generatieve AI agenten zijn een veelzijdig en krachtig hulpmiddel voor grote ondernemingen. Ze kunnen de operationele efficiëntie, klantenservice en besluitvorming verbeteren, terwijl ze de kosten verlagen en innovatie mogelijk maken. Deze agenten blinken uit in het automatiseren van een breed scala aan routinematige en repetitieve taken, zoals gegevensinvoer, vragen over klantenondersteuning en het genereren van inhoud. Bovendien kunnen ze complexe, uit meerdere stappen bestaande workflows orkestreren door taken op te splitsen in kleinere, beheersbare stappen, verschillende acties te coördineren en de efficiënte uitvoering van processen binnen een organisatie te garanderen. Dit vermindert de druk op de menselijke hulpbronnen aanzienlijk en stelt werknemers in staat zich te concentreren op meer strategische en creatieve taken.
Naarmate de AI-technologie zich blijft ontwikkelen, wordt verwacht dat de mogelijkheden van generatieve AI-agenten zullen toenemen, waardoor klanten nog meer mogelijkheden krijgen om een concurrentievoordeel te behalen. In de voorhoede van deze evolutie zit Amazonebodem, een volledig beheerde service die goed presterende funderingsmodellen (FM's) van Amazon en andere toonaangevende AI-bedrijven beschikbaar maakt via een API. Met Amazon Bedrock kun je generatieve AI-applicaties bouwen en schalen met beveiliging, privacy en verantwoorde AI. Je kunt nu gebruiken Agenten voor Amazon Bedrock en Kennisbanken voor Amazon Bedrock om gespecialiseerde agenten te configureren die naadloos acties uitvoeren op basis van natuurlijke taalinvoer en de gegevens van uw organisatie. Deze beheerde agenten spelen de dirigent en orkestreren de interacties tussen FM's, API-integraties, gebruikersgesprekken en kennisbronnen boordevol uw gegevens.
In dit bericht wordt belicht hoe u agenten en kennisbanken voor Amazon Bedrock kunt gebruiken om voort te bouwen op bestaande bedrijfsbronnen om de taken die verband houden met de levenscyclus van verzekeringsclaims te automatiseren, de klantenservice efficiënt te schalen en te verbeteren, en de beslissingsondersteuning te verbeteren door verbeterd kennisbeheer. Je door Amazon Bedrock ondersteunde verzekeringsagent kan menselijke agenten helpen door nieuwe claims aan te maken, openstaande documentherinneringen voor openstaande claims te verzenden, claimbewijs te verzamelen en te zoeken naar informatie in bestaande claims en klantkennisopslagplaatsen.
Overzicht oplossingen
Het doel van deze oplossing is om als basis voor klanten te fungeren, waardoor u uw eigen gespecialiseerde agenten kunt creëren voor verschillende behoeften, zoals virtuele assistenten en automatiseringstaken. De code en bronnen die nodig zijn voor de implementatie zijn beschikbaar in de Amazon-bedrock-voorbeelden repository.
De volgende demo-opname belicht de functionaliteit van agenten en kennisbanken voor Amazon Bedrock en technische implementatiedetails.
Agenten en kennisbanken voor Amazon Bedrock werken samen om de volgende mogelijkheden te bieden:
- Taakorkestratie – Agenten gebruiken FM's om vragen in natuurlijke taal te begrijpen en taken die uit meerdere stappen bestaan, op te splitsen in kleinere, uitvoerbare stappen.
- Interactieve gegevensverzameling – Agenten voeren natuurlijke gesprekken om aanvullende informatie van gebruikers te verzamelen.
- Taakvervulling – Agenten voltooien klantverzoeken via een reeks redeneerstappen en bijbehorende acties op basis van ReAct-prompts.
- Systeemintegratie – Agenten voeren API-aanroepen uit naar geïntegreerde bedrijfssystemen om specifieke acties uit te voeren.
- Gegevens opvragen – Kennisbanken verbeteren de nauwkeurigheid en prestaties door volledig beheerd Ophalen Augmented Generation (RAG) met behulp van klantspecifieke databronnen.
- Bronvermelding – Agenten voeren brontoewijzing uit en identificeren en traceren de oorsprong van informatie of acties door middel van gedachteketenredenering.
Het volgende diagram illustreert de oplossingsarchitectuur.
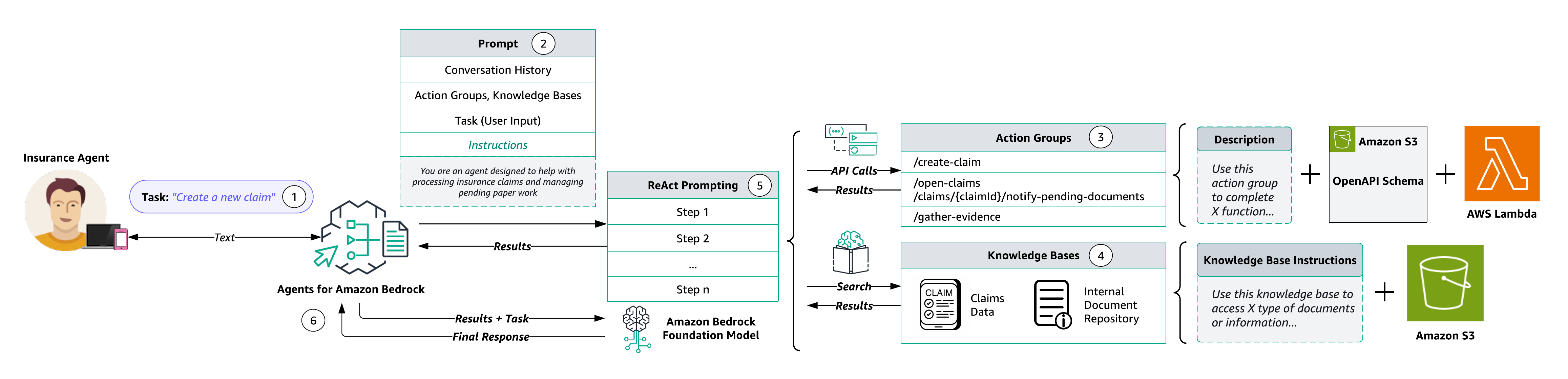
De workflow bestaat uit de volgende stappen:
- Gebruikers leveren natuurlijke taalinvoer aan de agent. Hieronder volgen enkele voorbeeldaanwijzingen:
- Maak een nieuwe claim aan.
- Stuur een herinnering aan openstaande documenten naar de verzekeringnemer van claim 2s34w-8x.
- Verzamel bewijsmateriaal voor claim 5t16u-7v.
- Wat is het totale claimbedrag voor claim 3b45c-9d?
- Wat is de totale reparatieschatting voor diezelfde claim?
- Welke factoren bepalen de premie van mijn autoverzekering?
- Hoe kan ik de tarieven van mijn autoverzekering verlagen?
- Welke claims hebben een open status?
- Stuur herinneringen naar alle polishouders met openstaande claims.
- Tijdens de voorverwerking valideert, contextualiseert en categoriseert de agent de gebruikersinvoer. De gebruikersinvoer (of taak) wordt door de agent geïnterpreteerd met behulp van de chatgeschiedenis en de instructies en onderliggende FM die tijdens de chat zijn opgegeven creatie van agenten. De instructies van de agent zijn beschrijvende richtlijnen waarin de beoogde acties van de agent worden beschreven. Ook kunt u optioneel configureren geavanceerde aanwijzingen, waarmee u de nauwkeurigheid van uw agent kunt vergroten door meer gedetailleerde configuraties te gebruiken en handmatig geselecteerde voorbeelden aan te bieden voor prompts in enkele stappen. Met deze methode kunt u de prestaties van het model verbeteren door gelabelde voorbeelden aan te bieden die aan een bepaalde taak zijn gekoppeld.
- Actie groepen zijn een set API's en bijbehorende bedrijfslogica, waarvan het OpenAPI-schema wordt gedefinieerd als JSON-bestanden die zijn opgeslagen in Amazon eenvoudige opslagservice (Amazone S3). Dankzij het schema kan de agent rond de functie van elke API redeneren. Elke actiegroep kan een of meer API-paden specificeren, waarvan de bedrijfslogica via de AWS Lambda functie verbonden aan de actiegroep.
- Knowledge Bases voor Amazon Bedrock biedt een volledig beheerde RAG om de agent toegang te geven tot uw gegevens. U configureert eerst de kennisbank door een beschrijving op te geven die de agent instrueert wanneer hij uw kennisbank moet gebruiken. Vervolgens verwijst u de kennisbank naar uw Amazon S3-gegevensbron. Ten slotte specificeert u een inbeddingsmodel en kiest u ervoor om uw bestaande vectorwinkel te gebruiken of Amazon Bedrock de vectorwinkel namens u te laten maken. Nadat het is geconfigureerd, wordt elk synchronisatie van gegevensbronnen creëert vectorinsluitingen van uw gegevens die de agent kan gebruiken om informatie terug te sturen naar de gebruiker of om daaropvolgende FM-prompts aan te vullen.
- Tijdens de orkestratie ontwikkelt de agent een grondgedachte met de logische stappen waarvan actiegroep-API-aanroepen en kennisbankquery's nodig zijn om een observatie te genereren die kan worden gebruikt om de basisprompt voor de onderliggende FM uit te breiden. Deze prompt in ReAct-stijl dient als input voor het activeren van de FM, die vervolgens anticipeert op de meest optimale reeks acties om de taak van de gebruiker te voltooien.
- Tijdens de nabewerking, nadat alle orkestratie-iteraties zijn voltooid, stelt de agent een definitief antwoord samen. Nabewerking is standaard uitgeschakeld.
In de volgende secties bespreken we de belangrijkste stappen om de oplossing te implementeren, inclusief pre-implementatiestappen en testen en validatie.
Creëer oplossingsbronnen met AWS CloudFormation
Voordat u uw agent- en kennisbank aanmaakt, is het essentieel om een gesimuleerde omgeving op te zetten die nauw aansluit bij de bestaande bronnen die door klanten worden gebruikt. Agenten en kennisbanken voor Amazon Bedrock zijn ontworpen om op deze bronnen voort te bouwen, met behulp van door Lambda geleverde bedrijfslogica en opslagplaatsen voor klantgegevens die zijn opgeslagen in Amazon S3. Deze fundamentele afstemming zorgt voor een naadloze integratie van uw agent- en kennisbankoplossingen met uw bestaande infrastructuur.
Om de bestaande klantresources te emuleren die door de agent worden gebruikt, maakt deze oplossing gebruik van de create-customer-resources.sh shell-script om het inrichten van de geparametriseerde bestanden te automatiseren AWS CloudFormatie sjabloon, bedrock-customer-resources.yml, om de volgende bronnen in te zetten:
- An Amazon DynamoDB tafel gevuld met synthetisch gegevens claimen.
- Drie Lambda-functies die de bedrijfslogica van de klant vertegenwoordigen voor het creëren van claims, het verzenden van openstaande documentherinneringen voor claims met een open status en het verzamelen van bewijsmateriaal over nieuwe en bestaande claims.
- Een S3-bucket met API-documentatie in OpenAPI-schema-indeling voor de voorgaande Lambda-functies en de reparatieschattingen, claimbedragen, veelgestelde vragen over bedrijven en vereiste claimdocumentbeschrijvingen die als onze moeten worden gebruikt kennisbankgegevensbronmiddelen.
- An Amazon eenvoudige meldingsservice (Amazon SNS) onderwerp waarop de e-mails van polishouders zijn geabonneerd voor e-mailwaarschuwingen over de claimstatus en lopende acties.
- AWS Identiteits- en toegangsbeheer (IAM)-machtigingen voor de voorgaande bronnen.
AWS CloudFormation vult de stapelparameters vooraf in met de standaardwaarden uit de sjabloon. Om alternatieve invoerwaarden op te geven, kunt u parameters opgeven als omgevingsvariabelen waarnaar wordt verwezen in het ParameterKey=<ParameterKey>,ParameterValue=<Value> paren in de volgende shellscripts aws cloudformation create-stack opdracht.
Voer de volgende stappen uit om uw resources in te richten:
- Maak een lokale kopie van het
amazon-bedrock-samplesopslagplaats gebruiktgit clone: - Voordat u het shellscript uitvoert, navigeert u naar de map waarin u het
amazon-bedrock-samplesrepository en wijzig de shell-scriptmachtigingen naar uitvoerbaar: - Stel uw CloudFormation-stacknaam, SNS-e-mail en URL-omgevingsvariabelen voor het uploaden van bewijsmateriaal in. Het SNS-e-mailadres wordt gebruikt voor meldingen aan polishouders, en de URL voor het uploaden van bewijsmateriaal wordt gedeeld met polishouders om hun claimbewijs te uploaden. De Voorbeeld van verwerking van verzekeringsclaims biedt een voorbeeldfront-end voor de URL voor het uploaden van bewijsmateriaal.
- Voer de ... uit
create-customer-resources.shshell-script om de geëmuleerde klantresources te implementeren die zijn gedefinieerd in hetbedrock-insurance-agent.ymlCloudFormation-sjabloon. Dit zijn de bronnen waarop de agent en de kennisbasis zullen worden gebouwd.
De voorgaande source ./create-customer-resources.sh shell-opdracht voert het volgende uit AWS-opdrachtregelinterface (AWS CLI)-opdrachten om de geëmuleerde klantbronnenstapel te implementeren:
Creëer een kennisbank
Knowledge Bases voor Amazon Bedrock maakt gebruik van RAG, een techniek die klantdataopslag gebruikt om de reacties van FM's te verbeteren. Dankzij kennisbanken hebben agenten toegang tot bestaande opslagplaatsen voor klantgegevens zonder uitgebreide beheerdersoverhead. Om een kennisbank aan uw gegevens te koppelen, geeft u een S3-bucket op als databron. Met kennisbanken verkrijgen applicaties verrijkte contextuele informatie, waardoor de ontwikkeling wordt gestroomlijnd via een volledig beheerde RAG-oplossing. Dit abstractieniveau versnelt de time-to-market door de inspanning van het opnemen van uw gegevens in de agentfunctionaliteit te minimaliseren, en het optimaliseert de kosten door de noodzaak van voortdurende herscholing van modellen om privégegevens te gebruiken teniet te doen.
Het volgende diagram illustreert de architectuur voor een kennisbank met een inbeddingsmodel.
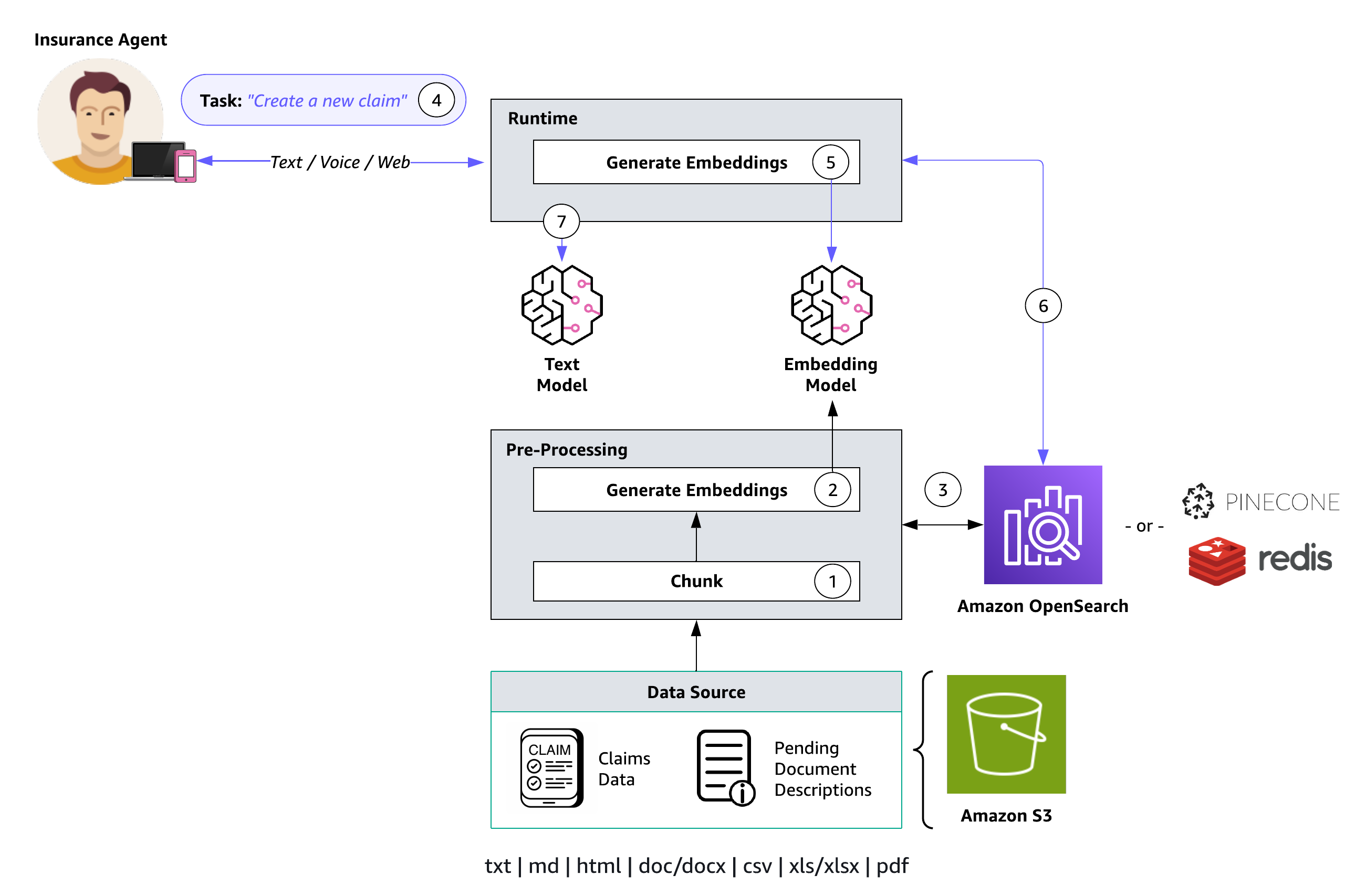
De functionaliteit van de kennisbank wordt afgebakend via twee belangrijke processen: voorverwerking (stappen 1-3) en runtime (stappen 4-7):
- Documenten worden gesegmenteerd (chunking) in beheersbare secties.
- Deze stukjes worden omgezet in inbedding met behulp van een Amazon Bedrock-inbeddingsmodel.
- De insluitingen worden gebruikt om een vectorindex te maken, waardoor semantische gelijkenisvergelijkingen tussen gebruikersquery's en gegevensbrontekst mogelijk worden.
- Tijdens runtime geven gebruikers hun tekstinvoer als prompt op.
- De invoertekst wordt omgezet in vectoren met behulp van een Amazon Bedrock-inbeddingsmodel.
- De vectorindex wordt doorzocht op segmenten die verband houden met de zoekopdracht van de gebruiker, waardoor de gebruikersprompt wordt uitgebreid met aanvullende context die uit de vectorindex wordt opgehaald.
- De uitgebreide prompt, gekoppeld aan de aanvullende context, wordt gebruikt om een antwoord voor de gebruiker te genereren.
Voer de volgende stappen uit om een kennisbank te maken:
- Kies op de Amazon Bedrock-console Kennisbank in het navigatievenster.
- Kies Creëer kennisbasis.
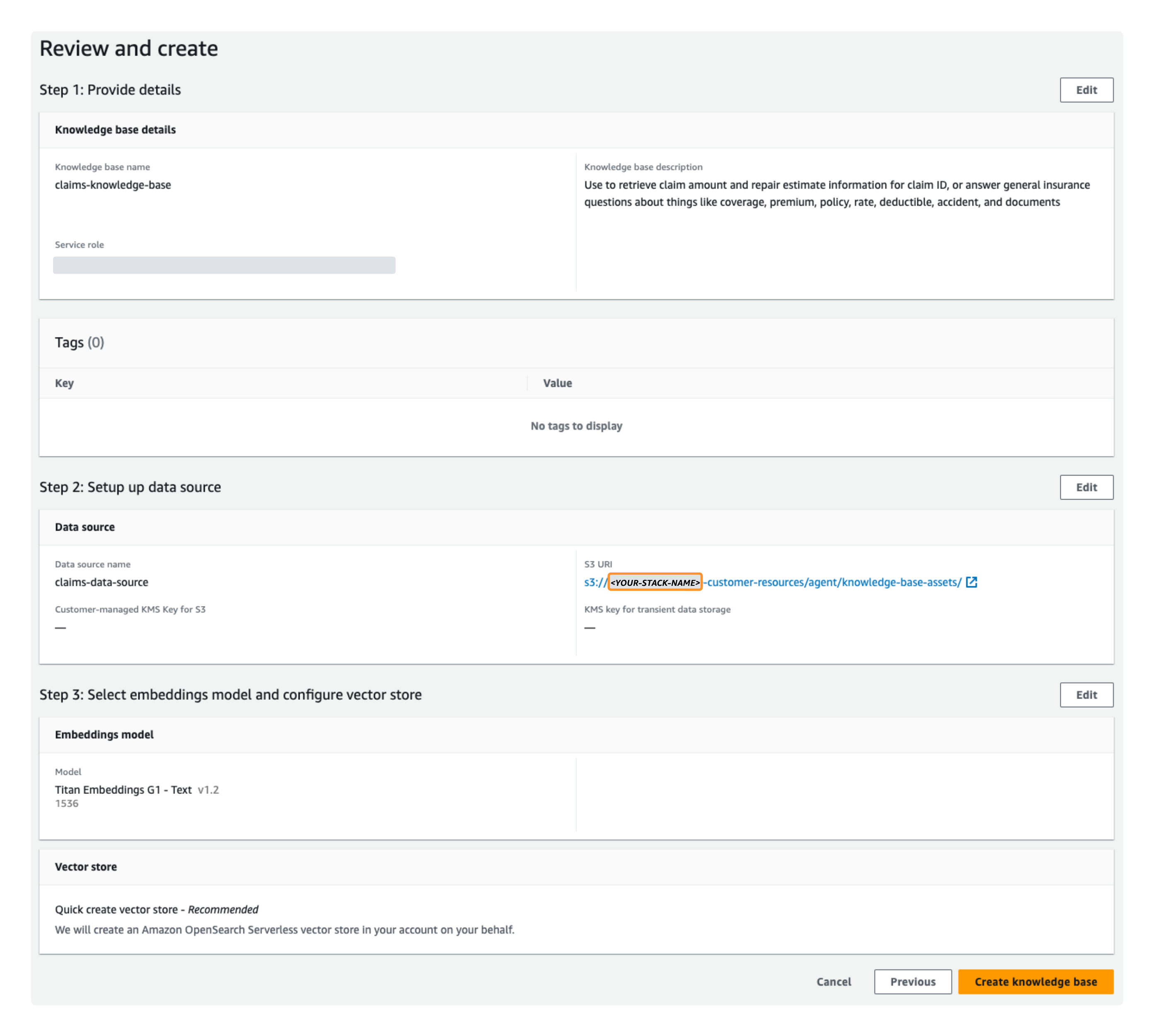
- Onder Geef kennisbankgegevens op, voer een naam en optionele beschrijving in, waarbij u alle standaardinstellingen behoudt. Voor dit bericht voeren we de beschrijving in:
Use to retrieve claim amount and repair estimate information for claim ID, or answer general insurance questions about things like coverage, premium, policy, rate, deductible, accident, and documents. - Onder Gegevensbron instellen, voer een naam in.
- Kies Blader door S3 in en selecteer het
knowledge-base-assetsmap van de gegevensbron S3-bucket die u eerder hebt geïmplementeerd (<YOUR-STACK-NAME>-customer-resources/agent/knowledge-base-assets/).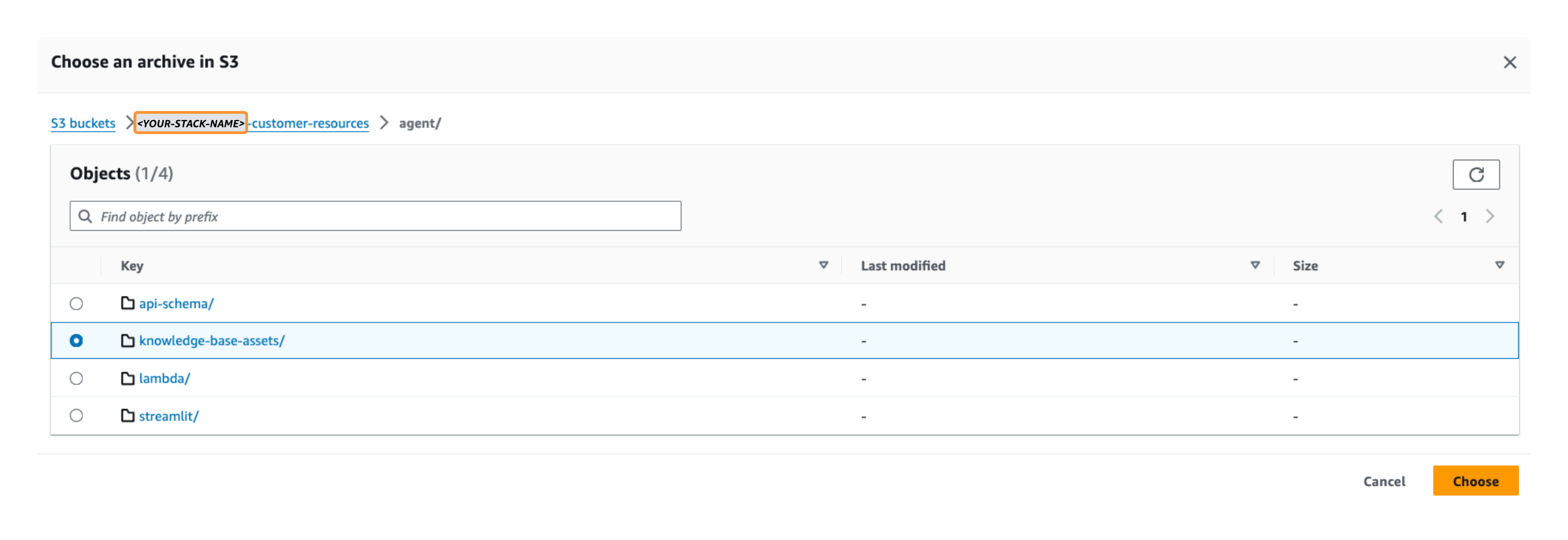
- Onder Selecteer het inbeddingsmodel en configureer vectoropslag, kiezen Titan Embeddings G1 – Tekst en laat de overige standaardinstellingen staan. Een Amazon OpenSearch Serverloos Collectie wordt voor u gemaakt. In deze vectoropslag worden de voorverwerkingsinsluitingen van de kennisbank opgeslagen en later gebruikt voor het zoeken naar semantische overeenkomsten tussen query's en gegevensbrontekst.
- Onder Bekijk en creëer, bevestig uw configuratie-instellingen en kies vervolgens Creëer kennisbasis.
- Nadat uw kennisbank is aangemaakt, wordt een groene banner ‘succesvol gemaakt’ weergegeven met de optie om uw gegevensbron te synchroniseren. Kiezen Synchroniseren om de gegevensbronsynchronisatie te starten.

- Navigeer op de Amazon Bedrock-console naar de kennisbank die u zojuist hebt gemaakt en noteer vervolgens de kennisbank-ID eronder Overzicht kennisbank.
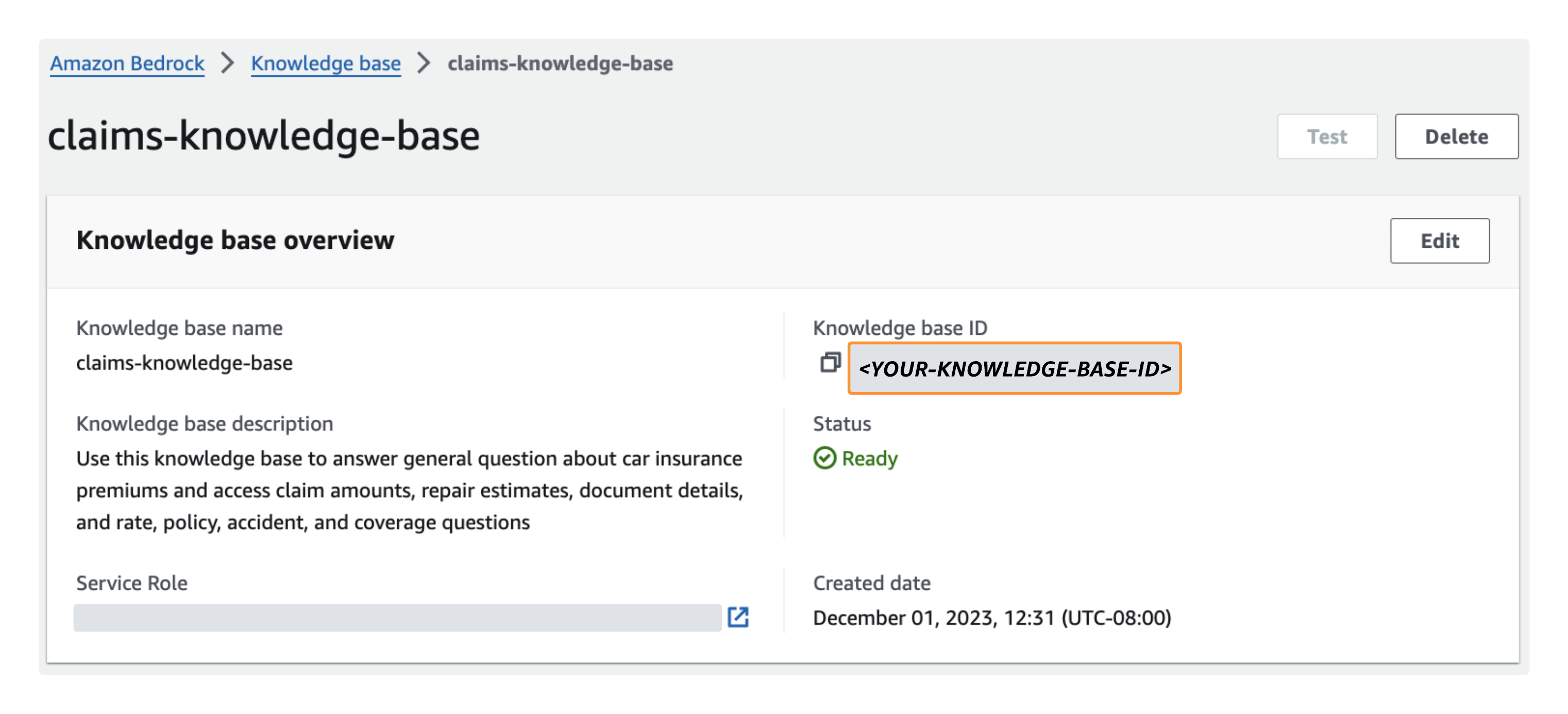
- Terwijl uw kennisbank nog steeds is geselecteerd, kiest u de hieronder vermelde kennisbankgegevensbron Databronen noteer vervolgens de gegevensbron-ID onder Overzicht gegevensbronnen.
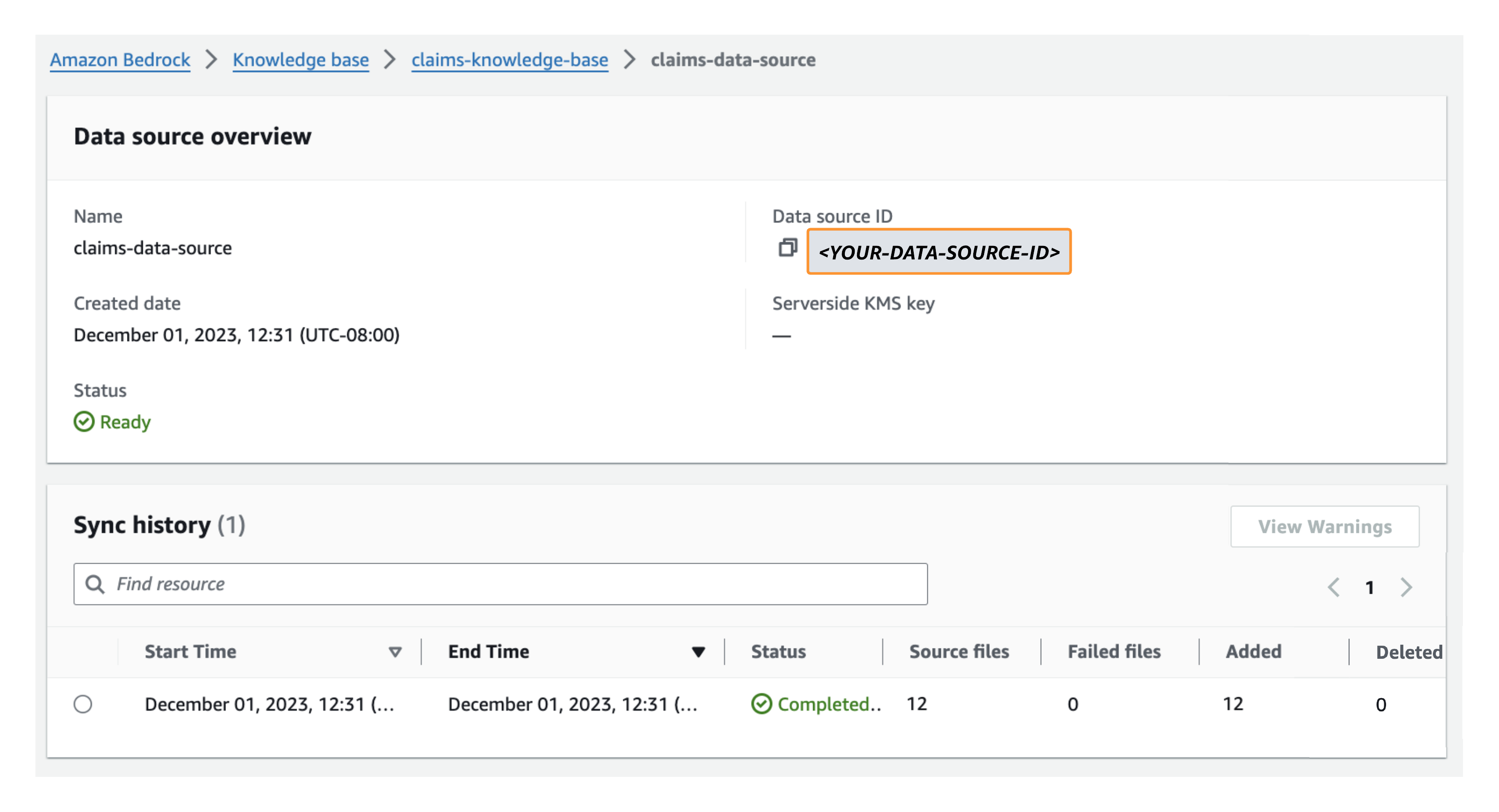
De kennisbank-ID en gegevensbron-ID worden in een latere stap als omgevingsvariabelen gebruikt wanneer u de Streamlit-webgebruikersinterface voor uw agent implementeert.
Maak een agent aan
Agenten werken via een build-time run-proces, dat verschillende belangrijke componenten omvat:
- Funderingsmodel – Gebruikers selecteren een FM die de agent begeleidt bij het interpreteren van gebruikersinvoer, het genereren van reacties en het aansturen van daaropvolgende acties tijdens het orkestratieproces.
- Instructies – Gebruikers stellen gedetailleerde instructies op die de beoogde functionaliteit van de agent schetsen. Optionele geavanceerde prompts maken aanpassing bij elke orkestratiestap mogelijk, waarbij Lambda-functies worden opgenomen om de uitvoer te parseren.
- (Optioneel) Actiegroepen – Gebruikers definiëren acties voor de agent, met behulp van een OpenAPI-schema om API's te definiëren voor taakuitvoeringen en Lambda-functies om API-invoer en -uitvoer te verwerken.
- (Optioneel) Kennisbanken – Gebruikers kunnen agenten aan kennisbanken koppelen, waardoor toegang wordt verleend tot aanvullende context voor het genereren van antwoorden en orkestratiestappen.
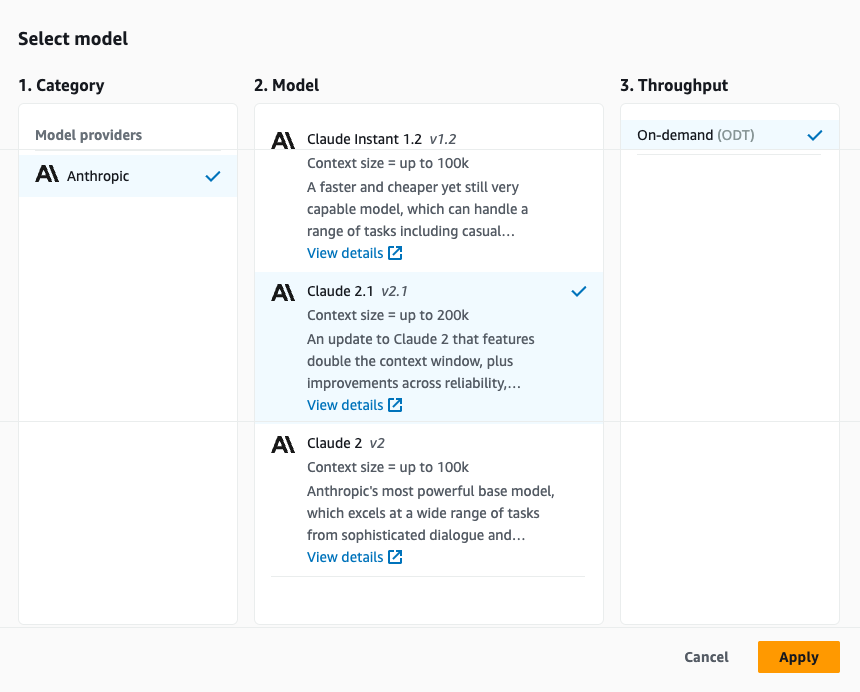
De agent in deze voorbeeldoplossing gebruikt een Anthropic Claude V2.1 FM op Amazon Bedrock, een reeks instructies, drie actiegroepen en één kennisbank.
Voer de volgende stappen uit om een agent te maken:
- Kies op de Amazon Bedrock-console Ontmoet het team in het navigatievenster.
- Kies Agent maken.
- Onder Geef agentgegevens op, voer een agentnaam en optionele beschrijving in en laat alle andere standaardinstellingen staan.
- Onder Selecteer een model, kiezen Antropische Claude V2.1 en geef de volgende instructies voor de agent op:
You are an insurance agent that has access to domain-specific insurance knowledge. You can create new insurance claims, send pending document reminders to policy holders with open claims, and gather claim evidence. You can also retrieve claim amount and repair estimate information for a specific claim ID or answer general insurance questions about things like coverage, premium, policy, rate, deductible, accident, documents, resolution, and condition. You can answer internal questions about things like which steps an agent should follow and the company's internal processes. You can respond to questions about multiple claim IDs within a single conversation - Kies Volgende.
- Onder Actiegroepen toevoegen, voeg uw eerste actiegroep toe:
- Voor Voer de naam van de actiegroep in, ga naar binnen
create-claim. - Voor Omschrijving, ga naar binnen
Use this action group to create an insurance claim - Voor Lambda-functie selecteren, kiezen
<YOUR-STACK-NAME>-CreateClaimFunction. - Voor Selecteer API-schema, kiezen Blader door S3, kies de eerder gemaakte bucket (
<YOUR-STACK-NAME>-customer-resources), kies danagent/api-schema/create_claim.json.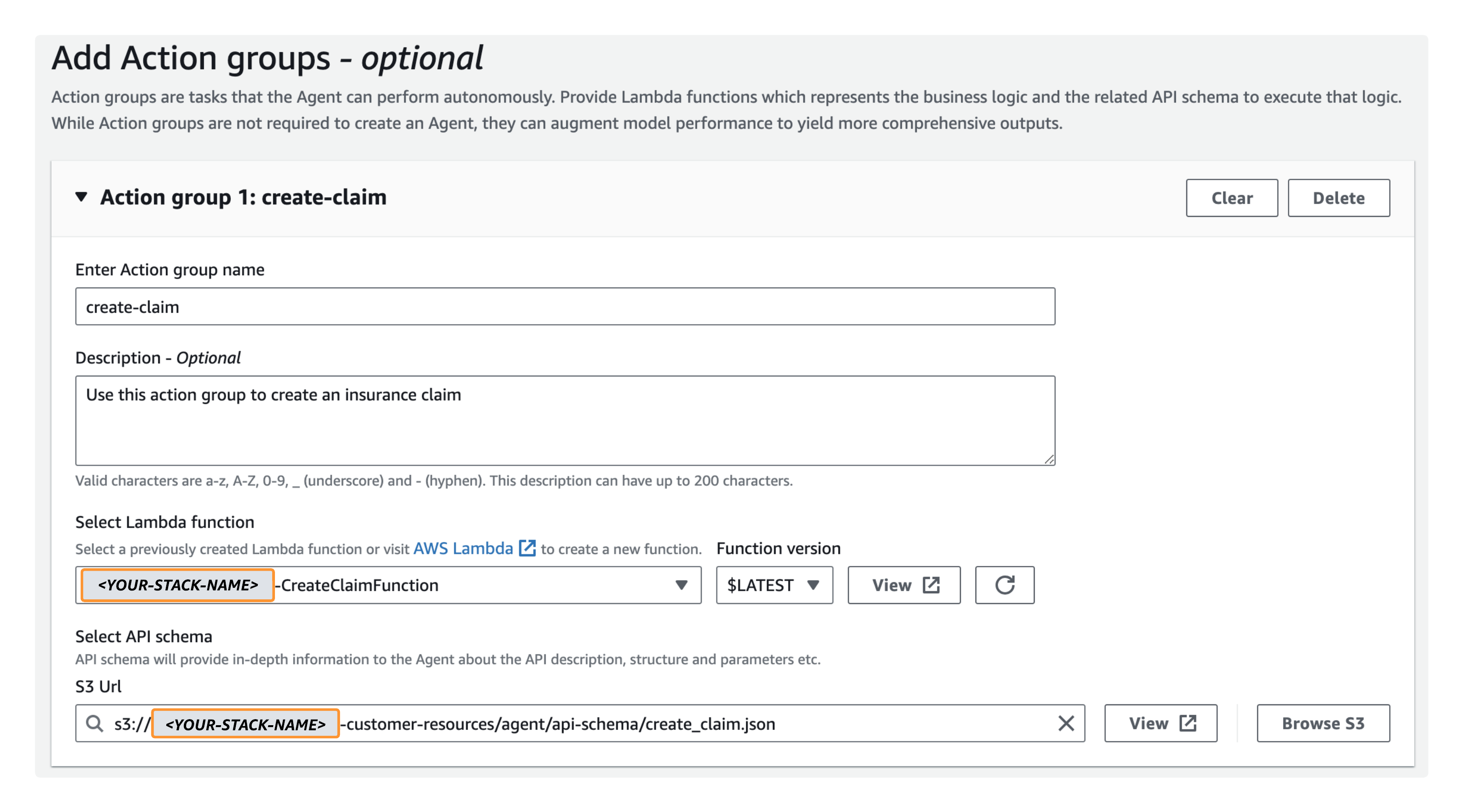
- Voor Voer de naam van de actiegroep in, ga naar binnen
- Creëer een tweede actiegroep:
- Voor Voer de naam van de actiegroep in, ga naar binnen
gather-evidence. - Voor Omschrijving, ga naar binnen
Use this action group to send the user a URL for evidence upload on open status claims with pending documents. Return the documentUploadUrl to the user - Voor Lambda-functie selecteren, kiezen
<YOUR-STACK-NAME>-GatherEvidenceFunction. - Voor Selecteer API-schema, kiezen Blader door S3, kies de eerder gemaakte bucket en kies vervolgens
agent/api-schema/gather_evidence.json.
- Voor Voer de naam van de actiegroep in, ga naar binnen
- Creëer een derde actiegroep:
- Voor Voer de naam van de actiegroep in, ga naar binnen
send-reminder. - Voor Omschrijving, ga naar binnen
Use this action group to check claim status, identify missing or pending documents, and send reminders to policy holders - Voor Lambda-functie selecteren, kiezen
<YOUR-STACK-NAME>-SendReminderFunction. - Voor Selecteer API-schema, kiezen Blader door S3, kies de eerder gemaakte bucket en kies vervolgens
agent/api-schema/send_reminder.json.
- Voor Voer de naam van de actiegroep in, ga naar binnen
- Kies Volgende.
- Voor Selecteer kennisbank, kies de kennisbank die u eerder hebt gemaakt (
claims-knowledge-base). - Voor Knowledgebase-instructies voor Agent, Vul het volgende in:
Use to retrieve claim amount and repair estimate information for claim ID, or answer general insurance questions about things like coverage, premium, policy, rate, deductible, accident, and documents - Kies Volgende.

- Onder Bekijk en creëer, bevestig uw configuratie-instellingen en kies vervolgens Agent maken.
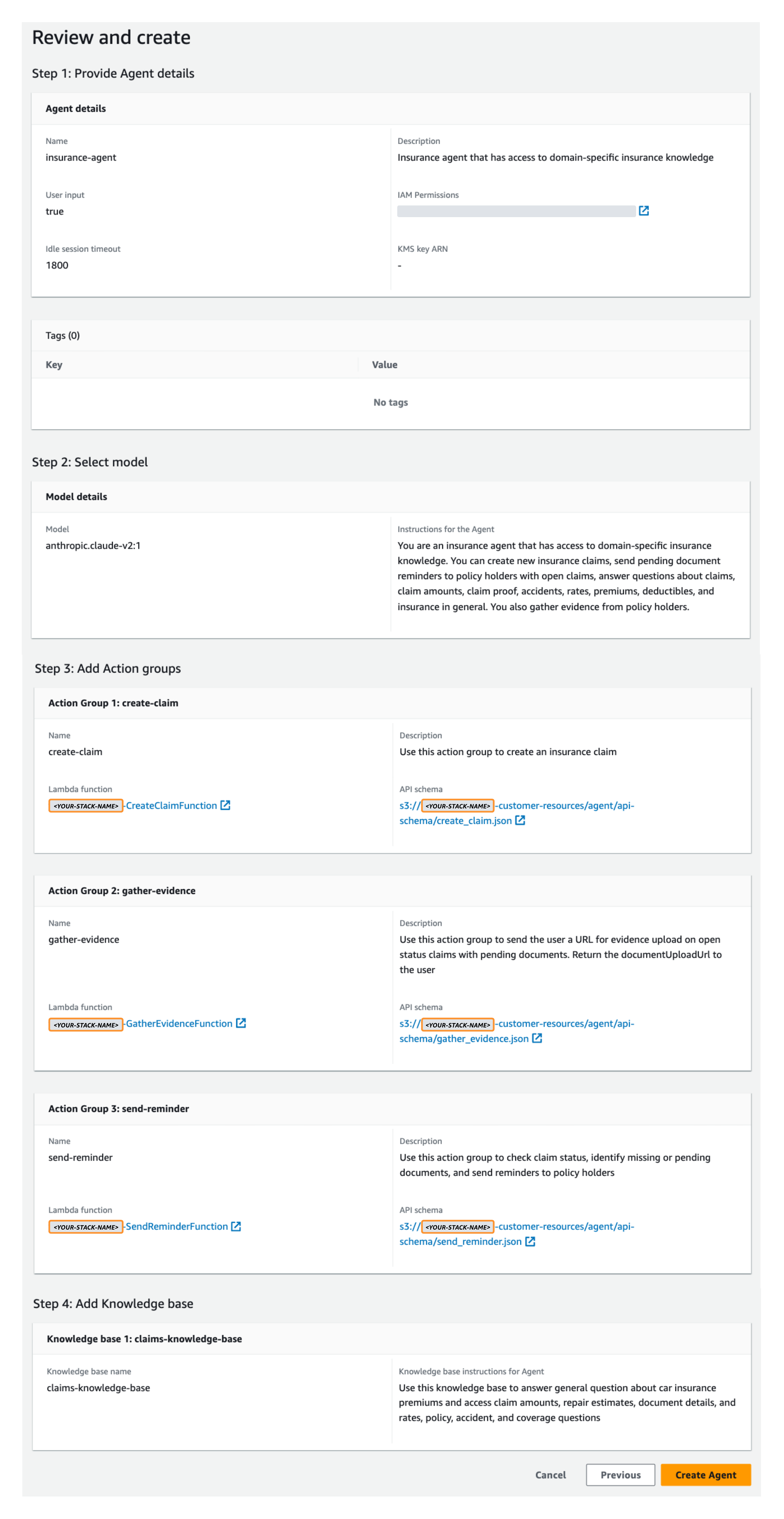
Nadat uw agent is aangemaakt, ziet u een groene banner ‘succesvol gemaakt’.

Testen en valideren
De volgende testprocedure heeft tot doel te verifiëren dat de agent de intenties van de gebruiker voor het aanmaken van nieuwe claims, het verzenden van openstaande documentherinneringen voor openstaande claims, het verzamelen van claimbewijsmateriaal en het zoeken naar informatie in bestaande claims en klantkennisopslagplaatsen correct identificeert en begrijpt. De nauwkeurigheid van de respons wordt bepaald door het evalueren van de relevantie, samenhang en mensachtige aard van de antwoorden die worden gegenereerd door agenten en kennisbanken voor Amazon Bedrock.
Beoordelingsmaatregelen en evaluatietechniek
Validatie van gebruikersinvoer en agentinstructie omvat het volgende:
- Voorverwerking – Gebruik voorbeeldprompts om de interpretatie, het begrip en het reactievermogen van de agent op diverse gebruikersinvoer te beoordelen. Valideer de naleving door de agent van geconfigureerde instructies voor het nauwkeurig valideren, contextualiseren en categoriseren van gebruikersinvoer.
- orkestratie – Evalueer de logische stappen die de agent volgt (bijvoorbeeld 'Trace') voor API-aanroepen van actiegroepen en kennisbankquery's om de basisprompt voor de FM te verbeteren.
- Nabewerking – Controleer de uiteindelijke antwoorden die door de agent zijn gegenereerd na orkestratie-iteraties om nauwkeurigheid en relevantie te garanderen. De nabewerking is standaard inactief en daarom niet meegenomen in de tracering van onze agent.
De evaluatie van de actiegroep omvat het volgende:
- Validatie van API-schema's – Valideer dat het OpenAPI-schema (gedefinieerd als JSON-bestanden opgeslagen in Amazon S3) de redenering van de agent rond het doel van elke API effectief begeleidt.
- Implementatie van bedrijfslogica – Test de implementatie van bedrijfslogica die is gekoppeld aan API-paden via Lambda-functies die zijn gekoppeld aan de actiegroep.
Evaluatie van de kennisbank omvat het volgende:
- Configuratieverificatie – Controleer of de Knowledge Base-instructies de agent correct aangeven wanneer hij toegang moet krijgen tot de gegevens.
- S3-gegevensbronintegratie – Valideer de mogelijkheid van de agent om toegang te krijgen tot en gebruik te maken van gegevens die zijn opgeslagen in de opgegeven S3-gegevensbron.
De end-to-end-test omvat het volgende:
- Geïntegreerde werkstroom – Voer uitgebreide tests uit waarbij zowel actiegroepen als kennisbanken betrokken zijn om scenario's uit de echte wereld te simuleren.
- Beoordeling van de responskwaliteit – Evalueer de algehele nauwkeurigheid, relevantie en samenhang van de reacties van de agent in diverse contexten en scenario's.
Test de kennisbank
Nadat u uw kennisbank in Amazon Bedrock heeft opgezet, kunt u het gedrag ervan rechtstreeks testen om de reacties te beoordelen voordat u deze met een agent integreert. Met dit testproces kunt u de prestaties van de kennisbank evalueren, reacties inspecteren en problemen oplossen door de bronfragmenten te verkennen waaruit informatie wordt opgehaald. Voer de volgende stappen uit:
- Kies op de Amazon Bedrock-console Kennisbank in het navigatievenster.
- Selecteer de kennisbank die u wilt testen en kies vervolgens test om een chatvenster uit te vouwen.
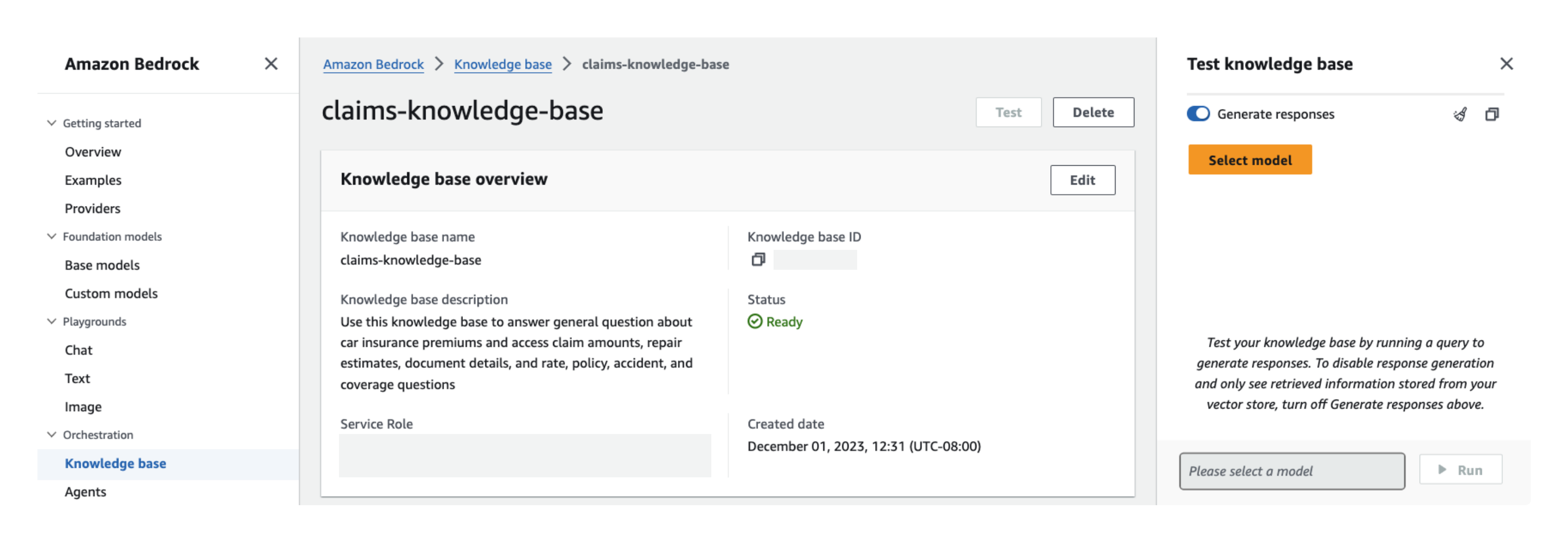
- Selecteer in het testvenster uw basismodel voor het genereren van antwoorden.
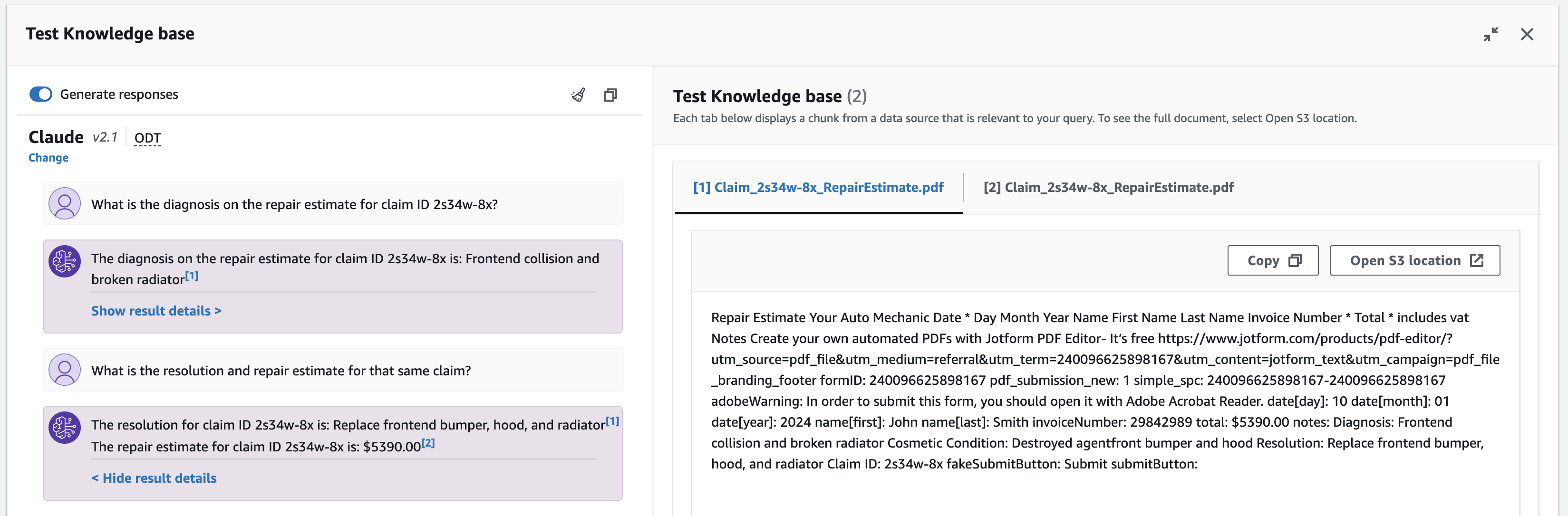
- Test uw kennisbank met behulp van de volgende voorbeeldquery's en andere invoer:
- Wat is de diagnose op de reparatieschatting voor claim ID 2s34w-8x?
- Wat is de geschatte oplossing en reparatie voor diezelfde claim?
- Wat moet de bestuurder doen na een ongeval?
- Wat wordt aanbevolen voor het ongevalsrapport en de afbeeldingen?
- Wat is een eigen risico en hoe werkt het?
U kunt schakelen tussen het genereren van reacties en het retourneren van directe citaten in het chatvenster, en u heeft de mogelijkheid om het chatvenster leeg te maken of alle uitvoer te kopiëren met behulp van de meegeleverde pictogrammen.
Om kennisbankreacties en bronfragmenten te inspecteren, kunt u de bijbehorende voetnoot selecteren of kiezen Resultaatdetails weergeven. Er verschijnt een venster met bronfragmenten waarin u kunt zoeken, tekstfragmenten kunt kopiëren en naar de S3-gegevensbron kunt navigeren.
Test de agent
Na het succesvol testen van uw kennisbank, omvat de volgende ontwikkelingsfase het voorbereiden en testen van de functionaliteit van uw agent. Het voorbereiden van de agent omvat het verpakken van de laatste wijzigingen, terwijl testen een cruciale kans biedt om te communiceren met het gedrag van de agent en deze te evalueren. Via dit proces kunt u de capaciteiten van agenten verfijnen, de efficiëntie ervan verbeteren en eventuele problemen of verbeteringen aanpakken die nodig zijn voor optimale prestaties. Voer de volgende stappen uit:
- Kies op de Amazon Bedrock-console Ontmoet het team in het navigatievenster.
- Kies uw agent en noteer de agent-ID.
U gebruikt de agent-ID als omgevingsvariabele in een latere stap wanneer u de Streamlit-webgebruikersinterface voor uw agent implementeert. - Navigeer naar uw Werkversie. In eerste instantie hebt u een werkconcept en een standaard
TestAliaswijzend op dit ontwerp. Het werkconcept maakt iteratieve ontwikkeling mogelijk. - Kies Voorbereiden om de agent te verpakken met de laatste wijzigingen voordat deze wordt getest. U moet regelmatig de laatst voorbereide tijd van de agent controleren om er zeker van te zijn dat u test met de nieuwste configuraties.
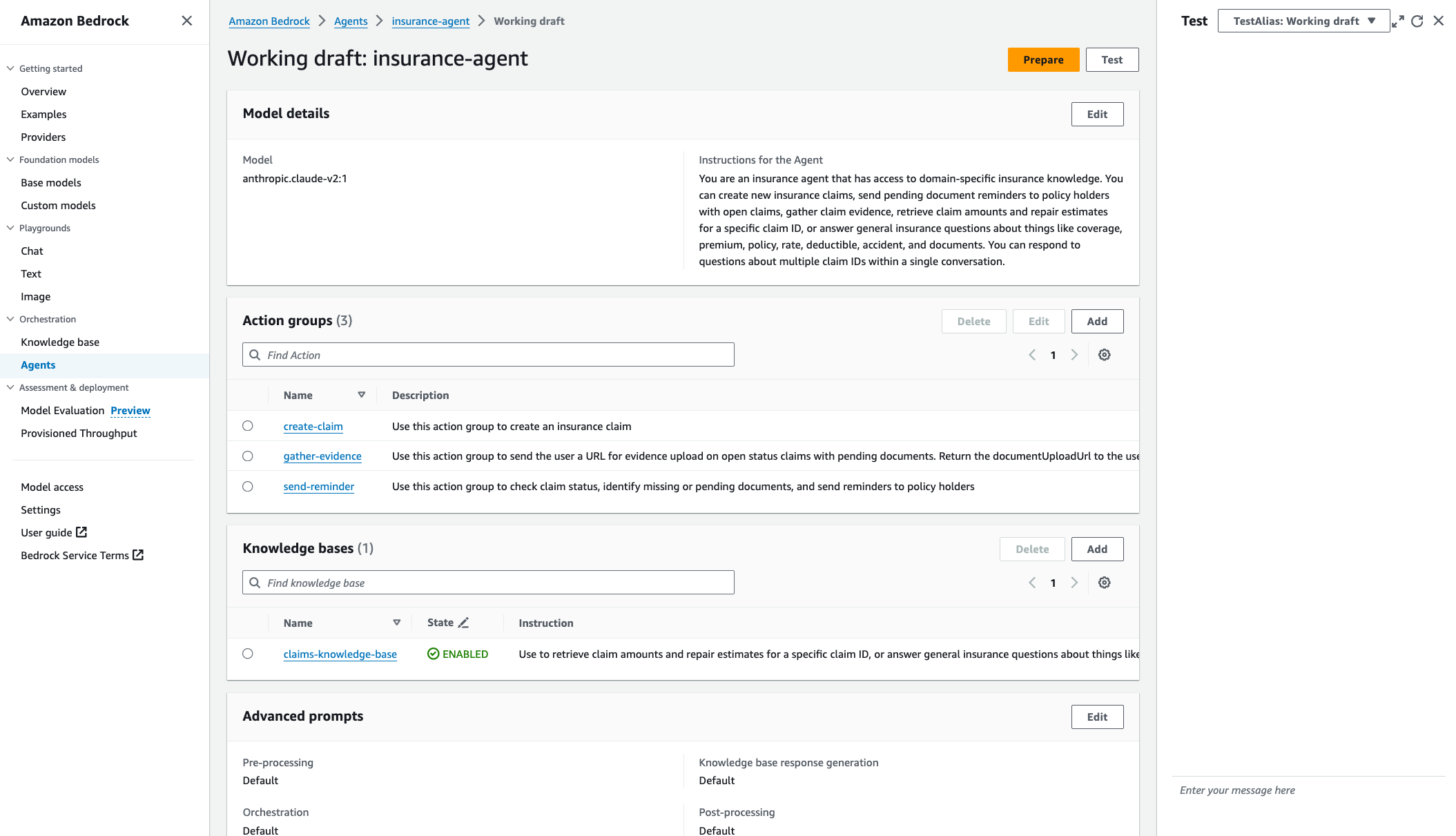
- Open het testvenster vanaf elke pagina binnen de werkende conceptconsole van de agent door te kiezen test of het pijltje naar links.
- Kies in het testvenster een alias en de versie ervan om te testen. Voor dit bericht gebruiken we
TestAliasom de conceptversie van uw agent op te roepen. Als de agent niet is voorbereid, verschijnt er een prompt in het testvenster.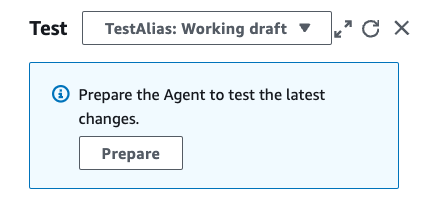
- Test uw agent met behulp van de volgende voorbeeldprompts en andere invoer:
- Maak een nieuwe claim aan.
- Stuur een herinnering aan openstaande documenten naar de verzekeringnemer van claim 2s34w-8x.
- Verzamel bewijsmateriaal voor claim 5t16u-7v.
- Wat is het totale claimbedrag voor claim 3b45c-9d?
- Wat is de totale reparatieschatting voor diezelfde claim?
- Welke factoren bepalen de premie van mijn autoverzekering?
- Hoe kan ik de tarieven van mijn autoverzekering verlagen?
- Welke claims hebben een open status?
- Stuur herinneringen naar alle polishouders met openstaande claims.
Zorg ervoor dat je kiest Voorbereiden nadat u wijzigingen hebt aangebracht om deze toe te passen voordat u de agent test.
Het volgende voorbeeld van een testgesprek benadrukt de mogelijkheid van de agent om actiegroep-API's aan te roepen met AWS Lambda-bedrijfslogica die de Amazon DynamoDB-tabel van een klant bevraagt en klantmeldingen verzendt met behulp van Amazon Simple Notification Service. In dezelfde gespreksreeks wordt de integratie van agenten en kennisbanken getoond om de gebruiker van antwoorden te voorzien met behulp van gezaghebbende gegevensbronnen van de klant, zoals claimbedragen en FAQ-documenten.
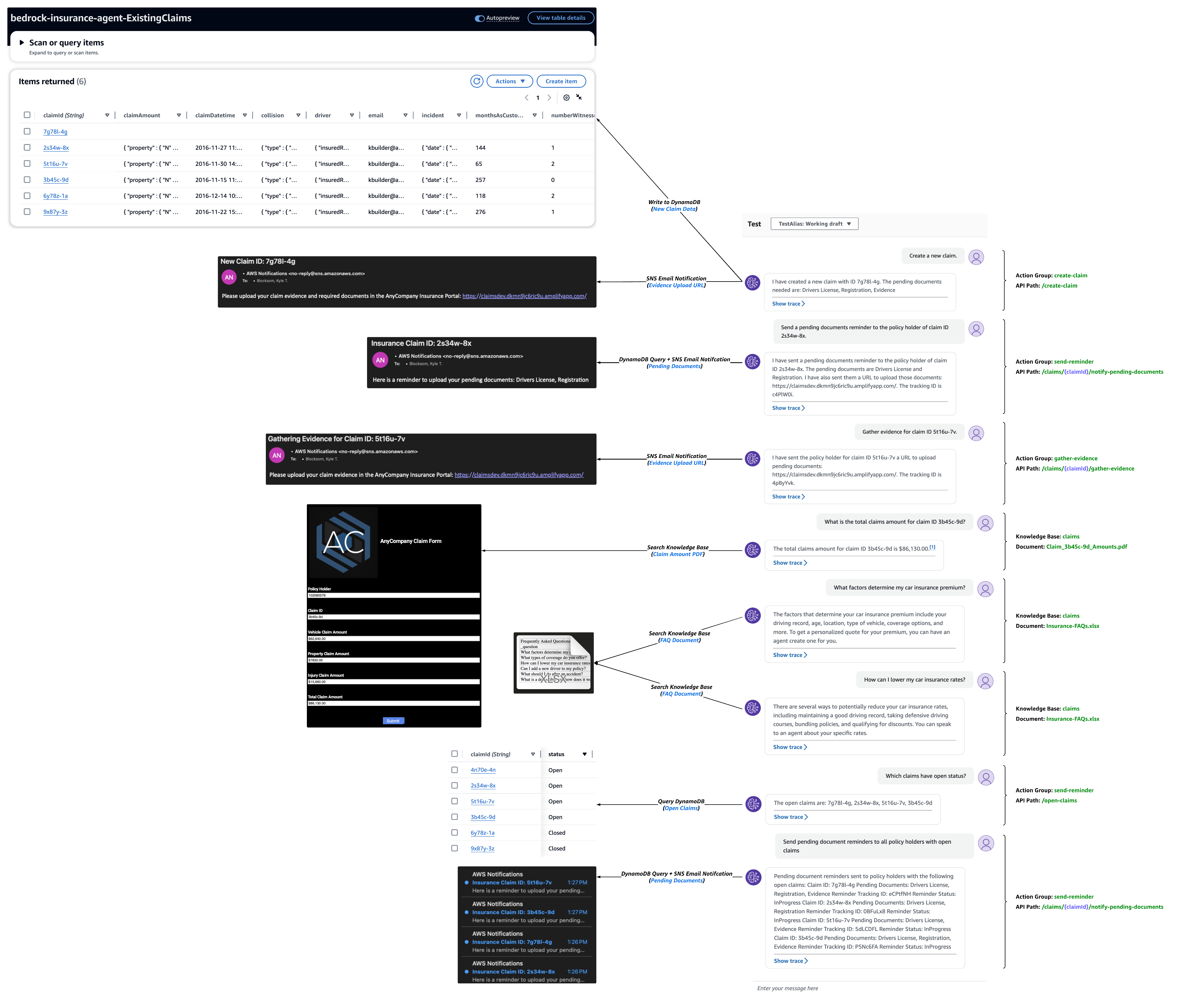
Hulpmiddelen voor agentanalyse en foutopsporing
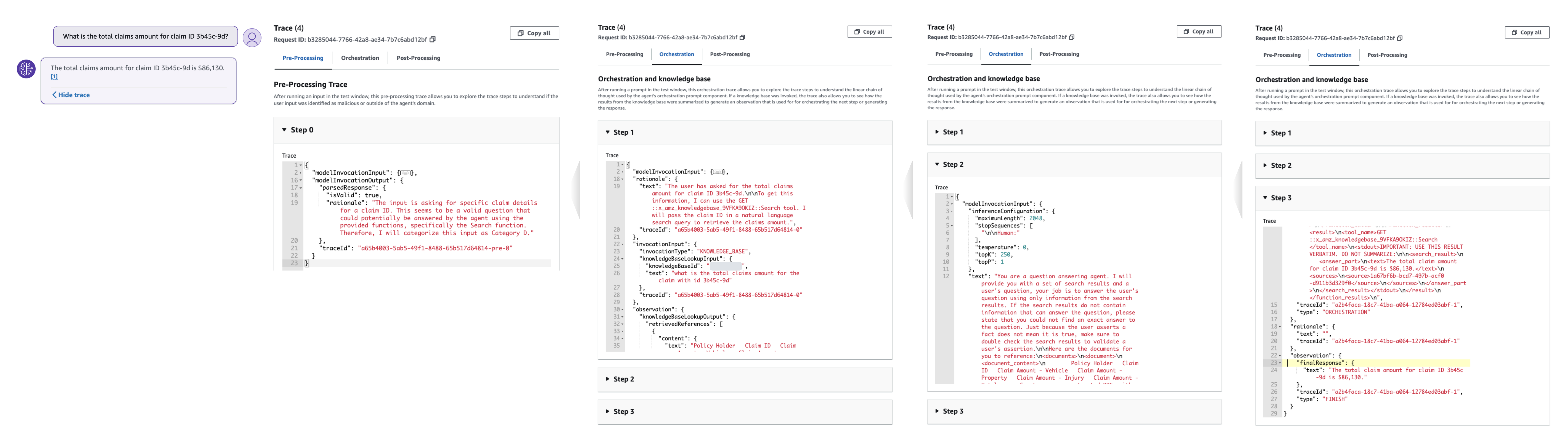
Agentreactietraceringen bevatten essentiële informatie om de besluitvorming van de agent in elke fase te helpen begrijpen, het opsporen van fouten te vergemakkelijken en inzicht te geven in gebieden die voor verbetering vatbaar zijn. De ModelInvocationInput object binnen elke trace biedt gedetailleerde configuraties en instellingen die worden gebruikt in het besluitvormingsproces van de agent, waardoor klanten de effectiviteit van de agent kunnen analyseren en verbeteren.
Uw agent sorteert gebruikersinvoer in een van de volgende categorieën:
- Categorie A – Schadelijke of schadelijke input, ook al zijn het fictieve scenario's.
- Categorie B – Invoer waarbij de gebruiker informatie probeert te krijgen over welke functies, API's of instructies onze functie-aanroepende agent heeft gekregen of invoer die probeert het gedrag of de instructies van onze functie-aanroepende agent of van u te manipuleren.
- Categorie C – Vragen die onze functie-oproepende agent niet kan beantwoorden of nuttige informatie kan verstrekken voor het gebruik van alleen de functies die hem zijn aangeboden.
- Categorie D – Vragen die door onze functie-aanroepende agent kunnen worden beantwoord of bijgestaan, met alleen de functies die hem zijn aangeboden en argumenten van binnenuit
conversation_historyof relevante argumenten die het kan verzamelen met behulp van deaskuserfunctie. - Categorie E – Invoer die geen vragen zijn, maar in plaats daarvan antwoorden zijn op een vraag die de functie-aanroepende agent aan de gebruiker heeft gesteld. Invoer komt alleen in aanmerking voor deze categorie als de
askuserfunctie is de laatste functie die de functie die de agent aanroept in het gesprek heeft aangeroepen. U kunt dit controleren door deconversation_history.
Kies Toon spoor onder een reactie om de configuraties en het redeneringsproces van de agent te bekijken, inclusief het gebruik van de kennisbank en actiegroepen. Traceringen kunnen worden uitgevouwen of samengevouwen voor gedetailleerde analyse. Reacties met broninformatie bevatten ook voetnoten voor citaten.
In het volgende traceringsvoorbeeld van actiegroepen wijst de agent de gebruikersinvoer toe aan de create-claim actiegroep createClaim functie tijdens de voorbewerking. De agent heeft inzicht in deze functie op basis van de agentinstructies, de actiegroepbeschrijving en het OpenAPI-schema. Tijdens het orkestratieproces, dat in dit geval uit twee stappen bestaat, roept de agent de createClaim functie en ontvangt een antwoord met de nieuw aangemaakte claim-ID en een lijst met openstaande documenten.

In het volgende voorbeeld van tracering in de Knowledge Base wijst de agent de gebruikersinvoer tijdens de voorverwerking toe aan categorie D, wat betekent dat een van de beschikbare functies van de agent een antwoord moet kunnen geven. Tijdens de gehele orkestratie doorzoekt de agent de kennisbank, haalt de relevante delen op met behulp van insluitingen en geeft die tekst door aan het basismodel om een definitief antwoord te genereren.
Implementeer de Streamlit-webinterface voor uw agent
Wanneer u tevreden bent met de prestaties van uw agent en kennisbank, bent u klaar om hun capaciteiten te productiseren. We gebruiken Gestroomlijnd in deze oplossing om een voorbeeld front-end te lanceren, bedoeld om een productieapplicatie te emuleren. Streamlit is een Python-bibliotheek die is ontworpen om het proces van het bouwen van front-end-applicaties te stroomlijnen en te vereenvoudigen. Onze applicatie biedt twee functies:
- Invoer van agentprompt – Staat gebruikers toe beroep doen op de makelaar met behulp van hun eigen taakinvoer.
- Kennisbankbestand uploaden – Hiermee kan de gebruiker zijn lokale bestanden uploaden naar de S3-bucket die wordt gebruikt als gegevensbron voor de kennisbank. Nadat het bestand is geüpload, wordt de applicatie start een opnametaak om de kennisbankgegevensbron te synchroniseren.
Om de afhankelijkheden van onze Streamlit-applicaties te isoleren en de implementatie te vergemakkelijken, gebruiken we de setup-streamlit-env.sh shell-script om een virtuele Python-omgeving te creëren waarin de vereisten zijn geïnstalleerd. Voer de volgende stappen uit:
- Voordat u het shellscript uitvoert, navigeert u naar de map waarin u het
amazon-bedrock-samplesrepository en wijzig de Streamlit-shellscriptmachtigingen naar uitvoerbaar:
- Voer het shellscript uit om de virtuele Python-omgeving met de vereiste afhankelijkheden te activeren:
- Stel uw Amazon Bedrock-agent-ID, agentalias-ID, kennisbank-ID, gegevensbron-ID, kennisbank-bucketnaam en AWS-regio-omgevingsvariabelen in:
- Start uw Streamlit-applicatie en begin met testen in uw lokale webbrowser:

Opruimen
Om kosten in uw AWS-account te voorkomen, ruimt u de ingerichte bronnen van de oplossing op
De verwijder-klant-resources.sh shell-script leegt en verwijdert de S3-bucket van de oplossing en verwijdert de bronnen die oorspronkelijk waren ingericht uit de bedrock-customer-resources.yml CloudFormation-stack. De volgende opdrachten gebruiken de standaardstapelnaam. Als u de stapelnaam hebt aangepast, past u de opdrachten dienovereenkomstig aan.
De voorgaande ./delete-customer-resources.sh shell-opdracht voert de volgende AWS CLI-opdrachten uit om de geëmuleerde klantbronnenstapel en S3-bucket te verwijderen:
Volg de instructies voor om uw agent en kennisbank te verwijderen een agent verwijderen en een kennisbank verwijderen, Respectievelijk.
Overwegingen
Hoewel de gedemonstreerde oplossing de mogelijkheden van Agents en Knowledge Bases voor Amazon Bedrock laat zien, is het belangrijk om te begrijpen dat deze oplossing nog niet klaar is voor productie. Het dient eerder als een conceptuele gids voor klanten die gepersonaliseerde agenten willen creëren voor hun eigen specifieke taken en geautomatiseerde workflows. Klanten die productie-implementatie nastreven, moeten dit initiële model verfijnen en aanpassen, rekening houdend met de volgende beveiligingsfactoren:
- Veilige toegang tot API's en gegevens:
- Beperk de toegang tot API's, databases en andere agent-geïntegreerde systemen.
- Maak gebruik van toegangscontrole, geheimbeheer en encryptie om ongeautoriseerde toegang te voorkomen.
- Invoervalidatie en opschoning:
- Valideer en zuiver gebruikersinvoer om injectieaanvallen of pogingen om het gedrag van de agent te manipuleren te voorkomen.
- Stel invoerregels en mechanismen voor gegevensvalidatie vast.
- Toegangscontroles voor agentbeheer en testen:
- Implementeer de juiste toegangscontroles voor consoles en tools die worden gebruikt om de agent te bewerken, testen of configureren.
- Beperk de toegang tot geautoriseerde ontwikkelaars en testers.
- Beveiliging van de infrastructuur:
- Houd u aan de best practices op het gebied van AWS-beveiliging met betrekking tot VPC's, subnetten, beveiligingsgroepen, logboekregistratie en monitoring voor het beveiligen van de onderliggende infrastructuur.
- Validatie van agentinstructies:
- Zorg voor een nauwgezet proces om de instructies van de agent te beoordelen en te valideren om onbedoeld gedrag te voorkomen.
- Testen en auditeren:
- Test de agent en geïntegreerde componenten grondig.
- Implementeer audits, logboekregistratie en regressietests van agentgesprekken om problemen op te sporen en aan te pakken.
- Kennisbankbeveiliging:
- Als gebruikers de kennisbank kunnen uitbreiden, valideer dan uploads om vergiftigingsaanvallen te voorkomen.
Voor andere belangrijke overwegingen, zie Bouw generatieve AI-agents met Amazon Bedrock, Amazon DynamoDB, Amazon Kendra, Amazon Lex en LangChain.
Conclusie
De implementatie van generatieve AI-agents met behulp van Agents en Knowledge Bases voor Amazon Bedrock vertegenwoordigt een aanzienlijke vooruitgang in de operationele en automatiseringsmogelijkheden van organisaties. Deze tools stroomlijnen niet alleen de levenscyclus van verzekeringsclaims, maar scheppen ook een precedent voor de toepassing van AI in verschillende andere bedrijfsdomeinen. Door taken te automatiseren, de klantenservice te verbeteren en besluitvormingsprocessen te verbeteren, stellen deze AI-agenten organisaties in staat zich te concentreren op groei en innovatie, terwijl ze routinematige en complexe taken efficiënt afhandelen.
Terwijl we getuige blijven van de snelle evolutie van AI, is het potentieel van tools zoals Agents en Knowledge Bases voor Amazon Bedrock bij het transformeren van bedrijfsactiviteiten enorm. Bedrijven die deze technologieën gebruiken, zullen een aanzienlijk concurrentievoordeel behalen, gekenmerkt door verbeterde efficiëntie, klanttevredenheid en besluitvorming. De toekomst van bedrijfsdatabeheer en -operaties neigt onmiskenbaar naar een grotere AI-integratie, en Amazon Bedrock loopt voorop in deze transformatie.
Voor meer informatie, bezoek Agenten voor Amazon Bedrock, raadpleeg de Amazon Bedrock-documentatie, verken het generatieve AI-ruimte op community.awsen ga aan de slag met de Amazon Bedrock-workshop.
Over de auteur
 Kyle T. Blocksom is een Sr. Solutions Architect bij AWS, gevestigd in Zuid-Californië. Kyle's passie is om mensen samen te brengen en technologie te benutten om oplossingen te bieden waar klanten dol op zijn. Buiten zijn werk houdt hij van surfen, eten, worstelen met zijn hond en zijn nichtje en neefje verwennen.
Kyle T. Blocksom is een Sr. Solutions Architect bij AWS, gevestigd in Zuid-Californië. Kyle's passie is om mensen samen te brengen en technologie te benutten om oplossingen te bieden waar klanten dol op zijn. Buiten zijn werk houdt hij van surfen, eten, worstelen met zijn hond en zijn nichtje en neefje verwennen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/automate-the-insurance-claim-lifecycle-using-agents-and-knowledge-bases-for-amazon-bedrock/

