개요
이 기사에서는 봇 감지 문제에 대한 개요를 제시하고 봇 감지와 관련된 주요 과제를 강조합니다. 봇 활동을 식별하고 차단하기 위해 널리 사용되는 다양한 기술과 방법을 살펴봅니다. 이 기사에서는 온라인 개인 정보 보호, 보안에 대한 봇 탐지의 영향에 대해서도 설명합니다. 또한 봇 탐지의 정확성과 효율성을 개선하는 데 있어 기계 학습과 인공 지능의 역할을 조사합니다.

학습 목표:
- 데이터 과학의 맥락에서 봇 탐지의 개념 이해
- 온라인 플랫폼에서 접하는 다양한 유형의 봇 탐색
- 봇 탐지에 사용되는 다양한 기술과 알고리즘을 검토합니다.
- 봇 탐지에서 데이터 과학 및 기계 학습의 역할 이해
- 봇 탐지 및 잠재적인 향후 개발의 한계와 과제에 대해 논의합니다.
이 기사는 데이터 과학 블로그.
차례
봇은 무엇입니까?
봇으로 알려진 소프트웨어 프로그램은 사람의 개입 없이 인터넷에서 작업을 수행하도록 설계되었습니다. 단순한 웹 스크레이퍼 및 데이터 입력 봇에서 보다 정교한 챗봇, 소셜 미디어 봇, 맬웨어 봇 및 스팸 봇에 이르기까지 다양합니다. 봇은 속도, 일관성, 감정 부족, 반복적인 행동, 제한된 창의성 등 인간 사용자와 구별되는 특정 특성을 가지고 있습니다.

다양한 목적을 수행하는 다양한 유형의 봇이 있습니다. 몇 가지 일반적인 유형의 봇은 다음과 같습니다.
- 웹 크롤러: 웹사이트를 자동으로 스캔하고 다양한 검색 엔진 및 기타 애플리케이션에 대한 데이터를 수집하는 봇
- 봇봇: 인간의 대화를 시뮬레이션하고 자동화된 고객 서비스 또는 메시징 플랫폼 지원을 제공하는 봇입니다.
- 소셜 미디어 봇: 소셜 미디어 계정을 생성 및 관리하고 게시 및 댓글 작성을 자동화하며 온라인 담론을 조작하는 봇입니다.
- 멀웨어 봇: 컴퓨터와 기기를 악성코드로 감염시키고 데이터 탈취, 사이버 공격 등 악의적인 활동을 수행하는 봇.
- 스팸 봇: 이메일 및 메시징 플랫폼에서 사용자에게 요청하지 않은 메시지 및 광고를 보내는 봇입니다.
봇은 인간 사용자와 구별되는 특정 특성을 공유합니다. 이러한 특성 중 일부는 다음과 같습니다.
- 속도 : 봇은 인간보다 훨씬 빠른 속도로 작업을 수행할 수 있습니다.
- 일관성 : 봇은 높은 정확도와 일관성으로 작업을 수행할 수 있습니다.
- 감정 부족: 봇에는 행동에 영향을 줄 수 있는 감정이나 주관적인 편견이 없습니다.
- 반복적인 행동: 프로그래머는 특정 작업을 반복적으로 수행하는 봇을 만듭니다.
- 창의성 부족: 봇은 인간과 같은 방식으로 창의적으로 생각하거나 새로운 상황에 적응하는 능력이 없습니다.
봇이 존재하는 이유는 무엇입니까?
봇은 제작자의 의도에 따라 다양한 이유로 존재합니다. 봇 생성의 몇 가지 일반적인 이유는 다음과 같습니다.
- 효율성:봇은 인간보다 빠르고 효율적으로 작업을 수행할 수 있어 반복적이거나 시간이 많이 걸리는 작업을 자동화하는 데 유용합니다.
- 악의적인 활동: 스팸 유포, 사이버 공격 시작, 데이터 도용과 같은 악의적인 활동에 봇을 사용합니다.
- 마케팅과 광고: 봇을 사용하여 가짜 사용자 리뷰 및 소셜 미디어 참여를 생성하여 제품 및 서비스를 홍보합니다.
- 연구 및 데이터 수집: 봇을 사용하여 연구 목적으로 인터넷에서 데이터를 수집하거나 비즈니스 결정을 알립니다.

봇 사용의 예는 다음과 같습니다.
- 웹 스크래핑: 봇을 사용하여 시장 조사, 가격 비교 및 기타 비즈니스 목적에 유용할 수 있는 웹 사이트에서 데이터를 검색합니다.
- 고객 서비스 : 챗봇은 메시징 플랫폼에서 자동화된 고객 지원을 제공하므로 사람의 개입이 필요하지 않습니다.
- 소셜 미디어 조작: 봇을 사용하여 가짜 소셜 미디어 계정을 생성 및 관리하고 인위적으로 참여 메트릭을 부풀리고 잘못된 정보를 퍼뜨립니다.
- 사이버 공격: 맬웨어 봇을 사용하여 데이터를 도용하고 DDoS 공격을 실행하고 기타 악의적인 활동을 수행하는 데 사용할 수 있는 맬웨어로 컴퓨터와 장치를 감염시킵니다.
- 노름: 봇을 사용하여 게임 플레이를 자동화하고 온라인 게임에서 부당한 이점을 얻습니다.
봇 탐지 기술
봇을 탐지하는 몇 가지 다른 기술은 다음과 같습니다.
- 행동 분석: 이 기술에는 사용자 행동 패턴을 분석하여 사람과 봇 활동을 구분하는 작업이 포함됩니다.
- 장치 지문: 이 기술에는 봇을 식별하기 위해 웹 사이트 또는 애플리케이션에 액세스하는 장치의 고유한 특성을 분석하는 작업이 포함됩니다.
- CAPTCHA: 이 기술은 봇이 풀기 어렵지만 사람이 풀기 쉬운 퍼즐이나 도전 과제를 사용하는 것과 관련이 있습니다.
- 기계 학습: 이 기술에는 봇 활동과 관련된 패턴 및 특성을 식별하는 훈련 알고리즘이 포함됩니다.

각 봇 감지 기술에는 고유한 장점과 단점이 있습니다. 이들 중 일부는 다음과 같습니다.
- 행동 분석
이점: 이전에 본 적이 없는 봇을 감지하고 인간 사용자의 행동에 대한 통찰력도 제공할 수 있습니다.
불리: 설정하는 데 시간이 많이 걸리고 비용도 많이 들 수 있으며 가양성 또는 가음성이 발생할 수 있습니다.
2. 장치 지문 인식
이점: 자동화된 도구 또는 스크립트를 사용하는 봇을 식별하는 데 효과적이며 높은 수준의 정확도를 제공합니다.
불리: 스푸핑된 장치 또는 가상 장치를 사용하는 정교한 봇은 이를 우회하여 잠재적으로 민감한 장치 정보를 수집하고 개인 정보 보호 문제를 제기할 수 있습니다.
3. 보안 문자
이점: 정교한 AI 기능이 없는 단순한 봇을 차단하는 데 효과적입니다.
불리: 인간 사용자는 봇이 기계 학습 또는 기타 고급 기술을 사용하여 이를 우회할 수 있기 때문에 불편하고 좌절감을 느낍니다.
4. 기계 학습
이점: 새로운 유형의 봇 활동에 적응하는 데 높은 수준의 정확도를 달성하고 인간이 식별하기 어려운 미묘한 패턴을 감지합니다.
불리: 효과적이려면 방대한 양의 교육 데이터가 필요하며 교육 데이터 또는 기계 학습 알고리즘을 조작하려는 공격에 취약할 수 있습니다.
우리는 각 봇 탐지 기술의 장점과 단점을 살펴보았습니다. 이제 실제 사례를 살펴보겠습니다.
실제 사례
- 행동 분석: 일부 사이버 보안 회사는 이 기술을 활용하여 봇넷 활동을 탐지합니다. 네트워크 트래픽의 동작을 분석하고 장치 간의 통신 패턴을 식별합니다.
- 장치 지문 인식: 일부 웹 사이트 및 애플리케이션은 이 기술을 사용하여 봇 활동을 감지합니다. 사용자 에이전트, 화면 해상도 및 기타 장치 속성을 포함하여 서비스에 액세스하는 데 사용되는 장치의 특성을 분석합니다.
- CAPTCHA: 웹 사이트는 일반적으로 자동 계정 생성, 댓글 스팸 및 기타 유형의 봇 활동을 방지하기 위해 이 기술을 사용합니다.
- 기계 학습 : Google과 같은 회사는 이 기술을 활용하여 플랫폼에서 봇 활동을 감지합니다. 그들은 기계 학습 알고리즘을 훈련시켜 봇과 관련된 행동 패턴을 식별합니다.
봇 탐지를 위한 기계 학습
인공 지능의 일부인 ML에는 명시적인 프로그래밍 없이 데이터의 패턴과 관계를 학습하는 훈련 알고리즘이 포함됩니다. 사용자 행동, 네트워크 트래픽 또는 기타 관련 데이터의 광범위한 데이터 세트에 대한 교육 알고리즘을 통해 봇 탐지에 널리 사용됩니다. 이 교육을 통해 봇 활동과 관련된 패턴을 식별할 수 있습니다. 훈련된 알고리즘은 새로운 데이터를 봇 또는 봇이 아닌 활동으로 자동 분류할 수 있습니다.
봇 탐지에 기계 학습을 사용하면 다음과 같은 이점이 있습니다.
- 확장성: 기계 학습 알고리즘은 대량의 데이터를 빠르게 처리할 수 있으므로 실시간으로 봇 활동을 감지하는 데 적합합니다.
- 적응성: 기계 학습 알고리즘은 새로운 유형의 봇 활동에 적응하기 위해 새로운 데이터에 대해 훈련될 수 있으므로 새롭고 진화하는 위협을 보다 효과적으로 탐지할 수 있습니다.
- 정확성: 기계 학습 알고리즘은 데이터에서 인간이 감지하기 어려운 미묘한 패턴을 식별할 수 있어 기존의 규칙 기반 방법보다 더 정확합니다.
봇 탐지를 위한 기계 학습 사용의 제한 사항은 다음과 같습니다.
- 바이어스: 기계 학습 알고리즘은 훈련 데이터가 분석 중인 모집단을 대표하지 않는 경우 때때로 편향됩니다.
- 복잡성: 기계 학습 알고리즘은 복잡하고 해석하기 어려울 수 있으므로 결정에 도달하는 방법을 이해하기 어렵습니다.
- 피팅: 머신 러닝 알고리즘은 훈련 데이터를 과대적합할 수 있어 보이지 않는 새로운 봇 활동을 감지하는 데 덜 효과적입니다.
이제 간단한 코드 예제를 통해 이를 이해하겠습니다. Google Collab을 열고 다음 코드를 구현하여 더 잘 이해할 수 있습니다.
코드 예제
더미 데이터 세트를 생성하고 설명 목적으로 작업합니다.
import pandas as pd
# Define dummy data
data = { 'num_requests': [50, 100, 150, 200, 250, 300, 350, 400, 450, 500], 'num_failed_requests': [5, 10, 15, 20, 25, 30, 35, 40, 45, 50], 'num_successful_requests': [45, 90, 135, 180, 225, 270, 315, 360, 405, 450], 'avg_response_time': [100, 110, 120, 130, 140, 150, 160, 170, 180, 190], 'is_bot': [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
} # Convert data to pandas dataframe
df = pd.DataFrame(data) # Save dataframe to csv file
df.to_csv('bot_data.csv', index=False) from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # Load dataset
data = pd.read_csv('bot_data.csv') # Split dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split( data.drop('is_bot', axis=1), data['is_bot'], test_size=0.3) # Initialize random forest classifier
rfc = RandomForestClassifier() # Train classifier on training set
rfc.fit(X_train, y_train) # Predict labels for test set
y_pred = rfc.predict(X_test) # Evaluate the accuracy of classifier
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
# Load trained model
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
이제 우리는 모델을 훈련시켰고 좋은 정확도를 얻었습니다. (참고: 실제 시나리오에서는 정확도가 많이 다를 수 있습니다.) 이제 새로운 무작위 데이터를 제공하여 모델을 테스트할 수 있습니다.
# Create new request data
new_data = { 'num_requests': [500], 'num_failed_requests': [60], 'num_successful_requests': [200], 'avg_response_time': [190]
} # Convert new data to pandas dataframe
new_df = pd.DataFrame(new_data) # Predict whether new data represents a bot or not
prediction = rfc.predict(new_df)
if prediction[0] == 1: print('This request data is likely from a bot.')
else: print('This request data is likely from a human.') 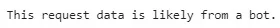
봇 감지에 사람이 관여
인간은 인지 능력을 활용하여 기계가 인식하기 어려울 수 있는 복잡한 패턴을 식별하고 해석합니다.
봇 탐지에서 인간 개입의 이점은 다음과 같습니다.
- 인간은 기계가 쉽게 식별할 수 없는 미묘한 패턴과 이상 현상을 감지할 수 있습니다.
- 인간은 진화하는 새로운 봇 위협에 적응하고 탐지 전략을 신속하게 업데이트하여 공격자보다 한발 앞서 나갈 수 있습니다.
- 인간 전문가는 특정 산업이나 기술에 대한 지식과 같은 전문 지식과 기술을 봇 탐지 노력에 가져올 수 있습니다.
제한 사항
봇 탐지에서 인간 개입의 제한 사항은 다음과 같습니다.
- 주관: 인간의 감지는 주관적일 수 있으며 편견과 오류가 발생하기 쉽습니다.
- 시간이 많이 걸리는: 수동 검색은 특히 대규모 데이터 세트에서 시간이 많이 걸리고 노동 집약적일 수 있습니다.
- 확장성: 사람의 감지는 특히 실시간 감지 시나리오에서 확장되지 않을 수 있습니다.
산업 기반 사례
성공적인 인간 주도 봇 탐지 노력의 예는 다음과 같습니다.
- 미국(CISA)의 Cybersecurity and Infrastructure Security Agency에는 네트워크 트래픽에서 봇 활동의 징후를 모니터링하는 분석가 팀이 있습니다. 분석가는 전문 지식을 사용하여 의심스러운 활동을 식별한 다음 자동화된 도구를 사용하여 위협을 확인하고 완화합니다.
- 금융 기관은 계정 탈취 및 자격 증명 스터핑과 같은 봇 기반 공격을 비롯한 사기 활동을 탐지하기 위해 인간 분석가에게 의존하는 경우가 많습니다.
- Wikimedia Foundation은 자동 및 수동 봇 탐지 기술의 조합을 사용하여 Wikipedia에서 봇을 식별하고 차단합니다. 인간 편집자는 편집 기록, IP 주소 및 사용자 행동 분석을 포함하여 다양한 전략을 사용하여 봇을 탐지하고 차단합니다.
인간 개입의 중요성과 인간과 봇 요청을 정확하게 구별하는 봇의 중요성을 알았으니 이제 샘플 데이터 포인트로 모델의 성능을 테스트해 보겠습니다. 주어진 요청이 인간 또는 봇에서 온 것인지 모델이 올바르게 예측하는지 검사합니다.
코드 예제
import pandas as pd
from sklearn.ensemble import RandomForestClassifier # Load trained model
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train) # Create new request data
new_data = { 'num_requests': [100], 'num_failed_requests': [10], 'num_successful_requests': [90], 'avg_response_time': [120]
} # Convert new data to pandas dataframe
new_df = pd.DataFrame(new_data) # Predict whether new data represents a bot or not
prediction = rfc.predict(new_df)
if prediction[0] == 1: print('This request data is likely from a bot.')
else: print('This request data is likely from a human.') 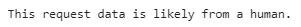
실제 사례 및 사례 연구
수많은 조직과 사이버 보안 회사가 봇 탐지에서 데이터 과학 기술의 중요성을 인식하고 이를 플랫폼에 구현했습니다. 몇 가지 실제 사례를 살펴보겠습니다.
- 소셜 미디어 네트워크: 소셜 미디어 플랫폼은 잘못된 정보를 퍼뜨리거나 여론을 조작하거나 스팸 활동에 참여하려는 봇의 표적이 되는 경우가 많습니다. 데이터 과학은 이러한 봇 활동을 식별하고 완화하는 데 중요한 역할을 합니다. 기계 학습 모델은 대량의 가짜 계정 생성, 자동화된 콘텐츠 게시 또는 조정된 네트워크 상호 작용과 같은 의심스러운 행동 패턴을 감지하기 위해 대량의 사용자 데이터에 대해 훈련됩니다.
- 전자상거래 사이트: 온라인 마켓플레이스는 경쟁 우위를 확보하거나 가격을 조작하기 위해 가격 정보를 추출하는 가격 스크래핑 봇과 같은 문제에 직면해 있습니다. 데이터 과학 기술은 브라우징 행동, IP 주소 및 구매 패턴을 분석하여 이러한 봇을 식별하고 차단할 수 있습니다. 기계 학습 알고리즘은 비정상적인 데이터 액세스 패턴을 인식하고 합법적인 사용자와 악의적인 봇을 구별할 수 있습니다.
- 금융 기관: 은행 및 금융기관은 계좌 탈취, 신원 도용, 사기 거래 등 봇에 의한 사기 행위의 주요 대상입니다. 데이터 과학은 의심스러운 행동을 식별하고 추가 조사를 위해 잠재적인 봇 기반 활동을 표시할 수 있는 사기 탐지 시스템을 구축하는 데 중요한 역할을 합니다. 트랜잭션 패턴, 사용자 행동 및 장치 정보를 분석하여 기계 학습 모델은 이상 징후를 감지하고 고객 계정을 보호할 수 있습니다.
봇 탐지의 미래

- 봇 공격의 복잡성: 봇은 점점 더 정교해지고 있어 기존 방법으로는 탐지하기가 더 어려워지고 있습니다.
- 기계 학습의 부상: ML은 봇 탐지에 효과적이지만 모델을 교육하려면 많은 양의 데이터와 전문 지식이 필요합니다. 이로 인해 소규모 조직에서는 구현하기가 어렵습니다.
- 정확성과 유용성의 균형: 봇 감지 도구는 정확성과 유용성 사이의 균형을 유지해야 합니다. 지나치게 복잡한 도구는 비전문가가 효과적으로 사용하기 어려울 수 있습니다.
봇 감지 기술의 향후 개발 가능성:
- 기계 학습의 발전: 머신 러닝 알고리즘은 계속해서 개선되어 봇을 보다 효과적으로 탐지할 것입니다.
- 행동 분석 사용 증가: 시간이 지남에 따라 사용자가 시스템과 상호 작용하는 방식을 살펴보면 봇을 감지하는 보다 일반적인 접근 방식이 될 수 있습니다.
- 자동화 활용 확대: 봇이 더욱 발전함에 따라 자동화된 시스템은 봇 공격을 감지하고 완화하는 데 점점 더 중요해질 것입니다.
봇 탐지에 대한 지속적인 연구의 중요성:
- 봇 공격이 계속 진화함에 따라 공격자보다 앞서 나가기 위해서는 지속적인 연구가 필요합니다.
- 연구원, 실무자 및 조직 간의 협업 및 정보 공유는 새로운 봇 위협을 파악하는 데 매우 중요합니다.
- 보다 접근하기 쉬운 봇 탐지 도구를 개발하면 모든 규모의 조직이 봇 공격으로부터 자신을 보호하는 데 도움이 됩니다.
결론
봇 감지는 인간 행동을 모방하는 자동화된 프로그램을 식별하고 완화하는 것을 목표로 하는 데이터 과학 및 사이버 보안의 중요한 측면입니다. 행동 분석, 장치 지문, CAPTCHA 및 기계 학습 알고리즘을 포함한 다양한 기술의 구현을 통해 데이터 과학자는 강력한 봇 탐지 시스템을 개발할 수 있습니다. 데이터 과학 기술은 확장성, 새로운 위협에 대한 적응성, 미묘한 패턴 감지를 가능하게 합니다. 그러나 훈련 데이터의 편향과 복잡한 모델의 해석 가능성과 같은 문제를 해결해야 합니다. 현장이 발전함에 따라 협업, 실시간 감지 및 고급 머신 러닝 기술은 봇 감지의 미래를 지속적으로 형성하여 궁극적으로 온라인 상호 작용을 보호하고 디지털 플랫폼에 대한 신뢰를 유지할 것입니다.
주요 요점
- 봇은 온라인에서 다양한 작업을 수행할 수 있는 자동화된 프로그램일 뿐입니다.
- 봇 탐지는 계정 탈취, 스팸 및 서비스 거부 공격을 포함할 수 있는 악의적인 봇 활동으로부터 보호하는 데 중요합니다.
- IP 기반 차단, 시그니처 기반 탐지, 기계 학습 등 다양한 봇 탐지 기술이 있습니다.
- 기계 학습은 봇 탐지를 위한 효과적인 방법이지만 구현하려면 많은 양의 데이터와 전문 지식이 필요합니다.
- 인간 전문가가 자동화 시스템에서 놓칠 수 있는 패턴과 동작을 식별할 수 있으므로 인간 참여도 봇 탐지에 중요합니다.
- 봇 감지의 미래에는 자동화 및 행동 분석에 중점을 둔 인간의 전문 지식과 기계 학습 도구의 조합이 포함될 가능성이 높습니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoAiStream. Web3 데이터 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 미래 만들기 w Adryenn Ashley. 여기에서 액세스하십시오.
- PREIPO®로 PRE-IPO 회사의 주식을 사고 팔 수 있습니다. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/05/guardians-of-the-internet-power-of-data-science-in-bot-detection/

