
작성자 별 이미지
데이터가 새로운 석유인 세상에서는 데이터 과학 경력의 미묘한 차이를 이해하는 것이 그 어느 때보다 중요합니다. 데이터를 좋아하는 사람이든 기회를 탐색하는 베테랑이든 관계없이 SQL을 사용하면 데이터 과학 취업 시장에 대한 통찰력을 얻을 수 있습니다.
나는 당신이 어느 것을 알고 싶어하기를 바랍니다 데이터 과학 직책 가장 매력적이거나 가장 많은 급여를 제공하는 회사입니다. 아니면 경험 수준이 어떻게 연결되는지 궁금할 수도 있습니다. 데이터 과학 평균 급여?
이 기사에서는 데이터 과학 구직 시장에 깊이 들어가면서 이러한 모든 질문과 그 이상을 다루었습니다. 시작하자!
이 기사에서 사용할 데이터 세트는 2021년부터 2023년까지 데이터 과학 분야의 급여 패턴을 밝히기 위해 설계되었습니다. 근무 이력, 직무, 회사 위치와 같은 요소를 조명함으로써 임금 분산에 대한 중요한 통찰력을 제공합니다. 부문.
이 기사에서는 다음 질문에 대한 답을 찾을 수 있습니다.
- 다양한 경험 수준에 따른 평균 급여는 어떻게 되나요?
- 데이터 과학에서 가장 일반적인 직위는 무엇입니까?
- 급여 분배는 회사 규모에 따라 어떻게 달라지나요?
- 데이터 과학 일자리는 주로 지리적으로 어디에 위치해 있나요?
- 데이터 과학에서 가장 높은 급여를 제공하는 직위는 무엇입니까?
이 데이터는 다음에서 다운로드할 수 있습니다. 카글.
1. 다양한 경험 수준에 따른 평균 급여는 어떻게 되나요?
이 SQL 쿼리에서는 다양한 경험 수준에 대한 평균 급여를 찾습니다. GROUP BY 절은 경험 수준별로 데이터를 그룹화하고 AVG 함수는 각 그룹의 평균 급여를 계산합니다.
이는 현장 경험이 수익 잠재력에 어떻게 영향을 미치는지 이해하는 데 도움이 되며, 이는 계획을 세울 때 반드시 필요합니다. 데이터 과학 분야의 진로. 코드를 보자.
SELECT experience_level, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY experience_level;
이제 Python을 사용하여 이 출력을 시각화해 보겠습니다.
다음은 코드입니다.
# Import required libraries for plotting
import matplotlib.pyplot as plt
import seaborn as sns
# Set up the style for the graphs
sns.set(style="whitegrid") # Initialize the list for storing graphs
graphs = [] plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x))
plt.title('Average Salary by Experience Level')
plt.xlabel('Experience Level')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
이제 초급 및 경력 연봉과 중급 및 고위급 급여를 비교해 보겠습니다.
초급 및 경험자부터 시작하겠습니다. 코드는 다음과 같습니다.
# Filter the data for Entry_Level and Experienced levels
entry_experienced = df[df['experience_level'].isin(['Entry_Level', 'Experienced'])] # Filter the data for Mid-Level and Senior levels
mid_senior = df[df['experience_level'].isin(['Mid-Level', 'Senior'])] # Plotting the Entry_Level vs Experienced graph
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=entry_experienced, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('Average Salary: Entry_Level vs Experienced')
plt.xlabel('Experience Level')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
여기 그래프가 있습니다.
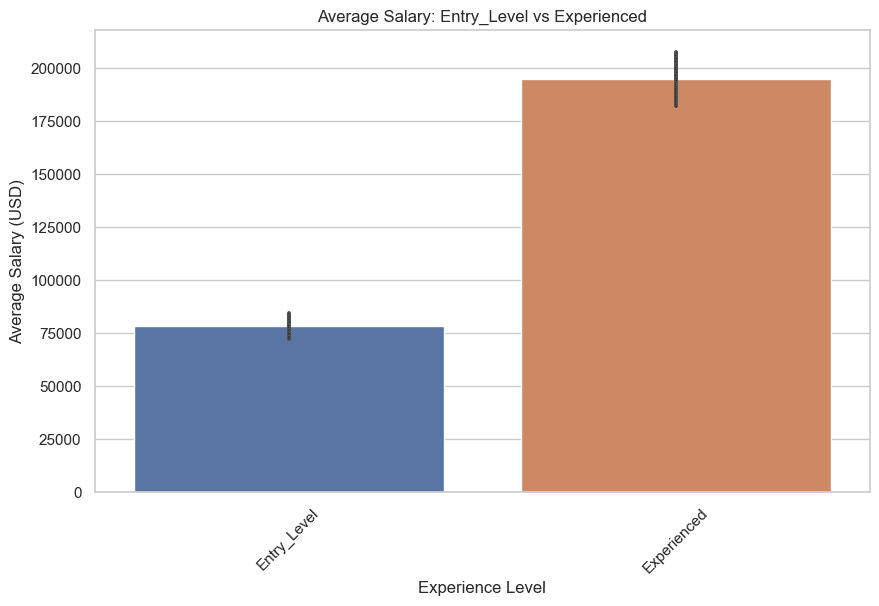
이제 중급&고급을 그려봅시다. 코드는 다음과 같습니다.
# Plotting the Mid-Level vs Senior graph
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=mid_senior, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('Average Salary: Mid-Level vs Senior')
plt.xlabel('Experience Level')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
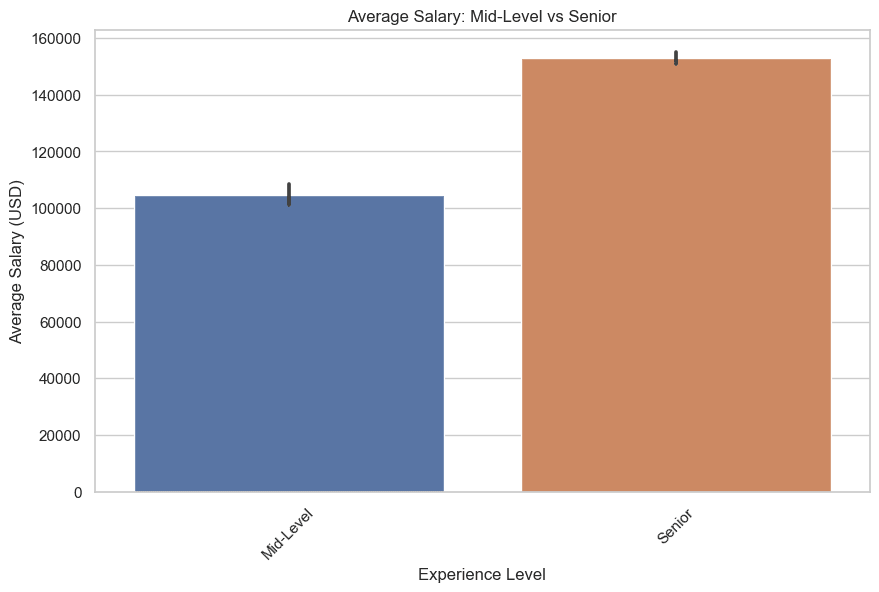
2. 데이터 과학에서 가장 일반적인 직위는 무엇입니까?
여기에서는 데이터 과학 분야에서 가장 일반적인 직위 상위 10개를 추출합니다. COUNT 함수는 각 직위의 출현 횟수를 세어, 가장 많이 사용되는 직위가 맨 위에 오도록 내림차순으로 결과를 정렬합니다.
이 정보는 취업 시장 수요에 대한 정보를 제공하여 목표로 삼을 수 있는 잠재적인 역할을 식별하는 데 도움을 줍니다. 코드를 보자.
SELECT job_title, COUNT(*) AS job_count
FROM salary_data
GROUP BY job_title
ORDER BY job_count DESC
LIMIT 10;
이제 Python을 사용하여 이 쿼리를 시각화할 차례입니다.
다음은 코드입니다.
plt.figure(figsize=(12, 8))
sns.countplot(y='job_title', data=df, order=df['job_title'].value_counts().index[:10])
plt.title('Most Common Job Titles in Data Science')
plt.xlabel('Job Count')
plt.ylabel('Job Title')
graphs.append(plt.gcf())
plt.show()
그래프를 보겠습니다.
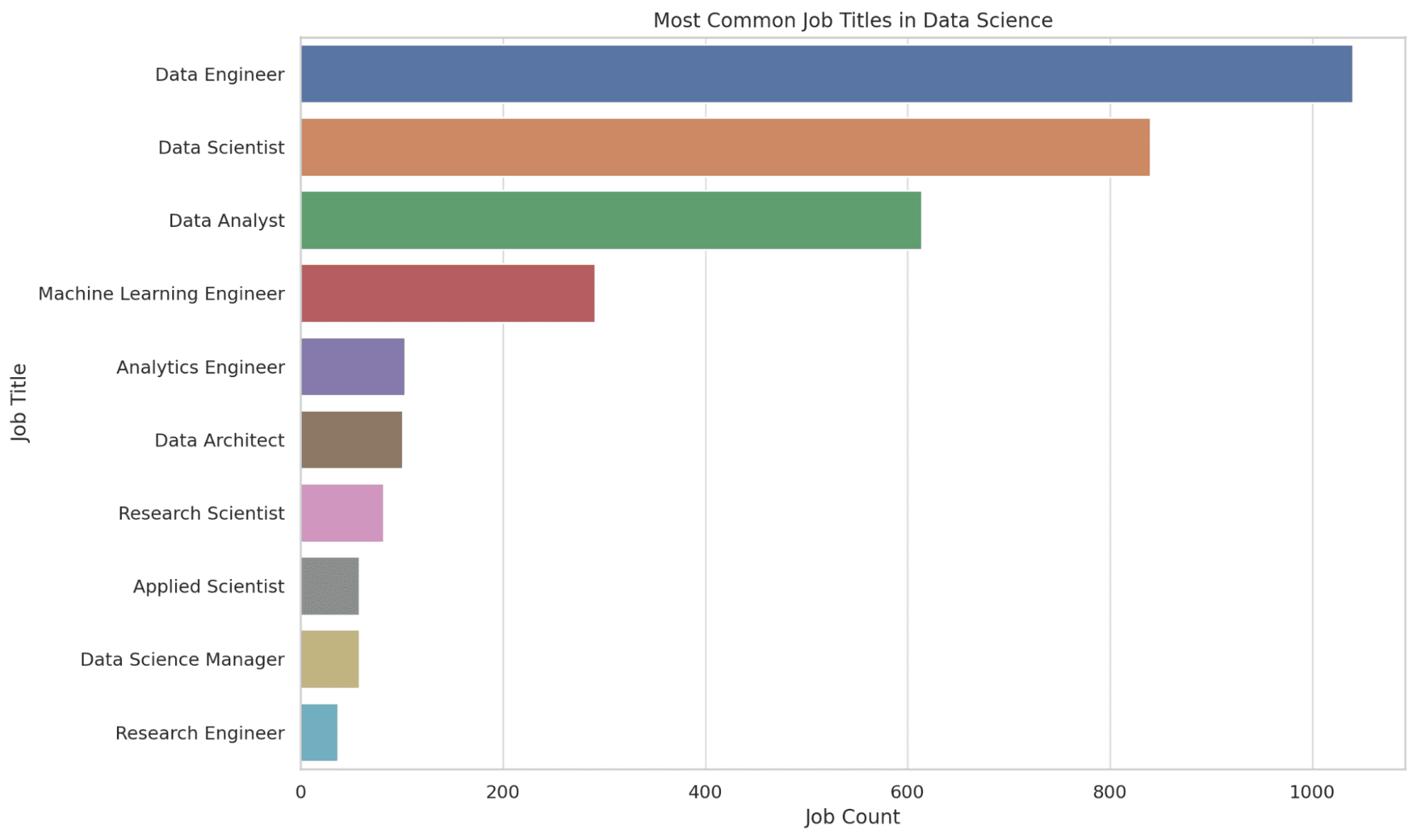
3. 회사 규모에 따라 급여 분배가 어떻게 달라지나요?
이 쿼리에서는 각 회사 규모 그룹에 대한 평균, 최소 및 최대 급여를 추출합니다. AVG, MIN, MAX 등의 집계 함수를 사용하면 회사 규모와 관련된 급여 환경에 대한 포괄적인 보기를 제공하는 데 도움이 됩니다.
이 데이터는 가입하려는 회사의 규모에 따라 기대할 수 있는 잠재적 수입을 이해하는 데 도움이 되므로 필수적입니다. 코드를 살펴보겠습니다.
SELECT company_size, AVG(salary_in_usd) AS avg_salary, MIN(salary_in_usd) AS min_salary, MAX(salary_in_usd) AS max_salary
FROM salary_data
GROUP BY company_size;
이제 Python을 사용하여 이 쿼리를 시각화해 보겠습니다.
다음은 코드입니다.
plt.figure(figsize=(12, 8))
sns.barplot(x='company_size', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0, order=['Small', 'Medium', 'Large'])
plt.title('Salary Distribution by Company Size')
plt.xlabel('Company Size')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
다음은 출력입니다.
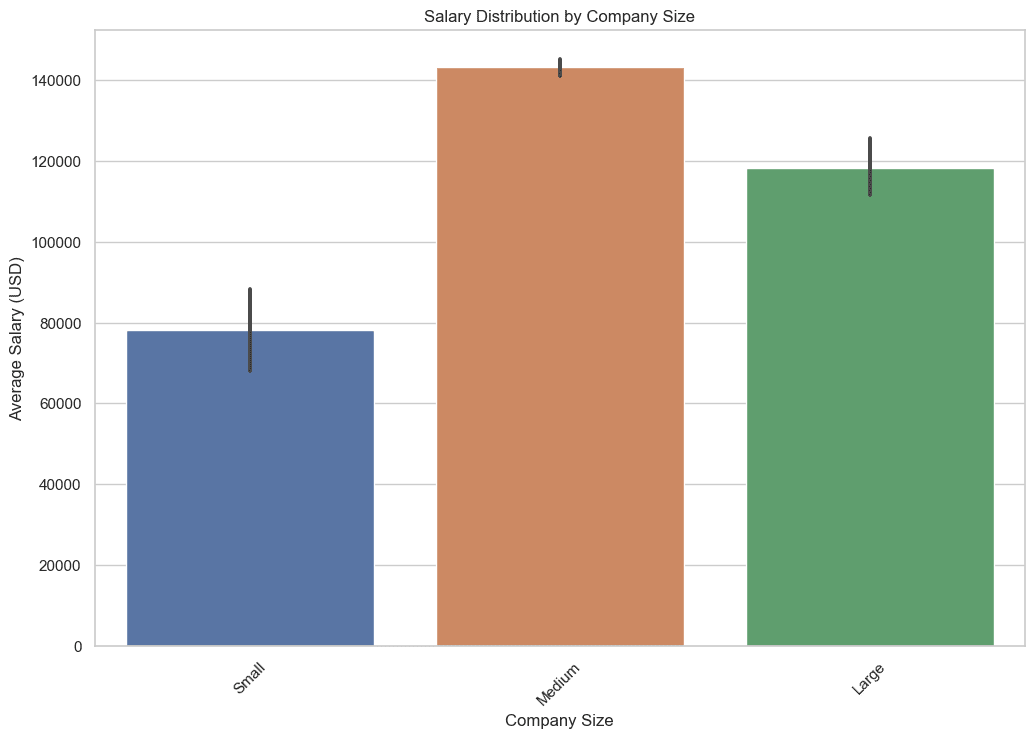
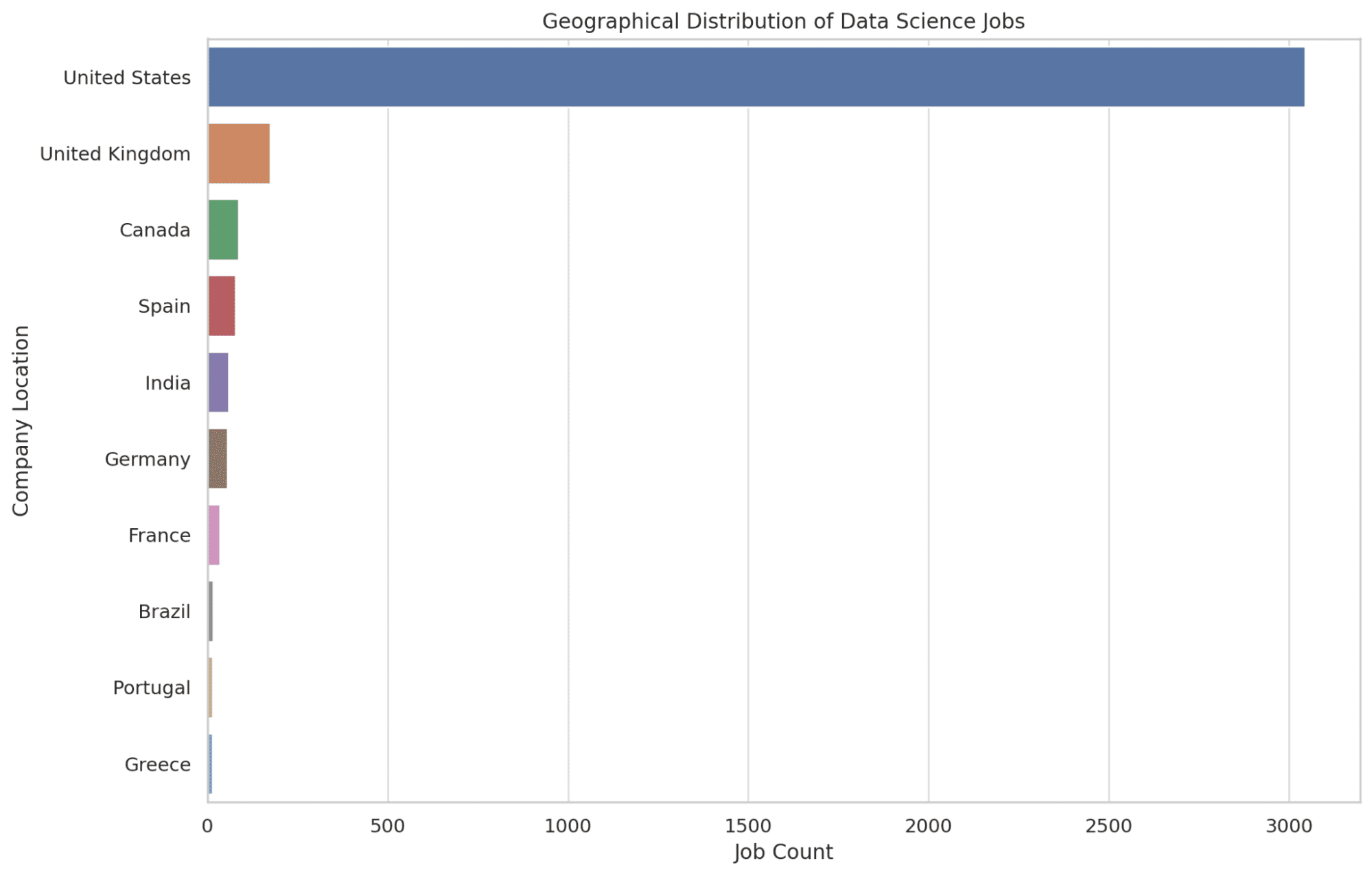
4. 데이터 과학 일자리는 주로 지리적으로 어디에 위치해 있나요?
여기서는 데이터 과학 취업 기회가 가장 많은 상위 10개 위치를 정확히 찾아보겠습니다. 우리는 COUNT 함수를 사용하여 각 위치의 채용 공고 수를 결정하고 기회가 가장 많은 영역을 강조하기 위해 내림차순으로 정렬합니다.
이 정보가 있으면 독자는 데이터 과학 역할의 허브인 지리적 영역에 대한 지식을 얻을 수 있어 잠재적인 재배치 결정에 도움이 됩니다. 코드를 보자.
SELECT company_location, COUNT(*) AS job_count
FROM salary_data
GROUP BY company_location
ORDER BY job_count DESC
LIMIT 10;
이제 Python을 사용하여 위 코드의 그래프를 만들어 보겠습니다.
plt.figure(figsize=(12, 8))
sns.countplot(y='company_location', data=df, order=df['company_location'].value_counts().index[:10])
plt.title('Geographical Distribution of Data Science Jobs')
plt.xlabel('Job Count')
plt.ylabel('Company Location')
graphs.append(plt.gcf())
plt.show()
아래 그래프를 살펴보겠습니다.
5. 데이터 과학 분야에서 가장 높은 급여를 제공하는 직위는 무엇입니까?
여기에서는 데이터 과학 부문에서 가장 높은 연봉을 받는 직위 상위 10개를 식별합니다. AVG를 사용하여 각 직위의 평균 급여를 계산하고 평균 급여를 기준으로 내림차순으로 정렬하여 가장 수익성이 높은 직위를 강조합니다.
이 데이터를 보면 경력 여정에서 열망을 가질 수 있습니다. 독자가 이 데이터에 대한 Python 시각화를 생성할 수 있는 방법을 이해해 보겠습니다.
SELECT job_title, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY job_title
ORDER BY avg_salary DESC
LIMIT 10;
다음은 출력입니다.
(여기서는 위에 사진 4장을 추가하고 썸네일용으로 한 장 남았기 때문에 사진을 사용할 수 없습니다. 출력을 시연하기 위해 아래와 같은 표를 사용할 기회가 있습니까?)
| 계급 | 직위 | 평균 급여(USD) |
| 1 | 데이터 과학 기술 리드 | 375,000.00 |
| 2 | 클라우드 데이터 설계자 | 250,000.00 |
| 3 | 데이터 리드 | 212,500.00 |
| 4 | 데이터 분석 리드 | 211,254.50 |
| 5 | 주요 데이터 과학자 | 198,171.13 |
| 6 | 데이터 과학 이사 | 195,140.73 |
| 7 | 수석 데이터 엔지니어 | 192,500.00 |
| 8 | 기계 학습 소프트웨어 엔지니어 | 192,420.00 |
| 9 | 데이터 과학 관리자 | 191,278.78 |
| 10 | 응용 과학자 | 190,264.48 |
이번에는 직접 그래프를 만들어 보겠습니다.
방문 꿀팁: ChatGPT에서 다음 프롬프트를 사용하여 이 그래프의 Python 코드를 생성할 수 있습니다.
<SQL Query here> Create a Python graph to visualize the top 10 highest-paying job titles in Data Science, similar to the insights gathered from the given SQL query above.데이터 과학 경력 세계의 다양한 영역을 통과하는 여정을 마무리하면서 SQL이 신뢰할 수 있는 가이드가 되어 귀하의 경력 결정을 지원하는 보석 같은 통찰력을 발굴하는 데 도움이 되기를 바랍니다.
이제 진로를 계획하는 것뿐만 아니라 SQL을 사용하여 원시 데이터를 강력한 내러티브로 만드는 데 더 많은 준비가 되기를 바랍니다. 따라서 데이터를 나침반으로 삼고 SQL을 지도력으로 삼아 기회로 가득 찬 미래를 향해 나아가십시오!
읽어 주셔서 감사합니다!
네이트 로시디 데이터 과학자이자 제품 전략 분야의 전문가입니다. 그는 분석을 가르치는 겸임 교수이기도 하며, 스트라타스크래치, 데이터 사이언티스트가 상위 기업의 실제 인터뷰 질문을 통해 인터뷰를 준비하는 데 도움이 되는 플랫폼입니다. 그와 연결 트위터: StrataScratch or 링크드인.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/using-sql-to-understand-data-science-career-trends?utm_source=rss&utm_medium=rss&utm_campaign=using-sql-to-understand-data-science-career-trends

