607 8
| SEO | - 13 min gelezen - | 2 januari 2024 |


De Serpstat API heeft veel eindpunten die vrijwel alle facetten van de SEO-workflow omvatten, van trefwoordonderzoek tot backlinkanalyse. Het Domain Keywords-eindpunt kan niet alleen worden gebruikt om de onbewerkte gegevens over uw klant en zijn concurrenten te extraheren, maar ook om data science-technieken te gebruiken om inzicht te genereren. Hieronder laten we zien hoe u dit kunt doen door Python te gebruiken.
De inzichten kunnen worden gebruikt als onderdeel van een datapijplijn voor cloud computing om uw SEO-dashboardrapporten zoals Looker, Power BI, enz. aan te sturen.
Ontvang uw API-token
U heeft een API-token nodig voordat u een query kunt uitvoeren op de SERPSTAT API, die op elke documentatiepagina verschijnt, zoals de hoofd-API-pagina, zoals hieronder getoond:

Nadat u uw API-token heeft gekopieerd, kunt u deze gebruiken bij het opstarten van uw Jupyter iPython-notebook.
Start uw Jupyter iPython Notebook
Alle Python-code wordt uitgevoerd in de Jupyter iPython-notebookomgeving. Op dezelfde manier wordt de code uitgevoerd in een COLABs-notebook als dat uw voorkeur heeft. Zodra u dat operationeel heeft, importeert u de functies in de bibliotheken:
importaanvragen
importeer panda's als pd
numpy importeren als np
json importeren
van plotnine-import *
Om API-aanroepen te doen, heeft u de verzoekenbibliotheek nodig.
Om dataframes te verwerken, vergelijkbaar met Excel in Python, gebruiken we Python en wijzen we 'pd' toe als een verkorte alias, wat het gebruik van panda's-functies vereenvoudigt. We zullen Numpy ook gebruiken, afgekort als 'np', om gegevens in dataframes te manipuleren.
Gegevens uit API's zijn vaak in woordenboekformaat, dus de JSON zal ons helpen de resultaten uit te pakken in datastructuren die we naar een dataframe kunnen pushen.
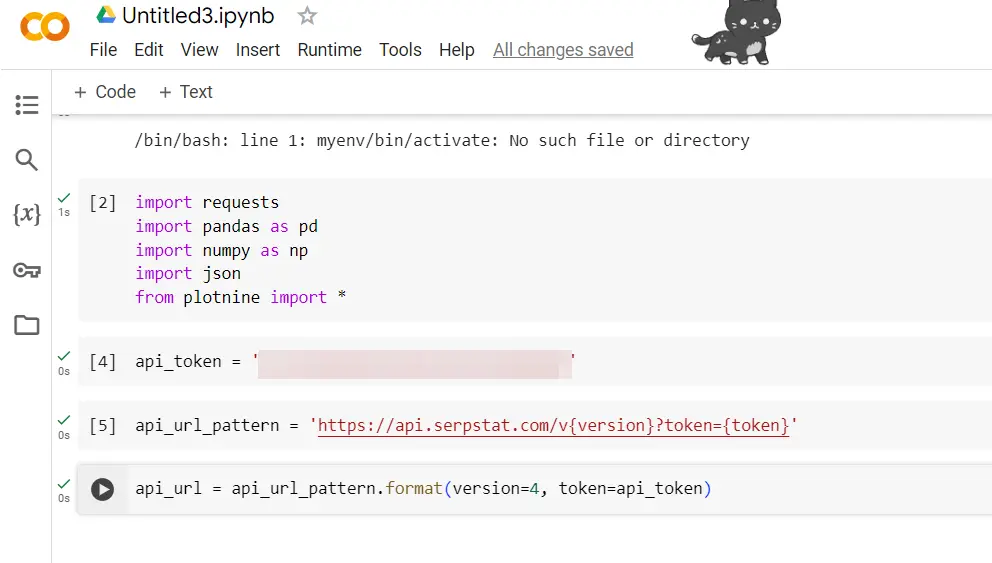
api_token = 'uw API-sleutel'
Dit werd eerder verkregen (zie hierboven).
api_url_pattern = 'https://api.serpstat.com/v{version}?token={token}'
We stellen een URL-patroon in waarmee we verschillende eindpunten van de Serpstat API kunnen opvragen. De huidige versie is APIv4. Omdat u de applicatieprogrammeringsinterface een paar keer zult aanroepen, voorkomt u dat repetitieve code wordt getypt.
api_url = api_url_pattern.format(versie=4, token=api_token)
Stel de API-URL zo in dat deze de API-versie en uw API-token bevat.
Domeinzoekwoorden ophalen
Het spannende deel. We kunnen nu trefwoorden extraheren voor elk domein dat zichtbaar is door het Domein Trefwoorden eindpunt. Hier worden alle trefwoorden weergegeven die een domein in de top 100 van een bepaalde zoekmachine plaatst.
We beginnen met het instellen van de invoerparameters die de API vereist:
domain_keyword_params = {
"id": "1",
"method": "SerpstatDomainProcedure.getDomainKeywords",
"params": {
"domain": "deel.com",
"se": "g_uk",
"withSubdomains": False,
"sort": {
"region_queries_count": "desc"
},
"minusKeywords": [
"deel", "deels"
],
"size": "1000",
"filters": {
"right_spelling": False
}
}
}
Een ding om op te merken: het eindpunt van Domain Keywords is toegankelijk door de methode in te stellen op “SerpstatDomainProcedure.getDomainKeywords”
U moet uw domeinnaam instellen "domein" onder en uw zoekmachine onder “g_uk”.
In ons geval gaan we kijken naar de trefwoorden van deel.com in Google UK. Er is een volledige lijst met zoekmachines beschikbaar hier die de wereldwijde regio's van Google en Bing US omvat.
Extra opties zijn onder meer minuszoekwoorden (uitsluitingszoekwoorden). In ons geval zijn we alleen geïnteresseerd in niet-merkzoekwoorden om te begrijpen waar het organische verkeer vandaan komt.
Wij hebben ook de "grootte" parameter op 1,000, wat de maximale rijuitvoer is die mogelijk is.
Er zijn nog andere interessante parameters, zoals de mogelijkheid om de API te beperken tot bepaalde trefwoorden ("Zoekwoorden") of site-URL's binnen het domein ("URL").
Met de parameterset kunnen we het verzoek doen met behulp van de onderstaande code:
domain_keyword_resp = requests.post(api_url, json=domain_keyword_params)
if domain_keyword_resp.status_code == 200:
domain_keyword_result = domain_keyword_resp.json()
print(domain_keyword_result)
else:
print(domain_keyword_resp.text)
De resultaten van de API-aanroep worden opgeslagen in domein_trefwoord_resp. We lezen het antwoord met behulp van de json-functie en slaan de gegevens op in domein_trefwoord_resultaat.
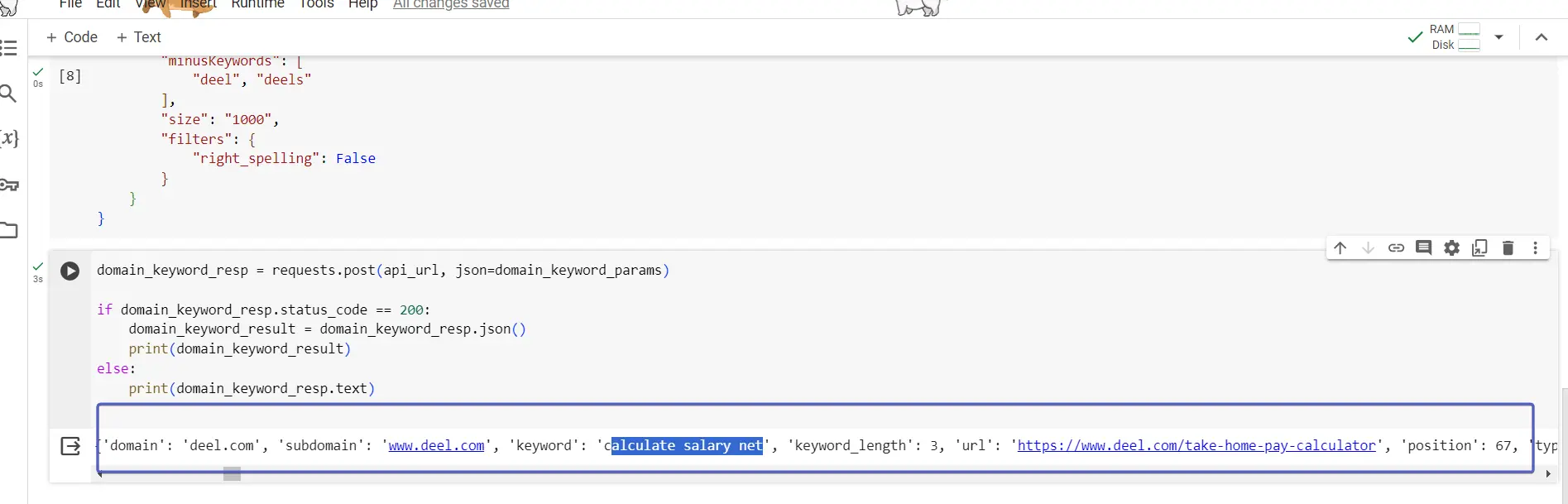
De if else-structuur wordt gebruikt om u informatie te geven voor het geval de API-aanroep niet werkt zoals verwacht, en laat u zien wat de API-reactie is als er geen gegevens of een fout zijn die de aanroep tot stand brengt.
Het uitvoeren van de gespreksafdrukken domein_trefwoord_resultaat die er zo uitziet:
{'id': '1',
'result':
{'data': [
{'domain': 'deel.com', 'subdomain': 'www.deel.com', 'keyword':
'support for dell', 'keyword_length': 3, 'url': 'https://www.deel.com/',
'position': 73, 'types': ['pic', 'kn_graph_card', 'related_search',
'a_box_some', 'snip_breadcrumbs'], 'found_results': 830000000,
'cost': 0.31, 'concurrency': 3, 'region_queries_count': 33100,
'region_queries_count_wide': 0, 'geo_names': [], 'traff': 0,
'difficulty': 44.02206115387234, 'dynamic': None},
{'domain': 'deel.com', 'subdomain': 'www.deel.com',
'keyword': 'hr and go',
'keyword_length': 3, 'url': 'https://www.deel.com/',
'position': 67, 'types': ['related_search', 'snip_breadcrumbs'],
'found_results': 6120000000, 'cost': 0.18, 'concurrency': 4,
'region_queries_count': 12100, 'region_queries_count_wide': 0,
'geo_names': [], 'traff': 0, 'difficulty': 15.465889053157944,
'dynamic': 3},
Wanneer u met een API werkt, is het belangrijk om de gegevensstructuur af te drukken, zodat u weet hoe u de gegevens in een bruikbaar formaat kunt parseren. Niet dat levert een woordenboek op met meerdere sleutels, waarbij de gewenste gegevens zich bevinden onder de resultaatgegevenssleutels. De waarden van gegevens staan in een lijst met woordenboeken, waarbij elk woordenboek een trefwoord vertegenwoordigt.
We hebben de onderstaande code geproduceerd om de gegevens uit te extraheren domein_trefwoord_resultaat en duw deze naar de domein_trefwoord_df dataframe:
domein_sleutelwoord_df = pd.DataFrame(domein_sleutelwoord_resultaat['resultaat']['gegevens'])
Laten we het dataframe weergeven:
weergave(domein_trefwoord_df)
Wat lijkt op:
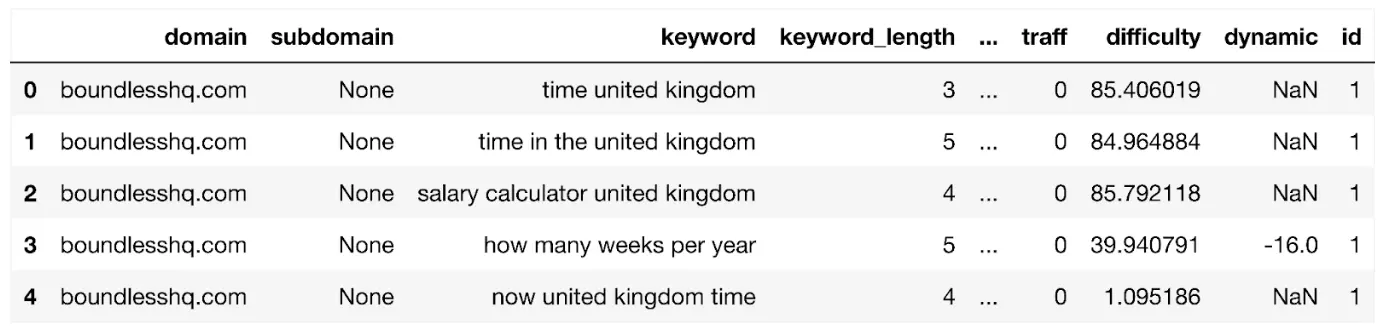
Het dataframe toont alle trefwoorden voor het domein tot maximaal 1,000 rijen. Het bevat kolomvelden zoals:
- region_queries_count: zoekvolume binnen uw doelregio
- url: de rangschikkings-URL voor het zoekwoord
- positie: SERP-rang
- types: SERP-functies
- samenloop: de hoeveelheid betaalde zoekadvertenties die het niveau van transactionele en/of commerciële intentie kunnen aangeven.
Als u meer wilt omdat u aan een grotere site werkt, kunt u het volgende doen:
2.Voer meerdere domeintrefwoordaanroepen uit met de bovenstaande code op die site-URL's als onderdeel van een for-lus waarbij de URL wordt opgegeven als invoerparameter voor 'url'.
Gegevensfuncties maken
Voor inzichten willen we enkele functies creëren die helpen bij het samenvatten van de onbewerkte gegevens. Volgens de beste praktijk maken we een kopie van het dataframe en slaan we deze op in een nieuw dataframe genaamd dk_enhanced_df.
dk_enhanced_df = domein_trefwoord_df.copy()
Het instellen van een nieuwe kolom genaamd 'graaf' zal ons in staat stellen om letterlijk dingen te tellen, zoals je later zult zien.
dk_enhanced_df['aantal'] = 1
We willen ook een aangepaste kolom maken met de naam 'serp' die de SERP-paginacategorie aangeeft, wat handig kan zijn voor het bekijken van de distributie van siteposities door SERP en gepusht in dashboardrapporten.
<code data-code="dk_enhanced_df['serp'] = np.where(dk_enhanced_df['position'] dk_enhanced_df['serp'] = np.waar(dk_verbeterd_df['positie'] < 11, '1', 'Nergens') dk_enhanced_df['serp'] = np.waar(dk_verbeterd_df['positie'].tussen(11, 20), '2', dk_enhanced_df['serp']) dk_enhanced_df['serp'] = np.waar(dk_verbeterd_df['positie'].tussen(21, 30), '3', dk_enhanced_df['serp']) dk_enhanced_df['serp'] = np.waar(dk_verbeterd_df['positie'].tussen(31, 99), '4+', dk_enhanced_df['serp'])
De SERP is hierboven gecodeerd met behulp van de numpy.waar? functie, die lijkt op de Python-versie van de meer bekende Excel if-instructie.
Als u de kolom Typen noteert, bevatten de waarden een lijst met de universele typen zoekresultaten die in de zoekmachine voor het trefwoord worden weergegeven.
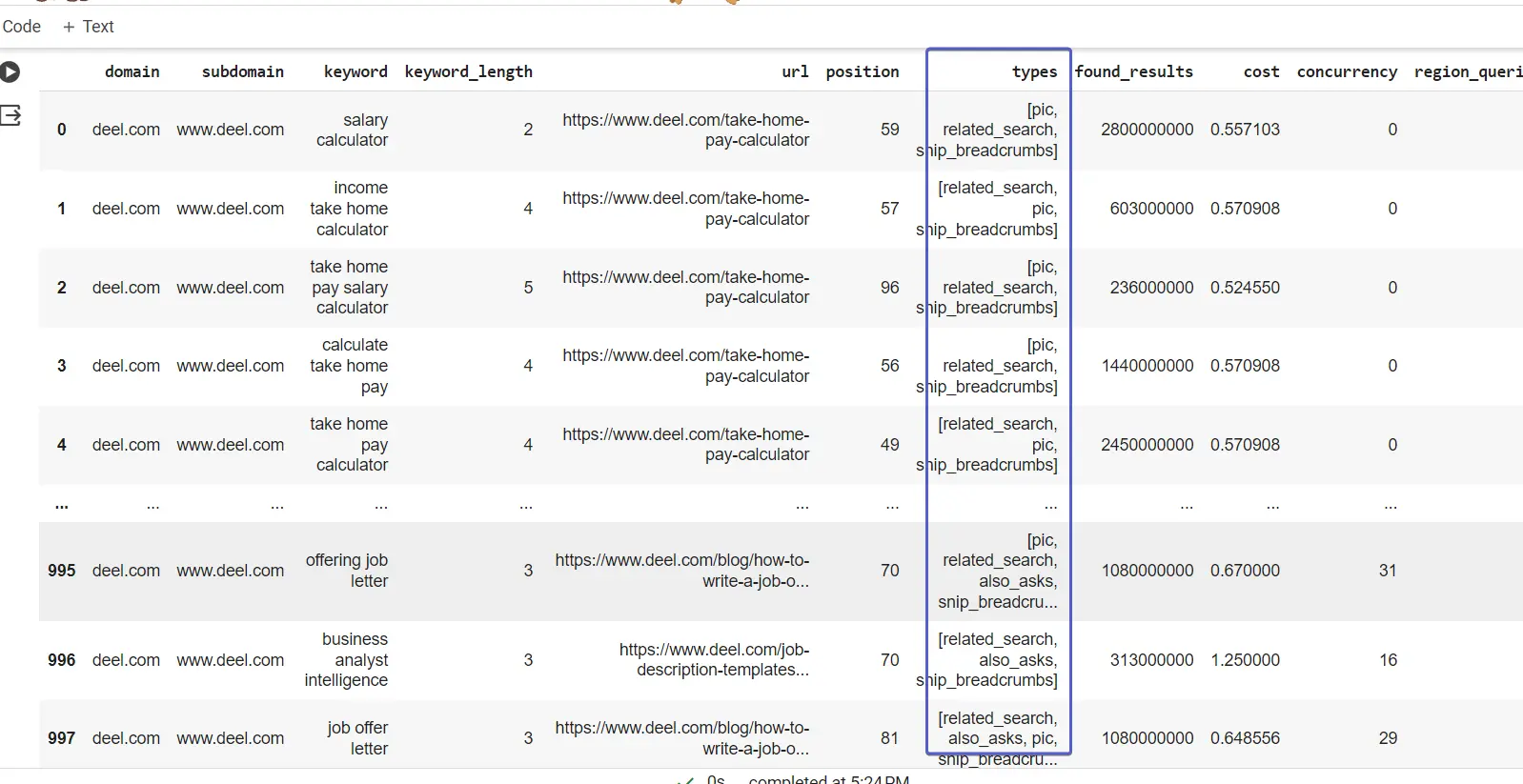
We kunnen dit uitpakken en het gemakkelijker maken om te analyseren met behulp van de one-hot codering (OHE) techniek. OHE maakt kolommen voor alle waarden van het resultaattype en plaatst een 1 waar er een resultaat bestaat voor het trefwoord:
types_dummies = pd.get_dummies(dk_enhanced_df['types'].apply(pd.Series).stack()).
som(niveau=0)
Voeg de kolommen van het one-hot gecodeerde resultaattype samen met de dk_enhanced_df dataframe
dk_enhanced_df = pd.concat([dk_enhanced_df.drop(columns=['types']), types_dummies], as=1)
weergave(dk_enhanced_df)

Dankzij OHE en de andere verbeteringen hebben we nu een uitgebreid dataframe met kolommen die het gemakkelijker maken om te analyseren en inzichten te genereren.
Begin uw SEO-reis met vertrouwen!
Meld u aan voor onze proefperiode van 7 dagen en duik in de wereld van geavanceerde SEO-analyse met behulp van onze API. Geen verplichtingen, gewoon pure verkenning.
Domeinzoekwoordgegevens verkennen
We beginnen met het bekijken van de statistische eigenschappen van de trefwoordgegevens van het domein met behulp van de beschrijven() functie:
dk_enhanced_df.describe()
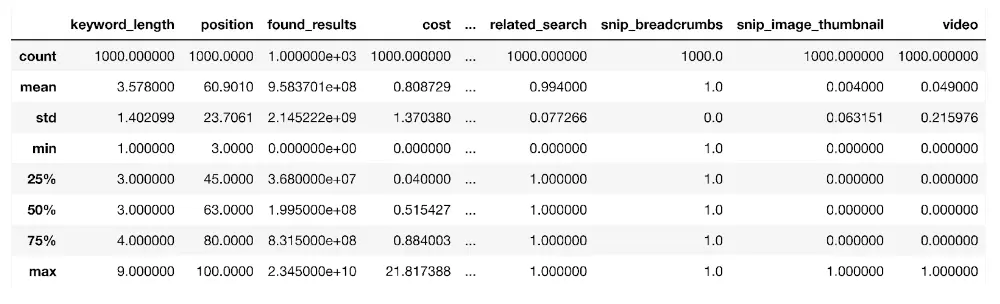
De functie gebruikt alle numerieke kolommen in een dataframe om hun statistische eigenschappen te schatten, zoals het gemiddelde (gemiddelde), de standaarddeviatie (std), die de mate van spreiding ten opzichte van het gemiddelde meet, het aantal datapunten (telling) en de percentielen zoals de 25e (25%) zoals hierboven weergegeven.
Hoewel de functie nuttig is als samenvatting, is het vanuit zakelijk perspectief vaak nuttig om de gegevens samen te voegen. Gebruik bijvoorbeeld de combinatie van GroupBy en agg functies kunnen we tellen hoeveel trefwoorden er op SERP 1 staan, enzovoort, met behulp van de onderstaande code:
serp_agg = dk_enhanced_df.groupby('serp').agg({'count': 'sum'}).reset_index()
De groupby-functie groepeert het dataframe op kolom (net zoals een Excel-draaitabel dat doet) en voegt vervolgens de andere kolommen samen. In ons gebruiksscenario groeperen we op SERP om te tellen hoeveel zoekwoorden er in elke SERP zijn, zoals hieronder weergegeven:
weergeven(serp_agg)
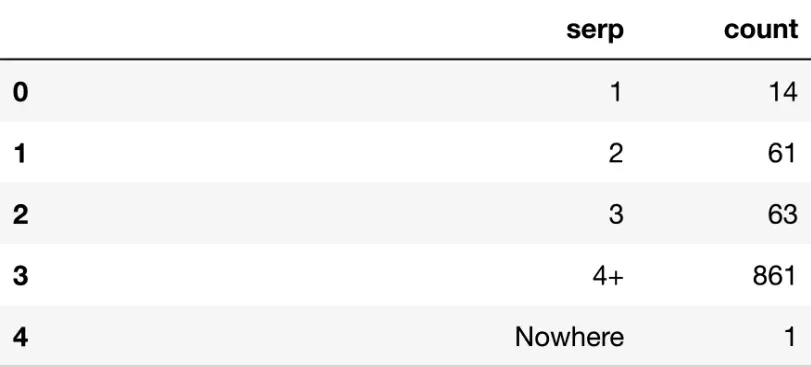
De meeste zoekwoorden bevinden zich buiten pagina 3, zoals blijkt uit de 861 telwaarde voor SERP 4+.
Als we de gegevens willen visualiseren voor een niet-SEO-expertpubliek, kunnen we de ggplot-functies van plotnine gebruiken:
serp_dist_plt = (ggplot(serp_agg,
aes(x = 'serp', y = 'count')) +
geom_bar(stat = 'identity', alpha = 0.8, fill = 'blue') +
labs(y = 'SERP', x = '') +
theme_classic() +
theme(legend_position = 'none')
)
ggplot neem twee hoofdargumenten, namelijk het dataframe en de esthetiek (aes). aes specificeert de delen van het dataframe die op de grafiek worden weergegeven. Er worden extra lagen aan de code toegevoegd om het diagramtype, de aslabels, enzovoort te bepalen. In ons geval gebruiken we geom_bar, een staafdiagram.
De code wordt opgeslagen in het kaartobject serp_dist_plt die tijdens het uitvoeren de grafiek weergeeft:
serp_dist_plt
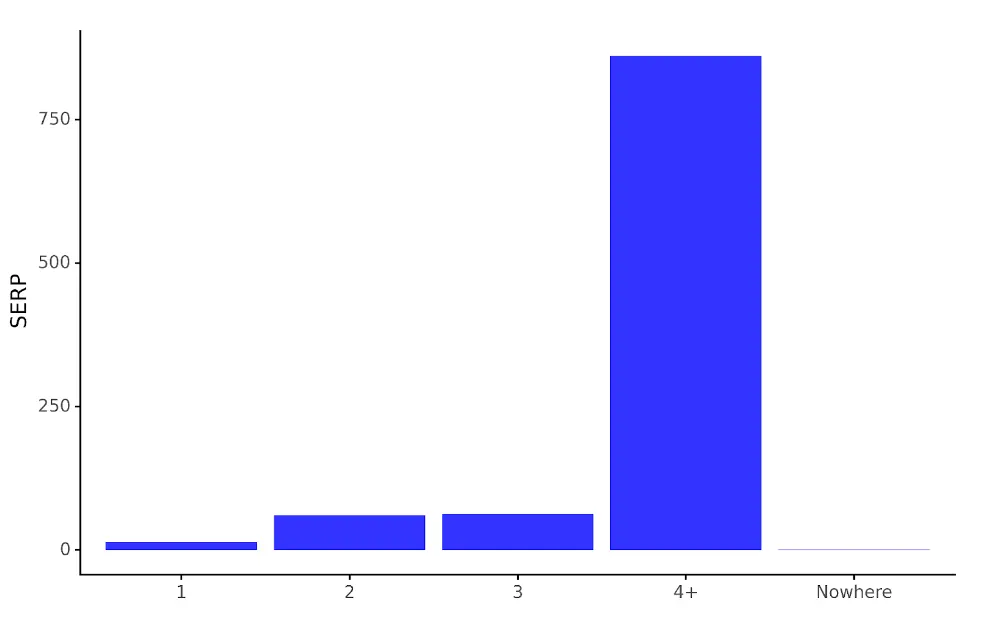
De geproduceerde grafiek creëert een gevisualiseerde versie van de serp_agg dataframe, wat het veel gemakkelijker maakt om het aantal trefwoordposities tussen SERP’s te vergelijken.
Concurrentie-inzichten uit domeinsleutelwoorden
Hoewel dit geweldig is, zijn de cijfers voor een enkel websitedomein niet zo inzichtelijk als wanneer ze worden vergeleken met andere sites die in dezelfde zoekruimte concurreren. In het bovenstaande voorbeeld heeft deel.com 14 trefwoorden in SERP 1. Is dat goed? Slecht? Gemiddeld? Hoe kunnen we dat weten?
Concurrerende domeingegevens voegen die context en betekenis toe, wat een goed gebruiksscenario is voor het uitgeven van die API-credits. Door de bovenstaande code aan te passen, kunnen we gegevens over verschillende domeinen verkrijgen om iets zinvoller te krijgen.
Nadat we bijvoorbeeld hetzelfde API-eindpunt hebben gebruikt op sites van concurrenten die in dezelfde ruimte opereren, hebben we nu een tabel met de trefwoordtellingen per SERP voor elk domein:
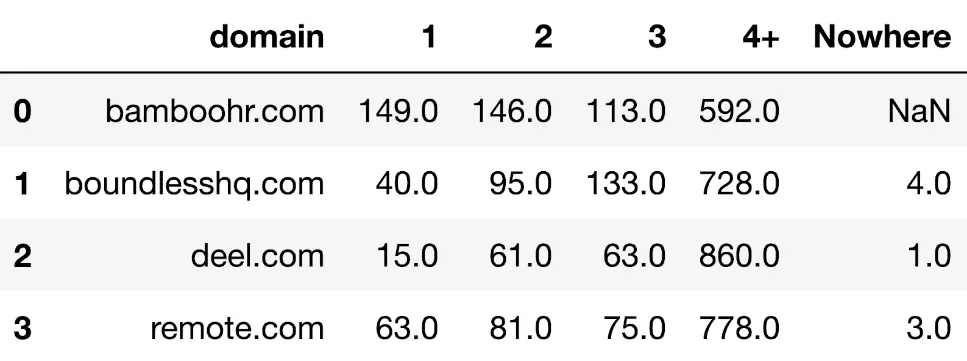
In een meer gevisualiseerd formaat krijgen we:
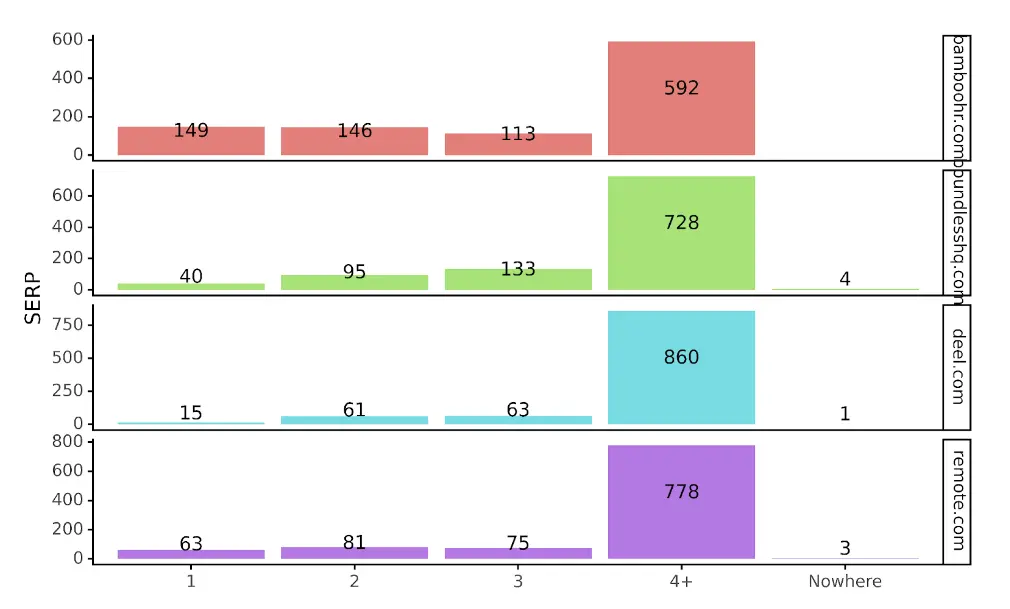
Met de toegevoegde context kunnen we zien dat deel mogelijk ondermaats presteert op SERP 1’s vergeleken met andere concurrenten. We kunnen ook zien dat Bamboo HR leidend is, gevolgd door remote.com. In feite is Bamboo de enige site met meer SERP 1's dan SERP 2's.
Met de API kunnen we niet alleen de trends uit de gegevens distilleren, we beschikken ook over de daadwerkelijke gegevens om te zien welke SERP-trefwoorden de zichtbaarheid van Bamboo bevorderen. In Python zou dat zijn:
bamboe_serp_1s = mdk_enhanced_df.loc[mdk_enhanced_df['domein'] == 'bamboohr.com'].copy()
Het bovenstaande neemt het dataframe met de gecombineerde API-gegevens voor de domeinen en filters voor het domein bamboehr.com
weergave(bamboe_serp_1s)

Dit kan vervolgens worden geëxporteerd naar Excel voor doeleinden van contentplanning.
Andere domeinzoekwoordinzichten
De code tot nu toe concentreerde zich op het extraheren van de gegevens uit de Domain Keywords API en liet zien hoe slechts één kolom inzichten kan genereren over een enkel domein en meerdere domeinen.
Hoeveel meer inzichten zouden er nog kunnen worden gegenereerd door het verkennen van de andere kolommen en het vergelijken van domeinen van concurrenten binnen het eindpunt Domeinzoekwoorden. Dat is voordat we andere eindpunten gaan gebruiken die ons ter beschikking worden gesteld via de SERPSTAT API.
Welke resultaattypen komen bijvoorbeeld het meest voor? Zijn er in de loop van de tijd bepaalde resultaattypen die ons kunnen helpen begrijpen waar Google trending is? De code waarboven de kolom met resultaattypen is uitgepakt, zou u op weg moeten helpen.
De mening van de auteurs van de gastpost valt mogelijk niet samen met de mening van de redactie en specialisten van Serpstat.
Fout gevonden? Selecteer het en druk op Ctrl + Enter om het ons te vertellen
Ontdek meer SEO-tools
Backlink Checker
Backlinks controleren voor elke website. Vergroot de kracht van uw backlinkprofiel
API voor SEO
Doorzoek big data en krijg resultaten met behulp van SEO-API
Aanbevolen berichten
Heb je geen tijd om het nieuws te volgen? Geen zorgen! Onze redacteur kiest artikelen die u zeker zullen helpen bij uw werk. Word lid van onze gezellige community 🙂
Door op de knop te klikken, gaat u akkoord met onze privacybeleid.
Weet je het zeker?
Bedankt, we hebben je nieuwe mailinginstellingen opgeslagen.
Meld een bug
Het laden, even geduld ...
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://serpstat.com/blog/competitor-keywords-api-with-python

