We hebben onlangs een nieuwe verbetering aangekondigd voor OpenSearch Serverless voor het beheren van gegevensretentie van Time Series-collecties en indexen. OpenSearch Serverloos voor Amazon OpenSearch-service maakt het eenvoudig om zoek- en analysewerklasten uit te voeren zonder dat u hoeft na te denken over infrastructuurbeheer. Met de nieuwe automatische tijdgebaseerde gegevensverwijderingsfunctie kunt u opgeven hoe lang ze gegevens willen bewaren, en OpenSearch Serverless beheert automatisch de levenscyclus van de gegevens op basis van deze configuratie.
Om tijdreeksgegevens zoals applicatielogboeken en gebeurtenissen in OpenSearch te analyseren, moet u gegevens maken en opnemen in indexen. Normaal gesproken worden deze logboeken continu gegenereerd en regelmatig, bijvoorbeeld elke paar minuten, in OpenSearch opgenomen. Grote hoeveelheden logboeken kunnen een groot deel van de beschikbare bronnen in beslag nemen, zoals opslag in de clusters, en moeten daarom efficiënt worden beheerd om optimale prestaties te maximaliseren. U kunt de levenscyclus van de geïndexeerde gegevens beheren door geautomatiseerde tools te gebruiken om dagelijkse indexen te maken. U kunt vervolgens scripts gebruiken om de geïndexeerde gegevens van de primaire opslag in clusters naar een secundaire externe opslag te roteren om de prestaties op peil te houden en de kosten onder controle te houden, en vervolgens de verouderde gegevens na een bepaalde bewaarperiode te verwijderen.
De nieuwe geautomatiseerde, op tijd gebaseerde gegevensverwijderingsfunctie in OpenSearch Serverless minimaliseert de noodzaak om handmatig dagelijkse indexen aan te maken en te beheren of scripts voor de levenscyclus van gegevens te schrijven. U kunt nu een enkele index maken en OpenSearch Serverless zorgt automatisch voor het maken van een verzameling indexen met tijdstempel onder één logische groepering. U hoeft alleen het gewenste gegevensretentiebeleid voor uw tijdreeksgegevensverzamelingen te configureren. OpenSearch Serverless zal vervolgens indexen efficiënt overbrengen van de primaire opslag naar Amazon Simple Storage Service (Amazon S3) naarmate ze ouder worden, en automatisch verouderde gegevens verwijderen volgens het geconfigureerde bewaarbeleid, waardoor de operationele overhead wordt verminderd en kosten worden bespaard.
In dit bericht bespreken we het nieuwe beleid voor de levenscyclus van gegevens en hoe u met dit beleid aan de slag kunt gaan in OpenSearch Serverless
Overzicht oplossingen
Overweeg een gebruiksscenario waarbij het fictieve bedrijf Octank Broker logboeken van zijn webservices verzamelt en deze opneemt in OpenSearch Serverless voor analyse van de beschikbaarheid van services. Het bedrijf is geïnteresseerd in het volgen van webtoegang en de hoofdoorzaak wanneer fouten worden waargenomen met fouttypen 4xx en 5xx. Over het algemeen zijn de serverproblemen binnen een onmiddellijk tijdsbestek van belang, bijvoorbeeld binnen een paar dagen. Na 30 dagen zijn deze logboeken niet langer interessant.
Octank wil hun loggegevens 7 dagen bewaren. Als de collecties of indexen zijn geconfigureerd voor een gegevensretentie van zeven dagen, verwijdert OpenSearch Serverless de gegevens na zeven dagen. De indexen zijn niet langer beschikbaar voor zoeken. Opmerking: Het aantal documenten in de zoekresultaten kan gegevens weerspiegelen die voor een korte tijd zijn gemarkeerd voor verwijdering.
U kunt het bewaren van gegevens configureren door een beleid voor de levenscyclus van gegevens te maken. De bewaartijd kan onbeperkt zijn, of u kunt een specifieke tijdsduur opgeven in dagen en uren met een minimale bewaartermijn van 24 uur en een maximum van 10 jaar. Als de bewaartijd onbeperkt is, zoals de naam al doet vermoeden, worden er geen gegevens verwijderd.
Om het gegevenslevenscyclusbeleid in OpenSearch Serverless te gaan gebruiken, kunt u de stappen volgen die in dit bericht worden beschreven.
Voorwaarden
In dit bericht wordt ervan uitgegaan dat je al een OpenSearch Serverless-collectie hebt opgezet. Zo niet, raadpleeg dan Loganalyse op een gemakkelijke manier met Amazon OpenSearch Serverless voor instructies.
Maak een beleid voor de levenscyclus van gegevens
U kunt een gegevenslevenscyclusbeleid maken vanuit de AWS-beheerconsole AWS-opdrachtregelinterface (AWS-CLI), AWS CloudFormatie, AWS Cloud-ontwikkelingskit (AWS CDK), en Terraform. Voer de volgende stappen uit om een gegevenslevenscyclusbeleid via de console te maken:
- Kies in de OpenSearch Service-console Beleid voor de levenscyclus van gegevens voor Serverless in het navigatievenster.
- Kies Creëer een datalevenscyclusbeleid.
- Voor Beleid voor de levenscyclus van gegevens naam, voer een naam in (bijvoorbeeld weblogbeleid).
- Kies Toevoegen voor Gegevenslevenscyclus.
- Onder Broncollectie, kies de verzameling waarop u het beleid wilt toepassen (bijvoorbeeld weblogverzameling).
- Onder IndexenVoer de index of indexpatronen in om de bewaarduur toe te passen (bijvoorbeeld weblogs).
- Onder Dataretentie, uitschakelen Ongelimiteerde (om de specifieke retentie in te stellen voor het indexpatroon dat u hebt gedefinieerd).
- Voer de uren of dagen in waarna u gegevens uit Amazon S3 wilt verwijderen.
- Kies Maken.
De volgende afbeelding geeft een snelle demonstratie van het maken van het OpenSearch Serverless Data-levenscyclusbeleid via de voorgaande stappen.

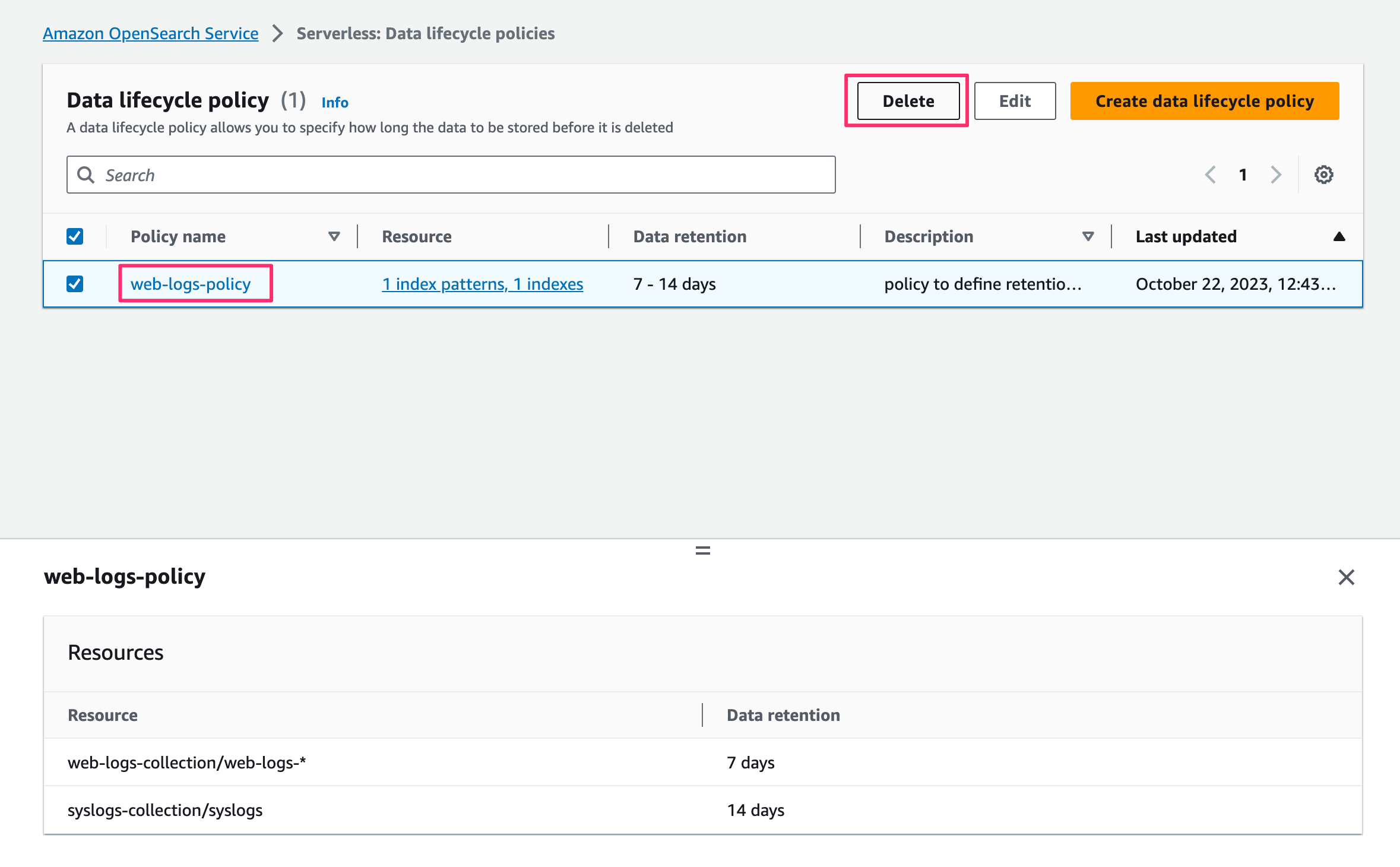
Bekijk het datalevenscyclusbeleid
Nadat u het gegevenslevenscyclusbeleid hebt gemaakt, kunt u het beleid bekijken door de volgende stappen te voltooien:
- Kies in de OpenSearch Service-console Beleid voor de levenscyclus van gegevens voor Serverless in het navigatievenster.
- Selecteer het beleid dat u wilt bekijken (bijvoorbeeld weblogbeleid).
- Kies de hyperlink onder Beleidsnaam.
Op deze pagina vindt u details zoals het indexpatroon en de bewaartermijn voor een specifieke index en collectie. De volgende afbeelding geeft een snelle demonstratie van het bekijken van het OpenSearch Serverless-gegevenslevenscyclusbeleid via de voorgaande stappen.

Update het gegevenslevenscyclusbeleid
Nadat u het gegevenslevenscyclusbeleid hebt gemaakt, kunt u dit wijzigen en bijwerken om meer regels toe te voegen. U kunt bijvoorbeeld nog een indexpatroon toevoegen of een nieuwe collectie met een nieuw indexpatroon toevoegen om de retentie in te stellen. In het volgende voorbeeld ziet u de stappen om nog een regel toe te voegen aan het beleid voor de syslog-index onder syslogs-collection.
- Kies in de OpenSearch Service-console Beleid voor de levenscyclus van gegevens voor Serverless in het navigatievenster.
- Selecteer het beleid dat u wilt bewerken (bijvoorbeeld weblogbeleid) en kies vervolgens Edit.
- Kies Toevoegen voor Gegevenslevenscyclus.
- Onder Broncollectie, kiest u de verzameling die u gaat gebruiken voor het instellen van het gegevenslevenscyclusbeleid (bijvoorbeeld syslogs-collection).
- Onder Indexen, voer de index of indexpatronen in waarvoor u de retentie gaat instellen (bijvoorbeeld syslogs).
- Onder Dataretentie, uitschakelen Ongelimiteerde (om specifieke retentie in te stellen voor het indexpatroon dat u hebt gedefinieerd).
- Voer de uren of dagen in waarna u gegevens uit Amazon S3 wilt verwijderen.
- Kies Bespaar.
De volgende afbeelding geeft een snelle demonstratie van het bijwerken van bestaand beleid voor de levenscyclus van gegevens via de voorgaande stappen.

Verwijder het gegevenslevenscyclusbeleid
Verwijder het bestaande gegevenslevenscyclusbeleid met de volgende stappen:
- Kies in de OpenSearch Service-console Beleid voor de levenscyclus van gegevens voor Serverless in het navigatievenster.
- Selecteer het beleid dat u wilt bewerken (bijvoorbeeld weblogbeleid).
- Kies Verwijder.
Beleidsregels voor de levenscyclus van gegevens
In een gegevenslevenscyclusbeleid specificeert u een reeks regels. Met het gegevenslevenscyclusbeleid kunt u de bewaarperiode beheren van gegevens die zijn gekoppeld aan indexen of verzamelingen die aan deze regels voldoen. Deze regels bepalen de bewaartermijn voor gegevens in een index of groep indexen. Elke regel bestaat uit een resourcetype (index), een bewaarperiode en een lijst met bronnen (indexen) waarop de bewaarperiode van toepassing is.
U definieert de bewaartermijn met een van de volgende formaten:
- “MinIndexRetentie”: “24 uur” – OpenSearch Serverless bewaart de indexgegevens gedurende een bepaalde periode in uren of dagen. U kunt deze periode instellen van 24 uur (24 uur) tot 3,650 dagen (3650 d).
- “NoMinIndexRetention”: waar – OpenSearch Serverless bewaart de indexgegevens voor onbepaalde tijd.
Wanneer beleidsregels voor de gegevenslevenscyclus elkaar overlappen, binnen of tussen beleidsregels, overschrijft de regel met een specifiekere bronnaam of patroon voor een index een regel met een meer algemene bronnaam of patroon voor indexen die gemeenschappelijk zijn voor beide regels. In het volgende beleid zijn bijvoorbeeld twee regels van toepassing op de index index/sales/logstash. In deze situatie heeft de tweede regel voorrang omdat index/sales/log* de langste overeenkomst is met index/sales/logstash. Daarom stelt OpenSearch Serverless geen bewaarperiode in voor de index.
Samengevat
Het gegevenslevenscyclusbeleid biedt een consistente en eenvoudige manier om indexen te beheren in OpenSearch Serverless. Met beleid voor de levenscyclus van gegevens kunt u het gegevensbeheer automatiseren en menselijke fouten voorkomen. Het verwijderen van niet-relevante gegevens zonder handmatige tussenkomst vermindert uw operationele belasting, bespaart opslagkosten en helpt het systeem performant te houden bij het zoeken.
Over de auteurs
 Prashant Agrawal is een Senior Search Specialist Solutions Architect bij Amazon OpenSearch Service. Hij werkt nauw samen met klanten om hen te helpen hun workloads naar de cloud te migreren en helpt bestaande klanten hun clusters te verfijnen om betere prestaties te bereiken en kosten te besparen. Voordat hij bij AWS kwam, hielp hij verschillende klanten OpenSearch en Elasticsearch te gebruiken voor hun zoek- en loganalyse-gebruiksscenario's. Als hij niet aan het werk is, kun je hem tegenkomen op reis en nieuwe plekken verkennen. Kortom, hij houdt van eten → reizen → herhalen.
Prashant Agrawal is een Senior Search Specialist Solutions Architect bij Amazon OpenSearch Service. Hij werkt nauw samen met klanten om hen te helpen hun workloads naar de cloud te migreren en helpt bestaande klanten hun clusters te verfijnen om betere prestaties te bereiken en kosten te besparen. Voordat hij bij AWS kwam, hielp hij verschillende klanten OpenSearch en Elasticsearch te gebruiken voor hun zoek- en loganalyse-gebruiksscenario's. Als hij niet aan het werk is, kun je hem tegenkomen op reis en nieuwe plekken verkennen. Kortom, hij houdt van eten → reizen → herhalen.
 Satish Nandi is een Senior Product Manager bij Amazon OpenSearch Service. Hij is gefocust op OpenSearch Serverless en heeft jarenlange ervaring in netwerken, beveiliging en ML/AI. Hij heeft een bachelordiploma in computerwetenschappen en een MBA in ondernemerschap. In zijn vrije tijd vliegt hij graag met vliegtuigen, zweefvliegtuigen en rijdt hij op zijn motor.
Satish Nandi is een Senior Product Manager bij Amazon OpenSearch Service. Hij is gefocust op OpenSearch Serverless en heeft jarenlange ervaring in netwerken, beveiliging en ML/AI. Hij heeft een bachelordiploma in computerwetenschappen en een MBA in ondernemerschap. In zijn vrije tijd vliegt hij graag met vliegtuigen, zweefvliegtuigen en rijdt hij op zijn motor.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/amazon-opensearch-serverless-now-supports-automated-time-based-data-deletion/

