
最近、私は NLP ハカソン「研究記事のトピック モデリング 2.0」に参加しました。 このハッカソンを主催したのは、 分析Vidhya プラットフォームの一部として ハックライブ 主導権。 参加者は2時間のライブセッションで専門家の指導を受け、その後、XNUMX週間の競争をしてリーダーボードを駆け上がる時間が与えられました。
問題提起
研究論文のセットの要約が与えられた場合、タスクはテスト セットに含まれる各論文のタグを予測することです。

研究論文の要約は、コンピュータ サイエンス、数学、物理学、統計の 4 つのトピックから引用されています。 各記事には、数論、アプリケーション、人工知能、銀河の天体物理学、情報理論、材料科学、機械学習などの 25 個のタグのうち複数のタグを付けることができます。 提出物は次のように評価されます マイクロF1スコア テスト セット内の各記事の予測タグと観測タグの間。

問題ステートメントを完了すると、データセットが利用可能になります こちら.
早速、コードを始めてみましょう。
データのロードと探索
必要なライブラリをインポートする —
%matplotlib インライン import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns #---------------------------- ------- from nltk.tokenize import word_tokenize from nltk.stem import PorterStemmer #---------------------------- ----- sklearn.feature_extraction.text から CountVectorizer をインポート sklearn.feature_extraction.text からインポート TfidfVectorizer #---------------------------- ------- sklearnから sklearn.metricsからメトリクスをインポート sklearn.metricsからaccuracy_scoreをインポート f1_scoreをインポート
からトレーニング データとテスト データをロードします。csvファイル Pandas DataFrame へのファイル —
train_data = pd.read_csv('Train.csv') test_data = pd.read_csv('Test.csv')
データ形状のトレーニングとテスト —
print(“トレインサイズ:”, train_data.shape) print(“テストサイズ:”, test_data.shape)
出力:
![]()
トレーニング データセットには最大 14 個のデータポイントがあり、テスト セットには最大 6 個のデータポイントがあります。 トレーニングおよびテスト データセットの概要 —
train_data.info()
出力:

test_data.info()
出力:
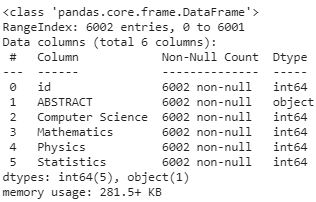
トレーニング データ情報からわかるように、列は 31 列あります。ID 用に 1 列、抽象テキスト用に 1 列、トピック用に 4 列あります。これらはすべて特徴変数を形成し、次の 25 列はクラス ラベルです。予測タスクを「学習」します。
topic_cols = ['コンピュータサイエンス'、'数学'、'物理学'、'統計'】
target_cols = ['偏微分方程式の分析'、'アプリケーション'、'人工知能'、'銀河の天体物理学'、'計算と言語'、'コンピュータビジョンとパターン認識'、'宇宙論と非銀河天体物理学'、'データ構造とアルゴリズム、「微分幾何学」、「地球惑星天体物理学」、「流体力学」、「情報理論」、「天体物理学の機器と方法」、「機械学習」、「材料科学」、「方法論」、「数論」 、「最適化と制御」、「表現理論」、「ロボット工学」、「社会および情報ネットワーク」、「統計理論」、「強相関電子」、「超伝導」、「システムと制御」]
複数のタグを持つデータポイントはいくつありますか?
my_list = [] for i in range(train_data.shape[0]): my_list.append(sum(train_data.iloc[i, 6:])) pd.Series(my_list).value_counts()
出力:

したがって、ほとんどの研究論文には 1 つまたは 2 つのタグが付いています。
OneVsRest Classifier のデータ クリーニングと前処理
データのクリーニングと前処理に進む前に、概要を把握するために、まずトレーニング データからランダムなサンプルをいくつか出力して観察することをお勧めします。 私の観察に基づいて、テキスト データのクリーニングと前処理のために以下のパイプラインを構築しました。
縮約解除 → 特殊文字の削除 → ストップワードの削除 → ステミング
まず、テキスト処理に必要ないくつかのヘルパー関数を定義します。
英語のフレーズを解体する —
def decontracted(phrase): #特定のフレーズ = re.sub(r「しない」, 「しない」, フレーズ) フレーズ = re.sub(r「できない」, 「できない」, フレーズ) # 一般的なフレーズ= re.sub(r"n't", " not", フレーズ) フレーズ = re.sub(r"'re", "are", フレーズ) フレーズ = re.sub(r"'s", " は”, フレーズ) フレーズ = re.sub(r”'d”, “ would”, フレーズ) フレーズ = re.sub(r”'ll”, “will”, フレーズ) フレーズ = re.sub(r”'t ”, “ not”, フレーズ) フレーズ = re.sub(r”'ve”, “ have”, フレーズ) フレーズ = re.sub(r”'m”, “ am”, フレーズ) フレーズ = re.sub( r"'em"、"them"、フレーズ) フレーズを返す
ストップワードを宣言する —
(私は、組み込みのものよりも独自のカスタム ストップワード セットを好みます。これは、問題に応じてストップワード セットを簡単に変更するのに役立ちます)
ストップワード = ['i'、'me'、'my'、'myself'、'we'、'our'、'ours'、'ourselves'、'you'、"you're"、"you've" 、「あなたはするでしょう」、「あなたがしたでしょう」、「あなたの」、「あなたの」、「あなた自身」、「あなた自身」、「彼」、「彼」、「彼」、「彼自身」、「彼女」、「彼女は」、「彼女」、「彼女の」、「彼女自身」、「それ」、「それは」、「それ」、「それ自体」、「彼ら」、「彼ら」、「彼らの」、「彼らの」、「彼ら自身」 、「何を」、「どの」、「誰が」、「誰が」、「これ」、「あれ」、「それは」、「これら」、「それら」、「午前」、「である」、「である」 、「だった」、「いた」、「である」、「いた」、「いる」、「持っている」、「持っている」、「持っていた」、「持っている」、「する」、「する」、「した」、 「やっている」、「a」、「an」、「the」、「and」、「but」、「if」、「or」、「 because」、「as」、「until」、「while」、「of」 、「で」、「によって」、「のために」、「とともに」、「約」、「反対」、「間」、「中へ」、「を通じて」、「中」、「前」、「後」、上」、「下」、「へ」、「から」、「上」、「下」、「中」、「外」、「オン」、「オフ」、「上」、「下」、「再び」 、「さらに」、「その後」、「一度」、「ここ」、「そこ」、「いつ」、「どこで」、「なぜ」、「どのように」、「すべて」、「いずれか」、「両方」、 「それぞれ」、「少し」、「もっと」、「ほとんど」、「その他」、「いくつか」、「そのような」、「のみ」、「自分の」、「同じ」、「だから」、「よりも」、「あまりにも」 、「とても」、「s」、「t」、「できる」、「する」、「ちょうど」、「しない」、「しない」、「すべき」、「すべきだった」、「今」、 d'、'll'、'm'、'o'、're'、've'、'y'、'ain'、'aren'、「ない」、「できる」、「できない」 、「した」、「しなかった」、「しなかった」、「しなかった」、「していた」、「しなかった」、「しなかった」、「しなかった」、「しなかった」、「しなかった」 、「です」、「ありません」、「ま」、「かもしれない」、「かもしれない」、「しなければなりません」、「してはならない」、「必要です」、「必要ありません」、「シャン」、「 「してはならない」、「すべきだった」、「すべきではなかった」、「だった」、「ではなかった」、「だった」、「しなかった」、「勝った」、「しないだろう」、「だろう」、「そうはしないだろう」]
または、ストップワードを直接インポートすることもできます。 単語の雲 API —
from wordcloud import WordCloud、STOPWORDS stopwords = set(list(STOPWORDS))
Porter ステマーを使用したステミング —
def Stemming(sentence): token_words = word_tokenize(sentence) stop_sentence = [] token_words 内の単語: Stemmer = PorterStemmer() Stemmer.stem(word)) Stem_sentence.append(" ") return "".join(ステム_センテンス)
すべての関数を定義したので、テキスト前処理パイプラインを作成しましょう。
def text_preprocessing(text): preprocessed_abstract = [] テキスト内の文: send = decontracted(sentence) send = re.sub('[^A-Za-z0–9]+', ' ', send) send = ' ' .join(e. lower() for e in send.split() if e. lower() not in stopwords) send = Stemming(sent) preprocessed_abstract.append(sent.strip()) return preprocessed_abstract
列車データの抽象テキストの前処理 -
train_data['preprocessed_abstract'] = text_preprocessing(train_data['ABSTRACT'].values) train_data[['ABSTRACT', 'preprocessed_abstract']].head()
出力:

同様に、テスト データセットの前処理 –
test_data['preprocessed_abstract'] = text_preprocessing(test_data['ABSTRACT'].values) test_data[['ABSTRACT', 'preprocessed_abstract']].head()
出力:

元の 'ABSTRACT' 列はもう必要ありません。 この列をデータセットから削除できます。
テキストデータのエンコーディング
トレーニング データをトレーニング データセットと検証データセットに分割する —
X = train_data[['コンピュータサイエンス', '数学', '物理学', '統計', 'preprocessed_abstract']] y = train_data[target_cols] from sklearn.model_selection import train_test_split X_train, X_cv, y_train, y_cv = train_test_split(X 、y、test_size = 0.25、random_state = 21) print(X_train.shape, y_train.shape) print(X_cv.shape, y_cv.shape)
出力:
![]()
ご覧のとおり、トレーニング セットには約 10500 個のデータポイントがあり、検証セットには約 3500 個のデータポイントがあります。
テキストデータのTF-IDFベクトル化
語彙を構築する —
combined_vocab = list(train_data['preprocessed_abstract']) + list(test_data['preprocessed_abstract'])
そう、ここで私は故意に罪を犯しました! 語彙を構築するための完全なトレーニング データとテスト データを使用して、モデルをトレーニングしました。 理想的には、モデルがテスト データを参照しないようにする必要があります。
Vectorizer = TfidfVectorizer(min_df = 5, max_df = 0.5, sublinear_tf = True, ngram_range = (1, 1)) Vectorizer.fit(combined_vocab)
X_train_tfidf = Vectorizer.transform(X_train['preprocessed_abstract']) X_cv_tfidf = Vectorizer.transform(X_cv['preprocessed_abstract'])
print(X_train_tfidf.shape, y_train.shape) print(X_cv_tfidf.shape, y_cv.shape)
出力:
![]()
TF-IDF エンコード後、9136 個の特徴が得られ、それぞれが語彙内の個別の単語に対応します。
ここで知っておくべき重要なこと —
- 私は、TF-IDF ベクトル化を採用すべきだという結論に直接至ったわけではありません。 BOW、事前トレーニング済み GloVe モデルを使用した W2V など、さまざまな方法を試しました。その中で、TF-IDF が最もパフォーマンスが優れていることが判明したので、ここではこれのみをデモします。
- 私には、uni-gram を使用するべきだと魔法のようには思えませんでした。 バイグラム、トリグラム、さらにはXNUMXグラムも試しました。 ユニグラムを採用したモデルがすべての中で最高のパフォーマンスを示しました。
テキストデータのエンコードは難しいものです。 特に競技では、パフォーマンス指標の 0.001 の差でも、リーダーボードで数順位後退する可能性があります。 したがって、初歩的な段階では、さまざまな順列や組み合わせを積極的に試してみる必要があります。
モデリングを進める前に、トレーニング データセットとテスト データセットの両方について、すべての特徴 (トピック特徴 + TF-IDF エンコードされたテキスト特徴) をそれぞれスタックします。
scipy.sparse からインポート hstack X_train_data_tfidf = hstack((X_train[topic_cols], X_train_tfidf)) X_cv_data_tfidf = hstack((X_cv[topic_cols], X_cv_tfidf))
OneVsRest Classifier を使用したマルチラベル分類
これまでは、特徴変数の調整とベクトル化のみを扱っていました。 ご存知のとおり、これはマルチラベル分類の問題であり、各ドキュメントには 2 つ以上の事前定義されたタグが同時に存在する可能性があります。 いくつかのデータポイントに 3 つまたは XNUMX つのタグがあることはすでに確認しました。
従来の機械学習アルゴリズムのほとんどは、単一ラベルの分類問題向けに開発されています。 したがって、文献にある多くのアプローチは、既存の単一ラベル アルゴリズムを使用できるように、マルチラベル問題を複数の単一ラベル問題に変換します。
そのようなテクニックの XNUMX つが、 XNUMX 対残り (OvR) マルチクラス/マルチラベル分類子、別名 一対全員。 OneVsRest Classifier では、クラスごとに XNUMX つの分類子を適合させます。これは、マルチクラス/マルチラベル分類に最も一般的に使用される戦略であり、公正なデフォルトの選択です。 各分類子について、そのクラスは他のすべてのクラスに対して適合されます。 計算効率に加えて、このアプローチの利点の XNUMX つは、その解釈可能性です。 各クラスは XNUMX つの分類子のみで表されるため、対応する分類子を検査することでクラスに関する知識を得ることができます。
最適なハイパーパラメータ「C」を探してみましょう —
(「C」は正則化強度の逆数を示します。値が小さいほど、より強い正則化を指定します)。
sklearn.multiclass から OneVsRestClassifier をインポート sklearn.linear_model からインポート LogisticRegression
C_range = [0.01, 0.1, 1, 10, 100] for i for C_range: clf = OneVsRestClassifier(LogisticRegression(C = i,solver = 'sag')) clf.fit(X_train_data_tfidf, y_train) y_pred_train = clf.predict(X_train_data_tfidf) ) y_pred_cv = clf.predict(X_cv_data_tfidf) f1_score_train = f1_score(y_train, y_pred_train, Average = 'micro') f1_score_cv = f1_score(y_cv, y_pred_cv, Average = 'micro') print(“C:”, i, “トレーニングスコア: ”,f1_score_train, “CVスコア:”, f1_score_cv) print(”-”*50)
出力:

C = 10 で最高の検証スコアが得られることがわかります。しかし、ここでのトレーニング スコアも非常に高く、これはある程度の予想通りでした。
ハイパーパラメータをさらに調整しましょう —
sklearn.multiclass からインポート OneVsRestClassifier sklearn.linear_model からインポート LogisticRegressionC_range = [10, 20, 40, 70, 100] for i in C_range: clf = OneVsRestClassifier(LogisticRegression(C = i,solver = 'sag')) clf.fit( X_train_data_tfidf, y_train) y_pred_train = clf.predict(X_train_data_tfidf) y_pred_cv = clf.predict(X_cv_data_tfidf) f1_score_train = f1_score(y_train, y_pred_train, 平均 = 'micro') f1_score_cv = f1_score(y_cv, y_pre d_cv, 平均 = 'マイクロ') print( "C:", i, "トレーニングスコア:",f1_score_train, "CV スコア:", f1_score_cv) print("- "*50)
出力:

C = 20 のモデルは、検証セットで最高のスコアを与えます。 したがって、さらに進んで、C = 20 とします。
お気づきかと思いますが、ここでは、L2、L2、およびエラスティック ネット ミキシングの中で L1 を使用したモデルが最良の結果をもたらしたため、ここでは正則化にデフォルトの L2 ペナルティを使用しています。
OneVsRest 分類子の適切なしきい値の決定
バイナリ分類アルゴリズムのデフォルトのしきい値は 0.5 です。 ただし、最大化しようとしているデータとパフォーマンス指標を考慮すると、これは最適なしきい値ではない可能性があります。 ご存知のとおり、F1 スコアは次の式で与えられます。
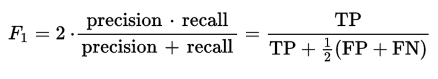
(個別のラベルごとに) 適切なしきい値は、F1 スコアを最大化するしきい値になります。
def get_best_thresholds(true, pred): しきい値 = [i/100 for i in range(100)] best_thresholds = [] for idx in range(25): f1_scores = [f1_score(true[:, idx], (pred[: 、idx] > thresh) * 1) しきい値のしきい値の場合] best_thresh = Thresholds[np.argmax(f1_scores)] best_thresholds.append(best_thresh) return best_thresholds
簡単に言うと、上記の関数が行うことは、25 のクラス ラベルのそれぞれについて、1 個のしきい値のそれぞれに対応する F1 スコアを計算し、指定されたクラス ラベルの最大 FXNUMX スコアを返すしきい値を選択することです。
個々の F1 スコアが高ければ、ミクロ平均 F1 も高くなります。 しきい値を取得しましょう —
clf = OneVsRestClassifier(LogisticRegression(C = 20,solver = 'sag')) clf.fit(X_train_data_tfidf, y_train) y_pred_train_proba = clf.predict_proba(X_train_data_tfidf) y_pred_cv_proba = clf.predict_proba(X_cv_data_tfidf) best_thresholds = get_best_thresholds(y_cv.values, y_pred_cv_proba ) print(best_thresholds)
出力:
[0.45、0.28、0.19、0.46、0.24、0.24、0.24、0.28、0.22、0.2、0.22、0.24、0.24、0.41、0.32、0.15、0.21、0.33、0.33、0.29、0.16. 0.66、0.33、0.36、0.4、XNUMX 】
ご覧のとおり、クラス ラベルごとに個別のしきい値が取得されました。 これらと同じ値を最終的な OneVsRest 分類子モデルで使用します。 上記のしきい値を使用して予測を行う —
y_pred_cv = np.empty_like(y_pred_cv_proba)for i、enumerate(best_thresholds) の thresh: y_pred_cv[:, i] = (y_pred_cv_proba[:, i] > thresh) * 1 print(f1_score(y_cv, y_pred_cv, Average = 'micro') ))
出力:
0.7765116517811312
したがって、可変閾値を使用して、大幅に優れたスコアを取得することができました。
これまでのところ、検証セットに対してハイパーパラメータ調整を実行し、最適なハイパーパラメータ (C = 20) を取得することができました。 また、しきい値を微調整し、F1 スコアが最大となる適切なしきい値のセットを取得しました。
OneVsRest Classifier を使用したテスト データの予測の作成
上記のパラメーターを使用して、トレーニング データ全体で本格的なモデルのトレーニングを構築し、テスト データで予測を行ってみましょう。
# データの学習とテスト X_tr = train_data[['Computer Science', 'Mathematics', 'Physics', 'Statistics', 'preprocessed_abstract']] y_tr = train_data[target_cols] X_te = test_data[['Computer Science', 'Mathematics] ', 'Physics', 'Statistics', 'preprocessed_abstract']] # テキスト データのエンコーディング Vectorizer.fit(combined_vocab) X_tr_tfidf = Vectorizer.transform(X_tr['preprocessed_abstract']) X_te_tfidf = Vectorizer.transform(X_te['preprocessed_abstract'] ) # スタッキング X_tr_data_tfidf = hstack((X_tr[topic_cols], X_tr_tfidf)) X_te_data_tfidf = hstack((X_te[topic_cols], X_te_tfidf)) # モデリングと最良のしきい値を使用した予測の作成 clf = OneVsRestClassifier(LogisticRegression(C = 20)) clf. fit(X_tr_data_tfidf, y_tr) y_pred_tr_proba = clf.predict_proba(X_tr_data_tfidf) y_pred_te_proba = clf.predict_proba(X_te_data_tfidf) y_pred_te = np.empty_like(y_pred_te_proba) for i、enumerate(best_thresholds) のしきい値: y_pred_te[:, i] = (y_pred_te_proba[ :, i] > thresh) * 1
テスト予測を取得したら、(サンプル提出ファイルのように) それぞれの ID に添付し、指定された形式で提出します。
ss = pd.read_csv('SampleSubmission.csv') ss[target_cols] = y_pred_te ss.to_csv('LR_tfidf10k_L2_C20.csv'、インデックス = False)
ハッカソンに参加する最も良い点は、さまざまなテクニックを試すことができることです。これにより、将来同じような問題に遭遇したときに、何が機能し、何が機能しないのかを正確に理解できるようになります。 また、ディスカッションに積極的に参加することで、他の参加者から多くのことを学ぶことができます。
あなたは完全なコードを見つけることができます こちら 私のGitHubプロフィールにあります。
著者について
プラティック・ナブリヤ 現在、ノイダを拠点とする分析および AI 会社に勤務している熟練したデータ プロフェッショナルです。 彼は機械学習、深層学習、NLP、時系列分析、SQL、データ操作と視覚化に熟練しており、クラウド環境での作業に精通しています。 余暇には、ハッカソンに参加したり、データとファイナンスの交差点でブログや記事を書いたりすることが大好きです。
PlatoAi。 Web3の再考。 増幅されたデータインテリジェンス。
アクセスするには、ここをクリックしてください。

