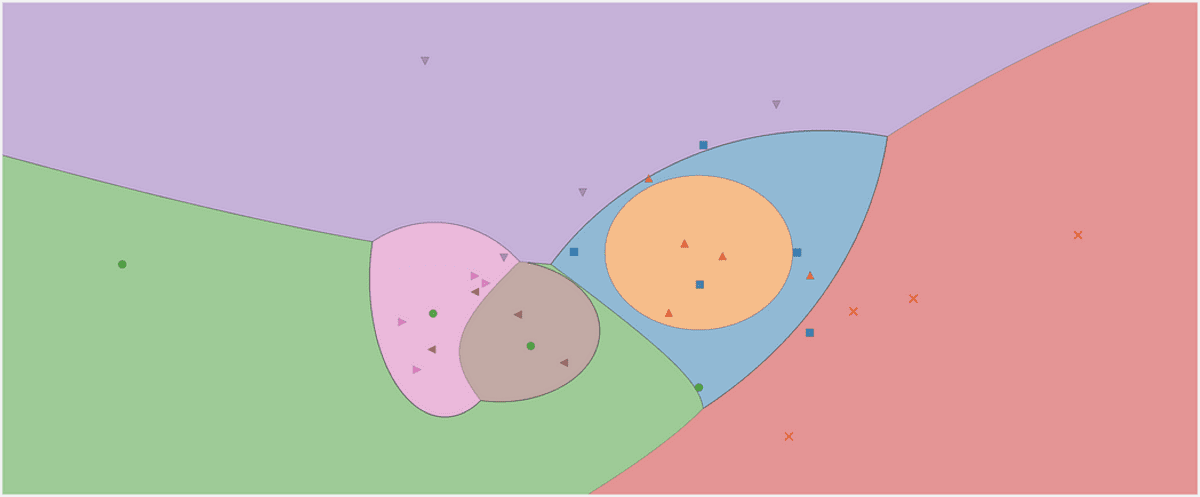
Het beslissingsgebied van een Gaussiaanse naïeve Bayes-classificator. Afbeelding door de auteur.
Ik denk dat dit een klassieker is aan het begin van elke data science-carrière: de Naïeve Bayes-classificatie. Of ik moet eerder zeggen de familie van naïeve Bayes-classificaties, omdat ze in vele smaken verkrijgbaar zijn. Er is bijvoorbeeld een multinominale naïeve Bayes-classificatie, een Bernoulli-naïeve Bayes-classificator en ook een Gaussiaanse naïeve Bayes-classificator, elk verschillend in slechts één klein detail, zoals we zullen zien. De naïeve Bayes-algoritmen zijn vrij eenvoudig van opzet, maar bleken nuttig in veel complexe praktijksituaties.
In dit artikel leer je
- hoe de naïeve Bayes-classificaties werken,
- waarom het zinvol is om ze te definiëren zoals ze zijn en
- hoe ze in Python te implementeren met behulp van NumPy.
Je vindt de code op mijn Github.
Het kan een beetje helpen om mijn inleiding over Bayesiaanse statistieken te bekijken Een zachte inleiding tot Bayesiaanse inferentie wennen aan de formule van Bayes. Aangezien we de classifier op een scikit leer-conforme manier zullen implementeren, is het ook de moeite waard om mijn artikel te lezen Bouw je eigen aangepaste scikit-learn regressie. De overhead van scikit-learn is echter vrij klein en je zou toch moeten kunnen volgen.
We beginnen met het verkennen van de verbazingwekkend eenvoudige theorie van de naïeve Bayes-classificatie en gaan dan over tot de implementatie.
Waar zijn we echt in geïnteresseerd bij het classificeren? Wat doen we eigenlijk, wat is de input en de output? Het antwoord is eenvoudig:
Gegeven een gegevenspunt x, wat is de kans dat x tot een bepaalde klasse c behoort?
Dat is alles waarmee we willen antwoorden elke classificatie. U kunt deze bewering direct modelleren als een voorwaardelijke kans: p(c|x).
Als die er zijn bijvoorbeeld
- 3 klassen c₁, c₂, c₃ en
- x bestaat uit 2 kenmerken x₁, x₂,
het resultaat van een classifier zou zoiets kunnen zijn p(c₁|x₁, x₂) = 0.3, p(c₂|x₁, x₂)=0.5 en p(c₃|x₁, x₂)=0.2. Als we zorgen voor een enkel label als uitvoer, kiezen we degene met de hoogste waarschijnlijkheid, dwz c₂ met een waarschijnlijkheid van 50% hier.
De naïeve Bayes-classificator probeert deze kansen rechtstreeks te berekenen.
Naïeve Bayes
Ok, dus gegeven een datapunt x, we willen berekenen p(c|x) voor alle klassen c en voer vervolgens de c met de grootste waarschijnlijkheid. In formules zie je dit vaak als

Afbeelding door de auteur.
Opmerking: max p(c|x) retourneert de maximale waarschijnlijkheid terwijl argmax p(c|x) geeft de . terug c met deze hoogste waarschijnlijkheid.
Maar voordat we kunnen optimaliseren p(c|x), moeten we het kunnen berekenen. Hiervoor gebruiken we Stelling van Bayes:
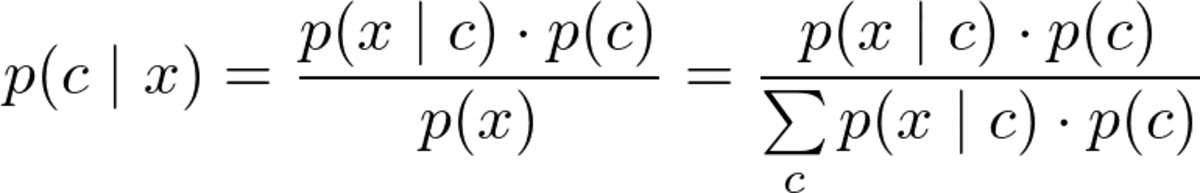
De stelling van Bayes. Afbeelding door de auteur.
Dit is het Bayes-gedeelte van naïeve Bayes. Maar nu hebben we het volgende probleem: Wat zijn p(x|c) en p(c)?
Dit is waar de training van een naïeve Bayes-classificator om draait.
De training
Laten we, om alles te illustreren, een speelgoeddataset gebruiken met twee echte kenmerken x₁, x₂ en drie klassen c₁, c₂, c₃ in de volgende.
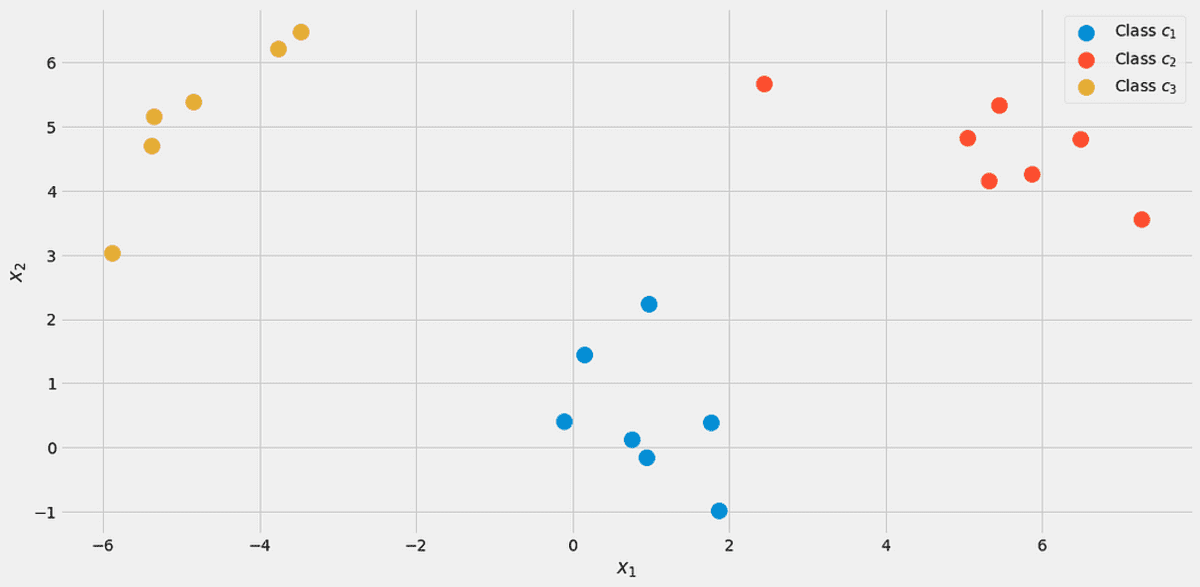
De gegevens, gevisualiseerd. Afbeelding door de auteur.
U kunt deze exacte dataset aanmaken via
from sklearn.datasets import make_blobs X, y = make_blobs(n_samples=20, centers=[(0,0), (5,5), (-5, 5)], random_state=0)Laten we beginnen met de klasse waarschijnlijkheid p(c), de kans dat een klasse c wordt waargenomen in de gelabelde dataset. De eenvoudigste manier om dit te schatten is door gewoon de relatieve frequenties van de klassen te berekenen en ze als kansen te gebruiken. We kunnen onze dataset gebruiken om te zien wat dit precies betekent.
Er zijn 7 van de 20 punten gelabeld als klasse c₁ (blauw) in de dataset, daarom zeggen we p(c₁)=7/20. We hebben 7 punten voor de klas c₂ (rood) ook, daarom zetten we p(c₂)=7/20. De laatste klas c₃ (geel) heeft dus maar 6 punten p(c₃)=6/20.
Deze eenvoudige berekening van de klassenkansen lijkt op een maximale waarschijnlijkheidsbenadering. U kunt echter ook een andere gebruiken voorafgaand distributie, zo u wilt. Als u bijvoorbeeld weet dat deze dataset niet representatief is voor de werkelijke populatie omdat class c₃ zou in 50% van de gevallen moeten verschijnen, dan stel je in p(c₁) = 0.25, p(c₂)=0.25 en p(c₃)=0.5. Alles wat u helpt de prestaties op de testset te verbeteren.
We gaan nu naar de waarschijnlijkheid p(x|c)=p(x₁, x₂|c). Een manier om deze waarschijnlijkheid te berekenen, is door de dataset te filteren op steekproeven met een label c en probeer dan een verdeling te vinden (bijvoorbeeld een 2-dimensionale Gaussiaanse) die de kenmerken vastlegt x₁, x₂.
Helaas hebben we meestal niet genoeg monsters per klasse om de waarschijnlijkheid goed in te schatten.
Om een robuuster model te kunnen bouwen, maken we de naïeve veronderstelling dat de eigenschappen x₁, x₂ zijn stochastisch onafhankelijkgegeven c. Dit is gewoon een mooie manier om de wiskunde gemakkelijker te maken via

Afbeelding door de auteur
voor elke klas c. Dit is waar de naïef een deel van de naïeve Bayes komt vandaan omdat deze vergelijking in het algemeen niet opgaat. Maar ook dan levert de naïeve Bayes in de praktijk goede, soms uitstekende resultaten op. Vooral voor NLP-problemen met zak-van-woorden-kenmerken schittert de multinominale naïeve Bayes.
De hierboven gegeven argumenten zijn hetzelfde voor elke naïeve Bayes-classificatie die u kunt vinden. Nu hangt het er gewoon vanaf hoe je modelleert p(x₁|c₁), p(x₂|c₁), p(x₁|c₂), p(x₂|c₂), p(x₁|c₃) en p(x₂|c₃).
Als uw functies alleen 0 en 1 zijn, kunt u a gebruiken Bernoulli-distributie. Als het gehele getallen zijn, a Multinomiale verdeling. We hebben echter echte kenmerkwaarden en kiezen voor a Gauss distributie, vandaar de naam Gaussiaanse naïeve Bayes. We gaan uit van de volgende vorm

Afbeelding door de auteur.
WAAR μᵢ,ⱼ is het gemiddelde en σᵢ,ⱼ is de standaarddeviatie die we moeten schatten op basis van de gegevens. Dit betekent dat we voor elk kenmerk één gemiddelde krijgen i in combinatie met een klas cⱼ, in ons geval betekent 2*3=6. Hetzelfde geldt voor de standaarddeviaties. Dit vraagt om een voorbeeld.
Laten we proberen in te schatten μ₂,₁ en σ₂,₁. Omdat j=1, we zijn alleen geïnteresseerd in de les c₁, laten we alleen monsters met dit label bewaren. De volgende voorbeelden blijven over:
# samples with label = c_1 array([[ 0.14404357, 1.45427351], [ 0.97873798, 2.2408932 ], [ 1.86755799, -0.97727788], [ 1.76405235, 0.40015721], [ 0.76103773, 0.12167502], [-0.10321885, 0.4105985 ], [ 0.95008842, -0.15135721]])Nu, vanwege i=2 we hoeven alleen maar naar de tweede kolom te kijken. μ₂,₁ is het gemiddelde en σ₂,₁ de standaarddeviatie voor deze kolom, dwz μ₂,₁ = 0.49985176 en σ₂,₁ = 0.9789976.
Deze cijfers zijn logisch als je de spreidingsplot opnieuw van bovenaf bekijkt. De eigenschappen x₂ van de monsters uit de klas c₁ zijn rond de 0.5, zoals je op de foto kunt zien.
We berekenen dit nu voor de andere vijf combinaties en we zijn klaar!
In Python kun je het als volgt doen:
from sklearn.datasets import make_blobs
import numpy as np # Create the data. The classes are c_1=0, c_2=1 and c_3=2.
X, y = make_blobs( n_samples=20, centers=[(0, 0), (5, 5), (-5, 5)], random_state=0
) # The class probabilities.
# np.bincounts counts the occurence of each label.
prior = np.bincount(y) / len(y) # np.where(y==i) returns all indices where the y==i.
# This is the filtering step.
means = np.array([X[np.where(y == i)].mean(axis=0) for i in range(3)])
stds = np.array([X[np.where(y == i)].std(axis=0) for i in range(3)])
Wij ontvangen
# priors
array([0.35, 0.35, 0.3 ])
# means array([[ 0.90889988, 0.49985176], [ 5.4111385 , 4.6491892 ], [-4.7841679 , 5.15385848]])
# stds
array([[0.6853714 , 0.9789976 ], [1.40218915, 0.67078568], [0.88192625, 1.12879666]])Dit is het resultaat van de training van een Gaussiaanse naïeve Bayes-classificator.
Voorspellingen doen
De volledige voorspellingsformule is
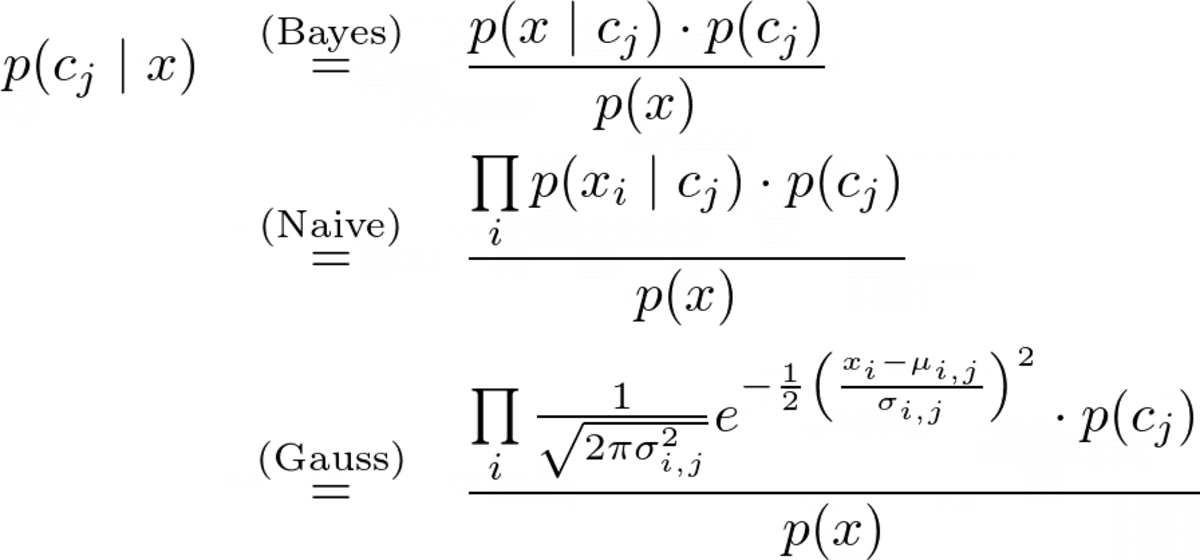
Afbeelding door de auteur.
Laten we uitgaan van een nieuw datapunt x*=(-2, 5) komt binnen.
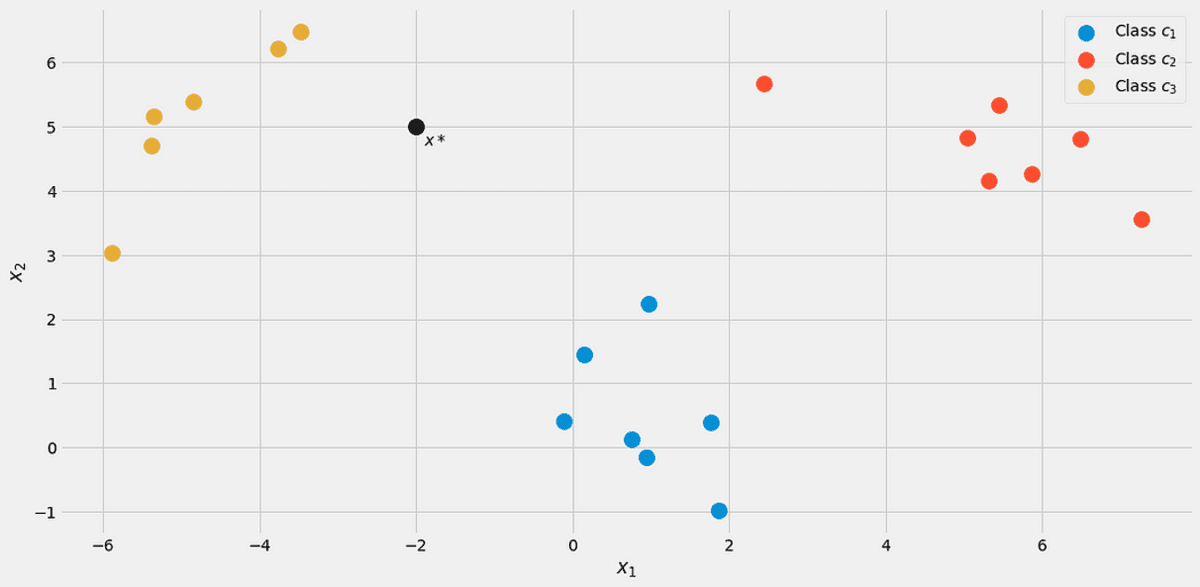
Afbeelding door de auteur.
Om te zien tot welke klasse het behoort, laten we het berekenen p(c|x*) voor alle klassen. Op de foto zou het tot klasse moeten behoren c₃ = 2, maar laten we eens kijken. Laten we de noemer negeren p(x) voor een seconde. Met behulp van de volgende lus zijn de nominatoren voor berekend j = 1, 2, 3.
x_new = np.array([-2, 5]) for j in range(3): print( f"Probability for class {j}: {(1/np.sqrt(2*np.pi*stds[j]**2)*np.exp(-0.5*((x_new-means[j])/stds[j])**2)).prod()*p[j]:.12f}" )
Wij ontvangen
Probability for class 0: 0.000000000263
Probability for class 1: 0.000000044359
Probability for class 2: 0.000325643718Deze natuurlijk waarschijnlijkheden (we zouden ze niet zo moeten noemen) tellen niet op tot één omdat we de noemer hebben genegeerd. Dit is echter geen probleem, aangezien we deze niet-genormaliseerde kansen gewoon kunnen nemen en ze kunnen delen door hun som, dan tellen ze op tot één. Dus als we deze drie waarden delen door hun som van ongeveer 0.00032569, krijgen we
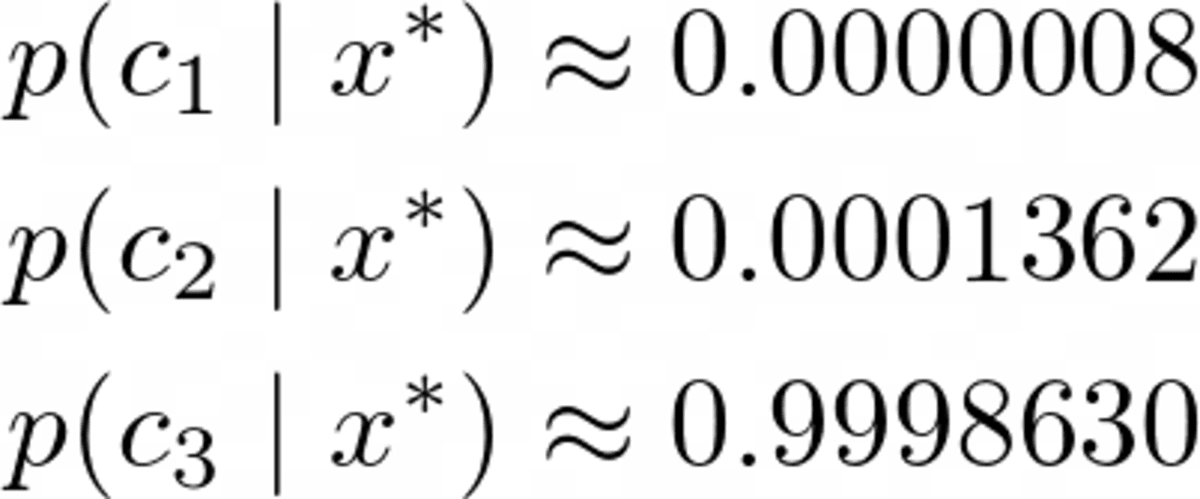
Afbeelding door de auteur.
Een duidelijke winnaar, zoals we hadden verwacht. Laten we het nu implementeren!
Deze implementatie is verre van efficiënt, niet numeriek stabiel, het dient alleen een educatief doel. We hebben de meeste dingen besproken, dus het zou nu gemakkelijk te volgen moeten zijn. Je kunt alles negeren check functies, of lees mijn artikel Bouw je eigen aangepaste scikit-learn als je geïnteresseerd bent in wat ze precies doen.
Houd er rekening mee dat ik een predict_proba methode eerst om kansen te berekenen. De methode predict roept gewoon deze methode aan en retourneert de index (=klasse) met de hoogste waarschijnlijkheid met behulp van een argmax-functie (daar is hij weer!). De klas wacht lessen van 0 tot k-1, waar k is het aantal klassen.
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.utils.validation import check_X_y, check_array, check_is_fitted class GaussianNaiveBayesClassifier(BaseEstimator, ClassifierMixin): def fit(self, X, y): X, y = check_X_y(X, y) self.priors_ = np.bincount(y) / len(y) self.n_classes_ = np.max(y) + 1 self.means_ = np.array( [X[np.where(y == i)].mean(axis=0) for i in range(self.n_classes_)] ) self.stds_ = np.array( [X[np.where(y == i)].std(axis=0) for i in range(self.n_classes_)] ) return self def predict_proba(self, X): check_is_fitted(self) X = check_array(X) res = [] for i in range(len(X)): probas = [] for j in range(self.n_classes_): probas.append( ( 1 / np.sqrt(2 * np.pi * self.stds_[j] ** 2) * np.exp(-0.5 * ((X[i] - self.means_[j]) / self.stds_[j]) ** 2) ).prod() * self.priors_[j] ) probas = np.array(probas) res.append(probas / probas.sum()) return np.array(res) def predict(self, X): check_is_fitted(self) X = check_array(X) res = self.predict_proba(X) return res.argmax(axis=1)Testen van de implementatie
Hoewel de code vrij kort is, is het nog steeds te lang om volledig zeker te zijn dat we geen fouten hebben gemaakt. Laten we dus eens kijken hoe het zich verhoudt tot de scikit-learn Gaussiaanse NB-classificatie.
my_gauss = GaussianNaiveBayesClassifier()
my_gauss.fit(X, y)
my_gauss.predict_proba([[-2, 5], [0,0], [6, -0.3]])uitgangen
array([[8.06313823e-07, 1.36201957e-04, 9.99862992e-01], [1.00000000e+00, 4.23258691e-14, 1.92051255e-11], [4.30879705e-01, 5.69120295e-01, 9.66618838e-27]])De voorspellingen met behulp van de predict methode zijn
# my_gauss.predict([[-2, 5], [0,0], [6, -0.3]])
array([2, 0, 1])Laten we nu scikit-learn gebruiken. Even wat code ingooien
from sklearn.naive_bayes import GaussianNB gnb = GaussianNB()
gnb.fit(X, y)
gnb.predict_proba([[-2, 5], [0,0], [6, -0.3]])opbrengsten
array([[8.06314158e-07, 1.36201959e-04, 9.99862992e-01], [1.00000000e+00, 4.23259111e-14, 1.92051343e-11], [4.30879698e-01, 5.69120302e-01, 9.66619630e-27]])De cijfers lijken een beetje op die van onze classifier, maar ze wijken een beetje af in de laatste paar weergegeven cijfers. Hebben we iets verkeerd gedaan? Nr. De scikit-learn-versie gebruikt gewoon een andere hyperparameter var_smoothing=1e-09 . Als we deze instellen op nul, krijgen we precies onze nummers. Perfect!
Bekijk de beslissingsgebieden van onze classificator. Ik heb ook de drie punten gemarkeerd die we hebben gebruikt om te testen. Dat ene punt vlak bij de grens heeft maar 56.9% kans om tot de rode klasse te behoren, zoals je kunt zien op de predict_proba uitgangen. De andere twee punten zijn geclassificeerd met veel meer vertrouwen.
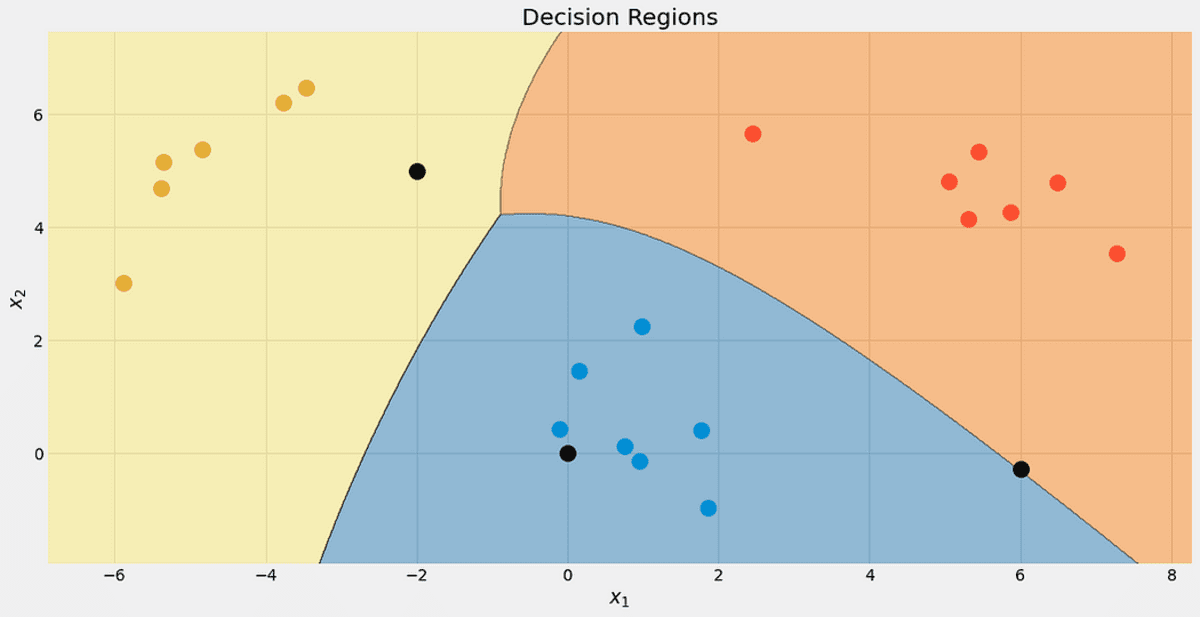
De beslissingsgebieden met de 3 nieuwe punten. Afbeelding door de auteur.
In dit artikel hebben we geleerd hoe de Gaussiaanse naïeve Bayes-classificator werkt en hebben we een intuïtie gegeven waarom deze op die manier is ontworpen - het is een directe benadering om de waarschijnlijkheid van interesse te modelleren. Vergelijk dit met Logistische regressie: daar wordt de kans gemodelleerd met behulp van een lineaire functie met daarop een sigmoïde functie. Het is nog steeds een eenvoudig model, maar het voelt niet zo natuurlijk aan als een naïeve Bayes-classificator.
We gingen door met het berekenen van een paar voorbeelden en het verzamelen van enkele bruikbare stukjes code onderweg. Ten slotte hebben we een volledige Gaussiaanse naïeve Bayes-classificatie geïmplementeerd op een manier die goed werkt met scikit-learn. Dat betekent dat u het bijvoorbeeld kunt gebruiken bij het zoeken naar pijplijnen of rasters.
Uiteindelijk hebben we een kleine gezond verstandscontrole uitgevoerd door de eigen Gaussiaanse naïeve Bayes-classificatie van scikit-learn te importeren en te testen of zowel onze classificatie als die van scikit-learn hetzelfde resultaat opleveren. Deze proef is geslaagd.
Dr. Robert Kübler is datawetenschapper bij Publicis Media en auteur bij Towards Data Science.
ORIGINELE. Met toestemming opnieuw gepost.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/03/gaussian-naive-bayes-explained.html?utm_source=rss&utm_medium=rss&utm_campaign=gaussian-naive-bayes-explained

