개요
검색 증강 세대(Retrieval Augmented Generation)가 한동안 여기에 있었습니다. 벡터 저장소, 검색 프레임워크 및 LLM과 같은 많은 도구와 애플리케이션이 이 개념을 기반으로 구축되어 사용자 정의 문서, 특히 Langchain을 사용한 반구조적 데이터 작업을 편리하게 만듭니다. 길고 조밀한 텍스트 작업이 이보다 쉽고 재미있던 적은 없었습니다. 기존의 RAG DOC, PDF 등과 같이 구조화되지 않은 텍스트가 많은 파일에 잘 작동합니다. 그러나 이 접근 방식은 PDF에 포함된 테이블과 같은 반구조화된 데이터에는 적합하지 않습니다.
반구조화된 데이터로 작업할 때 일반적으로 두 가지 우려 사항이 있습니다.
- 기존의 추출 및 텍스트 분할 방법은 PDF의 테이블을 고려하지 않습니다. 그들은 대개 테이블을 깨뜨리게 됩니다. 따라서 정보 손실이 발생합니다.
- 테이블을 포함하면 정확한 의미 검색으로 변환되지 않을 수 있습니다.
따라서 이 기사에서는 반구조화된 데이터에 대한 이러한 두 가지 문제를 해결하기 위해 Langchain을 사용하여 반구조화된 데이터에 대한 검색 생성 파이프라인을 구축할 것입니다.
학습 목표
- 정형, 비정형, 반정형 데이터의 차이점을 이해합니다.
- Retrieval Augement Generation 및 Langchain에 대한 약간의 재교육입니다.
- Langchain으로 반구조화된 데이터를 처리하기 위해 다중 벡터 검색기를 구축하는 방법을 알아보세요.
이 기사는 데이터 과학 Blogathon.
차례
데이터 유형
일반적으로 세 가지 유형의 데이터가 있습니다. 구조화, 반구조화, 비구조화.
- 구조화 된 데이터: 구조화된 데이터는 표준화된 데이터입니다. 데이터는 행, 열 등 미리 정의된 스키마를 따릅니다. SQL 데이터베이스, 스프레드시트, 데이터 프레임 등
- 비정형 데이터: 비정형 데이터는 정형 데이터와 달리 데이터 모델을 따르지 않습니다. 데이터는 얻을 수 있는 한 무작위입니다. 예를 들어 PDF, 텍스트, 이미지 등이 있습니다.
- 반구조화된 데이터: 앞의 데이터 타입을 조합한 것입니다. 구조화된 데이터와 달리 미리 정의된 엄격한 스키마가 없습니다. 그러나 데이터는 구조화되지 않은 유형과 달리 일부 마커를 기반으로 하는 계층적 순서를 여전히 유지합니다. 예를 들어 CSV, HTML, PDF에 포함된 테이블, XML 등이 있습니다.

RAG란 무엇인가요?
RAG는 검색 증강 생성(Retrieval Augmented Generation)을 의미합니다. 이는 대규모 언어 모델에 새로운 정보를 제공하는 가장 간단한 방법입니다. 이제 RAG에 대한 간략한 입문서를 살펴보겠습니다.
일반적인 RAG 파이프라인에는 로컬 파일, 웹 페이지, 데이터베이스 등과 같은 지식 소스, 임베딩 모델, 벡터 데이터베이스 및 LLM이 있습니다. 우리는 다양한 소스에서 데이터를 수집하고, 문서를 분할하고, 텍스트 청크의 임베딩을 가져와 벡터 데이터베이스에 저장합니다. 이제 쿼리 임베딩을 벡터 저장소에 전달하고 벡터 저장소에서 문서를 검색한 다음 마지막으로 LLM을 사용하여 답변을 생성합니다.
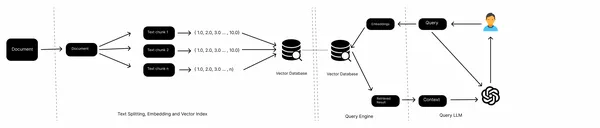
이는 기존 RAG의 워크플로우이며 텍스트와 같은 구조화되지 않은 데이터에 잘 작동합니다. 그러나 PDF에 포함된 테이블과 같이 반구조화된 데이터의 경우 제대로 수행되지 않는 경우가 많습니다. 이번 글에서는 이러한 임베디드 테이블을 처리하는 방법을 알아보겠습니다.
랭체인이란?
Langchain은 LLM 기반 애플리케이션을 구축하기 위한 오픈 소스 프레임워크입니다. 이 프로젝트는 출시 이후 소프트웨어 개발자들 사이에서 널리 채택되었습니다. AI 애플리케이션을 더 빠르게 구축할 수 있는 통합된 도구와 기술 범위를 제공합니다. Langchain에는 벡터 저장소, 문서 로더, 검색기, 임베딩 모델, 텍스트 분할기 등과 같은 도구가 포함되어 있습니다. 이는 AI 애플리케이션 구축을 위한 원스톱 솔루션입니다. 그러나 이를 차별화하는 두 가지 핵심 가치 제안이 있습니다.
- LLM 체인: Langchain은 다중 체인을 제공합니다. 이러한 체인은 단일 작업을 수행하기 위해 여러 도구를 함께 연결합니다. 예를 들어 ConversationalRetrievalChain은 LLM, 벡터 저장소 검색기, 임베딩 모델 및 채팅 기록 개체를 함께 연결하여 쿼리에 대한 응답을 생성합니다. 도구는 하드 코딩되어 있으며 명시적으로 정의해야 합니다.
- LLM 에이전트: LLM 체인과 달리 AI 에이전트에는 하드 코딩된 도구가 없습니다. 하나의 도구를 다른 도구로 연결하는 대신 LLM이 도구의 텍스트 설명을 기반으로 어떤 도구를 선택할지 결정하도록 합니다. 이는 추론 및 의사 결정과 관련된 복잡한 LLM 애플리케이션을 구축하는 데 이상적입니다.
RAG 파이프라인 구축
이제 개념에 대한 입문서가 생겼습니다. 파이프라인 구축 방법에 대해 논의해 보겠습니다. 반구조화된 데이터로 작업하는 것은 정보 저장을 위한 기존 스키마를 따르지 않기 때문에 까다로울 수 있습니다. 그리고 구조화되지 않은 데이터로 작업하려면 정보 추출을 위해 맞춤 제작된 전문 도구가 필요합니다. 따라서 이 프로젝트에서는 "비구조화"라는 도구 중 하나를 사용합니다. PDF, HTML, XML 등의 테이블과 같은 다양한 구조화되지 않은 데이터 형식에서 정보를 추출하기 위한 오픈 소스 도구입니다. Unstructured는 내부적으로 Tesseract 및 Poppler를 사용하여 파일의 여러 데이터 형식을 처리합니다. 이제 코딩 부분을 시작하기 전에 환경을 설정하고 종속성을 설치해 보겠습니다.
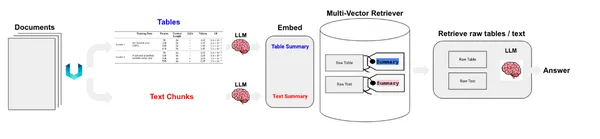
개발 환경 설정
다른 Python 프로젝트와 마찬가지로 Python 환경을 열고 Poppler 및 Tesseract를 설치합니다.
!sudo apt install tesseract-ocr
!sudo apt-get install poppler-utils이제 프로젝트에 필요한 종속성을 설치하십시오.
!pip install "unstructured[all-docs]" Langchain openai이제 종속성을 설치했으므로 PDF 파일에서 데이터를 추출하겠습니다.
from unstructured.partition.pdf import partition_pdf
pdf_elements = partition_pdf(
"mistral7b.pdf",
chunking_strategy="by_title",
extract_images_in_pdf=True,
max_characters=3000,
new_after_n_chars=2800,
combine_text_under_n_chars=2000,
image_output_dir_path="./"
)이를 실행하면 OCR에 필요한 YOLOx와 같은 여러 종속성이 설치되고 추출된 데이터를 기반으로 개체 유형이 반환됩니다. extract_images_in_pdf를 활성화하면 파일에서 구조화되지 않은 포함된 이미지를 추출할 수 있습니다. 이는 다중 모드 솔루션을 구현하는 데 도움이 될 수 있습니다.
이제 PDF의 요소 카테고리를 살펴보겠습니다.
# Create a dictionary to store counts of each type
category_counts = {}
for element in pdf_elements:
category = str(type(element))
if category in category_counts:
category_counts[category] += 1
else:
category_counts[category] = 1
# Unique_categories will have unique elements
unique_categories = set(category_counts.keys())
category_counts이것을 실행하면 요소 카테고리와 해당 개수가 출력됩니다.
이제 쉽게 다룰 수 있도록 요소를 분리합니다. Langchain의 Document 유형을 상속받은 Element 유형을 생성합니다. 이는 보다 체계화된 데이터를 보장하여 처리하기가 더 쉽습니다.
from unstructured.documents.elements import CompositeElement, Table
from langchain.schema import Document
class Element(Document):
type: str
# Categorize by type
categorized_elements = []
for element in pdf_elements:
if isinstance(element, Table):
categorized_elements.append(Element(type="table", page_content=str(element)))
elif isinstance(element, CompositeElement):
categorized_elements.append(Element(type="text", page_content=str(element)))
# Tables
table_elements = [e for e in categorized_elements if e.type == "table"]
# Text
text_elements = [e for e in categorized_elements if e.type == "text"]다중 벡터 리트리버
테이블과 텍스트 요소가 있습니다. 이제 우리가 이를 처리할 수 있는 두 가지 방법이 있습니다. 원시 요소를 문서 저장소에 저장하거나 텍스트 요약을 저장할 수 있습니다. 테이블은 의미론적 검색에 어려움을 줄 수 있습니다. 이 경우 테이블 요약을 생성하여 원시 테이블과 함께 문서 저장소에 저장합니다. 이를 달성하기 위해 MultiVectorRetriever를 사용합니다. 이 검색기는 요약 텍스트의 임베딩을 저장하는 벡터 저장소와 원시 문서를 저장하는 간단한 메모리 내 문서 저장소를 관리합니다.
먼저 앞서 추출한 테이블과 텍스트 데이터를 요약하는 요약 체인을 구축합니다.
from langchain.chat_models import cohere
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
prompt_text = """You are an assistant tasked with summarizing tables and text.
Give a concise summary of the table or text. Table or text chunk: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
model = cohere.ChatCohere(cohere_api_key="your_key")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
tables = [i.page_content for i in table_elements]
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
texts = [i.page_content for i in text_elements]
text_summaries = summarize_chain.batch(texts, {"max_concurrency": 5})저는 데이터 요약을 위해 Cohere LLM을 사용했습니다. GPT-4와 같은 OpenAI 모델을 사용할 수 있습니다. 더 나은 모델은 더 나은 결과를 낳습니다. 때로는 모델이 테이블 세부정보를 완벽하게 캡처하지 못할 수도 있습니다. 따라서 가능한 모델을 사용하는 것이 좋습니다.
이제 MultiVectorRetriever를 만듭니다.
from langchain.retrievers import MultiVectorRetriever
from langchain.prompts import ChatPromptTemplate
import uuid
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.document import Document
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name="collection",
embedding_function=OpenAIEmbeddings(openai_api_key="api_key"))
# The storage layer for the parent documents
store = InMemoryStore()
id_key = ""id"
# The retriever
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)
# Add texts
doc_ids = [str(uuid.uuid4()) for _ in texts]
summary_texts = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(text_summaries)
]
retriever.vectorstore.add_documents(summary_texts)
retriever.docstore.mset(list(zip(doc_ids, texts)))
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content=s, metadata={id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
우리는 텍스트와 테이블의 요약 임베딩을 저장하기 위해 Chroma 벡터 저장소를 사용하고 원시 데이터를 저장하기 위해 메모리 내 문서 저장소를 사용했습니다.
RAG
이제 검색기가 준비되었으므로 Langchain Expression Language를 사용하여 RAG 파이프라인을 구축할 수 있습니다.
from langchain.schema.runnable import RunnablePassthrough
# Prompt template
template = """Answer the question based only on the following context,
which can include text and tables::
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature=0.0, openai_api_key="api_key")
# RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
이제 벡터 스토어에서 검색된 임베딩을 기반으로 질문하고 답변을 받을 수 있습니다.
chain.invoke(input = "What is the MT bench score of Llama 2 and Mistral 7B Instruct??")결론
많은 정보가 반구조화된 데이터 형식에 숨겨져 있습니다. 그리고 이러한 데이터에 대해 기존 RAG를 추출하고 수행하는 것은 어렵습니다. 이 기사에서는 PDF에서 텍스트와 포함된 테이블을 추출하는 것부터 Langchain을 사용하여 다중 벡터 검색기와 RAG 파이프라인을 구축하는 것까지 진행했습니다. 따라서 기사의 주요 내용은 다음과 같습니다.
주요 요점
- 기존 RAG는 텍스트 분할 중 테이블 분할 및 부정확한 의미 검색과 같은 반구조화된 데이터를 처리하는 데 종종 어려움을 겪습니다.
- 반구조화된 데이터를 위한 오픈 소스 도구인 Unstructured는 PDF 또는 유사한 반구조화된 데이터에서 포함된 테이블을 추출할 수 있습니다.
- Langchain을 사용하면 더 나은 의미 검색을 위해 문서 저장소에 테이블, 텍스트 및 요약을 저장하기 위한 다중 벡터 검색기를 구축할 수 있습니다.
자주 묻는 질문
A: 반구조화된 데이터는 구조화된 데이터와 달리 엄격한 스키마를 갖지 않지만 계층을 시행하기 위한 다른 형태의 마커를 가지고 있습니다.
A. 반구조화된 데이터의 예로는 CSV, 이메일, HTML, XML, 쪽모이 세공 파일 등이 있습니다.
A. LangChain은 대규모 언어 모델을 사용하여 애플리케이션 생성을 단순화하는 오픈 소스 프레임워크입니다. 챗봇, RAG, 질문 답변, 생성 작업 등 다양한 작업에 사용할 수 있습니다.
A. RAG 파이프라인은 외부 데이터 저장소에서 문서를 검색하고, 이를 처리하여 지식 베이스에 저장하고, 쿼리하는 도구를 제공합니다.
A. Llama Index는 검색 및 검색 애플리케이션을 명시적으로 설계하는 반면 Langchain은 맞춤형 AI 에이전트를 생성할 수 있는 유연성을 제공합니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/12/building-a-rag-pipeline-for-semi-structured-data-with-langchain/

