概要
AI コーディング エージェントを使用するアプリケーションが大幅に増加しています。 LLM の品質が向上し、推論コストが低下するにつれて、有能な AI エージェントの構築はますます簡単になっています。これに加えて、ツール エコシステムは急速に進化しており、複雑な AI コーディング エージェントの構築が容易になっています。 Langchain フレームワークは、この分野のリーダーです。本番環境に対応した AI アプリケーションを作成するために必要なツールとテクニックがすべて備わっています。
しかし、これまでのところ、一つ欠けていることがありました。それは周期性を備えたマルチエージェントのコラボレーションです。これは、問題を分割して専門のエージェントに委任できる複雑な問題を解決するために非常に重要です。ここで、AI コーディング エージェント間のマルチアクターのステートフル コラボレーションに対応するように設計された Langchain フレームワークの一部である LangGraph が登場します。さらに、この記事では、LangGraph とその基本的な構成要素について説明し、それを使用してエージェントを構築します。
学習目標
- LangGraph とは何かを理解します。
- ステートフル エージェントを構築するための LangGraph の基本を学びます。
- TogetherAI を探索して、次のようなオープンアクセス モデルにアクセスします ディープシークコーダー.
- LangGraph を使用して AI コーディング エージェントを構築し、単体テストを作成します。

この記事は、の一部として公開されました データサイエンスブログ。
目次
ランググラフとは何ですか?
LangGraph は、LangChain エコシステムの拡張です。 LangChain では、複数のツールを使用してタスクを実行できる AI コーディング エージェントを構築できますが、ステップ全体で複数のチェーンやアクターを調整することはできません。これは、複雑なタスクを実行するエージェントを作成する場合に重要な動作です。 LangGraph はこれらのことを念頭に置いて考案されました。これは、エージェント ワークフローを循環グラフ構造として扱います。各ノードは関数または Langchain Runnable オブジェクトを表し、エッジはノード間の接続です。
LangGraph の主な機能は次のとおりです。
- Nodes: ツールなどの関数または Langchain Runnable オブジェクト。
- エッジ: ノード間の方向を定義します。
- ステートフル グラフ: グラフの主なタイプ。ノードを通じてデータを処理する際に、状態オブジェクトを管理および更新するように設計されています。
LangGraph はこれを利用して、状態の永続性を備えた周期的な LLM 呼び出しの実行を促進します。これはエージェントの動作にとって重要です。この建築は以下からインスピレーションを得ています。 プレゲル & アパッチビーム.
この記事では、メソッドを使用して Python クラスの Pytest 単体テストを作成するエージェントを構築します。そしてこれがワークフローです。
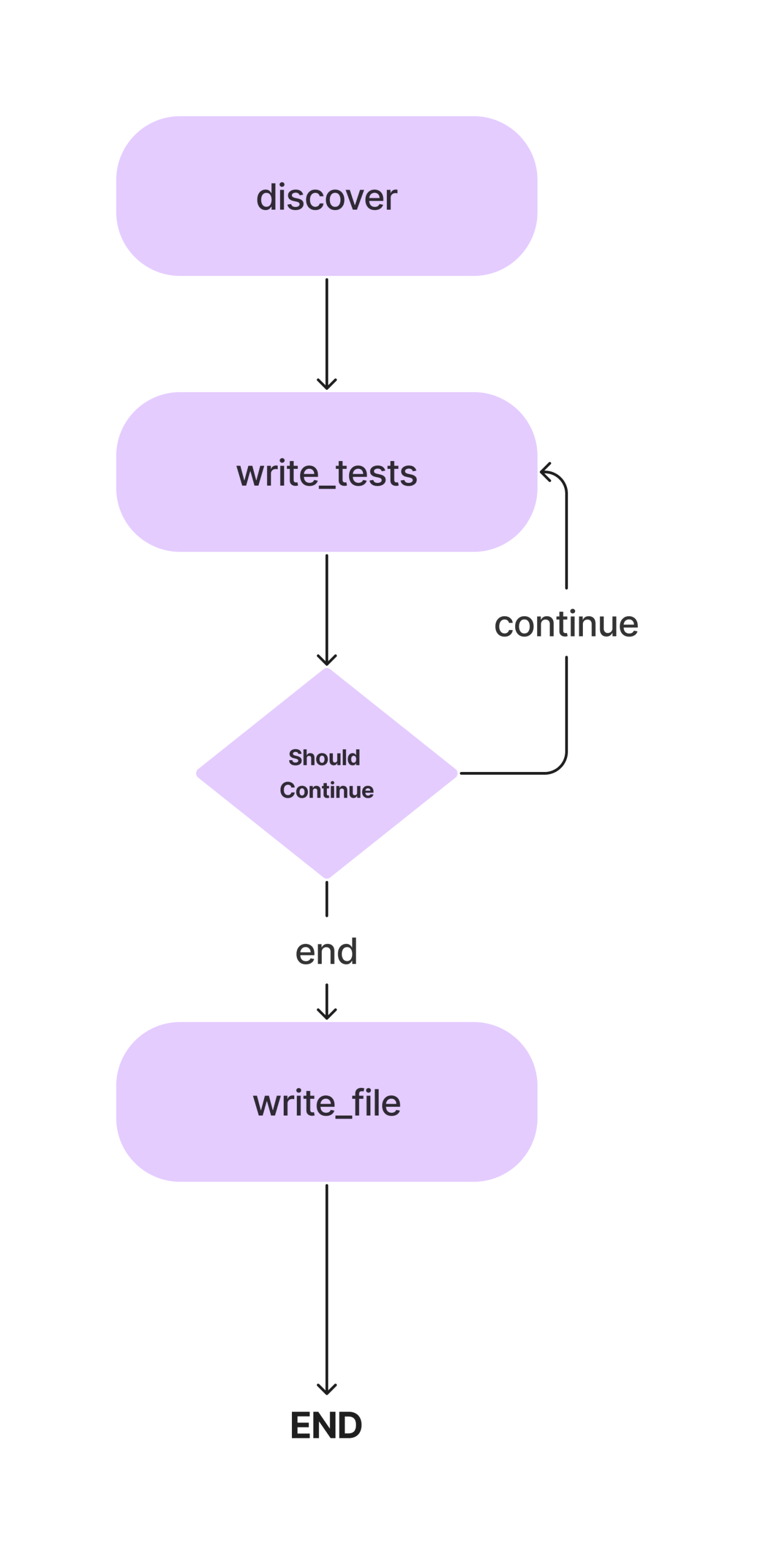
単純な単体テストを作成するための AI コーディング エージェントを構築する際に、その概念について詳しく説明します。それでは、コーディング部分に移りましょう。
その前に、開発環境をセットアップしましょう。
依存関係をインストールする
まず最初に。他の Python プロジェクトと同様に、仮想環境を作成してアクティブ化します。
python -m venv auto-unit-tests-writer
cd auto-unit-tests-writer
source bin/activate次に、依存関係をインストールします。
!pip install langgraph langchain langchain_openai coloramaすべてのライブラリとそのクラスをインポートします。
from typing import TypedDict, List
import colorama
import os
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage
from langchain_core.messages import HumanMessage
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, END
from langgraph.pregel import GraphRecursionErrorテスト ケース用のディレクトリとファイルも作成する必要があります。ファイルを手動で作成することも、Python を使用することもできます。
# Define the paths.
search_path = os.path.join(os.getcwd(), "app")
code_file = os.path.join(search_path, "src/crud.py")
test_file = os.path.join(search_path, "test/test_crud.py")
# Create the folders and files if necessary.
if not os.path.exists(search_path):
os.mkdir(search_path)
os.mkdir(os.path.join(search_path, "src"))
os.mkdir(os.path.join(search_path, "test"))次に、インメモリ CRUD アプリのコードを使用して crud.py ファイルを更新します。このコード部分を使用して単体テストを作成します。これには Python プログラムを使用できます。以下のプログラムを code.py ファイルに追加します。
#crud.py
code = """class Item:
def __init__(self, id, name, description=None):
self.id = id
self.name = name
self.description = description
def __repr__(self):
return f"Item(id={self.id}, name={self.name}, description={self.description})"
class CRUDApp:
def __init__(self):
self.items = []
def create_item(self, id, name, description=None):
item = Item(id, name, description)
self.items.append(item)
return item
def read_item(self, id):
for item in self.items:
if item.id == id:
return item
return None
def update_item(self, id, name=None, description=None):
for item in self.items:
if item.id == id:
if name:
item.name = name
if description:
item.description = description
return item
return None
def delete_item(self, id):
for index, item in enumerate(self.items):
if item.id == id:
return self.items.pop(index)
return None
def list_items(self):
return self.items"""
with open(code_file, 'w') as f:
f.write(code)LLM のセットアップ
次に、このプロジェクトで使用する LLM を指定します。ここでどのモデルを使用するかは、タスクとリソースの可用性によって異なります。 GPT-4、Gemini Ultra、GPT-3.5 などの独自の強力なモデルを使用できます。また、Mixtral や Llama-2 などのオープンアクセス モデルを使用することもできます。この場合、コードの記述が含まれるため、DeepSeekCoder-33B や Llama-2 コーダーなどの微調整されたコーディング モデルを使用できます。現在、LLM 推論には、Anayscale、Abacus、Togetter などの複数のプラットフォームがあります。 Together AI を使用して DeepSeekCoder を推論します。それで、 APIキー 先に進む前に「Togetter」から。
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(base_url="https://api.together.xyz/v1",
api_key="your-key",
model="deepseek-ai/deepseek-coder-33b-instruct")Together API は OpenAI SDK と互換性があるため、base_url パラメーターを次のように変更することで、Langchain の OpenAI SDK を使用して Together でホストされているモデルと通信できます。 「https://api.together.xyz/v1」。 api_key で Together API キーを渡し、モデルの代わりに モデル名 Together で利用可能です。
エージェント状態の定義
これは、LangGraph の重要な部分の 1 つです。ここでは、実行中のエージェントの状態を追跡する役割を担う AgentState を定義します。これは主に、エージェントの状態を維持するエンティティを含む TypedDict クラスです。 AgentState を定義しましょう
class AgentState(TypedDict):
class_source: str
class_methods: List[str]
tests_source: str上記の AgentState クラスでは、class_source には元の Python クラスが格納され、class_methods にはクラスのメソッドが格納され、tests_source には単体テスト コードが格納されます。これらを AgentState として定義し、実行ステップ全体で使用できるようにしました。
次に、AgentState を使用してグラフを定義します。
# Create the graph.
workflow = StateGraph(AgentState)前述したように、これはステートフル グラフであり、状態オブジェクトを追加しました。
ノードの定義
AgentState を定義したので、ノードを追加する必要があります。では、ノードとは正確には何でしょうか? LangGraph では、ノードは関数、または単一のアクションを実行するラングチェーン ツールなどの実行可能なオブジェクトです。この例では、クラス メソッドを検索する関数、単体テストを推論して状態オブジェクトに更新する関数、それをテスト ファイルに書き込む関数など、複数のノードを定義できます。
LLM メッセージからコードを抽出する方法も必要です。その方法は次のとおりです。
def extract_code_from_message(message):
lines = message.split("n")
code = ""
in_code = False
for line in lines:
if "```" in line:
in_code = not in_code
elif in_code:
code += line + "n"
return codeここのコード スニペットでは、コードが三重引用符の中にあることを前提としています。
次に、ノードを定義しましょう。
import_prompt_template = """Here is a path of a file with code: {code_file}.
Here is the path of a file with tests: {test_file}.
Write a proper import statement for the class in the file.
"""
# Discover the class and its methods.
def discover_function(state: AgentState):
assert os.path.exists(code_file)
with open(code_file, "r") as f:
source = f.read()
state["class_source"] = source
# Get the methods.
methods = []
for line in source.split("n"):
if "def " in line:
methods.append(line.split("def ")[1].split("(")[0])
state["class_methods"] = methods
# Generate the import statement and start the code.
import_prompt = import_prompt_template.format(
code_file=code_file,
test_file=test_file
)
message = llm.invoke([HumanMessage(content=import_prompt)]).content
code = extract_code_from_message(message)
state["tests_source"] = code + "nn"
return state
# Add a node to for discovery.
workflow.add_node(
"discover",
discover_function
)
上記のコード スニペットでは、コードを検出するための関数を定義しました。 AgentState からコードを抽出します。 クラスソース 要素を使用して、クラスを個別のメソッドに分割し、それをプロンプトとともに LLM に渡します。出力は AgentState の テストソース 要素。単体テスト ケースのインポート ステートメントのみを作成するようにします。
また、最初のノードを StateGraph オブジェクトに追加しました。
さて、次のノードに進みます。
また、ここで必要となるいくつかのプロンプト テンプレートをセットアップすることもできます。これらは必要に応じて変更できるサンプル テンプレートです。
# System message template.
system_message_template = """You are a smart developer. You can do this! You will write unit
tests that have a high quality. Use pytest.
Reply with the source code for the test only.
Do not include the class in your response. I will add the imports myself.
If there is no test to write, reply with "# No test to write" and
nothing more. Do not include the class in your response.
Example:
```
def test_function():
...
```
I will give you 200 EUR if you adhere to the instructions and write a high quality test.
Do not write test classes, only methods.
"""
# Write the tests template.
write_test_template = """Here is a class:
'''
{class_source}
'''
Implement a test for the method "{class_method}".
"""次に、ノードを定義します。
# This method will write a test.
def write_tests_function(state: AgentState):
# Get the next method to write a test for.
class_method = state["class_methods"].pop(0)
print(f"Writing test for {class_method}.")
# Get the source code.
class_source = state["class_source"]
# Create the prompt.
write_test_prompt = write_test_template.format(
class_source=class_source,
class_method=class_method
)
print(colorama.Fore.CYAN + write_test_prompt + colorama.Style.RESET_ALL)
# Get the test source code.
system_message = SystemMessage(system_message_template)
human_message = HumanMessage(write_test_prompt)
test_source = llm.invoke([system_message, human_message]).content
test_source = extract_code_from_message(test_source)
print(colorama.Fore.GREEN + test_source + colorama.Style.RESET_ALL)
state["tests_source"] += test_source + "nn"
return state
# Add the node.
workflow.add_node(
"write_tests",
write_tests_function
)ここでは、LLM に各メソッドのテスト ケースを作成させ、それらを AgentState の testing_source 要素に更新して、ワークフロー StateGraph オブジェクトに追加します。
エッジ
2 つのノードができたので、それらの間にエッジを定義して、ノード間の実行方向を指定します。 LangGraph は主に 2 種類のエッジを提供します。
- 条件付きエッジ: 実行の流れはエージェントの応答によって異なります。これは、ワークフローに周期性を追加するために非常に重要です。エージェントは、いくつかの条件に基づいて次にどのノードを移動するかを決定できます。前のノードに戻るか、現在のノードを繰り返すか、次のノードに移動するか。
- ノーマルエッジ: これは通常のケースで、ノードは常に前のノードの呼び出し後に呼び出されます。
Discover と write_tests を接続するための条件は必要ないため、通常のエッジを使用します。また、実行を開始する場所を指定するエントリ ポイントを定義します。
# Define the entry point. This is where the flow will start.
workflow.set_entry_point("discover")
# Always go from discover to write_tests.
workflow.add_edge("discover", "write_tests")実行はメソッドの検出から始まり、テストの作成機能に進みます。単体テスト コードをテスト ファイルに書き込むには別のノードが必要です。
# Write the file.
def write_file(state: AgentState):
with open(test_file, "w") as f:
f.write(state["tests_source"])
return state
# Add a node to write the file.
workflow.add_node(
"write_file",
write_file)これが最後のノードなので、write_tests と write_file の間のエッジを定義します。これができる方法です。
# Find out if we are done.
def should_continue(state: AgentState):
if len(state["class_methods"]) == 0:
return "end"
else:
return "continue"
# Add the conditional edge.
workflow.add_conditional_edges(
"write_tests",
should_continue,
{
"continue": "write_tests",
"end": "write_file"
}
)add_conditional_edge 関数は、write_tests 関数、class_methods エントリに基づいて実行するステップを決定する should_Continue 関数、および文字列をキーとして使用し、他の関数を値として使用するマッピングを受け取ります。
エッジは write_tests で開始し、 should_ continue の出力に基づいて、マッピング内のいずれかのオプションを実行します。たとえば、state[“class_methods”] が空でない場合、すべてのメソッドのテストを作成していないことになります。 write_tests 関数を繰り返し、テストの作成が完了すると、write_file が実行されます。
すべてのメソッドのテストが次から推論されたとき LLM、テストはテスト ファイルに書き込まれます。
次に、クロージャのワークフロー オブジェクトに最後のエッジを追加します。
# Always go from write_file to end.
workflow.add_edge("write_file", END)ワークフローを実行する
最後に残ったのは、ワークフローをコンパイルして実行することです。
# Create the app and run it
app = workflow.compile()
inputs = {}
config = RunnableConfig(recursion_limit=100)
try:
result = app.invoke(inputs, config)
print(result)
except GraphRecursionError:
print("Graph recursion limit reached.")これによりアプリが起動されます。再帰制限は、特定のワークフローに対して LLM が推論される回数です。制限を超えると、ワークフローは停止します。
ログはターミナルまたはノートブックで確認できます。これは、単純な CRUD アプリの実行ログです。
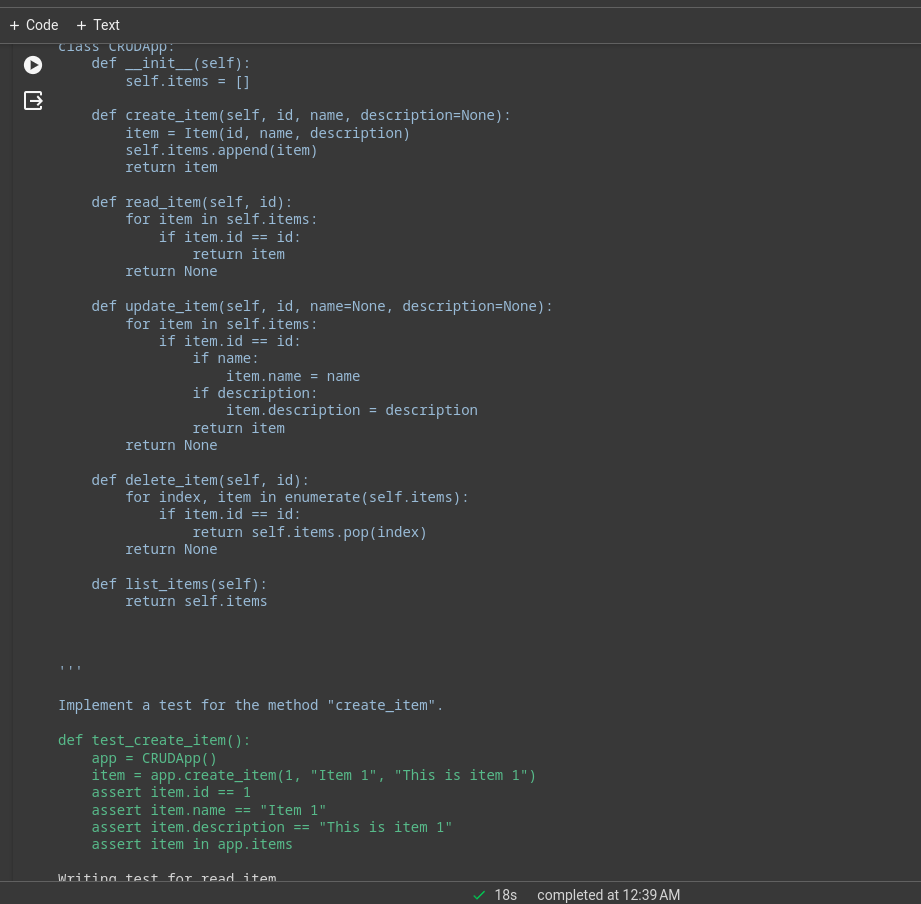
重労働の多くは基礎となるモデルによって行われます。これは Deepseek コーダー モデルを使用したデモ アプリケーションであり、パフォーマンスを向上させるために GPT-4 や Claude Opus、俳句などを使用できます。
Web サーフィンや株価分析などに Langchain ツールを使用することもできます。
ラングチェーンとランググラフ
さて、問題は、LangChain と LangChain をいつ使用するかです。 ランググラフ.
目標が、複数のエージェント間で調整を行うマルチエージェント システムを作成することである場合は、LangGraph が最適です。ただし、DAG またはチェーンを作成してタスクを完了したい場合は、LangChain 式言語が最適です。
LangGraph を使用する理由
LangGraph は、多くの既存のソリューションを改善できる強力なフレームワークです。
- RAG パイプラインの改善: LangGraph は、循環グラフ構造を使用して RAG を拡張できます。フィードバック ループを導入して、取得したオブジェクトの品質を評価し、必要に応じてクエリを改善してプロセスを繰り返すことができます。
- マルチエージェントのワークフロー: LangGraph は、マルチエージェント ワークフローをサポートするように設計されています。これは、より小さなサブタスクに分割された複雑なタスクを解決するために重要です。状態が共有されているさまざまなエージェントとさまざまな LLM およびツールが連携して、1 つのタスクを解決できます。
- 人間のループ: LangGraph には、人間参加型ワークフローのサポートが組み込まれています。これは、人間が次のノードに移動する前に状態を確認できることを意味します。
- 企画エージェント: LangGraph は、計画エージェントの構築に適しています。LLM プランナーがユーザー要求を計画および分解し、エグゼキューターがツールと関数を呼び出し、LLM が以前の出力に基づいて回答を合成します。
- マルチモーダルエージェント: LangGraph はビジョン対応などのマルチモーダル エージェントを構築できます ウェブナビゲーター。
実際の使用例
複雑な AI コーディング エージェントが役立つ分野は数多くあります。
- パーソナルエージェントs: あなたの電子デバイス上にジャービスのようなアシスタントがいて、テキスト、音声、さらにはジェスチャーでさえも、あなたの命令に従ってタスクを手伝ってくれる状態を想像してみてください。これは AI エージェントの最も魅力的な使い方の 1 つです。
- AIインストラクター: チャットボットは優れていますが、限界があります。適切なツールを備えた AI エージェントは、基本的な会話を超えることができます。ユーザーのフィードバックに基づいて指導方法を適応できる仮想 AI インストラクターは、状況を一変させる可能性があります。
- ソフトウェアUX: AI エージェントを使用すると、ソフトウェアのユーザー エクスペリエンスを向上させることができます。エージェントはアプリケーションを手動で操作する代わりに、音声またはジェスチャー コマンドを使用してタスクを実行できます。
- 空間コンピューティング:AR/VRテクノロジーの人気が高まるにつれて、AIエージェントの需要も高まるでしょう。エージェントは周囲の情報を処理し、オンデマンドでタスクを実行できます。これは近い将来、AI エージェントの最良の使用例の 1 つになる可能性があります。
- LLM OS: エージェントが第一級市民である AI ファーストのオペレーティング システム。エージェントは日常的なタスクから複雑なタスクまでを担当します。
まとめ
LangGraph は、サイクリック ステートフル マルチアクター エージェント システムを構築するための効率的なフレームワークです。これは、元の LangChain フレームワークのギャップを埋めます。これは LangChain の拡張であるため、LangChain エコシステムの利点をすべて活用できます。 LLM の品質と機能が向上するにつれて、複雑なワークフローを自動化するためのエージェント システムの作成がはるかに簡単になります。したがって、記事からの重要なポイントを以下に示します。
主要な取り組み
- LangGraph は LangChain の拡張機能であり、これにより周期的でステートフルなマルチアクター エージェント システムを構築できます。
- ノードとエッジを含むグラフ構造を実装します。ノードは機能またはツールであり、エッジはノード間の接続です。
- エッジには、条件付きと通常の 2 つのタイプがあります。条件付きエッジには、あるエッジから別のエッジに移動する際に条件があります。これは、ワークフローに周期性を追加するために重要です。
- LangGraph は循環マルチアクター エージェントの構築に適していますが、LangChain はチェーンまたは有向非循環システムの作成に優れています。
よくある質問
答え。 LangGraph は、ステートフルなサイクリック マルチアクター エージェント システムを構築するためのオープンソース ライブラリです。これは、LangChain エコシステムの上に構築されています。
答え。 LangGraph は循環マルチアクター エージェントの構築に適していますが、LangChain はチェーンまたは有向非循環システムの作成に優れています。
答え。 AI エージェントは、環境と対話し、意思決定を行い、最終目標を達成するために行動するソフトウェア プログラムです。
答え。これはユースケースと予算によって異なります。 GPT 4 は最も機能が優れていますが、高価です。コーディングには、DeepSeekCoder-33b が非常に安価なオプションです。
答え。チェーンは、従うべきハードコードされたアクションのシーケンスであり、エージェントは LLM およびその他のツール (チェーンも) を使用して、情報に従って推論し、行動します。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2024/03/build-an-ai-coding-agent-with-langgraph-by-langchain/

