Backtesting is een proces dat wordt gebruikt in kwantitatieve financiering om handelsstrategieën te evalueren met behulp van historische gegevens. Dit helpt handelaren de potentiële winstgevendheid van een strategie te bepalen en eventuele risico's te identificeren, waardoor ze deze kunnen optimaliseren voor betere prestaties.
Arbitrage voor het herbalanceren van indexen profiteert van prijsverschillen op korte termijn als gevolg van de inspanningen van ETF-beheerders om indexvolgfouten te minimaliseren. Belangrijke marktindexen, zoals de S&P 500, zijn onderhevig aan periodieke opnames en uitsluitingen om redenen die buiten het bestek van dit bericht vallen (zie bijvoorbeeld CoStar Group, Invitation Homes klaar om toe te treden tot S&P 500; Anderen sluiten zich aan bij S&P 100, S&P MidCap 400 en S&P SmallCap 600). De arbitragehandel probeert te profiteren van het long gaan op aandelen die aan een index zijn toegevoegd en het shorten van de verwijderde aandelen, met als doel winst te genereren uit deze prijsverschillen.
In dit bericht bekijken we het proces van het gebruik van backtesting om de prestaties van een winstgevendheidsstrategie voor indexarbitrage te evalueren. We onderzoeken specifiek hoe Amazon EMR en de nieuw ontwikkelde Apache Iceberg vertakking en tagging functie kan de uitdaging van look-ahead bias bij backtesting aanpakken. Dit zal een nauwkeurigere evaluatie mogelijk maken van de prestaties van de winstgevendheidsstrategie voor indexarbitrage.
Terminologie
Laten we eerst enkele van de terminologie bespreken die in dit bericht wordt gebruikt:
- Onderzoek datameer op Amazon S3 - A data lake is een grote, gecentraliseerde opslagplaats waarmee u al uw gestructureerde en ongestructureerde gegevens op elke schaal kunt beheren. Amazon eenvoudige opslagservice (Amazon S3) is een populaire cloudgebaseerde objectopslagservice die kan worden gebruikt als basis voor het bouwen van een datameer.
- Apache-ijsberg - Apache-ijsberg is een open-source tabelindeling die is ontworpen om efficiënte, schaalbare en veilige toegang tot grote datasets te bieden. Het biedt functies zoals ACID-transacties bovenop op Amazon S3 gebaseerde datalakes, schema-evolutie, partitie-evolutie en gegevensversiebeheer. Met schaalbare metadata-indexering kan Apache Iceberg performante query's leveren aan verschillende engines zoals Spark en Athena door de planningstijd te verkorten.
- Kijk-vooringenomenheid - Dit is een veelvoorkomende uitdaging bij backtesting, die optreedt wanneer toekomstige informatie onbedoeld wordt opgenomen in historische gegevens die worden gebruikt om een handelsstrategie te testen, wat leidt tot te optimistische resultaten.
- Ijsberg-tags – De ijsberg vertakkende en tagging-functie stelt gebruikers in staat om specifieke momentopnamen van hun gegevenstabellen te taggen met betekenisvolle labels met behulp van SQL-syntaxis of de Iceberg-bibliotheek, die overeenkomen met specifieke gebeurtenissen die opmerkelijk zijn voor interne investeringsteams. Dit, gecombineerd met IJsbergs tijdreizen functionaliteit, zorgt ervoor dat nauwkeurige gegevens de onderzoekspijplijn binnenkomen en beschermt deze tegen moeilijk te detecteren problemen zoals vooruitkijken.
Testbereik:
Overweeg het volgende voor onze testdoeleinden voorbeeld, waarin een wijziging in de S&P Dow Jones Indices wordt aangekondigd op 2 september 2022, van kracht wordt op 19 september 2022 en pas op 30 september zichtbaar wordt in de ETF-holdingsgegevens die we in het experiment zullen gebruiken, 2022. We gebruiken Iceberg-tags om momentopnamen van marktgegevens te labelen om vooruitziende blikken in het onderzoeksdatameer te voorkomen, waardoor we verschillende scenario's voor het betreden en verlaten van de handel kunnen testen en de respectieve winstgevendheid van elk kunnen beoordelen.
Experiment
Als onderdeel van ons experiment gebruiken we een betaalde, externe gegevensprovider API te identificeren SPY-ETF posities wijzigen en een portefeuille samenstellen. Onze modelportefeuille koopt aandelen die aan de index worden toegevoegd, ook wel long gaan genoemd, en verkoopt een gelijkwaardig aantal aandelen die uit de index worden verwijderd, ook wel long gaan genoemd. te kort.
We zullen korte bewaarperiodes testen, zoals 1 dag en 1, 2, 3 of 4 weken, omdat we ervan uitgaan dat het herbalancerende effect van zeer korte duur is en nieuwe informatie, zoals macro-economische gegevens, de prestaties verder zal stuwen dan de bestudeerde tijdshorizonten. Ten slotte simuleren we verschillende ingangspunten voor deze transactie:
- Markt open de dag na aankondigingsdag (AD+1)
- Marktsluiting van ingangsdatum (ED0)
- Markt open op de dag nadat ETF-holdings de wijziging registreerden (MD+1)
Onderzoek datameer
Om ons experiment uit te voeren, hebben we de volgende research data lake-omgeving gebruikt.

Zoals te zien is in het architectuurdiagram, is het datameer voor onderzoek gebouwd op Amazon S3 en beheerd met behulp van Apache Iceberg, een open tabelindeling die de betrouwbaarheid en eenvoud van RDBMS-tabellen (Relational Database Management Service) naar datameren brengt. Om vooringenomenheid bij backtesting te voorkomen, is het essentieel om momentopnamen van de gegevens op verschillende tijdstippen te maken. Het beheren en organiseren van deze momentopnamen kan echter een uitdaging zijn, vooral als het gaat om een grote hoeveelheid gegevens.
Dit is waar de tagging-functie in Apache Iceberg van pas komt. Met tagging kunnen onderzoekers snapshots van marktgegevens met verschillende namen maken en veranderingen in de loop van de tijd volgen. Ze kunnen bijvoorbeeld aan het einde van elke handelsdag een momentopname van de gegevens maken en deze taggen met de datum en eventuele relevante marktomstandigheden.
Door tags te gebruiken om de snapshots te ordenen, kunnen onderzoekers de gegevens eenvoudig opvragen en analyseren op basis van specifieke marktomstandigheden of gebeurtenissen, zonder zich zorgen te hoeven maken over de specifieke data van de gegevens. Dit kan met name handig zijn bij het uitvoeren van onderzoek dat niet tijdgevoelig is of bij het zoeken naar trends over een lange periode.
Bovendien kan de tagging-functie ook helpen bij andere aspecten van gegevensbeheer, zoals het bewaren van gegevens voor naleving van de AVG en het onderhouden van lijnen van de tafel via verschillende takken. Onderzoekers kunnen Apache Iceberg-tagging gebruiken om de integriteit en nauwkeurigheid van hun gegevens te waarborgen en tegelijkertijd het gegevensbeheer te vereenvoudigen.
Voorwaarden
Om deze walkthrough te volgen, moet u over het volgende beschikken:
- An AWS-account met een IAM-rol die voldoende toegang heeft om de vereiste resources in te richten.
- Om te voldoen aan licentieoverwegingen kunnen we geen voorbeeld geven van de gegevens van de ETF-bestanddelen. Daarom moet het apart worden aangeschaft voor de onboarding-doeleinden van de dataset.
Overzicht oplossingen
Om dit experiment op te zetten en te testen, doorlopen we de volgende stappen op hoog niveau:
- Maak een S3-bucket.
- Laad de dataset in Amazon S3. Voor dit bericht zijn de ETF-gegevens waarnaar wordt verwezen verkregen via een API-oproep via een externe provider, maar u kunt ook de volgende opties overwegen:
- U kunt het volgende gebruiken prescriptieve begeleiding, waarin wordt beschreven hoe gegevensopname van verschillende gegevensproviders in een datameer in Amazon S3 kan worden geautomatiseerd met behulp van AWS-gegevensuitwisseling.
- U kunt AWS Data Exchange ook gebruiken om te kiezen uit een reeks externe datasetproviders. Het vereenvoudigt het gebruik van gegevensbestanden, tabellen en API's voor uw specifieke behoeften.
- Ten slotte kunt u ook het volgende bericht raadplegen over hoe u AWS Data Exchange voor Amazon S3 kunt gebruiken om toegang te krijgen tot gegevens uit een providerbucket: Analyse van de impact van hervorming van de regelgeving op de aandelenmarkt met behulp van AWS- en Refinitiv-gegevens.
- Maak een EMR-cluster. U kunt dit gebruiken Zelfstudie Aan de slag met EMR of we gebruikten CDK om een EMR te implementeren in een EKS-omgeving met een aangepast beheerd eindpunt.
- Maak een EMR-notebook met EMR Studio. Voor onze testomgeving gebruikten we een op maat gemaakte Docker-image, die Iceberg v1.3 bevat. Raadpleeg voor instructies over het koppelen van een cluster aan een werkruimte Koppel een cluster aan een werkruimte.
- Configureer een Spark-sessie. U kunt meevolgen via onderstaande voorbeeld notebook.
- Maak een Iceberg-tabel en laad de testgegevens van Amazon S3 in de tabel.
- Tag deze gegevens om er een momentopname van te bewaren.
- Voer updates uit voor onze testgegevens en tag de bijgewerkte dataset.
- Voer gesimuleerde backtesting uit op onze testgegevens om het meest winstgevende startpunt voor een transactie te vinden.
Maak de experimentomgeving
We kunnen aan de slag met Iceberg door een tabel te maken via Spark SQL vanuit een bestaande weergave, zoals weergegeven in de volgende code:
Nu we een Iceberg-tabel hebben gemaakt, kunnen we deze gebruiken voor beleggingsonderzoek. Een van de belangrijkste kenmerken van Iceberg is de ondersteuning voor schaalbare gegevensversies. Dit betekent dat we wijzigingen in onze gegevens gemakkelijk kunnen volgen en kunnen terugdraaien naar eerdere versies zonder extra kopieën te maken. Omdat deze gegevens periodiek worden bijgewerkt, willen we benoemde momentopnamen van de gegevens kunnen maken, zodat kwantitatieve handelaren gemakkelijk toegang hebben tot consistente momentopnamen van gegevens die hun eigen bewaarbeleid hebben. Laten we in dit geval de dataset taggen om aan te geven dat deze de ETF-holdingsgegevens vertegenwoordigt vanaf Q1 2022:
Naarmate we verder gaan in de tijd en er in het derde kwartaal nieuwe gegevens beschikbaar komen, moeten we mogelijk bestaande gegevenssets bijwerken om deze wijzigingen weer te geven. In het volgende voorbeeld gebruiken we eerst een UPDATE-instructie om de aandelen te markeren als verlopen in de bestaande dataset met ETF-holdings. Dan gebruiken we het MERGE INTO statement op basis van matchingvoorwaarden zoals ISIN-code. Als er geen overeenkomst wordt gevonden tussen de bestaande dataset en de nieuwe dataset, worden de nieuwe gegevens als nieuwe records in de tabel ingevoegd en wordt de statuscode voor deze records op 'nieuw' gezet. Evenzo, als de bestaande dataset voorraden heeft die niet aanwezig zijn in de nieuwe dataset, blijven die records vervallen met de statuscode 'verlopen'. Tot slot, voor records waarbij een match is gevonden, worden de gegevens in de bestaande dataset bijgewerkt met de gegevens uit de nieuwe dataset en heeft het record een ongewijzigde statuscode. Met de ondersteuning van Iceberg voor efficiënt dataversiebeheer en transactionele consistentie, kunnen we erop vertrouwen dat onze data-updates correct en zonder datacorruptie worden toegepast.
Omdat we nu een nieuwe versie van de gegevens hebben, gebruiken we Iceberg-tagging om isolatie te bieden voor elke nieuwe versie van gegevens. In dit geval taggen we dit als Q3_2022 en laat kwantitatieve handelaren en andere gebruikers aan deze momentopname van de gegevens werken zonder te worden beïnvloed door voortdurende updates van de pijplijn:
Hierdoor is heel eenvoudig te zien welke aandelen worden toegevoegd en verwijderd. We kunnen de tijdreisfunctie van Iceberg gebruiken om de gegevens op een bepaalde driemaandelijkse tag te lezen. Laten we eerst eens kijken welke aandelen aan de index worden toegevoegd; dit zijn de rijen die in de Q3-snapshot staan, maar niet in de Q1-snapshot. Dan gaan we kijken welke voorraden er weggehaald worden; dit zijn de rijen die in de Q1-snapshot staan, maar niet in de Q3-snapshot:
Nu gebruiken we de delta verkregen in de voorgaande code om de volgende strategie te backtesten. Als onderdeel van het arbitrageproces voor het herbalanceren van de index, gaan we naar long-aandelen die aan de index worden toegevoegd en short-aandelen die uit de index worden verwijderd, en we zullen deze strategie testen voor zowel de ingangsdatum als de aankondigingsdatum. Als proof of concept van de twee verschillende lijsten hebben we PVH en PENN gekozen als verwijderde aandelen en CSGP en INVH als toegevoegde aandelen.
Om de onderstaande voorbeelden te volgen, moet u het notitieboek gebruiken dat in de Quant Research voorbeeld GitHub-repository.
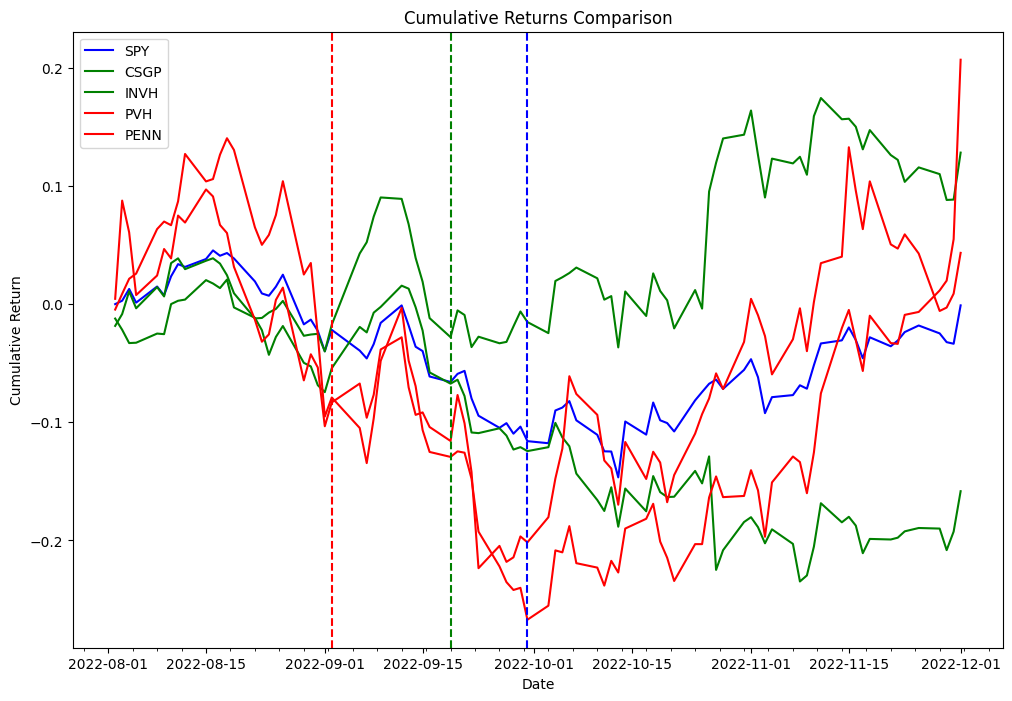
De volgende tabel geeft de records van de portfolio-orders weer:
| Order ID | Kolom | Tijdstempel | Maat | Prijs | vergoedingen | Kant |
|---|---|---|---|---|---|---|
| 0 | (PENNEN, PENNEN) | 2022-09-06 | 31948.881789 | 31.66 | 0.0 | Verkoop |
| 1 | (PVH, PVH) | 2022-09-06 | 18321.729571 | 55.15 | 0.0 | Verkoop |
| 2 | (INVH, INVH) | 2022-09-06 | 27419.797094 | 38.20 | 0.0 | Kopen |
| 3 | (CSGP, CSGP) | 2022-09-06 | 14106.361969 | 75.00 | 0.0 | Kopen |
| 4 | (CSGP, CSGP) | 2022-11-01 | 14106.361969 | 83.70 | 0.0 | Verkoop |
| 5 | (INVH, INVH) | 2022-11-01 | 27419.797094 | 31.94 | 0.0 | Verkoop |
| 6 | (PVH, PVH) | 2022-11-01 | 18321.729571 | 52.95 | 0.0 | Kopen |
| 7 | (PENNEN, PENNEN) | 2022-11-01 | 31948.881789 | 34.09 | 0.0 | Kopen |
Experimentele bevindingen
De volgende tabel toont Sharpe-ratio's voor verschillende periodes van bezit en twee verschillende ingangsmomenten voor transacties: aankondiging en ingangsdatums.

De gegevens suggereren dat de ingangsdatum het meest winstgevende startpunt is voor de meeste bezitsperioden, terwijl de aankondigingsdatum een effectief ingangspunt is voor korte termijn bezitsperioden (5 kalenderdagen, 2 werkdagen). Omdat de resultaten worden verkregen uit het testen van een enkele gebeurtenis, is dit niet statistisch significant om een hypothese te accepteren of te verwerpen dat indexherschikkingsgebeurtenissen kunnen worden gebruikt om consistente alfa te genereren. De infrastructuur die we voor onze tests hebben gebruikt, kan worden gebruikt om hetzelfde experiment uit te voeren dat nodig is om hypothesetests op schaal uit te voeren, maar gegevens over indexbestanddelen zijn niet direct beschikbaar.
Conclusie
In dit bericht hebben we laten zien hoe het gebruik van backtesting en de taggingfunctie van Apache Iceberg waardevolle inzichten kan opleveren in de prestaties van winstgevendheidsstrategieën voor indexarbitrage. Door gebruik te maken van een schaalbaar Amazon EMR op Amazon EKS stack kunnen onderzoekers gemakkelijk de volledige levenscyclus van investeringsonderzoek aan, van gegevensverzameling tot backtesting. Bovendien kan de Iceberg tagging-functie helpen om de uitdaging van look-ahead bias aan te gaan, terwijl het ook voordelen biedt zoals gegevensretentiebeheer voor naleving van de AVG en het behouden van de afstamming van de tabel via verschillende takken. De bevindingen van het experiment demonstreren de effectiviteit van deze aanpak bij het evalueren van de prestaties van indexarbitragestrategieën en kunnen dienen als een nuttige gids voor onderzoekers in de financiële sector.
Over de auteurs
 Boris Litvin is Principal Solution Architect, verantwoordelijk voor innovatie in de financiële dienstverlening. Hij is een voormalige oprichter van Quant en FinTech en heeft een passie voor systematisch beleggen.
Boris Litvin is Principal Solution Architect, verantwoordelijk voor innovatie in de financiële dienstverlening. Hij is een voormalige oprichter van Quant en FinTech en heeft een passie voor systematisch beleggen.
 Kerel Bachar is een Solutions Architect bij AWS, gevestigd in New York. Hij begeleidt greenfield-klanten en helpt hen op weg met hun cloudreis met AWS. Hij is gepassioneerd door identiteit, veiligheid en unified communications.
Kerel Bachar is een Solutions Architect bij AWS, gevestigd in New York. Hij begeleidt greenfield-klanten en helpt hen op weg met hun cloudreis met AWS. Hij is gepassioneerd door identiteit, veiligheid en unified communications.
 Noam Ouaknine is technisch accountmanager bij AWS en is gevestigd in Florida. Hij helpt zakelijke klanten bij het ontwikkelen en realiseren van hun langetermijnstrategie door middel van technische begeleiding en proactieve planning.
Noam Ouaknine is technisch accountmanager bij AWS en is gevestigd in Florida. Hij helpt zakelijke klanten bij het ontwikkelen en realiseren van hun langetermijnstrategie door middel van technische begeleiding en proactieve planning.
 Sercan Karaoglu is Senior Solutions Architect, gespecialiseerd in kapitaalmarkten. Hij is een voormalig data-ingenieur en gepassioneerd door kwantitatief beleggingsonderzoek.
Sercan Karaoglu is Senior Solutions Architect, gespecialiseerd in kapitaalmarkten. Hij is een voormalig data-ingenieur en gepassioneerd door kwantitatief beleggingsonderzoek.
 Jack Gij is een software-engineer in het Athena Data Lake en Storage-team. Hij is een Apache Iceberg Committer en PMC-lid.
Jack Gij is een software-engineer in het Athena Data Lake en Storage-team. Hij is een Apache Iceberg Committer en PMC-lid.
 Amogh Jahagirdar is Software Engineer in het Athena Data Lake-team. Hij is een Apache Iceberg Committer.
Amogh Jahagirdar is Software Engineer in het Athena Data Lake-team. Hij is een Apache Iceberg Committer.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/backtesting-index-rebalancing-arbitrage-with-amazon-emr-and-apache-iceberg/

