Introductie
In data scienceWaar innovatie en kansen samenkomen, blijft de vraag naar bekwame professionals omhoogschieten. Datawetenschap is niet alleen een carrière; het is een toegangspoort tot het oplossen van complexe problemen, het stimuleren van innovatie en het vormgeven van de toekomst. Terwijl de sector getuige is van een jaarlijks groeipercentage dat de grenzen overschrijdt 36%, een carrière in datawetenschap belooft zowel financiële beloningen als intellectuele vervulling. Een mix van theoretische kennis en praktische ervaring is van cruciaal belang om te kunnen gedijen in deze dynamische omgeving. Begeleide projecten in data science vormen de brug tussen theorie en toepassing en bieden een praktische leerervaring onder de waakzame begeleiding van mentoren.
Inhoudsopgave
Wat zijn begeleide projecten in data science?
Voordat we meer te weten komen over begeleide projecten, is het essentieel om de aantrekkingskracht van een carrière in de datawetenschap te begrijpen. Naast de complexe algoritmen en enorme datasets loopt datawetenschap voorop bij het ontrafelen van uitdagingen uit de echte wereld, waardoor industrieën vooruit worden geholpen. Recente brancherapporten benadrukken dat het gemiddelde salaris voor datawetenschappers boven het gemiddelde ligt, waardoor het een aantrekkelijke carrièrekeuze is. De snelle groei van de sector vergroot de kansen voor mensen met de juiste vaardigheden en expertise nog verder.
Uitdagingen bij onafhankelijke datawetenschapsprojecten
De uitdagingen variëren van het beheren van enorme datasets tot het implementeren van geavanceerde algoritmen en het afleiden van betekenisvolle inzichten. Real-world data science-scenario's vereisen een genuanceerd begrip van zowel de technische ingewikkeldheden als domeinspecifieke nuances. Hierin ligt de betekenis van begeleide projecten: ze bieden een gestructureerde aanpak en deskundig mentorschap, waardoor de lastige reis wordt omgezet in een verhelderende leerervaring.
Top 15 begeleide projecten waarmee we u kunnen helpen
Onderstaande projecten vallen onder onze AI & ML BlackBelt+-programma. Onze experts helpen je met hun uitzonderlijke mentorschap in de fijne kneepjes ervan te duiken.
1. NYC-taxivoorspelling

Het NYC Taxi Prediction-project dompelt deelnemers onder in de dynamische wereld van transportanalyses. Door gebruik te maken van historische taxiritgegevens verdiepen de deelnemers zich in voorspellende modellen om de taxivraag op verschillende locaties in New York City te voorspellen. Dit project scherpt de vaardigheden op het gebied van regressieanalyse en tijdreeksvoorspelling aan en biedt inzicht in de visualisatie van ruimtelijke gegevens. Het begrijpen en voorspellen van de taxivraag is van cruciaal belang voor het optimaliseren van het wagenparkbeheer, het verbeteren van de klantenservice en het bijdragen aan efficiënte stedelijke transportsystemen.
2. Uitdaging voor scèneclassificatie
In de Scene Classification Challenge krijgen deelnemers de opdracht een robuust beeldclassificatiemodel te ontwikkelen dat in staat is om afbeeldingen nauwkeurig in vooraf gedefinieerde klassen te categoriseren. Door gebruik te maken van deep learning-technieken zoals convolutionele neurale netwerken (CNN's) en transfer learning, krijgen deelnemers praktische ervaring met beeldherkenning. Dit project gaat over het bouwen van nauwkeurige modellen en het begrijpen van de nuances van kenmerkextractie, modeltraining en validatie in de context van beeldclassificatie.
3. Pascal VOC-beeldsegmentatie

Het Pascal VOC Beeldsegmentatieproject laat deelnemers kennismaken met de fascinerende wereld van beeldsegmentatie. Met behulp van de Pascal VOC-dataset leren deelnemers objecten nauwkeurig in afbeeldingen te schetsen. Dit project duikt in de fijne kneepjes van semantische segmentatie, waarbij het doel is om elke pixel in een afbeelding toe te wijzen aan een specifieke objectklasse. Het beheersen van beeldsegmentatie is van cruciaal belang voor toepassingen in computervisie, medische beeldvorming en autonome voertuigen.
4. Scènegeneratie
Scene Generation neemt deelnemers mee in generatieve modellen, met name Generative Adversarial Networks (GAN's). Het doel is om realistische scènes te creëren door beelden te genereren die lijken op scenario's uit de echte wereld. Deelnemers verkennen de principes van GAN's, vijandige training en latente ruimtemanipulatie. Dit project verbetert de vaardigheden op het gebied van generatieve modellering en biedt een creatieve uitlaatklep voor het maken van door AI gegenereerde inhoud.
5. Big Mart-verkoopvoorspelling

Het Big Mart Sales Prediction-project dompelt deelnemers onder in het retailanalysedomein. Door historische verkoopgegevens te analyseren, voorspellen deelnemers de verkoop van verschillende producten op verschillende verkooppunten. Dit project omvat regressieanalyse, feature engineering en modelevaluatietechnieken. De opgedane inzichten zijn van onschatbare waarde voor retailers die de voorraad willen optimaliseren, promoties effectief willen plannen en de algehele verkoopprestaties willen verbeteren.
6. Geslachtsclassificatie
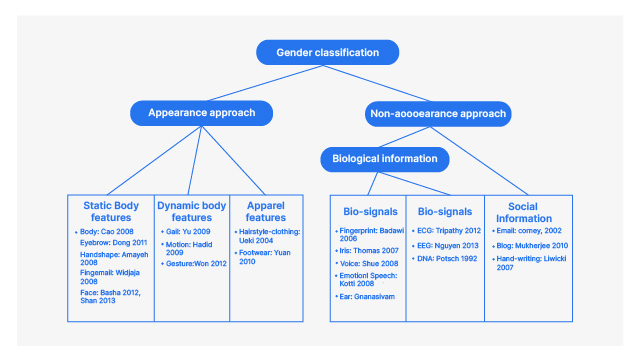
Genderclassificatie is een computervisieproject waarbij deelnemers een model bouwen om het geslacht van individuen te classificeren op basis van gelaatstrekken. Dit project omvat het voorbewerken van afbeeldingen, het extraheren van relevante gelaatstrekken en het trainen van een machinaal leermodel voor classificatie. Het begrijpen van genderclassificatie heeft toepassingen in verschillende domeinen, waaronder beveiligingssystemen, gepersonaliseerde marketing en aanpassing van de gebruikerservaring.
7. Identificeer gevoelens

Het project Identity Sentiments waagt zich aan natuurlijke taalverwerking (NLP) en sentimentanalyse. Deelnemers analyseren tekstuele gegevens, zoals productrecensies of opmerkingen op sociale media, om sentimenten als positief, negatief of neutraal te classificeren. Dit project omvat tekstvoorverwerking, functie-extractie en de toepassing van machine learning-algoritmen voor sentimentclassificatie. Sentimentanalyse is van cruciaal belang voor bedrijven om realtime klanttevredenheids- en sentimenttrends te meten.
8. Classificatie van stedelijk geluid
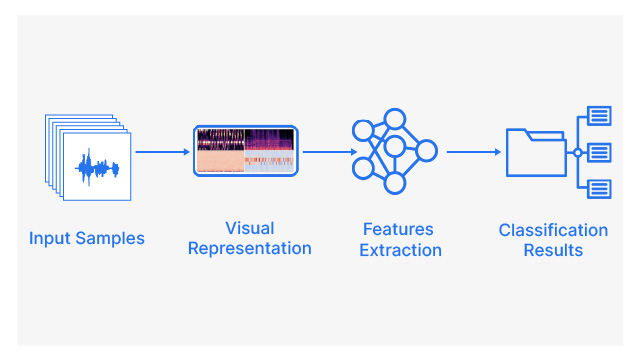
Urban Sound Classification daagt deelnemers uit om een machinaal leermodel te ontwikkelen dat stedelijke geluiden kan classificeren. Dit project omvat het voorbewerken van audiogegevens, het extraheren van relevante kenmerken en het trainen van een classificatiemodel. De toepassingen van stedelijke geluidsclassificatie variëren van het monitoren van geluidsoverlast tot het verbeteren van veiligheidssystemen voor slimme steden. Deelnemers krijgen inzicht in signaalverwerking, feature-engineering en de nuances van het werken met audiogegevens.
9. Beeldruis verwijderen

Image Denoising is een project gericht op het verbeteren van de kwaliteit van digitale beelden door het verwijderen van ruis. Deelnemers verkennen verschillende ruisonderdrukkingstechnieken, waaronder filters en op deep learning gebaseerde methoden. Beeldruis verwijderen is van cruciaal belang wanneer beelden verslechteren als gevolg van factoren zoals omstandigheden met weinig licht of compressieartefacten. Dit project geeft deelnemers een diepgaand inzicht in beeldverwerking, filterontwerp en de afwegingen die betrokken zijn bij het denoiseren van algoritmen.
10. Een op afbeeldingen gebaseerd genderclassificatiemodel implementeren met behulp van Streamlit
Door een op afbeeldingen gebaseerd genderclassificatiemodel te implementeren met behulp van Streamlit gaan deelnemers verder dan modelontwikkeling en implementeren. In dit project leren deelnemers hun genderclassificatiemodel in te zetten met behulp van Streamlit, een gebruiksvriendelijk webapp-framework. Dit vergroot hun technische vaardigheden op het gebied van modelimplementatie en biedt praktische ervaring met het creëren van interactieve en toegankelijke applicaties. De mogelijkheid om modellen in te zetten is cruciaal voor het presenteren van resultaten en het toegankelijk maken van machine learning-applicaties voor een breder publiek.
11. Implementatie van stedelijke geluidsclassificatie met behulp van Flask
Door Urban Sound Classification in te zetten met Flask wordt de implementatie-ervaring verder uitgebreid door deelnemers te begeleiden bij het in productie nemen van hun model. In dit project leren deelnemers een stedelijk geluidsclassificatiesysteem in te zetten met behulp van Flask, een webframework voor Python. Deze praktische ervaring met het op een schaalbare en robuuste manier implementeren van machine learning-modellen is van onschatbare waarde voor toepassingen in de echte wereld.
12. Wikipedia-tekstgeneratie

Wikipedia Text Generation verkent het fascinerende domein van natuurlijke taalgeneratie (NLG). Deelnemers verdiepen zich in het bouwen van een model dat tekst kan genereren in een formaat dat lijkt op Wikipedia-artikelen. Dit project omvat geavanceerde NLP-technieken, modellen voor het genereren van sequenties en de nuances van het creëren van coherente en contextueel relevante tekst. Inzicht in het genereren van tekst opent deuren naar toepassingen zoals het maken van inhoud, chatbots en geautomatiseerde samenvattingen.
13. Tekst vertalen van Frans naar Engels

Tekst vertalen van Frans naar Engels laat deelnemers kennismaken met taalvertaalmodellen. In dit project bouwen de deelnemers een reeks-tot-reeks-model voor het vertalen van tekst van het Frans naar het Engels. De complexiteiten omvatten het verwerken van meertalige gegevens, het trainen van encoder-decoder-architecturen en het afstemmen van taalvertalingen. Taalvertaalmodellen zijn van fundamenteel belang voor het slechten van taalbarrières in de huidige geglobaliseerde wereld.
14. Analyse van voedselvoorspellingen
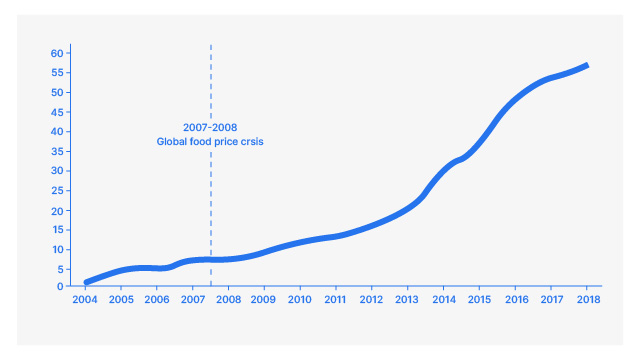
Food Forecasting Analysis pakt de praktische uitdaging aan van het voorspellen van de vraag naar verschillende voedingsmiddelen. Deelnemers passen tijdreeksanalyse- en voorspellingsmethoden toe om het voorraadbeheer in de voedingsmiddelenindustrie te optimaliseren. Dit project biedt inzicht in de nuances van tijdreeksgegevens, seizoensinvloeden en de factoren die de vraag beïnvloeden. Nauwkeurige prognoses zijn cruciaal voor het minimaliseren van verspilling, het garanderen van de beschikbaarheid van producten en het stroomlijnen van de supply chain-activiteiten.
15. Prognoses – Energieverbruik
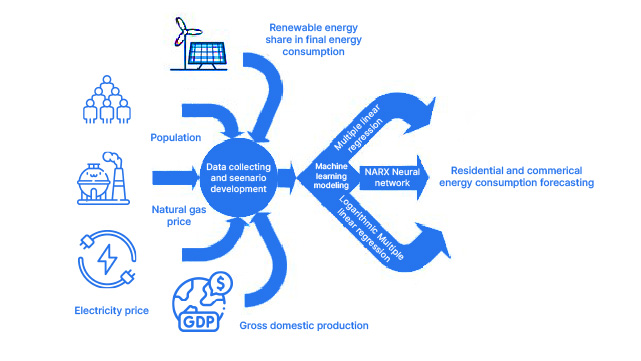
Het project Forecasting: Energy Consumption gaat dieper in op het voorspellen van energieverbruikspatronen. Deelnemers dragen bij aan strategieën voor duurzaam energiebeheer door tijdreeksvoorspellingstechnieken toe te passen. Dit project is essentieel voor het optimaliseren van de toewijzing van energiebronnen, het verbeteren van de efficiëntie en het ondersteunen van de transitie naar hernieuwbare energiebronnen. Deelnemers krijgen een dieper inzicht in tijdreeksvoorspellingen, modelevaluatie en de rol van gegevens bij het vormgeven van energiebeleid.
Conclusie
Deze begeleide projecten zijn niet louter leeroefeningen; het zijn meeslepende ervaringen die deelnemers de vaardigheden en inzichten bieden die nodig zijn om uit te blinken in het dynamische veld van data science. Of het nu gaat om het beheersen van beeldclassificatie, het verdiepen in natuurlijke taalverwerking, het inzetten van modellen of het voorspellen van toekomstige trends, elk project biedt unieke uitdagingen en leermogelijkheden. Deze projecten worden niet op zichzelf ondernomen; ze maken deel uit van ons AI & ML BlackBelt+-programma, waar mentorschap een aanvulling vormt op praktijkgericht leren, zodat uw reis in datawetenschap niet alleen educatief maar ook transformatief is.
Het beheersen van data science staat niet op zichzelf; het is samenwerkend, begeleid en veelzijdig. Ons BlackBelt+-programma biedt toegang tot deze eersteklas begeleide projecten en mentorschap om uw succes te garanderen. Of u nu een beginner bent die uw eerste stappen zet of een ervaren professional die zich wil bijscholen, ons programma is ontworpen om tegemoet te komen aan diverse leerbehoeften.
Begin vandaag nog met het opbouwen van uw toekomst in data science! Kom bij onze Gecertificeerd AI & ML BlackBelt+ Programma en ontgrendel een wereld van begeleide projecten, mentorschap en eindeloze mogelijkheden. Uw datawetenschapsreis begint hier!
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/12/guided-projects-to-sharpen-your-data-science-skills/

