AI is overal, zo lijkt het, hoewel vaak gepromoot met onvoldoende details om methoden te begrijpen. Ik zoek nu naar inhoud, geen handelsgeheimen, maar hoe ze precies AI gebruiken. Matt Graham (Product Engineering Group Director bij Cadence) gaf een goede en inhoudelijke tutorialpitch op DVCon, met echte voorbeelden van doelgerichte optimalisatie bij verificatie. Sommige hiervan zijn op leren gebaseerd, andere zijn gewoon verstandige automatisering. In de laatste klasse noemde hij testgewichtoptimalisatie, rangschikking van testwaarde en misschien het bestellen van tests op bijdrage aan dekking. De lage bijdragers naar het einde of uit de lijst duwen. Dit is menselijke intelligentie toegepast op automatisering, gewoon normale algoritmische vooruitgang.

AI is een grotere verandering, maar onze verwachtingen moeten gegrond blijven om teleurstelling en de AI-winters uit het verleden te voorkomen. Ik zie AI als een tweede industriële revolutie. We stopten met het gebruik van een os om een ploeg door een veld te slepen en begonnen met het bouwen van door stoom aangedreven tractoren. De industriële revolutie heeft de boeren niet vervangen, ze heeft ze productiever gemaakt. Tegenwoordig wijst AI op een vergelijkbare sprong in verificatieproductiviteit. Het grootste deel van Matts toespraak ging over kansen, waarvan sommige al waren geclaimd voor het Verisium-product.
AI-mogelijkheden in simulatie
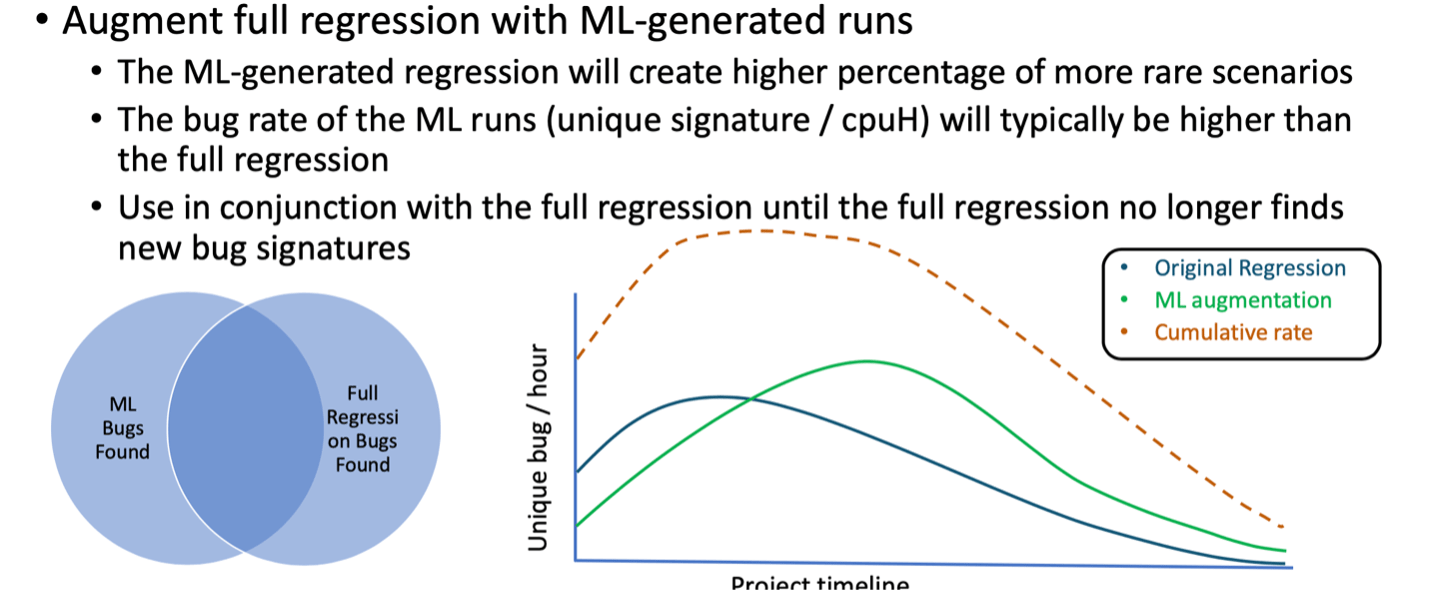
AI kan worden gebruikt om regressie te comprimeren door te leren van dekkingsgegevens in eerdere runs. Het kan worden gebruikt om de dekking te vergroten in licht bedekte gebieden en op licht bedekte eigendommen, beide het vermoeden waard dat ongeziene insecten op de loer liggen onder rotsen. Dergelijke methoden vervangen beperkte willekeur niet, maar verbeteren het eerder, waardoor de blootstelling aan bugs toeneemt ten opzichte van CR alleen.
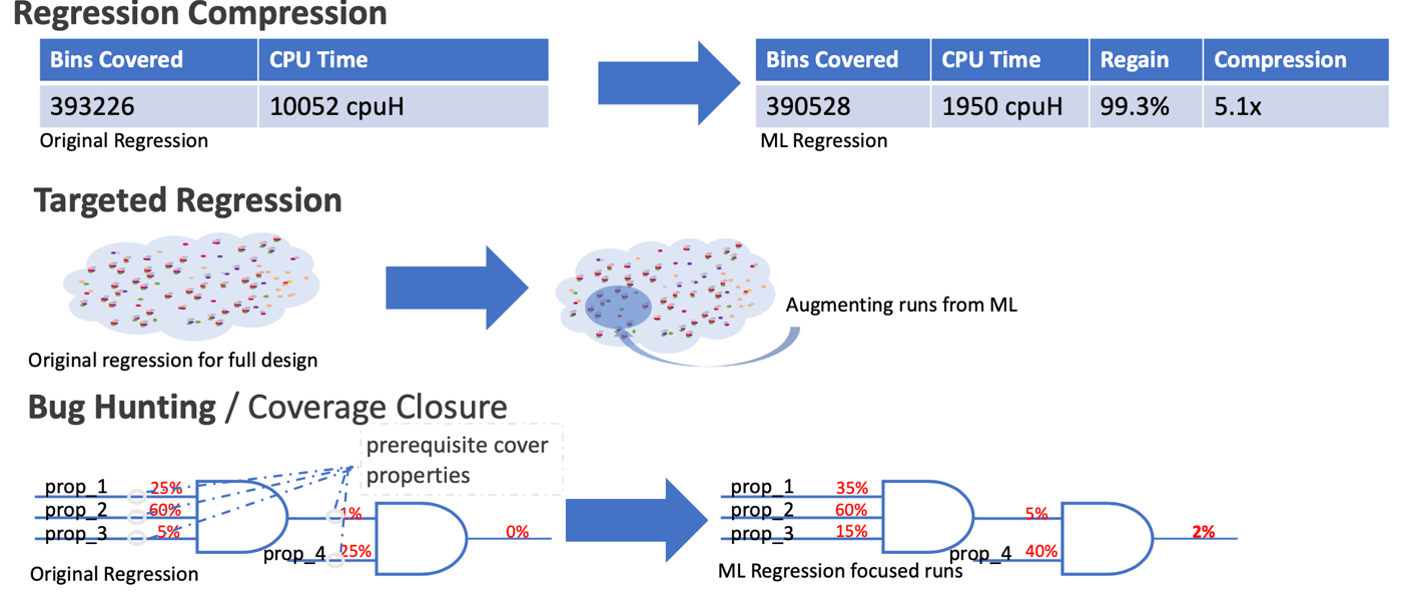
Een handige manier om zeldzame toestanden te benaderen, is door te leren over front-endtoestanden die van nature, zij het zelden, zeldzame toestanden bereiken of in de buurt komen. Nieuwe tests kunnen worden gesynthetiseerd op basis van dergelijk leren, wat samen met reguliere CR-tests het algehele bugpercentage zowel vroeg als laat in de bugrijpingscyclus kan verhogen.
AI-mogelijkheden in foutopsporing
Ik zie debug graag als de derde muur in verificatie. We hebben veel vooruitgang geboekt in de productiviteit van het genereren van tests door middel van hergebruik (VIP) en testsynthese, hoewel we duidelijk nog niet klaar zijn. En we blijven vooruitgang boeken op het gebied van verificatie-engines, van virtueel tot formeel en op hardware-ondersteunende platforms (ook nog niet gedaan). Maar debuggen blijft een hardnekkig handmatige taak, die een derde of meer van de verificatiebudgetten in beslag neemt. Debuggers zijn gepolijst, maar pakken de belangrijkste handmatige problemen niet aan - uitzoeken waar ze zich op moeten concentreren en vervolgens inzoomen om de onderliggende oorzaken te vinden. We gaan geen grote deuk maken totdat we beginnen met het afbreken van deze muur.

Dit begint met bugtriage. Er kan veel tijd in beslag worden genomen door simpelweg een post-regressie stapel bugs te scheiden in bugs die kritiek lijken en bugs die kunnen wachten op latere analyse. Vervolgens onderverdelen in groepen met vermoedelijke gemeenschappelijke oorzaken. Clustering is normaal voor leren zonder toezicht, in dit geval kijkend naar metadata van eerdere runs. Welke check-ins zijn er gedaan voordat de test mislukte? Wie heeft het uitgevoerd en wanneer? Hoe lang heeft de test geduurd? Wat was de storingsmelding? Welk deel van het ontwerp was verantwoordelijk voor de storingsmelding?
Matt wijst erop dat we als ingenieurs naar een kleine steekproef van deze factoren kunnen kijken, maar snel overweldigd raken als we naar honderd of duizenden stukjes informatie moeten kijken. AI is in deze context gewoon automatisering om grote hoeveelheden relatief ongestructureerde gegevens te verwerken om intelligente clustering te stimuleren. In een latere uitvoering, wanneer intelligente triage een probleem ziet dat met grote waarschijnlijkheid overeenkomt met een bestaand cluster, wordt de toewijzing van emmers duidelijk. Een ingenieur hoeft dan alleen maar de meest voor de hand liggende of gemakkelijkste falende test uit te voeren om een oorzaak te vinden. Ze kunnen dan de regressie opnieuw uitvoeren in de verwachting dat alle of de meeste van die klasse problemen zullen verdwijnen.
Bij problemen die u wilt debuggen, kan een diepgaande golfvormanalyse een waarschijnlijke oorzaak verder beperken. Legacy en huidige golfvormen vergelijken, legacy RTL versus huidige RTL, een legacy testbank versus de huidige testbank. Er is zelfs onderzoek gedaan naar AI-gestuurde methoden om een fout te lokaliseren – naar een bestand of mogelijk zelfs naar een module (zie dit bijvoorbeeld).
AI zal de verificatiecomplexiteit wegnemen
AI-gebaseerde verificatie is een nieuw idee voor ons allemaal; niemand verwacht een stapfunctiesprong naar volledige acceptatie. Dat gezegd hebbende, er zijn al veelbelovende tekenen. Het orkestreren van runs tegen bewijsmethoden verscheen al vroeg in formele methodologieën. Regressie-optimalisatie voor simulatie bevindt zich op een bemoedigende opgang naar een bredere acceptatie. Debug op basis van AI is de nieuweling in deze groep en laat bemoedigende resultaten zien bij vroege acceptatie. Wat ongetwijfeld zal leiden tot verdere verbeteringen, waardoor debug verder op de acceptatiecurve zal worden geduwd. Allemaal inspirerende vorderingen op weg naar een veel productievere verificatietoekomst.
U kunt HIER meer leren. (Heb een link nodig)
Deel dit bericht via:
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://semiwiki.com/artificial-intelligence/326633-ai-in-verification-a-cadence-perspective/

