개요
단일 클래스 SVM(Support Vector Machine)은 기존 SVM의 변형입니다. 이상 징후를 탐지하도록 특별히 맞춤화되었습니다. 주요 목표는 표준에서 크게 벗어난 인스턴스를 찾는 것입니다. 기존과는 다르게 기계 학습 이진 또는 다중 클래스 분류에 초점을 맞춘 모델인 단일 클래스 SVM은 데이터 세트 내 이상치 또는 신규성 탐지를 전문으로 합니다. 이 기사에서는 One-Class Support Vector Machine(SVM)이 기존 SVM과 어떻게 다른지 알아봅니다. 또한 OC-SVM의 작동 방식과 구현 방법을 배우게 됩니다. 또한 하이퍼파라미터에 대해서도 알아봅니다.
학습 목표
- 이상 현상을 이해하려면
- 단일 클래스 SVM에 대해 알아보기
- 기존 SVM(Support Vector Machine)과의 차이점 이해
- Sklearn의 OC-SVM 하이퍼파라미터
- OC-SVM을 사용하여 이상 징후를 탐지하는 방법
- One-class SVM 사용 사례
차례
이상 현상 이해
이상은 데이터 세트의 정상적인 동작에서 크게 벗어나는 관찰 또는 인스턴스입니다. 이러한 편차는 이상값, 노이즈, 오류 또는 예상치 못한 패턴과 같은 다양한 형태로 나타날 수 있습니다. 변칙 현상은 귀중한 통찰력을 나타낼 수 있기 때문에 흥미로운 경우가 많습니다. 이는 사기 거래 식별, 장비 오작동 감지 또는 새로운 현상 발견과 같은 통찰력을 제공할 수 있습니다. 특이치 및 신규성 감지는 이상치와 비정상적이거나 흔하지 않은 관측치를 식별합니다.
또한 읽기 : 이상 탐지에 대한 종단 간 가이드
원 클래스 SVM
SVM(지원 벡터 머신) 소개
서포트 벡터 머신(SVM) 인기있다 지도 학습 알고리즘 분류 및 회귀 작업용. SVM은 기능 공간에서 다양한 클래스를 분리하는 동시에 클래스 간의 마진을 최대화하는 최적의 초평면을 찾는 방식으로 작동합니다. 이 초평면은 지원 벡터라고 불리는 훈련 데이터 포인트의 하위 집합을 기반으로 합니다.
단일 클래스 SVM과 기존 SVM 비교
- 단일 클래스 SVM은 이상치 및 신규성 감지 작업에 주로 사용되는 기존 SVM 알고리즘의 변형을 나타냅니다. 이진 분류 작업을 처리하는 기존 SVM과 달리 One-Class SVM은 대상 클래스로 알려진 단일 클래스의 데이터 포인트에 대해서만 교육합니다. One-class SVM은 대상 클래스를 특징 공간에 캡슐화하는 경계 또는 결정 기능을 학습하여 데이터의 정상적인 동작을 효과적으로 모델링하는 것을 목표로 합니다.
- 기존 SVM은 서로 다른 클래스 간의 마진을 최대화하여 새로운 데이터 포인트를 최적으로 분류하는 결정 경계를 찾는 것을 목표로 합니다. 반면에 One-Class SVM은 대상 클래스를 캡슐화하는 동시에 경계 외부에 이상값이나 새로운 인스턴스가 포함될 위험을 최소화하는 경계를 찾습니다.
- 기존 SVM에는 여러 클래스의 인스턴스가 포함된 레이블이 지정된 데이터가 필요하므로 지도 분류 작업에 적합합니다. 이와 대조적으로 One-Class SVM은 대상 클래스의 데이터만 사용할 수 있는 시나리오에 적용할 수 있으므로 감독되지 않은 이상 탐지 및 신규 탐지 작업에 적합합니다.
자세히 알아보기 : 서포트 벡터 머신을 사용한 단일 클래스 분류
둘 다 소프트 마진 공식과 사용 방식이 다릅니다.
(SVM의 소프트 마진은 어느 정도의 오분류를 허용하는 데 사용됩니다.)
One-class SVM은 매핑된 데이터를 원점에서 분리하여 특징 공간 내에서 최대 마진을 갖는 초평면을 찾는 것을 목표로 합니다. 데이터 세트 Dn = {x1, . . . , xn} xi ∈ X(xi는 특성) 및 n 차원:
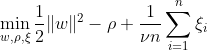
이 방정식은 OC-SVM에 대한 원초적 문제 공식을 나타냅니다. 여기서 w는 분리 초평면, ρ는 원점으로부터의 오프셋, ξi는 여유 변수입니다. 이는 소프트 마진을 허용하지만 위반 ξi에 페널티를 부과합니다. 하이퍼파라미터 ν ∈ (0, 1]은 여유 변수의 효과를 제어하며 필요에 따라 조정되어야 합니다. 목표는 w의 표준을 최소화하는 동시에 마진의 편차에 불이익을 주는 것입니다. 또한 이를 통해 데이터의 일부를 한계 내에 있거나 초평면의 잘못된 쪽에 속합니다.
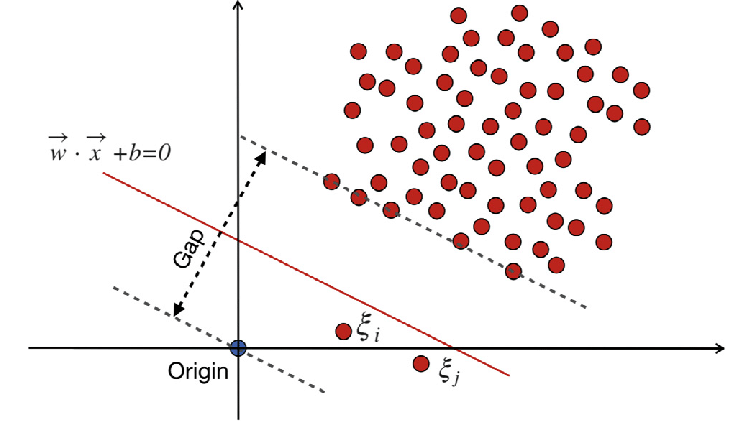
WX + b =0은 결정 경계이고 여유 변수는 편차에 페널티를 줍니다.
기존 지원 벡터 머신(SVM)
SVM(Traditional-Support Vector Machine)은 오분류 오류에 대해 소프트 마진 공식을 사용합니다. 또는 마진 내에 있거나 결정 경계의 잘못된 쪽에 있는 데이터 포인트를 사용합니다.
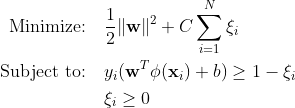
어디에:
w는 가중치 벡터입니다.
b는 바이어스 항입니다.
ξi는 소프트 마진 최적화를 허용하는 여유 변수입니다.
C는 마진 최대화와 분류 오류 최소화 간의 균형을 제어하는 정규화 매개변수입니다.
ф(xi)는 특징 매핑 함수를 나타냅니다.
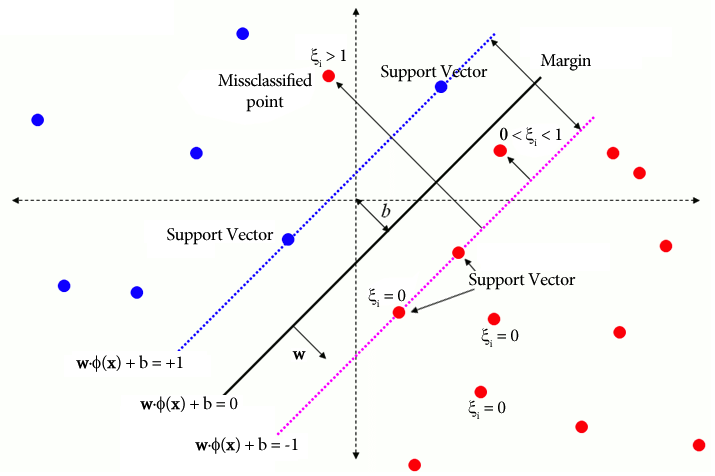
전통적인 SVM에서 분리를 위해 클래스 레이블에 의존하는 지도 학습 방법은 일정 수준의 오분류를 허용하기 위해 여유 변수를 통합합니다. SVM의 주요 목표는 결정 경계 WX + b = 0을 사용하여 서로 다른 클래스의 데이터 포인트를 분리하는 것입니다. 여유 변수의 값은 데이터 포인트의 위치에 따라 달라집니다. 데이터 포인트가 여백 너머에 있으면 0으로 설정됩니다. 데이터 포인트가 마진 내에 있는 경우 여유 변수의 범위는 0과 1 사이이며, 1보다 큰 경우 반대쪽 마진을 넘어 확장됩니다.
기존 SVM과 소프트 마진 공식을 사용하는 One-Class SVM 모두 가중치 벡터의 표준을 최소화하는 것을 목표로 합니다. 그러나 목표와 오분류 오류 또는 결정 경계에서의 편차를 처리하는 방법은 다릅니다. 기존 SVM은 과적합을 방지하기 위해 분류 정확도를 최적화하는 반면, One-Class SVM은 대상 클래스를 모델링하고 이상값 또는 새로운 인스턴스의 비율을 제어하는 데 중점을 둡니다.
또한 읽기 : 지원 벡터 머신에 대한 AZ 가이드
One-class SVM의 중요한 하이퍼파라미터
- 누: 이는 허용되는 이상값의 비율을 제어하는 One-Class SVM의 중요한 하이퍼 매개변수입니다. 훈련 오류 비율의 상한과 지원 벡터 비율의 하한을 설정합니다. 일반적으로 범위는 0에서 1 사이입니다. 값이 낮을수록 마진이 더 엄격해지고 더 적은 수의 이상값을 포착할 수 있으며, 값이 높을수록 더 허용됩니다. 기본값은 0.5입니다.
- 커널: 커널 함수는 SVM이 사용하는 결정 경계 유형을 결정합니다. 일반적인 선택에는 '선형', 'rbf'(가우스 방사형 기저 함수), '폴리'(다항식) 및 '시그모이드'가 포함됩니다. 'rbf' 커널은 복잡한 비선형 관계를 효과적으로 포착할 수 있기 때문에 자주 사용됩니다.
- 감마: 비선형 초평면에 대한 매개변수입니다. 단일 훈련 예시가 얼마나 많은 영향을 미치는지 정의합니다. 감마 값이 클수록 다른 예가 더 가깝게 영향을 받습니다. 이 매개변수는 RBF 커널에만 해당되며 일반적으로 'auto'로 설정되며 기본값은 1 / n_features입니다.
- 커널 매개변수(정도, coef0): 이러한 매개변수는 다항식 및 시그모이드 커널용입니다. 'degree'는 다항식 커널 함수의 차수이고, 'coef0'은 커널 함수의 독립항입니다. 최적의 성능을 달성하려면 이러한 매개변수를 조정해야 할 수도 있습니다.
- 비용: 정지기준입니다. 이중성 간격이 허용오차보다 작으면 알고리즘이 중지됩니다. 중지 기준에 대한 허용 오차를 제어하는 매개변수입니다.
단일 클래스 SVM의 작동 원리
단일 클래스 SVM의 커널 함수
커널 함수는 변환을 명시적으로 계산하지 않고도 알고리즘이 고차원 특징 공간에서 작동할 수 있도록 함으로써 One-Class SVM에서 중요한 역할을 합니다. One-Class SVM에서는 기존 SVM과 마찬가지로 커널 함수를 사용하여 입력 공간의 데이터 포인트 쌍 간의 유사성을 측정합니다. One-Class SVM에 사용되는 일반적인 커널 함수에는 RBF(가우스 커널), 다항식 및 시그모이드 커널이 포함됩니다. 이러한 커널은 원래 입력 공간을 고차원 공간으로 매핑합니다. 여기서 데이터 포인트는 선형으로 분리 가능하거나 보다 뚜렷한 패턴을 나타내어 학습을 촉진합니다. 적절한 커널 기능을 선택하고 해당 매개변수를 조정함으로써 One-Class SVM은 데이터의 복잡한 관계와 비선형 구조를 효과적으로 캡처하여 이상치나 이상치를 감지하는 능력을 향상시킬 수 있습니다.
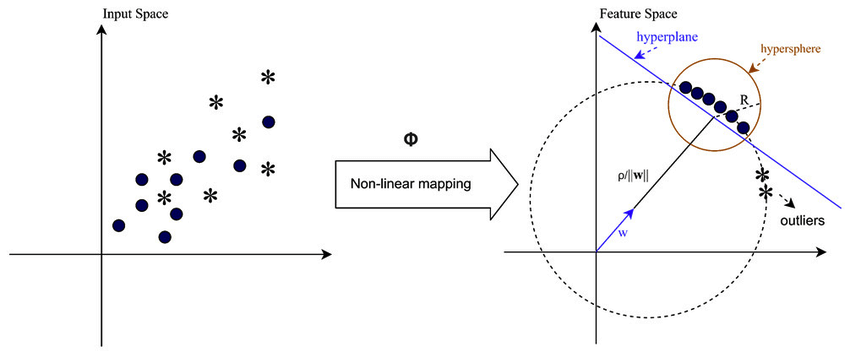
복잡하거나 겹치는 패턴을 처리할 때와 같이 데이터가 선형적으로 분리할 수 없는 경우 SVM(지원 벡터 머신)은 RBF(방사형 기초 함수) 커널을 사용하여 나머지 데이터에서 이상값을 효과적으로 분리할 수 있습니다. RBF 커널은 입력 데이터를 더 잘 분리할 수 있는 고차원 특징 공간으로 변환합니다.
여백 및 지원 벡터
One-Class SVM의 마진 및 서포트 벡터 개념은 기존 SVM의 개념과 유사합니다. 마진은 결정 경계(초평면)와 각 클래스의 가장 가까운 데이터 포인트 사이의 영역을 나타냅니다. One-Class SVM에서 마진은 대상 클래스에 속하는 대부분의 데이터 포인트가 있는 영역을 나타냅니다. 마진을 최대화하는 것은 새로운 데이터 포인트를 잘 일반화하고 모델의 견고성을 향상시키는 데 도움이 되므로 One-Class SVM에 매우 중요합니다. 서포트 벡터는 마진 위나 내에 있고 결정 경계를 정의하는 데 기여하는 데이터 포인트입니다.
One-Class SVM에서 지원 벡터는 결정 경계에 가장 가까운 대상 클래스의 데이터 포인트입니다. 이러한 서포트 벡터는 결정 경계의 모양과 방향을 결정하고 이에 따라 One-Class SVM 모델의 전반적인 성능을 결정하는 데 중요한 역할을 합니다. One-Class SVM은 지원 벡터를 식별함으로써 기능 공간에서 대상 클래스의 표현을 효과적으로 학습하고 이상값이나 새로운 인스턴스를 포함할 위험을 최소화하면서 대부분의 데이터 포인트를 캡슐화하는 결정 경계를 구성합니다.
One-Class SVM을 사용하여 이상 징후를 어떻게 감지할 수 있습니까?
참신함 탐지 및 이상치 탐지 기술을 모두 통해 One-class SVM(Support Vector Machine)을 사용하여 이상 탐지:
이상치 탐지
여기에는 훈련 데이터에서 나머지 데이터와 상당히 다른 관찰(종종 이상치라고 함)을 식별하는 작업이 포함됩니다. 추정기 이상치 탐지 이러한 일탈적인 관찰을 무시하고 훈련 데이터가 가장 집중된 영역을 맞추는 것을 목표로 합니다.
from sklearn.svm import OneClassSVM
from sklearn.datasets import load_wine
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
from sklearn.inspection import DecisionBoundaryDisplay
# Load data
X = load_wine()["data"][:, [6, 9]] # "banana"-shaped
# Define estimators (One-Class SVM)
estimators_hard_margin = {
"Hard Margin OCSVM": OneClassSVM(nu=0.01, gamma=0.35), # Very small nu for hard margin
}
estimators_soft_margin = {
"Soft Margin OCSVM": OneClassSVM(nu=0.25, gamma=0.35), # Nu between 0 and 1 for soft margin
}
# Plotting setup
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
colors = ["tab:blue", "tab:orange", "tab:red"]
legend_lines = []
# Hard Margin OCSVM
ax = axs[0]
for color, (name, estimator) in zip(colors, estimators_hard_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Hard Margin Outlier detection (wine recognition)",
)
# Soft Margin OCSVM
ax = axs[1]
legend_lines = []
for color, (name, estimator) in zip(colors, estimators_soft_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Soft Margin Outlier detection (wine recognition)",
)
plt.tight_layout()
plt.show()
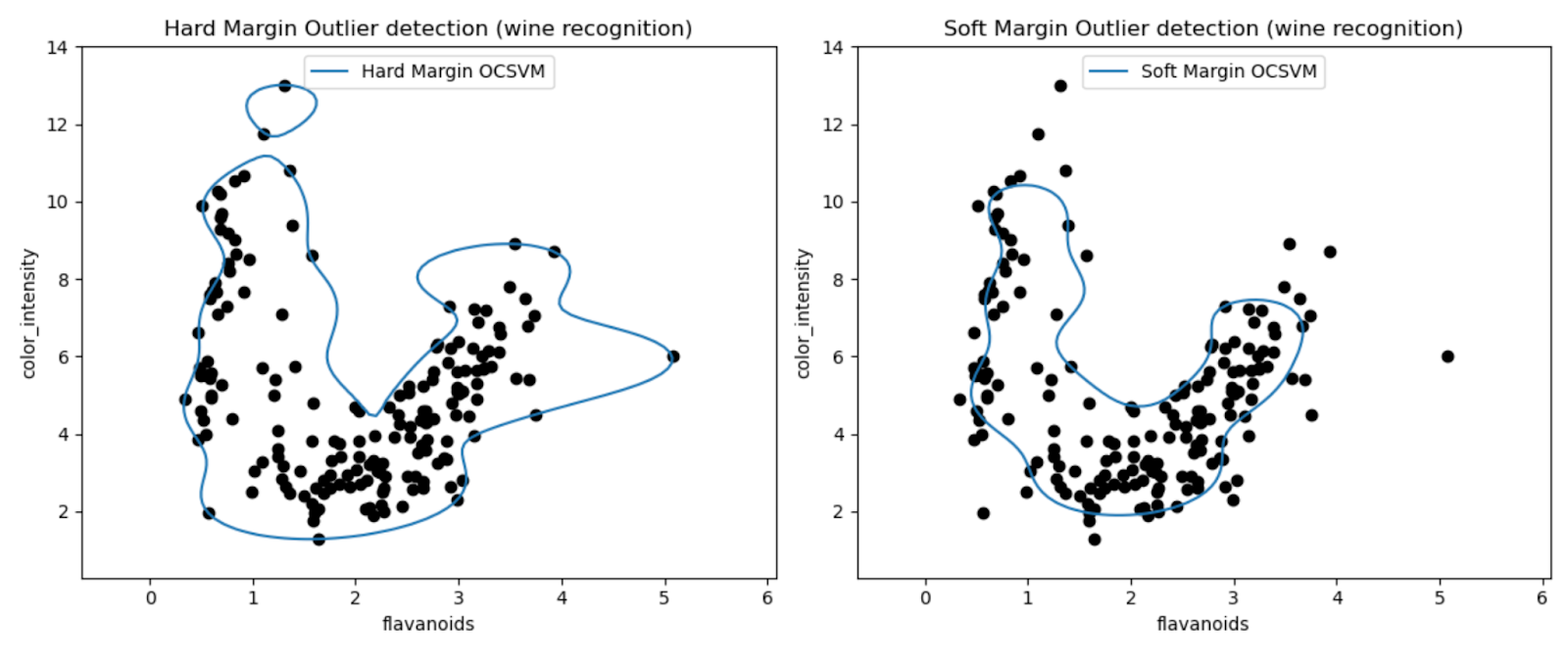
플롯을 통해 Wine 데이터 세트에서 이상값을 감지하는 One-Class SVM 모델의 성능을 시각적으로 검사할 수 있습니다.
하드 마진과 소프트 마진 One-Class SVM 모델의 결과를 비교함으로써 마진 설정(nu 매개변수)의 선택이 이상값 탐지에 어떤 영향을 미치는지 관찰할 수 있습니다.
매우 작은 Nu 값(0.01)을 갖는 하드 마진 모델은 보다 보수적인 결정 경계를 초래할 가능성이 높습니다. 이는 대부분의 데이터 포인트를 긴밀하게 둘러싸며 잠재적으로 더 적은 수의 포인트를 이상값으로 분류합니다.
반대로, 더 큰 Nu 값(0.35)을 갖는 소프트 마진 모델은 더 유연한 결정 경계를 초래할 가능성이 높습니다. 따라서 더 넓은 마진을 허용하고 잠재적으로 더 많은 이상값을 포착할 수 있습니다.
참신함 감지
반면, 훈련 데이터에 이상값이 없을 때 이를 적용하며 목표는 새로운 관찰이 드문지, 즉 알려진 관찰과 매우 다른지 여부를 결정하는 것입니다. 여기서 이 최신 관찰을 참신함이라고 합니다.
import numpy as np
from sklearn import svm
# Generate train data
np.random.seed(30)
X = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# Generate some regular novel observations
X = 0.3 * np.random.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# Generate some abnormal novel observations
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
n_error_outliers = y_pred_outliers[y_pred_outliers == 1].size
import matplotlib.font_manager
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
_, ax = plt.subplots()
# generate grid for the boundary display
xx, yy = np.meshgrid(np.linspace(-5, 5, 10), np.linspace(-5, 5, 10))
X = np.concatenate([xx.reshape(-1, 1), yy.reshape(-1, 1)], axis=1)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
cmap="PuBu",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
levels=[0, 10000],
colors="palevioletred",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contour",
ax=ax,
levels=[0],
colors="darkred",
linewidths=2,
)
s = 40
b1 = ax.scatter(X_train[:, 0], X_train[:, 1], c="white", s=s, edgecolors="k")
b2 = ax.scatter(X_test[:, 0], X_test[:, 1], c="blueviolet", s=s, edgecolors="k")
c = ax.scatter(X_outliers[:, 0], X_outliers[:, 1], c="gold", s=s, edgecolors="k")
plt.legend(
[mlines.Line2D([], [], color="darkred"), b1, b2, c],
[
"learned frontier",
"training observations",
"new regular observations",
"new abnormal observations",
],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11),
)
ax.set(
xlabel=(
f"error train: {n_error_train}/200 ; errors novel regular: {n_error_test}/40 ;"
f" errors novel abnormal: {n_error_outliers}/40"
),
title="Novelty Detection",
xlim=(-5, 5),
ylim=(-5, 5),
)
plt.show()

- 두 개의 데이터 포인트 클러스터를 사용하여 합성 데이터세트를 생성합니다. 학습 및 테스트 데이터의 경우 두 개의 서로 다른 중심((2, 2) 및 (-2, -2))을 중심으로 정규 분포를 사용하여 이를 생성합니다. 두 차원을 따라 -4에서 4 사이의 정사각형 영역 내에서 균일하게 XNUMX개의 데이터 포인트를 무작위로 생성합니다. 이러한 데이터 포인트는 열차 및 테스트 데이터에서 관찰된 정상적인 동작에서 크게 벗어나는 비정상적인 관찰 또는 이상값을 나타냅니다.
- 학습된 프론티어는 One-class SVM 모델에서 학습한 결정 경계를 나타냅니다. 이 경계는 모델이 데이터 포인트를 이상치로부터 정상으로 간주하는 특징 공간의 영역을 분리합니다.
- 등고선의 파란색에서 흰색까지의 색상 그라데이션은 One-Class SVM 모델이 특징 공간의 다양한 영역에 할당하는 신뢰도 또는 확실성의 다양한 정도를 나타내며, 음영이 어두울수록 데이터 포인트를 '정상'으로 분류하는 데 더 높은 신뢰도를 나타냅니다. 진한 파란색은 모델의 결정 기능에 따라 '정상'임을 강하게 나타내는 영역을 나타냅니다. 윤곽선의 색상이 밝아질수록 모델은 데이터 포인트를 '정상'으로 분류하는 것에 대한 확신이 약해집니다.
- 플롯은 One-class SVM 모델이 일반 관측값과 비정상 관측값을 어떻게 구별할 수 있는지를 시각적으로 나타냅니다. 학습된 결정 경계는 정상 관찰 영역과 비정상 관찰 영역을 구분합니다. 신규성 탐지를 위한 단일 클래스 SVM은 주어진 데이터 세트에서 비정상적인 관찰을 식별하는 데 있어 효율성을 입증합니다.
nu=0.5의 경우:
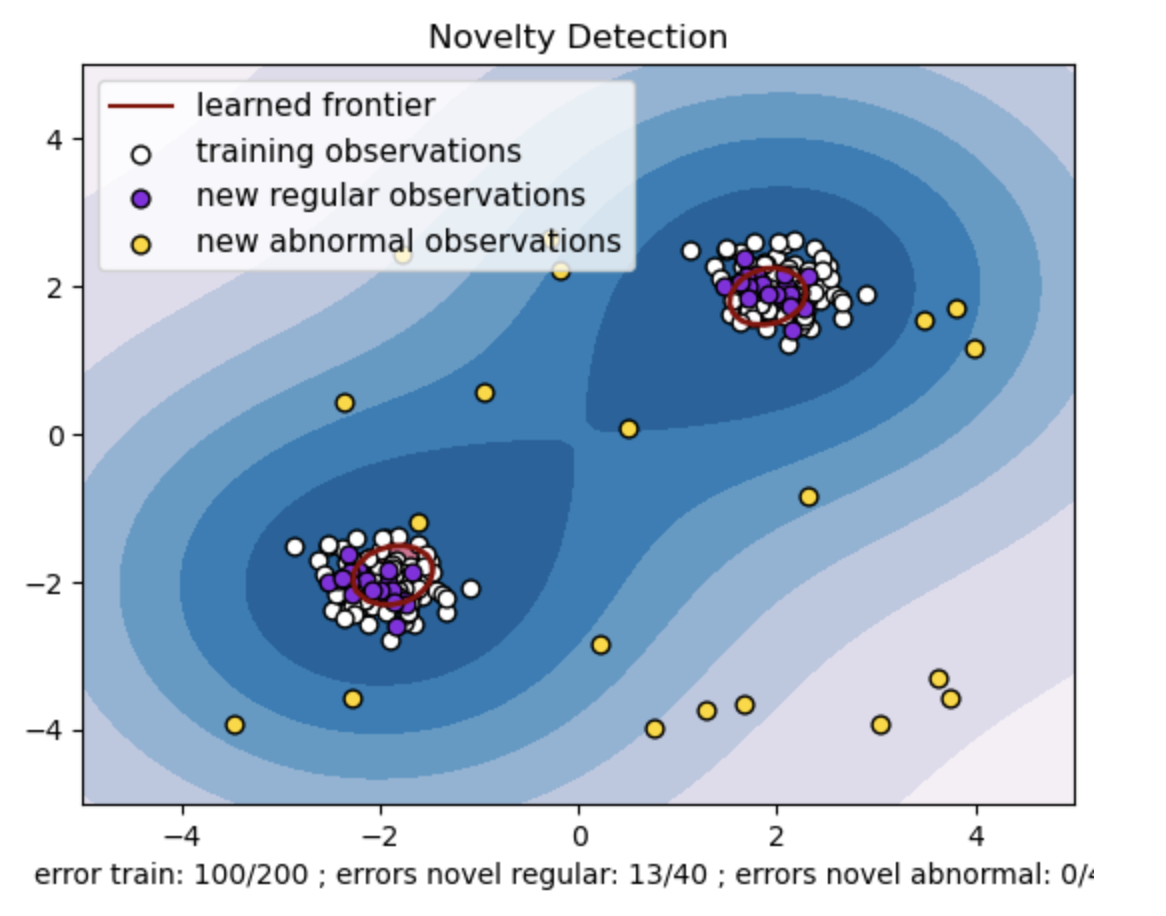
One-class SVM의 "nu" 값은 모델이 허용하는 이상값의 비율을 제어하는 데 중요한 역할을 합니다. 이는 이상 현상을 식별하는 모델의 능력에 직접적인 영향을 미치므로 예측에도 영향을 미칩니다. 모델이 100개의 훈련 포인트를 잘못 분류하는 것을 허용하고 있음을 알 수 있습니다. nu 값이 낮을수록 허용되는 이상값 비율에 대한 제약이 더 엄격해집니다. nu의 선택은 이상 징후를 탐지하는 모델의 성능에 영향을 미칩니다. 또한 애플리케이션의 특정 요구 사항과 데이터 세트의 특성을 기반으로 신중한 조정이 필요합니다.
감마=0.5 및 nu=0.5의 경우
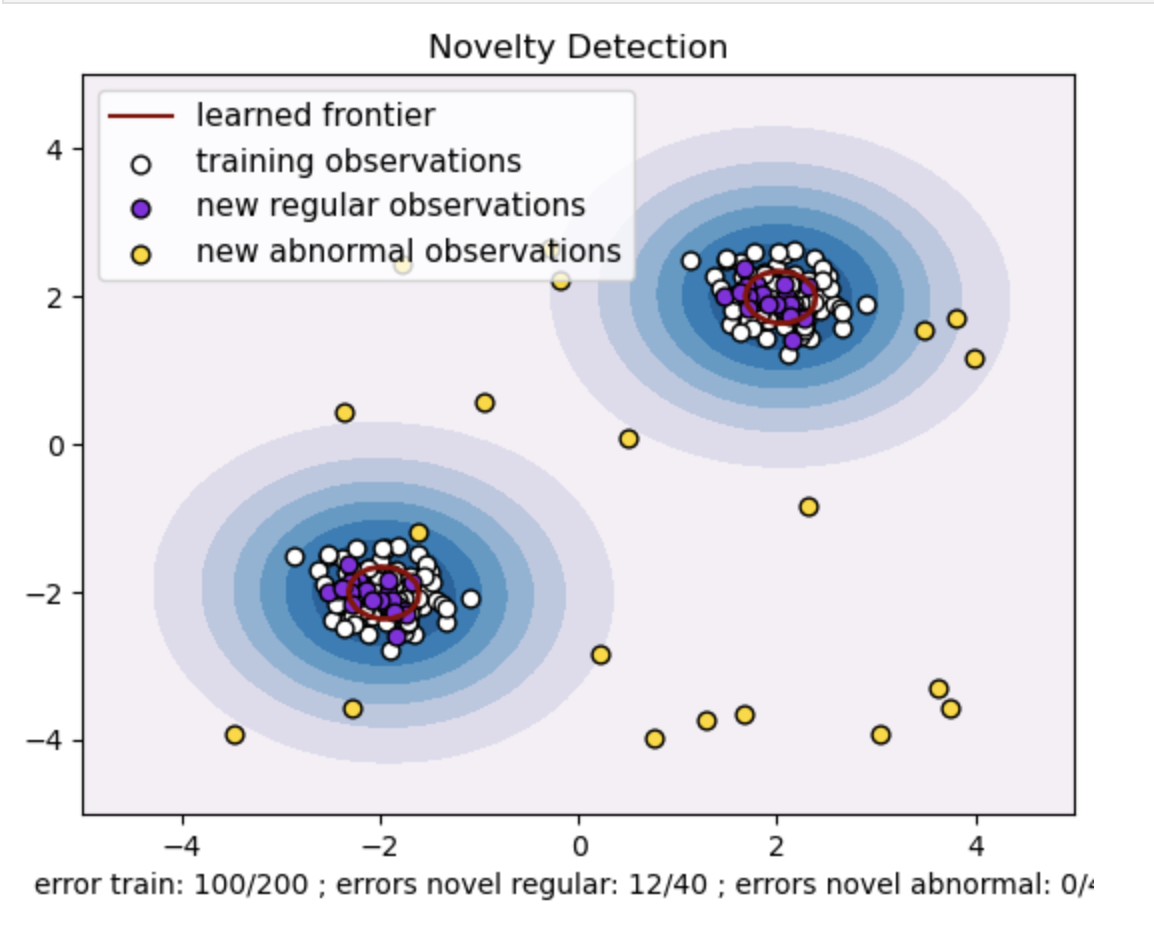
One-class SVM에서 감마 하이퍼파라미터는 'rbf' 커널에 대한 커널 계수를 나타냅니다. 이 하이퍼파라미터는 결정 경계의 모양에 영향을 미치고 결과적으로 모델의 예측 성능에 영향을 미칩니다.
감마가 높으면 단일 훈련 예제는 영향력을 바로 근처로 제한합니다. 이는 보다 지역화된 결정 경계를 만듭니다. 따라서 동일한 클래스에 속하려면 데이터 포인트가 서포트 벡터에 더 가까워야 합니다.
결론
이상치 탐지를 위해 One-Class SVM을 활용하고 이상치 및 신규성 탐지를 사용하면 다양한 영역에 걸쳐 강력한 솔루션을 제공합니다. 이는 레이블이 지정된 변칙 데이터가 부족하거나 사용할 수 없는 시나리오에 도움이 됩니다. 따라서 이상이 드물고 명시적으로 정의하기 어려운 실제 응용 프로그램에서 특히 유용합니다. 그 사용 사례는 이상 현상이 발생하는 사이버 보안 및 결함 진단과 같은 다양한 영역으로 확장됩니다. 그러나 One-Class SVM은 수많은 이점을 제공하지만 더 나은 결과를 얻으려면 데이터에 따라 하이퍼 매개변수를 설정해야 하는데 이는 때로는 지루할 수 있습니다.
자주 묻는 질문
A. One-Class SVM은 일반 데이터 포인트를 캡슐화하는 초평면(또는 더 높은 차원의 초구체)을 구성합니다. 이 초평면은 정규 데이터와 결정 경계 사이의 마진을 최대화하도록 배치됩니다. 데이터 포인트는 테스트 또는 추론 중에 정상(경계 내부) 또는 이상(경계 외부)으로 분류됩니다.
A. One-class SVM은 훈련 중 이상 징후에 대해 레이블이 지정된 데이터가 필요하지 않기 때문에 유리합니다. 일반 인스턴스만 포함된 데이터 세트에서 학습할 수 있으므로 변칙이 드물고 훈련을 위해 레이블이 지정된 예제를 얻기 어려운 시나리오에 적합합니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2024/03/one-class-svm-for-anomaly-detection/

