개요
컴퓨터 비전이라는 큰 그림에서 이미지에 라벨을 붙이거나 사진에 주석을 다는 것은 어려운 일이었습니다. 우리의 탐구는 정확한 주석과 효율적인 모델 구축을 결합한 강력한 듀오인 LabelImg와 Detectron의 팀워크를 탐구합니다. 사용하기 쉽고 정확한 LabelImg는 신중한 주석을 제공하여 명확한 개체 감지를 위한 견고한 기반을 마련합니다.
LabelImg를 탐색하고 경계 상자 그리기에 능숙해지면서 원활하게 Detectron으로 이동합니다. 이 강력한 프레임워크는 표시된 데이터를 구성하여 고급 모델을 교육하는 데 도움이 됩니다. LabelImg와 Detectron을 함께 사용하면 초보자든 전문가든 누구나 쉽게 객체를 감지할 수 있습니다. 표시된 각 이미지는 시각적 정보의 모든 힘을 활용하는 데 도움이 됩니다.
학습 목표
- LabelImg 시작하기.
- 환경설정 및 LabelImg 설치.
- LabelImg 및 해당 기능 이해.
- 객체 감지를 위해 VOC 또는 Pascal 데이터를 COCO 형식으로 변환합니다.
이 기사는 데이터 과학 Blogathon.
차례
순서도

환경 설정
1. 가상 환경 생성:
conda create -p ./venv python=3.8 -y이 명령은 Python 버전 3.8을 사용하여 "venv"라는 가상 환경을 생성합니다.
2. 가상 환경을 활성화합니다:
conda activate venvLabelImg 설치를 격리하려면 가상 환경을 활성화하세요.
LabelImg 설치 및 사용
1. LabelImg를 설치합니다.
pip install labelImg활성화된 가상 환경 내에 LabelImg를 설치합니다.
2. LabelImg를 실행합니다:
labelImg
문제 해결: 스크립트 실행 중 오류가 발생하는 경우
스크립트 실행 중 오류가 발생하는 경우를 대비해 가상 환경(venv)이 포함된 zip 아카이브를 준비했습니다.
1. Zip 아카이브를 다운로드합니다:
- 다음에서 venv.zip 아카이브를 다운로드하세요. (링크)
2. LabelImg 폴더를 생성합니다:
- 로컬 컴퓨터에 LabelImg라는 새 폴더를 만듭니다.
3. venv 폴더를 추출합니다:
- venv.zip 아카이브의 내용을 LabelImg 폴더에 추출합니다.
4. 가상 환경을 활성화합니다:
- 명령 프롬프트나 터미널을 엽니다.
- LabelImg 폴더로 이동합니다.
- 다음 명령을 실행하여 가상 환경을 활성화합니다.
conda activate ./venv이 프로세스를 통해 LabelImg와 함께 사용할 수 있는 사전 구성된 가상 환경이 준비되었습니다. 제공된 zip 아카이브는 필요한 종속성을 캡슐화하여 잠재적인 설치에 대한 걱정 없이 보다 원활한 환경을 제공합니다.
이제 활성화된 가상 환경 내에서 LabelImg를 설치하고 사용하기 위한 이전 단계를 진행하세요.
LabelImg를 사용한 주석 작업 흐름
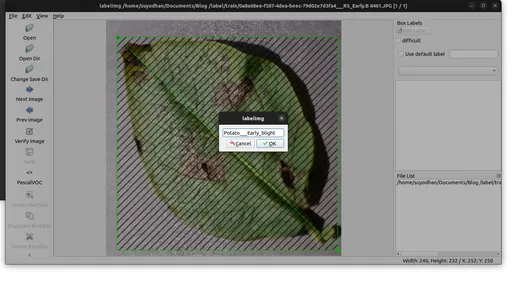
1. PascalVOC 형식으로 이미지에 주석을 답니다.
- LabelImg를 빌드하고 실행합니다.
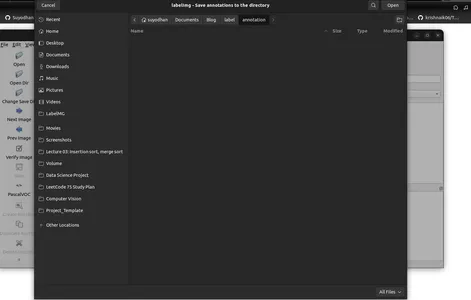
- 메뉴/파일에서 '기본 저장된 주석 폴더 변경'을 클릭하세요.
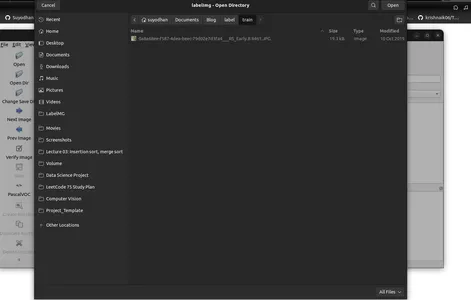
- 이미지 디렉터리를 선택하려면 '디렉터리 열기'를 클릭하세요.
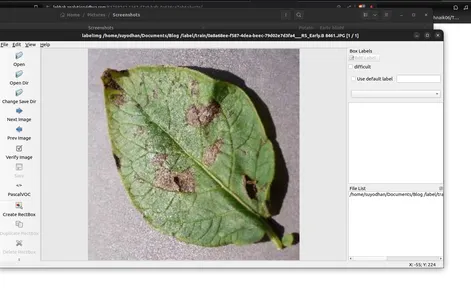
- 이미지의 개체에 주석을 추가하려면 'Create RectBox'를 사용하세요.
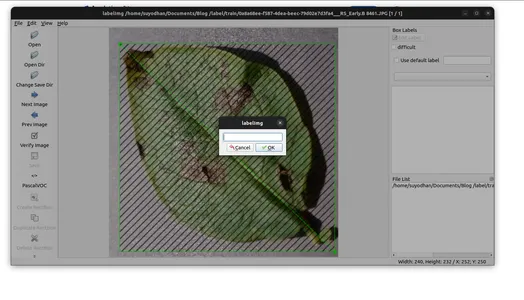
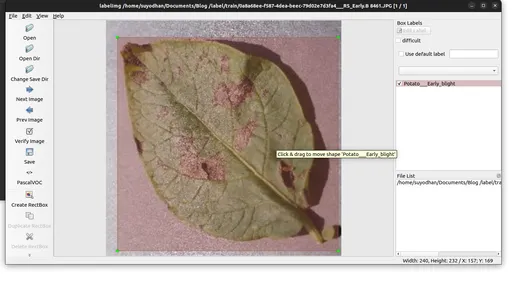
- 주석을 지정된 폴더에 저장합니다.
.xml 내부
<annotation>
<folder>train</folder>
<filename>0a8a68ee-f587-4dea-beec-79d02e7d3fa4___RS_Early.B 8461.JPG</filename>
<path>/home/suyodhan/Documents/Blog /label
/train/0a8a68ee-f587-4dea-beec-79d02e7d3fa4___RS_Early.B 8461.JPG</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>256</width>
<height>256</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>Potato___Early_blight</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>12</xmin>
<ymin>18</ymin>
<xmax>252</xmax>
<ymax>250</ymax>
</bndbox>
</object>
</annotation>이 XML 구조는 객체 감지 데이터 세트에 일반적으로 사용되는 Pascal VOC 주석 형식을 따릅니다. 이 형식은 컴퓨터 비전 모델 교육을 위해 주석이 달린 데이터의 표준화된 표현을 제공합니다. 주석이 포함된 추가 이미지가 있는 경우 해당 이미지의 주석이 달린 각 객체에 대해 유사한 XML 파일을 계속 생성할 수 있습니다.
Pascal VOC 주석을 COCO 형식으로 변환: Python 스크립트
객체 감지 모델은 효과적으로 훈련하고 평가하기 위해 특정 형식의 주석이 필요한 경우가 많습니다. Pascal VOC는 널리 사용되는 형식이지만 Detectron과 같은 특정 프레임워크는 COCO 주석을 선호합니다. 이러한 격차를 해소하기 위해 우리는 다용도 제품을 소개합니다. Python Pascal VOC 주석을 COCO 형식으로 원활하게 변환하도록 설계된 스크립트 voc2coco.py.
#!/usr/bin/python
# pip install lxml
import sys
import os
import json
import xml.etree.ElementTree as ET
import glob
START_BOUNDING_BOX_ID = 1
PRE_DEFINE_CATEGORIES = None
# If necessary, pre-define category and its id
# PRE_DEFINE_CATEGORIES = {"aeroplane": 1, "bicycle": 2, "bird": 3, "boat": 4,
# "bottle":5, "bus": 6, "car": 7, "cat": 8, "chair": 9,
# "cow": 10, "diningtable": 11, "dog": 12, "horse": 13,
# "motorbike": 14, "person": 15, "pottedplant": 16,
# "sheep": 17, "sofa": 18, "train": 19, "tvmonitor": 20}
def get(root, name):
vars = root.findall(name)
return vars
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise ValueError("Can not find %s in %s." % (name, root.tag))
if length > 0 and len(vars) != length:
raise ValueError(
"The size of %s is supposed to be %d, but is %d."
% (name, length, len(vars))
)
if length == 1:
vars = vars[0]
return vars
def get_filename_as_int(filename):
try:
filename = filename.replace("", "/")
filename = os.path.splitext(os.path.basename(filename))[0]
return str(filename)
except:
raise ValueError("Filename %s is supposed to be an integer." % (filename))
def get_categories(xml_files):
"""Generate category name to id mapping from a list of xml files.
Arguments:
xml_files {list} -- A list of xml file paths.
Returns:
dict -- category name to id mapping.
"""
classes_names = []
for xml_file in xml_files:
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall("object"):
classes_names.append(member[0].text)
classes_names = list(set(classes_names))
classes_names.sort()
return {name: i for i, name in enumerate(classes_names)}
def convert(xml_files, json_file):
json_dict = {"images": [], "type": "instances", "annotations": [], "categories": []}
if PRE_DEFINE_CATEGORIES is not None:
categories = PRE_DEFINE_CATEGORIES
else:
categories = get_categories(xml_files)
bnd_id = START_BOUNDING_BOX_ID
for xml_file in xml_files:
tree = ET.parse(xml_file)
root = tree.getroot()
path = get(root, "path")
if len(path) == 1:
filename = os.path.basename(path[0].text)
elif len(path) == 0:
filename = get_and_check(root, "filename", 1).text
else:
raise ValueError("%d paths found in %s" % (len(path), xml_file))
## The filename must be a number
image_id = get_filename_as_int(filename)
size = get_and_check(root, "size", 1)
width = int(get_and_check(size, "width", 1).text)
height = int(get_and_check(size, "height", 1).text)
image = {
"file_name": filename,
"height": height,
"width": width,
"id": image_id,
}
json_dict["images"].append(image)
## Currently we do not support segmentation.
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, "object"):
category = get_and_check(obj, "name", 1).text
if category not in categories:
new_id = len(categories)
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, "bndbox", 1)
xmin = int(get_and_check(bndbox, "xmin", 1).text) - 1
ymin = int(get_and_check(bndbox, "ymin", 1).text) - 1
xmax = int(get_and_check(bndbox, "xmax", 1).text)
ymax = int(get_and_check(bndbox, "ymax", 1).text)
assert xmax > xmin
assert ymax > ymin
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {
"area": o_width * o_height,
"iscrowd": 0,
"image_id": image_id,
"bbox": [xmin, ymin, o_width, o_height],
"category_id": category_id,
"id": bnd_id,
"ignore": 0,
"segmentation": [],
}
json_dict["annotations"].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {"supercategory": "none", "id": cid, "name": cate}
json_dict["categories"].append(cat)
#os.makedirs(os.path.dirname(json_file), exist_ok=True)
json_fp = open(json_file, "w")
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(
description="Convert Pascal VOC annotation to COCO format."
)
parser.add_argument("xml_dir", help="Directory path to xml files.", type=str)
parser.add_argument("json_file", help="Output COCO format json file.", type=str)
args = parser.parse_args()
xml_files = glob.glob(os.path.join(args.xml_dir, "*.xml"))
# If you want to do train/test split, you can pass a subset of xml files to convert function.
print("Number of xml files: {}".format(len(xml_files)))
convert(xml_files, args.json_file)
print("Success: {}".format(args.json_file))스크립트 개요
voc2coco.py 스크립트는 lxml 라이브러리를 활용하여 변환 프로세스를 단순화합니다. 사용법을 살펴보기 전에 주요 구성 요소를 살펴보겠습니다.
1. 종속성:
- pip install lxml을 사용하여 lxml 라이브러리가 설치되었는지 확인하세요.
2. 구성 :
- 선택적으로 PRE_DEFINE_CATEGORIES 변수를 사용하여 카테고리를 사전 정의합니다. 데이터세트에 따라 이 섹션의 주석 처리를 해제하고 수정하세요.
3. 함수Get
- get, get_and_check, get_filename_as_int: XML 구문 분석을 위한 도우미 함수입니다.
- get_categories: XML 파일 목록에서 ID 매핑에 대한 카테고리 이름을 생성합니다.
- 변환: 기본 변환 기능은 XML 파일을 처리하고 COCO 형식 JSON을 생성합니다.
이용 방법
스크립트 실행은 명령줄에서 간단하게 실행되며 Pascal VOC XML 파일에 대한 경로를 제공하고 COCO 형식 JSON 파일에 대해 원하는 출력 경로를 지정합니다. 예는 다음과 같습니다.
python voc2coco.py /path/to/xml/files /path/to/output/output.json출력:
이 스크립트는 이미지, 주석 및 카테고리에 대한 필수 정보가 포함된 잘 구조화된 COCO 형식 JSON 파일을 출력합니다.
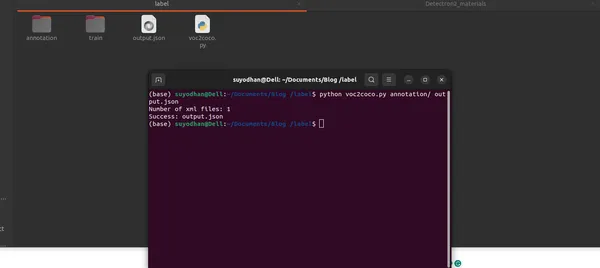
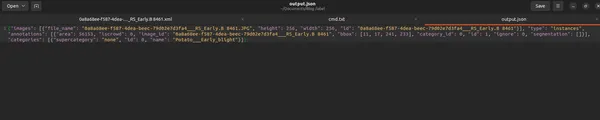
결론
결론적으로, LabelImg 및 Detectron을 사용한 객체 감지 여정을 마무리하면서 매니아와 전문가를 위한 다양한 주석 도구를 인식하는 것이 중요합니다. 오픈 소스 보석인 LabelImg는 다양성과 접근성을 제공하므로 최고의 선택입니다.
무료 도구 외에도 VIA(VGG Image Annotator), RectLabel 및 Labelbox와 같은 유료 솔루션이 복잡한 작업 및 대규모 프로젝트에 사용됩니다. 이러한 플랫폼은 재정적 투자에도 불구하고 고급 기능과 확장성을 제공하여 고위험 작업의 효율성을 보장합니다.
우리의 탐구는 프로젝트 세부 사항, 예산 및 정교함 수준에 따라 올바른 주석 도구를 선택하는 것을 강조합니다. LabelImg의 개방성을 고수하든 유료 도구에 투자하든 핵심은 프로젝트 규모 및 목표에 부합하는 것입니다. 진화하는 컴퓨터 비전 분야에서 주석 도구는 지속적으로 다양화되어 모든 규모와 복잡성의 프로젝트에 대한 옵션을 제공합니다.
주요 요점
- LabelImg의 직관적인 인터페이스와 고급 기능은 정밀한 이미지 주석을 위한 다용도 오픈 소스 도구로, 개체 감지를 시작하는 사용자에게 이상적입니다.
- VIA, RectLabel 및 Labelbox와 같은 유료 도구는 복잡한 주석 작업 및 대규모 프로젝트에 적합하며 고급 기능과 확장성을 제공합니다.
- 중요한 점은 프로젝트 요구 사항, 예산 및 원하는 정교함에 따라 올바른 주석 도구를 선택하여 객체 감지 노력의 효율성과 성공을 보장한다는 것입니다.
추가 학습을 위한 리소스:
1. LabelImg 문서:
- LabelImg의 공식 문서를 탐색하여 해당 기능에 대한 심층적인 통찰력을 얻으십시오.
- LabelImg 문서
2. Detectron 프레임워크 문서:
- 강력한 개체 감지 프레임워크인 Detectron의 문서를 자세히 살펴보고 해당 기능과 사용법을 이해하세요.
- 디텍트론 문서
3. VGG 이미지 주석자(VIA) 가이드:
- VGG Image Annotator인 VIA를 탐색하는 데 관심이 있다면 종합 가이드에서 자세한 지침을 참조하세요.
- VIA 사용자 가이드
4.RectLabel 문서:
- 사용법 및 기능에 대한 지침은 공식 문서를 참조하여 유료 주석 도구인 RectLabel에 대해 자세히 알아보세요.
- RectLabel 문서
5.Labelbox 학습 센터:
- 이 주석 플랫폼에 대한 이해를 높이기 위해 Labelbox 학습 센터에서 교육 리소스와 튜토리얼을 찾아보세요.
- 라벨박스 학습 센터
자주하는 질문
A: LabelImg는 객체 감지 작업을 위한 오픈 소스 이미지 주석 도구입니다. 사용자 친화적인 인터페이스와 다재다능함이 이 제품을 차별화합니다. 일부 도구와 달리 LabelImg는 정확한 경계 상자 주석을 허용하므로 객체 감지를 처음 접하는 사람들이 선호하는 선택입니다.
A: 예, VIA(VGG Image Annotator), RectLabel 및 Labelbox와 같은 여러 유료 주석 도구는 고급 기능과 확장성을 제공합니다. LabelImg와 같은 무료 도구는 기본 작업에 탁월하지만 유료 솔루션은 보다 복잡한 프로젝트에 맞춰져 공동 작업 기능과 향상된 효율성을 제공합니다.
A: 주석을 Pascal VOC 형식으로 변환하는 것은 Detectron과 같은 프레임워크와의 호환성을 위해 중요합니다. 일관된 클래스 라벨링과 학습 파이프라인으로의 원활한 통합을 보장하여 정확한 객체 감지 모델 생성을 촉진합니다.
A: Detectron은 모델 훈련 프로세스를 간소화하는 강력한 객체 감지 프레임워크입니다. 주석이 달린 데이터를 처리하고, 훈련을 위해 준비하고, 객체 감지 모델의 전반적인 효율성을 최적화하는 데 중요한 역할을 합니다.
A: 유료 주석 도구는 기업 수준의 작업과 관련된 경우가 많지만 소규모 프로젝트에도 도움이 될 수 있습니다. 결정은 특정 요구 사항, 예산 제약, 주석 작업에 대한 원하는 정교함 수준에 따라 달라집니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/11/detectron-integration-with-labelimg/

