden blijven, ongeacht de vorm van de oorspronkelijke populatieverdeling als de gegevens groot genoeg zijn. Hoe meer gegevens worden verzameld, hoe nauwkeuriger de statistische gevolgtrekkingen worden, en dus hoe nauwkeuriger parameterschattingen worden gegenereerd.
Wet van grote getallen (LLN)
Veronderstellen X1, X2, . . . , Xn zijn allemaal onafhankelijke willekeurige variabelen met dezelfde onderliggende verdeling, ook wel onafhankelijk identiek verdeeld of iid genoemd, waarbij alle X'en hetzelfde gemiddelde hebben ? en standaarddeviatie ?. Naarmate de steekproef groter wordt, is de kans dat het gemiddelde van alle X-en gelijk is aan het gemiddelde ? is gelijk aan 1. De wet van de grote getallen kan als volgt worden samengevat:
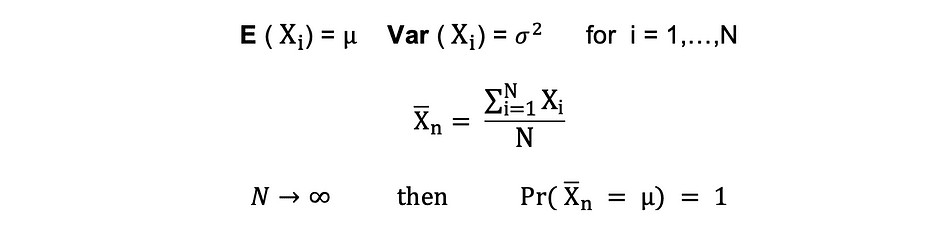
Centrale limietstelling (CLM)
Veronderstellen X1, X2, . . . , Xn zijn allemaal onafhankelijke willekeurige variabelen met dezelfde onderliggende verdeling, ook wel onafhankelijk identiek verdeeld of iid genoemd, waarbij alle X'en hetzelfde gemiddelde hebben ? en standaarddeviatie ?. Naarmate de steekproef groter wordt, neemt de kansverdeling van X convergeert in de verdeling in normale verdeling met gemiddelde ? en variantie ?-kwadraat. De centrale limietstelling kan als volgt worden samengevat:
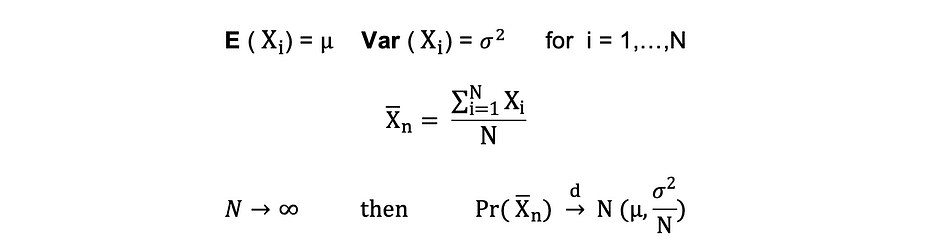
Anders gezegd, als je een populatie hebt met gemiddelde ? en standaarddeviatie? en je neemt voldoende grote steekproeven uit die populatie met vervanging, dan zal de verdeling van de steekproefgemiddelden ongeveer normaal verdeeld zijn.
Dimensionaliteitsreductie is de transformatie van gegevens van een hoogdimensionale ruimte een laagdimensionale ruimte zodanig dat deze laagdimensionale weergave van de gegevens zoveel mogelijk de betekenisvolle eigenschappen van de oorspronkelijke gegevens bevat.
Met de toename in populariteit in Big Data, nam ook de vraag toe naar deze technieken voor het verminderen van dimensionaliteit, waardoor de hoeveelheid onnodige gegevens en functies wordt verminderd. Voorbeelden van populaire technieken voor het verminderen van dimensionaliteit zijn Principe Componenten Analyse, Factoren analyse, Canonieke correlatie, Willekeurig bos.
Principe Componenten Analyse (PCA)
Principal Component Analysis of PCA is een dimensionaliteitsreductietechniek die heel vaak wordt gebruikt om de dimensionaliteit van grote datasets te verminderen, door een grote set variabelen om te zetten in een kleinere set die nog steeds de meeste informatie of de variatie in de oorspronkelijke grote dataset bevat. .
Laten we aannemen dat we een gegevens X hebben met p variabelen; X1, X2, …., Xp met eigenvectoren e1, …, ep, en eigenwaarden ?1,…, ?p. Eigenwaarden tonen de variantie verklaard door een bepaald gegevensveld uit de totale variantie. Het idee achter PCA is om nieuwe (onafhankelijke) variabelen te creëren, genaamd Principal Components, die een lineaire combinatie zijn van de bestaande variabele. de ikth hoofdcomponent kan als volgt worden uitgedrukt:
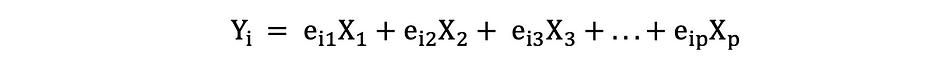
Dan gebruiken elleboog regel or Kaiser-regelkunt u het aantal hoofdcomponenten bepalen dat de gegevens optimaal samenvat zonder al te veel informatie te verliezen. Het is ook belangrijk om naar te kijken het aandeel van de totale variatie (PRTV) dat wordt uitgelegd door elke hoofdcomponent om te beslissen of het voordelig is om het op te nemen of uit te sluiten. PRTV voor de ith hoofdcomponent kan als volgt worden berekend met behulp van eigenwaarden:
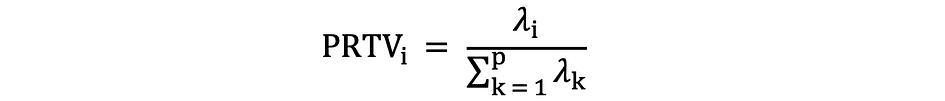
elleboog regel
De elleboogregel of de elleboogmethode is een heuristische benadering die wordt gebruikt om het aantal optimale hoofdcomponenten uit de PCA-resultaten te bepalen. Het idee achter deze methode is plotten de verklaarde variatie als functie van het aantal componenten en kies de bocht van de curve als het aantal optimale hoofdcomponenten. Hieronder volgt een voorbeeld van zo'n spreidingsplot waarbij de PRTV (Y-as) is uitgezet op het aantal hoofdcomponenten (X-as). De elleboog komt overeen met de X-aswaarde 2, wat suggereert dat het aantal optimale hoofdcomponenten 2 is.
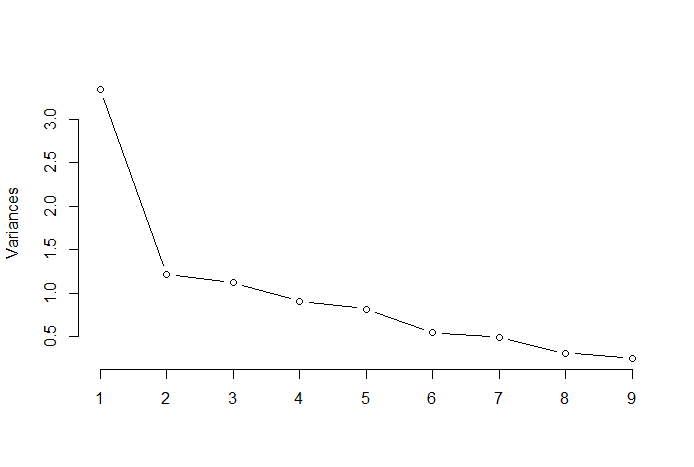
Bron afbeelding: Multivariate statistieken Github
Factoranalyse (FA)
Factoranalyse of FA is een andere statistische methode voor dimensionaliteitsreductie. Het is een van de meest gebruikte technieken voor onderlinge afhankelijkheid en wordt gebruikt wanneer de relevante set variabelen een systematische onderlinge afhankelijkheid vertoont en het doel is om de latente factoren te achterhalen die een gemeenschappelijkheid creëren. Laten we aannemen dat we een gegevens X hebben met p variabelen; X1, X2, …., XP. FA-model kan als volgt worden uitgedrukt:
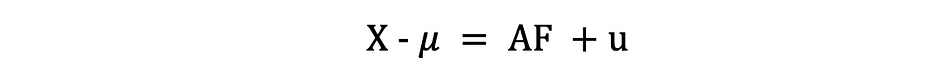
waarbij X een [px N] matrix is van p variabelen en N waarnemingen, µ is [px N] populatiegemiddelde matrix, A is [pxk] gemeenschappelijk factorladingen matrix, F [kx N] is de matrix van gemeenschappelijke factoren en u [pxN] is de matrix van specifieke factoren. Dus, anders gezegd, een factormodel is als een reeks van meerdere regressies, waarbij elk van de variabelen Xi wordt voorspeld op basis van de waarden van de niet-waarneembare gemeenschappelijke factoren fi:
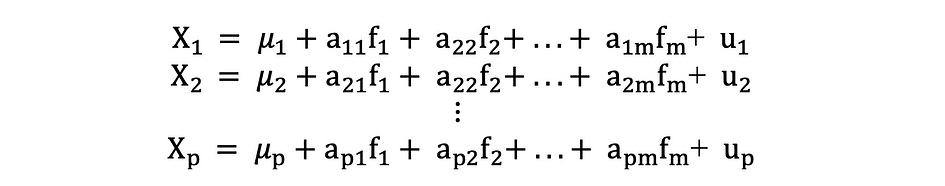
Elke variabele heeft k van zijn eigen gemeenschappelijke factoren, en deze zijn als volgt gerelateerd aan de waarnemingen via factorladingsmatrix voor een enkele waarneming: In factoranalyse is de factoren worden berekend maximaliseren variantie tussen groepen en minimaliseren van in-groep variantiee. Het zijn factoren omdat ze de onderliggende variabelen groeperen. In tegenstelling tot de PCA moeten de gegevens bij FA worden genormaliseerd, aangezien FA ervan uitgaat dat de dataset de normale verdeling volgt.
Tatev Karen Aslanyan is een ervaren full-stack datawetenschapper met een focus op Machine Learning en AI. Ze is ook mede-oprichter van Lunar Tech, een online tech-educatief platform, en de bedenker van The Ultimate Data Science Bootcamp. Tatev Karen, met Bachelor en Master in Econometrics and Management Science, is gegroeid op het gebied van Machine Learning en AI, gericht op Recommender Systems en NLP, ondersteund door haar wetenschappelijk onderzoek en gepubliceerde artikelen. Na vijf jaar lesgeven, kanaliseert Tatev nu haar passie in LunarTech en helpt ze de toekomst van datawetenschap vorm te geven.
ORIGINELE. Met toestemming opnieuw gepost.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/08/fundamentals-statistics-data-scientists-analysts.html?utm_source=rss&utm_medium=rss&utm_campaign=fundamentals-of-statistics-for-data-scientists-and-analysts

