개요
전 워들Walk Through California 프로그램, 스도쿠 퍼즐 분노했고 여전히 인기가 많습니다. 최근에는 최적화 퍼즐을 해결하는 방법이 지배적인 주제였습니다. 보다 “Arkieva의 최적화를 사용하여 스도쿠 퍼즐 풀기".
현재 인공지능(AI)의 활용은 올가미 회귀(lasso regression)부터 강화학습(reinforcement learning)까지 광범위한 방법을 포괄하는 기계학습(machine learning)에 초점을 맞추고 있습니다. AI를 활용한 것은 부활 복잡한 문제를 해결하기 위해 일정 도전. 한 가지 방법인 역추적을 통한 검색은 일반적으로 사용되며 스도쿠에 적합합니다.
이 블로그에서는 이 방법을 사용하여 스도쿠를 푸는 방법에 대해 자세히 설명합니다. 결과적으로 "역추적"은 최적화 및 기계 학습 엔진 내에서 찾을 수 있으며 Arkieva가 일정 관리에 사용하는 고급 경험적 방법의 초석입니다. 알고리즘은 다음을 처리하는 함수 지향 프로그래밍 언어인 "어레이 프로그래밍 언어"로 구현됩니다. 풍부한 배열 구조 세트.
스도쿠의 기본
위키 백과: 스도쿠는 논리 기반의 조합 숫자 배치 퍼즐입니다. 목표는 9×9 격자를 숫자로 채워서 각 열, 각 행, 그리고 격자를 구성하는 3개의 3×1 하위 격자(“상자”, “블록”, “영역”이라고도 함)를 채우는 것입니다. 또는 "하위 사각형")에는 9부터 9까지의 모든 숫자가 포함됩니다. 퍼즐 설정기는 일반적으로 고유한 솔루션이 있는 부분적으로 완성된 그리드를 제공합니다. 완성된 퍼즐은 항상 개별 지역의 내용에 대한 추가 제약이 있는 일종의 라틴 방진입니다. 예를 들어, 동일한 단일 정수가 동일한 9×3 플레이 보드 행이나 열 또는 3×9 플레이 보드의 9개 XNUMX×XNUMX 하위 영역에 두 번 나타날 수 없습니다.
표 1에는 예제 문제가 있습니다. 행 9개와 열 9개로 총 81개의 셀이 있습니다. 각각은 1과 9 사이의 1,1개의 정수 중 하나만 가질 수 있습니다. 시작 솔루션에서 셀은 단일 값을 가지거나(이 셀의 값을 해당 값으로 고정) 셀이 비어 있어 필요함을 나타냅니다. 이 셀의 값을 찾으려면 셀(2)의 값은 6,5이고 셀(6)의 값은 1,2입니다. 셀(2,3)과 셀(XNUMX)은 비어 있으며 알고리즘은 이러한 셀에 대한 값을 찾습니다.

합병증
셀은 단 하나의 행과 열에 속할 뿐만 아니라 단 하나의 상자에도 속합니다. 1개의 상자가 있으며 표 9에서 색상으로 표시됩니다. 표 1에서는 2에서 1 사이의 고유한 정수를 사용하여 각 상자 또는 그리드를 식별합니다. 행 값이 (9, 1 또는 2)이고 열 값이 (3, 1 또는 2)인 셀은 상자 3에 속합니다. 상자 1은 행 값 (6, 4, 5)과 열 값 (6, 7)입니다. , 8). 상자 ID는 BOX_ID = {9x(floor((ROW_ID-3) /1)} + 천장(COL_ID/3) 공식에 의해 결정됩니다. 셀 (3)의 경우 5,7 = 6x(floor(3-5) ))/1) + 천장(3/8)= 3×3 + 1 = 3+3.

퍼즐의 핵심
각 열, 각 행 및 각 상자에 대해 정수 1~9가 한 번만 사용되도록 알 수 없는 각 셀에 대해 1~9 사이의 정수 값 하나를 찾습니다.
비어 있는 셀 (1,3)을 살펴보겠습니다. 행 1에는 이미 값 2와 7이 있습니다. 이 셀에서는 이러한 값이 허용되지 않습니다. 열 3에는 이미 3, 5,6, 7,9 값이 있습니다. 이는 허용되지 않습니다. 상자 1(노란색)에는 값 2, 3, 8이 있습니다. 이는 허용되지 않습니다. 다음 값은 허용되지 않습니다(2,7). (3, 5, 6, 7, 9); (2, 3, 8). 허용되지 않는 고유 값은 (2, 3, 5, 6, 7, 8, 9)입니다. 유일한 후보 값은 (1,4)입니다.
해결 방법은 일시적으로 셀 (1)에 1,3을 할당한 다음 다른 셀에 대한 후보 값을 찾는 것입니다.
역추적 솔루션: 구성 요소 시작
배열 구조
시작점은 소스 문제를 저장하고 검색을 지원하기 위한 배열 구조를 결정하는 것입니다. 표 3은 이러한 배열 구조를 가지고 있습니다. 열 1은 각 셀의 고유한 정수 ID입니다. 값 범위는 1부터 81까지입니다. 열 2는 셀의 행 ID입니다. 열 3은 셀의 열 ID입니다. 열 4는 상자 ID입니다. 열 5는 셀의 값입니다. 값이 없는 셀에는 공백이나 null 대신 XNUMX이라는 값이 부여됩니다. 이는 "정수 전용 배열"을 유지하여 성능이 훨씬 뛰어납니다.

APL에서 이 배열은 모양이 2 x 81인 5차원 배열에 저장됩니다. 표 3의 요소가 변수 MAT에 저장되어 있다고 가정합니다. 예제 함수는 다음과 같습니다:
MAT[1 2 3;] 명령은 MAT의 처음 3개 행을 가져옵니다.
1 1 1 1 2
2 1 2 1 0
3 1 3 1 0
매트[1 2 3; 4 5] 행 1, 2, 3과 열 4, 5만 보호합니다.
1
1
1
(MAT[;5]=0)/MAT[;1]은 값이 필요한 모든 셀을 찾습니다.
표 3 삽입
온전성 검사: 중복
검색을 시작하기 전, 온전한 확인이 중요합니다! 이것이 가능한 시작 솔루션입니다. 스도쿠에 적합합니다. 이제 모든 행, 열 또는 상자에 중복 항목이 있습니까? 현재 시작 솔루션(예: 1)이 가능합니다. 표 4에는 시작 솔루션에 중복이 있는 예가 있습니다. 행 1에는 두 개의 값 2가 있습니다. 영역 1에는 두 개의 값 2가 있습니다. "SANITY_DUPE" 함수가 이 논리를 처리합니다.

온전성 검사: 값이 없는 셀에 대한 옵션
매우 유용한 정보는 값이 없는 셀에 대해 가능한 모든 값입니다. 후보자가 없으면 이 퍼즐은 풀 수 없습니다. 셀은 이웃이 이미 요구한 값을 가질 수 없습니다. 셀(1,'1,3' - 마지막 1이 boxid임)에 대해 표 1을 사용하면 해당 이웃은 행 1, 열 3 및 상자 1입니다. 행 1에는 값 (2,7)이 있습니다. 열 3에는 값 (3,5,6,7,9)이 있습니다. 상자 1에는 값 (2,3,8)이 있습니다. 셀(1,3.1)은 다음 값(2,3,5,6,7,8,9)을 사용할 수 없습니다. 셀 (1,3,1)에 대한 유일한 옵션은 (1,4)입니다. 셀 (4,1,2)의 경우 값 1, 2, 3, 5, 6, 7, 9가 이미 행 4, 열 1 및/또는 상자 4에서 사용되었습니다. 유일한 후보 값은 (4,8)입니다. . “SANITY_CAND” 기능이 이 논리를 처리합니다.
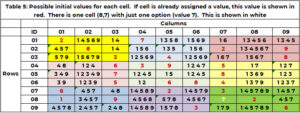
표 5는 검색 과정 시작 시 후보, 예를 들어 1을 보여줍니다. 시작 조건(표 1)에서 셀에 이미 값이 할당된 경우 이 값이 반복되어 빨간색으로 표시됩니다. 값이 필요한 셀에 옵션이 하나만 있는 경우 흰색으로 표시됩니다. 셀 (8,7,9)에는 흰색의 단일 값 7이 있습니다. (2,5,8,4,3)은 이웃 열 7에 의해 요구됩니다. (1, 2, 9)는 행 8에 의해. (3,2,6)은 상자 9에 의해 요구됩니다. 값 7만 요구되지 않습니다.
건전성 검사: 충돌 찾기
값이 필요한 셀에 대한 모든 옵션을 식별하는 정보(표 4에 게시됨)를 통해 검색 프로세스를 시작하기 전에 충돌을 식별할 수 있습니다. 값이 필요한 두 셀에 후보가 하나만 있고 후보 값이 동일하며 두 셀이 이웃인 경우 충돌이 발생합니다. 표 4에서 우리는 값이 필요하고 후보가 하나만 있는 유일한 셀은 셀 (8,7,9)임을 알 수 있습니다. 예를 들어 1에서는 충돌이 없습니다.
갈등은 무엇입니까? 셀 (3,7,3)에 가능한 유일한 값이 7(1, 6, 7 대신)인 경우 충돌이 있는 것입니다. 셀 (8,7)과 셀 (3,7)은 이웃이며 동일한 열입니다. 그러나 셀 (4,9,2)에 대해 가능한 유일한 값이 7(1, 2, 7 대신)인 경우 충돌이 발생하지 않습니다. 이 셀은 이웃이 아닙니다.
온전성 검사 요약
- 중복이 있으면 시작 솔루션을 사용할 수 없습니다.
- 값이 필요한 셀에 후보가 없으면 이 퍼즐에 대한 가능한 해결책이 없습니다. 각 셀의 후보 값 목록은 역추적 및 최적화를 위해 검색 공간을 줄이는 데 사용될 수 있습니다.
- 갈등을 찾는 능력은 검색 프로세스 없이는 퍼즐이 실현 불가능하고 해결책이 없음을 식별합니다. 또한 "문제 셀"을 식별합니다.
역추적 솔루션: 검색 프로세스
핵심 데이터 구조와 온전성 검사가 이루어지면 검색 프로세스에 관심을 돌립니다. 반복되는 주제는 검색을 지원하기 위해 데이터 구조를 마련하는 것입니다.
검색 추적
어레이 트래커 수행된 과제를 추적합니다.
- 1열은 카운터
- Col 2는 이 셀에 할당할 수 있는 옵션의 수입니다.
- 1은 사용 가능한 옵션 1개를 의미하고, 2는 옵션 XNUMX개를 의미합니다.
- 0은 사용 가능한 옵션이 없거나 0(할당된 값 없음)으로 재설정되고 역추적됨을 의미합니다.
- Col 3은 값 인덱스 번호(1~81)가 할당된 셀입니다.
- Col 4는 트랙 히스토리의 셀에 할당된 값입니다.
- 값 9999는 이 셀이 막다른 골목을 발견했을 때의 셀임을 의미합니다.
- 1에서 9 사이의 정수 값은 검색 프로세스의 이 시점에서 이 셀에 할당된 값입니다.
- 값이 0이면 이 셀에 할당이 필요함을 의미합니다.
추적기 배열은 검색 프로세스를 지원하는 데 사용됩니다. 배열 트랙히스트 추적기와 동일한 구조를 가지고 있지만 전체 검색 프로세스의 기록을 유지합니다. 표 6에는 예제 1에 대한 TRACKHIST의 일부가 있습니다. 이에 대해서는 이후 섹션에서 자세히 설명합니다.

추가적으로, 배열 포장 (벡터의 벡터)는 이 셀에 이전에 할당된 값을 추적합니다. 이는 TABU에서 수행된 것과 유사하게 실패한 솔루션을 다시 방문하지 않도록 보장합니다.
검색 프로세스가 각 단계를 기록하는 선택적 로그 프로세스가 있습니다.
검색 시작
부기 및 온전성 검사가 완료되었으므로 이제 검색 프로세스를 시작할 수 있습니다. 단계는 다음과 같습니다.
- 값이 필요한 셀이 남아 있나요? – 그렇지 않다면 끝난 것입니다.
- 값이 필요한 각 셀에 대해 각 셀에 대한 모든 후보 옵션을 찾습니다. 표 4에는 솔루션 프로세스 시작 시 이러한 값이 있습니다. 각 반복마다 셀에 할당된 값을 수용하도록 업데이트됩니다.
- 이 순서대로 옵션을 평가하십시오.
- 셀에 ZERO 옵션이 있는 경우 역추적을 실시합니다.
- 하나의 옵션으로 모든 셀을 찾고, 이 셀 중 하나를 선택하고, 이 할당을 수행하고,
- 추적 테이블, 현재 솔루션 및 PAV를 업데이트합니다.
- 모든 셀에 둘 이상의 옵션이 있는 경우 하나의 셀과 하나의 값을 선택하고 업데이트합니다.
- 추적 테이블, 현재 솔루션 및 PAV를 업데이트합니다.
각 단계를 설명하기 위해 솔루션 프로세스(TRACKHIST라고 함) 기록의 일부인 표 6을 사용합니다.
첫 번째 반복(CTR=1)에서는 셀 70(행 8, 열 7, 상자 9)이 선택되어 값이 할당됩니다. 후보(7)만 있고 이 값은 셀 70에 할당됩니다. 또한 셀 7에 대해 이전에 할당된 값(PAV)의 벡터에 값 70이 추가됩니다.
두 번째 반복에서는 셀 30에 값 1이 할당됩니다. 이 셀에는 두 개의 후보 값이 있습니다. 가장 작은 후보 값이 셀에 할당됩니다(논리를 쉽게 따르도록 하기 위한 임의의 규칙일 뿐입니다).
값이 필요한 셀을 식별하고 값을 할당하는 프로세스는 반복(CTR) 20까지 잘 작동합니다. 셀 9에는 값이 필요하지만 후보 수는 XNUMX입니다. 두 가지 옵션이 있습니다:
- 이 퍼즐에는 해결책이 없습니다.
- 일부 과제를 실행 취소(역추적)하고 다른 경로를 선택합니다.
우리는 둘 이상의 옵션이 있는 이에 가장 가까운 셀 할당을 찾았습니다. 이 예에서는 반복 18에서 발생했습니다. 여기서 셀 5에는 값 3이 할당되었지만 셀 5에는 값 3과 8이라는 두 가지 후보 값이 있었습니다.
셀 5(CTR = 18)와 셀 9(CTR = 20) 사이에서 셀 8에는 값 4(CTR=19)가 할당됩니다. 셀 8과 5를 "값 필요" 목록에 다시 넣습니다. 이는 값이 20으로 설정된 두 번째 및 세 번째 CTR=0 항목에 캡처됩니다. 값 3은 셀 5에 대한 PAV 벡터에 유지됩니다. 즉, 검색 엔진은 값 3을 셀 5에 할당할 수 없습니다.
검색 엔진이 다시 시작되어 셀 5(3은 더 이상 옵션이 아님)의 값을 식별하고 값 8을 셀 5(CTR=21)에 할당합니다. 모든 셀에 값이 있거나 옵션이 없고 역추적 경로가 없는 셀이 있을 때까지 계속됩니다. 솔루션은 표 7에 게시되어 있습니다.

셀에 대한 후보가 두 개 이상인 경우 이는 병렬 처리의 기회입니다.
MILP 최적화 솔루션과 비교
표면 수준에서 스도쿠 퍼즐의 표현은 크게 다릅니다. AI 접근 방식은 정수를 사용하며 어떤 기준으로든 더 엄격하고 직관적으로 표현됩니다. 또한 온전성 검사기는 더 강력한 공식을 만드는 데 유용한 정보를 제공합니다. MILP 표현은 끝이 없습니다 바이너리 (0/1). 그러나 최신 MILP 솔버의 강점을 고려하면 바이너리는 강력한 표현입니다.
그러나 내부적으로 MILP 솔버는 바이너리를 유지하지 않고 희소 배열 방법을 사용하여 모든 1980 저장을 제거합니다. 또한 바이너리를 해결하는 알고리즘은 1990년대와 1983년대까지 등장하지 않았습니다. XNUMX년 논문 크라우더, 존슨, 패드버그 바이너리를 사용한 최초의 실용적인 최적화 솔루션 중 하나에 대해 보고합니다. 그들은 성공적인 솔루션을 위해서는 영리한 전처리와 분기 및 바인딩 방법의 중요성을 지적합니다.
최근 제약 프로그래밍과 다음과 같은 소프트웨어의 사용이 폭발적으로 증가하고 있습니다. 로컬 솔버 선형 계획법, 최소 제곱법 등 독창적인 최적화 방법과 함께 AI 방법을 사용하는 것의 중요성을 분명히 했습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://blog.arkieva.com/an-artificial-intelligence-based-solution-to-sudoku/?utm_source=rss&utm_medium=rss&utm_campaign=an-artificial-intelligence-based-solution-to-sudoku

