Python을 사용하여 데이터 분야에 능숙합니까? 그렇다면 대부분의 분들이 데이터 조작에 Pandas를 사용하실 것입니다.
당신이 모르는 경우에, 판다 데이터 분석 및 조작을 위해 특별히 개발된 오픈 소스 Python 패키지입니다. 가장 많이 사용되는 패키지 중 하나이며 Python에서 데이터 과학 여정을 시작할 때 일반적으로 배우는 패키지입니다.
그렇다면 판다 AI란 무엇인가? 이 글을 읽고 계신 분들이 알고 싶어서 이 글을 읽고 계신 것 같습니다.
글쎄요, 아시다시피 우리는 Generative AI가 어디에나 있는 시대에 살고 있습니다. Generative AI를 사용하여 데이터에 대한 데이터 분석을 수행할 수 있다고 상상해 보십시오. 일이 훨씬 쉬울 것입니다.
이것이 Pandas AI가 제공하는 것입니다. 간단한 프롬프트를 통해 데이터를 어딘가로 보내지 않고도 데이터 세트를 빠르게 분석하고 조작할 수 있습니다.
이 기사에서는 데이터 분석 작업에 Pandas AI를 활용하는 방법을 살펴보겠습니다. 이 기사에서는 다음 내용을 배울 것입니다.
- 팬더 AI 설정
- Pandas AI를 사용한 데이터 탐색
- Pandas AI를 사용한 데이터 시각화
- Pandas AI 고급 사용법
배울 준비가 되셨다면 지금 바로 시작해 보세요!
팬더 AI Pandas API에 LLM(Large Language Model) 기능을 구현하는 Python 패키지입니다. Pandas를 대화 도구로 전환하는 Generative AI 향상 기능과 함께 표준 Pandas API를 사용할 수 있습니다.
우리는 패키지가 제공하는 간단한 프로세스 때문에 주로 Pandas AI를 사용하고 싶습니다. 패키지는 복잡한 코드 없이 간단한 프롬프트를 사용하여 자동으로 데이터를 분석할 수 있습니다.
소개는 충분합니다. 실습에 들어가 보겠습니다.
먼저, 다른 것보다 먼저 패키지를 설치해야 합니다.
pip install pandasai
다음으로 Pandas AI에 사용하려는 LLM을 설정해야 합니다. OpenAI GPT 및 HuggingFace와 같은 몇 가지 옵션이 있습니다. 그러나 이 튜토리얼에서는 OpenAI GPT를 사용합니다.
OpenAI 모델을 Pandas AI로 설정하는 것은 간단하지만 OpenAI API 키가 필요합니다. 가지고 있지 않다면, 당신은 그들에게 갈 수 있습니다 웹 사이트.
모든 것이 준비되었으면 아래 코드를 사용하여 Pandas AI LLM을 설정해 보겠습니다.
from pandasai.llm import OpenAI
llm = OpenAI(api_token="Your OpenAI API Key")
이제 Pandas AI를 사용하여 데이터 분석을 수행할 준비가 되었습니다.
Pandas AI를 사용한 데이터 탐색
샘플 데이터 세트로 시작하여 Pandas AI를 사용하여 데이터 탐색을 시도해 보겠습니다. 이 예에서는 Seaborn 패키지의 Titanic 데이터를 사용하겠습니다.
import seaborn as sns
from pandasai import SmartDataframe
data = sns.load_dataset('titanic')
df = SmartDataframe(data, config = {'llm': llm})
Pandas AI를 시작하려면 이를 Pandas AI 스마트 데이터 프레임 개체에 전달해야 합니다. 그런 다음 DataFrame에서 대화 활동을 수행할 수 있습니다.
간단한 질문을 해보자.
response = df.chat("""Return the survived class in percentage""")
response
생존한 승객의 비율은 38.38%입니다.
프롬프트에서 Pandas AI는 솔루션을 제시하고 우리의 질문에 답변할 수 있습니다.
DataFrame 개체에서 답변을 제공하는 Pandas AI 질문을 할 수 있습니다. 예를 들어, 다음은 데이터 분석을 위한 몇 가지 프롬프트입니다.
#Data Summary
summary = df.chat("""Can you get me the statistical summary of the dataset""")
#Class percentage
surv_pclass_perc = df.chat("""Return the survived in percentage breakdown by pclass""")
#Missing Data
missing_data_perc = df.chat("""Return the missing data percentage for the columns""")
#Outlier Data
outlier_fare_data = response = df.chat("""Please provide me the data rows that
contains outlier data based on fare column""")
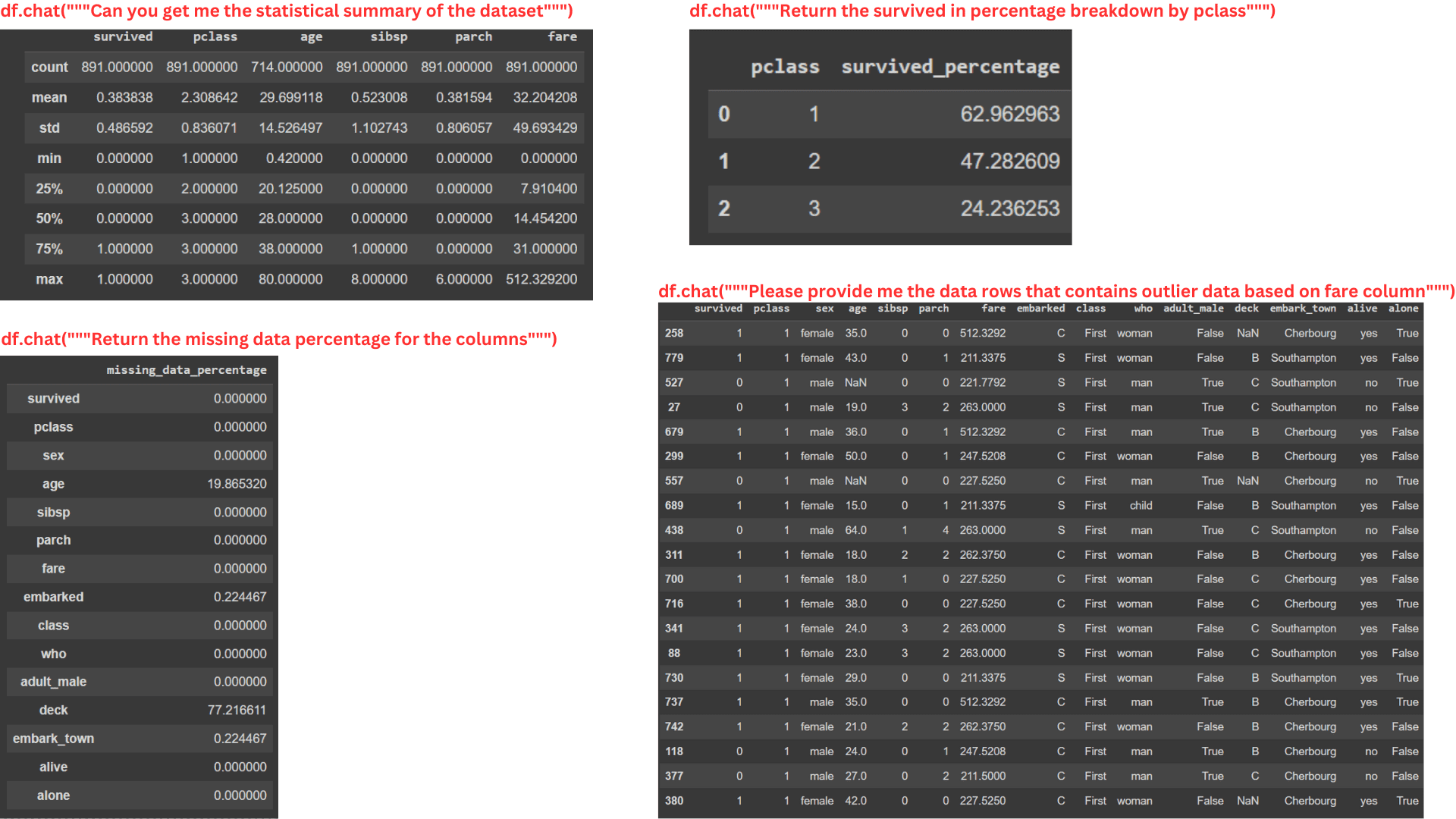
작성자 별 이미지
위 이미지를 보면 프롬프트가 매우 복잡하더라도 Pandas AI가 DataFrame 개체를 통해 정보를 제공할 수 있다는 것을 알 수 있습니다.
그러나 Pandas AI는 패키지가 SmartDataFrame 개체에 전달되는 LLM으로 제한되므로 너무 복잡한 계산을 처리할 수 없습니다. 앞으로 LLM 기능이 발전함에 따라 Pandas AI가 훨씬 더 자세한 분석을 처리할 수 있을 것이라고 확신합니다.
Pandas AI를 사용한 데이터 시각화
Pandas AI는 데이터 탐색에 유용하며 데이터 시각화를 수행할 수 있습니다. 프롬프트를 지정하는 한 Pandas AI는 시각화 출력을 제공합니다.
간단한 예를 들어보겠습니다.
response = df.chat('Please provide me the fare data distribution visualization')
response
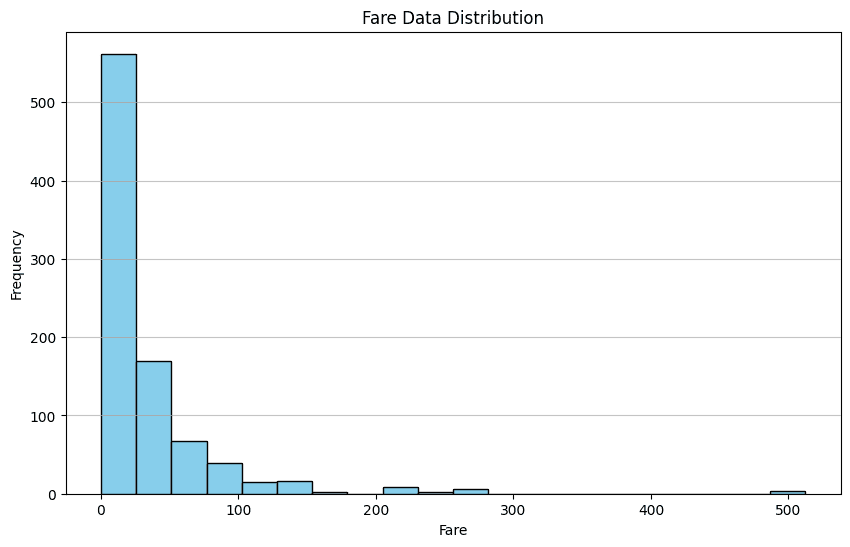
작성자 별 이미지
위 예에서는 Pandas AI에 Fare 열의 분포를 시각화하도록 요청합니다. 출력은 데이터 세트의 막대 차트 분포입니다.
데이터 탐색과 마찬가지로 모든 종류의 데이터 시각화를 수행할 수 있습니다. 그러나 Pandas AI는 여전히 더 복잡한 시각화 프로세스를 처리할 수 없습니다.
다음은 Pandas AI를 사용한 데이터 시각화의 다른 예입니다.
kde_plot = df.chat("""Please plot the kde distribution of age column and separate them with survived column""")
box_plot = df.chat("""Return me the box plot visualization of the age column separated by sex""")
heat_map = df.chat("""Give me heat map plot to visualize the numerical columns correlation""")
count_plot = df.chat("""Visualize the categorical column sex and survived""")
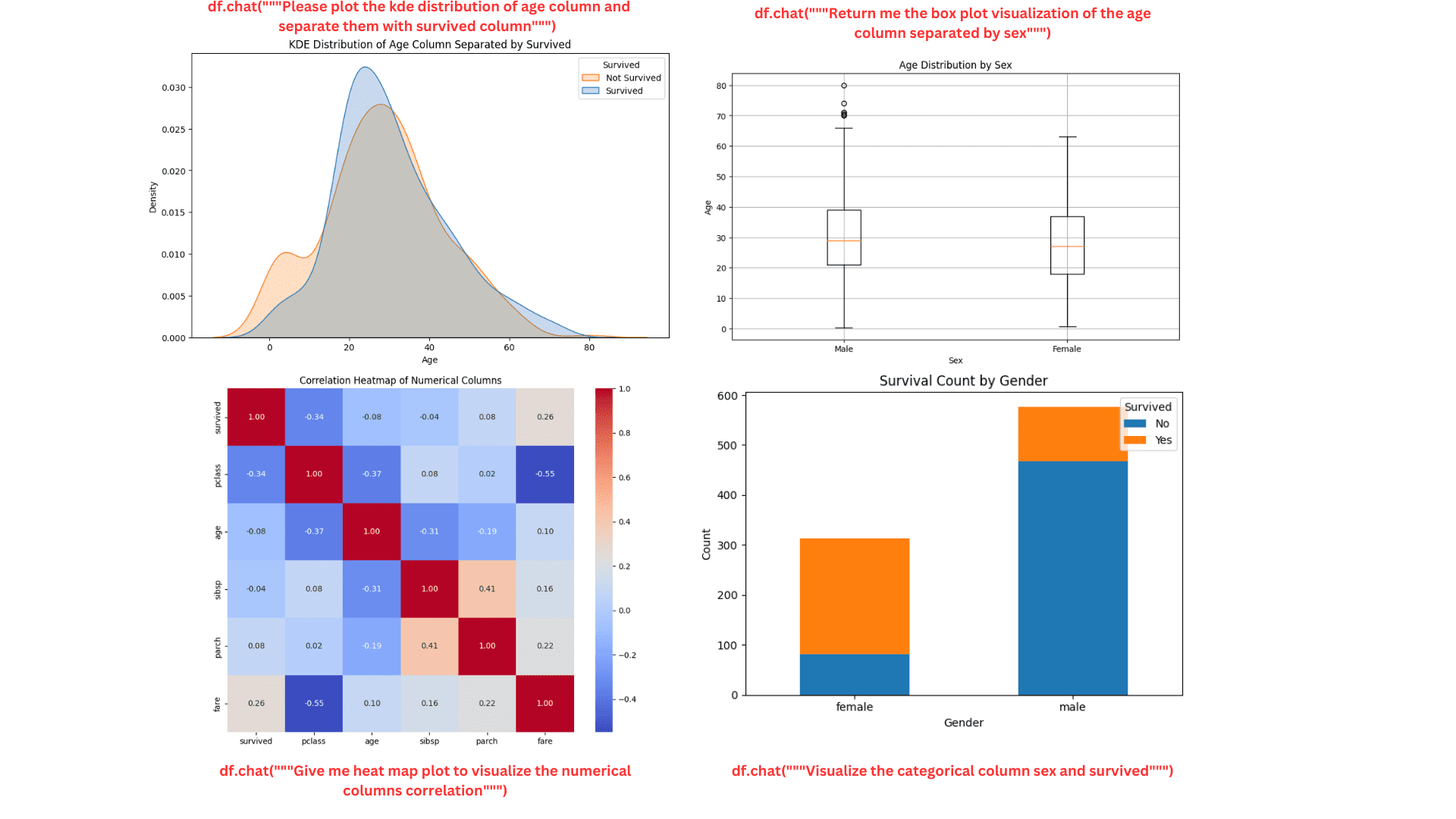
작성자 별 이미지
줄거리는 멋지고 깔끔해 보입니다. 필요한 경우 Pandas AI에 계속해서 자세한 내용을 요청할 수 있습니다.
Pandas AI, 활용도 향상
Pandas AI의 여러 내장 API를 사용하여 Pandas AI 경험을 향상할 수 있습니다.
캐시 지우기
기본적으로 Pandas AI 개체의 모든 프롬프트와 결과는 로컬 디렉터리에 저장되어 처리 시간을 줄이고 Pandas AI가 모델을 호출하는 데 필요한 시간을 단축합니다.
그러나 이 캐시는 과거 결과를 고려할 때 Pandas AI 결과를 관련성이 없게 만들 수 있습니다. 그렇기 때문에 캐시를 지우는 것이 좋습니다. 다음 코드를 사용하여 지울 수 있습니다.
import pandasai as pai
pai.clear_cache()
처음에 캐시를 끌 수도 있습니다.
df = SmartDataframe(data, {"enable_cache": False})
이런 방식으로 처음부터 프롬프트나 결과가 저장되지 않습니다.
커스텀 헤드
샘플 헤드 DataFrame을 Pandas AI에 전달할 수 있습니다. 일부 개인 데이터를 LLM과 공유하고 싶지 않거나 Pandas AI에 예시를 제공하려는 경우에 유용합니다.
그렇게 하려면 다음 코드를 사용할 수 있습니다.
from pandasai import SmartDataframe
import pandas as pd
# head df
head_df = data.sample(5)
df = SmartDataframe(data, config={
"custom_head": head_df,
'llm': llm
})Pandas AI 기술 및 에이전트
Pandas AI를 사용하면 사용자가 예제 기능을 전달하고 에이전트 결정에 따라 실행할 수 있습니다. 예를 들어 아래 함수는 두 개의 서로 다른 DataFrame을 결합하고 Pandas AI 에이전트가 실행할 샘플 플롯 함수를 전달합니다.
import pandas as pd
from pandasai import Agent
from pandasai.skills import skill
employees_data = {
"EmployeeID": [1, 2, 3, 4, 5],
"Name": ["John", "Emma", "Liam", "Olivia", "William"],
"Department": ["HR", "Sales", "IT", "Marketing", "Finance"],
}
salaries_data = {
"EmployeeID": [1, 2, 3, 4, 5],
"Salary": [5000, 6000, 4500, 7000, 5500],
}
employees_df = pd.DataFrame(employees_data)
salaries_df = pd.DataFrame(salaries_data)
# Function doc string to give more context to the model for use of this skill
@skill
def plot_salaries(names: list[str], salaries: list[int]):
"""
Displays the bar chart having name on x-axis and salaries on y-axis
Args:
names (list[str]): Employees' names
salaries (list[int]): Salaries
"""
# plot bars
import matplotlib.pyplot as plt
plt.bar(names, salaries)
plt.xlabel("Employee Name")
plt.ylabel("Salary")
plt.title("Employee Salaries")
plt.xticks(rotation=45)
# Adding count above for each bar
for i, salary in enumerate(salaries):
plt.text(i, salary + 1000, str(salary), ha='center', va='bottom')
plt.show()
agent = Agent([employees_df, salaries_df], config = {'llm': llm})
agent.add_skills(plot_salaries)
response = agent.chat("Plot the employee salaries against names")
에이전트는 우리가 Pandas AI에 할당한 기능을 사용해야 할지 여부를 결정합니다.
Skill과 Agent를 결합하면 DataFrame 분석에 대해 보다 제어 가능한 결과를 얻을 수 있습니다.
우리는 Pandas AI를 사용하여 데이터 분석 작업을 돕는 것이 얼마나 쉬운지 배웠습니다. LLM의 힘을 활용하면 데이터 분석 작업의 코딩 부분을 제한하고 대신 중요한 작업에 집중할 수 있습니다.
이 글에서는 Pandas AI를 설정하는 방법, Pandas AI를 사용하여 데이터 탐색 및 시각화를 수행하는 방법, 사전 사용법을 배웠습니다. 패키지로 더 많은 일을 할 수 있으니 다음 사이트를 방문하세요. 선적 서류 비치 더 자세히 알아보기 위해.
코넬리우스 유다 위자야 데이터 과학 보조 관리자이자 데이터 작성자입니다. Allianz Indonesia에서 풀타임으로 일하는 동안 그는 소셜 미디어와 글쓰기 미디어를 통해 Python과 데이터 팁을 공유하는 것을 좋아합니다. Cornellius는 다양한 AI 및 기계 학습 주제에 대해 글을 씁니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/utilizing-pandas-ai-for-data-analysis?utm_source=rss&utm_medium=rss&utm_campaign=utilizing-pandas-ai-for-data-analysis

