In het zich ontwikkelende productielandschap is de transformatieve kracht van AI en machine learning (ML) duidelijk zichtbaar, waardoor een digitale revolutie ontstaat die de bedrijfsvoering stroomlijnt en de productiviteit verhoogt. Deze vooruitgang brengt echter unieke uitdagingen met zich mee voor ondernemingen die op zoek zijn naar datagestuurde oplossingen. Industriële faciliteiten worstelen met enorme hoeveelheden ongestructureerde gegevens, afkomstig van sensoren, telemetriesystemen en apparatuur verspreid over productielijnen. Realtime data zijn van cruciaal belang voor toepassingen als voorspellend onderhoud en detectie van afwijkingen, maar het ontwikkelen van aangepaste ML-modellen voor elk industrieel gebruik met dergelijke tijdreeksdata vergt veel tijd en middelen van datawetenschappers, wat een brede acceptatie belemmert.
generatieve AI met behulp van grote, vooraf getrainde funderingsmodellen (FM's), zoals Claude kan snel een verscheidenheid aan inhoud genereren, van conversatietekst tot computercode op basis van eenvoudige tekstprompts, ook wel bekend als zero-shot-aanwijzing. Dit elimineert de noodzaak voor datawetenschappers om handmatig specifieke ML-modellen voor elke gebruikssituatie te ontwikkelen, en democratiseert daardoor de toegang tot AI, waar zelfs kleine fabrikanten van profiteren. Werknemers worden productiever dankzij door AI gegenereerde inzichten, ingenieurs kunnen proactief afwijkingen opsporen, managers van de toeleveringsketen optimaliseren de voorraden en het fabrieksmanagement neemt weloverwogen, datagestuurde beslissingen.
Niettemin worden zelfstandige FM's geconfronteerd met beperkingen bij het verwerken van complexe industriële gegevens met beperkingen op het gebied van de contextgrootte (doorgaans minder dan 200,000 tokens), wat uitdagingen met zich meebrengt. Om dit aan te pakken, kunt u de mogelijkheid van de FM gebruiken om code te genereren als reactie op natuurlijke taalquery's (NLQ's). Agenten houden van Panda'sAI spelen een rol door deze code uit te voeren op tijdreeksgegevens met een hoge resolutie en fouten af te handelen met behulp van FM's. PandasAI is een Python-bibliotheek die generatieve AI-mogelijkheden toevoegt aan panda's, de populaire tool voor gegevensanalyse en -manipulatie.
Complexe NLQ's, zoals tijdreeksgegevensverwerking, aggregatie op meerdere niveaus en draaitabel- of gezamenlijke tabelbewerkingen, kunnen echter inconsistente Python-scriptnauwkeurigheid opleveren met een zero-shot-prompt.
Om de nauwkeurigheid van het genereren van code te verbeteren, stellen we dynamisch construeren voor aanwijzingen voor meerdere opnames voor NLQ's. Multi-shot-prompts bieden extra context aan de FM door verschillende voorbeelden van gewenste outputs voor soortgelijke prompts te tonen, waardoor de nauwkeurigheid en consistentie worden vergroot. In dit bericht worden multi-shot-prompts opgehaald uit een insluiting met succesvolle Python-code die wordt uitgevoerd op een vergelijkbaar gegevenstype (bijvoorbeeld tijdreeksgegevens met hoge resolutie van Internet of Things-apparaten). De dynamisch geconstrueerde multi-shot prompt biedt de meest relevante context voor de FM en vergroot de mogelijkheden van de FM op het gebied van geavanceerde wiskundige berekeningen, verwerking van tijdreeksgegevens en begrip van gegevensacroniemen. Deze verbeterde respons maakt het voor werknemers en operationele teams mogelijk om met data om te gaan en inzichten te verkrijgen zonder dat daarvoor uitgebreide datawetenschapsvaardigheden nodig zijn.
Naast de analyse van tijdreeksgegevens blijken FM's waardevol in verschillende industriële toepassingen. Onderhoudsteams beoordelen de staat van activa en maken beelden voor Amazon Rekognition-gebaseerde functionaliteitssamenvattingen en analyse van de hoofdoorzaak van afwijkingen met behulp van intelligente zoekopdrachten met Ophalen Augmented Generation (VOD). Om deze workflows te vereenvoudigen heeft AWS geïntroduceerd Amazonebodem, waardoor u generatieve AI-applicaties kunt bouwen en schalen met ultramoderne, vooraf getrainde FM's zoals Claude v2. Met Kennisbanken voor Amazon Bedrockkunt u het RAG-ontwikkelingsproces vereenvoudigen, zodat fabrieksarbeiders een nauwkeurigere analyse van de hoofdoorzaak van afwijkingen kunnen krijgen. Onze post toont een intelligente assistent voor industrieel gebruik, mogelijk gemaakt door Amazon Bedrock, die NLQ-uitdagingen aanpakt, samenvattingen van onderdelen genereert uit afbeeldingen en de FM-reacties voor apparatuurdiagnose verbetert via de RAG-aanpak.
Overzicht oplossingen
Het volgende diagram illustreert de oplossingsarchitectuur.

De workflow omvat drie verschillende gebruiksscenario's:
Use case 1: NLQ met tijdreeksgegevens
De workflow voor NLQ met tijdreeksgegevens bestaat uit de volgende stappen:
- We gebruiken een conditiemonitoringsysteem met ML-mogelijkheden voor het detecteren van afwijkingen, zoals Amazone Monitron, om de gezondheid van industriële apparatuur te monitoren. Amazon Monitron kan potentiële apparatuurstoringen detecteren aan de hand van de trillings- en temperatuurmetingen van de apparatuur.
- Wij verzamelen tijdreeksgegevens door deze te verwerken Amazone Monitron gegevens door Amazon Kinesis-gegevensstromen en Amazon Data-brandslang, het converteren naar een CSV-tabelformaat en het opslaan in een Amazon eenvoudige opslagservice (Amazon S3) emmer.
- De eindgebruiker kan beginnen met chatten met zijn tijdreeksgegevens in Amazon S3 door een zoekopdracht in natuurlijke taal naar de Streamlit-app te sturen.
- De Streamlit-app stuurt gebruikersvragen door naar de Amazon Bedrock Titan-tekstinsluitingsmodel om deze zoekopdracht in te sluiten, en voert een overeenkomstzoekopdracht uit binnen een Amazon OpenSearch-service index, die eerdere NLQ's en voorbeeldcodes bevat.
- Na het zoeken naar overeenkomsten worden de belangrijkste vergelijkbare voorbeelden, waaronder NLQ-vragen, gegevensschema's en Python-codes, ingevoegd in een aangepaste prompt.
- PandasAI stuurt deze aangepaste prompt naar het Amazon Bedrock Claude v2-model.
- De app gebruikt de PandasAI-agent om te communiceren met het Amazon Bedrock Claude v2-model, waarbij Python-code wordt gegenereerd voor Amazon Monitron-gegevensanalyse en NLQ-reacties.
- Nadat het Amazon Bedrock Claude v2-model de Python-code retourneert, voert PandasAI de Python-query uit op de Amazon Monitron-gegevens die zijn geüpload vanuit de app, waarbij code-uitvoer wordt verzameld en eventuele noodzakelijke nieuwe pogingen voor mislukte uitvoeringen worden aangepakt.
- De Streamlit-app verzamelt de respons via PandasAI en levert de output aan gebruikers. Als de uitvoer bevredigend is, kan de gebruiker deze als nuttig markeren en de door NLQ en Claude gegenereerde Python-code opslaan in OpenSearch Service.
Use case 2: Samenvatting van het genereren van defecte onderdelen
Onze gebruikscasus voor het genereren van samenvattingen bestaat uit de volgende stappen:
- Nadat de gebruiker weet welk industrieel bedrijfsmiddel afwijkend gedrag vertoont, kan hij of zij afbeeldingen van het defecte onderdeel uploaden om vast te stellen of er fysiek iets mis is met dit onderdeel, afhankelijk van de technische specificaties en bedrijfstoestand.
- De gebruiker kan de Amazon-herkenning DetectText API om tekstgegevens uit deze afbeeldingen te extraheren.
- De geëxtraheerde tekstgegevens worden opgenomen in de prompt voor het Amazon Bedrock Claude v2-model, waardoor het model een samenvatting van 200 woorden kan genereren van het defecte onderdeel. De gebruiker kan deze informatie gebruiken om verdere inspectie van het onderdeel uit te voeren.
Gebruiksscenario 3: Diagnose van de hoofdoorzaak
Onze gebruikscasus voor hoofdoorzaakdiagnose bestaat uit de volgende stappen:
- De gebruiker verkrijgt bedrijfsgegevens in verschillende documentformaten (PDF, TXT, enzovoort) die verband houden met defecte assets, en uploadt deze naar een S3-bucket.
- Een kennisbank van deze bestanden wordt gegenereerd in Amazon Bedrock met een Titan-tekstinsluitingsmodel en een standaard OpenSearch Service-vectorarchief.
- De gebruiker stelt vragen met betrekking tot de diagnose van de hoofdoorzaak van defecte apparatuur. Antwoorden worden gegenereerd via de Amazon Bedrock-kennisbank met een RAG-aanpak.
Voorwaarden
Om dit bericht te kunnen volgen, moet u aan de volgende vereisten voldoen:
Implementeer de oplossingsinfrastructuur
Voer de volgende stappen uit om uw oplossingsbronnen in te stellen:
- Implementeer de AWS CloudFormatie sjabloon opensearchsagemaker.yml, waarmee een OpenSearch Service-verzameling en -index wordt gemaakt, Amazon Sage Maker notebook-instantie en S3-bucket. U kunt deze AWS CloudFormation-stack een naam geven als:
genai-sagemaker. - Open de SageMaker-notebookinstantie in JupyterLab. U vindt het volgende GitHub repo al gedownload op dit exemplaar: het ontsluiten van het potentieel van generatieve AI in industriële activiteiten.
- Voer het notitieblok uit vanuit de volgende map in deze repository: ontsluiten-het-potentieel-van-generatieve-ai-in-industrial-operations/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. Dit notebook laadt de OpenSearch Service-index met behulp van het SageMaker-notebook om sleutel-waardeparen op te slaan uit de bestaande 23 NLQ-voorbeelden.
- Upload documenten uit de gegevensmap assetpartdoc in de GitHub-repository naar de S3-bucket die wordt vermeld in de CloudFormation-stackuitvoer.

Vervolgens maak je de kennisbank voor de documenten in Amazon S3.
- Kies op de Amazon Bedrock-console Kennisbank in het navigatievenster.
- Kies Creëer kennisbasis.
- Voor Naam kennisbank, voer een naam in.
- Voor Runtime-rolselecteer Maak en gebruik een nieuwe servicerol.
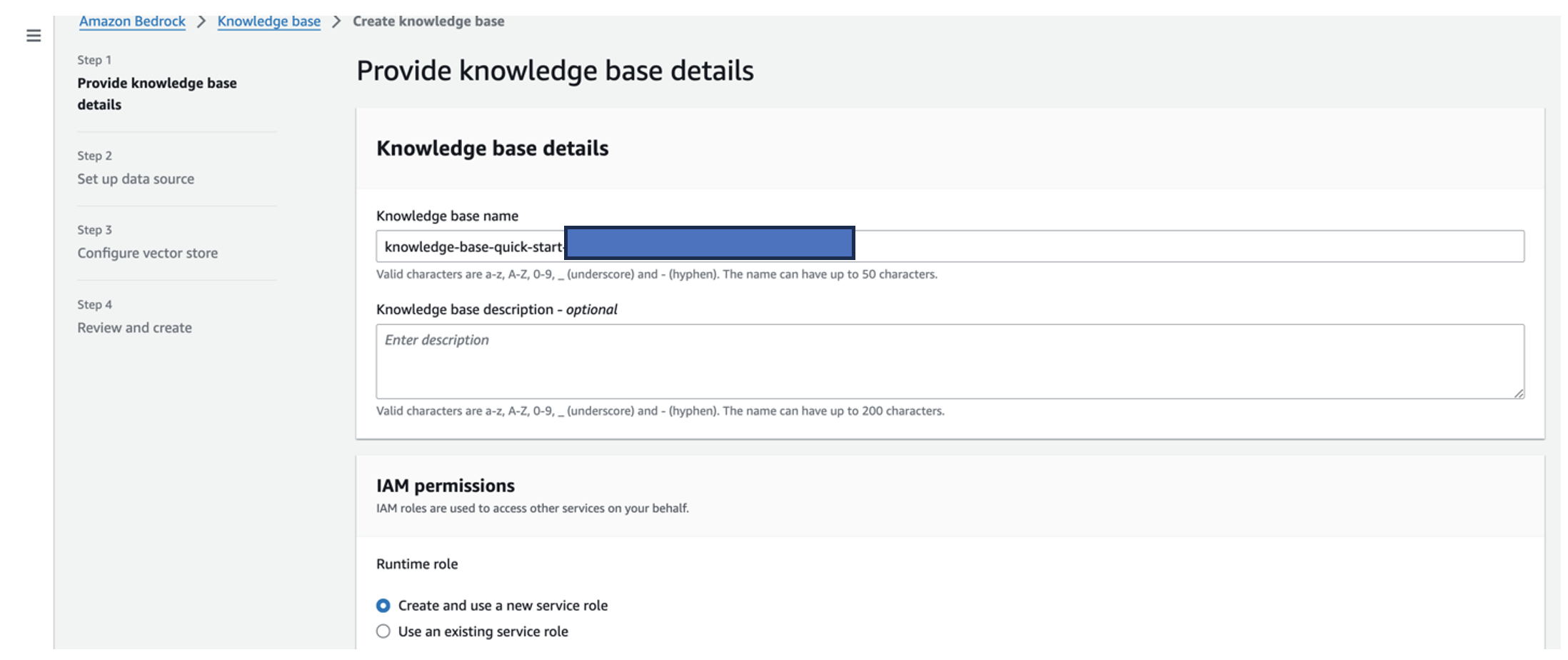
- Voor Naam gegevensbron, voer de naam van uw gegevensbron in.
- Voor S3-URI, voer het S3-pad in van de bucket waar u de hoofdoorzaakdocumenten hebt geüpload.
- Kies Volgende.
 Het Titan-inbeddingsmodel wordt automatisch geselecteerd.
Het Titan-inbeddingsmodel wordt automatisch geselecteerd. - kies Maak snel een nieuwe vectorwinkel.
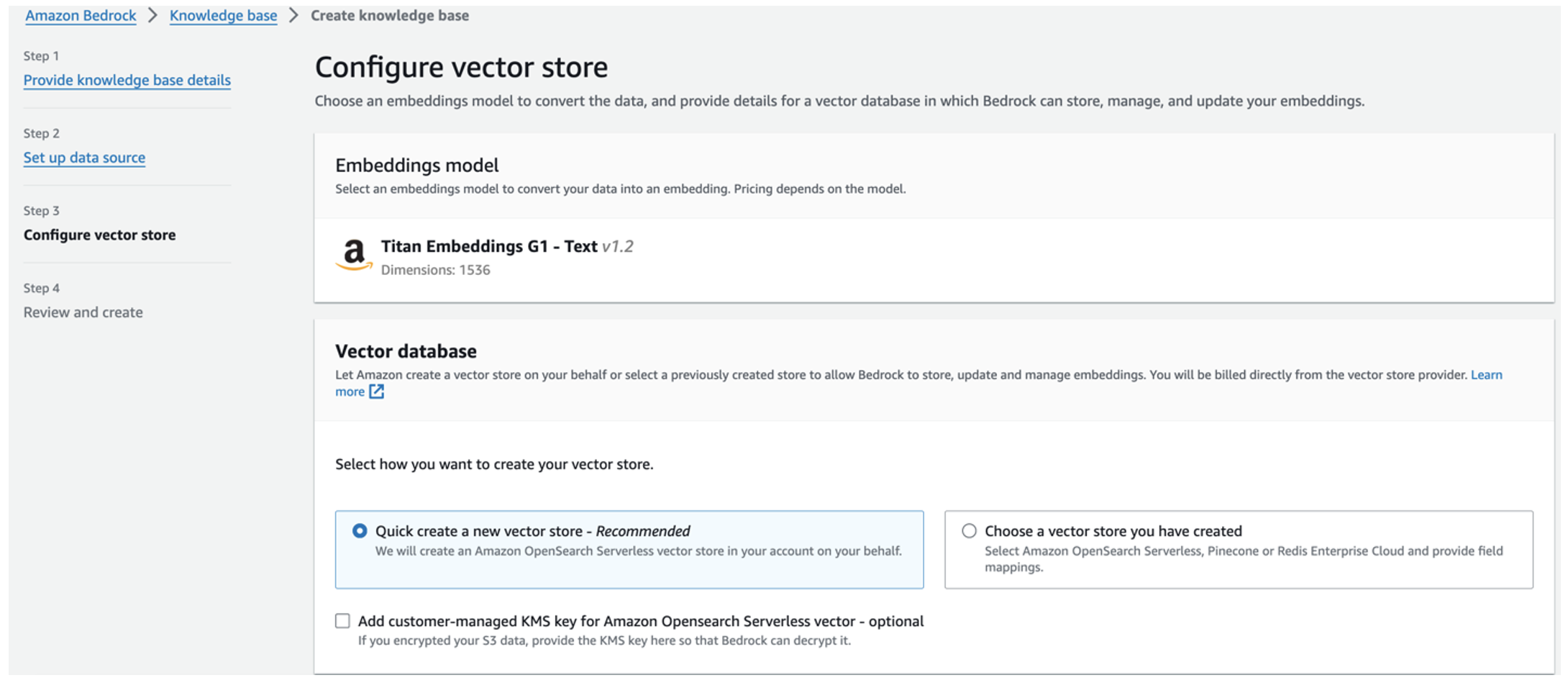
- Controleer uw instellingen en creëer de kennisbank door te kiezen Creëer kennisbasis.
- Nadat de kennisbank met succes is gemaakt, kiest u Synchroniseren om de S3-bucket te synchroniseren met de kennisbank.

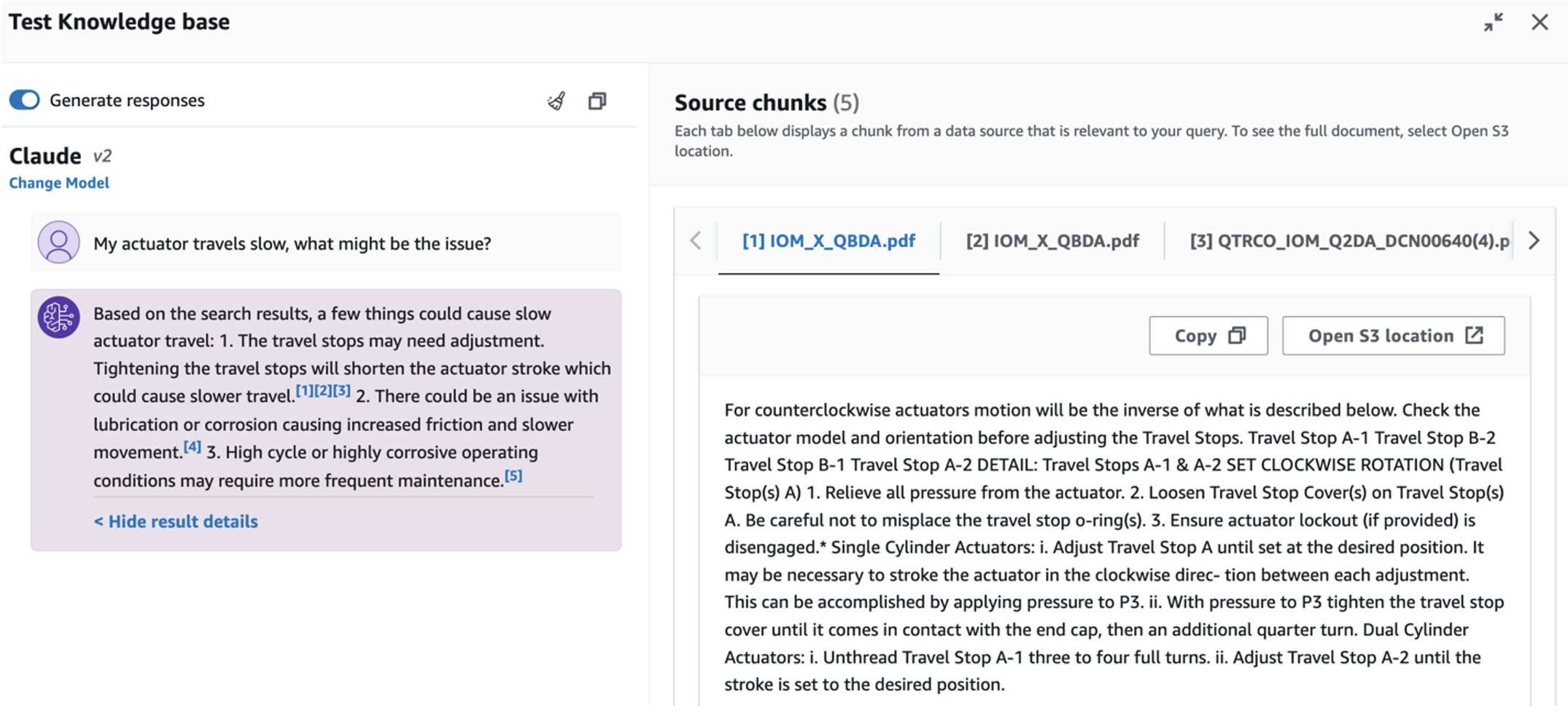
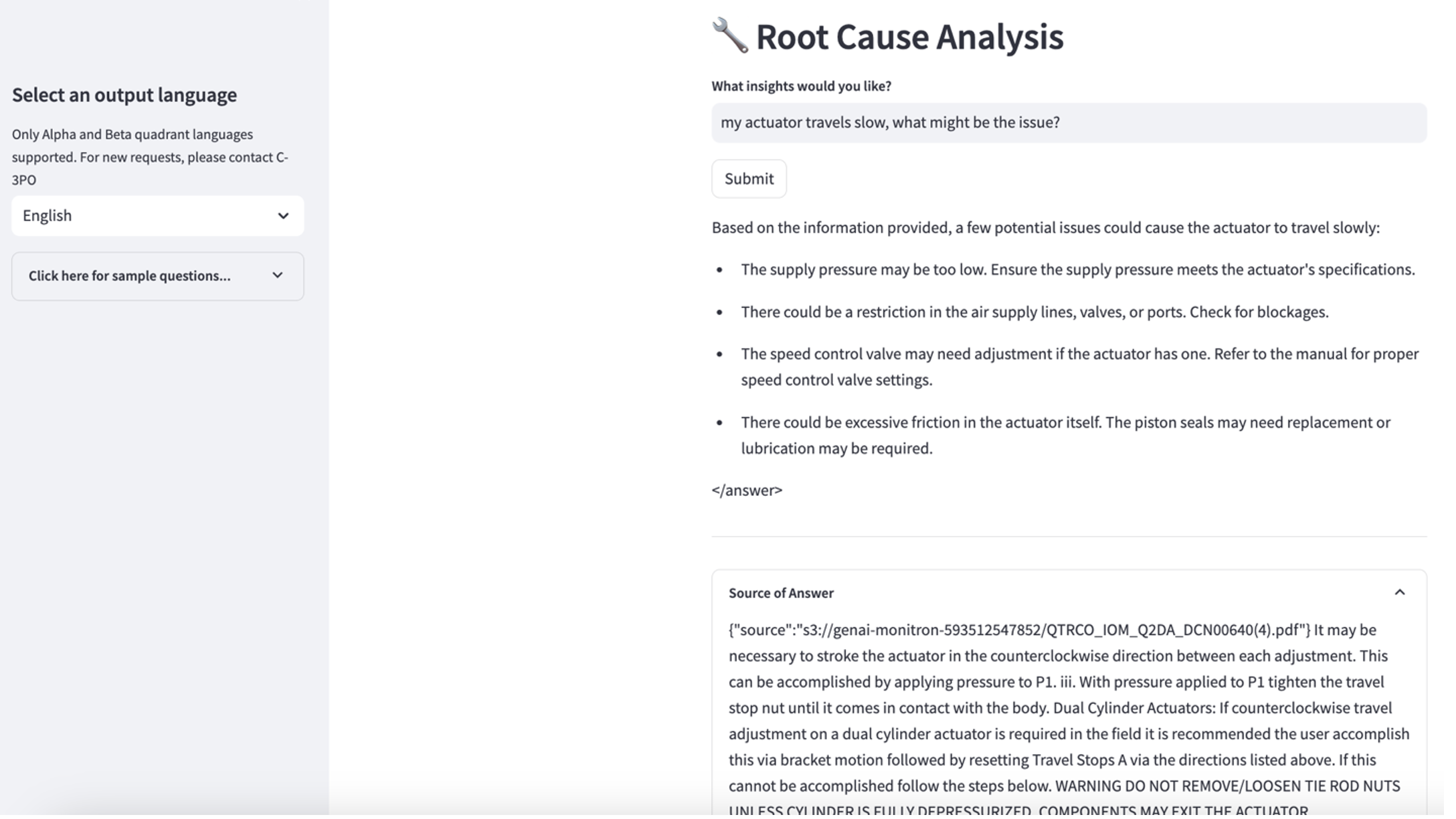
- Nadat u de kennisbank heeft opgezet, kunt u de RAG-aanpak voor de diagnose van de hoofdoorzaak testen door vragen te stellen als "Mijn actuator beweegt langzaam, wat kan het probleem zijn?"
De volgende stap is het implementeren van de app met de vereiste bibliotheekpakketten op uw pc of een EC2-instantie (Ubuntu Server 22.04 LTS).
- Stel uw AWS-inloggegevens in met de AWS CLI op uw lokale pc. Voor de eenvoud kunt u dezelfde beheerdersrol gebruiken die u hebt gebruikt om de CloudFormation-stack te implementeren. Als u Amazon EC2 gebruikt, koppel een geschikte IAM-rol aan de instantie.
- Kloon GitHub repo:
- Verander de map in
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcen voer desetup.shscript in deze map om de vereiste pakketten te installeren, inclusief LangChain en PandasAI:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Voer de Streamlit-app uit met de volgende opdracht:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Geef de OpenSearch Service-verzameling ARN op die u in Amazon Bedrock uit de vorige stap hebt gemaakt.
Chat met uw asset health-assistent
Nadat u de end-to-end-implementatie hebt voltooid, heeft u toegang tot de app via localhost op poort 8501, waardoor een browservenster met de webinterface wordt geopend. Als u de app op een EC2-instantie heeft geïmplementeerd, geef toegang tot poort 8501 via de inkomende regel van de beveiligingsgroep. U kunt naar verschillende tabbladen navigeren voor verschillende gebruiksscenario's.
Ontdek gebruiksscenario 1
Om de eerste gebruikscasus te verkennen, kiest u Gegevensinzicht en grafiek. Begin met het uploaden van uw tijdreeksgegevens. Als u geen bestaand tijdreeksgegevensbestand heeft om te gebruiken, kunt u het volgende uploaden voorbeeld CSV-bestand met anonieme Amazon Monitron-projectgegevens. Als je al een Amazon Monitron-project hebt, raadpleeg dan Genereer bruikbare inzichten voor voorspellend onderhoudsbeheer met Amazon Monitron en Amazon Kinesis om uw Amazon Monitron-gegevens naar Amazon S3 te streamen en uw gegevens met deze applicatie te gebruiken.
Wanneer het uploaden is voltooid, voert u een vraag in om een gesprek met uw gegevens te starten. In de linkerzijbalk vindt u voor uw gemak een reeks voorbeeldvragen. De volgende schermafbeeldingen illustreren het antwoord en de Python-code die door de FM wordt gegenereerd bij het invoeren van een vraag zoals “Vertel mij het unieke aantal sensoren voor elke site die respectievelijk wordt weergegeven als Waarschuwing of Alarm?” (een moeilijke vraag) of "Kunt u voor sensoren waarbij het temperatuursignaal NIET Gezond is, de tijdsduur in dagen berekenen voor elke sensor die een abnormaal trillingssignaal vertoont?" (een vraag op uitdagingsniveau). De app beantwoordt uw vraag en toont ook het Python-script van de gegevensanalyse die is uitgevoerd om dergelijke resultaten te genereren.


Als u tevreden bent met het antwoord, kunt u het markeren als Nuttig, waarbij de door NLQ en Claude gegenereerde Python-code wordt opgeslagen in een OpenSearch Service-index.

Ontdek gebruiksscenario 2
Om de tweede gebruikscasus te verkennen, kiest u de Samenvatting van vastgelegde afbeeldingen tabblad in de Streamlit-app. U kunt een afbeelding van uw industriële asset uploaden en de applicatie genereert op basis van de afbeeldingsinformatie een samenvatting van 200 woorden van de technische specificaties en bedrijfstoestand. De volgende schermafbeelding toont de samenvatting die is gegenereerd op basis van een afbeelding van een riemmotoraandrijving. Om deze functie te testen kunt u, als u geen geschikte afbeelding heeft, het volgende gebruiken voorbeeld afbeelding.
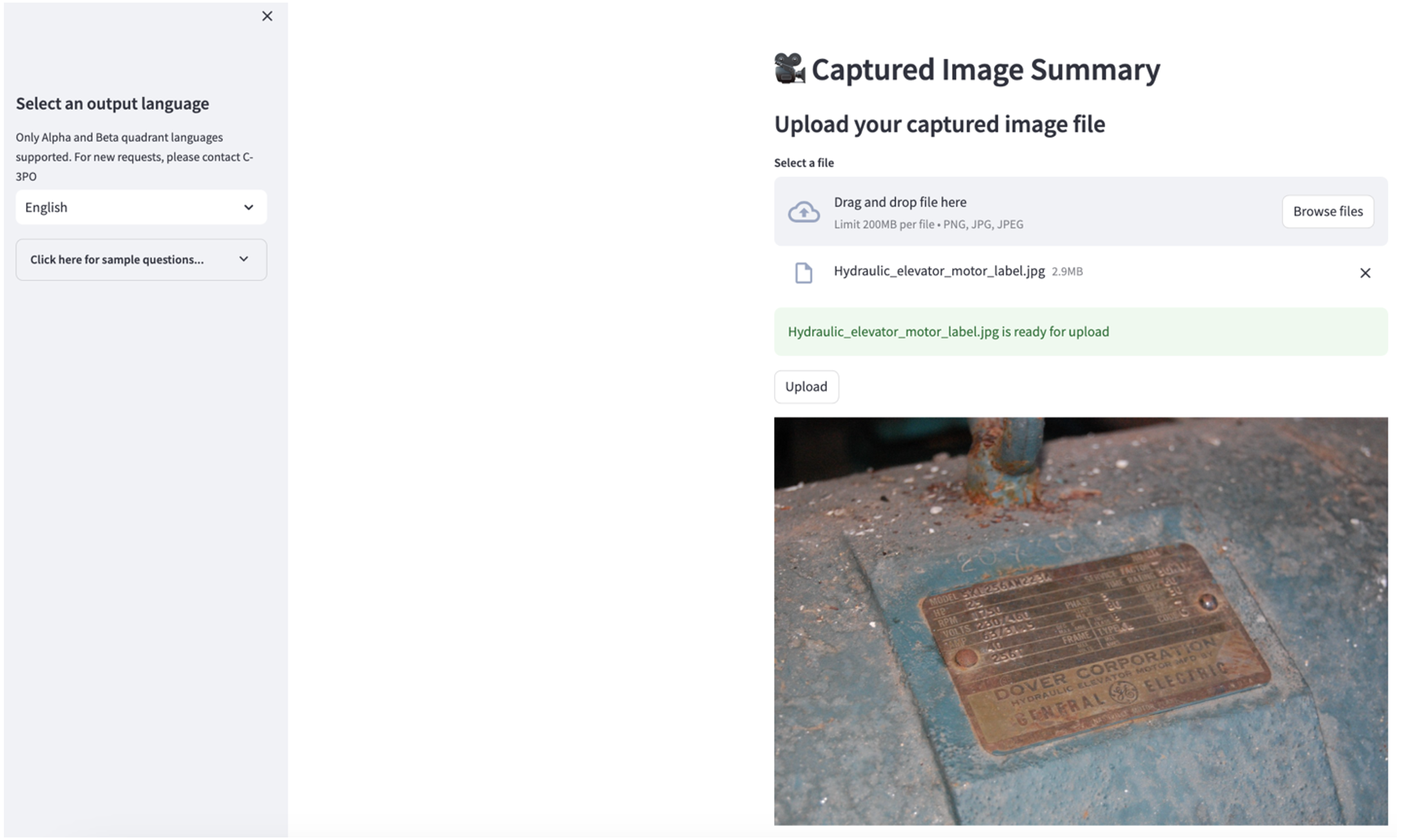
Etiket hydraulische liftmotor” van Clarence Risher heeft een licentie onder CC BY-SA 2.0.

Ontdek gebruiksscenario 3
Om de derde gebruikscasus te verkennen, kiest u de Diagnose van de oorzaak tabblad. Voer een vraag in met betrekking tot uw kapotte industriële asset, zoals: 'Mijn actuator beweegt langzaam, wat kan het probleem zijn?' Zoals weergegeven in de volgende schermafbeelding levert de toepassing een antwoord met het brondocumentfragment dat is gebruikt om het antwoord te genereren.
Gebruiksscenario 1: Ontwerpdetails
In deze sectie bespreken we de ontwerpdetails van de applicatieworkflow voor de eerste use case.
Op maat gemaakt promptgebouw
De zoekopdracht in natuurlijke taal van de gebruiker heeft verschillende moeilijke niveaus: eenvoudig, moeilijk en uitdagend.
Duidelijke vragen kunnen de volgende verzoeken omvatten:
- Selecteer unieke waarden
- Tel de totale aantallen
- Sorteer waarden
Voor deze vragen kan PandasAI rechtstreeks communiceren met de FM om Python-scripts te genereren voor verwerking.
Moeilijke vragen vereisen een eenvoudige aggregatie of tijdreeksanalyse, zoals de volgende:
- Selecteer eerst de waarde en groepeer de resultaten hiërarchisch
- Voer statistieken uit na de eerste recordselectie
- Aantal tijdstempels (bijvoorbeeld min en max)
Voor moeilijke vragen helpt een promptsjabloon met gedetailleerde stapsgewijze instructies FM's bij het geven van nauwkeurige antwoorden.
Voor vragen op uitdagingsniveau zijn geavanceerde wiskundige berekeningen en tijdreeksverwerking vereist, zoals de volgende:
- Bereken de duur van de afwijking voor elke sensor
- Bereken maandelijks afwijkingensensoren voor de locatie
- Vergelijk sensormetingen onder normale werking en abnormale omstandigheden
Voor deze vragen kunt u multi-shots gebruiken in een aangepaste prompt om de nauwkeurigheid van de antwoorden te verbeteren. Dergelijke multi-shots tonen voorbeelden van geavanceerde tijdreeksverwerking en wiskundige berekeningen, en zullen context bieden voor de FM om relevante gevolgtrekkingen te maken op basis van soortgelijke analyses. Het dynamisch invoegen van de meest relevante voorbeelden uit een NLQ-vragenbank in de prompt kan een uitdaging zijn. Eén oplossing is om insluitingen te construeren op basis van bestaande NLQ-vraagvoorbeelden en deze insluitingen op te slaan in een vectoropslag zoals OpenSearch Service. Wanneer een vraag naar de Streamlit-app wordt verzonden, wordt de vraag gevectoriseerd door Bedrock-inbedding. De top N meest relevante insluitingen voor die vraag worden opgehaald met behulp van opensearch_vector_search.similarity_search en ingevoegd in de promptsjabloon als een multi-shotprompt.
Het volgende diagram illustreert deze workflow.
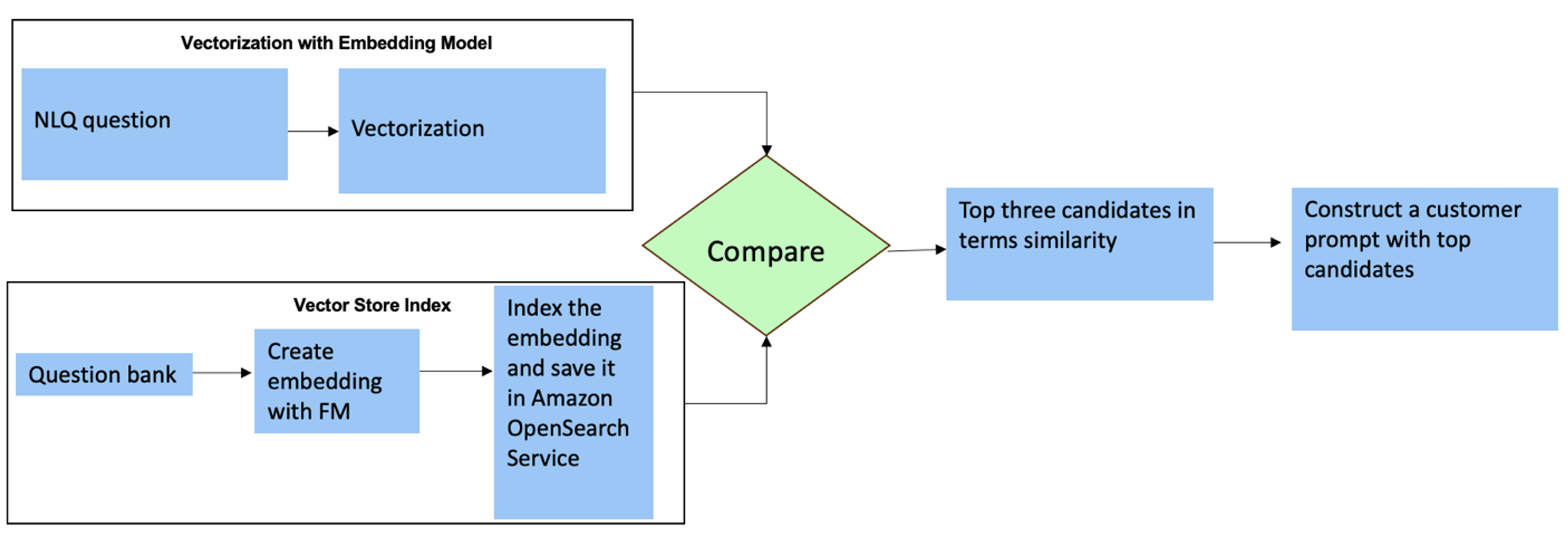
De inbeddingslaag wordt opgebouwd met behulp van drie belangrijke hulpmiddelen:
- Inbeddingsmodel – We gebruiken Amazon Titan Embeddings die beschikbaar zijn via Amazon Bedrock (amazon.titan-embed-text-v1) om numerieke representaties van tekstdocumenten te genereren.
- Vectorwinkel – Voor onze vectorwinkel gebruiken we OpenSearch Service via het LangChain-framework, waardoor de opslag van insluitingen die zijn gegenereerd op basis van NLQ-voorbeelden in dit notitieboekje wordt gestroomlijnd.
- Index – De OpenSearch Service-index speelt een cruciale rol bij het vergelijken van invoerinsluitingen met documentinsluitingen en het vergemakkelijken van het ophalen van relevante documenten. Omdat de Python-voorbeeldcodes als JSON-bestand werden opgeslagen, werden ze in OpenSearch Service als vectoren geïndexeerd via een OpenSearchVevtorSearch.fromtexts API-oproep.
Continue verzameling van door mensen gecontroleerde voorbeelden via Streamlit
Bij het begin van de app-ontwikkeling zijn we begonnen met slechts 23 opgeslagen voorbeelden in de OpenSearch Service-index als insluitingen. Terwijl de app in het veld live gaat, beginnen gebruikers hun NLQ's via de app in te voeren. Vanwege de beperkte voorbeelden die beschikbaar zijn in de sjabloon, vinden sommige NLQ's echter mogelijk geen vergelijkbare aanwijzingen. Om deze insluitingen voortdurend te verrijken en relevantere gebruikersprompts te bieden, kunt u de Streamlit-app gebruiken voor het verzamelen van door mensen gecontroleerde voorbeelden.
Binnen de app dient hiervoor de volgende functie. Wanneer eindgebruikers de uitvoer nuttig vinden en selecteren Nuttig, volgt de applicatie deze stappen:
- Gebruik de callback-methode van PandasAI om het Python-script te verzamelen.
- Formatteer het Python-script, de invoervraag en de CSV-metagegevens opnieuw in een tekenreeks.
- Controleer of dit NLQ-voorbeeld al bestaat in de huidige OpenSearch Service-index met behulp van opensearch_vector_search.similarity_search_with_score.
- Als er geen soortgelijk voorbeeld is, wordt deze NLQ toegevoegd aan de OpenSearch Service-index met behulp van opensearch_vector_search.add_texts.
In het geval dat een gebruiker selecteert Niet behulpzaam, er wordt geen actie ondernomen. Dit iteratieve proces zorgt ervoor dat het systeem voortdurend verbetert door het opnemen van door de gebruiker bijgedragen voorbeelden.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
Door menselijke auditing op te nemen, groeit het aantal voorbeelden in OpenSearch Service dat beschikbaar is voor snelle insluiting naarmate de app meer gebruikt wordt. Deze uitgebreide inbeddingsdataset resulteert in een verbeterde zoeknauwkeurigheid in de loop van de tijd. Specifiek voor uitdagende NLQ's bereikt de responsnauwkeurigheid van de FM ongeveer 90% bij het dynamisch invoegen van vergelijkbare voorbeelden om aangepaste aanwijzingen voor elke NLQ-vraag te construeren. Dit vertegenwoordigt een opmerkelijke stijging van 28% vergeleken met scenario's zonder multi-shot-prompts.
Gebruiksscenario 2: Ontwerpdetails
Op de Streamlit-app Samenvatting van vastgelegde afbeeldingen tabblad kunt u direct een afbeeldingsbestand uploaden. Hiermee wordt de Amazon Rekognition API gestart (detecteer_tekst API), het extraheren van tekst uit het afbeeldingslabel met gedetailleerde machinespecificaties. Vervolgens worden de geëxtraheerde tekstgegevens als context van een prompt naar het Amazon Bedrock Claude-model gestuurd, wat resulteert in een samenvatting van 200 woorden.
Vanuit het perspectief van de gebruikerservaring is het inschakelen van streamingfunctionaliteit voor een tekstsamenvattingstaak van het grootste belang, waardoor gebruikers de door FM gegenereerde samenvatting in kleinere stukjes kunnen lezen in plaats van te wachten op de volledige uitvoer. Amazon Bedrock faciliteert streaming via zijn API (bedrock_runtime.invoke_model_with_response_stream).
Gebruiksscenario 3: Ontwerpdetails
In dit scenario hebben we een chatbot-applicatie ontwikkeld die zich richt op analyse van de hoofdoorzaak, waarbij we gebruik maken van de RAG-aanpak. Deze chatbot maakt gebruik van meerdere documenten met betrekking tot lagerapparatuur om de analyse van de hoofdoorzaak te vergemakkelijken. Deze op RAG gebaseerde chatbot voor oorzaakanalyse maakt gebruik van kennisbanken voor het genereren van vectortekstrepresentaties of insluitingen. Knowledge Bases voor Amazon Bedrock is een volledig beheerde mogelijkheid waarmee u de volledige RAG-workflow kunt implementeren, van opname tot ophalen en snelle uitbreiding, zonder dat u aangepaste integraties met gegevensbronnen hoeft te bouwen of gegevensstromen en RAG-implementatiedetails hoeft te beheren.
Als u tevreden bent met de kennisbankreactie van Amazon Bedrock, kunt u de hoofdoorzaakreactie uit de kennisbank integreren in de Streamlit-app.
Opruimen
Om kosten te besparen, verwijdert u de bronnen die u in dit bericht heeft gemaakt:
- Verwijder de kennisbank van Amazon Bedrock.
- Verwijder de OpenSearch Service-index.
- Verwijder de genai-sagemaker CloudFormation-stack.
- Stop de EC2-instantie als u een EC2-instantie hebt gebruikt om de Streamlit-app uit te voeren.
Conclusie
Generatieve AI-toepassingen hebben al verschillende bedrijfsprocessen getransformeerd, waardoor de productiviteit en vaardigheden van werknemers zijn verbeterd. De beperkingen van FM's bij het verwerken van tijdreeksgegevensanalyse hebben echter de volledige benutting ervan door industriële klanten belemmerd. Deze beperking heeft de toepassing van generatieve AI op het belangrijkste gegevenstype dat dagelijks wordt verwerkt belemmerd.
In dit bericht hebben we een generatieve AI-toepassingsoplossing geïntroduceerd die is ontworpen om deze uitdaging voor industriële gebruikers te verlichten. Deze applicatie maakt gebruik van een open source-agent, PandasAI, om de tijdreeksanalysemogelijkheden van een FM te versterken. In plaats van tijdreeksgegevens rechtstreeks naar FM's te verzenden, gebruikt de app PandasAI om Python-code te genereren voor de analyse van ongestructureerde tijdreeksgegevens. Om de nauwkeurigheid van het genereren van Python-code te verbeteren, is een aangepaste workflow voor het genereren van prompts met menselijke auditing geïmplementeerd.
Dankzij inzichten in de gezondheid van hun bedrijfsmiddelen kunnen industriële werknemers het potentieel van generatieve AI volledig benutten voor verschillende gebruiksscenario's, waaronder diagnose van de hoofdoorzaak en planning van vervanging van onderdelen. Met Knowledge Bases voor Amazon Bedrock kunnen ontwikkelaars de RAG-oplossing eenvoudig bouwen en beheren.
Het traject van bedrijfsdatabeheer en -operaties beweegt zich onmiskenbaar in de richting van een diepere integratie met generatieve AI voor uitgebreide inzichten in de operationele gezondheid. Deze verschuiving, onder leiding van Amazon Bedrock, wordt aanzienlijk versterkt door de groeiende robuustheid en het potentieel van LLM’s zoals Amazonebodem Claude 3 om oplossingen verder te verheffen. Voor meer informatie kunt u terecht op de website raadplegen Amazon Bedrock-documentatieen ga aan de slag met de Amazon Bedrock-workshop.
Over de auteurs
 Julia Hu is een Sr. AI/ML Solutions Architect bij Amazon Web Services. Ze is gespecialiseerd in Generatieve AI, Toegepaste Data Science en IoT-architectuur. Momenteel maakt ze deel uit van het Amazon Q-team en is ze een actief lid/mentor in de Machine Learning Technical Field Community. Ze werkt met klanten, variërend van start-ups tot ondernemingen, om geweldige generatieve AI-oplossingen te ontwikkelen. Ze is vooral gepassioneerd door het inzetten van grote taalmodellen voor geavanceerde data-analyse en het verkennen van praktische toepassingen die uitdagingen in de echte wereld aanpakken.
Julia Hu is een Sr. AI/ML Solutions Architect bij Amazon Web Services. Ze is gespecialiseerd in Generatieve AI, Toegepaste Data Science en IoT-architectuur. Momenteel maakt ze deel uit van het Amazon Q-team en is ze een actief lid/mentor in de Machine Learning Technical Field Community. Ze werkt met klanten, variërend van start-ups tot ondernemingen, om geweldige generatieve AI-oplossingen te ontwikkelen. Ze is vooral gepassioneerd door het inzetten van grote taalmodellen voor geavanceerde data-analyse en het verkennen van praktische toepassingen die uitdagingen in de echte wereld aanpakken.
 Sudeesh Sasidharan is Senior Solutions Architect bij AWS, binnen het Energy-team. Sudeesh houdt ervan om te experimenteren met nieuwe technologieën en innovatieve oplossingen te bouwen die complexe zakelijke uitdagingen oplossen. Wanneer hij niet aan het bedenken is van oplossingen of aan het sleutelen is aan de nieuwste technologieën, kun je hem op de tennisbaan aan zijn backhand vinden.
Sudeesh Sasidharan is Senior Solutions Architect bij AWS, binnen het Energy-team. Sudeesh houdt ervan om te experimenteren met nieuwe technologieën en innovatieve oplossingen te bouwen die complexe zakelijke uitdagingen oplossen. Wanneer hij niet aan het bedenken is van oplossingen of aan het sleutelen is aan de nieuwste technologieën, kun je hem op de tennisbaan aan zijn backhand vinden.
 Neil Desai is een technologiemanager met meer dan 20 jaar ervaring in kunstmatige intelligentie (AI), datawetenschap, software-engineering en bedrijfsarchitectuur. Bij AWS leidt hij een team van wereldwijde AI-services-specialistische oplossingsarchitecten die klanten helpen bij het bouwen van innovatieve generatieve AI-aangedreven oplossingen, het delen van best practices met klanten en het aansturen van de productroadmap. In zijn eerdere functies bij Vestas, Honeywell en Quest Diagnostics heeft Neil leidinggevende functies bekleed bij het ontwikkelen en lanceren van innovatieve producten en diensten die bedrijven hebben geholpen hun activiteiten te verbeteren, de kosten te verlagen en de omzet te verhogen. Hij heeft een passie voor het gebruik van technologie om problemen uit de echte wereld op te lossen en is een strategische denker met een bewezen staat van dienst op het gebied van succes.
Neil Desai is een technologiemanager met meer dan 20 jaar ervaring in kunstmatige intelligentie (AI), datawetenschap, software-engineering en bedrijfsarchitectuur. Bij AWS leidt hij een team van wereldwijde AI-services-specialistische oplossingsarchitecten die klanten helpen bij het bouwen van innovatieve generatieve AI-aangedreven oplossingen, het delen van best practices met klanten en het aansturen van de productroadmap. In zijn eerdere functies bij Vestas, Honeywell en Quest Diagnostics heeft Neil leidinggevende functies bekleed bij het ontwikkelen en lanceren van innovatieve producten en diensten die bedrijven hebben geholpen hun activiteiten te verbeteren, de kosten te verlagen en de omzet te verhogen. Hij heeft een passie voor het gebruik van technologie om problemen uit de echte wereld op te lossen en is een strategische denker met een bewezen staat van dienst op het gebied van succes.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

