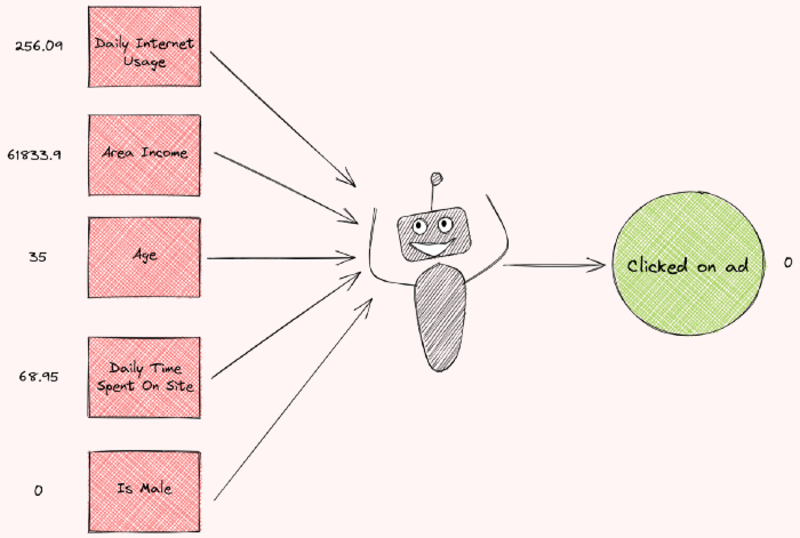
특정 사람이 광고를 클릭했는지 여부를 예측하기 위해 머신 러닝 모델을 훈련한다고 상상해 보십시오. 사람에 대한 정보를 받은 후 모델은 사람이 광고를 클릭하지 않을 것이라고 예측합니다.
작성자 별 이미지
그런데 왜 모델이 그것을 예측합니까? 각 기능이 예측에 얼마나 기여합니까? 아래와 같이 각 기능이 예측에 얼마나 기여하는지 나타내는 플롯을 볼 수 있다면 좋지 않을까요?
작성자 별 이미지
바로 그때 Shapley 가치가 도움이 됩니다.
Shapley 값은 연합에서 일하는 행위자에게 이득과 비용을 모두 공정하게 분배하는 것과 관련된 게임 이론에서 사용되는 방법입니다.
각 행위자는 연합에 다르게 기여하기 때문에 Shapley 값은 각 행위자가 그들이 기여한 정도에 따라 공평한 몫을 얻습니다..

작성자 별 이미지
간단한 예
Shapley 값은 그룹의 각 작업자/기능의 기여도에 의문을 제기하는 광범위한 문제에 사용됩니다. Shapley 가치가 작동하는 방식을 이해하기 위해 귀사에서 다양한 광고 전략 조합을 테스트하는 A/B 테스트를 방금 수행했다고 가정해 보겠습니다.
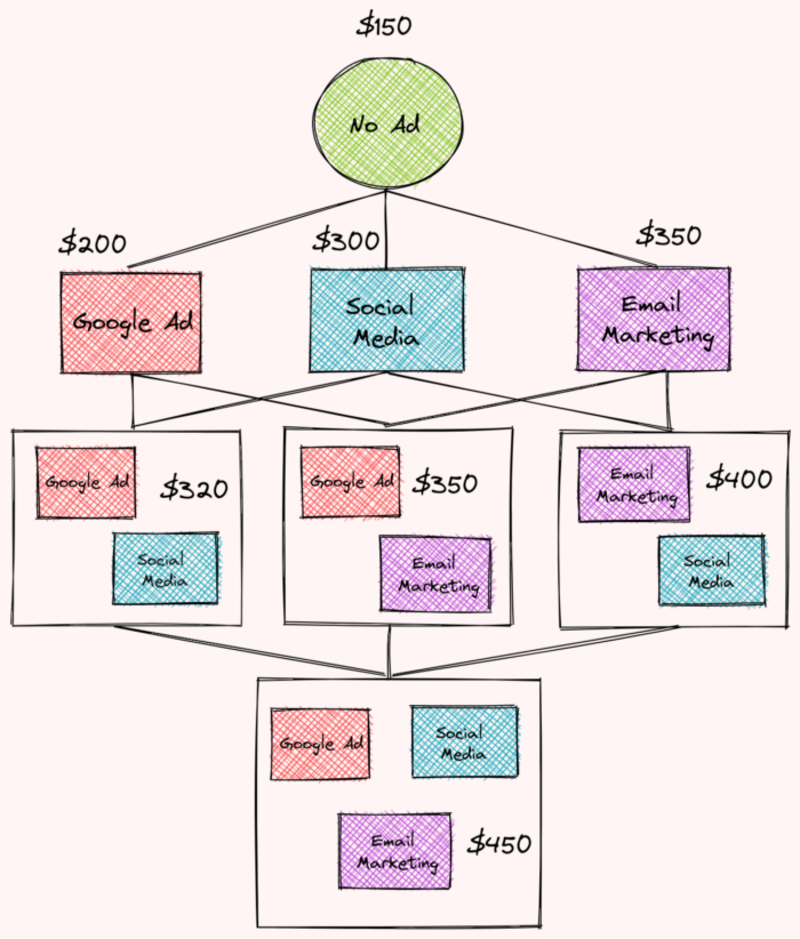
특정 월의 각 전략에 대한 수익은 다음과 같습니다.
- 광고 없음: $150
- 소셜 미디어: $300
- 구글 광고: $200
- 이메일 마케팅: $350
- 소셜 미디어 및 Google 광고 $320
- 소셜 미디어 및 이메일 마케팅: $400
- Google 광고 및 이메일 마케팅: $350
- 이메일 마케팅, Google 광고 및 소셜 미디어: $450
작성자 별 이미지
300개의 광고를 사용하는 것과 광고를 사용하지 않는 것 사이의 수익 차이는 $XNUMX입니다. 각 광고가 이 차이에 얼마나 기여합니까?

작성자 별 이미지
각 광고 유형에 대한 Shapley 값을 계산하여 알아낼 수 있습니다. 이 문서는 Shap 값을 계산하는 훌륭한 방법을 제공합니다. 여기에 요약하겠습니다.
회사 수익에 대한 Google 광고의 총 기여도를 계산하는 것으로 시작합니다. Google 광고의 총 기여도는 다음 공식으로 계산할 수 있습니다.

작성자 별 이미지
구글광고의 한계기여도와 가중치를 알아보자.
Google 광고의 한계 기여도 찾기
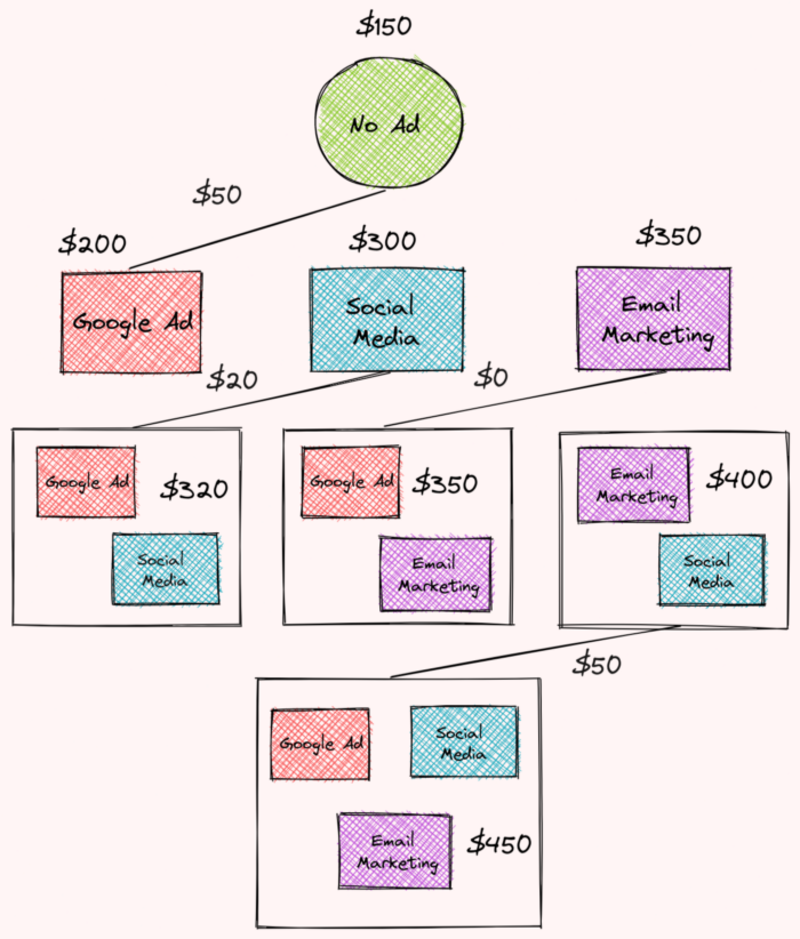
먼저 다음 그룹에 대한 Google 광고의 한계 기여도를 찾습니다.
- 광고 없음
- Google 광고 + 소셜 미디어
- 구글 광고 + 이메일 마케팅
- Google 광고 + 이메일 마케팅 + 소셜 미디어
작성자 별 이미지
광고 없음에 대한 Google 광고의 한계 기여도는 다음과 같습니다.

작성자 별 이미지
Google 광고 및 소셜 미디어 그룹에 대한 Google 광고의 한계 기여도는 다음과 같습니다.

작성자 별 이미지
Google 광고 및 이메일 마케팅 그룹에 대한 Google 광고의 한계 기여도는 다음과 같습니다.

작성자 별 이미지
Google 광고, 이메일 마케팅 및 소셜 미디어 그룹에 대한 Google 광고의 한계 기여도는 다음과 같습니다.

작성자 별 이미지
가중치 찾기
가중치를 찾기 위해 다양한 광고 전략의 조합을 아래와 같이 여러 수준으로 구성합니다. 각 수준은 각 조합의 광고 전략 수에 해당합니다.
그런 다음 각 수준의 가장자리 수에 따라 가중치를 할당합니다. 우리는 그것을 보았다:
- 첫 번째 수준에는 다음이 포함됩니다. 3 개의 가장자리 따라서 각 가장자리의 가중치는 1/3
- 두 번째 수준에는 다음이 포함됩니다. 6 개의 가장자리 따라서 각 가장자리의 가중치는 1/6
- 세 번째 수준에는 다음이 포함됩니다. 3 개의 가장자리 따라서 각 가장자리의 가중치는 1/3
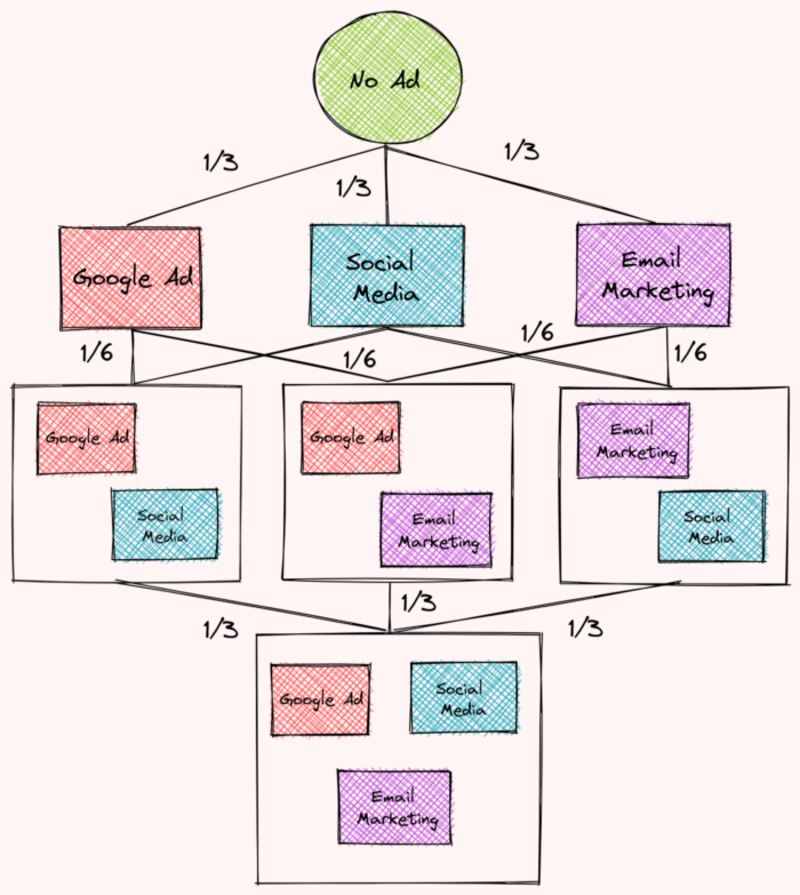
작성자 별 이미지
Google 광고의 총 기여도 찾기
이제 앞에서 구한 가중치와 한계 기여도를 기반으로 Google 광고의 총 기여도를 찾을 준비가 되었습니다!
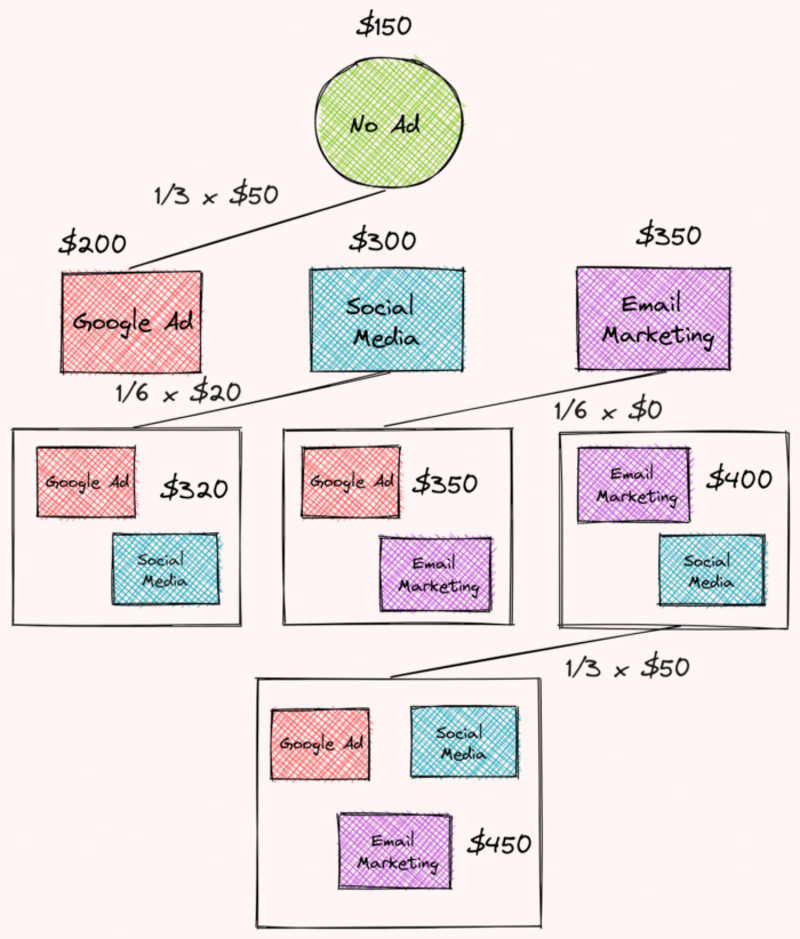
작성자 별 이미지
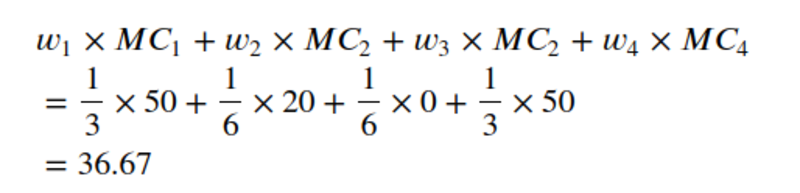
작성자 별 이미지
시원한! 따라서 Google 광고는 36.67가지 광고 전략을 사용하는 것과 광고를 사용하지 않는 것 사이의 총 수익 차이에 $3를 기여합니다. 36.67은 Google 광고의 Shapey 값입니다.
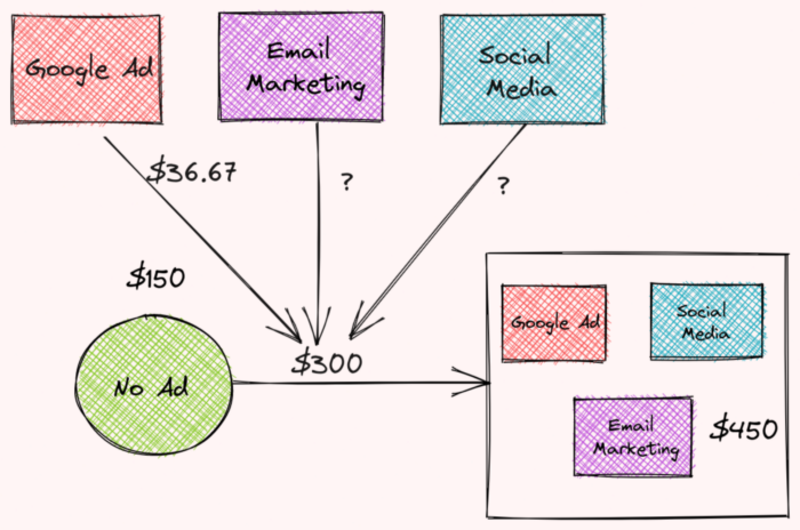
작성자 별 이미지
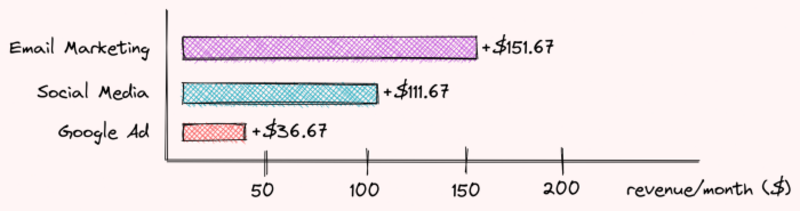
두 가지 다른 광고 전략에 대해 위의 단계를 반복하면 다음을 확인할 수 있습니다.
- 이메일 마케팅 기여 $151.67
- 소셜 미디어 기부 $111.67
- Google 광고는 $36.67를 기부합니다.
작성자 별 이미지
그들은 함께 300가지 유형의 광고를 사용하는 것과 광고를 사용하지 않는 것의 차이에 $3를 기부합니다! 꽤 멋지죠?
이제 Shapley 값을 이해했으므로 이를 사용하여 기계 학습 모델을 해석하는 방법을 살펴보겠습니다.
P Shapley 값을 사용하여 기계 학습 모델의 출력을 설명하는 Python 라이브러리입니다.
SHAP를 설치하려면 다음을 입력하십시오.
pip install shap
모델 교육
SHAP의 작동 방식을 이해하기 위해 광고 데이터세트:
사용자에 대한 일부 정보를 기반으로 사용자가 광고를 클릭했는지 여부를 예측하는 기계 학습 모델을 구축할 것입니다.
우리는 팻시 DataFrame을 기능 배열과 대상 값 배열로 변환하려면 다음을 수행하십시오.
데이터를 학습 세트와 테스트 세트로 분할합니다.
다음으로 XGBoost를 사용하여 모델을 구축하고 예측합니다.
모델의 성능을 확인하기 위해 F1 점수를 사용합니다.
0.9619047619047619
꽤 좋아요!
모델 해석
이 모델은 사용자가 광고를 클릭했는지 여부를 잘 예측했습니다. 그런데 어떻게 그런 예측이 나왔을까요? 각 기능이 최종 예측과 평균 예측 간의 차이에 얼마나 기여했습니까?
이 문제는 기사 시작 부분에서 다룬 문제와 매우 유사합니다.
그렇기 때문에 각 기능의 Shapley 값을 찾는 것이 기여도를 결정하는 데 도움이 될 수 있습니다. 기능 i의 중요도를 얻는 단계는 이전과 유사합니다. 여기서 i는 기능의 인덱스입니다.
- 기능 i를 포함하지 않는 모든 하위 집합 가져오기
- 이러한 각 하위 집합에 대한 기능 i의 한계 기여도를 찾습니다.
- 기능 i의 기여도를 계산하기 위해 모든 한계 기여도를 집계합니다.
SHAP를 사용하여 Shapley 값을 찾으려면 훈련된 모델을 shap.Explainer :
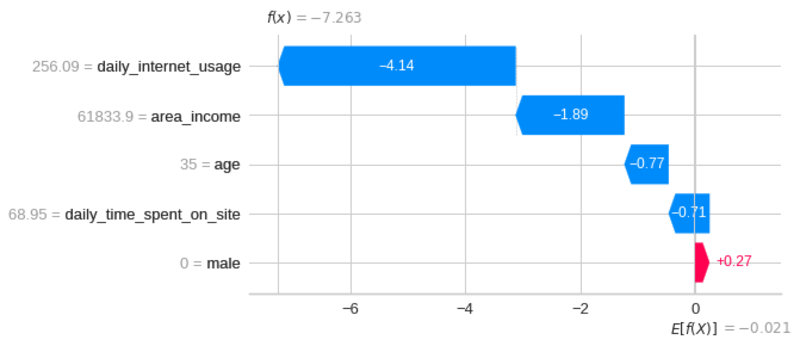
첫 번째 예측의 설명을 시각화합니다.
작성자 별 이미지
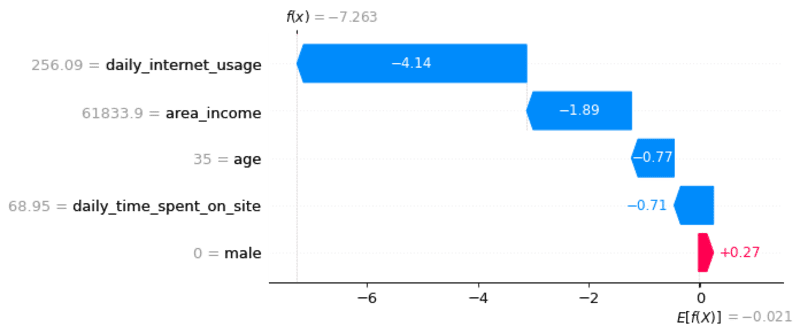
아하! 이제 우리는 첫 번째 예측에 대한 각 기능의 기여도를 알고 있습니다. 위의 그래프에 대한 설명:

작성자 별 이미지
- 파란색 막대는 특정 기능이 예측 값을 얼마나 감소시키는지를 보여줍니다.
- 빨간색 막대는 특정 기능이 예측 값을 얼마나 증가시키는지 보여줍니다.
- 음수 값은 사용자가 광고를 클릭한 확률이 0.5 미만임을 의미합니다.
이러한 각 하위 집합에 대해 SHAP는 기능을 제거한 다음 모델을 재교육하지 않고 해당 기능을 해당 기능의 평균 값으로 대체한 다음 예측을 생성합니다.
총 기여도는 예측과 평균 예측의 차이와 같을 것으로 예상해야 합니다. 다음을 확인하겠습니다.
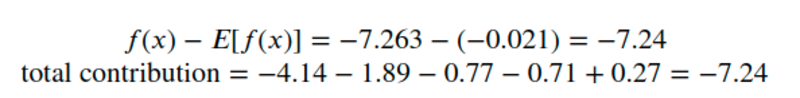
작성자 별 이미지
시원한! 그들은 동등합니다.
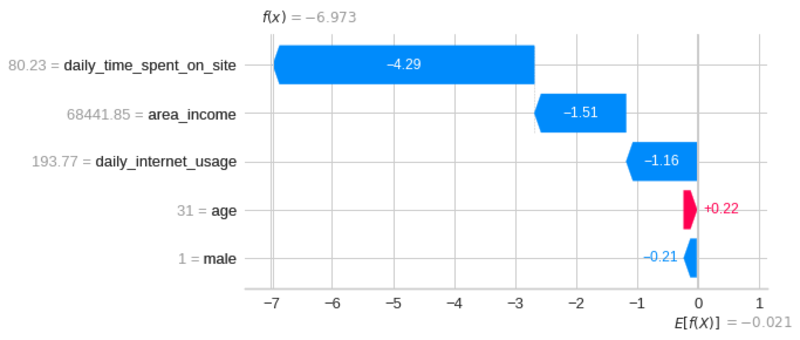
두 번째 예측의 설명을 시각화합니다.
작성자 별 이미지
각각의 개별 인스턴스를 보는 대신 SHAP 요약 플롯을 사용하여 여러 인스턴스에 걸쳐 이러한 기능의 전반적인 영향을 시각화할 수 있습니다.
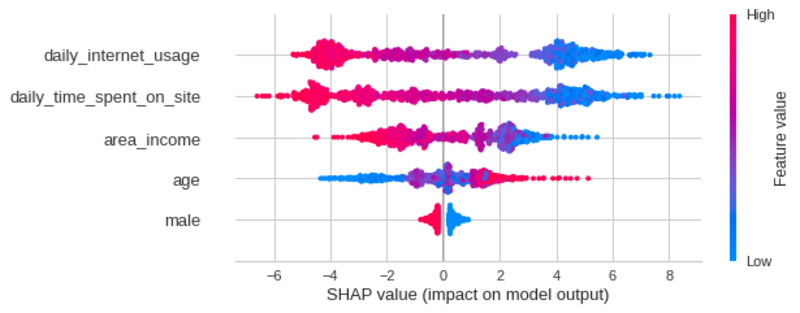
작성자 별 이미지
SHAP 요약 플롯은 가장 중요한 기능과 데이터 세트에 대한 효과 범위를 알려줍니다.
위의 플롯에서 모델의 예측에 대한 몇 가지 흥미로운 통찰력을 얻을 수 있습니다.
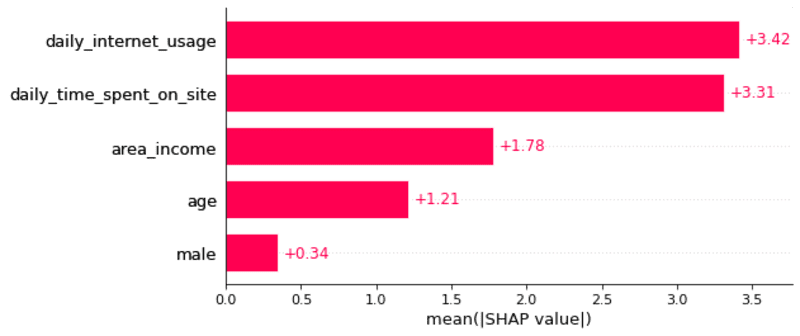
- 사용자의 일일 인터넷 사용은 사용자가 광고를 클릭했는지 여부에 가장 큰 영향을 미칩니다.
- 으로 매일 인터넷 사용 증가, 사용자는 덜 광고를 클릭하려면.
- 으로 사이트에서 보내는 일일 시간이 증가하고, 사용자는 덜 광고를 클릭하려면.
- 으로 지역 소득이 증가하고, 사용자는 덜 광고를 클릭하려면.
- 나이로 증가, 사용자는 가능성 광고를 클릭하려면.
- 사용자가 남성, 해당 사용자는 덜 광고를 클릭하려면.
SHAP 바 플롯을 사용하여 전역 기능 중요도 플롯을 얻을 수도 있습니다.
작성자 별 이미지
SHAP 종속성 산점도를 사용하여 모델이 만든 모든 예측에 대한 단일 기능의 영향을 관찰할 수 있습니다.
매일 인터넷 사용
일일 인터넷 사용 기능의 산점도:
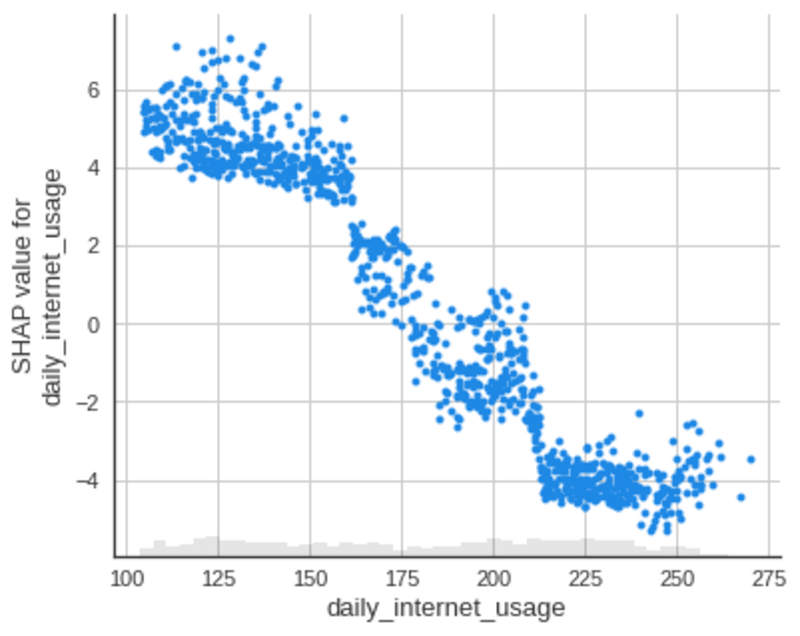
작성자 별 이미지
위의 도표에서 일일 인터넷 사용량이 증가함에 따라 일일 인터넷 사용량에 대한 SHAP 값이 감소하는 것을 볼 수 있습니다. 이것은 이전 플롯에서 본 것을 확인합니다.
또한 추가를 통해 동일한 플롯의 다른 기능과 일일 인터넷 사용 기능 간의 상호 작용을 관찰할 수 있습니다. color=shap_values .
산점도는 매일 사이트에서 보내는 시간인 일일 인터넷 사용과 가장 강한 상호 작용이 있는 기능 열을 선택하려고 시도합니다.
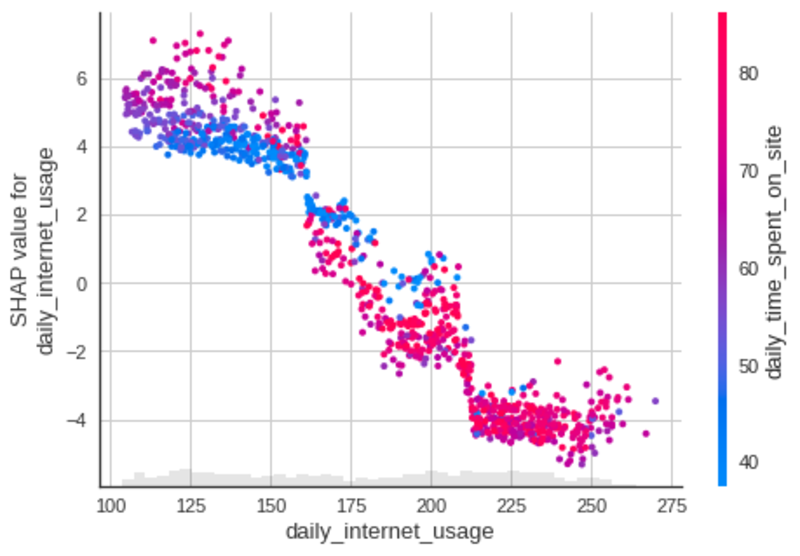
작성자 별 이미지
시원한! 위 도표에서 하루에 150분 동안 인터넷을 사용하고 하루에 웹사이트에서 적은 시간을 보내는 사람이 광고를 클릭할 가능성이 더 높다는 것을 알 수 있습니다.
다른 기능의 산점도를 살펴보겠습니다.
사이트에서 보낸 일일 시간
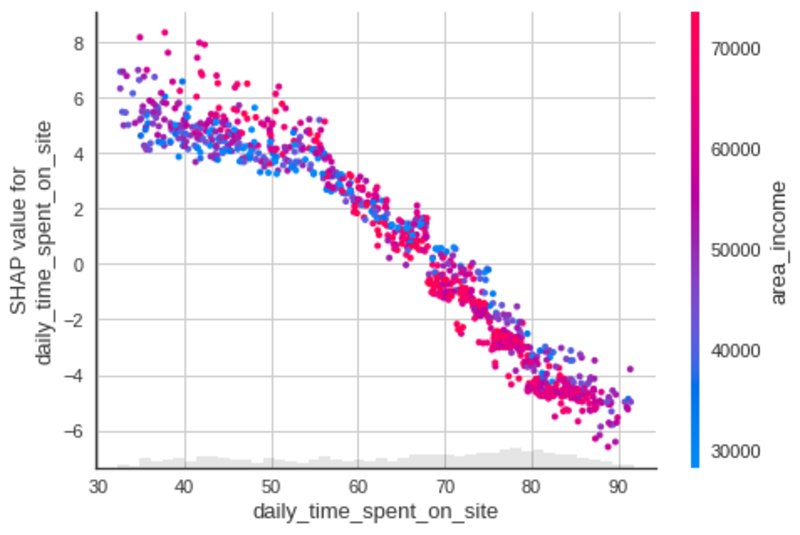
작성자 별 이미지
지역 소득
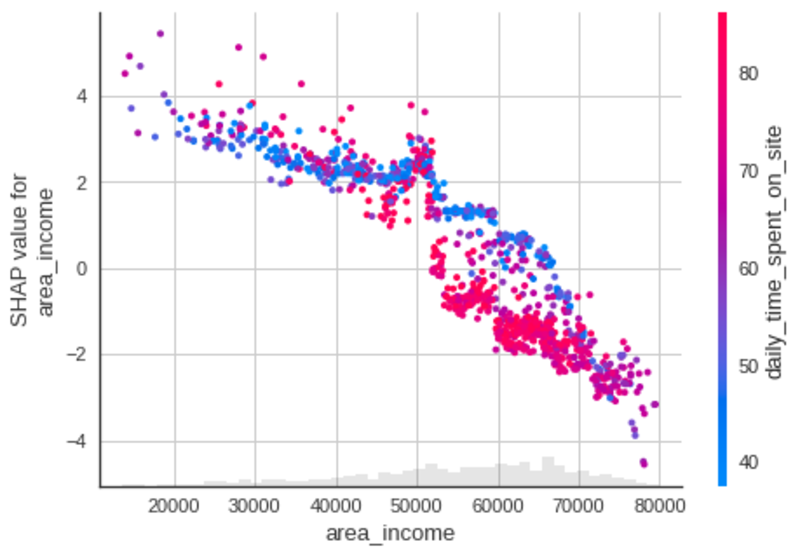
작성자 별 이미지
연령
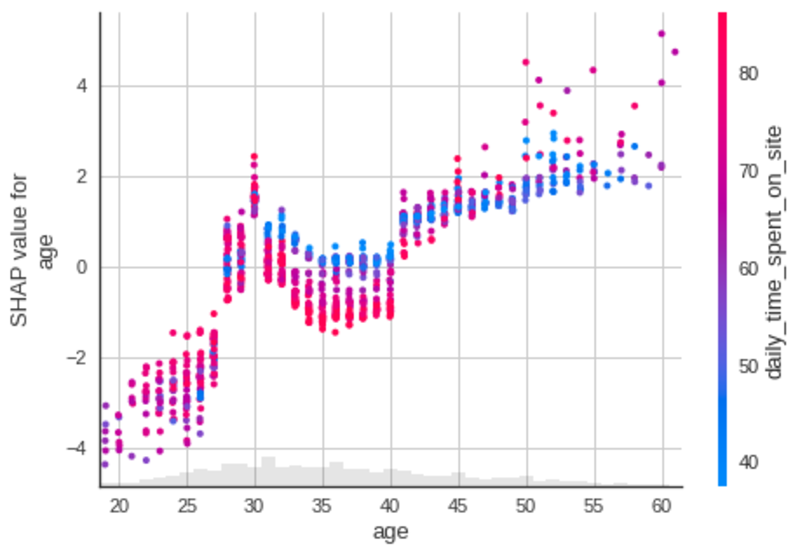
작성자 별 이미지
성별
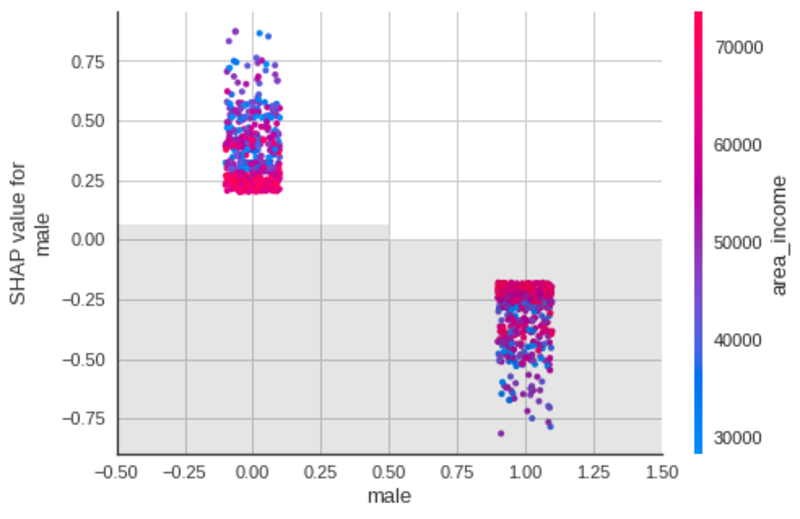
작성자 별 이미지
의 행렬도 관찰할 수 있습니다. 기능 간의 상호 작용 SHAP 상호 작용 값 요약 플롯을 사용합니다. 이 그림에서 주효과는 대각선에 있고 교호작용 효과는 대각선에 없습니다.
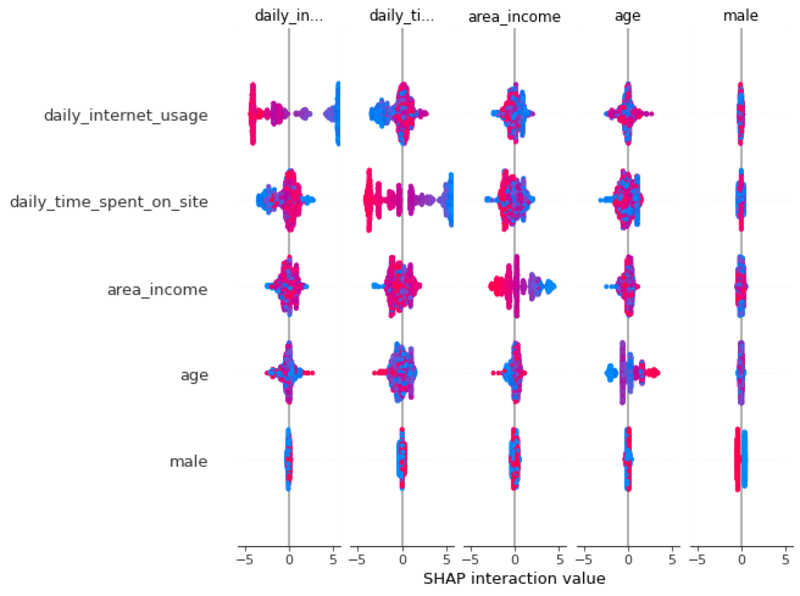
작성자 별 이미지
정말 멋진!
축하합니다! 방금 Shapey 가치와 이를 사용하여 기계 학습 모델을 해석하는 방법에 대해 배웠습니다. 이 기사가 Python을 사용하여 자신의 기계 학습 모델을 해석하는 데 필요한 필수 지식을 제공하기를 바랍니다.
나 체크 아웃하는 것이 좋습니다. SHAP 문서 SHAP의 다른 응용 프로그램에 대해 자세히 알아보십시오.
에서 소스 코드로 자유롭게 플레이하십시오. 이 대화형 노트북 또는 내 포크 저장소.
참조
마잔티, S. (2021년 21월 XNUMX일). SHAP는 누군가가 나에게 설명했으면 하는 방식으로 설명했습니다.. 중간. 23년 2021월 XNUMX일에 검색함 https://towardsdatascience.com/shap-explained-the-way-i-wish-someone-explained-it-to-me-ab81cc69ef30.
쿠옌 트란 다작 데이터 과학 작가이며 코드 및 기사와 함께 유용한 데이터 과학 주제의 인상적인 컬렉션. Khuyne은 현재 2022년 XNUMX월 이후 Bay Area에서 기계 학습 엔지니어 역할, 데이터 과학자 역할 또는 개발자 지지자 역할을 찾고 있으므로 그녀의 기술을 갖춘 사람을 찾고 있다면 연락해 주세요.
실물. 허가를 받아 다시 게시했습니다.
- 코인스마트. 유럽 최고의 비트코인 및 암호화폐 거래소.Click Here
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/2022/11/shap-explain-machine-learning-model-python.html?utm_source=rss&utm_medium=rss&utm_campaign=shap-explain-any-machine-learning-model-in-python

