LLM 評価の将来は、ベンチマークよりもソフトウェア テストに似ています。 実際のテストの様子 このような、LLM に次のようなお父さんジョークを作成するように依頼します。 重力についての本を読んでいるのですが、それを手放すのは不可能です.
によって公開されているような機械学習ベンチマーク 先週の Gemini2 についての Googleまたは 適合率と再現率 犬と猫の写真を分類するため、または BLUE 機械翻訳を測定するためのスコアは、相対的なモデルのパフォーマンスの高レベルの比較を提供します。
しかし、製品チームが LLM 対応製品が実際の環境で適切に動作することに満足するには、これだけでは十分ではありません。
LLM は扱いが難しいです。 同じまたは類似の入力に対して常に同じ答えが得られるとは限りません。 1 は 4 よりも大きい値にすることができます。。 これを非決定論といいます。
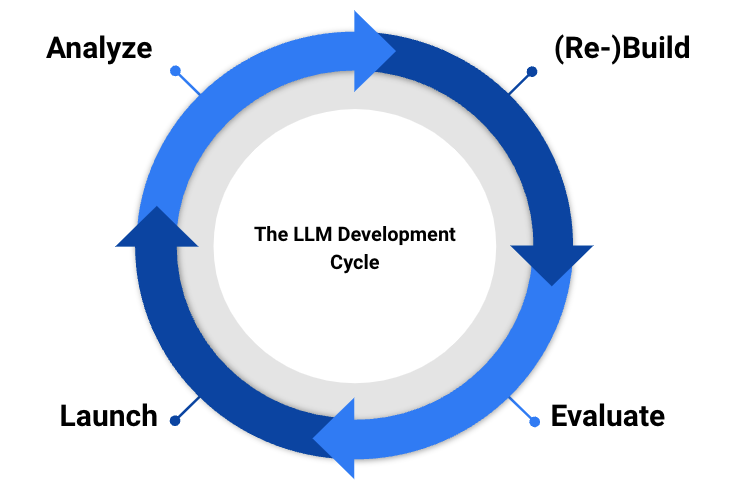
この問題を解決するには?
高品質の LLM 製品を生産するには、チームは次のことを行う必要があります。 分析と評価を組み合わせる.
分析と評価を組み合わせることがパフォーマンスを向上させる鍵となります。 分析は、モデルを使用するときにユーザーが抱く質問を明らかにします。
これらの質問によって、製品チームがパフォーマンスを決定するために使用する評価が作成されます。 追加データを収集し、モデルを再トレーニング/微調整して、再度リリースします。
現在、評価はルールベースまたは人間参加型の評価になっています。 しかし将来的には、時間の経過とともに一貫性を確保するために、他のモデルが出力を判断するようになるでしょう。
また、イテレーション ホイールが改善され、モデルからのお父さんのジョークが本当に最高であることが保証されます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.tomtunguz.com/how-good-is-your-ml-model/

