Wilt u gegevens extraheren uit patiëntregistratieformulieren? Probeer Nanonets OCR-software om velden te extraheren met een nauwkeurigheid van meer dan 98%+.
De gezondheidszorg herbergt een grote hoeveelheid gegevens, waarvan de meeste ongestructureerd en complex zijn. Persoonlijke gezondheidsinformatie is niet ten volle benut, aangezien de beschikbare gegevens gefragmenteerd en geïsoleerd zijn.
Maar als deze gegevens correct zouden kunnen worden geëxtraheerd en georganiseerd om nauwkeurige en betrouwbare informatie te creëren die zou kunnen worden gebruikt om zorgdoelen te bereiken van vroege detectie, vertraging van de progressie en preventie van meerdere ziekten, vermindering van hoge en groeiende zorgkosten en verbetering van de patiënt communicatie om een verbeterde patiëntenzorg in het algemeen te leveren.
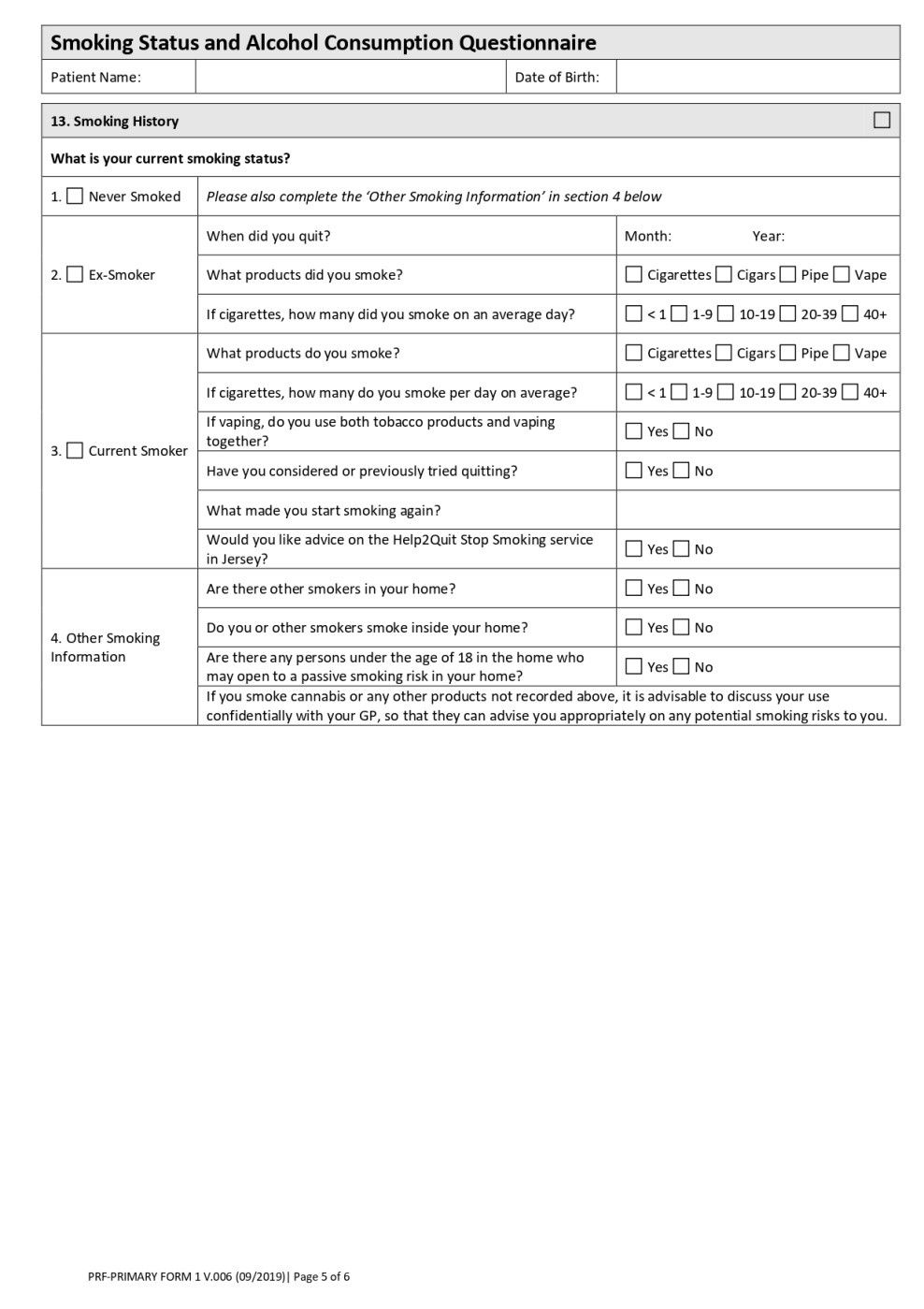
Patiëntregistratieformulier en wat staat er in?
Een patiëntregistratieformulier is een document dat wordt ingevuld door een patiënt die voor het eerst een zorginstelling bezoekt. Het stelt zorgverleners in staat om persoonlijke en gezondheidsgerelateerde informatie te verzamelen voordat ze worden geregistreerd om de beoogde zorg te ontvangen.
De inhoud van een Patiëntregistratieformulier verschilt per zorginstelling, maar de algemene inhoud is als volgt.
In het eerste deel wordt gevraagd naar de gegevens van de patiënt, waaronder naam, geslacht, geboortedatum, adres, burgerlijke staat, contactgegevens en identificatienummer in de vorm van een nationaal identiteits- of paspoortnummer.
Het tweede deel bevat de informatie over het personeel waarmee contact moet worden opgenomen in geval van nood, de nabestaanden of de wettelijke voogd van een minderjarige.
Het derde deel bevat informatie over het verzekeringsschema van de patiënt, inclusief de bedrijfsnaam, het verzekeringsnummer en de polis.
Het volgende gedeelte bevat het toestemmingsformulier van de patiënt, inclusief de patiëntverklaring, vertrouwelijkheidsovereenkomst en andere wettelijk bindende voorwaarden, die moeten worden ondertekend met de datum van de patiënt.
Daarnaast zijn er secties met de medische geschiedenis, de huidige medicijnen die de patiënt gebruikt, allergieën, familiegeschiedenis, geschiedenis van middelenmisbruik, enz.

A. Handmatige gegevensinvoer
Bij deze methode voert een operator de informatie in het patiëntregistratieformulier handmatig in een database in. Deze traditionele methoden voor gegevensinvoer zijn afhankelijk van operatorfactoren en zullen meer nadelen dan voordelen met zich meebrengen in vergelijking met geautomatiseerde systemen.
VOORDELEN
De kapitaaluitgaven zullen lager zijn in termen van training van operators en infrastructuur, aangezien handmatige gegevensinvoer geen hooggekwalificeerd personeel en geavanceerde software en hardware vereist om de gegevens te verzamelen en te presenteren.
NADELEN
Aangezien de medische dossiers vrij gedetailleerd zijn, duurt het extraheren van gegevens uren en kunnen er tijdens het typen en berekenen fouten in de zorginformatie worden toegevoegd, doordat richtlijnen en definities niet worden nageleefd, wat kan leiden tot niet-uniformiteit in gegevens. Dit kan trapsgewijze effecten veroorzaken die leiden tot slechte diagnoses, foutieve voorschriften en ongunstige resultaten voor de patiënt.
Vanwege de complexiteit van geëxtraheerde gegevens, gebruiken traditionele methoden slechts een beperkt aantal algemeen verzamelde variabelen voor voorspellingen. Dit kan valse positieven en valse alarmen bij patiënten veroorzaken, wat zou kunnen leiden tot alerte vermoeidheid, en klinisch significante gebeurtenissen zullen worden gemist, wat leidt tot slecht patiëntbeheer.
B. Elektronische medische dossiers (EPD)
EPD legt een grote hoeveelheid gegevens vast, die gefragmenteerd en geïsoleerd is over veel zorginstellingen, waaronder ziekenhuizen, huisartsenpraktijken, laboratoria, apotheken, enz.
VOORDELEN
EPD heeft het aantal fouten op operatorniveau bij het invoeren van gegevens, berekeningen en het niet naleven van richtlijnen en gegevensdefinities verminderd, waardoor medische fouten zijn verminderd. De kwaliteit van de zorg voor de patiënt is verbeterd, wat blijkt uit een onderzoek dat in 2011 onder artsen in de Verenigde Staten is uitgevoerd, waaruit blijkt dat EPD 65% van de mogelijke medicatiefouten heeft gewaarschuwd en 62% van kritische laboratoriumwaarden, waardoor de algehele patiëntenzorg met 78% is verbeterd.
De kosten voor gezondheidszorg zijn verlaagd door juiste diagnoses, passende onderzoeken en beheer na nauwkeurige voorspellingen gemaakt met behulp van EPD en deep learning-technieken.
Het gebruik van EPD maakte het proces van Health Information Exchange (HIE) mogelijk, waarbij informatie op patiëntniveau wordt gedeeld tussen verschillende organisaties. Dit heeft gezorgd voor gemakkelijke toegang voor artsen tot iemands medische dossiers wanneer patiënten medische hulp zoeken bij zorgverleners op verschillende locaties.
NADELEN
Verschillende zorginstellingen hebben iets andere formaten voor het presenteren van gegevens. Ondertussen verschillen de richtlijnen en kunnen de diagnoses die worden gesteld door de International Classification of Diseases (ICD) willekeurige fouten toevoegen aan EPD-voorspellingen. Daarom kan het ontbreken van een uniforme terminologie, systeemarchitectuur en indexering de verwachte voordelen van EPD verminderen.
EHR gaat gepaard met hoge opstartkosten voor hardware en operatortraining, die variabel kunnen zijn vanwege de ongelijkheid van gebruikers op het gebied van computerkennis en databaseverwerking.
De vertrouwelijkheid en veiligheid van de gevoelige informatie van patiënten staan op het spel omdat er een grote hoeveelheid gegevens wordt verzameld en er geen goede veiligheidsmaatregelen zijn getroffen.
C. Hybride benaderingen
Aangezien de informatie die beschikbaar is in EPD de vorm heeft van niet-standaard codes en structuren, zijn transformatie van gezondheidsgegevens en laadbenaderingen zoals Dynamic ETL (Extraction, Transformation, and Loading) in de praktijk gekomen om EPD-gegevens te herstructureren en om te zetten in een gemeenschappelijk formaat en standaardterminologieën om te harmoniseren tussen verschillende organisaties en onderzoeksdatanetwerken.
Nanonets is een op AI gebaseerde OCR-software (GDPR & SOC2-klacht) die medische gegevens kan automatiseren documentverwerking met workflows zonder code.
Nanonets kunnen meerdere stappen in de verwerking van zorgdocumenten automatiseren, waaronder:
document uploaden, data-extractie, gegevensverwerking (gegevens opschonen, formatteren, converteren), goedkeuringen en document archiveren.
Nanonets houdt zich aan uw specifieke vereisten en aangezien het een volledig no-code platform is, kan het door iedereen in de organisatie worden gebruikt.
Laten we eens kijken hoe u het kunt gebruiken om gegevens uit medische registratieformulieren te extraheren.
Ten eerste, om het te gebruiken, maak een gratis account aan op Nanonets of log in op uw account.
Selecteer een aangepast OCR-model. Om dit model te trainen, moet je tien medische rapporten overleggen.
Waarom moet ik dit doen? Als u tien medische documenten verstrekt, kunt u de AI trainen om uw document efficiënt te herkennen.
Eenmaal getraind, kunt u nu regels instellen om uw gegevens op te maken. U kunt het aantal nullen wijzigen of de waarde opzoeken in de database en meer met deze regels zonder code.

De volgende stap is het exporteren en selecteren op welke manier u de gegevens uit uw medische rapporten wilt exporteren. Verken de opties of selecteer een integratie en sluit deze rechtstreeks aan op uw EPD-systeem voor de gezondheidszorg.
Moet u meer doen? Plan een gesprek met onze AI-experts waar u uw use case aan ons kunt uitleggen, en we zullen workflows voor u opzetten.
Waarom Nanonets?
Nanonets is een intelligent OCR-platform. Er is geen sjabloon nodig om tekst van patiëntregistratieformulieren te identificeren. Het kan gemakkelijk tekst uit een niet-herkend document identificeren.
Het is gemakkelijk te gebruiken, kan in 1 dag worden ingesteld en zorgt voor een nauwkeurigheid van meer dan 99% tijdens het extraheren van gegevens.
Maar afgezien van de reguliere OCR-functies, is dit wat Nanonets onderscheidt:
Ongeëvenaarde beeldverwerking
Patiëntregistratieformulieren kunnen verschillende formaten hebben voor verschillende zorginstellingen. Nanonetten kunnen data-extractie uit elk document of elke afbeelding aan, wat niet perfect is om mee te beginnen. Met geavanceerde voor- en nabewerking kan het platform rechtzetten, heroriënteren, roteren, bijsnijden en fuzzy matching uitvoeren, zodat u elke keer de exacte gegevens van uw registratieformulieren krijgt.

Beste OCR in zijn klasse
Nanonetten kunnen gegevens uit uw medisch document halen met een nauwkeurigheid van meer dan 98%+. Het kan meer dan 40 talen detecteren en ondersteunt aangepaste OCR-ondersteuning.
Krachtige integraties
U kunt de invoer van gegevens in uw systemen eenvoudig automatiseren met Nanonets. Scan uw documenten en update patiëntprofielen in meer dan 500 bedrijfssoftware in realtime met Nanonets-integraties.
Geautomatiseerde aanpasbare workflows
Automatiseer documentscreening, onboarding van patiënten, gegevensopmaak, gegevensverrijking, verzameling van medische rapporten, gegevenssynchronisatie, documentmatching en meer met workflows zonder code. Voer gewoon uw regels in en zet het op de automatische pilootmodus.
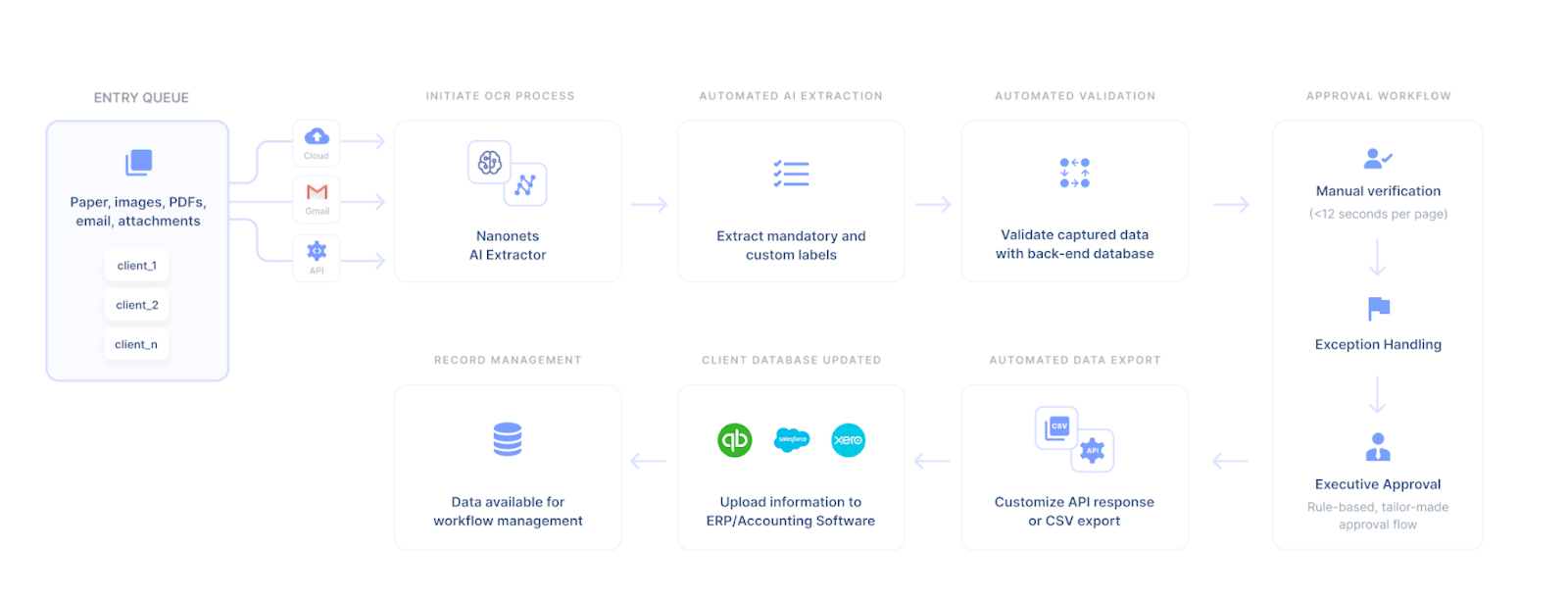
En meer. Nanonets kan worden aangepast aan uw behoeften en biedt white-label OCR-software en hostingopties op locatie of in de cloud.
Moet u gegevens uit patiëntregistratieformulieren halen?
Als dat zo is, ga naar Nanonets or plan een gesprek met ons team.
Technologie
Health Information Management Systemen die EPD gebruiken, vereisen dure netwerkverbindingen met snelle, betrouwbare internettoegang, hardware en software. Vanwege de hoge opstartkosten en de onbeschikbaarheid van betaalbare en effectieve technologie, zal het implementeren van op kunstmatige intelligentie gebaseerde methoden voor geautomatiseerde gegevensextractie slechts een consistent programma zijn bij sommige organisaties.
Gegevensbezit
Met de bestaande concurrentieverhoudingen tussen zorgaanbieders ontstaan problemen met betrekking tot het type en de hoeveelheid uitgewisselde informatie. De gedeelde eigendomsinformatie wordt door de technologieleveranciers beperkt tot 'alleen-lezen'. Er zal dus geen actuele informatie beschikbaar zijn.
Privacyzorgen van patiënten
Aangezien persoonlijke gezondheidsinformatie wordt behandeld, wordt het delen van informatie tussen organisaties alleen gedaan voor patiëntenzorg die zich houdt aan de privacywetgeving. Wettelijke aansprakelijkheden zijn verbonden om onwettige openbaarmaking van informatie te voorkomen; daarom moet het risico van schade bij gegevensuitwisseling altijd opwegen tegen mogelijke beloningen.
A. Verbeterde gegevensnauwkeurigheid
In plaats van trage, foutgevoelige traditionele methoden voor gegevensinvoer die waardevol personeelstalent verspillen, zorgt geautomatiseerde gegevensextractie voor grotere nauwkeurigheid bij herhaald gebruik.
Aangezien data-extractie uit EPD en vrije teksten worden opgenomen in deep learning-technieken, worden geldige en nauwkeurige voorspellingen gedaan over uiteenlopende zorgdomeinen met betrekking tot de kwaliteit en resultaten van zorg en gebruik van middelen. Betrouwbare en nauwkeurige informatie helpt bij het stellen van de juiste diagnose en het juiste beheer, waardoor de resultaten voor de patiënt verbeteren.
B. Verhoogde efficiëntie
De geautomatiseerde systemen zullen de gefragmenteerde en geïsoleerde persoonlijke gezondheidsinformatie, die nog niet ten volle moet worden benut, samenbrengen tot een gestructureerde vorm die de effectiviteit en efficiëntie van de geleverde zorg verbetert.
Uit een onderzoek uit 2016 bleek dat data-analisten slechts 20% van hun werkuren besteden aan data-analyse, terwijl de rest van de tijd wordt besteed aan het verzamelen en extraheren van de data. Geautomatiseerde data-extractie vermindert het personeelsbestand en de tijd die wordt verspild aan handmatige, foutgevoelige data-extractie en helpt hen om de patiëntenzorg te verbeteren.
C. Verbeterde patiëntenzorg
Mensen zullen vanaf verschillende locaties toegang krijgen tot zorginstellingen. Daarom zal een onderling verbonden en geautomatiseerd systeem zorgaanbieders een duidelijk beeld geven van de toestand van de patiënt en een consistent en effectief beheer kunnen bieden. 30 - 50% van de artsen in de Verenigde Staten heeft gemeld dat elektronische systemen nuttig zijn bij het bieden van aanbevolen zorg en passend onderzoek en een goede communicatie met de patiënt mogelijk maken door verbeterde algehele patiëntenzorg bij 78% van een onderzoekspopulatie.
D. Lagere kosten
Aangezien patiëntendossiers een veelheid aan gegevens over verschillende domeinen bevatten, zal handmatige gegevensinvoer tijdrovend en kostbaar zijn met een slecht gewaardeerd foutief resultaat. Hoewel geautomatiseerde gegevensextractie hoge opstartkosten met zich meebrengt, kan op de lange termijn een kostenbesparing worden bereikt wanneer reguliere repetitieve activiteiten die menselijke arbeid vergen, kunnen worden geautomatiseerd om gestructureerde en nauwkeurige gegevens en voorspellingen te verkrijgen.
In tegenstelling tot geïsoleerde gegevensverzameling, zal geautomatiseerde gegevensextractie en -compilatie centraal gecontroleerde databases met persoonlijke gezondheidsinformatie opleveren die door veel zorgverleners kunnen worden gebruikt, waardoor de kosten voor het dupliceren van gegevens worden verminderd.
E. Gestroomlijnde workflow en besluitvorming
EPD op basis van Fast Healthcare Interoperability Resources (FHIR) en deep learning-methoden kunnen nauwkeurige voorspellingen doen over medische gebeurtenissen in meerdere centra. Er worden voorspellingen gedaan over sterftecijfers, heropnames, duur van het ziekenhuisverblijf, enz. Dit zal helpen om de beschikbare middelen te beheren om aan de vraag te voldoen. De on-/semi-gestructureerde gegevens die uit een patiëntregistratieformulier worden gehaald, kunnen worden gebruikt om de effecten en tekortkomingen van de behandelingen en comorbiditeiten te identificeren en om het verwachte resultaat bij de patiënt met een bepaalde aandoening te bepalen.
Referenties:
- Choi, E., Schuetz, A., Stewart, WF, & Sun, J. (2016). Gebruik van terugkerende neurale netwerkmodellen voor vroege detectie van hartfalen. Tijdschrift van de American Medical Informatics Association, 24(2), 361-370. Koppeling: https://doi.org/10.1093/jamia/ocw112
- Jones, SS, Rudin, RS, Perry, T., & Shekelle, PG (2012). Gezondheidsinformatietechnologie: een bijgewerkte systematische review met een focus op zinvol gebruik. Annalen van interne geneeskunde, 156(1), 48-54. Koppeling: https://doi.org/10.7326/0003-4819-156-1-201201030-00007
- Kharrazi, H., Anzaldi, LJ, Hernandez, L., Davison, A., Boyd, CM, & Leff, B. (2018). Een stand van de wetenschap van de toepassing van digitale gezondheidstechnologieën voor het beheer van chronische aandoeningen. JMIR mHealth en uHealth, 6(4), e107. Koppeling: https://doi.org/10.2196/mhealth.8474
- King, J., Patel, V., Jamoom, EW, & Furukawa, MF (2014). Klinische voordelen van het gebruik van elektronische medische dossiers: nationale bevindingen. Onderzoek naar gezondheidsdiensten, 49(1 Pt 2), 392-404. Koppeling: https://doi.org/10.1111/1475-6773.12135
- Rajkomar, A., Oren, E., Chen, K., Dai, AM, Hajaj, N., Hardt, M., … & Sundberg, P. (2018). Schaalbaar en nauwkeurig deep learning met elektronische medische dossiers. NPJ Digitale Geneeskunde, 1(1), 1-10. Koppeling: https://doi.org/10.1038/s41746-018-0029-1
- Savova, GK, Masanz, JJ, Ogren, PV, Zheng, J., Sohn, S., Kipper-Schuler, KC, & Chute, CG (2010). Mayo klinische tekstanalyse en kennisextractiesysteem (cTAKES): architectuur, componentevaluatie en toepassingen. Tijdschrift van de American Medical Informatics Association, 17(5), 507-513. Koppeling: https://doi.org/10.1136/jamia.2009.001560
- Terry, NP (2012). Bescherming van de privacy van patiënten in het tijdperk van Big Data. UMKC Law Review, 81, 385. Link: https://ssrn.com/abstract=2108079
- Vest, JR, & Gamm, LD (2011). Uitwisseling van gezondheidsinformatie: aanhoudende uitdagingen en nieuwe strategieën. Tijdschrift van de American Medical Informatics Association, 17(3), 288-294. Koppeling: https://doi.org/10.1136/jamia.2010.003673
- Ong, TC, Kahn, MG, Kwan, BM, Yamashita, T., Brandt, E., Hosokawa, P., Uhrich, C., & Schilling, LM (2017). Dynamic-ETL: een hybride aanpak voor het extraheren, transformeren en laden van gezondheidsgegevens. BMC Medische Informatica en Besluitvorming, 17(1). https://doi.org/10.1186/s12911-017-0532-3
- Joseph, N., Lindblad, I., Zaker, S., Elfversson, S., Albinzon, M., Ødegård, Ø., Hantler, L., & Hellström, PM (2022). Geautomatiseerde gegevensextractie van elektronische medische dossiers: validiteit van datamining om onderzoeksdatabases op te bouwen om in aanmerking te komen voor gastro-enterologische klinische onderzoeken. Upsala Journal of Medische Wetenschappen, 127. https://doi.org/10.48101/ujms.v127.8260
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://nanonets.com/blog/automate-data-extraction-from-patient-registration-forms/

