Rayを使用して最初の分散Pythonアプリケーションを作成する
Rayを使用すると、順次実行されるPythonコードを取得して、最小限のコード変更で分散アプリケーションに変換できます。 Rayを使用する理由と、開始方法については、以下をお読みください。
By マイケル・ガラニク、データサイエンスプロフェッショナル

Rayは、並列分散コンピューティングをあなたが望むように機能させます(画像ソース)
レイ は高速でシンプルな分散実行フレームワークであり、アプリケーションのスケーリングと最先端の機械学習ライブラリの活用を容易にします。 Rayを使用すると、順次実行されるPythonコードを取得して、最小限のコード変更で分散アプリケーションに変換できます。
このチュートリアルの目的は、以下を調査することです。
- Rayと並列化して配布する必要があるのはなぜですか
- Rayを使い始める方法
- 分散コンピューティングのトレードオフ(計算コスト、メモリ、I / Oなど)
なぜレイと並列化して配布する必要があるのですか?
として 以前の投稿が指摘した、並列および分散コンピューティングは、最新のアプリケーションの定番です。 問題は、既存のPythonコードを取得して並列化または配布しようとすると、既存のコードを最初から書き直すことになる可能性があることです。 さらに、最新のアプリケーションには、既存のモジュールのような要件があります マルチプロセッシング 足らない。 これらの要件は次のとおりです。
- 複数のマシンで同じコードを実行する
- 状態があり、通信できるマイクロサービスとアクターの構築
- マシンの障害とプリエンプションの適切な処理
- 大きな物体や数値データの効率的な処理
Rayライブラリはこれらの要件を満たし、アプリケーションを書き直さずにスケーリングできます。 並列分散コンピューティングをシンプルにするために、Rayは関数とクラスを受け取り、それらをタスクとアクターとして分散設定に変換します。 このチュートリアルの残りの部分では、これらの概念と、並列および分散アプリケーションを構築する際に考慮すべきいくつかの重要事項について説明します。

このチュートリアルでは、RayがプレーンなPythonコードの並列化を容易にする方法を探りますが、Rayとそのエコシステムにより、次のような既存のライブラリの並列化も容易になることに注意してください。 scikit-学ぶ, XGブースト, ライトGBM, パイトーチ、および大いに多く。
Rayを使い始める方法
Python関数をリモート関数に変換する(レイタスク)
Rayはpipを介してインストールできます。
pip install 'ray[default]'Rayタスクを作成してRayの旅を始めましょう。 これは、通常のPython関数を@ray.remoteで装飾することで実行できます。 これにより、ラップトップのCPUコア(またはRayクラスター)全体でスケジュールできるタスクが作成されます。
フィボナッチ数列(最初のXNUMXつ以降のすべての数が前のXNUMXつの数の合計であるという事実によって特徴付けられる整数列)を生成する以下のXNUMXつの関数について考えてみます。 XNUMXつ目は通常のPython関数で、XNUMXつ目はRayタスクです。
import os import time import ray#通常のPython def fibonacci_local(sequence_size):fibonacci = [] for i in range(0、sequence_size):if i 2:fibonacci.append(i)continue fibonacci.append(fibonacci [i-1] + fibonacci [i-2])return sequence_size#Ray task @ ray.remote def fibonacci_distributed(sequence_size):fibonacci = [] for i in range(0、sequence_size):if i 2:fibonacci.append(i)continuefibonacci。 append(fibonacci [i-1] + fibonacci [i-2])return sequence_size
これらのXNUMXつの機能に関して注意すべき点がいくつかあります。 まず、fibonacci_distributed関数の@ray.remoteデコレータを除いて同じです。
次に注意すべきことは、戻り値が小さいことです。 それらはフィボナッチ数列自体を返すのではなく、整数である配列サイズを返します。 これは重要です。分散関数は、大量のデータ(パラメーター)を必要とするか返すように設計することで、分散関数の価値を下げる可能性があるためです。 エンジニアは、これを分散関数の入出力(IO)と呼ぶことがよくあります。
ローカルパフォーマンスとリモートパフォーマンスの比較
このセクションの関数を使用すると、ローカルと並列の両方で複数の長いフィボナッチ数列を生成するのにかかる時間を比較できます。 以下の両方の関数は、システム内のCPUの数を返すos.cpu_count()を利用していることに注意することが重要です。
os.cpu_count()
このチュートリアルで使用されるマシンには8つのCPUがあります。つまり、以下の各関数はXNUMXつのフィボナッチ数列を生成します。
#通常のPython def run_local(sequence_size):start_time = time.time()results = [fibonacci_local(sequence_size)for _ in range(os.cpu_count())] duration = time.time()--start_time print('Sequence size: {}、ローカル実行時間:{}'。format(sequence_size、duration))#Ray def run_remote(sequence_size):#開始Ray ray.init()start_time = time.time()results = ray.get([fibonacci_distributed。 remote(sequence_size)for _ in range(os.cpu_count())])duration = time.time()-start_time print('シーケンスサイズ:{}、リモート実行時間:{}'。format(sequence_size、duration))
run_localとrun_remoteのコードがどのように機能するかを説明する前に、これらの関数の両方を実行して、ローカルとリモートの両方で複数の100000個のフィボナッチ数列を生成するのにかかる時間を確認しましょう。
run_local(100000)run_remote(100000)

run_remote関数は、複数のCPU間で計算を並列化したため、処理時間が短縮されました(1.76秒対4.20秒)。
RayAPI
run_remoteが高速である理由をよりよく理解するために、コードを簡単に調べて、途中でRayAPIがどのように機能するかを説明しましょう。

ray.init()コマンドは、関連するすべてのRayプロセスを開始します。 デフォルトでは、RayはCPUコアごとにXNUMXつのワーカープロセスを作成します。 クラスターでRayを実行する場合は、ray.init(address ='InsertAddressHere')のようなクラスターアドレスを渡す必要があります。

fibonacci_distributed.remote(100000)

fibonacci_distributed.remote(sequence_size)を呼び出すと、関数の戻り値ではなく、すぐにfutureが返されます。 実際の関数の実行はバックグラウンドで行われます。 すぐに戻るので、各関数呼び出しを並行して実行できます。 これにより、これらの複数の100000の長いフィボナッチ数列の生成にかかる時間が短縮されます。


ray.getは、タスクが完了すると、結果の値をタスクから取得します。
最後に、ray.init()を呼び出すプロセスが終了すると、Rayランタイムも終了することに注意することが重要です。 ray.init()を複数回実行しようとすると、RuntimeErrorが発生する可能性があることに注意してください(誤ってray.initをXNUMX回呼び出した可能性がありますか?)。 これは、を使用して解決できます ray.shutdown()
#Rayを明示的に停止または再起動するには、shutdown API ray.shutdown()を使用します
レイダッシュボード
Rayには、ray.init関数を呼び出した後、http://127.0.0.1:8265で利用できるダッシュボードが付属しています。
の間で 他のもの、ダッシュボードでは次のことができます。
- Rayのメモリ使用率を理解し、メモリエラーをデバッグします。
- アクターごとのリソース使用量、実行されたタスク、ログなどを参照してください。
- クラスタメトリックを表示します。
- 俳優を殺し、レイの仕事をプロファイリングします。
- エラーと例外を一目で確認できます。
- XNUMXつのペインで多数のマシンのログを表示します。
- 見る レイチューン 仕事とトライアル情報。
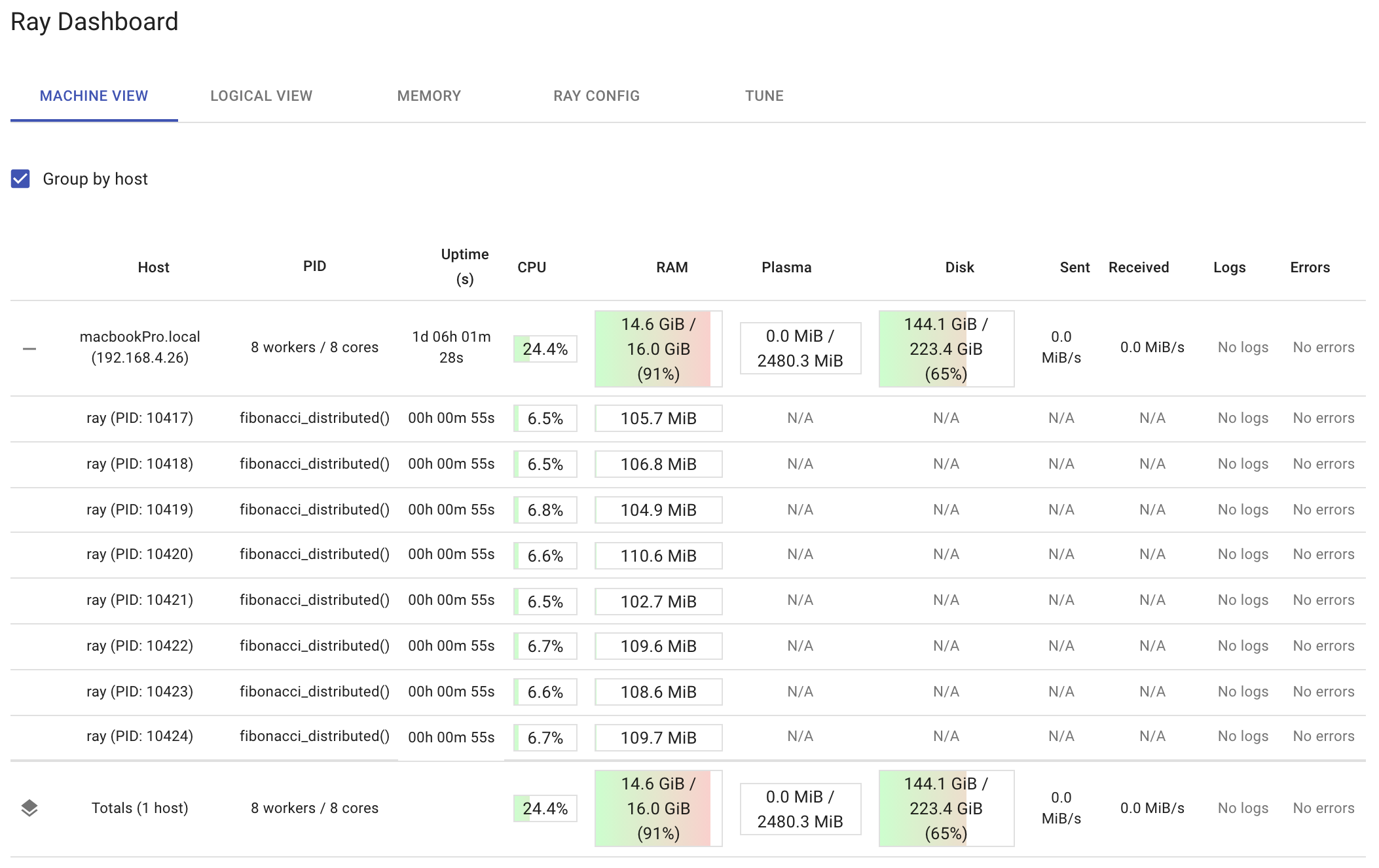
以下のダッシュボードは、run_remote(200000)を実行した後の、ノードごとおよびワーカーごとのリソース使用率を示しています。 ダッシュボードに、各ワーカーで実行されている関数fibonacci_distributedがどのように表示されているかに注目してください。 分散関数の実行中にそれらを観察することをお勧めします。 そうすれば、100人のワーカーがすべての作業を行っているのを見ると、ray.get関数を誤って使用している可能性があります。 また、合計CPU使用率がXNUMX%に近づいている場合は、実行しすぎている可能性があります。
分散コンピューティングのトレードオフ
このチュートリアルでは、コンピューティングとIOを微調整するためのいくつかのオプションを提供するため、フィボナッチ数列を使用しました。 シーケンスサイズを増減することで、各関数呼び出しに必要な計算量を変更できます。 シーケンスサイズが大きいほど、シーケンスを生成するために必要な計算量が多くなりますが、シーケンスサイズが小さいほど、必要な計算量は少なくなります。 分散する計算が小さすぎると、Rayのオーバーヘッドが合計処理時間を支配し、関数を分散しても何の価値も得られません。
IOは、関数を分散するときにも不可欠です。 これらの関数を変更して、計算したシーケンスを返す場合、シーケンスサイズが大きくなると、IOが大きくなります。 ある時点で、データの送信に必要な時間は、分散関数への複数の呼び出しを完了するために必要な合計時間の大半を占めることになります。 これは、関数をクラスターに分散する場合に重要です。 これにはネットワークを使用する必要があり、ネットワーク呼び出しは、このチュートリアルで使用されるプロセス間通信よりもコストがかかります。
したがって、分散フィボナッチ関数とローカルフィボナッチ関数の両方を試してみることをお勧めします。 リモート機能の恩恵を受けるために必要な最小シーケンスサイズを決定してみてください。 コンピューティングを理解したら、IOを試して、全体的なパフォーマンスがどうなるかを確認します。 分散アーキテクチャは、使用するツールに関係なく、大量のデータを移動する必要がない場合に最適に機能します。
幸い、Rayの主な利点は、オブジェクト全体をリモートで管理できることです。 これは、IOの問題を軽減するのに役立ちます。 次にそれを見てみましょう。
アクターとしてのリモートオブジェクト
RayがPython関数をタスクとして分散設定に変換するのと同じように、RayはPythonクラスをアクターとして分散設定に変換します。 Rayは、クラスのインスタンスを並列化できるようにするアクターを提供します。 コード的には、Pythonクラスに追加する必要があるのは、@ray.remoteデコレータをアクターにすることだけです。 そのクラスのインスタンスを作成すると、Rayは、クラスター内で実行され、オブジェクトのコピーを保持するプロセスである新しいアクターを作成します。
それらはリモートオブジェクトであるため、データを保持でき、メソッドはそのデータを操作できます。 これにより、プロセス間通信を削減できます。 データを返すタスクが多すぎる場合は、アクターの使用を検討してください。データは他のタスクに送信されます。
以下のアクターを見てみましょう。
コレクションからimportnamedtupleimport csv import tarfile import time import ray @ ray.remote class GSODActor():def __init __(self、year、high_temp):self.high_temp = float(high_temp)self.high_temp_count = None self.rows = [] self.stations=なしself.year=年defget_row_count(self):return len(self.rows)def get_high_temp_count(self):if self.high_temp_count is None:filtered = [l for l in self.rows if float(l .TEMP)> = self.high_temp] self.high_temp_count = len(filtered)return self.high_temp_count def get_station_count(self):return len(self.stations)def get_stations(self):return self.stations def get_high_temp_count(self、stations ):filtered_rows = [l for l in self.rows if float(l.TEMP)> = self.high_temp and l.STATION in station] return len(filtered_rows)def load_data(self):file_name = self.year+'。 tar.gz'row = namedtuple(' Row'、(' STATION'、' DATE'、' LATITUDE'、' LONGITUDE'、' ELEVATION'、' NAME'、' TEMP'、' TEMP_ATTRIBUTES'、' DEWP'、' DEWP_ATTRIBUTES'、' SLP'、' SLP_ATTRIBUTES '、' STP'、' STP_ATTRIBUTES'、' VISIB'、' VISIB_ATTRIBUTES'、' WDSP'、' WDSP_ATTRIBUTES'、' MXSPD'、' GUST'、' MAX'、' MAX_ATTRIBUTES'、' MIN'、' MIN_ATTRIBUTES'、 'PRCP'、'PRCP_ATTRIBUTES'、'SNDP'、'FRSHTT'))tar = tarfile.open(file_name、'r:gz')for member in tar.getmembers():member_handle = tar.extractfile(member)byte_data = member_handle.read()decode_string = byte_data.decode()lines = decode_string.splitlines()reader = csv.reader(lines、delimiter ='、')#メンバーのすべての行を取得します。 ヘッダーをスキップします。 _ = next(reader)file_rows = [row(* l)for l in reader] self.rows + = file_rows self.stations = {l.STATION for l in self.rows}
上記のコードを使用して、Global Surface Summary of the Day(GSOD)と呼ばれる公開データセットからデータを読み込んで操作できます。 データセットは米国海洋大気庁(NOAA)によって管理されており、米国海洋大気庁で無料で入手できます。 ウェブサイト。 NOAAは現在、世界中の9,000以上の観測所からのデータを維持しており、GSODデータセットにはこれらの観測所からの毎日の要約情報が含まれています。 1929年から2020年まで毎年XNUMXつのgzipファイルがあります。このチュートリアルでは、次のファイルをダウンロードするだけで済みます。 1980 & 2020.
このアクター実験の目標は、1980年と2020年の測定値が100度以上であったかどうかを計算し、2020年が1980年よりも極端な気温であったかどうかを判断することです。公正な比較を実装するには、1980年と2020年の両方に存在したステーションのみを使用する必要があります。考慮されます。 したがって、この実験のロジックは次のようになります。
- 1980年のデータをロードします。
- 2020年のデータをロードします。
- 1980年に存在したステーションのリストを取得します。
- 2020年に存在したステーションのリストを取得します。
- 駅の交差点を決定します。
- 100年のステーションの交差点から1980度以上の読み取り値の数を取得します。
- 100年のステーションの交差点から2020度以上の読み取り値の数を取得します。
- 結果を印刷します。
問題は、このロジックが完全にシーケンシャルであるということです。 あることが次々と起こります。 Rayを使用すると、このロジックの多くを並行して実行できます。
次の表は、より並列化可能なロジックを示しています。

この方法でロジックを書き出すことは、並列化可能な方法で実行できるすべてのことを確実に実行するための優れた方法です。 以下のコードは、このロジックを実装しています。
#コードは、現在の作業ディレクトリに1980.tar.gzファイルと2020.tar.gzファイルがあることを前提としています。 def compare_years(year1、year2、high_temp):#必要なワーカー数がデフォルトより少ないことがわかっている場合は、#num_cpusパラメーターを変更できますray.init(num_cpus = 2)#アクタープロセスを作成しますgsod_y1 = GSODActor.remote( year1、high_temp)gsod_y2 = GSODActor.remote(year2、high_temp)ray.get([gsod_y1.load_data.remote()、gsod_y2.load_data.remote()])y1_stations、y2_stations = ray.get([gsod_y1.get_stations.remote ()、gsod_y2.get_stations.remote()])intersection = set.intersection(y1_stations、y2_stations)y1_count、y2_count = ray.get([gsod_y1.get_high_temp_count.remote(intersection)、gsod_y2.get_high_temp_count.remote(section) print('共通ステーションの数:{}'。format(len(intersection)))print('{}-共通ステーションの高温カウント:{}'。format(year1、y1_count))print('{} -一般的なステーションの一時カウントが高い:{}'。format(year2、y2_count))#以下のコードを実行すると、どの年がより極端な温度であったかが出力されますcompare_years( '1980'、 '2020'、100)

上記のコードについて言及すべき重要なことがいくつかあります。 まず、@ ray.remoteデコレータをクラスレベルに配置すると、すべてのクラスメソッドをリモートで呼び出すことができます。 次に、上記のコードは、メソッドを並行して実行できる1つのアクタープロセス(gsod_y2とgsod_y1980)を利用します(ただし、各アクターは一度に2020つのメソッドしか実行できません)。 これにより、XNUMX年とXNUMX年のデータの読み込みと処理を同時に行うことができました。
まとめ
レイ は高速でシンプルな分散実行フレームワークであり、アプリケーションのスケーリングと最先端の機械学習ライブラリの活用を容易にします。 このチュートリアルでは、Rayを使用すると、順次実行される既存のPythonコードを簡単に取得して、最小限のコード変更で分散アプリケーションに変換する方法を示しました。 ここでの実験はすべて同じマシンで実行されましたが、 Rayを使用すると、すべての主要なクラウドプロバイダーでPythonコードを簡単にスケーリングできます。。 Rayについて詳しく知りたい場合は、 GitHubのRayプロジェクト、フォロー ツイッターで @raydistributed、にサインアップします レイニュースレター.
バイオ: マイケル・ガラニク はデータサイエンスの専門家であり、AnyscaleのDeveloperRelationsで働いています。
元の。 許可を得て転載。
関連する
| 過去30日間の人気記事 | |||||
|---|---|---|---|---|---|
|
|
||||
PlatoAi。 Web3の再考。 増幅されたデータインテリジェンス。
アクセスするには、ここをクリックしてください。
ソース:https://www.kdnuggets.com/2021/08/distributed-python-application-ray.html

